Python配置训练环境对打标图片信息进行配置时候出问题:运行voc_label.py文件时无法生成2025_train.txt 、2025_val.txt 、 train.txt文件...如何解决?
🏆本文收录于 《全栈 Bug 调优(实战版)》 专栏。专栏聚焦真实项目中的各类疑难 Bug,从成因剖析 → 排查路径 → 解决方案 → 预防优化全链路拆解,形成一套可复用、可沉淀的实战知识体系。无论你是初入职场的开发者,还是负责复杂项目的资深工程师,都可以在这里构建一套属于自己的「问题诊断与性能调优」方法论,助你稳步进阶、放大技术价值 。
🏆本文收录于 《全栈 Bug 调优(实战版)》 专栏。专栏聚焦真实项目中的各类疑难 Bug,从成因剖析 → 排查路径 → 解决方案 → 预防优化全链路拆解,形成一套可复用、可沉淀的实战知识体系。无论你是初入职场的开发者,还是负责复杂项目的资深工程师,都可以在这里构建一套属于自己的「问题诊断与性能调优」方法论,助你稳步进阶、放大技术价值 。
📌 特别说明:
文中问题案例来源于真实生产环境与公开技术社区,并结合多位一线资深工程师与架构师的长期实践经验,经过人工筛选与AI系统化智能整理后输出。文中的解决方案并非唯一“标准答案”,而是兼顾可行性、可复现性与思路启发性的实践参考,供你在实际项目中灵活运用与演进。
欢迎你 关注、收藏并订阅本专栏,与持续更新的技术干货同行,一起让问题变资产,让经验可复制,技术跃迁,稳步向上。
📢 问题描述
详细问题描述如下:配置训练环境对打标图片信息进行配置时候出问题:运行voc_label.py文件时候无法生成2025_train.txt 、2025_val.txt 、 train.txt文件。
如下是相关代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2025', 'train'), ('2025', 'val')] #这里需要修改成对应的Main中
classes = ["shu"] #这里需要改成对应的类别,可以有多类
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\Annotations\\%s.xml'%(year, image_id))
out_file = open('D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\labels\\%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\labels\\'%(year)):
