【零基础强化学习】第一阶段:基础 DQN
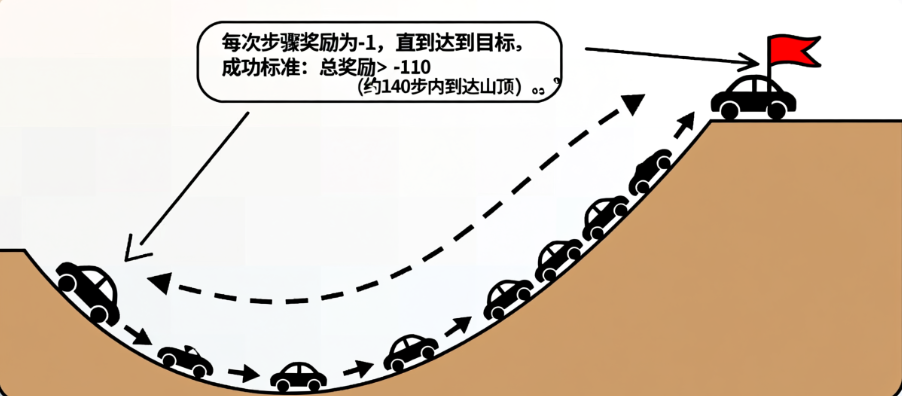
MountainCar 是一个经典的强化学习环境,目标是通过控制小车的加速方向(向左/向右/不加速),使其从山谷底部到达右侧山顶(旗帜位置)。挑战:小车动力不足,无法直接冲上坡,需要利用重力在两侧坡面之间来回摆动积蓄能量。成功标准:总奖励 > -110(约 140 步内到达山顶)
学习目标:
- 理解强化学习基本概念(状态、动作、奖励、策略)
- 掌握DQN核心算法(Q网络、经验回放、目标网络)
- 能够运行和理解现有代码
经典的 MountainCar DQN 强化学习项目
使用 Stable-Baselines3 的 DQN (Deep Q-Network) 算法训练智能体解决 MountainCar-v0 任务。
简单介绍
案例介绍
MountainCar 是一个经典的强化学习环境,目标是通过控制小车的加速方向(向左/向右/不加速),使其从山谷底部到达右侧山顶(旗帜位置)。
挑战:小车动力不足,无法直接冲上坡,需要利用重力在两侧坡面之间来回摆动积蓄能量。
成功标准:总奖励 > -110(约 140 步内到达山顶)
运行环境
Python 3.11,使用 CPU 版本的 PyTorch,Windows
依赖说明:
stable-baselines3 # 强化学习算法库
gymnasium # 环境接口
torch # PyTorch (CPU 版本)
numpy # 数值计算
tensorbord # 监控
训练目标
训练的是什么?
在项目代码学习之前,需要知道练的是什么,是 DQN 吗?准确来说训练的是 Q 网络(Q-Network)训练的是价值预测函数。具体来说Q函数:它学习预测在山地车环境中的每个状态下执行每个动作后,未来能获得的累积奖励。
在 DQN 中:
Policy (策略): 本质上是 π(a|s) = argmax Q(s,a),即选择 Q 值最大的动作
Q-Network: 神经网络 Q(s,a;θ),输入状态,输出每个动作的价值
训练整体流程
内部执行:
1. ε-贪婪策略收集经验 (s, a, r, s')
平衡探索与利用:大部分时间选择当前最优动作,偶尔随机探索,收集环境交互数据
2. 存入经验回放缓冲区
打破数据相关性:存储历史经验,使训练数据更接近独立同分布,提高样本利用率
3. 从缓冲区采样 batch_size=32
稳定训练信号:随机抽取不相关的经验批次,避免连续样本导致的训练震荡
4. 计算TD目标: y = r + γ * max Q_target(s', a')
构建学习目标:用目标网络估计下一状态的最佳价值,结合即时奖励形成更新目标(γ控制未来奖励权重)
5. 计算损失: Loss = (Q(s,a) - y)²
量化预测误差:衡量当前网络预测与目标值差距,指导参数更新方向
6. 反向传播更新 Q-Network 参数
优化价值估计:通过梯度下降调整网络权重,使Q值预测越来越接近真实累积奖励
该案例中各组件的作用
DQN的工作
DQN (Deep Q-Network) 是一种训练框架,它:
- 用神经网络代替传统Q表
- 通过经验回放(Experience Replay)打破数据相关性
- 用目标网络(Target Network)稳定训练过程
- 通过最小化预测误差来更新网络
MLP的工作
MLP (多层感知机) 是DQN中的函数近似器,它:
- 输入:环境状态(小车位置和速度)
- 处理:通过多层神经网络计算
- 输出:三个动作(左/不动/右)对应的Q值估计
本质:训练MLP网络使其能准确预测每个状态下各动作的长期价值,从而指导智能体学会先累积动量再冲上山顶的策略。
DQN的核心概念
Q值(Q-Value)
什么是Q值?Q值,是在某个状态下采取某个动作的"长期价值"。简单来说就是"这个动作有多好?"
