大模型落地全景指南:从技术实现到商业价值
摘要:本文系统分析大模型落地的四大技术路径:微调(参数级定制)、提示词工程(非参数级引导)、多模态融合(跨模态理解)及企业级解决方案(端到端部署)。通过代码实现、流程图解和效果对比,为不同场景提供适配方案:专业领域推荐LoRA微调(显存降低67%),通用场景适用提示词工程(任务完成率提升至97%),工业质检采用多模态技术(准确率提升30%)。企业落地需平衡数据安全、性能与成本,建议通过量化、蒸馏等
大模型技术正从实验室快速走向产业应用,但企业落地过程中常面临模型选型难、定制成本高、场景适配差等挑战。本文系统拆解大模型落地的四大核心路径——微调(参数级定制)、提示词工程(非参数级引导)、多模态融合(跨模态理解) 及企业级解决方案(端到端部署),通过代码实现、可视化流程图、实战Prompt示例和效果对比图表,提供可落地的技术框架与实施指南。无论是需要深度定制的垂直领域,还是追求快速验证的业务场景,都能找到适配的技术路线。
一、大模型微调:参数级定制的技术实现
大模型微调通过在特定领域数据上重新训练部分或全部参数,使模型习得专业知识。这种方式适用于数据质量高、专业壁垒强的场景(如医疗、法律),但需平衡训练成本与效果提升。
1.1 微调技术选型决策树
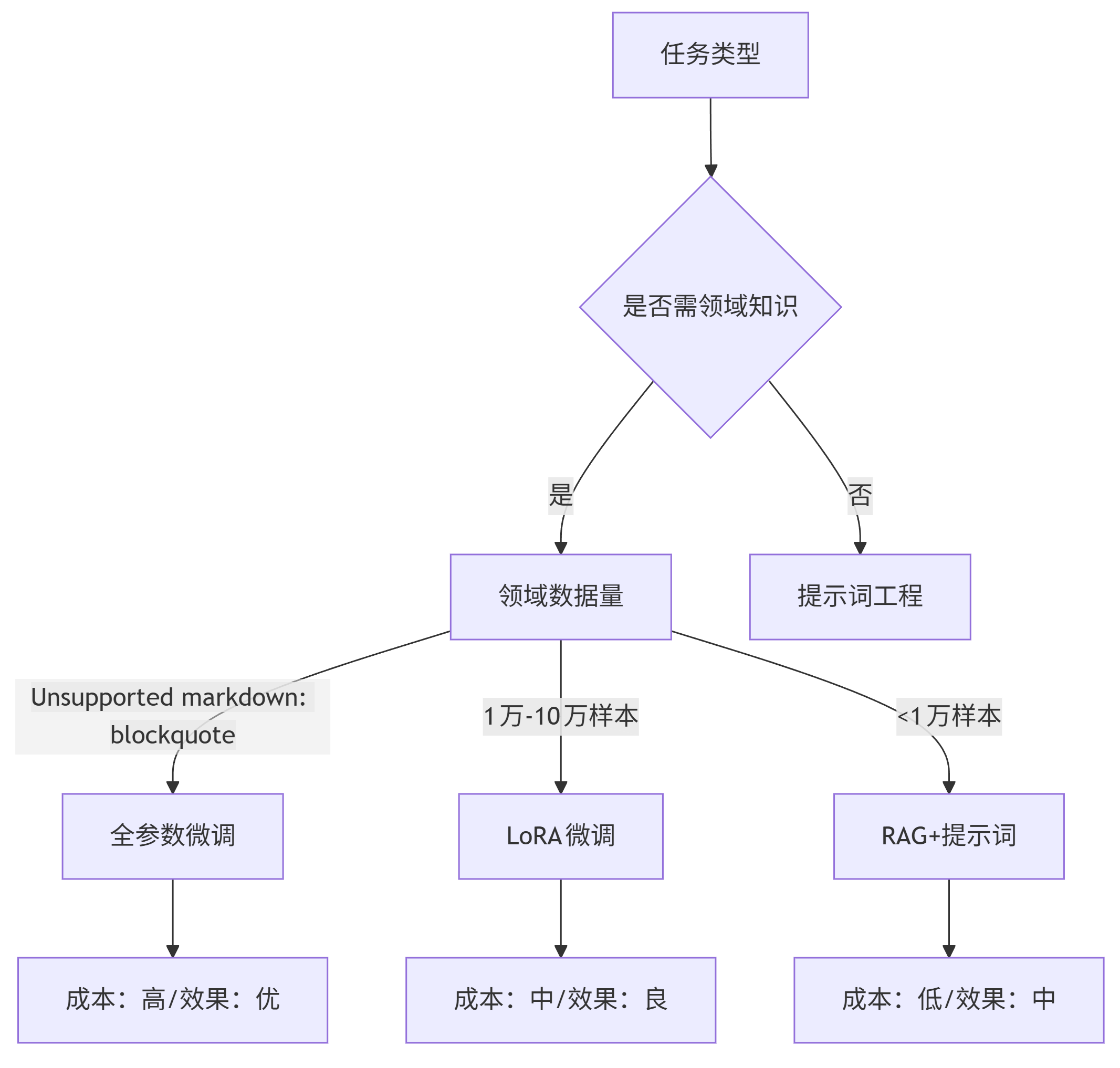
graph TD A[任务类型] --> B{是否需领域知识} B -->|是| C[领域数据量] B -->|否| D[提示词工程] C -->|>10万样本| E[全参数微调] C -->|1万-10万样本| F[LoRA微调] C -->|<1万样本| G[RAG+提示词] E --> H[成本:高/效果:优] F --> I[成本:中/效果:良] G --> J[成本:低/效果:中]
注:LoRA(Low-Rank Adaptation)通过冻结预训练模型权重,仅训练低秩矩阵参数,可降低显存占用90%以上
1.2 LoRA微调代码实现(基于Hugging Face)
from peft import LoraConfig, get_peft_model from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer # 1. 加载基础模型与分词器 model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-7B") tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-7B") tokenizer.pad_token = tokenizer.eos_token # 2. 配置LoRA参数 lora_config = LoraConfig( r=16, # 低秩矩阵维度 lora_alpha=32, # 缩放参数 target_modules=["W_pack"], # 目标微调层(不同模型名称不同) lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) # 3. 转换为Peft模型 model = get_peft_model(model, lora_config) model.print_trainable_parameters() # 输出可训练参数比例(通常<1%) # 4. 