深入理解 Flink 任务执行模型:从 Operator 到 StreamTask
本文深入解析了Flink的执行模型,重点探讨了StreamTask作为最小执行单元的工作原理。文章首先说明理解执行模型的必要性,然后详细介绍了算子链(OperatorChain)的形成机制及其性能优势。接着剖析了StreamTask的生命周期,包括初始化、运行和终止阶段的核心逻辑。文章指出Flink通过多Task实例水平扩展并发度,同时保持单线程确定性执行的独特设计哲学,为后续分析Shuffle机
Flink 的并行,不是多线程的混乱并发,而是多 Task 协同并行与单线程确定执行的完美结合; 它让每一条流水线有序流动,让数据在高并发中依然保持严格的一致性。
一、为什么要理解 Flink 的执行模型
前面几篇文章中,我们了解了 Flink 作业从提交、调度到容错的完整生命周期。但这些主要停留在“全局视角”——作业怎么部署、任务怎么调度、状态怎么恢复。真正的数据计算,是在每个 Task 内部完成的。那么一个 Task 是如何驱动算子运行的?多个算子如何串联执行?为什么 Flink 能做到高并发而状态仍然一致呢?
这些问题的答案,就藏在 Flink 的执行模型中。如果Flink 的运行是一座自动化数据工厂。调度器(JobMaster)负责规划每条生产线,TM 是车间,而 StreamTask 就是 Slot(工位)上具体执行生产的“加工设备”了。理解 StreamTask 的工作方式,就理解了 Flink 数据流动的最小执行单元。
二、从 Operator 到 OperatorChain:算子链的形成
Flink 的计算逻辑最初以算子(Operator)为单位。每个 map、filter、keyBy、window 等都是一个算子节点。如果这些算子逐一运行,系统就需要频繁切换线程、进行网络序列化,性能会显著下降。为此,Flink 在生成执行图时进行了 算子链(OperatorChain)优化:将能直接连接、且不涉及 shuffle 的算子,合并到同一个 Task 内执行。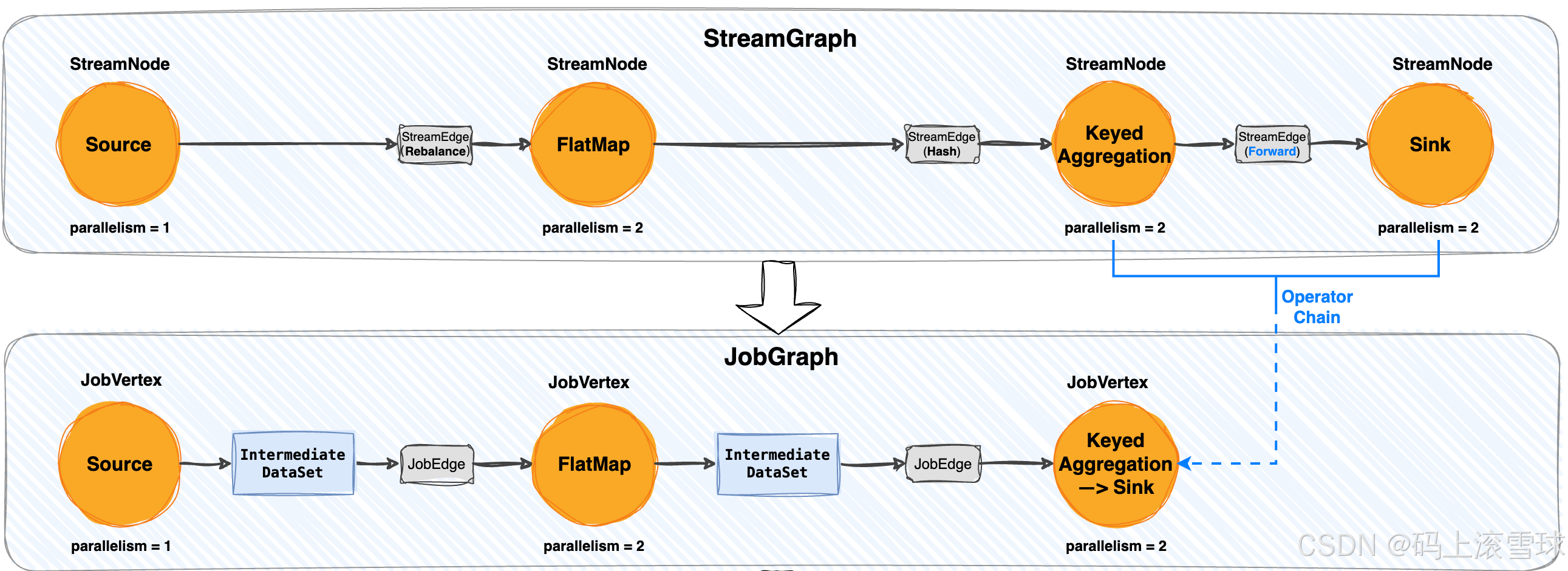
如上图:Source → Map → KeyBy → Sink 在逻辑上是四个算子,但在物理执行时,后面两个算子最终会合并到一个 Task 中,作为一个 StreamTask 实例运行,内部形成 OperatorChain。核心源码逻辑在:
StreamingJobGraphGenerator#setChaining()
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
// 对source节点进行分类,找出可chain的source节点
final Map<Integer, OperatorChainInfo> chainEntryPoints =
buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
// 将链式入口点按节点ID排序,以确保处理顺序的一致性
final Collection<OperatorChainInfo> initialEntryPoints =
chainEntryPoints.entrySet().stream()
.sorted(Comparator.comparing(Map.Entry::getKey))
.map(Map.Entry::getValue)
.collect(Collectors.toList());
// 遍历排序后的入口点集合,对每个入口点调用 createChain 函数来递归构建任务链
for (OperatorChainInfo info : initialEntryPoints) {
createChain(
info.getStartNodeId(),
1, // operators start at position 1 because 0 is for chained source inputs
info,
chainEntryPoints);
}
}
该方法将可以链在一起的算子打包为一个 OperatorChain,并最终在 StreamTask 中顺序执行。这使得:
- 算子之间以方法调用替代网络通信;
- 数据在算子链中零拷贝传递;
- 显著减少线程切换与序列化成本。
三、StreamTask 执行模型:一条流水线的运行逻辑
每个 Task 的核心执行单元是 StreamTask。它是所有流任务的抽象基类(如 OneInputStreamTask、TwoInputStreamTask、SourceStreamTask 都继承于此)。
StreamTask 的生命周期包括以下主要阶段:
1. 初始化阶段