Q(s, a) = 在状态 s 下采取动作 a,之后一直采取最优策略,能获得的期望累积奖励。
举个例子,在 MountainCar 任务中,小车在山谷中,目标是到达右边的旗帜。
不同动作的Q值:向右加速 (动作2): Q值 = +50 ✅ (能到目标,获得高奖励) ;向左加速 (动作0): Q值 = -10 ❌ (离目标更远);不动 (动作1): Q值 = -5 ⚠️ (浪费时间)。
神经网络的作用
DQN用神经网络来预测Q值。输入:当前状态 [位置, 速度];输出:3个动作的Q值 [Q(左), Q(不动), Q(右)]。
# 伪代码示例
state = [位置=-0.5, 速度=0.0] # 小车在谷底
q_values = Q_network(state) # 神经网络预测
# 输出: [-10.2, -5.1, 8.3]
# 选择Q值最大的动作
action = argmax(q_values) # 选择动作2 (向右)
经验回放(Experience Replay)
为什么要经验回放?简单来说就是"不要遗忘历史"。
问题1:数据相关性
如果按顺序训练,连续的样本高度相关,神经网络会"过拟合"到当前策略,就像考试只复习最近的知识,会忘记旧知识。
问题2:样本利用率低
每个经验只用一次就丢掉太浪费,重复利用可以提高样本效率。
经验回放的做法:
1. 收集经验:每次与环境交互,记录一条经验
experience = (state, action, reward, next_state, done)
2. 存储到缓冲区:一个大容量的"记忆库"
replay_buffer = [
(s1, a1, r1, s2, done1),
(s2, a2, r2, s3, done2),
...
(s50000, a50000, r50000, s50001, done50000)
]
3. 随机采样训练:每次从缓冲区随机抽取32条
batch = random_sample(replay_buffer, batch_size=32) # 打破了时间顺序,降低数据相关性为了更好的理解经验回放,可以类比复习考试:
顺序学习:只看最后一章的题 → 效果差(遗忘前面的知识)
经验回放:从全书随机抽题复习 → 效果好(覆盖全面)
目标网络(Target Network)
为什么需要目标网络?简单来说就是为了"稳定的学习目标"。
问题:训练不稳定
DQN的学习目标是:Q(s, a) ← r + γ * max {Q'(s', a')} ← 目标值
注意:其中 Q' 也是同一个网络!
问题:你用网络自己预测目标值来更新自己,就像"追着移动的目标跑",每更新一次,目标就变了,容易发散(训练崩溃)。
解决方案:目标网络
两个网络:1. 主网络(Q-network)需要不断更新;2. 目标网络(Target network)每1000步才更新一次 。
# 训练时
q_values = main_network(state) # 主网络预测
target_q = target_network(next_state) # 目标网络计算目标
loss = (q_values - (reward + gamma * target_q))^2
main_network.update() # 只更新主网络
# 每1000步
target_network = main_network # 复制主网络参数为什么这样有效?
1. 稳定目标:短期内目标不变,训练更稳定
2. 减少震荡:避免"狗追尾巴"式的循环
3. 收敛性:理论上保证收
查看训练曲线:
tensorboard --logdir=dqn_mountaincar_tensorboard/ ,这会启动 TensorBoard 可视化界面,显示:
Episode reward(每回合奖励)变化趋势
Episode length(每回合步数)
Loss(损失函数值)
Q值的变化
train.py 代码解读
import os # 操作系统接口,用于路径操作
from pathlib import Path # 面向对象的路径处理
import numpy as np # 处理数组、统计计算
from stable_baselines3 import DQN # 强化学习算法主类
from stable_baselines3.dqn import MlpPolicy # 多层感知机策略网络,定义神经网络结构
from stable_baselines3.common.callbacks import BaseCallback # Stable Baselines3 提供的回调机制基类,用于在训练过程中插入自定义逻辑
from gymnasium import envs # OpenAI Gym 的继任者,提供强化学习环境接口'''环境与训练配置'''
ENV_ID = "MountainCar-v0" # 环境名称:小车爬山任务
TOTAL_TIMESTEPS = 300000 # 总训练步数:30万步
LOG_DIR = "dqn_mountaincar_tensorboard" # TensorBoard日志目录
MODEL_SAVE_PATH = "models/dqn_mountaincar.zip" # 模型保存路径# DQN 超参数
