收藏!从0到1掌握RAG技术:附实操代码+大模型学习路线
RAG(Retrieval-Augmented Generation,检索增强生成)是一种融合信息检索与文本生成能力的技术框架,核心目标是通过引入外部私有知识库,解决传统大模型(如GPT、DeepSeek等)生成内容时的准确性不足、知识过时、领域适配性差等问题,从根源上降低模型“幻觉”概率。其中,RAG知识库是整个技术体系的核心支撑,可存储文档、网页内容、数据库记录等各类结构化与非结构化数据。当模
1、什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种融合信息检索与文本生成能力的技术框架,核心目标是通过引入外部私有知识库,解决传统大模型(如GPT、DeepSeek等)生成内容时的准确性不足、知识过时、领域适配性差等问题,从根源上降低模型“幻觉”概率。
其中,RAG知识库是整个技术体系的核心支撑,可存储文档、网页内容、数据库记录等各类结构化与非结构化数据。当模型需要生成回答时,会先从知识库中动态检索相关信息,再结合自身能力输出精准结果,实现“生成+检索”的双重赋能。
2、RAG架构及执行流程
传统生成模型仅依赖预训练阶段习得的参数化知识,受限于训练数据的时间窗口(如数据截止到2023年)和领域范围,在处理实时信息、垂直领域问题时易生成错误内容。而RAG通过引入外部知识库,让模型“实时查资料”,完美弥补了这一短板。
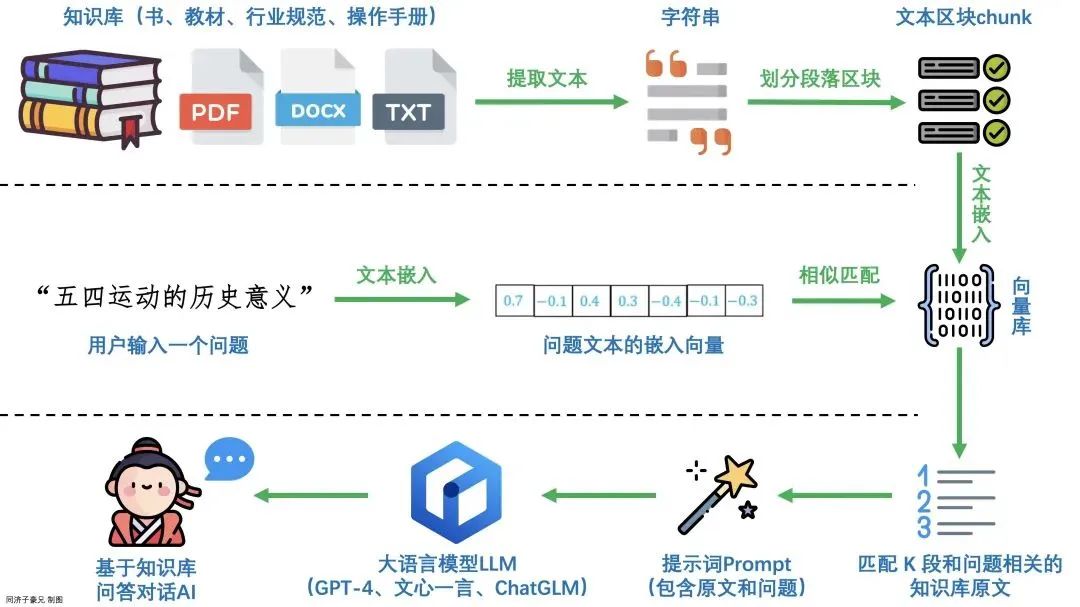
RAG完整执行流程可拆解为四大核心步骤,逻辑清晰且易于落地:
- 语料预处理与向量转化:将原始语料库内容拆分、清洗后,转化为计算机可识别的向量(Embedding);
- 向量入库存储:将生成的文本向量批量写入向量数据库,建立可检索的向量索引;
- 向量相似度检索:用户查询文本先转化为向量,通过向量数据库计算相似度,匹配出最相关的语料内容;
- 大模型生成优化:将检索到的相关语料作为上下文,传给大模型生成贴合需求、准确无误的回答。
第一步:语料库及转化为向量
可以通过deepseek等大模型生成,比如:请给我生成一个套出租房屋业务客服语料库。生成好后,复制到本地txt文件。
# 内容提取和段落划分很简单
def get_chunk_list():
with open("dataset/1.txt", encoding='utf-8') as fp:
data = fp.read()
chunk_list = data.split("\n\n")
return [chunk for chunk in chunk_list if chunk]
向量化处理我们借助于ollama,官网https://ollama.com下载。
安装好后,我们可以直接在命令行安装模型。
ollama pu11 nomic-embed-text
把文本内容转化为向量
# 文本妆化为向量
def ollama_embedding_by_api(text):
