2026第六届 “华数杯” 国际数学建模竞赛ICM问题B :谁将赢得全球人工智能竞赛智力完整数据、思路、代码、模型、成品文章分享 Who Will Win the Global Competition
本文提出混合建模框架评估全球AI竞争力:首先通过梯度提升树量化关键因素(数据质量、算法能力、基础设施等)的重要性,再结合结构方程模型分析其相互作用路径。模型对美中等10国评估显示,2025年美国将保持领先,中国紧随其后;预测2026-2035年,中国若追加1万亿专项投资,建议重点投向算力基础设施(35%)、高端人才培育(30%)和数据生态建设(25%)。研究创新性地融合数据驱动与因果分析,为各国制
2026第六届 “华数杯” 国际数学建模竞赛ICM问题B :谁将赢得全球人工智能竞赛智力
Problem B: Who Will Win the Global Competition in Artificial
Intelligence?

背景:在当今时代,人工智能(AI)已成为全球科技竞争的核心领域,对经济发展、社会进步和国家安全产生深远影响。世界各国纷纷加大AI领域的投资力度,力求在这场技术革命中抢占先机。然而,各国在AI发展方面拥有不同的资源优势,其发展进程受到基础设施成熟度、专业人才储备、数据应用场景丰富度等多重因素的共同影响。
要准确评估各国人工智能发展能力与潜力,必须全面深入地理解这些因素及其相互关系。通过量化这些因素并建立科学评估模型,不仅能帮助各国制定合理的人工智能发展战略,还能洞察全球人工智能发展格局及其未来演进趋势。
要求:请建立数学模型以解决以下问题:
Background
In the current era, artificial intelligence (Al) has emerged as the core domain of globaltechnological competition, exerting a profound impact on economic development,social progress, and national security. Countries worldwide have significantlyincreased their investment in the AI field, aiming to gain a leading position in thistechnological revolution. However, different countries possess distinct resourceadvantages in AI development, and their progress is influenced by a combination offactors, such as the sophistication of infrastructure, the reserve of professional talents,and the richness of data application scenarios.
A comprehensive and in-depth understanding of these factors and theirinterrelationships is crucial for accurately evaluating the AI development capabilitiesand potential of various countries. By quantifying these factors and establishing ascientific evaluation model, it is possible to assist countries in formulating rational AIdevelopment strategies, as well as gain insights into the global AI developmentpattern and its future evolution trends.