LEARNING_RATE = 1e-3 # 学习率,控制神经网络参数更新的步长
BUFFER_SIZE = 50000 # 经验回放缓冲区大小,存储50万条 (s, a, r, s')
LEARNING_STARTS = 1000 # 在收集1000步经验后才开始训练,保证缓冲区有足够数据
BATCH_SIZE = 32 # 每次训练从缓冲区随机抽取32个样本
GAMMA = 0.99 # 折扣因子,衡量未来奖励的重要性 (0.99表示非常重视长期奖励)
EXPLORATION_FRACTION = 0.1 # 前10%的训练时间用于探索(ε从1线性衰减),总训练步数中用于探索衰减的比例,控制探索率从1.0线性衰减到 EXPLORATION_FINAL_EPS 的时间跨度
EXPLORATION_FINAL_EPS = 0.02 # 训练结束时保留的最小探索率,探索结束后ε值保持在0.02(仍有2%随机动作)
TRAIN_FREQ = 4 # 每收集4步经验进行一次训练
GRADIENT_STEPS = 1 # 每次训练执行1次梯度更新
TARGET_NETWORK_UPDATE_FREQ = 1000 # 每1000步更新一次目标网络class TensorBoardLoggingCallback(BaseCallback):
"""
自定义 TensorBoard 日志回调函数
确保训练数据被正确记录到 TensorBoard
"""
def __init__(self, verbose=0):
super().__init__(verbose)
def _on_step(self):
# 每100步记录一次到 logger
if self.n_calls % 100 == 0 and hasattr(self.model, 'logger'):
# 记录训练步数
self.logger.record('train/timestep', self.n_calls)
# 记录探索率
if hasattr(self.model, 'exploration_rate'):
self.logger.record('train/exploration_rate', self.model.exploration_rate)
# 立即写入磁盘
self.logger.dump()
return Truedef create_environment():
"""创建并返回 MountainCar 环境"""
import gymnasium as gym
env = gym.make(ENV_ID)
return envdef train_dqn():
"""训练 DQN 模型"""
print("=" * 60)
print("MountainCar DQN 训练开始")
print("=" * 60)
print(f"环境: {ENV_ID}")
print(f"总训练步数: {TOTAL_TIMESTEPS:,}")
print(f"设备: CPU")
print(f"模型保存路径: {MODEL_SAVE_PATH}")
print(f"TensorBoard 日志: {LOG_DIR}/")
print("=" * 60)
# 创建环境
env = create_environment()
# 创建模型保存目录
Path(MODEL_SAVE_PATH).parent.mkdir(parents=True, exist_ok=True)
# 创建 DQN 模型
model = DQN(
policy=MlpPolicy, # 使用多层感知机策略网络
env=env, # 绑定环境
learning_rate=LEARNING_RATE,
buffer_size=BUFFER_SIZE,
learning_starts=LEARNING_STARTS,
batch_size=BATCH_SIZE,
gamma=GAMMA,
exploration_fraction=EXPLORATION_FRACTION,
exploration_final_eps=EXPLORATION_FINAL_EPS,
train_freq=TRAIN_FREQ,
gradient_steps=GRADIENT_STEPS,
target_update_interval=TARGET_NETWORK_UPDATE_FREQ,
tensorboard_log=LOG_DIR,
verbose=1,
device="cpu", # 我的设备没有GPU所以指定CPU
)
# 训练模型
print("\n开始训练...")
model.learn(
total_timesteps=TOTAL_TIMESTEPS,
log_interval=1000,
progress_bar=True,
)
# 保存模型
print(f"\n保存模型到: {MODEL_SAVE_PATH}")
model.save(MODEL_SAVE_PATH)
print("模型保存完成!")
# 关闭环境
env.close()
print("\n" + "=" * 60)
print("训练完成!")
