AI学习笔记整理(51)——大模型之RAG优化技术
那么这样的嵌入模型是如何得到的呢,例如Google开发的Word2Vec模型,还有其他高级的嵌入模型如BERT和GPT系列,它们通过更复杂的网络结构捕捉更深层次的语义关系。父chunk检索,也叫自动合并检索,即递归地将document分割成若干较大的父chunk,其中包含较小的子chunk,能搜索更细粒度的信息,将document分割成层次chunk结构,最终索引的是叶子chunk的embeddi
RAG基本流程
RAG(Retrieval Augmented Generation)为生成式模型提供了与外部世界互动提供了一个很有前景的解决方案。RAG的主要作用类似搜索引擎,找到用户提问最相关的知识或者是相关的对话历史,并结合原始提问(查询),创造信息丰富的prompt,指导模型生成准确输出。其本质上应用了情境学习(In-Context Learning)的原理。
RAG可分为5个基本流程:知识文档的准备;嵌入模型嵌入模型(embedding model);向量数据库;查询检索和生产回答。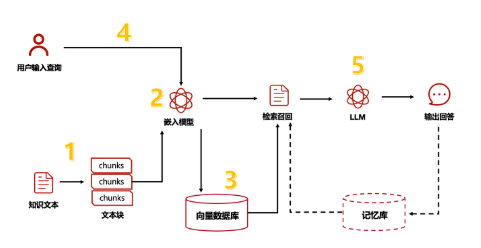
NO.1 知识文档的准备
在构建一个高效的RAG系统时,首要步骤是准备知识文档。现实场景中,我们面对的知识源可能包括多种格式,如Word文档、TXT文件、CSV数据表、Excel表格,甚至是PDF文件、图片和视频等。因此,第一步需要使用专门的文档加载器(例如PDF提取器)或多模态模型(如OCR技术),将这些丰富的知识源转换为大语言模型可理解的纯文本数据。例如,处理PDF文件时,可以利用PDF提取器抽取文本内容;对于图片和视频,OCR技术能够识别并转换其中的文字信息。此外,鉴于文档可能存在过长的问题,我们还需执行一项关键步骤:文档切片。我们需要将长篇文档分割成多个文本块,以便更高效地处理和检索信息。这不仅有助于减轻模型的负担,还能提高信息检索的准确性。
NO.2 嵌入模型
嵌入模型的核心任务是将文本转换为向量形式。简而言之,我们使用的日常语言中充满歧义和对表达词意无用的助词,而向量表示则更加密集、精确,能够捕捉到句子的上下文关系和核心含义。这种转换使得我们能够通过简单计算向量之间的差异来识别语义上相似的句子。举例来说,如果我们想比较“苹果是一种水果”和“香蕉是黄色的”,嵌入模型可以将这些句子转换为向量,然后通过计算它们之间的相似度便可以确定它们的关联程度。那么这样的嵌入模型是如何得到的呢,例如Google开发的Word2Vec模型,还有其他高级的嵌入模型如BERT和GPT系列,它们通过更复杂的网络结构捕捉更深层次的语义关系。总之嵌入模型是连接用户查询和知识库的桥梁,确保了系统回答的准确性和相关性。
NO.3 向量数据库
顾名思义,向量数据库是专门设计用于存储和检索向量数据的数据库系统。在RAG系统中,通过嵌入模型生成的所有向量都会被存储在这样的数据库中。这种数据库优化了处理和存储大规模向量数据的效率,使得在面对海量知识向量时,我们能够迅速检索出与用户查询最相关的信息。
NO.4 查询检索
经过上述几个步骤的准备后,我们就可以开始进行处理用户查询了。首先,用户的问题会被输入到嵌入模型中进行向量化处理。然后,系统会在向量数据库中搜索与该问题向量语义上相似的知识文本或历史对话记录并返回。
NO.5 生成回答
最终将用户提问和上一步中检索到的信息结合,构建出一个提示模版,输入到大语言模型中,静待模型输出答案即可。