url = "http://127.0.0.1:11434/api/embeddings"
res = requests.post(
url=url,
json={
"model": "nomic-embed-text",
'prompt': text
}
)
return res.json()['embedding']
第二步:语料库内容嵌入向量数据库
向量数据库有很多:chromadb、Faiss、Qdrant、Elasticsearch等等。 今天我们就使用chromadb,直接本地安装使用。
# 安装向量数据库
pip install chromadb
# 批量导入向量数据库
def bulk_insert_collection(lines):
collection = get_collection()
ids = [str(uuid.uuid4()) for _ in range(len(lines))]
vectors = [ollama_embedding_by_api(line) for line in lines]
collection.add(
ids=ids,
documents=lines,
embeddings=vectors
)
通过update和delete函数对表更新和删除操作,调整语料。
collection.update(ids=['id'],documents=['text'])
collection.delete(ids=['id'])
第三步:向量相似度搜索
检索数据转化为向量化数据,然后进行查询
def query_text(text):
vector = ollama_embedding_by_api(text)
collection = get_collection()
# n_result 匹配数量 2
res = collection.query(
query_embeddings=[vector, ],
query_texts=text,
n_results=2)
return "\n".join(res['documents'][0])
第四步:文本大模型润色
使用文本大模型进行推理,安装deepseak蒸馏的r1模型
# 继续使用ollama进行安装
ollama pull deepseek-r1:1.5b
根据自己的应用场景或行业定义提示词。
def get_deepseek_response(question,answer):
prompt = f"""你是一个房屋出租客服机器人,任务是根据参考
信息回然用户问题,如果参考信息不足以回然用户问题,
请回复不知道,不要去杜撰任何信息,请用中文同然。
参考信息:{question},来回答问题:{answer}
"""
res = requests.post(
url="http://127.0.0.1:11434/api/generate",
json={
