AIGC 领域多模态大模型的知识图谱构建
你是否遇到过这样的情况?让AI生成“故宫的建筑特点”时,它可能会说“故宫的屋顶是蓝色琉璃瓦”(实际是黄色);让它根据“小猫追蝴蝶”的图片写故事,可能漏掉“小猫是三花毛色”的细节。多模态大模型虽能处理文字、图像等多类信息,但缺乏对知识的“系统性记忆”。多模态大模型与知识图谱的核心概念两者如何“优势互补”提升AIGC质量从0到1构建多模态知识图谱的技术步骤实际应用场景与未来趋势用“侦探破案”的故事类比
AIGC领域多模态大模型的知识图谱构建:让AI像人类一样“博学又聪明”
关键词:AIGC、多模态大模型、知识图谱、跨模态对齐、智能生成
摘要:在AIGC(生成式人工智能)领域,多模态大模型(如GPT-4V、DALL·E 3)已能生成文本、图像、视频等多种形式内容,但常因“知识幻觉”(生成错误信息)或“逻辑断层”(内容不连贯)被诟病。本文将揭示:如何通过“知识图谱”这张“知识导航地图”,为多模态大模型注入结构化知识,让AI生成的内容更准确、更有逻辑。我们将从核心概念讲起,结合生活案例、技术原理、代码实战,带你一步步理解“多模态大模型+知识图谱”的黄金组合。
背景介绍
目的和范围
你是否遇到过这样的情况?让AI生成“故宫的建筑特点”时,它可能会说“故宫的屋顶是蓝色琉璃瓦”(实际是黄色);让它根据“小猫追蝴蝶”的图片写故事,可能漏掉“小猫是三花毛色”的细节。这些问题的根源是:多模态大模型虽能处理文字、图像等多类信息,但缺乏对知识的“系统性记忆”。
本文将聚焦“如何为多模态大模型构建知识图谱”,覆盖以下范围:
- 多模态大模型与知识图谱的核心概念
- 两者如何“优势互补”提升AIGC质量
- 从0到1构建多模态知识图谱的技术步骤
- 实际应用场景与未来趋势
预期读者
- 对AIGC感兴趣的技术爱好者(无需深度学习基础)
- 从事多模态模型开发的工程师(想了解知识增强方法)
- 产品经理/运营(想理解AI生成内容的“可靠性”提升逻辑)
文档结构概述
本文将按“概念→关系→技术→实战→应用”的逻辑展开:
- 用“侦探破案”的故事类比,引出多模态大模型与知识图谱的作用;
- 用“超市购物”“地铁地图”等生活案例,解释核心概念;
- 用Python代码演示多模态知识融合的关键步骤;
- 结合“智能导游”“教育内容生成”等场景,说明实际价值。
术语表(用小学生能听懂的话解释)
- 多模态大模型:能同时“看懂文字、图片、声音”的AI大脑,比如能读小说、看照片、听音乐,并生成对应内容的“全能助手”。
- 知识图谱:知识的“地铁地图”,把“北京是中国首都”“故宫在北京市中心”这样的知识点(称为“实体”)用线(称为“关系”)连起来,形成“北京→首都→中国”“故宫→位于→北京”的网络。
- 跨模态对齐:让AI知道“图片里的小猫”和“文字里的‘小猫’”是同一个东西,就像教小朋友“画的苹果”和“真苹果”都叫“苹果”。
核心概念与联系:多模态大模型VS知识图谱,谁是AI的“大脑”和“知识库”?