RAG智能优化技术
RAG(检索增强生成)智能优化技术主要通过一系列范式演进来实现,从基础的检索生成逐步发展为融合多种智能技术的复杂系统。根据2025年发布的权威综述,RAG技术已形成五大核心范式,每一种都代表了不同的优化方向。
- 朴素RAG(Naive RAG):这是RAG的最基础形态,其核心优化在于简单的检索与生成流程。它通过语义相似性计算从外部知识库中检索相关文档块,然后将这些块作为上下文输入给大语言模型(LLM)进行答案生成。其主要优势是实现简单,能有效缓解LLM的“幻觉”问题,但缺乏对检索结果的深度处理和生成过程的精细控制。
- 高级RAG(Advanced RAG):该范式在朴素RAG基础上进行了多方面的智能增强,优化重点包括:
- 查询重写与扩展:对用户原始查询进行语义重构,以提高检索的准确率。
- 多粒度检索与融合:从不同层级(如段落、句子)检索信息并进行融合,提升信息覆盖度。
- 结果重排序与过滤:对检索到的文档进行相关性重排序或冗余过滤,确保输入上下文的质量。
- 模块化RAG(Modular RAG):此范式将RAG系统拆分为独立的、可插拔的功能模块,如查询理解、检索器、重排序器、生成器等。其智能优化体现在高度的灵活性与可定制性上,允许根据具体任务需求选择和组合最优模块,并支持独立优化每个模块,例如更换更先进的检索模型或微调生成器。
- 图RAG(Graph RAG):由微软于2024年提出,是RAG范式的重要突破。其核心智能优化在于利用知识图谱结构。它不仅检索文本片段,更从知识图谱中检索实体及其关系,从而能更好地理解查询中实体间的复杂关联,生成的答案更具推理性和系统性,尤其擅长处理需要多跳推理的复杂问题。
- 智能体RAG(Agentic RAG):这是目前最先进的范式,融合了前四种范式的优势,并引入了智能体(Agent)的自主决策与行动能力。其智能优化体现在自适应性与复杂任务处理上,智能体可以规划检索策略、动态调用工具、进行逻辑推理,并根据中间结果调整后续行动,从而能自主完成如多轮对话、复杂问答、决策支持等高度灵活的任务。
RAG检索优化技术
参考链接:https://hub.baai.ac.cn/view/34798
https://www.51cto.com/aigc/148.html
刚才讲述的流程仅仅为基本的RAG流程,但是其中的各个环节均有着极大的优化空间。下面我们将从上述5个环节中穿插几个具体优化策略来依次讲解。下面介绍的方法均在AI开发框架langchain和LLamaIndex中有具体实现,具体操作方法可参考官方文档。
1)Self-querying retrieval
自我查询检索(Self-querying retrieval)是一种信息检索技术,特别是在自然语言处理(NLP)和数据库查询领域,它允许一个查询语句直接在数据库或数据集中检索相关信息,同时还能在检索过程中使用检索结果来进一步细化或扩展原始查询。这种方法通常用于构建复杂的查询逻辑,特别是在需要从大量数据中提取特定信息时。
自我查询检索的工作原理:
- 初始查询:首先,用户或系统提出一个初始查询。这个查询可能是简单的,旨在从数据集中检索一些初始信息。
- 结果集:数据库或数据系统执行初始查询,返回一个结果集。
- 二次查询:基于第一次查询的结果,系统可以构造一个新的查询(即自我查询),这个查询会进一步利用第一次查询得到的数据。例如,如果第一次查询返回了一些特定类型的文档或记录,那么第二次查询可能针对这些特定文档的某些特征进行进一步的筛选或分析。