"model": "deepseek-r1:1.5b",
'prompt': prompt,
'stream': False,
}
)
return res.json()['response']
第五步:测试运行
写入预料到向量数据库
bulk_insert_collection(get_chunk_list())
检索并文本输出
question = '你好,我想租房'
answer = query_text(question)
res = get_deepseek_response(question,answer)
print(res)
总结起来就是:知识库是将知识数据的索引保存到向量数据库中,然后利用prompt的向量到向量数据库中搜索,根据阈值搜到符合要求的,并对搜索到的知识进行二次处理,然后连同prompt一起作为上下文提交给大模型。
普通人如何抓住AI大模型的风口?
为什么要学习大模型?
在DeepSeek大模型热潮带动下,“人工智能+”赋能各产业升级提速。随着人工智能技术加速渗透产业,AI人才争夺战正进入白热化阶段。如今近**60%的高科技企业已将AI人才纳入核心招聘目标,**其创新驱动发展的特性决定了对AI人才的刚性需求,远超金融(40.1%)和专业服务业(26.7%)。餐饮/酒店/旅游业核心岗位以人工服务为主,多数企业更倾向于维持现有服务模式,对AI人才吸纳能力相对有限。
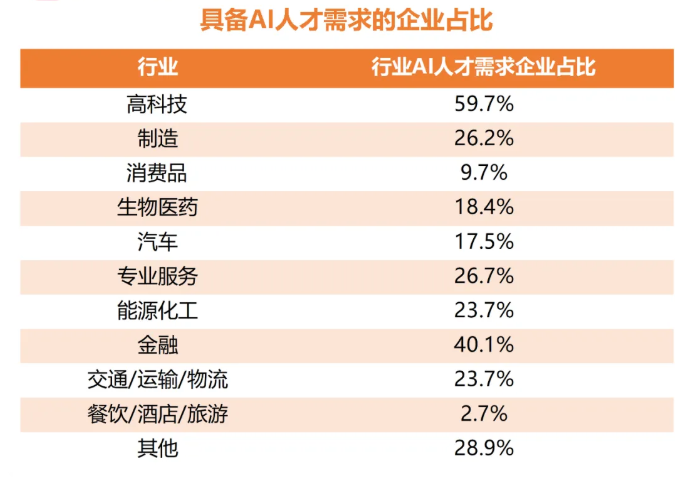
这些数字背后,是产业对AI能力的迫切渴求:互联网企业用大模型优化推荐算法,制造业靠AI提升生产效率,医疗行业借助大模型辅助诊断……而餐饮、酒店等以人工服务为核心的领域,因业务特性更依赖线下体验,对AI人才的吸纳能力相对有限。显然,AI技能已成为职场“加分项”乃至“必需品”,越早掌握,越能占据职业竞争的主动权
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
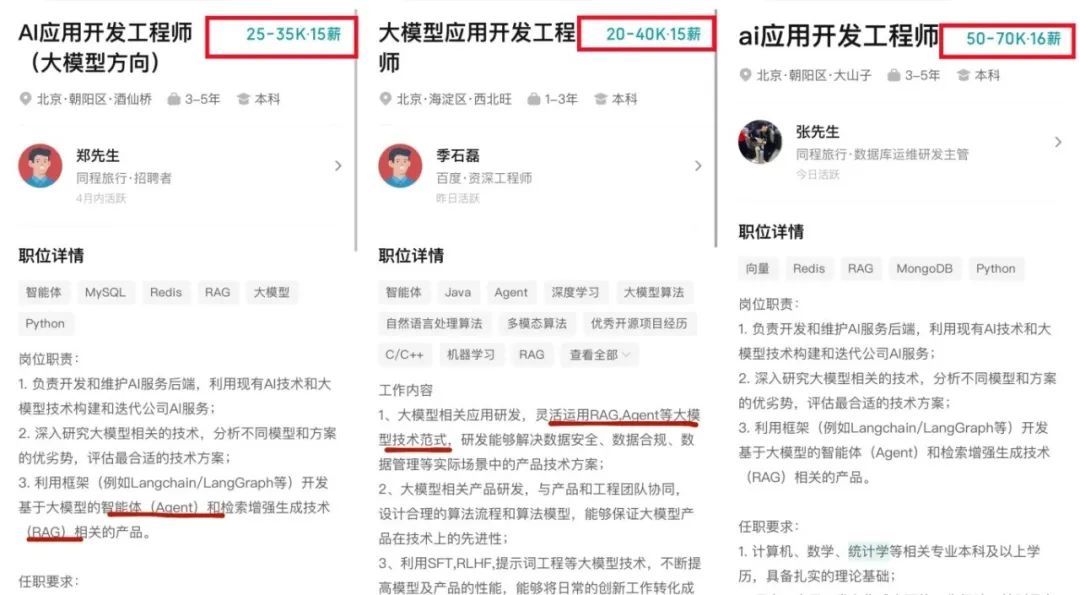
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可

部分资料展示
一、 AI大模型学习路线图
这份路线图以“阶段性目标+重点突破方向”为核心,从基础认知(AI大模型核心概念)到技能进阶(模型应用开发),再到实战落地(行业解决方案),每一步都标注了学习周期和核心资源,帮你清晰规划成长路径。

二、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

三、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

四、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 34
34 0
0- 0



 已为社区贡献523条内容
已为社区贡献523条内容

所有评论(0)