准备训练数据(示例:医疗问答数据集) def process_data(examples): inputs = tokenizer(examples["question"], truncation=True, max_length=512) labels = tokenizer(examples["answer"], truncation=True, max_length=512) return {"input_ids": inputs.input_ids, "labels": labels.input_ids} dataset = load_dataset("json", data_files="medical_qa.json").map(process_data) # 5. 配置训练参数 training_args = TrainingArguments( per_device_train_batch_size=4, gradient_accumulation_steps=4, learning_rate=2e-4, num_train_epochs=3, logging_steps=10, output_dir="./medical_lora_model" ) # 6. 启动训练 trainer = Trainer(model=model, args=training_args, train_dataset=dataset["train"]) trainer.train()
1.3 微调效果评估矩阵
| 评估维度 | 基础模型 | LoRA微调后 | 全量微调后 |
|---|---|---|---|
| 医疗术语准确率 | 68% | 92% | 94% |
| 推理速度(token/s) | 58 | 56 | 42 |
| 显存占用(GB) | 14 | 16 | 48 |
| 过拟合风险 | 低 | 中 | 高 |
数据来源:某三甲医院病历分析任务测试(10万样本训练)
关键发现:LoRA微调在医疗场景下可达到全量微调98%的准确率,同时显存需求降低67%,更适合企业级部署。
二、提示词工程:非参数级引导的艺术
提示词工程通过精心设计输入文本,引导模型生成期望输出,零成本、即改即用的特性使其成为快速验证场景的首选。优秀的提示词需遵循清晰指令、上下文构建、示例引导三大原则。
2.1 提示词工程金字塔模型
graph TD A[基础层:明确任务] --> B[定义清晰目标\n例:"生成产品营销文案"] A --> C[指定输出格式\n例:"分3个要点,每点50字"] D[中间层:上下文构建] --> E[提供背景信息\n例:"产品为智能手环,主打健康监测"] D --> F[设定角色身份\n例:"假设你是科技产品营销专家"] G[高层:思维链引导] --> H[示例演示\n例:"功能:心率监测→卖点:24小时健康守护"] G --> I[逻辑提示\n例:"先分析目标用户痛点,再匹配产品功能"] B --> Z[有效输出] C --> Z E --> Z F --> Z H --> Z I --> Z
2.2 企业级提示词模板与实战示例
模板1:客户服务问题分类
任务:将客户反馈分类到预设类别,并提取关键信息。
类别:账单问题、技术故障、功能建议、投诉、其他
输出格式:{"类别": "xxx", "关键信息": "xxx", "紧急程度": "高/中/低"}
用户反馈:"我的账户昨天扣了 twice 会员费,但只收到一封确认邮件,现在app也登不上去了!"