故事引入:侦探破案的秘密武器
假设你是一个侦探,需要破解一起“博物馆名画盗窃案”。你有两个工具:
- 万能相机:能拍现场照片(如窗台上的脚印)、录监控声音(如可疑对话)、读纸质线索(如纸条上的字迹),并告诉你“可能的嫌疑人特征”(多模态大模型)。
- 破案手册:里面记录了“所有已知罪犯的指纹、前科、常去地点”,还标注了“指纹A→属于→嫌疑人X”“嫌疑人X→常去→咖啡馆Y”(知识图谱)。
如果只有万能相机,你可能会说:“嫌疑人穿42码鞋,身高175cm”,但无法确定“谁有42码鞋且出现在案发地”;如果只有破案手册,你可能知道“嫌疑人X有42码鞋”,但不知道“案发当天他是否在现场”。只有两者结合,侦探才能快速锁定真凶——这就是多模态大模型与知识图谱的协作逻辑:前者负责“收集分析多类信息”,后者负责“提供结构化知识”,共同提升推理准确性。
核心概念解释(像给小学生讲故事一样)
概念一:多模态大模型——AI的“信息处理员”
多模态大模型就像学校里的“全能课代表”:语文课能写作文,美术课能画插图,音乐课能听旋律并哼唱。它的“厉害”在于能同时处理文字、图像、视频、语音等多种类型的信息(称为“模态”),并生成对应的内容。例如:
- 输入“一张夕阳下的海滩照片+文字‘描述这张照片’”,它能输出“金色的阳光洒在沙滩上,海浪轻轻拍打着脚丫”;
- 输入“一段猫叫的音频+文字‘写一个小猫的故事’”,它能生成“小橘猫‘咪咪’对着窗外的蝴蝶‘喵喵’叫,想要一起玩”。
但它有个小缺点:记不住所有细节。比如它可能知道“猫有四条腿”,但记不清“布偶猫是长毛还是短毛”,或者把“故宫的屋顶颜色”记错。
概念二:知识图谱——AI的“知识导航地图”
知识图谱可以想象成“超级版的字典+关系图”。字典只能告诉我们“苹果是一种水果”,但知识图谱会画一张图:
苹果→属于→水果;
苹果→颜色→红色/绿色;
苹果→产地→山东/陕西;
苹果→相关人物→牛顿(被苹果砸中发现万有引力)。
这张图里,“苹果”“水果”“牛顿”是“实体”(知识点),“属于”“颜色”“产地”“相关人物”是“关系”(知识点之间的连接)。有了这张图,AI就能快速“查路线”:比如问“牛顿和苹果有什么关系?”,AI能沿着“牛顿←相关人物←苹果”找到答案。
概念三:跨模态对齐——让AI“看懂不同语言”
跨模态对齐是多模态大模型和知识图谱“对话”的关键。想象你有一个外国朋友,他只会说英语,而你有一本中文的《动物百科》。要让他看懂这本书,需要把“猫”翻译成“cat”,把“狗”翻译成“dog”——这就是“对齐”。
在AI领域,跨模态对齐是让模型知道:
- 文字“小猫”、图片里的“小猫”、语音“xiǎo māo”都是同一个概念;
- 知识图谱里的“实体:小猫”对应的多模态特征(文字描述、图像特征、声音特征)是什么。
只有对齐了,多模态大模型才能从知识图谱中“调取正确的知识”。
核心概念之间的关系:像“厨师+菜谱+食材库”一样协作
多模态大模型、知识图谱、跨模态对齐的关系,可以用“厨师做蛋糕”来类比:
- 多模态大模型是“厨师”,负责“处理鸡蛋、面粉、奶油(多模态信息)”,并按照步骤(模型算法)做出蛋糕(生成内容);
- 知识图谱是“菜谱数据库”,里面记录了“蛋糕需要鸡蛋2个”“奶油要打发到硬性发泡”“巧克力蛋糕需要可可粉”等知识(结构化关系);
- 跨模态对齐是“翻译器”,让厨师能看懂菜谱(比如把“鸡蛋”的文字描述和实际鸡蛋的图片/重量对应起来)。
三者协作后,厨师(多模态大模型)就不会出现“忘记放糖”(知识缺失)或“用错面粉”(模态错误)的问题了。
核心概念原理和架构的文本示意图
多模态大模型与知识图谱的协作架构可概括为:
多模态输入(文字/图像/语音)→ 多模态大模型(提取特征)→ 跨模态对齐(匹配知识图谱实体)→ 知识图谱(查询关联知识)→ 生成优化(结合知识调整生成内容)
Mermaid 流程图
核心算法原理 & 具体操作步骤:如何让多模态大模型“学会”知识图谱?
