信息提取进入“高亮显示”时代:每个结果都能点回原文,LangExtract让AI提取不再黑盒
LangExtract是Google开源的高精度结构化信息提取框架,基于大语言模型实现非结构化文本到结构化数据的转换。核心功能包括:通过Few-shot示例定义任务、智能分块处理长文档、精确溯源结果到原文位置,以及生成交互式可视化报告。相比传统方法,它显著降低了开发成本(预估价值$85,000+),避免了数据标注需求,并解决了LLM提取中的"黑箱"问题。技术亮点包括插件化模型适
LangExtract:基于大语言模型的高精度结构化信息提取框架深度解析
1. 整体介绍
1.1 项目概况与生态
项目地址:google/langextract (Apache 2.0 License)
项目状态:当前版本 v1.1.1,处于活跃维护阶段。作为Google的开源项目,其设计体现了生产级代码的严谨性,包括完整的CI/CD流程(GitHub Actions)、类型提示、模块化架构以及对Python 3.10+的严格依赖。项目在PyPI上可用,并提供了详尽的文档和示例。
核心定位:LangExtract是一个以精确溯源(Grounding)为核心的Python库,它利用大语言模型的推理能力,结合用户定义的少量示例,从非结构化文本中提取并结构化信息,同时将每个提取结果映射回原文的精确位置。
1.2 主要功能与可视化
LangExtract的核心工作流是:定义任务(Prompt + Few-shot Examples) → 执行提取 → 获得可溯源的标注结果 → 生成交互式可视化报告。
其生成的交互式HTML报告是标志性功能。如下图所示,它能将提取出的实体(如人物、情感)在原文中高亮显示,并通过侧边栏列表进行导航,实现了提取结果的直观验证与审查。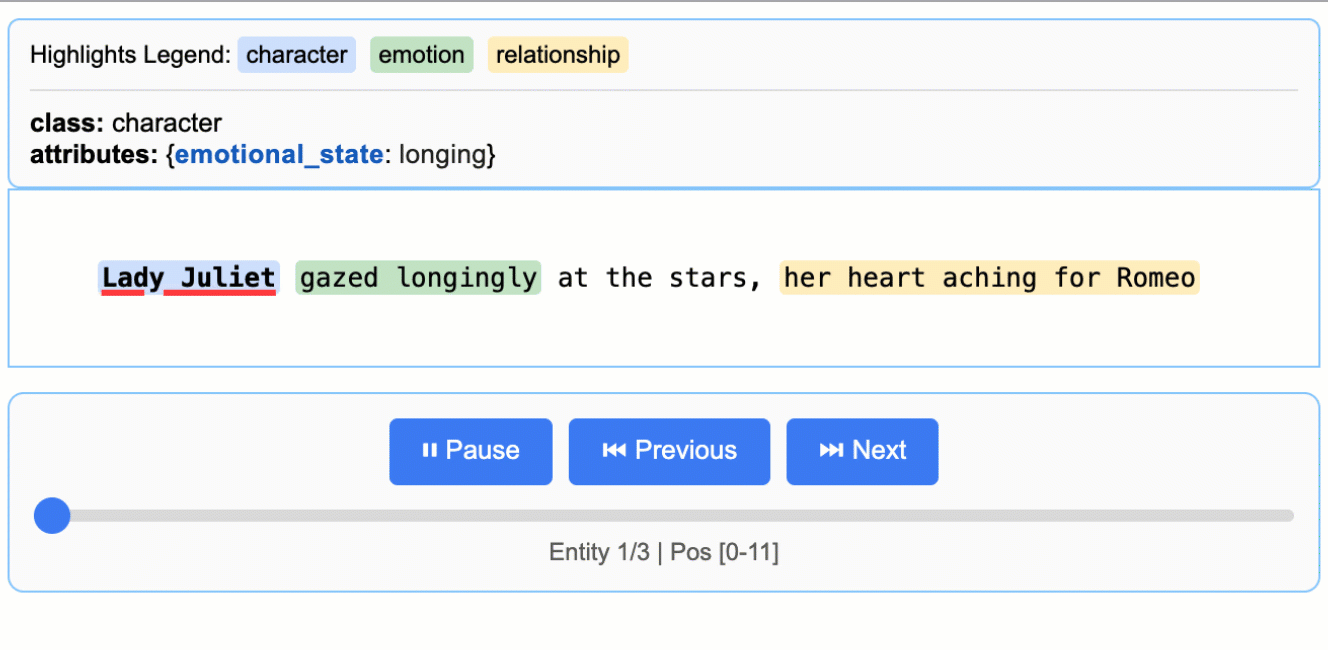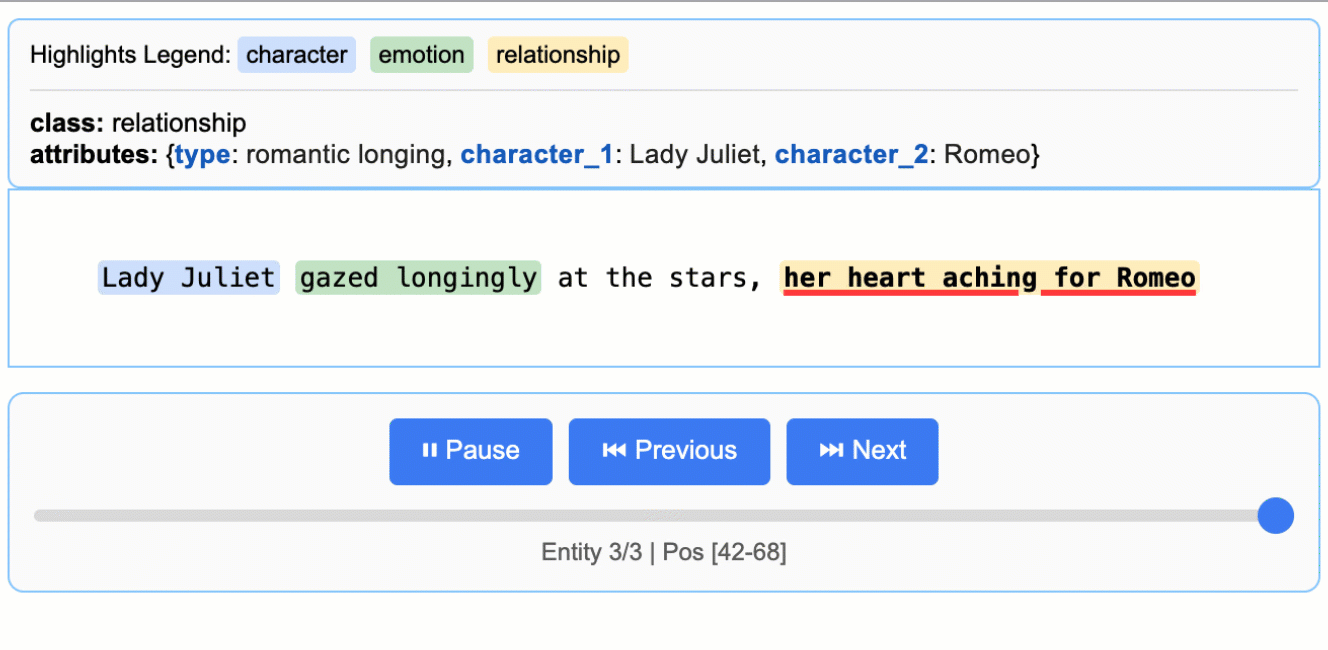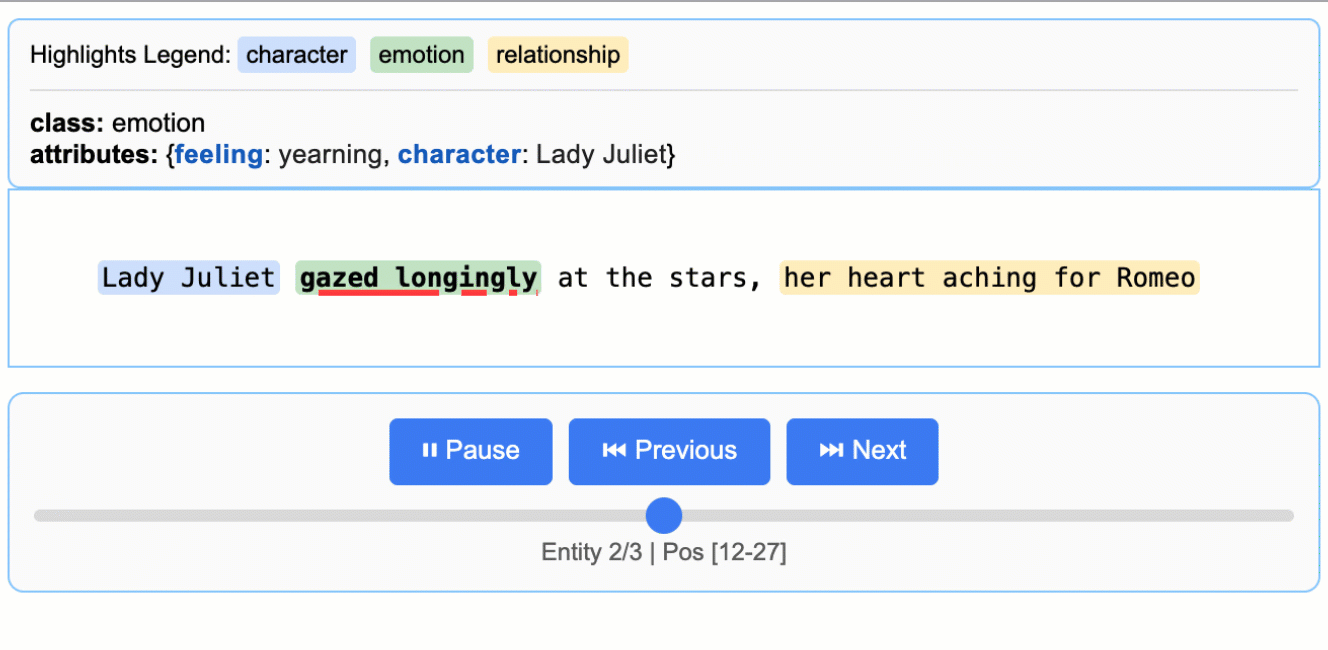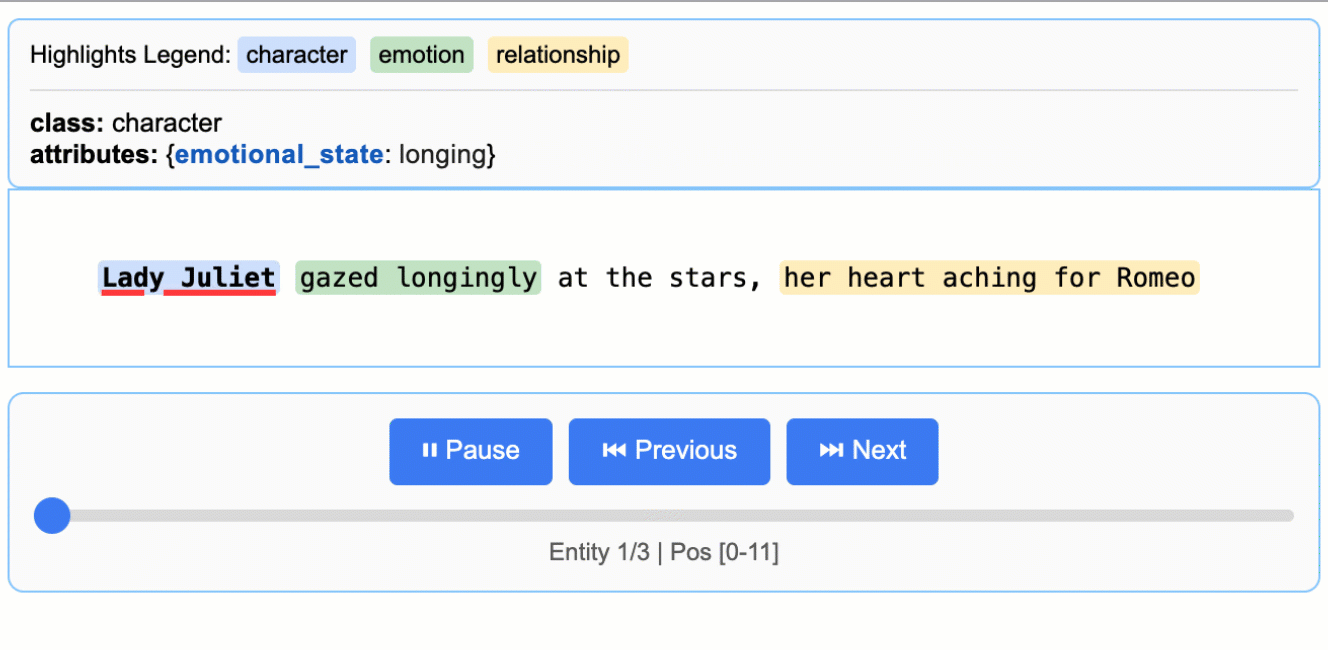
(该动图展示了从莎士比亚文本中提取的人物、情感实体在原文中的高亮与交互)