- 迭代:这个过程可以迭代进行,每次迭代都可能根据前一次的查询结果调整查询条件,直到达到用户所需的精确度或满足特定的业务逻辑。
2)Multi-Query retriever
多查询检索/多路召回, MultiQueryRetriever,这是 LangChain 框架中用于提升检索效果的一种查询转换工具。使用LLM生成多个搜索查询,特别适用于一个问题可能需要依赖多个子问题的情况。
MultiQueryRetriever 的核心思想是通过生成多个视角的查询变体来克服单一查询表述可能带来的信息召回不足问题。它的工作流程如下:
- 查询生成:利用一个大型语言模型(LLM),基于用户原始的查询,生成多个语义相关但表达方式和视角不同的查询问题。
- 并行检索:对每一个生成的查询变体,分别在向量数据库中执行检索。
- 结果合并:将所有检索结果合并,并进行去重处理。
- 返回结果:最终返回一个相关性更高、覆盖更全面的文档集合。
3)Step-back prompting
Step-Back Prompting(后退式提示)是一种旨在提升大型语言模型(LLM)复杂推理能力的提示工程技术。其核心思想是模拟人类专家解决问题时“先退后进”的思维方式:不直接应对具体问题,而是先引导模型抽象出更高层次的通用原理或基础知识,再基于这些原则进行推理,最终得出答案。
这种方法通过构建“抽象-推理”两阶段认知框架,有效降低了模型在多步推理中因陷入细节或表面特征而犯错的概率,尤其在科学、技术、数学和多跳问答等需要深度理解的任务中表现突出。
Step-Back Prompting 的典型过程包含两个关键步骤:
- 抽象(Abstraction):模型被引导将原始的具体问题,转化为一个更广泛、更基础的通用问题。例如,面对“为什么苹果会从树上掉下来?”这个问题,模型会先抽象出“什么是导致物体向地面运动的普遍物理原理?”。
- 推理(Reasoning):在获得抽象问题的答案(如“万有引力”)后,模型将此作为知识基础,回溯并推理出原始具体问题的解答。
4)基于历史对话重新生成Query
在向量空间中,对人类来说看似相同的两个问题其向量大小并不一定很相似。我们可以直接利用LLM 重新表述问题来进行尝试。此外,在进行多轮对话时,用户的提问中的某个词可能会指代上文中的部分信息,因此可以将历史信息和用户提问一并交给LLM重新表述。
其他Query优化相关策略
1)Sentence window retrieval
上下文压缩:当文档文块过大时,可能包含太多不相关的信息,传递这样的整个文档可能导致更昂贵的LLM调用和更差的响应。上下文压缩的思想就是通过LLM的帮助根据上下文对单个文档内容进行压缩,或者对返回结果进行一定程度的过滤仅返回相关信息。
句子窗口搜索:相反,文档文块太小会导致上下文的缺失。其中一种解决方案就是窗口搜索,该方法的核心思想是当提问匹配好分块后,将该分块周围的块作为上下文一并交给LLM进行输出,来增加LLM对文档上下文的理解。
2)Parent-child chunksretrieval
无独有偶,父文档搜索也是一种很相似的解决方案,父文档搜索先将文档分为尺寸更大的主文档,再把主文档分割为更短的子文档两个层级,用户问题会与子文档匹配,然后将该子文档所属的主文档和用户提问发送给LLM。