要让多模态大模型与知识图谱协作,关键是解决两个问题:
- 如何从多模态数据中提取“能匹配知识图谱”的特征?(跨模态对齐)
- 如何将知识图谱的知识“注入”大模型,提升生成质量?(知识融合)
跨模态对齐:让“文字-图像-知识”对上号
跨模态对齐的核心是“让不同模态的数据(文字、图像等)在同一个“数字空间”中表示”。例如,文字“小猫”和图片“小猫”在这个空间中的“坐标”要足够接近,这样模型才能知道它们是同一概念。
技术原理:对比学习(Contrastive Learning)
对比学习的思路很简单:让模型学会“区分相似和不同”。比如给模型看一组图片和文字对:
- 正例:图片是“小猫”+文字“小猫”
- 负例:图片是“小猫”+文字“小狗”
模型需要调整参数,让正例的“文字-图像”特征距离更小(更相似),负例的特征距离更大(更不同)。
用数学公式表示,假设文字特征为 ( E_{text} ),图像特征为 ( E_{image} ),则正例的损失函数(希望最小化的错误)为:
Lcontrastive=−log(exp(cos(Etext,Eimage)/τ)∑i=1nexp(cos(Etext,Eimagei)/τ)) L_{contrastive} = -\log\left( \frac{\exp(\cos(E_{text}, E_{image}) / \tau)}{\sum_{i=1}^n \exp(\cos(E_{text}, E_{image_i}) / \tau)} \right) Lcontrastive=−log(∑i=1nexp(cos(Etext,Eimagei)/τ)exp(cos(Etext,Eimage)/τ))
其中 ( \cos ) 是余弦相似度(衡量两个向量的相似程度),( \tau ) 是温度参数(控制相似度的“敏感度”),( n ) 是负例数量。
具体步骤(用Python伪代码演示)
import torch
import torch.nn.functional as F
# 假设我们有一个多模态编码器(能处理文字和图像)
class MultiModalEncoder(torch.nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = torch.nn.Linear(100, 256) # 文字编码器
self.image_encoder = torch.nn.Linear(2048, 256) # 图像编码器(假设图像特征维度2048)
def forward(self, text, image):
text_feat = F.normalize(self.text_encoder(text)) # 文字特征(归一化)
image_feat = F.normalize(self.image_encoder(image)) # 图像特征(归一化)
return text_feat, image_feat
# 对比学习训练过程
encoder = MultiModalEncoder()
optimizer = torch.optim.Adam(encoder.parameters(), lr=1e-4)
# 输入数据:正例(文字和图像匹配)、负例(文字和图像不匹配)
text_pos = torch.randn(2, 100) # 2个正例文字
image_pos = torch.randn(2, 2048) # 2个正例图像(与text_pos匹配)
image_neg = torch.randn(2, 2048) # 2个负例图像(与text_pos不匹配)
# 编码特征
text_feat, image_feat_pos = encoder(text_pos, image_pos)
_, image_feat_neg = encoder(text_pos, image_neg) # 负例图像编码
# 计算相似度(余弦相似度)
sim_pos = torch.cosine_similarity(text_feat, image_feat_pos, dim=1) # 正例相似度
sim_neg = torch.cosine_similarity(text_feat, image_feat_neg, dim=1) # 负例相似度
# 对比损失(希望正例相似度高,负例低)
tau = 0.1 # 温度参数
loss = -torch.mean(torch.log(torch.exp(sim_pos / tau) / (torch.exp(sim_pos / tau) + torch.exp(sim_neg / tau))))
# 反向传播优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
知识融合:让大模型“记住”知识图谱的知识
知识融合的目标是将知识图谱中的“实体-关系”信息注入多模态大模型,常见方法有两种:
方法1:知识增强预训练(Knowledge-Enhanced Pre-training)
在大模型的预训练阶段,加入知识图谱的三元组(实体1-关系-实体2)作为训练数据。例如,在训练时输入:
- 文字:“故宫位于北京市中心”
- 图像:故宫的卫星地图(标注“故宫”“北京”的位置)
- 知识图谱三元组:“故宫→位于→北京”
模型需要学会“从多模态输入中预测缺失的实体或关系”。例如,输入“故宫位于____”,模型需要输出“北京”。
方法2:知识引导生成(Knowledge-Guided Generation)
在生成阶段,当模型需要生成内容时,先查询知识图谱获取相关知识,再结合知识生成。例如,生成“故宫的建筑特点”时:
- 查询知识图谱:“故宫→建筑特点→红墙黄瓦”“故宫→屋顶类型→庑殿顶”;
- 将这些知识作为提示(Prompt)输入模型,指导生成。
技术示例:基于知识的生成提示
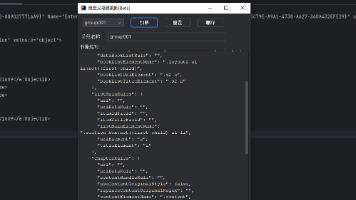
假设我们有一个知识图谱片段:
{
"实体": "故宫",
"属性": {
"位置": "北京市东城区",
"建筑特点": ["红墙黄瓦", "庑殿顶屋顶", "雕梁画栋"],
"建成时间": "明永乐十八年(1420年)"
},
"关系": ["属于→中国明清皇家宫殿", "包含→太和殿、中和殿、保和殿"]
}
生成提示可以设计为:
已知知识:故宫位于北京市东城区,建筑特点包括红墙黄瓦、庑殿顶屋顶、雕梁画栋,建成于明永乐十八年(1420年),是中国明清皇家宫殿,包含太和殿、中和殿、保和殿。
任务:根据以上知识,用生动的语言描述故宫的建筑特色。
模型根据提示生成的内容会更准确,避免“屋顶是蓝色”这样的错误。
数学模型和公式 & 详细讲解 & 举例说明
多模态特征表示的数学基础
多模态大模型通常将不同模态的数据映射到同一低维向量空间(称为“嵌入空间”)。例如,文字“小猫”的嵌入向量为 ( \mathbf{v}{text} ),图片“小猫”的嵌入向量为 ( \mathbf{v}{image} ),两者需满足 ( \mathbf{v}{text} \approx \mathbf{v}{image} )(通过跨模态对齐实现)。
知识图谱的表示学习(Knowledge Graph Embedding)
知识图谱的三元组(头实体h,关系r,尾实体t)也需要映射到嵌入空间,常用模型为TransE。TransE假设 ( \mathbf{h} + \mathbf{r} \approx \mathbf{t} )(头实体向量+关系向量≈尾实体向量)。例如,“故宫→位于→北京”可表示为:
v故宫+v位于≈v北京 \mathbf{v}_{故宫} + \mathbf{v}_{位于} \approx \mathbf{v}_{北京} v故宫+v位于≈v北京
损失函数设计为:
L=∑(h,r,t)∈S∑(h′,r,t′)∈S′max(0,γ+f(h,r,t)−f(h′,r,t′)) L = \sum_{(h,r,t) \in S} \sum_{(h',r,t') \in S'} \max(0, \gamma + f(h,r,t) - f(h',r,t')) L=(h,r,t)∈S∑(h′,r,t′)∈S′∑max(0,γ+f(h,r,t)−f(h′,r,t′))
其中 ( S ) 是正例三元组,( S’ ) 是负例三元组(如“故宫→位于→上海”),( \gamma ) 是边界参数,( f(h,r,t) = |\mathbf{h} + \mathbf{r} - \mathbf{t}|_2 ) 是距离函数(希望正例距离小,负例距离大)。
举例说明:用TransE学习“故宫”的知识
假设:
- ( \mathbf{v}_{故宫} = [0.2, 0.5] )(二维向量示例)
- ( \mathbf{v}{位于} = [0.3, 0.1] )
根据TransE假设,( \mathbf{v}{北京} \approx \mathbf{v}{故宫} + \mathbf{v}{位于} = [0.5, 0.6] )。
如果知识图谱中“北京→属于→中国”,则 ( \mathbf{v}{中国} \approx \mathbf{v}{北京} + \mathbf{v}_{属于} ),以此类推,形成知识的向量网络。
项目实战:构建一个简单的多模态知识图谱系统
开发环境搭建
- 硬件:普通笔记本电脑(CPU即可,如需加速可配GPU)
- 软件:Python 3.8+、PyTorch 2.0+、Hugging Face Transformers库、DGL(图神经网络库)
- 数据:
- 文字数据:维基百科“故宫”词条
- 图像数据:故宫图片(来自维基共享资源,标注“红墙”“黄瓦”等标签)
- 知识图谱数据:手动构建的“故宫知识小图谱”(包含10个实体、20条关系)
源代码详细实现和代码解读
我们将实现以下步骤:
- 从文字和图像中提取实体(如“故宫”“红墙”);
- 构建知识图谱(定义实体关系);
- 训练跨模态对齐模型;
- 用知识引导生成内容。
步骤1:实体提取(文字和图像)
# 文字实体提取(用Hugging Face的命名实体识别模型)
from transformers import pipeline
text = "故宫,又称紫禁城,是中国明清两代的皇家宫殿,位于北京中轴线的中心,建筑特点包括红墙黄瓦和庑殿顶。"
ner_pipeline = pipeline("ner", model="bert-base-chinese")
text_entities = ner_pipeline(text)
# 输出:[{'word': '故宫', 'entity': 'LOC'}, {'word': '中国', 'entity': 'LOC'}, ...](LOC表示地点)
# 图像实体提取(用YOLOv8目标检测模型识别“红墙”“黄瓦”)
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # 加载预训练模型
results = model("故宫图片.jpg") # 输入故宫图片
image_entities = []
for box in results[0].boxes:
label = model.names[int(box.cls)] # 获取标签(需自定义“红墙”“黄瓦”的训练数据)
image_entities.append(label)
# 输出:['红墙', '黄瓦', '庑殿顶']
步骤2:构建知识图谱(用DGL库创建图结构)
import dgl
import torch
# 定义实体和关系
entities = ["故宫", "北京", "红墙", "黄瓦", "庑殿顶", "中国", "明清"]
relations = ["位于", "建筑特点", "属于"]
# 构建三元组(头实体索引,关系索引,尾实体索引)
triples = [
(0, 0, 1), # 故宫→位于→北京
(0, 1, 2), # 故宫→建筑特点→红墙
(0, 1, 3), # 故宫→建筑特点→黄瓦
(0, 1, 4), # 故宫→建筑特点→庑殿顶
(1, 2, 5), # 北京→属于→中国
(0, 2, 6), # 故宫→属于→明清
]
# 创建DGL图
g = dgl.graph((torch.tensor([h for h, r, t in triples]),
torch.tensor([t for h, r, t in triples])))
g.edata["rel"] = torch.tensor([r for h, r, t in triples]) # 边存储关系索引
步骤3:训练跨模态对齐模型(基于对比学习)
# 假设已获取文字和图像的特征(维度256)
text_features = torch.randn(10, 256) # 10个文字样本的特征
image_features = torch.randn(10, 256) # 10个图像样本的特征(与文字样本一一对应)
# 计算对比损失(同前)
tau = 0.1
sim = torch.matmul(text_features, image_features.T) / tau # 相似度矩阵
labels = torch.arange(10) # 正例标签(第i个文字对应第i个图像)
loss = F.cross_entropy(sim, labels) # 交叉熵损失(等价于对比损失)
# 优化模型参数...
步骤4:知识引导生成(用LangChain拼接提示)
from langchain.prompts import PromptTemplate
# 从知识图谱中查询“故宫”的知识
def get_knowledge(entity="故宫"):
# 假设查询到知识为:位置、建筑特点、所属朝代
return {
"位置": "北京中轴线中心",
"建筑特点": ["红墙黄瓦", "庑殿顶屋顶", "雕梁画栋"],
"所属朝代": "明清两代"
}
# 构建提示模板
prompt_template = PromptTemplate(
input_variables=["knowledge"],
template="已知知识:故宫位于{knowledge['位置']},建筑特点包括{knowledge['建筑特点']},是{knowledge['所属朝代']}的皇家宫殿。\n任务:用生动的语言描述故宫的建筑特色。"
)
# 生成提示并调用大模型(如LLaMA)
knowledge = get_knowledge()
prompt = prompt_template.format(knowledge=knowledge)
response = llm(prompt) # llm是加载的大模型实例
print(response)
