揭秘注意力机制:AI如何像人脑一样聚焦
摘要:注意力机制模仿人脑认知过程,通过动态分配计算资源聚焦关键信息。其核心是查询(query)、键(key)和值(value)的交互:查询代表当前关注点,键作为信息标识,值存储实际内容。文章介绍了Nadaraya-Watson核回归等注意力汇聚方法,通过实验对比了平均汇聚、非参数和带参数注意力汇聚的效果。结果表明,带参数注意力机制能更好地捕捉数据特征,其权重分布可视化提供了模型解释性。注意力机制突
1.引例:人脑的注意力
当你在阅读一段复杂的文章时,你的目光以及思维重点不会平均分配到每一个字,而是会:
- 聚焦在关键词语和句子上;
- 忽略或减弱对不重要的词的投入;
- 根据上下文,动态的调整关注点,比如看到某个指示代词,你会回溯前文寻找指代的内容。
注意力机制就是根据这一认知过程的数学模型:让模型在处理信息时,有选择的分配计算资源到最重要的部分。
2.核心:动态权重与上下文聚焦
传统神经网络(例如RNN)在处理序列时,通常将整个序列压缩为固定长度的词向量,这会导致信息瓶颈;长序列中靠前的信息容易被遗忘。
注意力机制的核心突破:允许模型在生成输出的每一步,都能直接回顾并聚焦于输入序列中的所有位置信息,并为这些信息分配不同的权重。
- 动态:权重不是固定的,根据当前的查询动态计算;
- 可解释:生成的权重分布图能直观展示模型“在看哪里”。
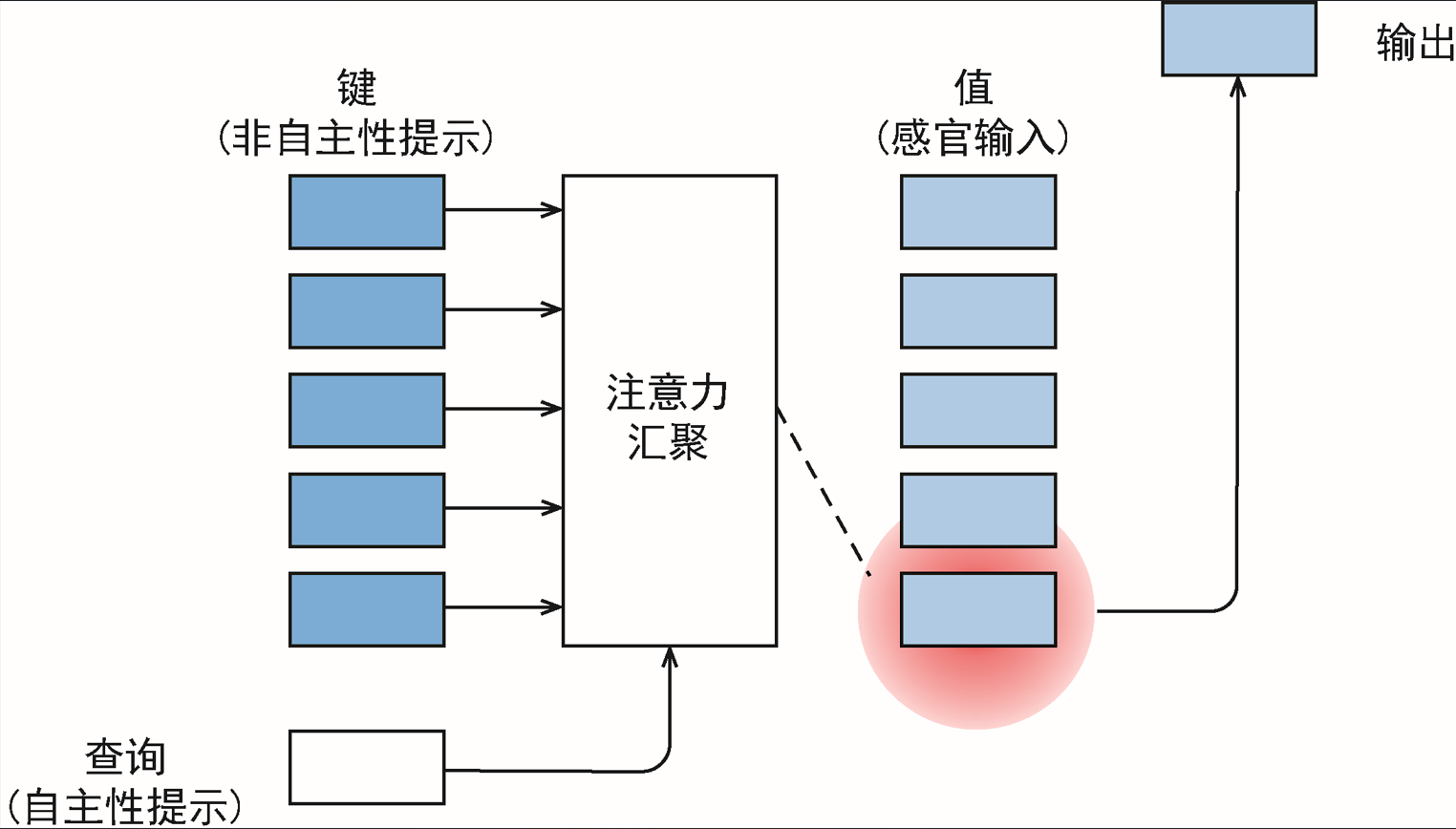
3.查询、键和值
自主性的与非自主性的注意力提示解释了人类的注意力方式:
-
非自主性提示: 指那些不依赖于主观意志、自动地吸引我们注意力的线索。它是自下而上、数据驱动、刺激驱动的。
-
自主性提示: 指那些依赖于我们的目标、意图和任务而主动发出的注意线索。它是自上而下、目标驱动的。
卷积层、全连接层、池化层都只考虑非自主性提示。
注意力机制则显示的考虑自主性提示,在其背景下:
- 自主性提示被称为查询(query)。他代表“我当前正在关注什么”。
- 感官输入被称为值(value)。他代表信息库中每个元素“实际包含的信息内容”。
- 感官输入的非自主性提示被称为键(key)。他代表信息库中每个元素的“身份标识”。
4.注意力汇聚
给定数据集 ,i=1,....n
4.1 平均汇聚
平均汇聚是最简单的方案,忽略了输入 ,基于所有训练样本输出值的平均值:
通常效果一般,真实函数与预测函数相差较大。
4.2 Nadaraya-Watson 核回归
这是最为经典的非参注意力池化形式,对于一个查询点 x,其预测值为:
其中,是键 key,
是值 value,K是核 kernel(衡量相似度或距离,它非负且对称),核常考虑高斯核:
Nadaraya-Watson 核回归具有一致性的优点:如果数据足够多,该模型会收敛到最优结果。
4.3 带参数注意力汇聚
将查询 x 和键之间的距离乘以可学习参数 w:
4.4 模型训练
(1)导入相关库
import torch
from torch import nn
from d2l import torch as d2l(2)生成数据集