1.3 面临问题、目标人群与应用场景
解决的痛点:
- “黑箱”提取:传统LLM调用返回纯文本或JSON,无法验证信息是否真正来源于输入文本,存在“幻觉”风险。
- 长文档处理瓶颈:LLM上下文长度有限,直接从长文档(如整本书、医疗记录)中提取信息困难。
- 结构化输出不稳定:让LLM遵循复杂、自定义的输出格式需要精细的提示工程,且输出易波动。
- 多模型适配成本高:为不同模型(云API、本地部署)重写适配逻辑繁琐。
目标用户:
- AI工程师/研究者:需要快速构建可验证的信息抽取原型。
- 领域专家(医疗、法律、金融):希望不编写复杂代码即可从领域文档中提取结构化数据。
- 数据科学家:处理大量非结构化文本,需要进行实体、关系标准化。
典型场景:
- 临床文本处理:从病历中提取药物、剂量、诊断。
- 文学与社科分析:从小说、访谈录中提取人物、事件、观点。
- 商业文档解析:从合同、报告中提取条款、责任方、金额。
- 知识库构建:从技术文档、论文中提取术语、定义、方法。
1.4 解决方案与优势对比
传统方法:
- 规则/正则表达式:精度高但泛化能力差,无法适应语言变化。
- 训练定制化NER模型:需要大量标注数据,成本高,迭代慢。
- 直接使用LLM API:需自行处理分块、提示工程、输出解析和溯源对齐,代码冗杂且脆弱。
LangExtract的新范式:
- Few-shot提示工程为核心:用户通过数个高质量示例定义任务,无需标注数据训练,适应性强。
- 内置分块与多轮提取算法:自动将长文档分解,通过多轮扫描(
extraction_passes)提高召回率,平衡上下文与计算成本。 - 强制结构化输出与精确溯源:利用模型的原生结构化输出能力(如Gemini的
generateContentschema约束)或后处理对齐,保证格式稳定并将结果映射回原文字符级位置。 - 统一的提供者抽象层:通过插件化架构,将
extract()API与底层模型(Gemini、OpenAI、Ollama)解耦,降低切换成本。
1.5 商业价值预估
价值估算逻辑:
- 开发成本节约:构建一个具备可比性(分块、多轮提取、对齐、多后端支持)的系统,至少需要1-2名高级工程师2-3个月的开发与测试投入。以人力成本折算,约为 $80,000 - $120,000。