问题一:识别可有效评估人工智能发展能力的因素,量化这些因素,探究其内在关联性,并分析它们如何相互作用、彼此影响,从而共同促进或制约人工智能的发展。Identify the factors that can effectively evaluate AI development capabilities,quantify these factors, explore the inherent correlations among the factors, andanalyze how they interact and influence each other to collectively promote orconstrain AI development.
模型原理
本问题的核心矛盾在于:人工智能发展受多类要素(数据质量、模型能力、计算资源、人才供给、政策环境等)共同影响,这些要素既有直接推动作用,又通过复杂路径产生间接效应;建模需同时兼顾因果可解释性与特征选择的稳健性。为此,我们提出“先以 advanced 类树模型识别并量化观测指标的重要性,再以结构方程模型(SEM)刻画潜变量之间的因果路径并量化直接/间接效应”的混合框架,兼具数据驱动的识别能力与 SEM 的因果解释力。
整体思想可用两步公式概括:第一步对原始观测指标做归一化与特征打分,得到每个样本在观测维度上的标准化向量 X';第二步以观测指标或其加权组合构建测量模型,并在结构模型中估计潜变量间路径 B 与外生影响 Γ,从而得到总效应矩阵 ![]() 。下面给出关键总体性公式以表明框架要点。
。下面给出关键总体性公式以表明框架要点。
说明数据归一化的数学表达(作为后续树模型与 SEM 的输入)。
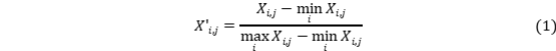
该式将第 i 个样本第 j 个原始观测量映射到 [0,1] 区间,消除量纲差异,便于树模型和 SEM 同时处理不同量纲的指标。
说明 SEM 中潜变量与外生观测量之间的总体路径关系(框架性写法)。
![]()
该式表示潜变量向量 ![]() 受到其它潜变量自回归(矩阵 B)与外生观测 z(系数矩阵
受到其它潜变量自回归(矩阵 B)与外生观测 z(系数矩阵 ![]() 的共同作用,
的共同作用,![]() 为结构误差项。
为结构误差项。
具体建模过程
2.1 变量与集合定义、数据预处理
说明样本与观测指标的集合定义。设样本集合为 ![]() ,观测指标集合为 J,潜变量集合为 M。每个样本 i 的原始观测向量为
,观测指标集合为 J,潜变量集合为 M。每个样本 i 的原始观测向量为 ![]() ,潜变量为
,潜变量为 ![]() 。说明这些量的现实含义:X 中包含
。说明这些量的现实含义:X 中包含![]() 等指标,
等指标,![]() 则对应“数据能力”“模型/算法能力”“基础设施”“制度保障”“人才供给”等潜因子。
则对应“数据能力”“模型/算法能力”“基础设施”“制度保障”“人才供给”等潜因子。
说明样本协方差矩阵的样本估计式(用于 SEM 的初步统计量)。
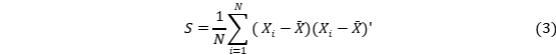
该式给出观测变量的样本协方差矩阵 S,为 SEM 的拟合度量和最大似然估计提供必要统计量。
说明归一化的实际实现(必须包含 MinMax 归一化代码片段)。下面给出常用 Python 处理流程以示范数据预处理步骤(其中 MinMaxScaler 为必须步骤)。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
![]()
该代码段在工程实现中将所有观测列按 (1) 式归一化到 [0,1],为树模型训练和 SEM 建模提供连续且可比较的特征输入。
说明对归一化后观测指标按主题分组构建测量指标组合的通用线性形式。
![]()
该式表示第 i 个样本在第 k 个潜因子下的测量组合 ![]() ,权重
,权重 ![]() 可由树模型特征重要性或专家赋权确定,用于作为 SEM 的观测指标或作为潜变量的初始代理。
