即插即用系列 | CVPR Agent Attention:集成Softmax与线性注意力——无损加速Stable Diffusion,高分辨率生成的显存救星
论文题目:Adaptive Point-to-Point Convolution for Remote Sensing Image Pansharpening
论文原文 (Paper):https://arxiv.org/abs/2312.08874
官方代码 (Code):https://github.com/LeapLabTHU/Agent-Attention
1. 核心思想
本文提出了一种名为**“代理注意力”(Agent Attention)的新型注意力范式,旨在解决标准 Softmax 注意力(表达能力强但计算量 O ( N 2 ) O(N^2) O(N2) 过高)与线性注意力(计算高效 O ( N ) O(N) O(N) 但表达能力不足)之间的矛盾。其核心思想是引入一组“代理 Token”(Agent Tokens, A A A),作为原始查询(Query, Q Q Q)和键/值(Key/Value, K , V K, V K,V)之间的“中间商”。该机制通过两步 Softmax 操作实现:1) 代理聚合:少数 A A A Token 从所有的 K , V K, V K,V 中聚合全局信息;2) 代理广播:所有的 Q Q Q Token 仅从 A A A Token 处获取信息。作者从数学上证明了这种双重 Softmax 操作等价于一种“广义线性注意力”**,从而在保持线性计算复杂度的同时,实现了媲美 Softmax 注意力的强大表达能力。
2. 背景与动机
Transformer 模型的成功依赖于自注意力机制,但标准 Softmax 注意力的计算复杂度与 Token 数量(即图像分辨率)呈平方关系 ( O ( N 2 ) O(N^2) O(N2))。这导致其在处理高分辨率视觉任务(如检测、分割、生成)时,计算开销高到难以承受。
为了解决这个问题,现有的工作分为两条路径,但都存在缺陷:
- 限制感受野(如 Swin Transformer): 通过将注意力计算限制在局部窗口内来降低成本。但这牺牲了 Transformer 最核心的全局长程依赖建模能力。
- 线性注意力(如 Linear Attention): 通过改变计算顺序或使用矩阵分解,将复杂度降至线性 ( O ( N ) O(N) O(N))。但这种近似通常会导致模型表达能力严重下降,性能弱于 Softmax 注意力。
本文的动机是:是否存在一种机制,能同时拥有 Softmax 的高表达能力和 Linear 的高效率?
- 动机图解分析(Figure 1 & 2):
-
图表 A (Figure 1):揭示“查询冗余”问题
- “看图说话”: Figure 1a (Softmax Attention) 展示了每一个查询(Query,用不同颜色的星星表示)都需要与图像中的所有键/值(Key/Value)进行一一对比,导致 O ( N 2 ) O(N^2) O(N2) 的复杂度。
- 分析: 论文的核心洞察是,这种计算是高度冗余的。例如,图 1a 中多个代表“天空”的查询(如图中紫色和蓝色的星星),它们需要聚合的上下文信息(例如“鸟”和“树枝”的特征)是高度相似的。
- 解决方案 (Figure 1b): Agent Attention 引入了少数几个“代理 Token”(Agent Tokens,深灰色方块)作为“信息中转站”。
- Step 1 (代理聚合): 少数 n n n 个代理 Token 先去访问所有的 K/V,聚合回 n n n 份“全局信息摘要”。
- Step 2 (代理广播): 所有的 N N N 个查询 Token 不再访问 N N N 个 K/V,而是只访问这 n n n 个代理 Token 来获取摘要信息。