恢复状态及操作符设置:通过invoke() 方法或显式调用 restore() 方法,核心实现在restoreInternal() 方法,主要工作包括:
- 创建操作符链(Operator Chain):构建过程会调用操作符的
setup()进行操作符设置 - 初始化任务特定的组件(通过
init()方法) - 恢复任务状态和输入门(Input Gates)
- 设置定时任务(如缓冲区优化器)
2. 运行阶段
1)打开操作符(Open Operators),主要工作如下:
- 调用所有操作符的
open()方法 - 初始化操作符的内部状态和资源
2)执行主循环(Run Main Loop):invoke() 方法会调用 runMailboxLoop(),核心实现在mailboxProcessor.runMailboxLoop()
- 主要工作:
- 处理输入数据(通过
processInput()方法) - 执行邮箱中的任务
- 处理检查点和其他系统事件
- 管理定时任务
- 处理输入数据(通过
这个循环持续运行,不断从邮箱(Mailbox)中取出事件或数据,执行相应操作。它既可以处理算子输入数据,也能响应控制事件(如 Checkpoint、Cancel、Timer)。这种统一的事件驱动模型,是 Flink 高并发执行的核心设计之一。
3. 终止阶段
1)完成操作符:调用所有Operator的 finish() 方法,确保所有输入数据都被处理完毕
2)关闭操作符:afterInvoke() 方法调用 closeAllOperators(),调用所有操作符的 close() 方法,释放Operator占用的资源
3)清理资源(Cleanup):正常结束时调用 afterInvoke(),异常时调用 cleanUp(),核心实现在resourceCloser.close()
- 主要工作:关闭邮箱处理器(Mailbox Processor)、释放输出资源、关闭通道 IO 执行器、清理所有可关闭资源
4. 异常处理
任务执行过程中发生异常时会进行异常处理,核心清理实现也是在cleanUp() 方法,主要工作包括:标记任务为失败状态、取消任务执行、清理所有资源、处理并传播异常。
四、线程机制与Mailbox 模型
Flink 的算子执行并不是多线程并发完成的,而是每个 Task 实例内部采用单线程事件循环驱动的。这种设计看似违背“高并发”理念,但恰恰是 Flink 并发哲学的核心体现:通过多个 Task 实例水平扩展并发度,每个 Task 内部通过单线程保证执行的确定性与状态安全。
单线程的原因
- 状态一致性要求:多线程并发访问算子状态会引入复杂的同步问题(如竞态条件、死锁),而单线程模型天然避免了此类问题,简化了状态管理的复杂性。
- 事件处理可预测性:单线程顺序执行能严格保证单个 Task 内的事件处理顺序(如先处理 Checkpoint Barrier 再处理普通数据),这对时间窗口、状态快照等依赖顺序的算子至关重要。
- 性能开销的可控性:避免了多线程场景下的锁竞争、上下文切换和缓存失效等开销,使 Task 执行的性能更加稳定可预期。
Mailbox 模型的核心逻辑
Mailbox 模型是 Flink 实现单线程事件循环的关键机制,其核心组件包括:
1. MailboxProcessor:事件循环的“心脏”
MailboxProcessor 是事件处理循环的核心类,它的作用是:
- 轮询邮箱:不断检查
TaskMailbox(邮箱)中是否有待处理的任务(Mail); - 任务执行:按优先级取出任务并执行,支持同步/异步任务的统一调度;
- 默认动作:在无任务时执行“默认动作”(如
processInput()处理输入数据),确保核心业务逻辑不被阻塞。
2. TaskMailbox:事件的“容器”
TaskMailbox 是存储待执行事件的队列,具有以下特性:
- 优先级支持:事件按优先级排序,高优先级任务(如 Checkpoint 控制事件)优先执行;
- 线程安全:支持异步线程安全地投递事件到主线程的邮箱;
- 状态管理:维护邮箱的生命周期状态(如 OPEN、CLOSED),确保任务调度的安全性。
3. MailboxExecutor:异步组件与主线程的“桥梁”
MailboxExecutor 是算子或异步组件(如定时器、异步 I/O)与主线程交互的标准化接口,提供了安全投递任务的能力:
// 异步任务通过 MailboxExecutor 投递到主线程执行
mailboxExecutor.execute(
MailboxExecutor.MailOptions.deferrable(),
() -> {
progressWatermarkScheduled = false;
emitWatermarkInsideMailbox();
},
"emitWatermarkInsideMailbox"
);