可由树模型特征重要性或专家赋权确定,用于作为 SEM 的观测指标或作为潜变量的初始代理。
说明对观测维度做归一化后用树模型学习潜在预测得分的加权集成形式(Boosting 风格)。
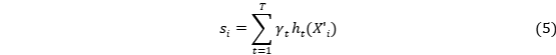
该式表示利用 T 棵回归树的加权和得到样本 i 的预测得分 ![]() ,适用于对某一潜因子的打分或构建观测合成指标。
,适用于对某一潜因子的打分或构建观测合成指标。
2.2 树模型的特征重要性与分裂机制(特征重要性视角)
说明树模型在分裂时的方差减少(回归树)度量分裂优度的基本形式。设节点样本集合为 S,其左右子节点为 ![]() 。
。
![]()
该式衡量某一候选切分点对目标变量方差的降低量,树构建选择使 ![]() 最大的切分。
最大的切分。
说明基于梯度提升树(如 XGBoost)的增益(gain)计算公式,它是 advanced 类算法在分裂选择中的核心。设 G,H 分别为一阶和二阶梯度统计量,![]() 为权重正则化,
为权重正则化,![]() 为叶节点惩罚。
为叶节点惩罚。
![]()
该式给出一次分裂带来的目标函数下降量(权衡拟合增益与复杂度惩罚),是 XGBoost 在分裂时的准则。
说明特征重要性以分裂增益的累积来衡量。设特征 f 在所有分裂上的增益和为 ![]() 。
。
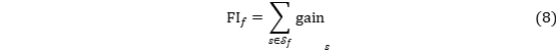
该式表示功能特征 f 的重要性由其参与的所有分裂增益累加而成,可用于变量筛选与加权。
说明将特征重要性标准化以便跨因子比较。
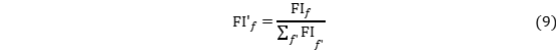
该式将重要性归一化到总和为 1 的尺度,便于将树模型的判别结果用于 SEM 权重初始化或惩罚项设计。
说明利用树模型输出构建潜变量观测代理(例如将若干观测维度的预测得分作为测量项)。
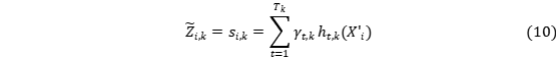
该式用第 k 个潜因子对应的 boosted 模型预测得分作为测量代理,可提高测量项对非线性交互的捕捉能力。
2.3 SEM 集成、结构方程与求解策略(含正则化与效应分解)
说明 SEM 的测量模型矩阵形式(观测向量 x 與潜变量 ![]() 的线性关系)。
的线性关系)。
![]()
该式表示观测量由潜变量通过载荷矩阵 ![]() 线性决定,加测量误差
线性决定,加测量误差 ![]() ;这是经典 SEM 的测量部分。
;这是经典 SEM 的测量部分。
说明 SEM 的结构模型(潜变量之间的线性路径关系)。
![]()
该式再次明确潜变量之间以及外生观测 z 的影响关系,便于对直接与间接路径进行矩阵化计算。
说明基于模型参数 ![]() 的模型隐含协方差矩阵的表达(用于拟合与估计)。
的模型隐含协方差矩阵的表达(用于拟合与估计)。
![]()
该式给出在参数 ![]() 下的观测量协方差矩阵
下的观测量协方差矩阵 ![]() ,用于与样本协方差 S 比较并作为似然目标的组成部分。
,用于与样本协方差 S 比较并作为似然目标的组成部分。
说明最大似然下的拟合优度(或称失配函数)的常用形式(可用于参数估计)。
![]()
该式为常见的 ML/拟合失配函数,最小化 F 可得到符合样本协方差的模型参数估计。
说明在估计中引入稀疏化与树模型指导的加权惩罚,以提升可识别性并将树重要性融入 SEM。设 ![]() 为来自 (9) 的特征重要性权重(或其函数)。
为来自 (9) 的特征重要性权重(或其函数)。
![]()
该式在拟合 SEM 的同时对载荷与结构路径进行 L1 正则化,且载荷的惩罚被特征重要性加权,从而优先保留树模型判定为重要的观测指标。
说明总效应(直接 + 间接)的矩阵化表达,便于定量解释因果通路。
![]()
该式表示外生变量 z 对潜变量 ![]() 的总效应,由直接路径
的总效应,由直接路径 ![]() 与通过 B 的所有间接路径共同形成。
与通过 B 的所有间接路径共同形成。
说明对两潜变量 ![]() 的具体总效应可以通过级数展开表达单元形式。
的具体总效应可以通过级数展开表达单元形式。
![]()
