【Kubernetes专项】Pod 资源的常见状态及重启策略
Kubernetes Pod 常见状态分为核心生命周期状态(Pod Phase)和具体容器状态。主要生命周期状态包括 Pending(未调度)、Running(运行中)、Succeeded(成功终止)、Failed(异常终止)和 Unknown(未知状态)。常见容器状态问题有 ImagePullBackOff(镜像拉取失败)、CrashLoopBackOff(容器崩溃循环)、OOMKilled(内
七、常见状态、重启策略
7.1 Kubernetes Pod 常见状态
7.1.1 第一阶段:Pod Phase(核心生命周期状态)
7.1.1.1 Failed
Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止(如 OOMKilled)
7.1.1.2 Unknown
未知状态,当 apiserver 无法与节点上的 kubelet 通信获取状态信息时出现。通常是由于节点故障、网络问题或 kubelet 服务异常导致。
7.1.1.3 Succeeded
Pod 中的所有容器都被成功终止,即所有容器正常退出(退出码为 0),且不会重启。常见于 Job 类型的工作负载。
7.1.1.4 Running
Pod 已被分配到节点,所有容器已创建,至少有一个容器正在运行或处于重启过程中。注意:此状态不保证应用已就绪。
7.1.1.5 Pending
Pod 已被集群接受,但尚未调度到节点,或正在拉取镜像。可能原因包括资源不足、镜像拉取中、调度延迟等。
7.1.2 第二阶段:Pod Conditions 与容器状态
7.1.2.1 Unschedulable
Pod 不能被调度,scheduler 未匹配到合适的 node 节点。常见原因:资源不足、节点选择器不匹配、污点容忍度问题。
7.1.2.2 PodScheduled
Pod 已成功分配到节点,但容器尚未启动。调度器已将 Pod 绑定到特定节点。
7.1.2.3 Initialized
所有 Pod 中的初始化容器(Init Containers)已完成。
7.1.2.4 ImagePullBackOff
Pod 所在节点下载镜像失败,kubelet 正在指数退避重试。原因可能是镜像不存在、认证失败或网络问题。
7.1.2.5 CrashLoopBackOff