print("=" * 60)
print(f"使用以下命令查看训练曲线:")
print(f" tensorboard --logdir={LOG_DIR}/")
print(f"\n使用以下命令测试模型:")
print(f" python test.py")
print("=" * 60)
return model
def evaluate_model(model_path=MODEL_SAVE_PATH, n_episodes=10):
"""评估训练好的模型"""
import gymnasium as gym
print("\n" + "=" * 60)
print("评估模型性能")
print("=" * 60)
# 加载模型
model = DQN.load(model_path, device="cpu")
env = create_environment()
episode_rewards = []
episode_lengths = []
for i in range(n_episodes):
obs, info = env.reset()
done = False
truncated = False
total_reward = 0
steps = 0
while not (done or truncated):
action, _ = model.predict(obs, deterministic=True)
obs, reward, done, truncated, info = env.step(action)
total_reward += reward
steps += 1
episode_rewards.append(total_reward)
episode_lengths.append(steps)
print(f"回合 {i+1:2d}: 奖励 = {total_reward:7.2f}, 步数 = {steps:3d}")
env.close()
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
mean_length = np.mean(episode_lengths)
print("=" * 60)
print(f"平均奖励: {mean_reward:.2f} ± {std_reward:.2f}")
print(f"平均步数: {mean_length:.1f}")
print(f"成功率 (奖励 > -110): {sum(1 for r in episode_rewards if r > -110)}/{n_episodes}")
print("=" * 60)
return mean_reward, episode_rewards
if __name__ == "__main__":
# 训练模型
model = train_dqn()
# 评估模型
evaluate_model()训练结果解读
训练日志解读
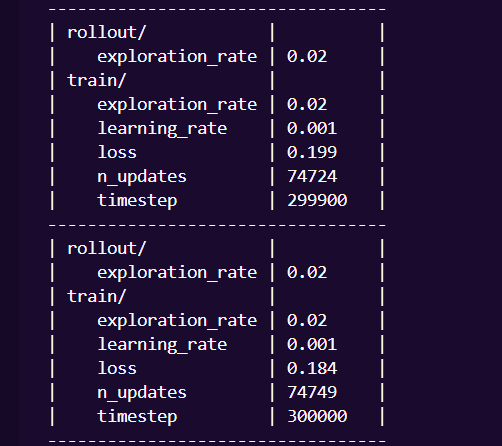
---------------------------------------
| rollout/ | |
| exploration_rate | | ← 当前回合的探索率
| train/ | |
| exploration_rate | | ← 训练使用的探索率