- 结论: 由于代理 n n n 远小于 N N N ( n ≪ N n \ll N n≪N),两步操作的复杂度约为 O ( N n d ) O(Nnd) O(Nnd),从“平方”降低到了“线性”。
-
图表 B (Figure 2):定位 Agent Attention
- “看图说话”: 这张图对比了三种注意力的计算流。
- 分析:
- (a) Softmax Attention:在 Q 和 K 之间计算 N × N N \times N N×N 的相似度矩阵,是 O ( N 2 ) O(N^2) O(N2) 的瓶颈。
- (b) Linear Attention:通过 ϕ \phi ϕ 函数映射 Q 和 K,然后改变计算顺序(先算 K T V K^T V KTV),避免了 N × N N \times N N×N 矩阵,复杂度为 O ( N d 2 ) O(Nd^2) O(Nd2),但表达能力受限于 ϕ \phi ϕ 函数。
- © Agent Attention:从结构上看,它像是 (a) 的两次应用(一次聚合,一次广播)。但从数学本质上看(如下文 Eq. 4 所证),它等价于 (b) 的一种广义形式。
- 结论: Figure 2 直观地展示了 Agent Attention 是如何通过一种新颖的结构,无缝集成了 Softmax 和 Linear Attention 两种范式,从而同时获得了二者的优点。
-
3. 主要贡献点
- 提出 Agent Attention 新范式: 创新性地提出了一个 (Q, A, K, V) 四元组注意力范式,引入“代理 Token” A A A。通过“代理聚合”和“代理广播”两步 Softmax 操作,将 O ( N 2 ) O(N^2) O(N2) 的复杂度降低至 O ( N n d ) O(Nnd) O(Nnd) 线性复杂度,同时保持了全局上下文建模能力。
- 揭示与线性注意力的等价性: 从理论上证明了 Agent Attention(两次 Softmax 操作)在数学上等价于一种**“广义线性注意力”**( O A = ϕ q ( Q ) ϕ k ( K ) T V O^A = \phi_q(Q)\phi_k(K)^T V OA=ϕq(Q)ϕk(K)TV)。其关键在于,它的映射函数 ϕ \phi ϕ 不再是固定的(如 ReLU),而是通过 Softmax 和代理 Token 动态学习的( ϕ q ( Q ) = σ ( Q A T ) \phi_q(Q) = \sigma(QA^T) ϕq(Q)=σ(QAT)),因此表达能力远超传统线性注意力。
- 设计完整的 Agent Attention 模块: 提出了一个即插即用的实用模块 (Figure 3b)。它不仅包含 Agent Attention 核心,还额外引入了 Agent Bias(提供空间位置信息)和 DWC(深度卷积,用于恢复线性注意力中容易丢失的特征多样性),进一步提升了模块性能。
- 在多种视觉任务上验证 SOTA 性能: 将 Agent Attention 作为即插即用模块替换现有 ViT(如 DeiT, PVT, Swin)中的注意力层,在图像分类、目标检测和语义分割等任务上均取得了显著的性能提升。
- 在高分辨率任务上展现巨大优势:
- 高分辨率微调: 由于其线性复杂度,Agent-ViT 在高分辨率(如 384 2 384^2 3842)微调时,性能-FLOPs 权衡远超基线(Figure 7c, Table 5)。
- 图像生成 (Stable Diffusion): 将 Agent Attention 免训练地(training-free)植入预训练的 Stable Diffusion 模型中,不仅显著加速了图像生成(例如,1.84 倍),还意外地提升了图像质量(FID 降低,伪影减少)。
4. 方法细节
-
整体网络架构(Figure 3(b) - Agent Attention Module):
- 模型名称: Agent Attention Module