容器反复崩溃重启,kubelet 正在指数退避延迟重启(10s/20s/40s…,上限 5 分钟)。表明应用存在严重问题。
7.1.2.6 ContainerCreating
容器正在创建过程中,可能因配置问题或资源准备导致延迟。
7.1.2.7 Terminating
Pod 正在终止过程中,Kubernetes 已发送终止信号,等待优雅终止周期结束。
7.1.2.8 OOMKilled
容器内存使用超出配置的限制值,被 Linux 内核 OOM (Out Of Memory) killer 强制终止。退出码通常为 137(128+SIGKILL),表明容器因内存超限被系统杀死。常见于未合理配置内存限制或应用存在内存泄漏的场景。
7.1.2.9 Evicted
节点资源压力(磁盘/内存/inode)超过阈值时,kubelet 主动驱逐 Pod 的状态。典型表现为磁盘空间不足(如 /var 分区使用率 >95%),节点会删除 Pod 以释放资源。被驱逐的 Pod 不会在原节点重启,需由控制器(如 Deployment)重建并调度到其他节点。
7.1.2.10 NodeLost
节点失联超过 pod-eviction-timeout(默认 5 分钟)时触发的状态。此时 API Server 无法与节点通信获取 Pod 状态,Pod Phase 变为 Unknown。通常由节点宕机、网络分区或 kubelet 服务异常引起,Kubernetes 会尝试在其他节点重建 Pod。
7.1.2.11 Error
容器启动后立即失败(非 0 退出码),但未进入重启循环的状态。与 CrashLoopBackOff 的区别在于:Error 通常发生在 restartPolicy=Never 的场景,或容器在首次启动时即失败。可能原因包括应用配置错误、依赖服务不可用或启动命令执行失败。
7.1.3 汇总
官方定义:
kubectl get pods的 STATUS 列中显示的基础状态,反映 Pod 整体生命周期阶段
| 状态 | 触发条件 | 典型场景 | 处理建议 |
|---|---|---|---|
| Pending | Pod 已创建但未调度到节点,或正在拉取镜像 | 资源不足、镜像下载中、调度延迟 | 检查节点资源/污点、镜像仓库状态、调度器日志 |
| Running | Pod 已绑定节点,所有容器创建完成,至少一个容器在运行/重启中 | 服务正常运行、容器崩溃重启中 | 结合就绪探针判断业务可用性;检查 CrashLoopBackOff |