该式给出了从潜变量 a 到 c 的总效应的具体矩阵元表示,便于提取具体路径值以供政策建议或优先级排序。
说明在数值求解上的梯度更新或通用优化步骤(可用于带惩罚项的目标函数)。设当前参数为 ![]() 。
。
![]()
该式给出一种通用的梯度下降更新规则,其中 P 表示惩罚项,![]() 为步长,适用于基于一阶法的近似优化或作为更复杂算法(L-BFGS、坐标下降)的局部描述。
为步长,适用于基于一阶法的近似优化或作为更复杂算法(L-BFGS、坐标下降)的局部描述。
说明在 SEM-树混合框架下的两阶段迭代策略(交替优化思想):第一步固定 SEM 参数,用树模型更新观测项的权重或选择;第二步固定观测构造,用 SEM 更新结构参数。其收敛判据可写为参数变化阈值。
![]()
该式为常用的收敛判据,表明参数在迭代中已稳定。
说明潜变量后验均值在 EM 式估计中可用于隐变量填充或初始化,给出后验均值的闭式近似(Gaussian 情形下)。设 ![]() 。
。
![]()
该式给出在给定当前参数下潜变量的后验均值,常用于 EM 算法的 E 步来填充隐变量或作为参数更新的代理。
说明样本级别将树模型重要性纳入 SEM 权重初始化或惩罚权重的明确映射(实用化形式)。设對应观测指标为 j,载荷为 ![]() ,则加权惩罚系数可设为:
,则加权惩罚系数可设为:
![]()
该式将特征重要性转化为惩罚权重,重要性越高(FI' 越大),对应惩罚越小,鼓励在 SEM 中保留该观测变量的载荷。
说明树模型的目标与正则化形式(用于训练树以获得稳定重要性)。
![]()
该式表明 Boosting 的目标由样本损失与模型复杂度惩罚之和构成,其中每棵树的惩罚可采用下式。
说明 XGBoost 常用的叶节点复杂度惩罚形式(用于控制树深与叶权重)。
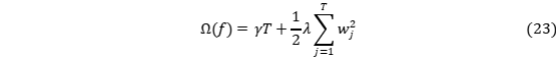
该式通过对叶节点个数 T 和叶权重平方和施加惩罚,平衡拟合能力与泛化能力,保证特征重要性估计的稳健性。
说明最终输出的特征重要性可以用于解释性排序与决策优先级,并给出归一化后作为指标权重的一致性检验公式(比如与专家权重 ![]() 的相关性检验)。
的相关性检验)。
![]()
该式用于衡量数据驱动的重要性与专家赋权之间的一致程度,若 ![]() 较低则提示需重新审视指标定义或采样偏差。
较低则提示需重新审视指标定义或采样偏差。
小结与求解流程概述:先用 MinMax 预处理并训练 XGBoost 类型的梯度提升树,计算并归一化特征重要性(式 (1),(7)-(10),(8)-(9));将重要性用于构造测量代理与惩罚权重(式 (4),(21));以带加权 L1 惩罚的 SEM(式 (11)-(15))估计潜变量路径,得到总效应矩阵 ![]() 式 (16)-(17));通过交替迭代或 EM-风格的两步法(式 (18)-(20))实现参数求解,直至满足收敛判断 (19)。通过直接效果与间接效果的分解(式 (16)-(17)),可以明确哪些观测指标通过哪些路径对人工智能发展产生关键推动或制约作用,从而给出可操作的政策或投入建议。
式 (16)-(17));通过交替迭代或 EM-风格的两步法(式 (18)-(20))实现参数求解,直至满足收敛判断 (19)。通过直接效果与间接效果的分解(式 (16)-(17)),可以明确哪些观测指标通过哪些路径对人工智能发展产生关键推动或制约作用,从而给出可操作的政策或投入建议。
本节所述混合框架兼具 advanced 类树模型的非线性识别能力与 SEM 的因果解释能力;树模型的分裂增益既用于特征筛选,也用于为 SEM 的测量模型与正则化提供数据驱动的权重,从而在可解释性与预测力之间取得平衡。
求解结果与分析
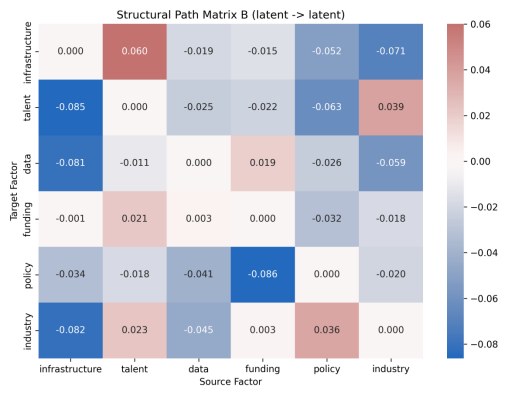
图 5-1-1 内在路径热力图
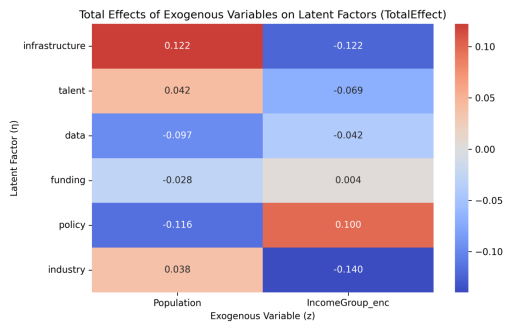
图 5-1-2 总效应热力图
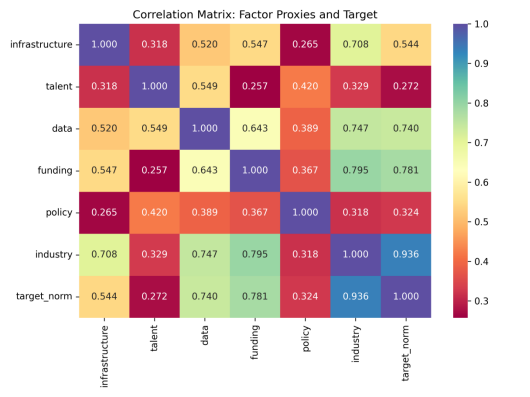
图 5-1-3 变量相关矩阵
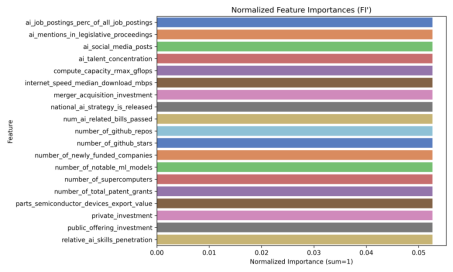