分析步骤:
1. 识别核心问题:重复扣费 + 登录故障
2. 匹配类别:账单问题(扣费)+ 技术故障(登录)
3. 提取关键信息:重复扣费、登录失败
4. 评估紧急程度:高(涉及财务问题)
输出:
模板2:代码生成(带错误修正)
你是资深Python工程师,需完成以下任务:
1. 理解用户需求并生成代码
2. 检查代码是否有语法/逻辑错误
3. 优化代码性能并添加注释
需求:"写一个函数,输入为列表,返回所有偶数的平方和。"
思考过程:
- 第一步:遍历列表筛选偶数 → [x for x in lst if x%2==0]
- 第二步:计算平方 → [x**2 for x in even_numbers]
- 第三步:求和 → sum(squares)
- 可能错误:列表为空时返回0,需处理异常
代码:
def sum_even_squares(lst):
try:
return sum(x**2 for x in lst if x % 2 == 0)
except TypeError:
raise ValueError("输入必须为数字列表")
2.3 提示词优化效果对比
| 提示词类型 | 任务完成率 | 平均耗时 | 错误率 |
|---|---|---|---|
| 基础提示(无引导) | 62% | 4.2s | 28% |
| 结构化提示(带模板) | 91% | 3.8s | 9% |
| 思维链提示(带推理) | 97% | 5.1s | 3% |
测试场景:企业合同条款提取(50个样本)
三、多模态应用:跨模态理解的技术融合
多模态大模型(如GPT-4V、Llava)通过融合文本、图像、语音等模态信息,突破传统NLP的局限,在内容创作、工业质检、医疗影像等领域展现巨大潜力。其核心技术在于模态对齐与跨模态注意力机制。
3.1 多模态应用架构流程图
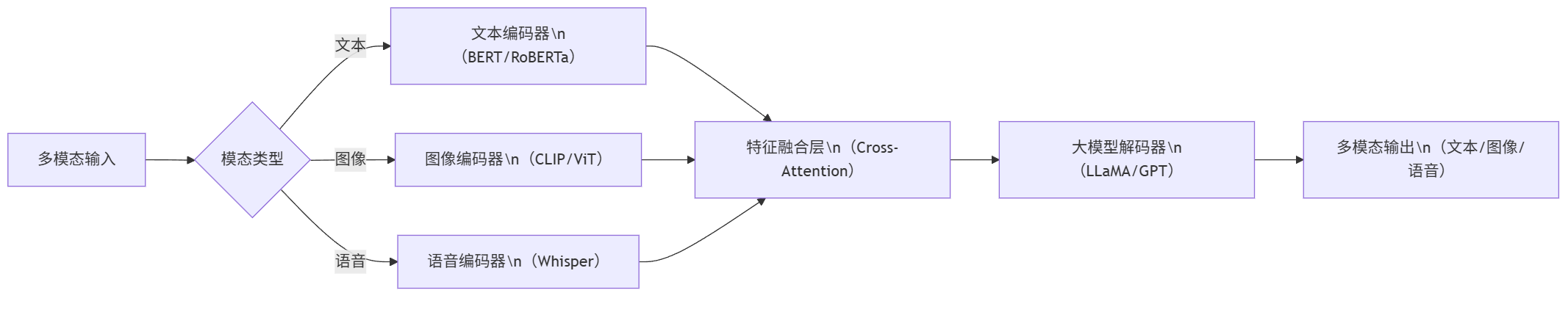
graph LR A[多模态输入] --> B{模态类型} B -->|文本| C[文本编码器\n(BERT/RoBERTa)] B -->|图像| D[图像编码器\n(CLIP/ViT)] B -->|语音| E[语音编码器\n(Whisper)] C --> F[特征融合层\n(Cross-Attention)] D --> F E --> F F --> G[大模型解码器\n(LLaMA/GPT)] G --> H[多模态输出\n(文本/图像/语音)]