| Succeeded | 所有容器成功终止(退出码 0),且不会重启 | Job/CronJob 任务完成 | 无需干预,由 Job 控制器管理 |
| Failed | 所有容器已终止,且至少一个容器失败(非 0 退出码或被系统终止) | 应用崩溃、资源超限、启动命令错误 | 检查容器日志:kubectl logs <pod> --previous |
| Unknown | API Server 无法从节点获取状态(通信中断) | 节点宕机、网络分区、kubelet 崩溃 | 检查节点状态:kubectl get node <node>;修复节点或等待自动重建 |
本质:
kubectl get podsSTATUS 列显示的具体原因,由容器状态和事件触发
| 状态 | 根本原因 | 关键特征 | 诊断命令 |
|---|---|---|---|
| ContainerCreating | 容器创建中(CRI 运行时操作) | 持续数秒~数分钟;常见于首次启动 | kubectl describe pod | grep -A 10 Events |
| PodInitializing | Init 容器正在运行 | Init 容器未完成前,主容器不启动 | 检查 Init 容器日志:kubectl logs <pod> -c <init-container> |
| ImagePullBackOff | 镜像拉取失败(仓库不存在/认证错误/网络问题) | 伴随 ErrImagePull 事件 |
检查镜像名称:kubectl describe pod | grep -i image |
| CrashLoopBackOff | 容器反复崩溃(非 0 退出码),kubelet 指数退避重启 | STATUS 轮流显示 Error → CrashLoopBackOff |
检查应用日志:kubectl logs <pod> --previous |
| Error | 容器启动后立即失败(非 0 退出码) | 与 CrashLoopBackOff 区别:未进入重启循环(如 restartPolicy=Never) | 检查启动命令:kubectl get pod -o jsonpath='{.spec.containers[0].command}' |
