《从 “胡言乱语” 到 “有理有据”:RAG 如何拯救大模型的致命缺陷》
摘要:RAG(检索增强生成)技术通过"开卷考试"模式解决大模型的时效性和幻觉问题。其核心流程分为三阶段:1)索引阶段将文档切片并向量化存储;2)检索阶段计算用户问题与文档片段的相似度;3)生成阶段结合检索结果输出答案。RAG具有四大优势:避免幻觉、保持时效性、保护数据隐私、确保答案可溯源。该技术作为用户与大模型间的中间层,通过检索外部知识库增强提示词,约束模型仅基于最新资料作答
引言
“你是不是也遇到过这种情况:问大模型一个时效性问题,它要么说‘不知道’,要么一本正经地给你编答案?
这不是模型‘笨’,而是它天生的‘闭卷考试’模式在作祟。今天要聊的 RAG(检索增强生成),就是给大模型开的‘开卷考试’外挂。它让模型在回答前先去‘翻书’—— 从你的知识库、最新文档里找答案,彻底告别‘幻觉’,让输出既精准又有时效性。
我会用一个极简的向量相似度计算例子,带你看懂 RAG 的完整流程:从文档切片、向量化存储,到检索相似片段,再到生成最终回答。看完你就明白,为什么现在做企业级大模型应用,RAG 已经成了标配。”
RAG 的核心思想可以比喻为:从“闭卷考试”变为“开卷考试”。
-
传统 LLM(没有 RAG):就像学生在闭卷考试,只能凭记忆(训练数据)回答。如果问它训练截止日期之后发生的事(如图片中 Sam Altman 被解雇又复职的“宫斗”大戏),它会回答“我不知道”或胡编乱造(幻觉)。
-
RAG(有 RAG):就像允许学生带书进考场。当遇到不会的问题,先去翻书(检索相关文档),把找到的答案抄在草稿纸上(构建 Prompt),最后结合题目和查到的资料写出答案。
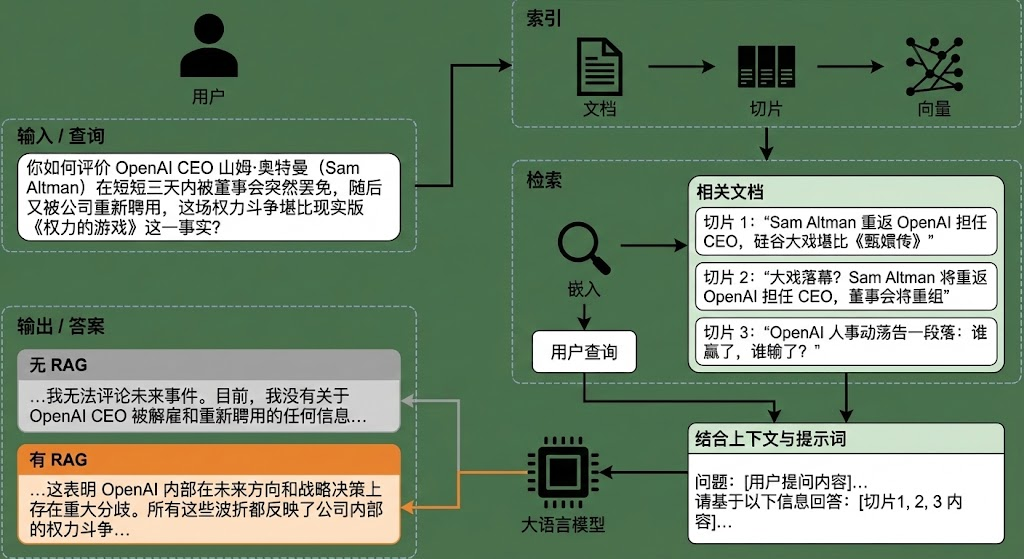
一、RAG定义与逻辑理解
图片清晰地展示了 RAG 的三个核心阶段:索引 (Indexing)、检索 (Retrieval) 和 生成 (Generation)。
Phase 1: 索引 (Indexing) —— 准备“教科书”
-
对应图片右上角:
-
Documents (文档): 也就是外部知识库(例如公司私有数据、最新的新闻)。
-
Chunks (切片): 长文档直接处理太慢且超出模型窗口,所以被切分成小的文本块(Chunk 1, Chunk 2...)。
-
Vectors/Embeddings (向量化): 计算机读不懂文字,只懂数字。系统通过 Embedding 模型将这些文本块转化为高维向量,存入向量数据库。
-
逻辑: 把知识变成计算机可快速查找的数学形式。
-
Phase 2: 检索 (Retrieval) —— “翻书找答案”
-
对应图片中间:
-
User Query: 用户提问“How do you evaluate...”。
-
系统将用户的 Query 也转换成向量。
-
系统在向量数据库中计算“Query 向量”与“文档 Chunk 向量”的相似度。
-
Relevant Documents: 找出最相似的那几个 Chunk(如图中的 Chunk 1, Chunk 2, Chunk 3)。