- 数据标注成本规避:采用few-shot学习替代全监督训练,假设一个中等复杂度实体抽取任务需标注5000个样本,可节约标注成本约 $5,000 - $15,000。
- 效率提升:将开发信息提取流程的时间从数周缩短至数小时,加速领域解决方案的迭代。
- 风险控制价值:精确溯源功能为医疗、法律等高风险场景提供了必要的可审计性,降低了因模型“幻觉”导致的决策风险,此项价值难以量化但至关重要。
综合估算:LangExtract为中小型团队或项目提供的直接技术替代价值在 $85,000+ 量级,其更大的价值在于降低了结构化信息提取的技术门槛,使领域专家能直接参与构建AI流程。
2. 详细功能拆解
2.1 产品视角核心流程
- 任务定义:用户提供
prompt_description(指令)和examples(包含原文和期望结构化提取结果的示例)。 - 文档预处理:支持直接输入文本、文档对象或URL。库函数自动获取并处理。
- 智能分块与推理:根据
max_char_buffer将长文本分块,可选择添加上下文窗口(context_window_chars)以解决指代问题,并行调用LLM。 - 结果解析与对齐:解析LLM返回的JSON/YAML,使用
Resolver和WordAligner将提取的文本片段与原文进行模糊或精确匹配,确定字符偏移量。 - 结果合并与输出:合并多轮、多块的结果,去重,输出
AnnotatedDocument对象列表,包含完整的溯源信息。 - 可视化与持久化:可序列化为JSONL,并一键生成交互式HTML报告。
2.2 技术架构核心模块
extraction(API层):提供统一的extract()函数,负责参数整合、验证和流程编排。annotation(协调层):Annotator类协调分块、提示构建、批量推理和结果解析。prompting(提示工程层):PromptTemplateStructured、QAPromptGenerator负责构建符合Few-shot格式的提示词。resolver(解析对齐层):Resolver类负责解析模型原始输出,WordAligner负责将提取文本定位到原文。