- 数据流: 该模块是一个即插即用的组件,其内部数据流如下:
- 输入与投影: 输入特征 x x x ( N × C N \times C N×C) 被线性投影为 Q, K, V ( N × d N \times d N×d)。
- 分支 1:Agent Attention (核心路径)
- 获取 Agents (A): Query 特征 Q Q Q ( N × d N \times d N×d) 经过一个
Pooling操作(默认)被降采样,生成Agent TokensA A A ( n × d n \times d n×d)。 - Step 1: 代理聚合 (Agent Aggregation):
- A A A 作为 Query,K 作为 Key,V 作为 Value,执行第一次 Softmax 注意力: V A = A t t n S ( A , K , V ) V_A = Attn^S(A, K, V) VA=AttnS(A,K,V)。
- 在计算 σ ( A K T ) \sigma(AK^T) σ(AKT) 时,会加入一个位置偏置 B 1 B_1 B1 (Agent Bias)。
- 此步骤的输出 V A V_A VA ( n × d n \times d n×d) 被称为
Agent Features,它汇聚了来自所有 N N N 个 V 的全局信息摘要。
- Step 2: 代理广播 (Agent Broadcast):
- 原始的 Q Q Q 作为 Query, A A A 作为 Key, V A V_A VA (Agent Features) 作为 Value,执行第二次 Softmax 注意力: O a t t n = A t t n S ( Q , A , V A ) O_{attn} = Attn^S(Q, A, V_A) Oattn=AttnS(Q,A,VA)。
- 在计算 σ ( Q A T ) \sigma(QA^T) σ(QAT) 时,会加入位置偏置 B 2 B_2 B2。
- 此步骤的输出 O a t t n O_{attn} Oattn ( N × d N \times d N×d) 是 Agent Attention 路径的最终结果。
- 获取 Agents (A): Query 特征 Q Q Q ( N × d N \times d N×d) 经过一个
- 分支 2:多样性恢复 (DWC 路径)
- 为了弥补线性注意力的“低秩”缺陷(可能导致特征多样性降低),一个并行的
DWC(Depthwise Conv) 模块被应用于原始的 V V V (或 Q Q Q)。
- 为了弥补线性注意力的“低秩”缺陷(可能导致特征多样性降低),一个并行的
- 输出 (Output): 最终输出 O O O 是分支 1 (Attention 输出) 和 分支 2 (DWC 输出) 的相加 ( O = O a t t n + D W C ( V ) O = O_{attn} + DWC(V) O=Oattn+DWC(V),如 Eq. 6 所示)。
-
核心创新模块详解(Figure 3(a)):
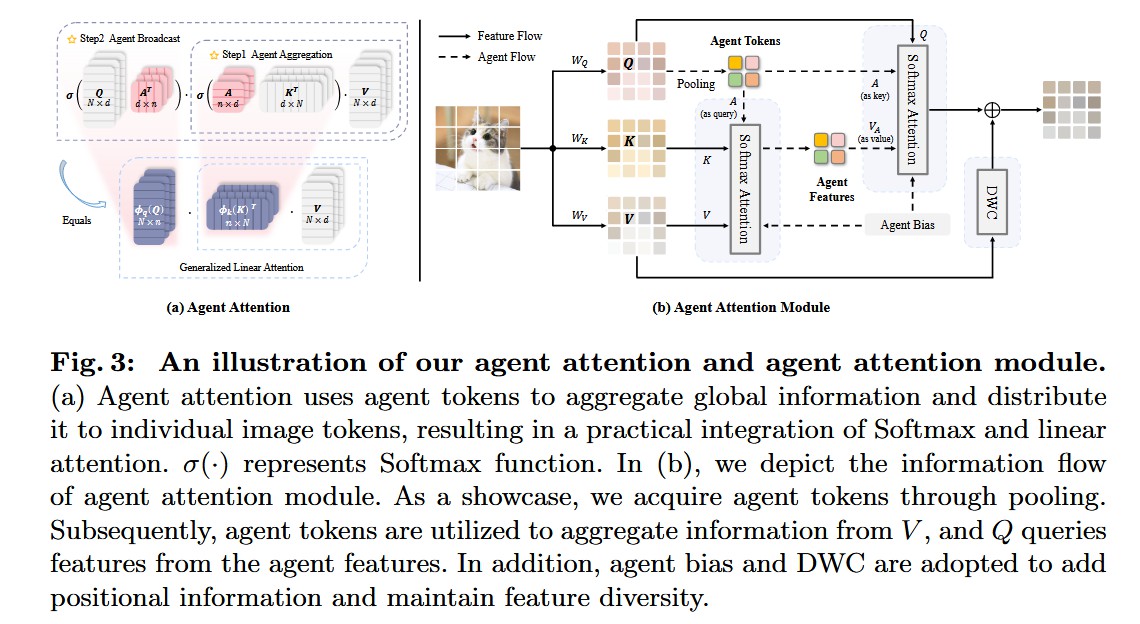
- 对于 广义线性注意力 (Figure 3a & Eq. 3, 4):
- 理念: 这是本文最核心的理论洞察,揭示了 Agent Attention 高效且强大的本质。
- 机制 (数学推导):
- Agent Attention 的两步操作 (不考虑 Bias 和 DWC) 可以写作 (Eq. 3):
O A = A t t n S ( Q , A , A t t n S ( A , K , V ) ) O^A = Attn^S(Q, A, Attn^S(A, K, V)) OA=AttnS(Q,A,AttnS(A,K,V)) - 将 A t t n S ( A , K , V ) Attn^S(A, K, V) AttnS(A,K,V) 展开为 σ ( A K T ) V \sigma(AK^T)V σ(AKT)V,代入上式:
O A = A t t n S ( Q , A , σ ( A K T ) V ) O^A = Attn^S(Q, A, \sigma(AK^T)V) OA=AttnS(Q,A,σ(AKT)V) - 再将 A t t n S ( Q , A , V A ) Attn^S(Q, A, V_A) AttnS(Q,A,VA) 展开为 σ ( Q A T ) V A \sigma(QA^T)V_A σ(QAT)VA:
O A = σ ( Q A T ) × ( σ ( A K T ) V ) O^A = \sigma(QA^T) \times (\sigma(AK^T)V) OA=σ(QAT)×(σ(AKT)V) - 利用矩阵乘法结合律,改变计算顺序:
O A = ( σ ( Q A T ) σ ( A K T ) ) × V O^A = (\sigma(QA^T) \sigma(AK^T)) \times V OA=(σ(QAT)σ(AKT))×V - 关键等价 (Eq. 4): 此时,如果我们将 ϕ q ( Q ) = σ ( Q A T ) \phi_q(Q) = \sigma(QA^T) ϕq(Q)=σ(QAT) 且 ϕ k ( K ) T = σ ( A K T ) \phi_k(K)^T = \sigma(AK^T) ϕk(K)T=σ(AKT),那么上式就变成了:
O A = ϕ q ( Q ) ϕ k ( K ) T V O^A = \phi_q(Q)\phi_k(K)^T V OA=ϕq(Q)ϕk(K)TV
- Agent Attention 的两步操作 (不考虑 Bias 和 DWC) 可以写作 (Eq. 3):
- 总结: 这个最终形式 O A = ϕ q ( Q ) ϕ k ( K ) T V O^A = \phi_q(Q)\phi_k(K)^T V OA=ϕq(Q)ϕk(K)TV 正是标准线性注意力的定义 (Eq. 2)。
- 结论: Agent Attention (图 3a 顶部) 在数学上等价于一种广义线性注意力 (图 3a 底部)。其区别在于,标准线性注意力的 ϕ \phi ϕ 是固定的(如 ReLU),而 Agent Attention 的 ϕ q \phi_q ϕq 和 ϕ k \phi_k ϕk 是通过 Softmax 和可学习的 Agent (A) 动态生成的。这使得它既有线性注意力的 O ( N ) O(N) O(N) 效率,又有 Softmax 注意力的数据依赖性和高表达能力。
- 对于 广义线性注意力 (Figure 3a & Eq. 3, 4):
-
理念与机制总结(Agent Bias 和 DWC):
- Agent Bias ( B 1 , B 2 B_1, B_2 B1,B2): 标准 ViT 使用的 RPB (相对位置偏置) 无法直接用于 (Q, A) 和 (A, K) 交互。因此,作者设计了 B 1 B_1 B1 (用于聚合) 和 B 2 B_2 B2 (用于广播) 两个偏置项,它们由更小的偏置分量(行偏置、列偏置、块偏置)高效构建而成,为 Agent 提供了必需的空间位置先验。
- DWC (多样性恢复模块): 线性注意力(包括 Agent Attention)的本质是一个低秩瓶颈(信息被压缩到 n n n 个 Agent 中)。这可能导致高频细节丢失。DWC 作为一个并行的分支(如 Eq. 6 所示),专门用于保留局部特征多样性。Ablation (Table 6) 证明 DWC 至关重要,它带来了 +1.5 的准确率提升。
-
图解总结(Figure 1, 7 & 10):
- Figure 1 提出了核心问题:Softmax 注意力(图 1a)存在计算冗余和 O ( N 2 ) O(N^2) O(N2) 瓶颈。