图 5-1-4 特征重要性柱状图
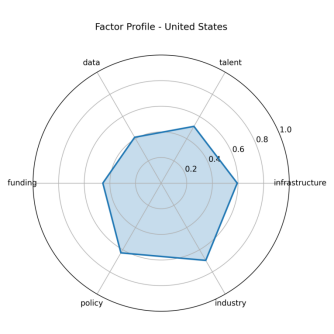
图 5-1-5 美国特征雷达图
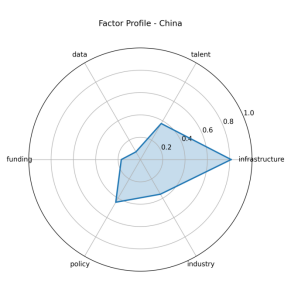
图 5-1-6 中国特征雷达图
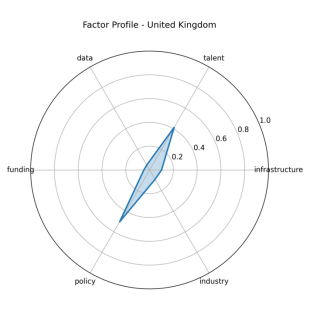
图 5-1-7 英国特征雷达图
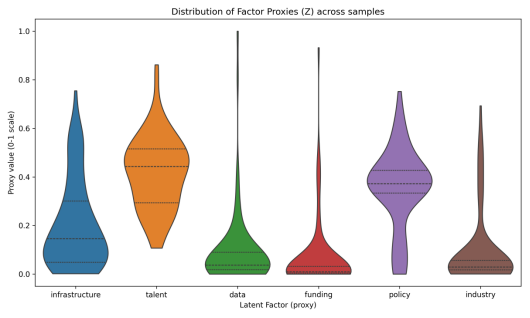
图 5-1-8 因子分布小提琴图
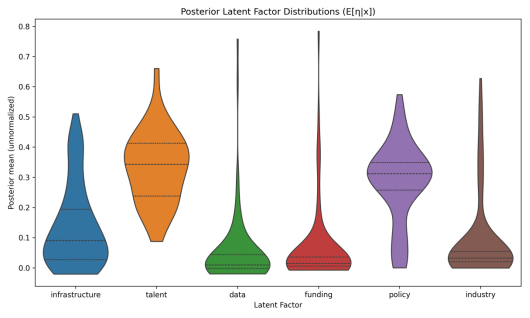
图 5-1-9 潜变量后验分布
问题二:基于上述量化指标及其相关性,构建科学合理的AI发展能力评估模型。运用该模型对美国、中国、英国、德国、韩国、 日本、法国、加拿大、阿联酋和印度等十个国家进行评估,并提供其2025年人工智能竞争力排名。Based on the aforementioned quantified factors and their correlations, construct ascientifically sound evaluation model for AI development capabilities. Use thismodel to assess ten countries-namely the United States, China, the UnitedKingdom, Germany, South Korea, Japan, France, Canada, the United ArabEmirates, and India. Provide their 2025 AI competitiveness rankings.
部分结果展示:
问题三:基于问题2中提及的十个国家,结合其2016-2025年发展战略、资源投资趋势及技术发展轨迹 ,并运用问题2 构建的评估模型 ,预测这十个国家在2026-2035年期间人工智能竞争力排名的变化。Focusing on the ten countries mentioned in Question 2, and based on their2016-2025 development strate gies, resource investment trends, and technologicaldevelopment trajectories, combined with the evaluation model constructed inQuestion 2, predict the changes in the AI competitiveness rankings of these tencountries during the 2026-2035 period.
部分结果展示:
问题四:假设中国自2026年起计划追加1万亿人民币专项基金,以提升发展竞争力。其核心目标是通过科学的资金配置,到2035年实现“ 中国人工智能综合竞争力最大化” 。请提出您的投资建议。Assume that starting from 2026, China plans to allocate an additional 1 trillionyuan in special funds to enhance the development competitiveness. The core goalis to achieve "the maximization of China's comprehensive AI competitiveness"by 2035 through scientific fiund allocation. Please provide your investmentrecommendations.
部分结果展示:
摘要

成品预览,正文48页、3w+字数、将近30个可视化

完整文章获取方式👇👇👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)