| Terminating | Pod 正在终止(收到 SIGTERM,等待优雅停机) | 持续时间 = terminationGracePeriodSeconds(默认 30s) |
强制删除:kubectl delete pod <pod> --grace-period=0 --force |
| OOMKilled | 容器内存超限被 Linux 内核杀死 | 退出码 137(128+9);事件含 OOMKilled |
检查内存限制:kubectl describe pod | grep -A 5 Limits |
| Evicted | 节点级资源压力触发 kubelet 主动驱逐(磁盘/内存/inode) | Phase 为 Failed;事件含 The node was low on resource |
清理节点资源:kubectl get pods --field-selector=status.phase==Failed -A -o name | xargs kubectl delete |
| NodeLost | 节点失联超过 pod-eviction-timeout(默认 5m) |
Phase 为 Unknown;STATUS 显示 NodeLost |
检查节点网络/供电;等待控制器重建 Pod |
| CreateContainerError | 容器创建失败(volume 挂载错误、权限不足、CRI 运行时故障) | 事件含 Failed to create container |
检查存储配置:kubectl describe pvc <pvc> |
| DeadlineExceeded | Job 超过 activeDeadlineSeconds 时限 |
Job Pod 被主动终止 | 调整 Job 超时:kubectl edit job <job> |
| Preempting | 被高优先级 Pod 抢占资源(调度器行为) | 仅出现在 Pending 阶段 | 检查 Pod 优先级:kubectl get pod -o custom-columns=NAME:.metadata.name,PRIORITY:.spec.priority |
7.2 Kubernetes Pod 重启策略
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,当某个容器异常退出或者健康检查失败时,kubelet将根据 重启策略来进行相应的操作。