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本
def f(x):
return 2 * torch.sin(x) + x ** 0.8 # 真实函数
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出(增加高斯噪声)
x_test = torch.arange(0, 5, 0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出
n_test = len(x_test) # 测试样本数
n_test(3)绘制训练样本图
样本由圆圈表示,Truth表示不带噪声项的真实数据生成函数;Pred表示学习得到的预测函数。
def plot_kernel_reg(y_hat):
d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],
xlim=[0, 5], ylim=[-1, 5])
d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);(4)平均汇聚结果
# 平均汇聚
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)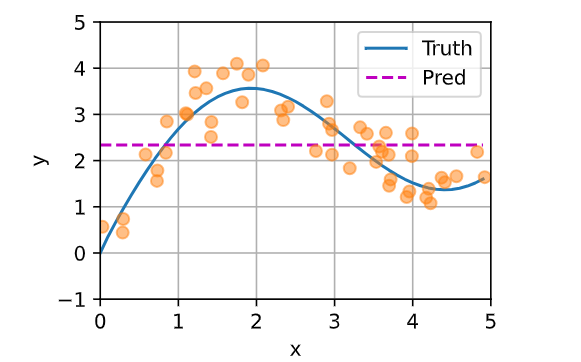
可以看到真实函数 f(Truth) 与预测函数 (Pred) 相差很大。
(5)非参数注意力汇聚
# 非参数注意力汇聚
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)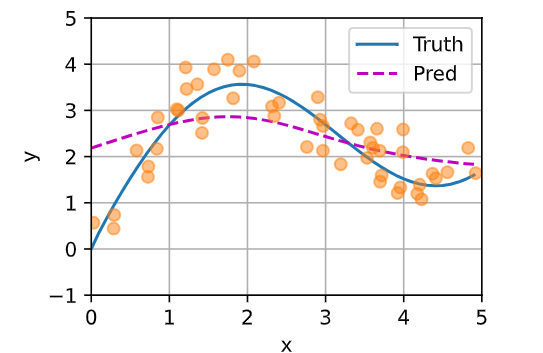
模型预测线相较于平均汇聚更加平滑,并且比平均汇聚的预测接近真实情况。
(6)带参数注意力汇聚
# 模型定义
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries和attention_weights的形状为(查询个数,“键-值”对个数)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)keys = x_train.repeat((n_test, 1))
values = y_train.repeat((n_test, 1))
y_hat = net(x_test, keys, values).unsqueeze(1).detach()
plot_kernel_reg(y_hat)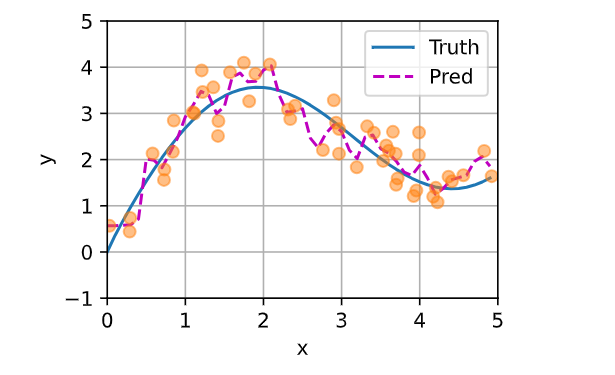
带参数的模型加入可学习的参数后,曲线在注意力权重较大的区域变得不平滑。
5.小结
- Nadaraya-Watson 核回归的注意力汇聚是对训练数据输出的加权平均,分配给每个值的注意力权重取决于将值所对应的键和查询作为输入的函数。
- 注意力汇聚可以分为非参数型和带参数型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)