providers(模型抽象层):定义了BaseLanguageModel接口,并由GeminiLanguageModel、OllamaLanguageModel等实现。通过entry_points实现插件化发现。core.data(数据模型层):使用Pydantic定义了ExampleData、Extraction、AnnotatedDocument等核心数据结构,确保类型安全。visualization(可视化层):将标注结果转换为自包含的HTML页面。
3. 技术难点与解决方案
-
难点:长文档上下文丢失与实体分散
- 解决方案:采用重叠分块与多轮提取策略。
extraction_passes > 1时,系统进行多次独立提取,合并非重叠结果,对于重叠部分采用“先到先得”策略,有效提高了分散实体的召回率。
- 解决方案:采用重叠分块与多轮提取策略。
-
难点:结构化输出的严格约束
- 解决方案:分层控制。
- 首选:利用模型原生能力(如Gemini的Schema)。
use_schema_constraints=True时,库会根据examples自动生成JSON Schema并传递给模型,实现强约束。 - 备选:提示词工程与后处理。对于不支持原生Schema的模型,通过
fence_output=True在提示词中要求代码块格式输出,并由Resolver进行解析。
- 首选:利用模型原生能力(如Gemini的Schema)。
- 解决方案:分层控制。
-
难点:提取文本与原文的精确对齐
- 解决方案:实现基于词的模糊对齐算法。
WordAligner在精确匹配失败后,会使用令牌重叠率(fuzzy_alignment_threshold,默认0.75)进行模糊匹配,应对LLM输出在空格、标点上的细微差异。
- 解决方案:实现基于词的模糊对齐算法。
-
难点:多模型后端适配与成本控制
- 解决方案:插件化提供者系统与批量处理。提供者抽象统一了接口;支持Vertex AI Batch API,可将大量请求离线处理,显著降低单位成本。
-
难点:Few-shot示例的质量控制
- 解决方案:预检提示验证。
prompt_validation_level可在运行前检查示例中extraction_text是否为原文的逐字匹配,发出警告或报错,引导用户构建高质量示例。
- 解决方案:预检提示验证。