Pod 的 spec 中包含一个 restartPolicy 字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
Always:- 只要容器异常退出,kubelet就会自动重启该容器。(这个是默认的重启策略)
OnFailure:- 当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
Never:- 不论容器运行状态如何,kubelet都不会重启该容器。
7.2.1 测试参数示例
7.2.1.1 Always 重启策略
[root@k8s-master1 pod]# vim pod-restart-always.yaml
[root@k8s-master1 pod]# more pod-restart-always.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-restart-always-demo
labels:
app: myapp
spec:
restartPolicy: "Always"
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: docker.io/xianchao/tomcat-8.5-jre8:v1
imagePullPolicy: IfNotPresent
[root@k8s-master1 pod]# kubectl apply -f pod-restart-always.yaml
pod/pod-restart-always-demo created
[root@k8s-master1 pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-restart-always-demo 1/1 Running 0 5s
# 打开另外一个终端去实时查看Pod资源转改变化过程(watch -n1 kubectl get pods)
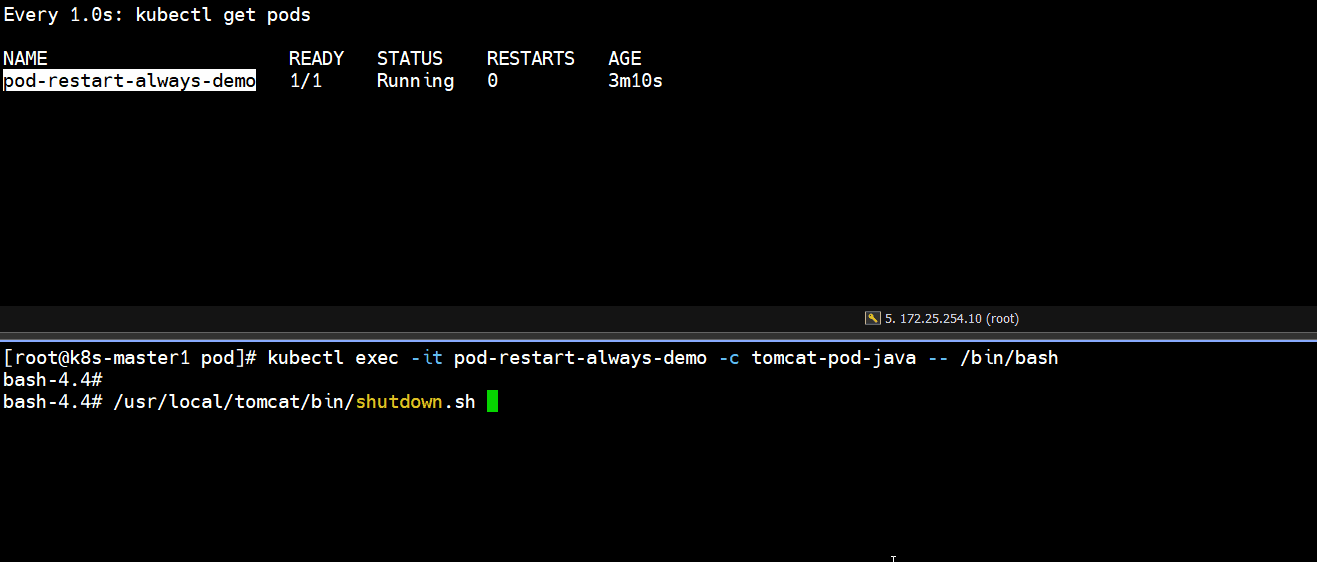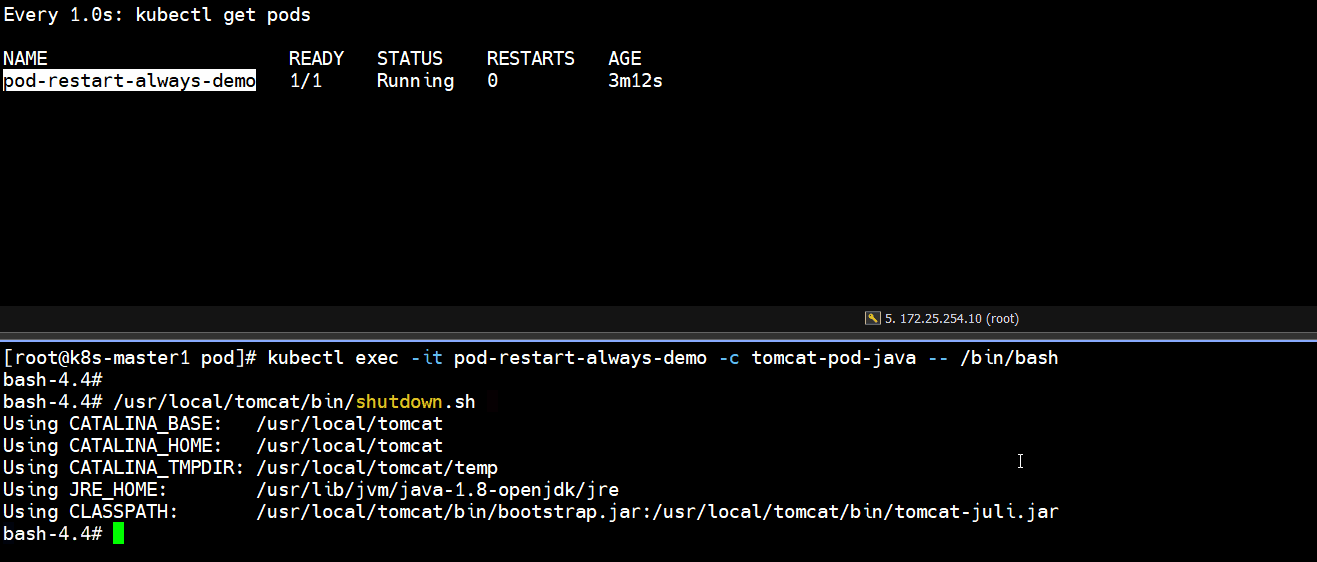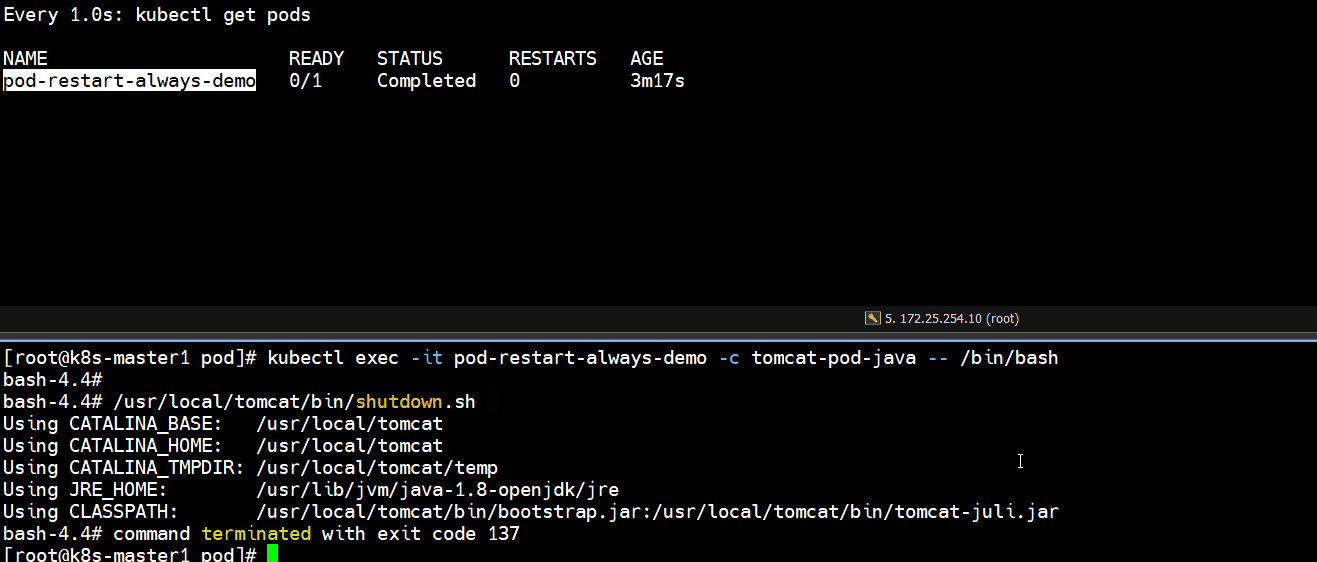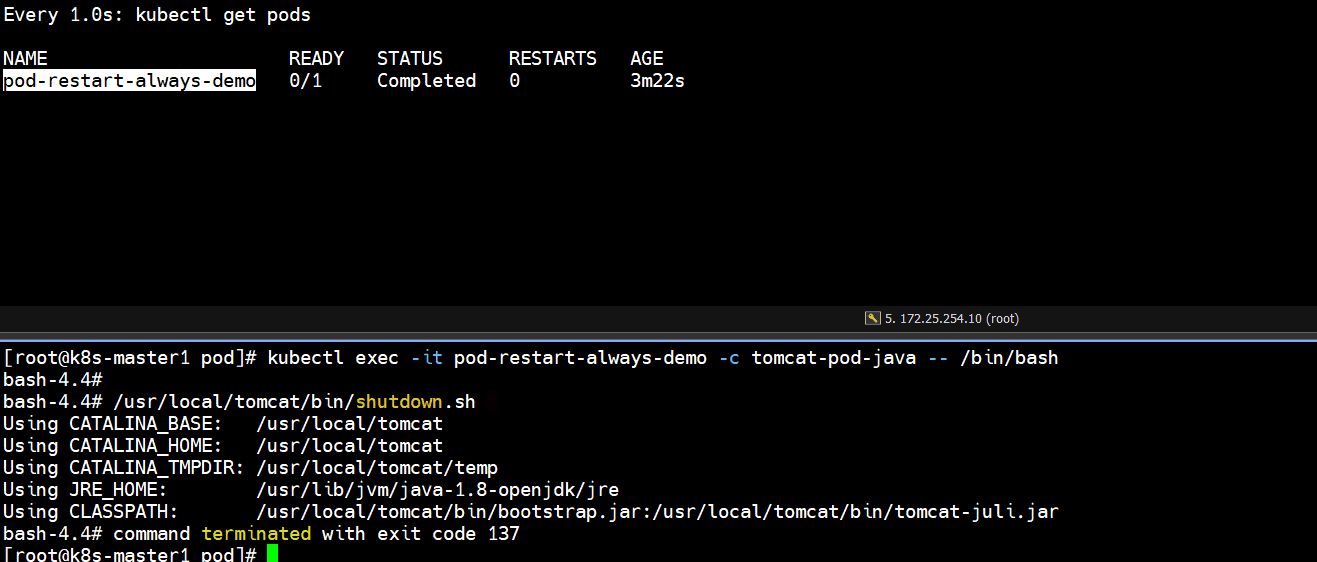