MailboxExecutor 支持多种投递方式:
execute():异步投递任务,不等待执行结果;submit():异步投递任务并返回Future,支持后续跟踪执行状态;yield():主动让出线程执行权,优先处理邮箱中的其他任务。
这种模型既保持了线程安全,又具备异步扩展能力。
在 Flink 的 Checkpoint、TimerService、异步 I/O 中都有广泛使用。
五、数据流向与算子调用栈
理解完线程模型,再来看数据是如何在 Task 内流动的。一次完整的事件处理流程大致如下:
NetworkInput → StreamInputProcessor → OperatorChain → 用户函数 → RecordWriter1. 核心组件与数据流向
-
数据输入:
InputGate从上游 Task(通过 Netty Shuffle)读取序列化的字节数据; -
反序列化与分发:
StreamInputProcessor将字节流反序列化为StreamRecord,并分发给相应的算子; -
算子链调用:数据被传递到
OperatorChain的第一个算子; -
算子执行:每个算子调用
processElement(),最终执行用户定义逻辑; -
数据输出:
RecordWriter将处理结果序列化并写入ResultPartition,发送到下游 Task。
2. 完整调用栈示例
1. StreamTask.runMailboxLoop()
2. StreamTask.processInput()
3. StreamOneInputProcessor.processInput()
4. StreamTaskNetworkInput.emitNext()
5. StreamTaskNetworkOutput.emitRecord()
6. RecordProcessorUtils$Processor.accept()
7. OneInputStreamOperator.processElement()
8. 用户自定义函数 (如 MapFunction.map())
9. Output.collect()
10. RecordWriterOutput.collect()
11. RecordWriter.emit()
数据从 InputGate 流入,经由算子链层层加工,再输出到 ResultPartition。
这一过程,就是 Task 内部的完整“数据生产流水线”。
六、总结:一条线程上的并行世界
Flink 的执行引擎看似以 “单线程” 为基本执行单元,实则精准诠释了分布式流计算的核心设计哲学 ——用确定性的单线程执行,构建高可靠的分布式并行:
| 关键机制 | 作用 | 延续整个专栏的自动化工厂类比 |
|---|---|---|
| OperatorChain | 将无数据 shuffle 的连续算子融合为一个执行单元,消除线程切换与序列化 / 反序列化开销,提升执行效率 | 把多道无缝衔接的工序集成到一台一体化加工设备,一次进料即可完成全流程处理,省去工序间转运耗时 |
| StreamTask | 承载算子链的核心执行载体,管理单个并行子任务(Subtask)的完整生命周期(初始化、运行、异常处理、销毁) | 设备的智能控制系统,统筹这台设备从启动自检、加工运行到故障停机、维护重启的全生命周期 |
| Mailbox | 统一主线程的异步事件调度(如 Checkpoint 触发、状态清理、算子通知),避免多线程并发冲突,保证主线程执行的确定性 | 设备的指令接收终端,所有调度指令(如 “执行状态快照”“清理缓存数据”)都按优先级排队执行,不打乱加工节奏 |
| InputProcessor | 连接上游数据源与算子链,负责数据的读取、反序列化和传递 | 设备进料口与分拣,接收上游输送的原料,按加工需求分配 |
| ResultPartition | 将算子链处理后的结果按分区规则缓存、输出到下游,是数据流转的 “出口枢纽” | 设备出料口与分类缓存区,按下游设备需求对成品分类存放,等待转运 |
Flink 的并行,不是多线程的混乱并发,而是多 Task 的协同并行与单线程的确定执行; 它让每一条流水线有序流动,让数据在高并发中依然保持严格的一致性。
当我们理解了单个 Task 内部的执行机制,下一个问题自然是:这些 Task 之间的数据如何高效传输?从 ResultPartition 到 InputGate,Flink 构建了一套高性能的 Shuffle 网络体系,让数据在上百 Task 节点间传递依旧丝滑顺畅。下一篇,我将带来:《Flink Shuffle 机制全解析:从 ResultPartition 到 InputGate》。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)