4. 详细设计图
4.1 系统架构图

4.2 核心提取序列图
4.3 核心类关系图
5. 核心代码解析
5.1 核心入口函数:extract()
此函数是库的总入口,负责参数整合、流程初始化与协调。
def extract(
text_or_documents: typing.Any,
prompt_description: str | None = None,
examples: typing.Sequence[typing.Any] | None = None,
model_id: str = "gemini-2.5-flash",
# ... 众多参数
) -> list[data.AnnotatedDocument] | data.AnnotatedDocument:
"""从文本中提取结构化信息。"""
# 1. 参数验证与预处理
if not examples:
raise ValueError("Examples are required...")
# 2. 提示词对齐预检(核心质量保证步骤)
if prompt_validation_level is not pv.PromptValidationLevel.OFF:
report = pv.validate_prompt_alignment(...)
pv.handle_alignment_report(...)
# 3. 模型工厂创建语言模型实例
if model:
language_model = model
elif config:
language_model = factory.create_model(config=config, ...)
else:
# 默认路径:根据model_id等参数自动创建配置
config = factory.ModelConfig(model_id=model_id, ...)
language_model = factory.create_model(config=config, ...)
# 4. 构建格式处理器和解析器
format_handler = fh.FormatHandler.from_resolver_params(...)
res = resolver.Resolver(...)