- 正常停止容器里的tomcat服务
]# kubectl exec -it pod-restart-always-demo -c tomcat-pod-java -- /bin/bash
bash-4.4# /usr/local/tomcat/bin/shutdown.sh
]# kubectl get pods
# 发现正常停止容器里的tomcat服务,容器重启了一次,pod又恢复正常了(如下图所示)
Running -- Completed -- Running
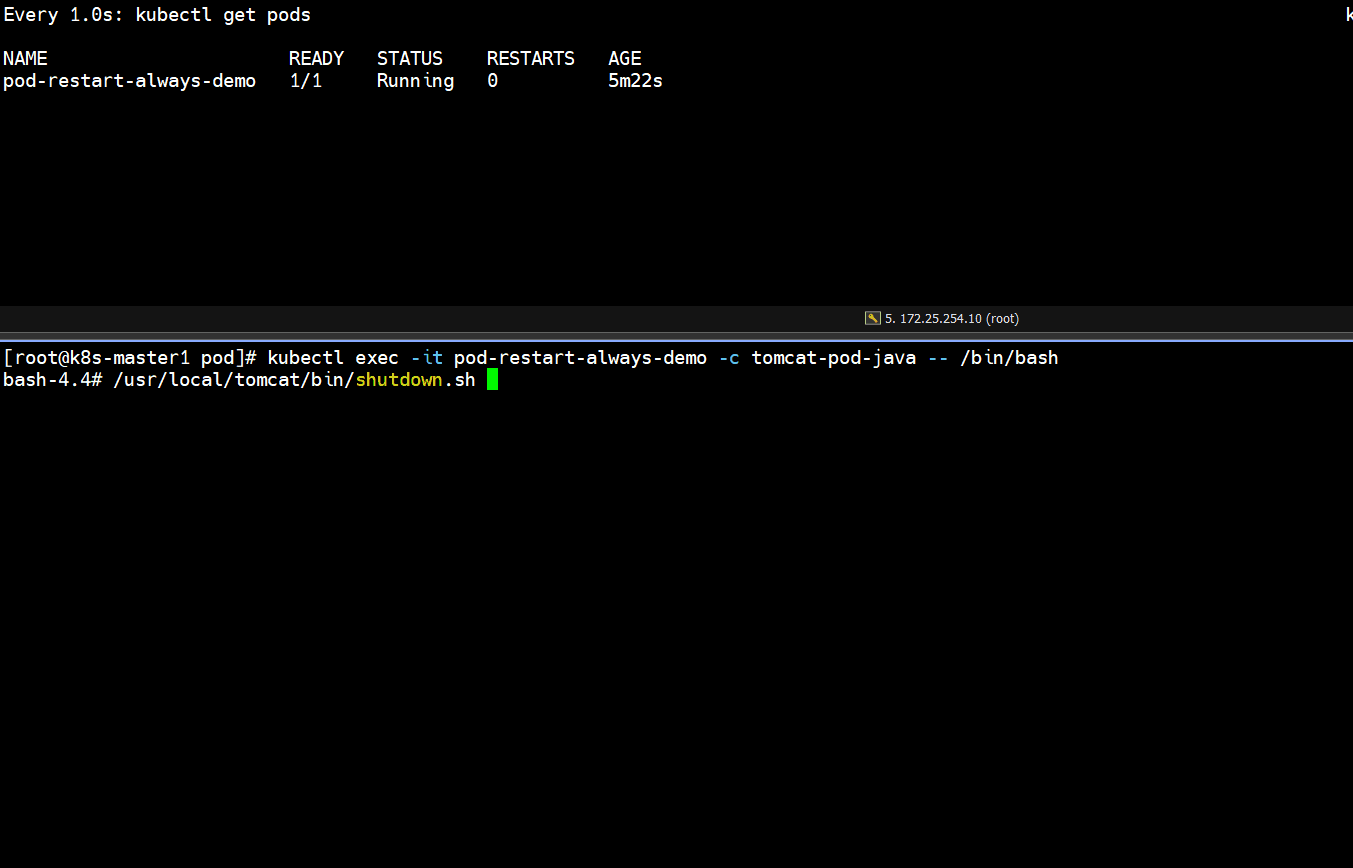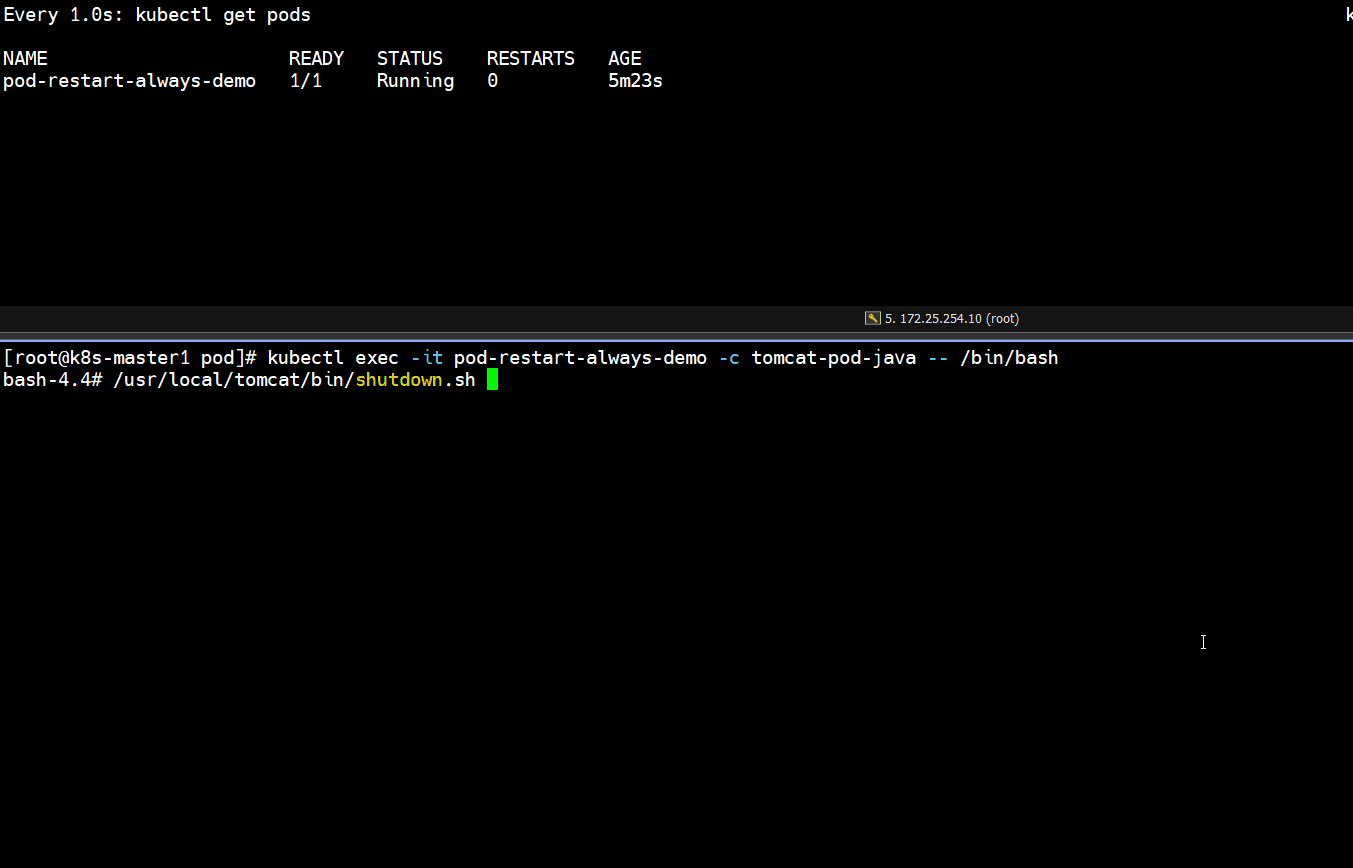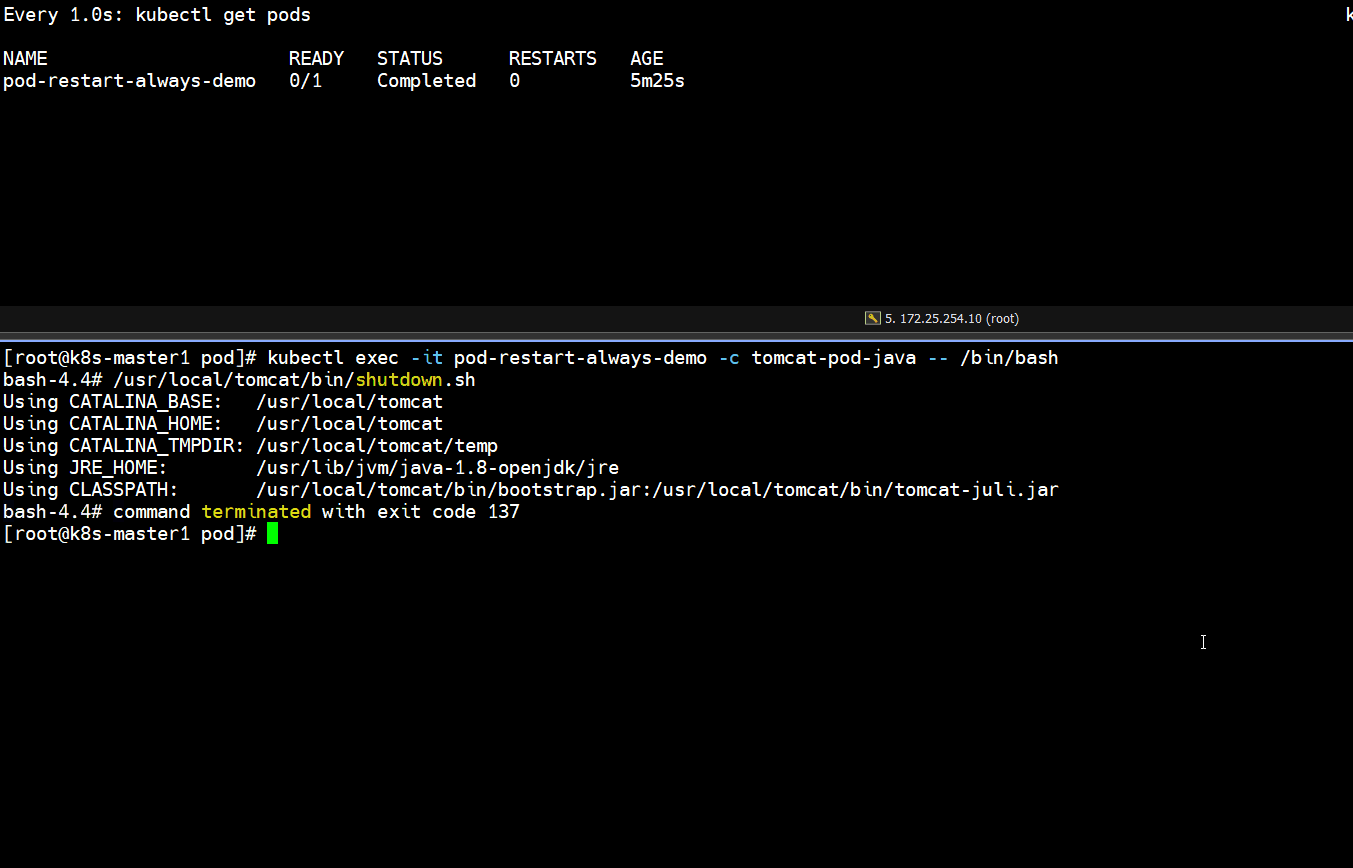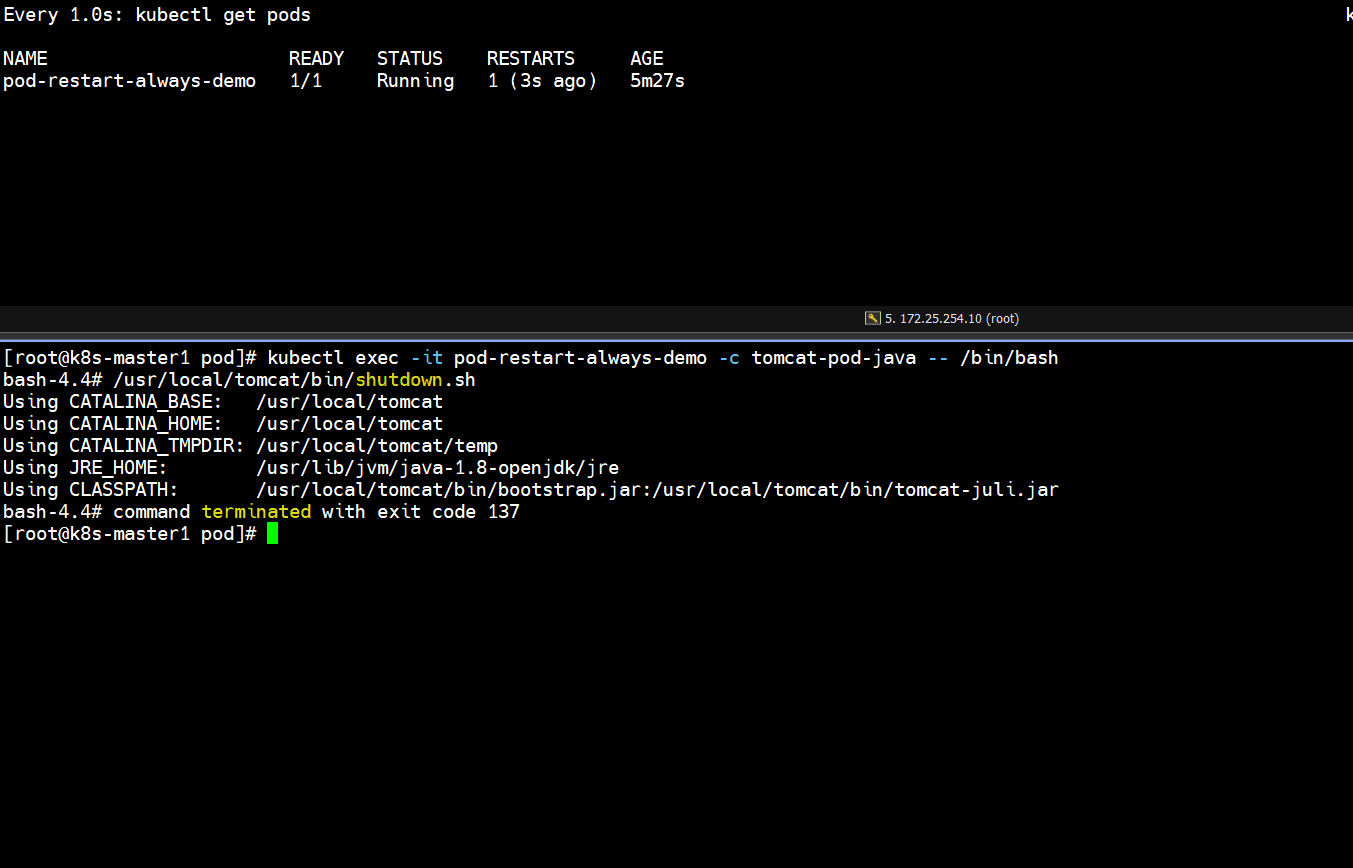
- 非正常停止容器里面的tomcat服务
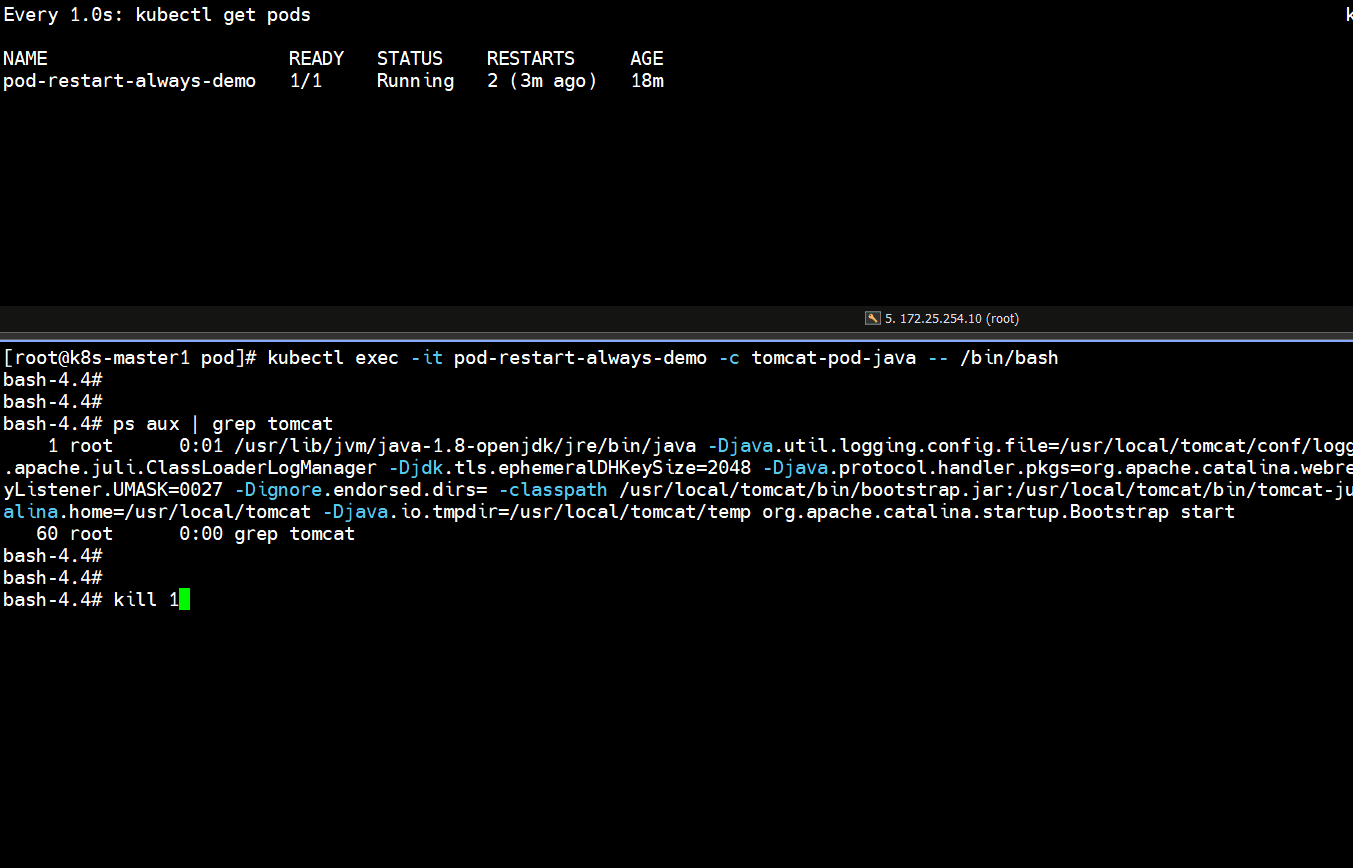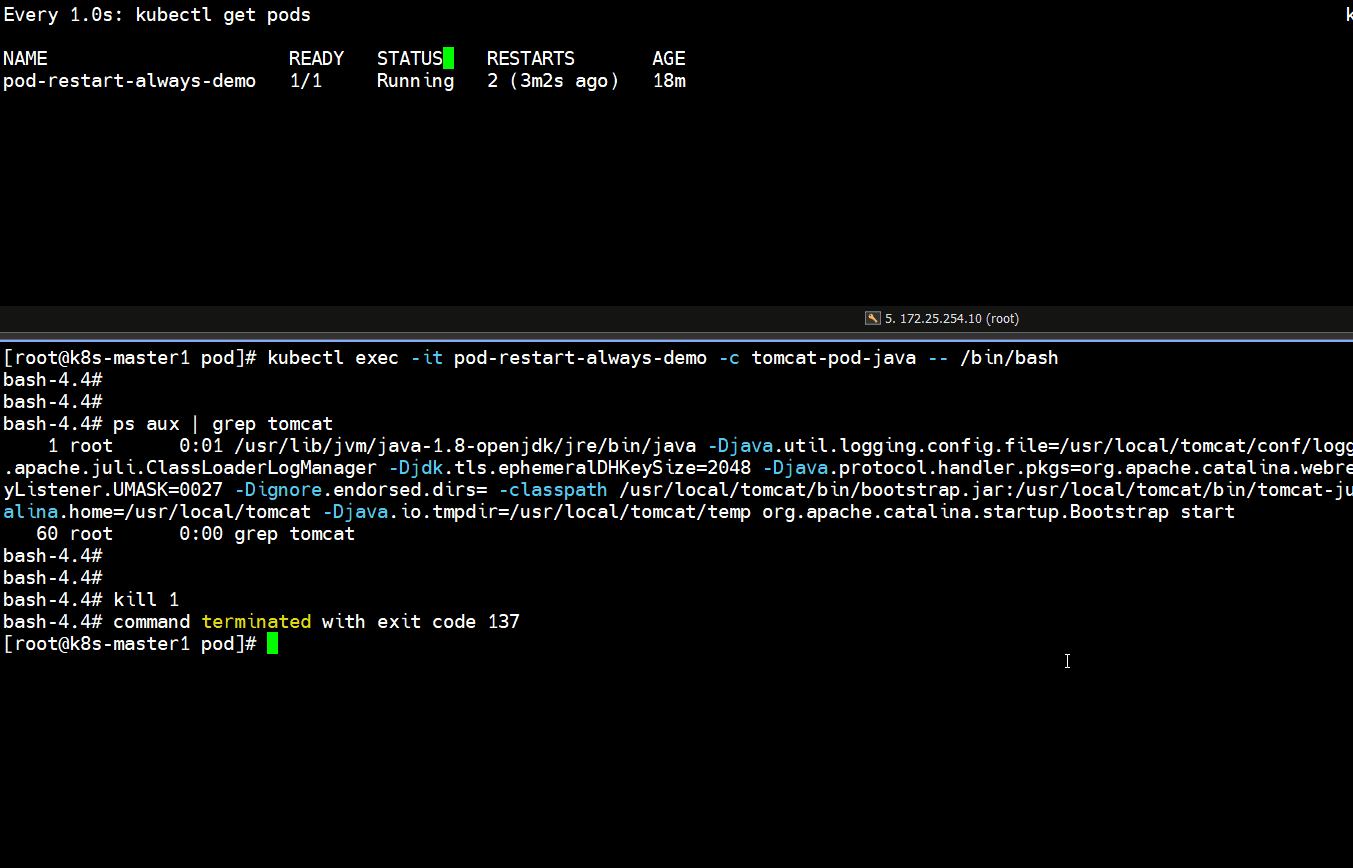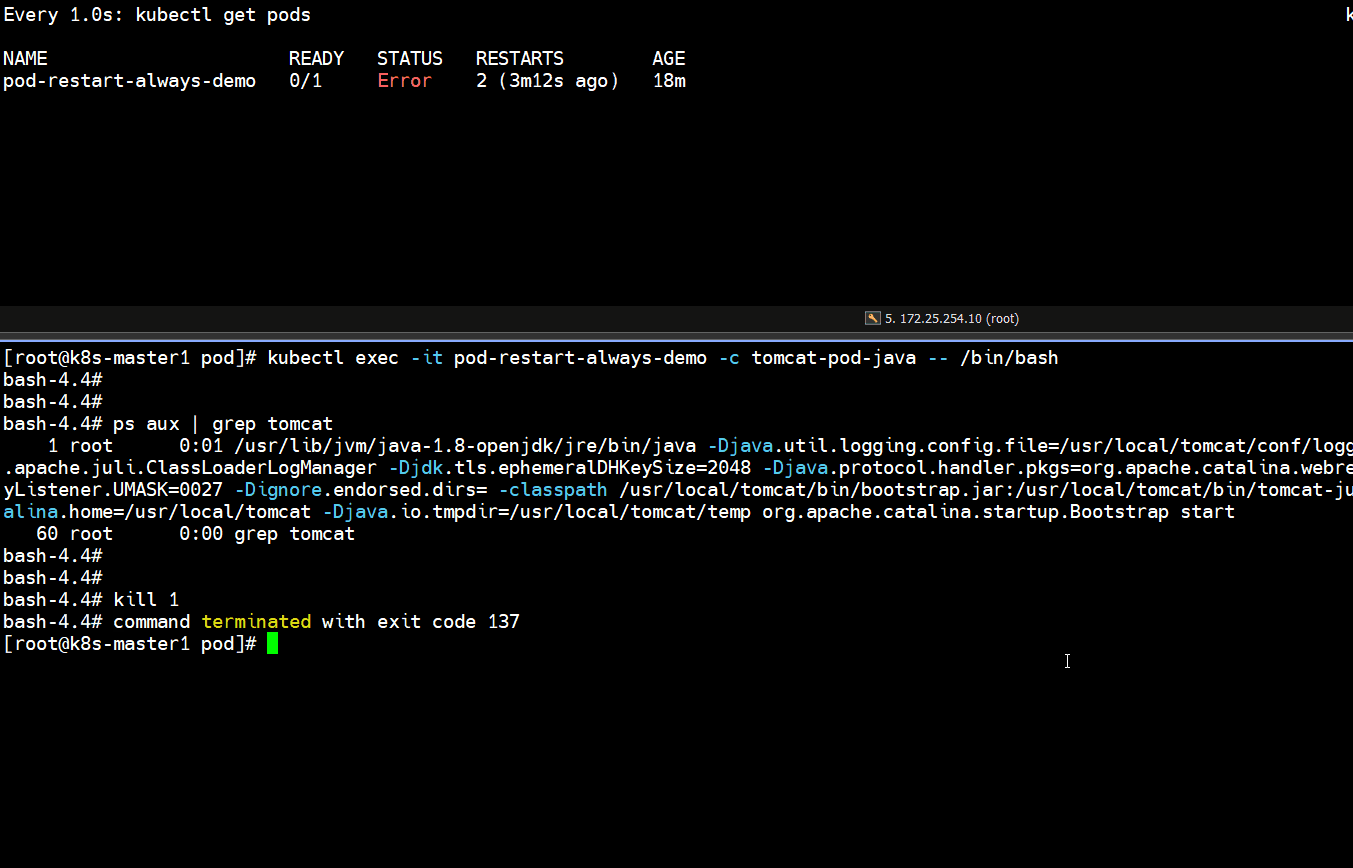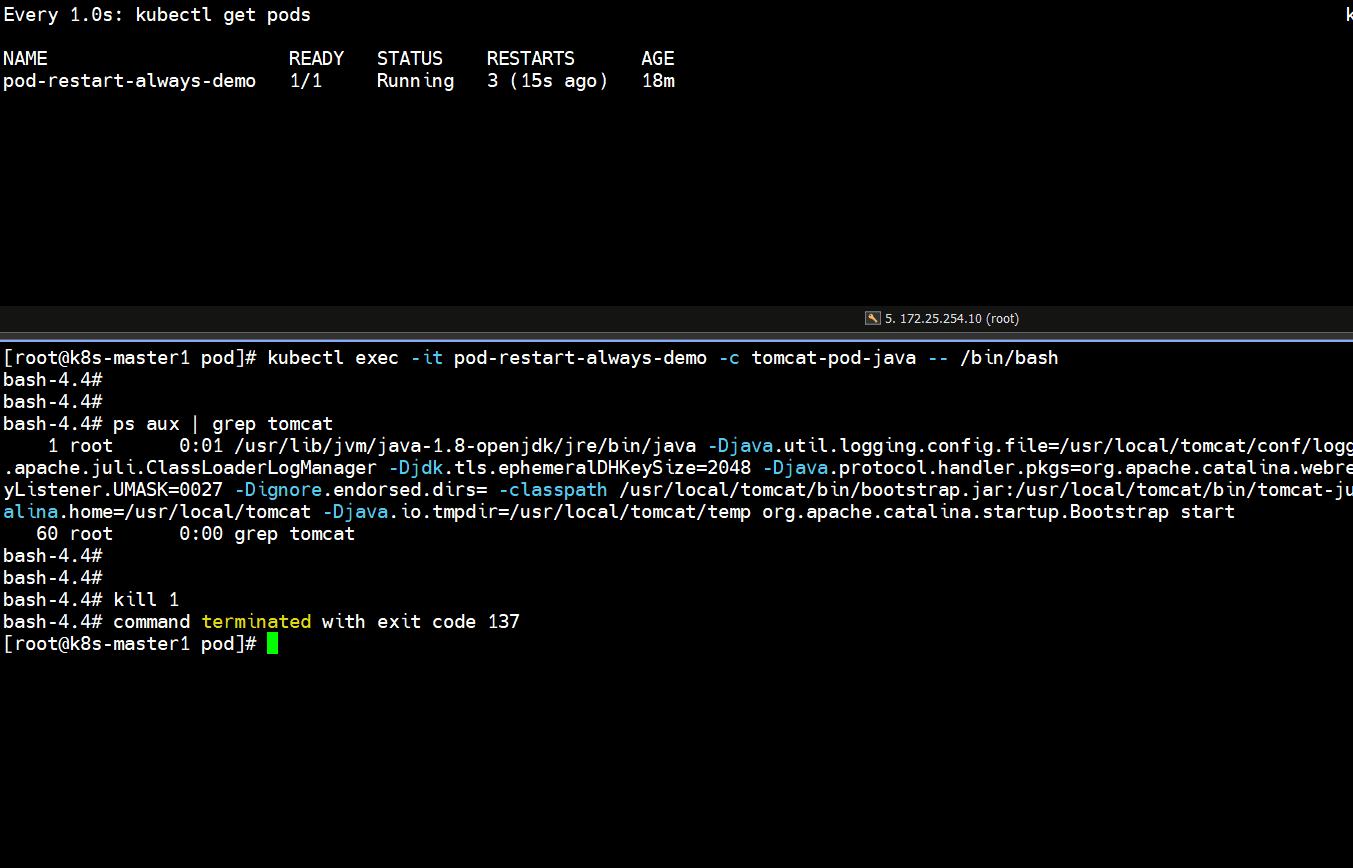
]# kubectl exec -it pod-restart-always-demo -c tomcat-pod-java -- /bin/bash
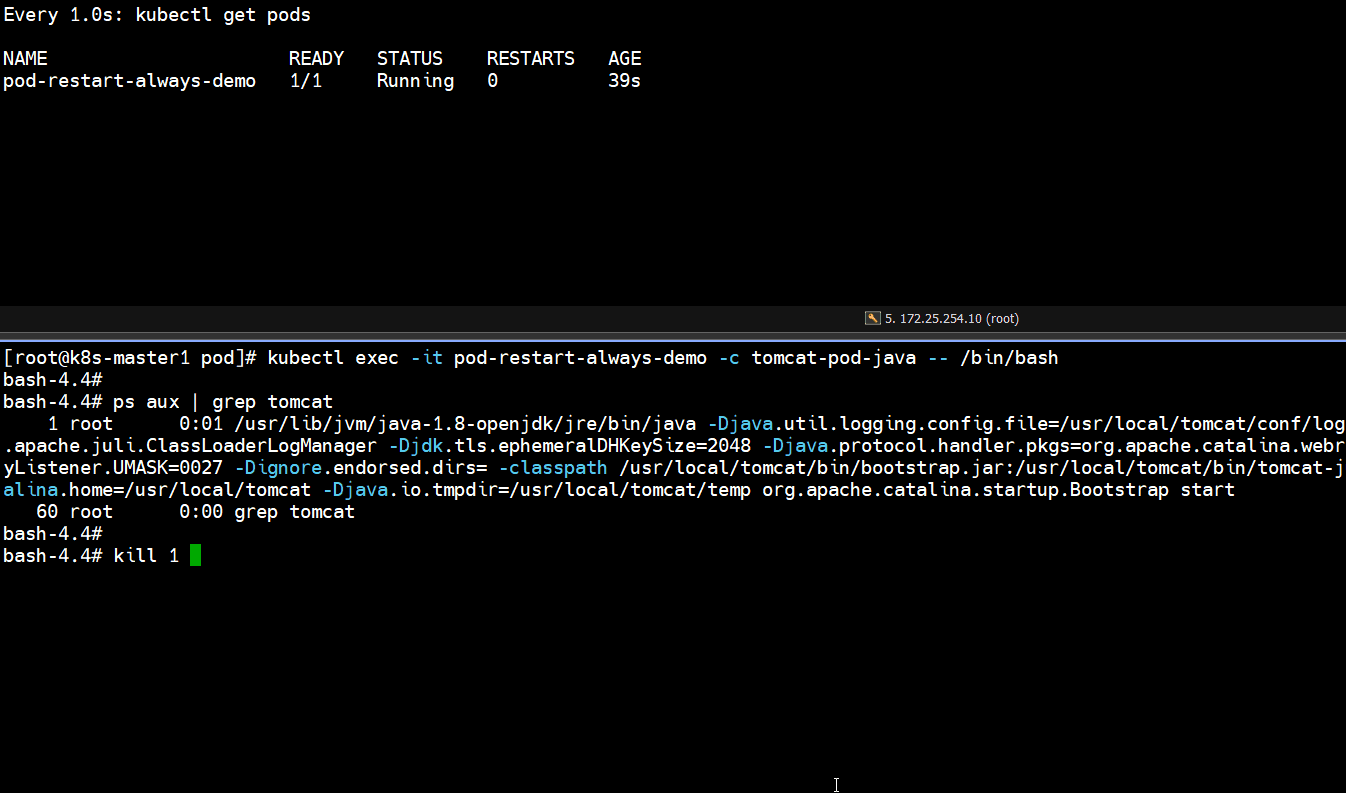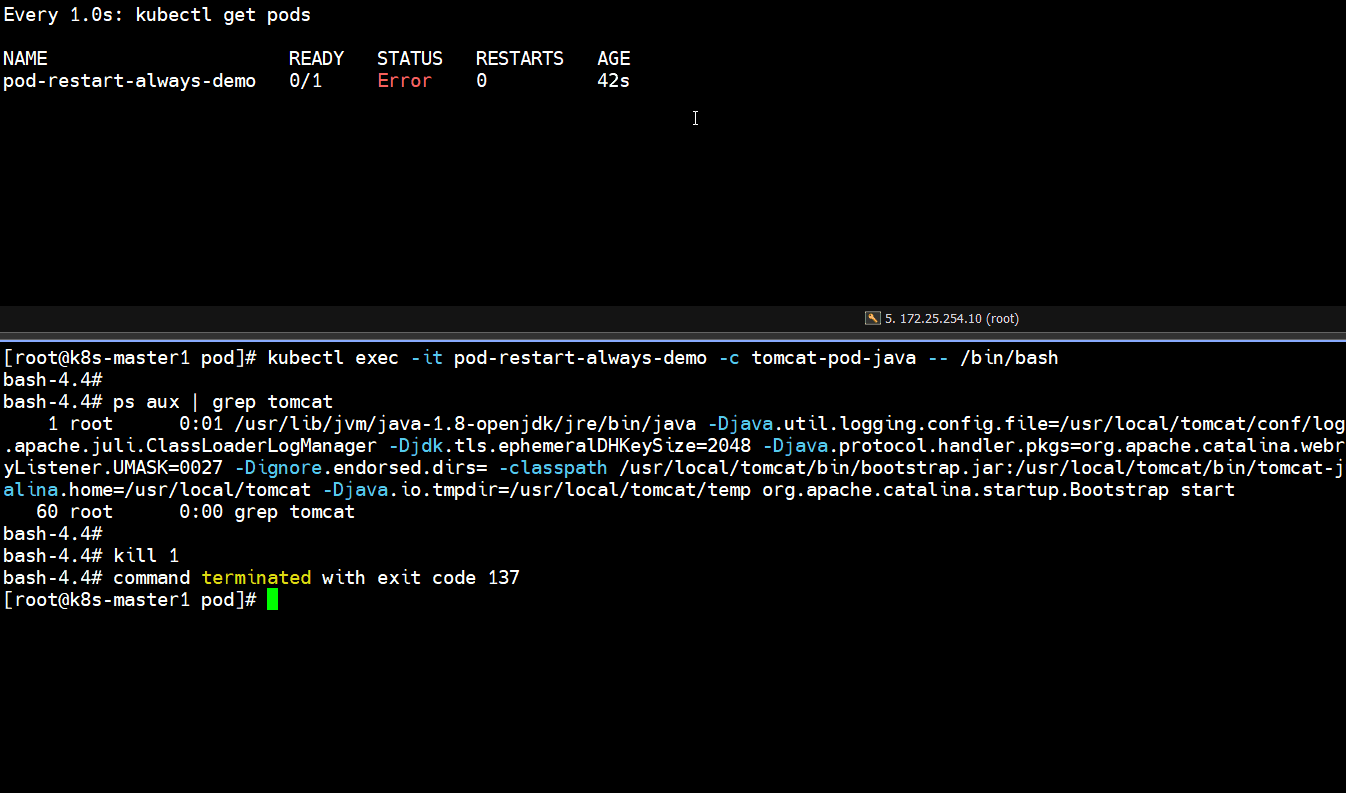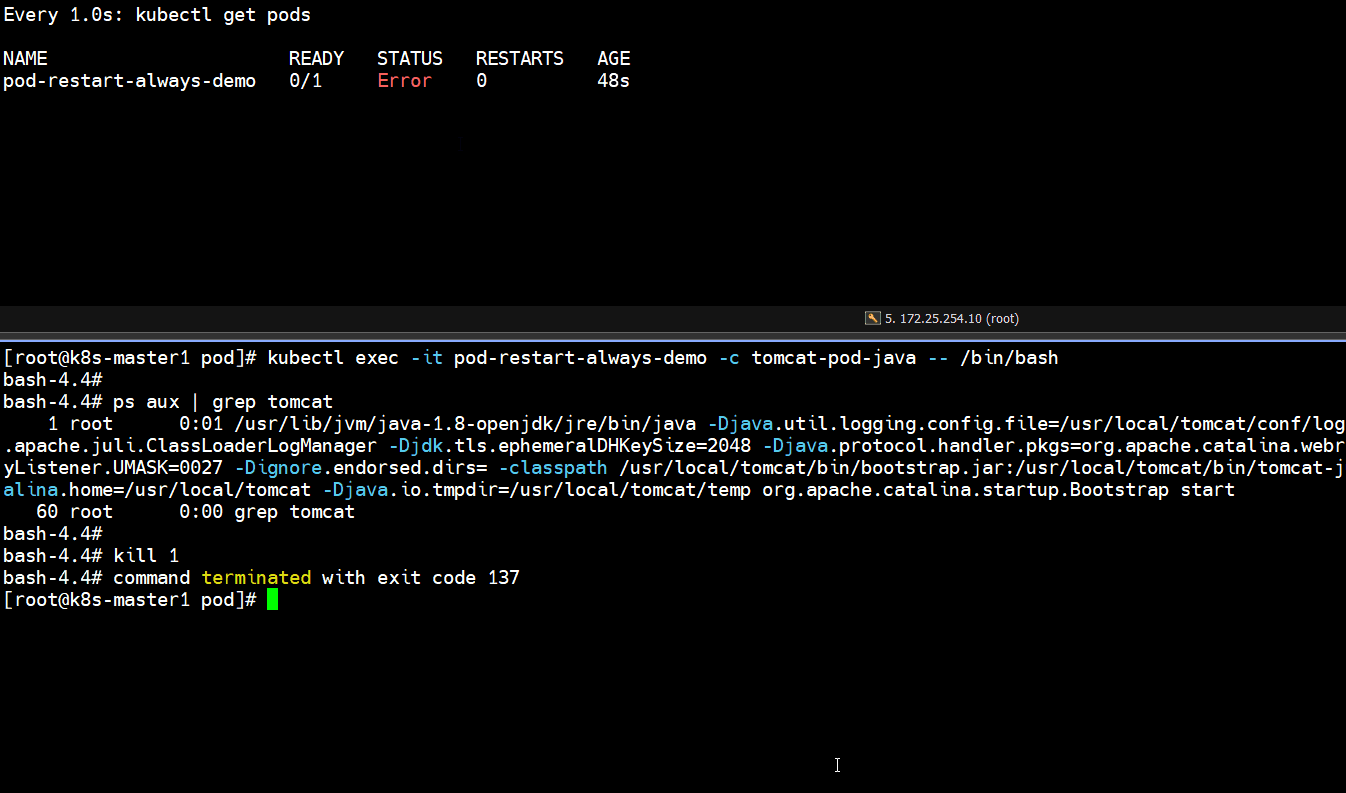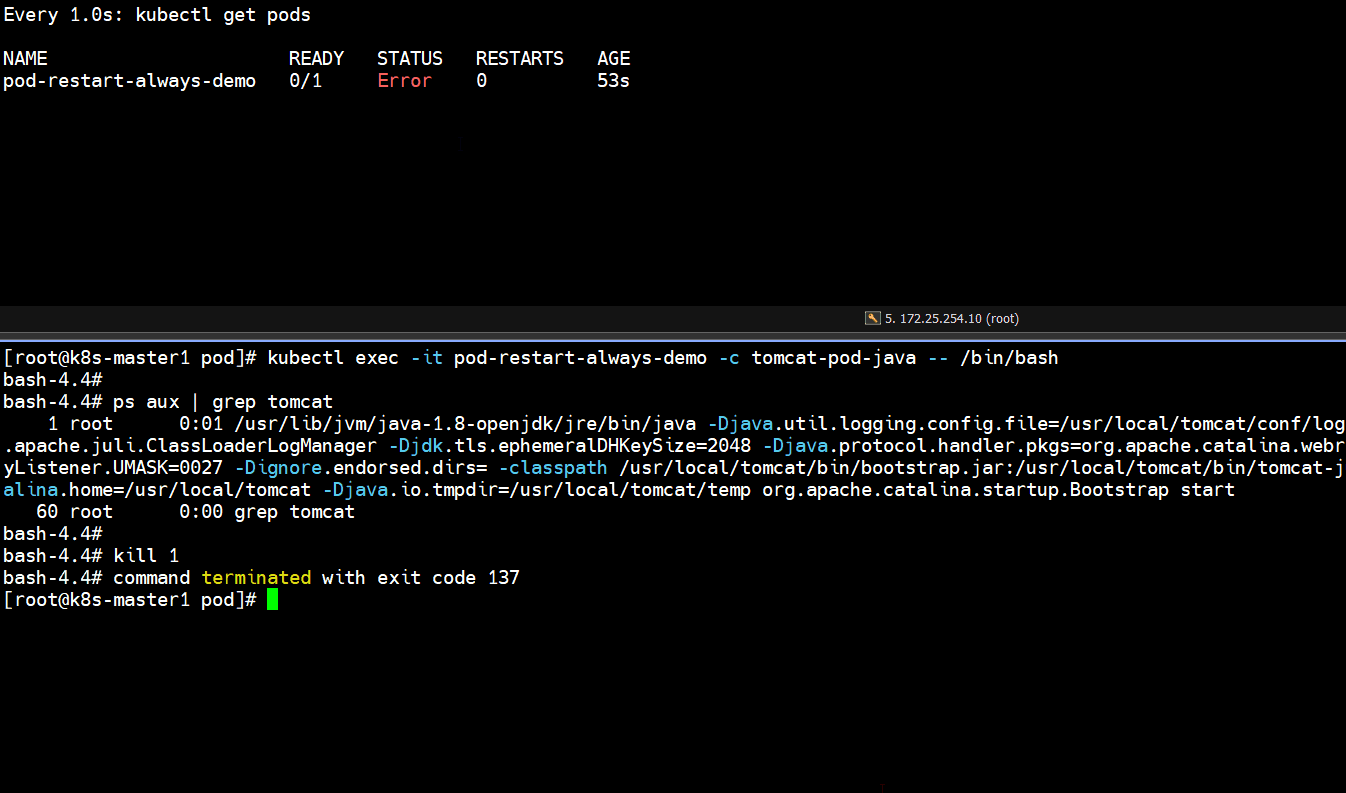
bash-4.4# ps aux | grep tomcat
bash-4.4# kill 1
# 上面可以看到容器终止了,并且又重启一次,重启次数增加了一次
Running -- Error -- CrashLoopBackOff -- Running
7.2.1.2 Never重启策略
[root@k8s-master1 pod]# vim pod-restart-nerver.yaml
...
restartPolicy: "Never"
...