父chunk检索,也叫自动合并检索,即递归地将document分割成若干较大的父chunk,其中包含较小的子chunk,能搜索更细粒度的信息,将document分割成层次chunk结构,最终索引的是叶子chunk的embedding,将top-k结果中超过n个叶子chunk的父chunk进行替换,以获得更完整的文本语义信息。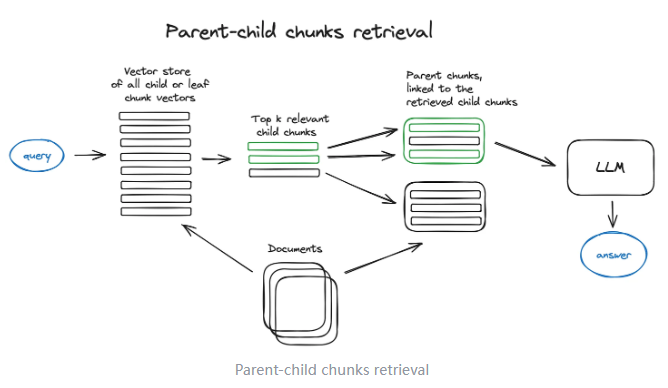
3)Fusion Retrieval
混合搜索:结合关键词搜索、语义搜索和向量搜索的技术以适应各种查询需求,并确保检索到相关且内容丰富的信息。
除了基于DL的检索方案之外,实际像经典的统计学检索方法TF-IDF和BM25这些稀疏检索算法也仍然有使用,在语料稀缺的垂直领域下甚至更为简单和高效,这种混合搜索策略能从互补的角度去recall chunk,基于DL方法从语义上recall,基于稀疏检索方法从关键字和文本上recall,然后将多路recall结果进行融合,弥补各自的优势和不足,能够提高整体的检索准确性和效率。而在这种多路recall方法的最后一步常常使用Reciprocal Rank Fusion(RRF)算法对每个chunk在不同recall方法中的排名进行加权求和,来解决不同路不同相似度之间score的融合问题,计算得到融合后的总score。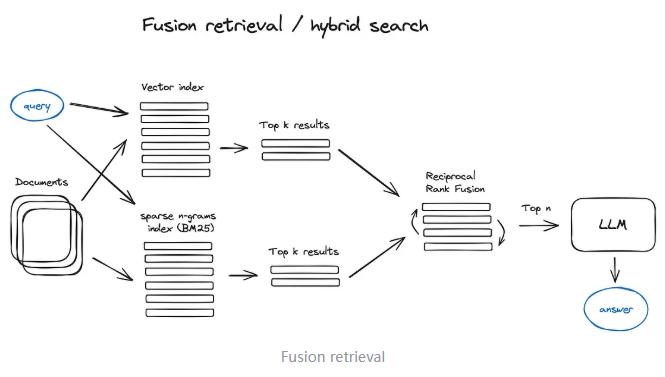
4)Ensemble Retrieval
集成检索:可以定义多个检索器,系统会将它们的结果加权融合,取长补短,最大化召回的准确性和多样性。
langchain EnsembleRetriever采用RRF算法,混合langchain的BM25、faiss、SQL等多种retriever的检索结果。
EnsembleRetriever接受多个retriever组成的列表作为输入,并根据各自的get_relevant_documents()进行集成,根据Reciprocal Rank Fusion算法重新计算排序分数。
EnsembleRetriever虽然忽略各自检索器的排序打分,但客观上有效利用了各自retriever的算法优势,相比任何单一retriever算法,排序结果更均衡,实际上排序结果更好。
5)RPF算法
如上所述,目前有多种排序结果,比如BM25,密集向量检索,那到底该优先采用那种排序结果。
用户有可能不理解这些排序算法的确切分布(或排序分数),不确定那种检索后排序更合理。
倒数融合排序(RRF, Reciprocal Rank Fusion),它忽略了各个检索的确切分数,也不考虑这些检索结果的分数。
RRF仅考虑每个检索排序结果中的每个文档的位置,比如在这个检索排序结果中文档d处于第几名,基于这些信息重新计算RRF分数,如此RRF通过这种简化逻辑,讲所有检索结果有效混合起来。
对于某个检索到的给定文档d,d必然在某个query检索到的有序结果中。
query可以是BM25,也可以是密集检索。
这里将query当作r,r(d)表示在本次query有序结果中d所处的排名位置,比如0、1、5的目光/
对于每次检索,对d的RRF score贡献表示为1/(k+r(d)),其中k为调节参数,通常为60。
对于某个检索到的给定文档d,RRF的计算公式如下所示,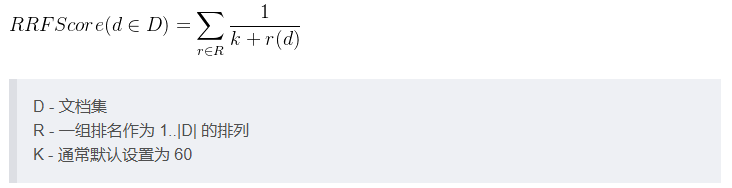

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)