| learning_rate | | ← 学习率
| loss | | ← Q 网络的训练损失
| n_updates | | ← 已完成的网络更新次数
| timestep | | ← 当前训练步数
----------------------------------------
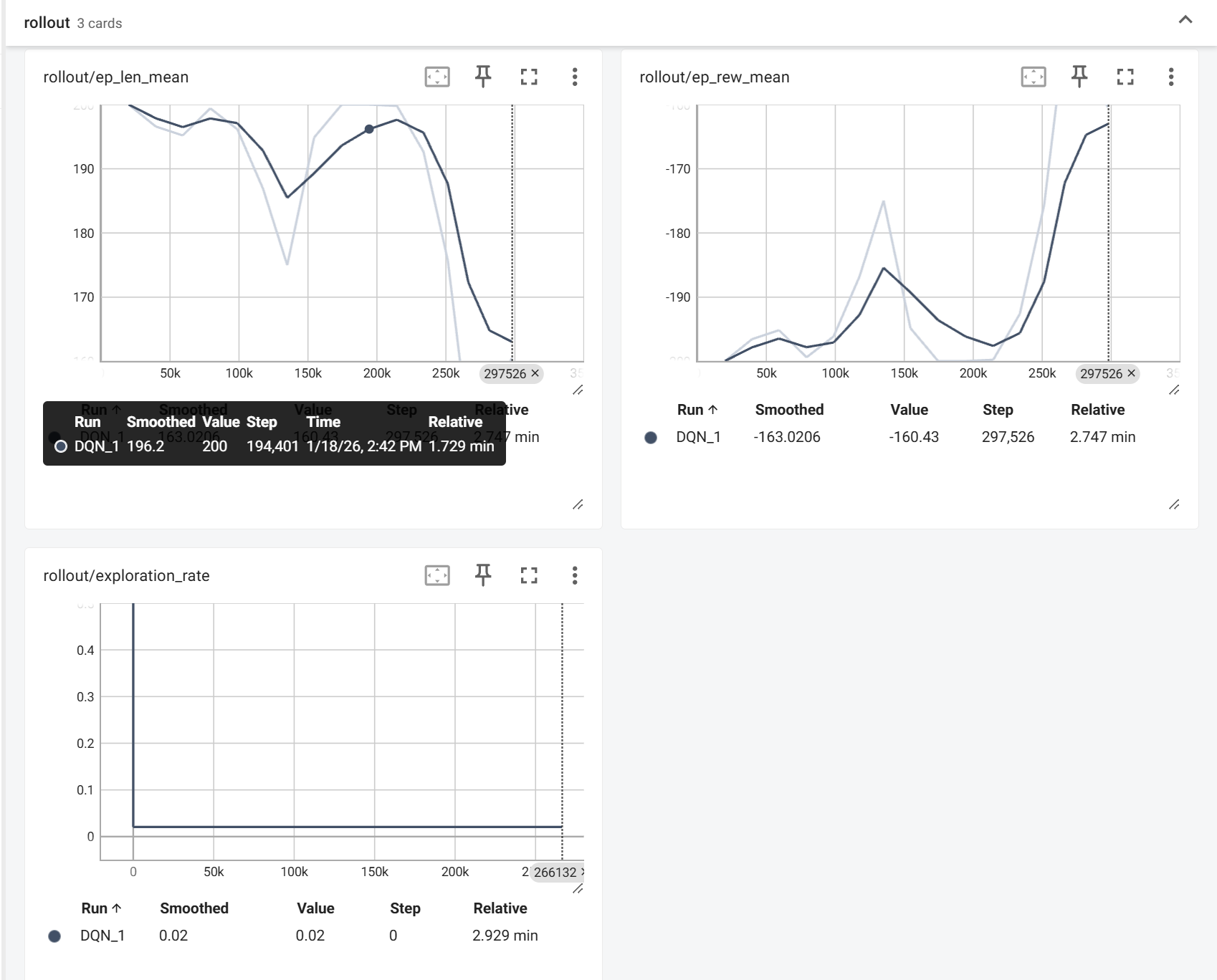
指标解读
- episode_reward_mean(右上):趋势:从-200+ → -160,说明智能体学会减少惩罚,开始有效探索。
- episode_len_mean(左上):趋势:从~200 → ~170,说明智能体学习到更快的策略,不再无谓徘徊。
- exploration_rate(左下):值后面稳定在0.02,说明探索阶段结束,进入利用阶段,同时也验证了ε-greedy 策略正常工作。
当前存在的问题:收敛不稳定,奖励曲线有剧烈波动。
可能的原因:学习率过高或经验回放缓冲区未充分混合
多次训练
针对以上原因进行参数修改
修改探索时间
之前的MountainCar 的学习曲线,探索阶段 (0-30,000 步),智能体主要在随机探索,如果探索时间太短,会陷入次优策略。这里将EXPLORATION_FRACTION改为0.3 (30%)。
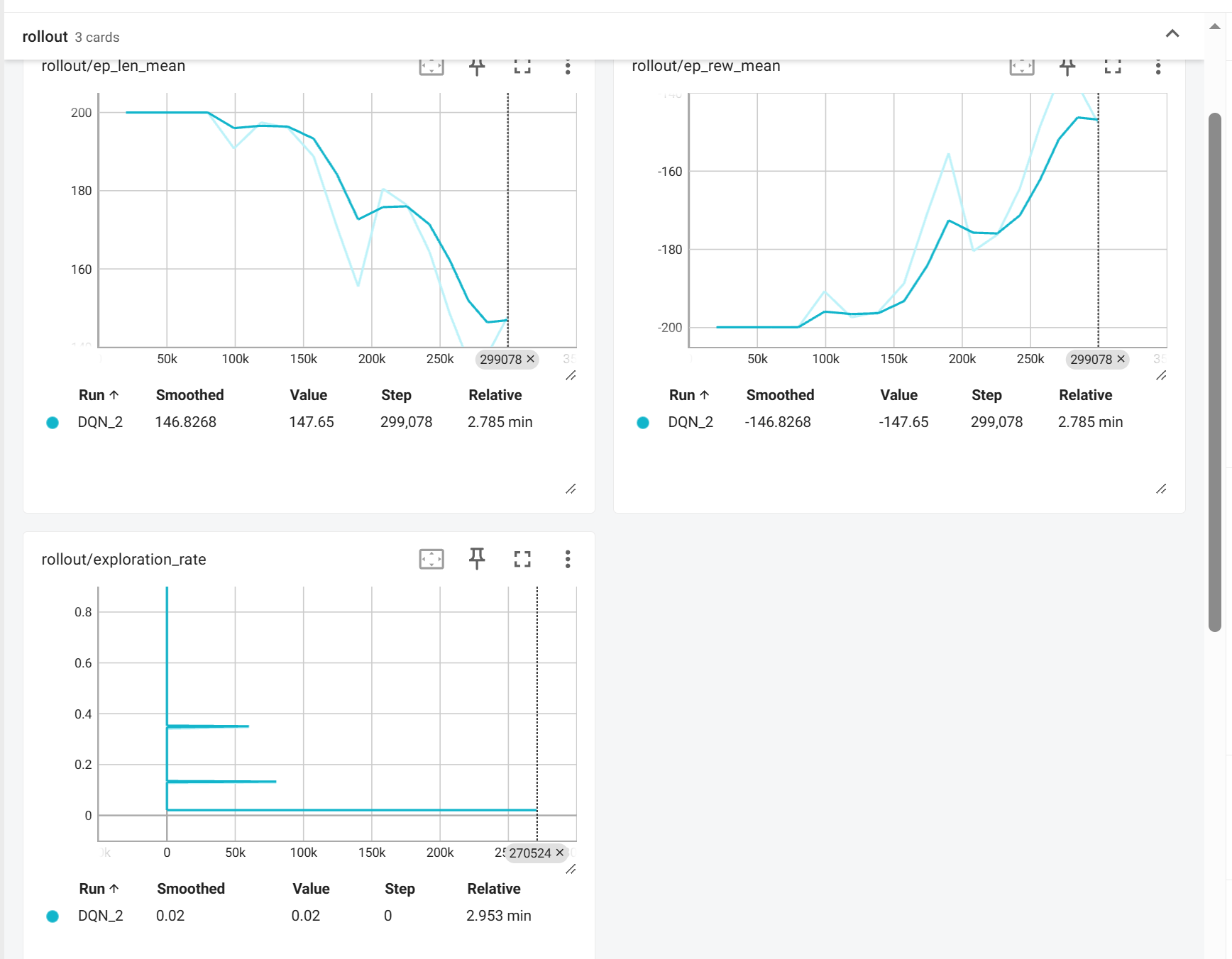
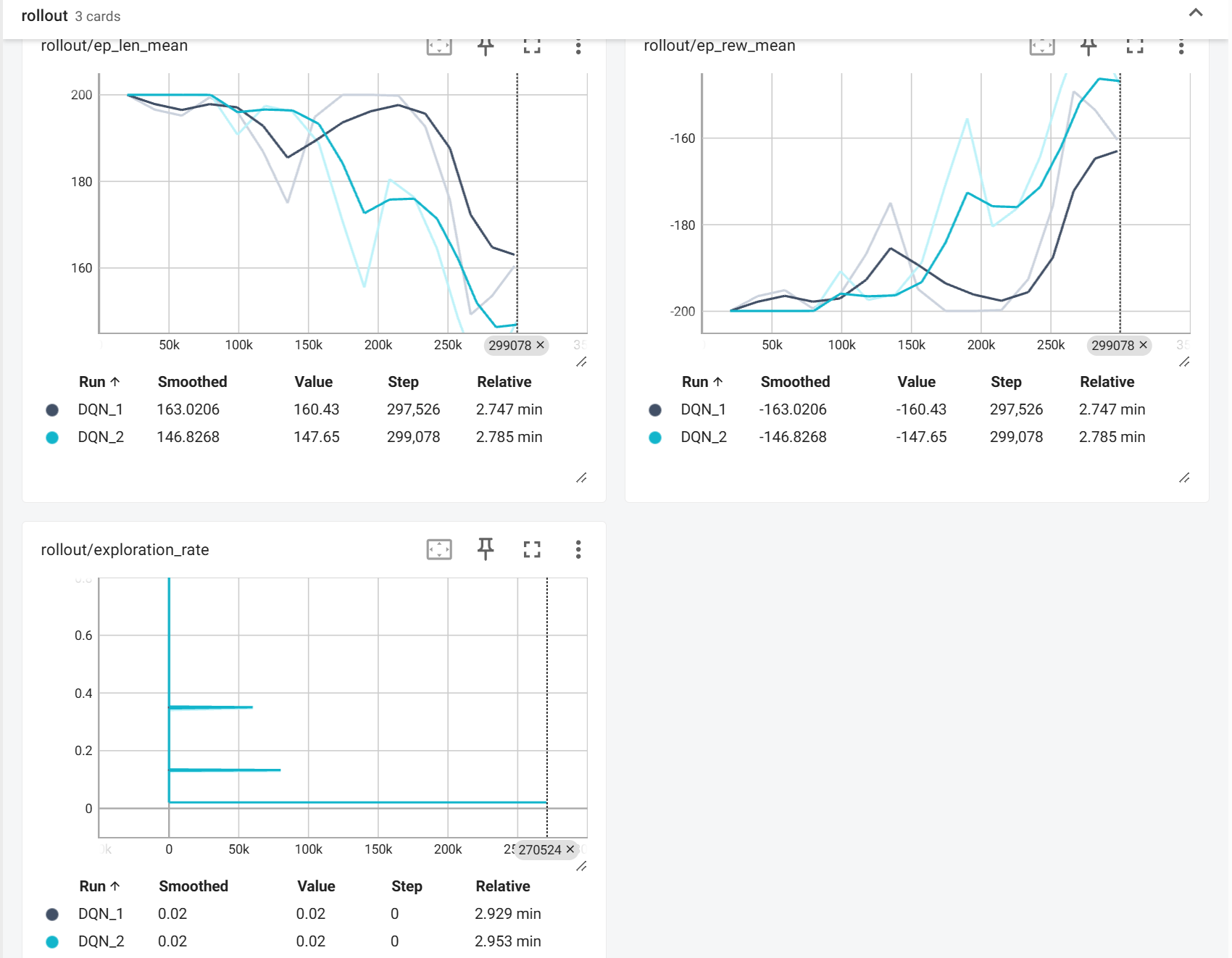
可以看见效果确实好了不少,但仍然不够理想。
修改最终探索率
可能是之前0.02 的探索率太小了,使得训练可能陷入局部最优解。
这里有一点需要解释,学习率和探索率有什么不同?