[root@k8s-master1 pod]# kubectl apply -f pod-restart-never.yaml
# 打开另外一个终端去实时查看Pod资源转改变化过程(watch -n1 kubectl get pods)
- 正常停止容器里的tomcat服务
]# kubectl exec -it pod-restart-always-demo -c tomcat-pod-java -- /bin/bash
bash-4.4# /usr/local/tomcat/bin/shutdown.sh
# 发现正常停止容器里的tomcat服务,pod正常运行,容器没有重启
]# kubectl get pods
pod-restart-always-demo 0/1 Completed
# Runing -- Completed ......
- 非正常停止容器里面的tomcat服务
]# kubectl exec -it pod-restart-always-demo -c tomcat-pod-java -- /bin/bash
bash-4.4# ps aux | grep tomcat
bash-4.4# kill 1
]# kubectl get pods
pod-restart-always-demo 0/1 Error # 一直是Error
# 上面可以看到容器状态是error,并且没有重启
# 这说明重启策略是never,那么pod里容器服务无论如何终止(人为还是崩溃),都不会重启
# 如下图所示(这里把pod名字搞错了,应该是 -never,不影响实验效果)
7.2.1.3 OnFailure 重启策略
[root@k8s-master1 pod]# vim pod-restart-onfailure.yaml
...
restartPolicy: "OnFailure"
...
[root@k8s-master1 pod]# kubectl apply -f pod-restart-onfailure.yaml