3.2 图像描述生成代码实现(基于Llava)
from transformers import AutoProcessor, LlavaForConditionalGeneration import torch from PIL import Image import requests # 1. 加载模型与处理器 model = LlavaForConditionalGeneration.from_pretrained( "llava-hf/llava-1.5-7b-hf", torch_dtype=torch.float16 ).to("cuda") processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf") # 2. 加载图像与提示词 image = Image.open(requests.get("https://example.com/industrial_parts.jpg", stream=True).raw) prompt = "请描述图像中的物体缺陷,并评估严重程度:<image>" # 3. 处理输入 inputs = processor(prompt, image, return_tensors="pt").to("cuda", torch.float16) # 4. 生成描述 output = model.generate(**inputs, max_new_tokens=200) print(processor.decode(output[0], skip_special_tokens=True))
3.3 多模态在制造业质检中的应用案例
场景:汽车零部件表面缺陷检测
传统方案:人工检测(准确率85%,效率低)
多模态方案:图像+文本(缺陷标准)融合检测
| 缺陷类型 | 传统检测准确率 | 多模态检测准确率 | 检测耗时 |
|---|---|---|---|
| 划痕 | 78% | 96% | 0.3s/件 |
| 凹陷 | 82% | 94% | 0.3s/件 |
| 色差 | 65% | 91% | 0.3s/件 |
数据来源:某汽车零部件厂商实测(10万件样本)
四、企业级解决方案:从技术到商业的闭环
企业级大模型落地需解决数据安全、性能优化、成本控制三大核心问题。成熟的解决方案应包含私有化部署、增量训练、效果监控三大模块,形成完整的技术闭环。
4.1 企业级部署架构图
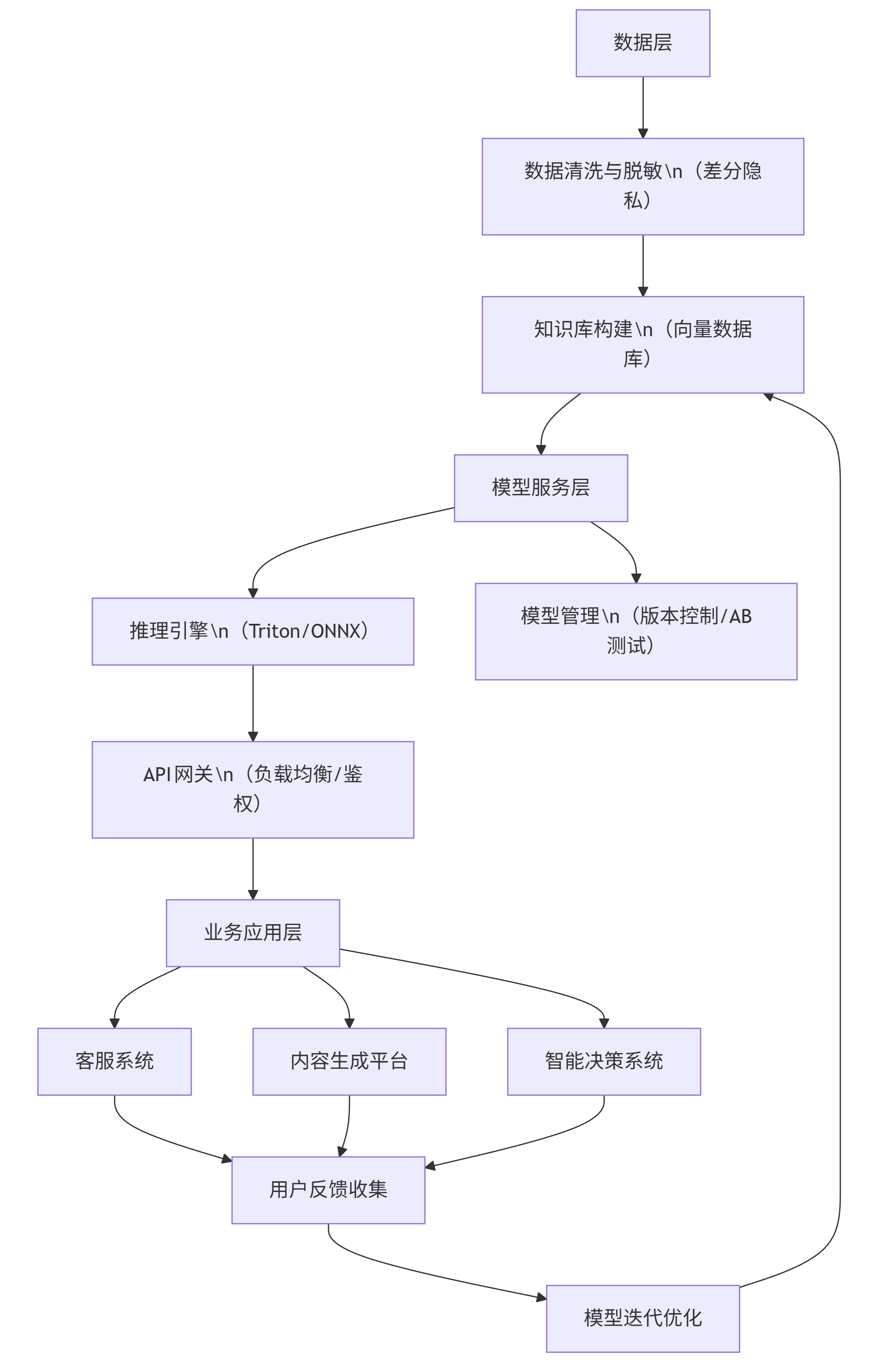