| 维度 | 学习率 (1e-3) | 探索率 (ε) |
|---|---|---|
| 作用对象 | 神经网络权重 | 动作选择策略 |
| 本质 | 参数更新步长 | 随机动作概率 |
| 影响阶段 | 训练过程内部 | 环境交互过程 |
| 时间行为 | 通常固定 | 从高到低衰减 |
更直观的对比:
| 学习率 = 学生改错幅度 | 探索率 = 学生尝试新方法频率 |
| 考试后错题订正时,是彻底推翻重学(高学习率)还是微调(低学习率) | 遇到数学题时,是沿用老方法(低ε)还是随机尝试新解法(高ε) |
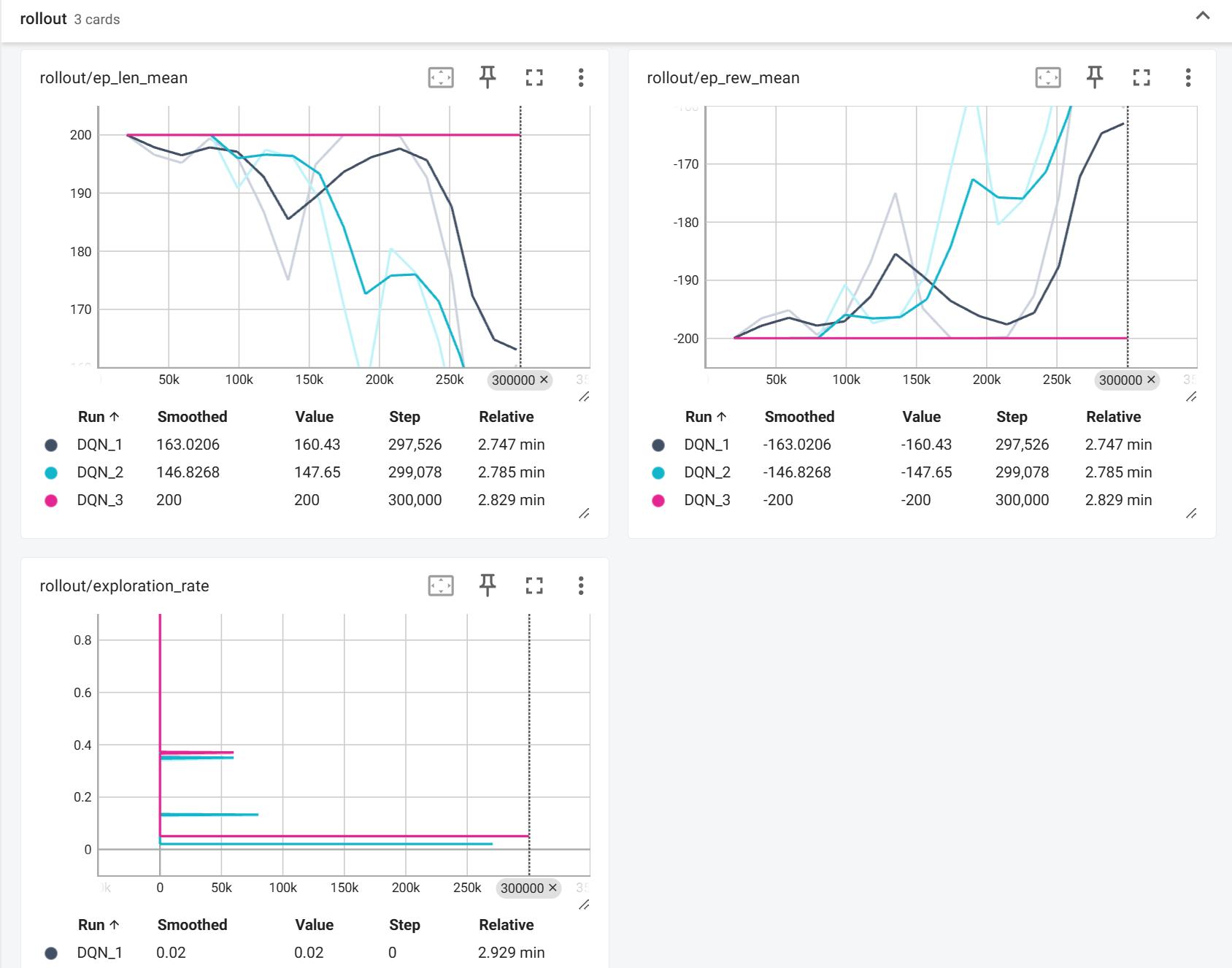
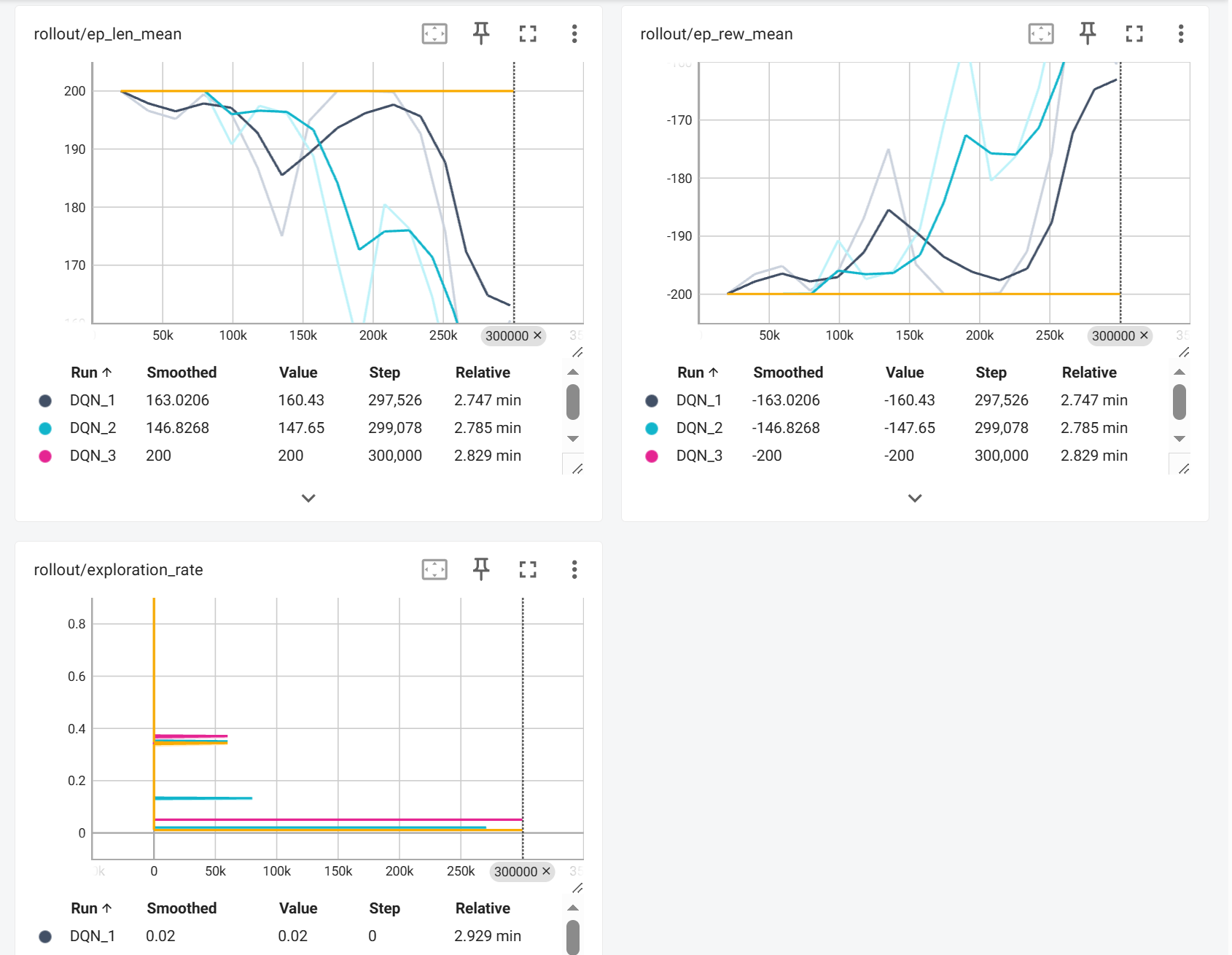
我尝试将最终探索率修改为0.05 和 0.01,发现效果都不好,而且差得一模一样。当探索率太高的时候,随机动作频率过高,高频随机动作产生无效经验,智能体无法稳定执行"蓄力→冲刺"策略,经验回放缓冲区被大量无意义样本污染。
当然,观察训练曲线可以知道,两个设置都失败的根本原因不是探索率数值,而是智能体根本没学会基础策略,也就是Q网络完全失效,因为没有正奖励样本,所有动作价值估计都接近-200,99%的"贪婪动作"仍是错误动作,1%和5%的随机探索差异微不足道。所以,最主要的不是修改探索率(如何使用经验),而是要让小车学会怎么到达山顶。
这就要修改学习率等,调参太多了,我就不一一尝试了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)