-
Phase 3: 生成 (Generation) —— “结合资料答题”
-
对应图片下方:
-
Combine Context: 系统将 用户的原始问题 + 检索到的 Chunk 拼接在一起,形成一个新的 Prompt(提示词)。
-
Prompt 结构通常是:“请根据以下背景资料:[Chunk 1, Chunk 2...],回答问题:[User Question]”。
-
-
LLM: 大模型接收到这个包含了答案线索的 Prompt。
-
Answer: 模型输出准确答案(如图中“With RAG”部分,能够详细解释 Sam Altman 事件)。
-
二、举例数值计算RAG
在“检索”这一步,计算机是如何知道哪段文字是相关的?它依靠的是 向量相似度计算(Vector Similarity),最常用的是 余弦相似度 (Cosine Similarity)。
假设我们的 Embedding 模型很简单,只有 2 个维度(实际通常是 768 或 1536 维),分别代表 [科技相关度, 烹饪相关度]。

三、RAG 有什么意义?
一共有四个突出的意义,分别是:解决幻觉、时效性、数据隐私、可溯源性。
结合图片左下角的对比(Without RAG vs With RAG):
-
解决幻觉 (Hallucination):
-
大模型在不知道答案时喜欢一本正经地胡说八道。RAG 强制模型基于提供的事实(Ground Truth)回答,大大降低了胡编的概率。
-
-
时效性 (Freshness):
-
训练一个大模型需要几个月和巨额资金,数据永远是滞后的(Knowledge Cutoff)。
-
图片证据:在“Without RAG”框中,模型说 "Currently, I do not have any information regarding the dismissal..."。而 RAG 允许你只需更新数据库(只需几秒钟),模型就能立刻回答昨天发生的新闻。
-
-
数据隐私 (Privacy):
-
企业不希望把私有数据(如财务报表)上传去训练公有模型。RAG 允许数据留在本地数据库,只在回答时临时调用,相对更安全。
-
-
可溯源 (Citability):
-
RAG 可以明确告诉你:“这个答案是参考了文档 X 的第 Y 页生成的”,方便人工核查。
-
四、RAG在整个流程中该步骤处于什么位置,作用是什么?
位置: RAG 处于 用户 (User) 和 大模型 (LLM) 之间。它是一个 中间层 或 预处理层。
流程简图:

具体作用:
-
拦截: 拦截用户的原始提问。
-
增强 (Augment): 这是 RAG 中 "A" 的含义。它不做最终的生成,而是负责 寻找外援。它将原始问题从一个干瘪的句子,变成了一个包含丰富背景信息的 Prompt。
-
约束: 它实际上是在对大模型说:“不要用你以前训练的那些旧知识或乱猜,只根据我刚才查到的这些资料来回答这个问题。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)