# 5. 创建标注器并执行核心流程
annotator = annotation.Annotator(
language_model=language_model,
prompt_template=prompt_template,
format_handler=format_handler,
)
# 6. 根据输入类型分派
if isinstance(text_or_documents, str):
return annotator.annotate_text(text=text_or_documents, resolver=res, ...)
else:
return annotator.annotate_documents(documents=text_or_documents, resolver=res, ...)
代码逻辑解析:
- 验证:确保用户提供了必要的
examples。 - 预检:调用
validate_prompt_alignment检查示例中的extraction_text是否与原文片段精确匹配,提前发现提示词设计问题。 - 模型创建:采用多层优先级(
model>config>model_id)创建语言模型实例,体现了高度的灵活性。 - 解析器准备:
FormatHandler根据输出格式(JSON/YAML)和是否使用围栏代码块来配置解析逻辑。 - 执行:将任务委托给
Annotator,由它负责具体分块、调用、解析、对齐的复杂流程。
5.2 提示词模板类:PromptTemplateStructured
此类是Few-shot学习的核心载体。
@dataclasses.dataclass
class PromptTemplateStructured:
"""用于Few-shot示例的结构化提示模板。"""
description: str # 任务指令,如“提取人物和情感”
examples: list[data.ExampleData] = dataclasses.field(default_factory=list)
# 每个ExampleData包含一段原文`text`和对应的`extractions`列表。
class QAPromptGenerator:
"""将结构化模板转换为LLM可理解的问答格式提示词。"""
def render(self, question: str, additional_context: str | None = None) -> str:
prompt_lines: list[str] = [f"{self.template.description}\n"]
# ... 添加示例 ...
prompt_lines.append(f"{self.question_prefix}{question}")
prompt_lines.append(self.answer_prefix)
return "\n".join(prompt_lines)
设计亮点:QAPromptGenerator采用“指令-示例-问题-答案”的标准格式组装提示词,确保与预训练任务格式一致,提升模型表现。ContextAwarePromptBuilder是其扩展,通过注入前文片段([Previous text]: ...)来解决跨分块的指代问题。
5.3 解析与对齐核心:Resolver 与 WordAligner
Resolver负责将模型返回的字符串解析为Extraction对象列表。
# 在Resolver的resolve方法中,核心步骤简化如下:
def resolve(self, llm_output: str, source_text: str) -> List[Extraction]:
# 1. 使用FormatHandler解析字符串,得到原始字典列表
raw_extractions = self.format_handler.parse(llm_output)
extractions = []
for raw in raw_extractions:
# 2. 为每个提取项计算在原文中的位置
start, end = self._aligner.align(
target=raw['extraction_text'],
source=source_text
)
# 3. 构建带位置信息的Extraction对象
ext = Extraction(
extraction_class=raw['class'],
extraction_text=raw['text'],
attributes=raw.get('attributes'),
char_start=start,
char_end=end
)
extractions.append(ext)
return extractions
WordAligner.align()方法首先尝试精确字符串匹配,失败后采用基于分词的重叠度计算进行模糊匹配。这种设计平衡了精度和鲁棒性,能有效处理LLM输出中常见的空格、缩写等微小差异。
总结与展望
LangExtract在技术选型与架构设计上做出了精准的权衡。它没有试图构建一个全能的“Agent”框架,而是聚焦于**“可溯源的少样本信息提取”**这一单一且高价值的任务,并做深做透。其核心优势在于将LLM的泛化能力与工程上的可验证性、可扩展性紧密结合。
对比同类工具:
- vs LangChain/ LlamaIndex:后两者是更通用的编排框架,组件更丰富,但实现同等精度的溯源提取需要更多自定义开发。LangExtract是“开箱即用”的垂直解决方案。
- vs 直接调用LLM API:LangExtract封装了全流程的最佳实践(分块、多轮、对齐、可视化),避免了重复造轮子。
潜在演进方向:
- 提取后处理链:引入对提取结果的标准化、验证或逻辑推理规则。
- 更丰富的对齐策略:支持语义相似度对齐,而不仅是词法匹配。
- 主动学习集成:根据模型置信度或不确定性,自动推荐需要标注的新示例。
对于需要在生产环境中部署可靠文本信息提取流程的团队而言,LangExtract提供了一个经过良好设计、可直接集成并降低总体拥有成本(TCO)的优质选择。其强调的“精确溯源”特性,使其在合规性和可审计性要求高的场景中具备独特优势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 35
35 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)