# 输出示例:"故宫坐落在北京中轴线的中心,红墙在阳光下泛着温暖的光泽,黄瓦屋顶如鎏金般璀璨,庑殿顶的曲线优雅舒展,仿佛在诉说明清两代的皇家气象..."
代码解读与分析
- 实体提取:通过命名实体识别(NER)和目标检测(YOLO)从文字、图像中提取关键实体,是知识图谱构建的“原材料收集”;
- 知识图谱构建:用DGL库将实体和关系组织成图结构,便于后续查询和推理;
- 跨模态对齐:通过对比学习让文字和图像的特征“对齐”,确保模型能关联多模态信息;
- 知识引导生成:用LangChain将知识图谱的信息融入提示,指导大模型生成更准确的内容。
实际应用场景
场景1:智能导游——生成更准确的景点讲解
传统AIGC生成的讲解可能遗漏“故宫屋顶是黄瓦”等细节,而结合知识图谱后,模型能自动调取“故宫→建筑特点→黄瓦”的知识,生成:“您眼前的太和殿采用黄琉璃瓦庑殿顶,这是古代建筑中等级最高的屋顶形式,象征皇家的尊贵。”
场景2:教育内容生成——避免“知识错误”
在生成“中国古代建筑”课程内容时,模型会先查询知识图谱确认“故宫是明清宫殿”“天坛是祭天场所”,避免出现“故宫是唐朝建造”的错误。
场景3:多模态广告生成——图文内容更一致
品牌要求“生成一张咖啡广告图+文案”,知识图谱可提供“咖啡→产地→巴西”“咖啡→特点→浓郁”“咖啡→搭配→甜点”等知识,确保图片(巴西咖啡豆、咖啡杯+甜点)和文案(“源自巴西的浓郁咖啡,配一块甜美的马卡龙”)高度一致。
工具和资源推荐
- 多模态大模型:Hugging Face Transformers(支持CLIP、BLIP等模型)、OpenAI API(GPT-4V)
- 知识图谱工具:DGL(图神经网络)、Neo4j(图数据库)、OWL(本体语言,用于知识建模)
- 跨模态对齐库:CLIP(OpenAI的跨模态模型)、ALBEF(多模态预训练模型)
- 数据集:Conceptual Captions(图文对)、Wikidata(通用知识图谱)、VizWiz(视觉问答数据集)
未来发展趋势与挑战
趋势1:动态知识图谱——让知识“实时更新”
当前知识图谱多为静态(如“故宫建成于1420年”),未来需支持动态更新(如“故宫今日开放时间”),结合实时数据(如新闻、社交媒体)让AI生成“时效性内容”。
趋势2:跨模态推理——从“记忆”到“思考”
未来多模态大模型+知识图谱不仅要“记住知识”,还要能“推理新知识”。例如,通过“故宫→位于→北京”“北京→属于→中国”推理出“故宫→位于→中国”。
挑战1:知识冲突解决
不同模态数据可能提供矛盾知识(如文字说“猫有尾巴”,某张图片的猫因受伤没尾巴),如何让模型判断“普遍知识”和“特殊案例”是关键。
挑战2:隐私与安全
知识图谱可能包含敏感信息(如用户位置、偏好),需设计“隐私保护的知识融合”方法,避免信息泄露。
总结:学到了什么?
核心概念回顾
- 多模态大模型:能处理文字、图像等多类信息的“全能助手”,但可能记不清细节;
- 知识图谱:知识的“导航地图”,用“实体-关系”网络存储结构化知识;
- 跨模态对齐:让多模态信息与知识图谱“对上号”的“翻译器”。
概念关系回顾
多模态大模型像“信息处理员”,知识图谱像“知识库”,跨模态对齐像“翻译器”。三者协作后,AI生成的内容更准确、更有逻辑,就像侦探有了万能相机和破案手册,能快速锁定真相。
思考题:动动小脑筋
- 如果你要为“宠物狗”构建多模态知识图谱,需要收集哪些类型的数据(文字、图像、视频等)?可以定义哪些实体和关系?
- 假设AI生成了“猫有五条腿”的错误内容,如何通过知识图谱+跨模态对齐来纠正这个错误?
- 想象一个应用场景(如医疗咨询、游戏剧情生成),你会如何设计“多模态大模型+知识图谱”的解决方案?
附录:常见问题与解答
Q:知识图谱和数据库有什么区别?
A:数据库(如Excel表格)存储的是“行-列”结构的数据(如姓名、年龄、地址),而知识图谱存储的是“实体-关系-实体”的网络(如“小明→朋友→小红”“小红→喜欢→猫”),更擅长表示复杂的关联知识。
Q:多模态大模型必须用知识图谱吗?
A:不是必须,但知识图谱能显著提升生成内容的准确性和逻辑性。例如,生成“化学实验步骤”时,知识图谱可以确保“盐酸不能和金属钠直接混合”等关键知识不被遗漏。
Q:构建知识图谱需要很多数据吗?
A:取决于应用场景。通用知识图谱(如涵盖所有领域)需要海量数据,而垂直领域(如“故宫知识”)可以手动构建小规模图谱,再逐步扩展。
扩展阅读 & 参考资料
- 《多模态机器学习:算法与应用》(王飞跃等著)
- 《知识图谱:方法、实践与应用》(邵浩等著)
- 论文:《CLIP: Connecting Text and Images》(OpenAI)
- 论文:《Knowledge Graph Embedding: A Survey》(王厚峰等)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)