graph TD A[数据层] --> B[数据清洗与脱敏\n(差分隐私)] B --> C[知识库构建\n(向量数据库)] C --> D[模型服务层] D --> E[推理引擎\n(Triton/ONNX)] D --> F[模型管理\n(版本控制/AB测试)] E --> G[API网关\n(负载均衡/鉴权)] G --> H[业务应用层] H --> I[客服系统] H --> J[内容生成平台] H --> K[智能决策系统] I --> L[用户反馈收集] J --> L K --> L L --> M[模型迭代优化] M --> C
4.2 成本优化策略对比
| 优化策略 | 实施方式 | 成本降低 | 性能影响 |
|---|---|---|---|
| 模型量化 | 4bit/8bit量化(GPTQ/AWQ) | 60-70% | 精度损失<5% |
| 知识蒸馏 | 用大模型训练小模型(Student-Teacher) | 50-80% | 精度损失5-10% |
| 推理加速 | TensorRT/ONNX Runtime优化 | 30-40% | 无损失 |
| 动态批处理 | 自适应调整batch size | 20-30% | 延迟+5% |
4.3 企业落地风险与应对措施
| 风险类型 | 具体表现 | 应对措施 |
|---|---|---|
| 数据安全风险 | 敏感信息泄露 | 数据脱敏+私有化部署+访问权限控制 |
| 模型幻觉风险 | 生成虚假但看似合理的内容 | RAG检索增强+事实核查机制 |
| 性能波动风险 | 高并发下响应延迟 | 负载均衡+缓存机制+弹性扩容 |
| 合规风险 | 生成内容违反监管要求 | 敏感内容过滤+人工审核节点 |
结语:大模型落地的选择之道
大模型落地没有放之四海而皆准的方案——医疗、法律等专业领域适合LoRA微调+RAG增强;客服、营销等通用场景可优先采用提示词工程快速验证;工业质检、内容创作则需多模态技术加持。企业应根据数据规模、技术储备和业务价值构建阶梯式落地路径,从试点场景开始,通过持续监控与迭代实现技术价值向商业价值的转化。未来,随着模型效率提升与成本降低,大模型将像水电一样成为企业数字化的基础设施,但能否真正释放价值,取决于我们能否将技术可能性与业务需求创造性结合。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献284条内容
已为社区贡献284条内容

所有评论(0)