# 打开另外一个终端去实时查看Pod资源转改变化过程(watch -n1 kubectl get pods)
- 正常停止容器里的tomcat服务
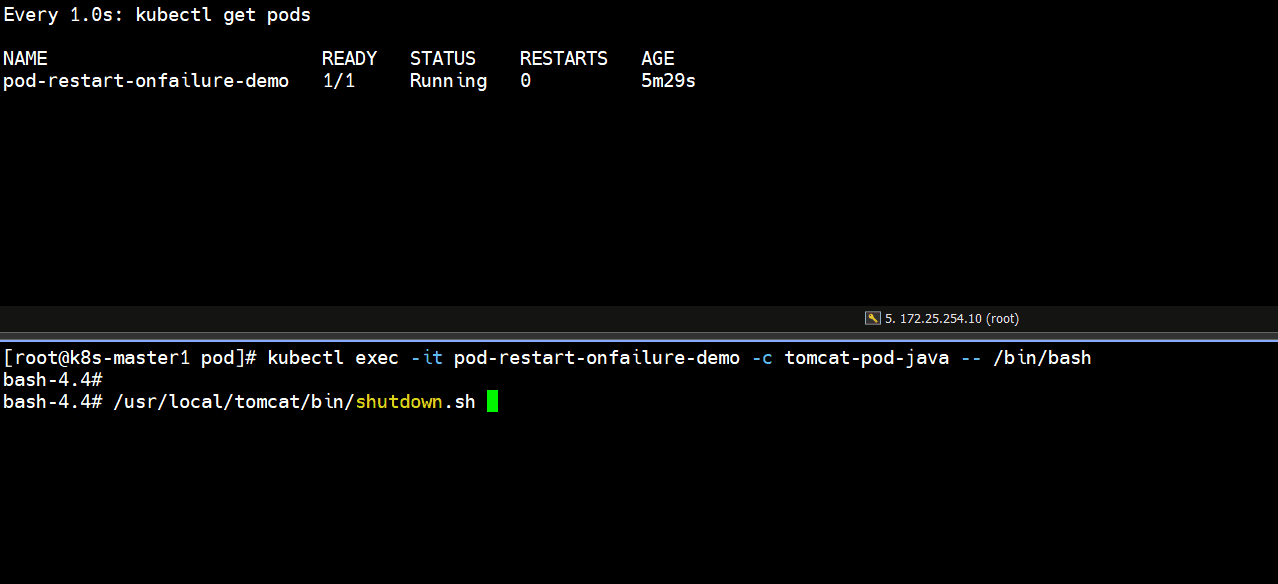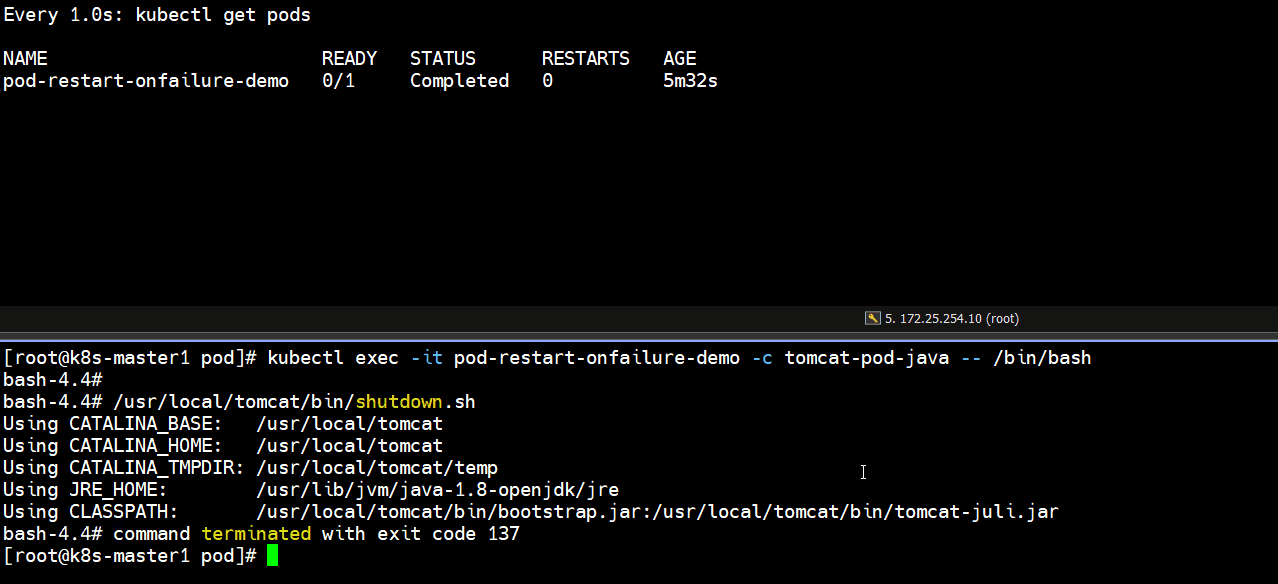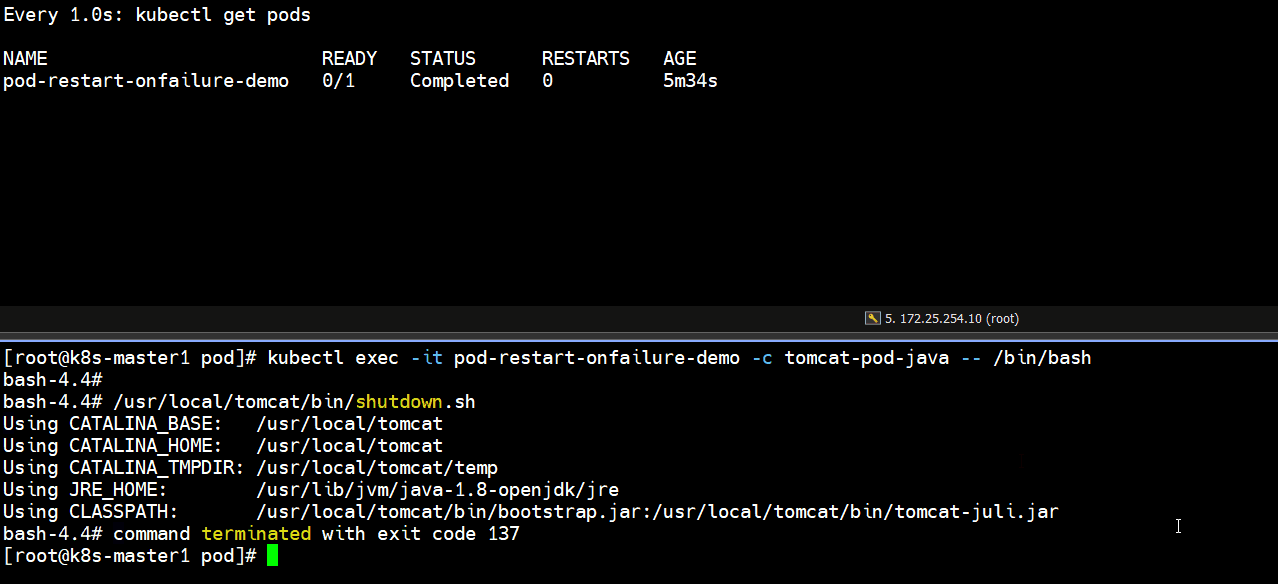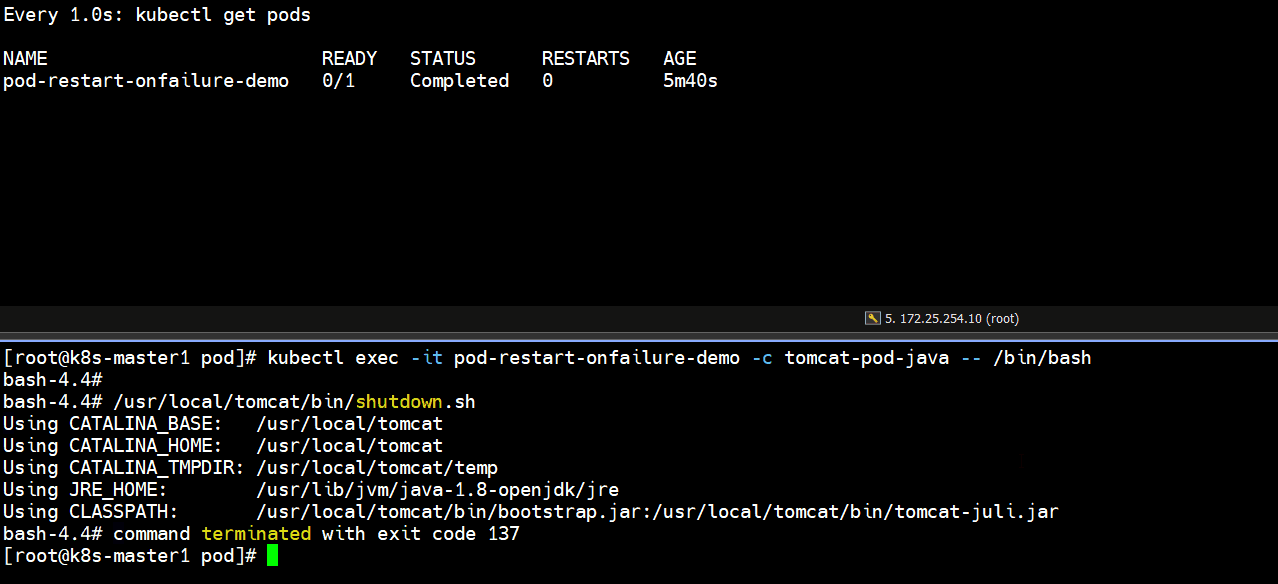
]# kubectl exec -it pod-restart-onfailure-demo -c tomcat-pod-java -- /bin/bash
bash-4.4# /usr/local/tomcat/bin/shutdown.sh
]# kubectl get pods # 发现正常停止容器里的tomcat服务,退出码是0,pod里的容器不会重启
pod-restart-onfailure-demo 0/1 Completed
- 非正常停止容器里的tomcat服务
[root@k8s-master1 pod]# kubectl exec -it pod-restart-onfailure-demo -c tomcat-pod-java -- /bin/bash
bash-4.4# kill 1
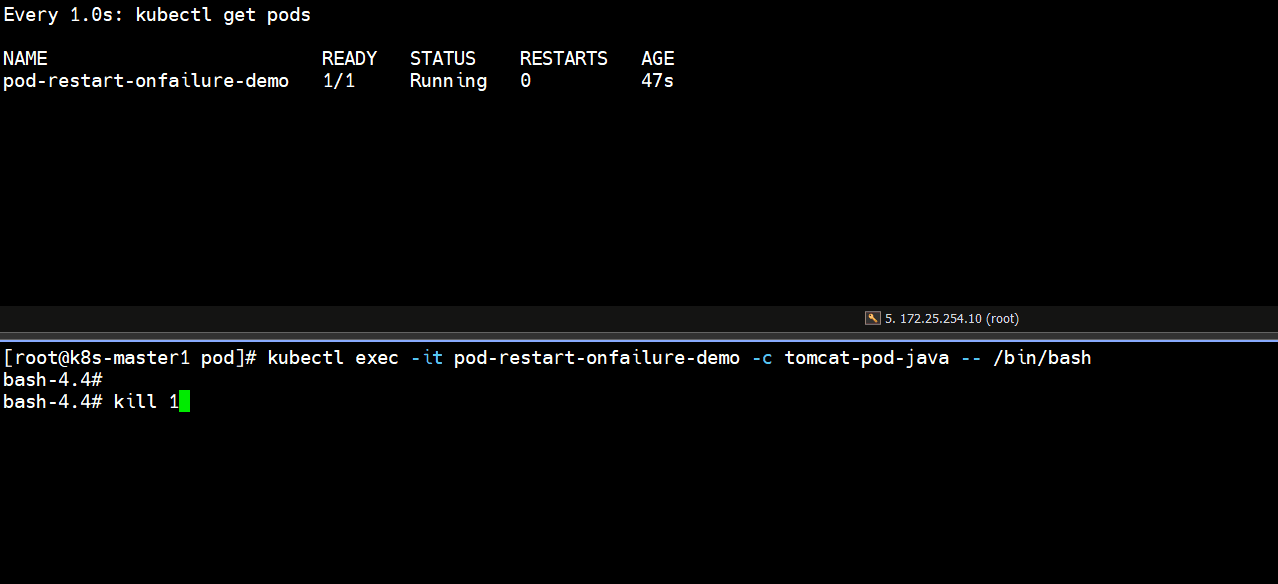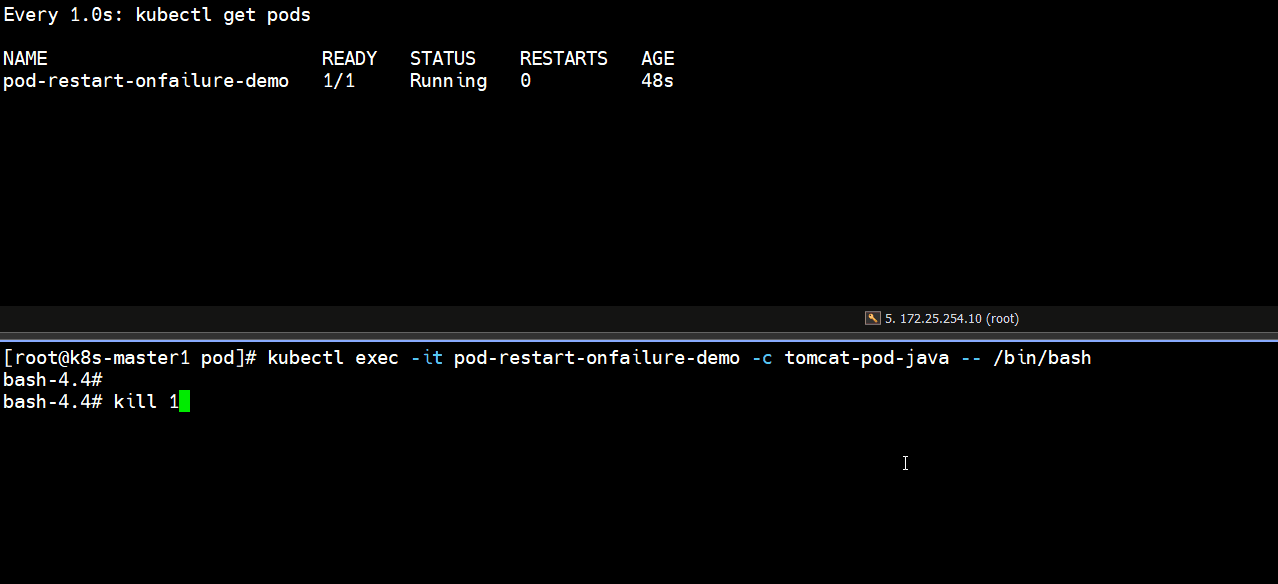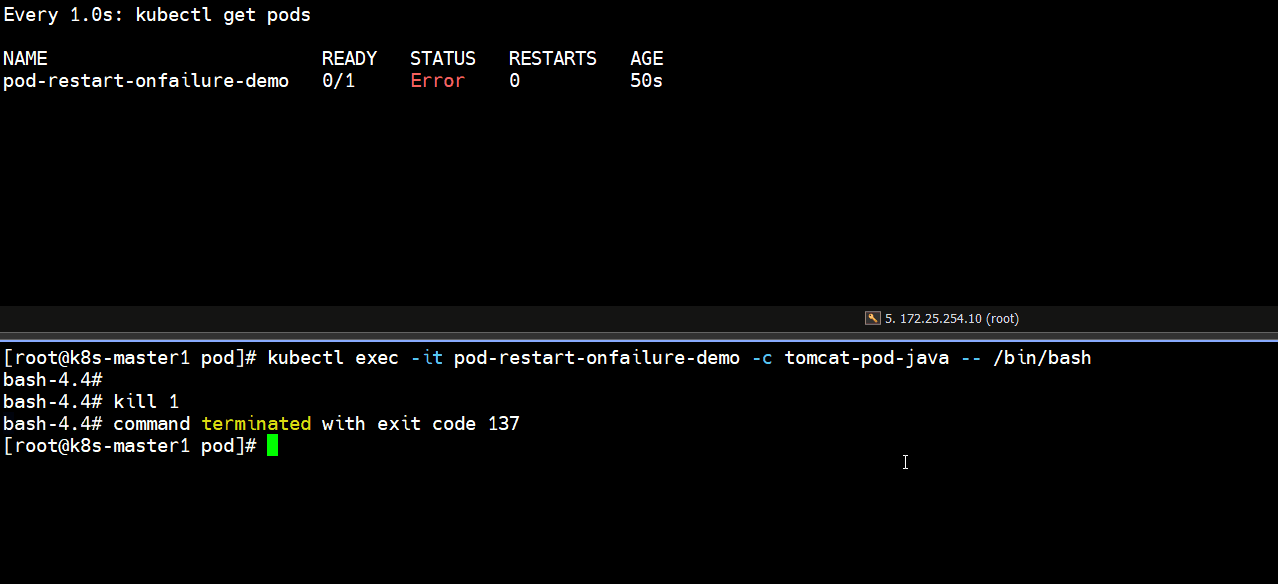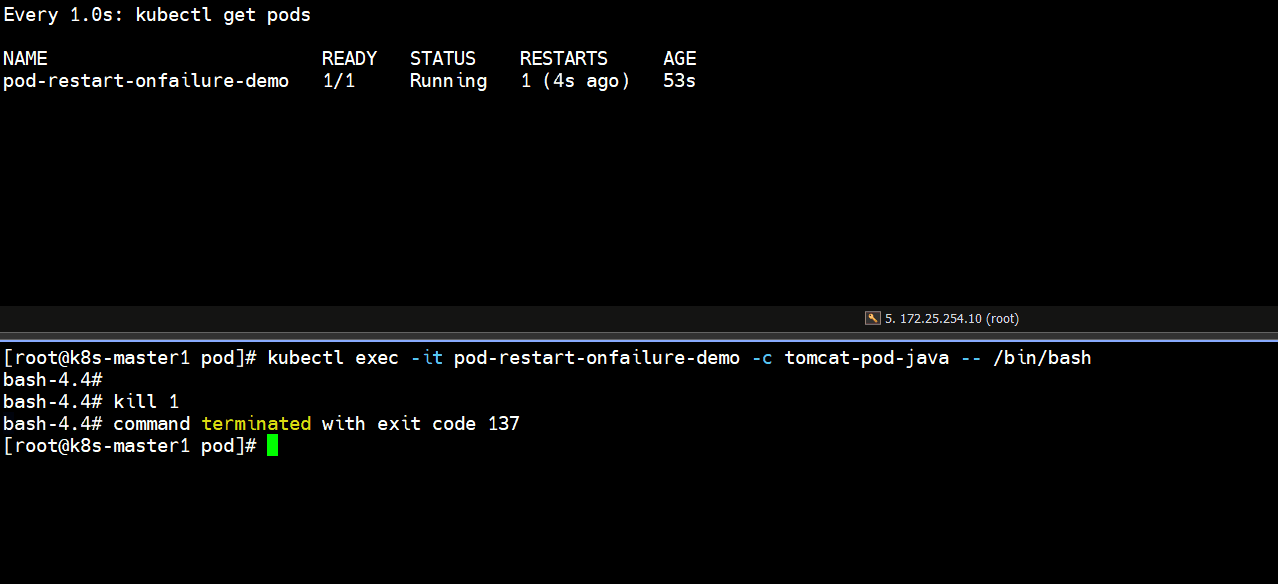
bash-4.4# command terminated with exit code 137
# 上面可以看到非正常停止pod里的容器,容器退出码不是0,那就会重启容器

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)