- Figure 1(b) 和 3(a) 提出了解决方案:使用 n n n 个 Agent Token 作为中间商,通过“聚合-广播”两步操作,将复杂度降至 O ( N n d ) O(Nnd) O(Nnd) 线性级别。
- Figure 7(a) 和 7(b) 定量验证了该方案的高效性。在 Swin-T 和 DeiT-T 上,Agent Attention (黑线) 的 FLOPs 增长(随窗口或分辨率)远低于标准 Softmax(蓝线),在 1024 2 1024^2 10242 分辨率下节省了 75% 的 FLOPs。
- Figure 10 定性验证了该方案的有效性。它对比了三种注意力的热力图。Softmax Attn 和 Agent Attn 都能准确聚焦到物体(橘子),而 Linear Attn 的注意力分布则非常弥散、不合理。这证明了 Agent Attention 确实保留了 Softmax 的高表达能力,而不仅仅是高效。
5. 即插即用模块的作用
Agent Attention 模块被设计为一个高效、高性能的**即插即用(plug-and-play)**组件,可以直接替代现有 Transformer 架构中的标准 Softmax 注意力或窗口注意力。
-
适用场景 1:升级标准 ViT 架构(分类、检测、分割)
- 应用: 在 DeiT, PVT, Swin Transformer 等模型的早期和中间阶段(分辨率较高、Token 数量 N N N 较大的阶段),用 Agent Attention 模块替换原有的注意力模块。
- 效果: 极大地提升了模型的“性价比”。例如,在 ImageNet 上,Agent-PVT-S 仅用 PVT-L 约 30% 的参数和 40% 的 FLOPs,就超越了其性能。Agent-Swin-T 获得了 +1.3% 的 Top-1 提升,同时 FLOPs 保持不变。
-
适用场景 2:高分辨率(HR)图像处理
- 应用: 在高分辨率输入下(如目标检测、语义分割、HR 分类微调),标准 Softmax 会导致计算量爆炸,而 Agent Attention 的线性复杂度使其成为理想选择。
- 效果: 如 Figure 7c 所示,在分辨率从 224 2 224^2 2242 提升到 384 2 384^2 3842 的过程中,Agent-Swin-S (黑线) 的性能-FLOPs 权衡曲线远优于标准 Swin-S 和 Swin-B。在 COCO 和 ADE20K 任务上,性能提升(+3.9 AP, +3.61 mIoU)尤为明显,证明了其在高分辨率场景的优势。
-
适用场景 3:加速预训练的生成模型(如 Stable Diffusion)
- 应用: 这是最引人注目的应用。Agent Attention 可以在**不进行任何额外训练(Training-Free)**的情况下,直接替换 Stable Diffusion (或 ToMeSD) 中的 Softmax 注意力模块。
- 效果(Figure 6):
- 显著加速: 相比原始 Stable Diffusion 和 ToMeSD,分别实现了 1.84 倍和 1.69 倍的生成加速。
- 质量提升: 与加速通常带来的质量下降相反,AgentSD (Agent Stable Diffusion) 的 FID 分数反而降低了(质量更好)。
- 伪影修复: 它能修正原始 SD 的生成错误,例如正确生成了鸟的腿(而不是一条腿)、正确区分了 “mitten”(手套)和 “cat”(猫)。
-
适用场景 4:加速生成模型的微调(如 Dreambooth)
- 应用: 在 Dreambooth 的微调和生成过程中均使用 Agent Attention。
- 效果: 可以在所有 diffusion 步骤中启用,实现 2.2 倍的生成加速,同时将微调的时间和显存成本降低约 15%,且不牺牲图像质量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)