os.makedirs('D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\labels\\'%(year))
image_ids = open('D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\ImageSets\\Main\\%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%sD:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\JPEGImages\\%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("type 2025_train.txt 2025_val.txt > train.txt")
运行voc_label.py文件时候原来train文件下所有图片文件名和所有所有标注txt文件夹会被清空。
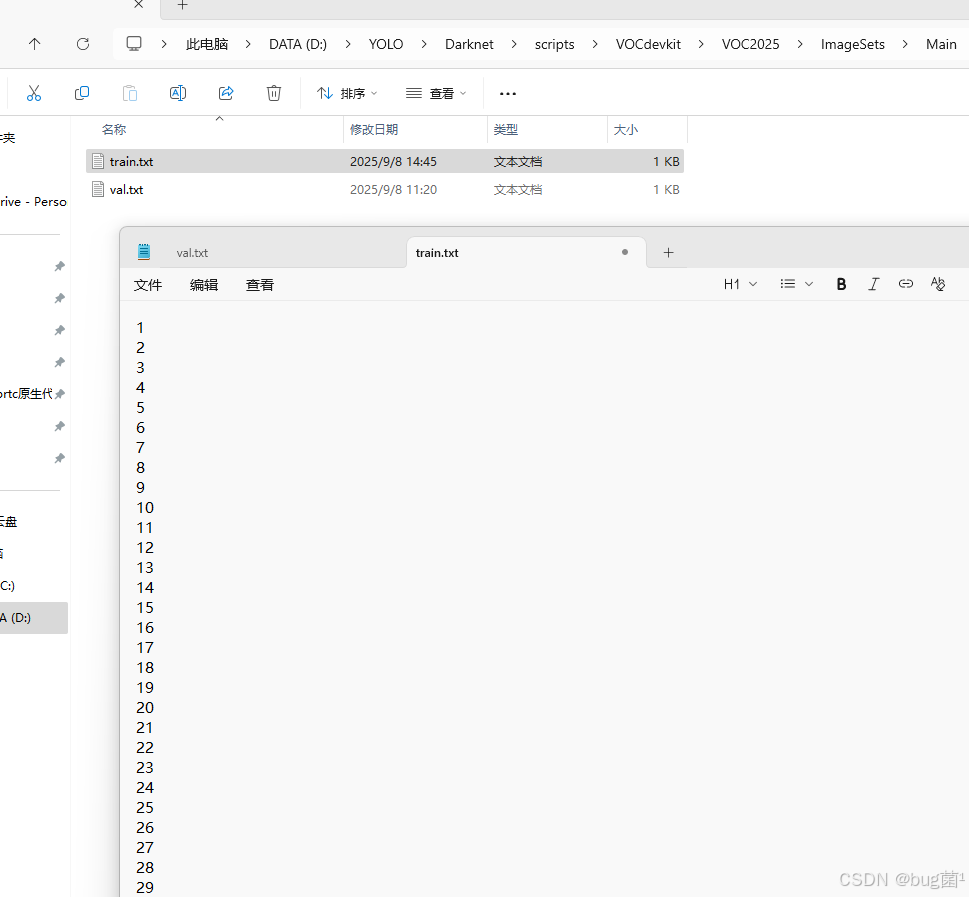
任意打开一个文件:
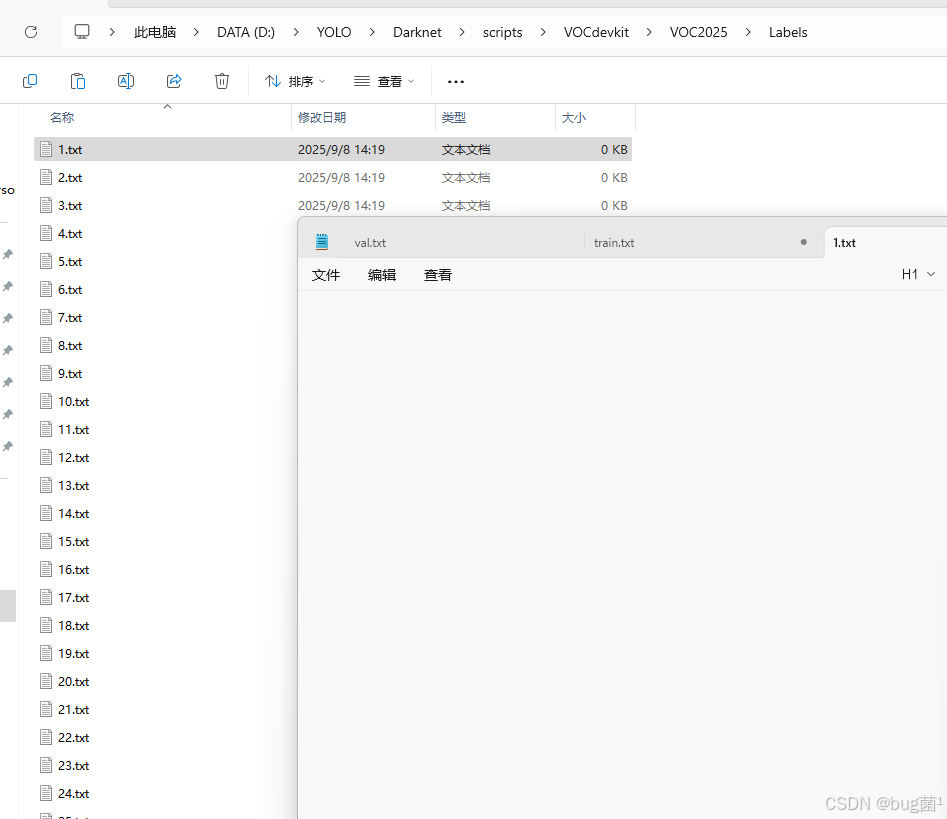
全文目录:
📣 请知悉:如下方案不保证一定适配你的问题!
如下是针对上述问题进行专业角度剖析答疑,不喜勿喷,仅供参考:

✅ 问题理解
🎯 核心问题分析
从你提供的截图和代码,我识别出了三个关键问题:
问题1️⃣:文件无法生成
2025_train.txt、2025_val.txt、train.txt这三个文件没有被正确生成- 这些文件是YOLO训练时用来索引图片路径的关键配置文件
问题2️⃣:标注文件被清空
- 运行脚本后,
Labels文件夹下的所有.txt标注文件被清空(显示0 KB) - 这意味着YOLO格式的标注数据丢失了
问题3️⃣:潜在的路径问题
- 你的代码中存在硬编码路径和路径拼接错误
list_file.write()中的路径格式有问题
🔬 问题根源深度剖析
原因A:路径拼接逻辑错误
list_file.write('%sD:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\JPEGImages\\%s.jpg\n'%(wd, year, image_id))
这行代码存在严重问题:
%s在前面会直接拼接wd(当前工作目录)和绝对路径- 例如:
C:\Users\xxx\D:\YOLO\...这样的路径是无效的 - 应该直接使用绝对路径或相对路径,不要混用
原因B:文件可能生成但在错误位置
list_file = open('%s_%s.txt'%(year, image_set), 'w')没有指定完整路径- 文件会生成在脚本运行的当前目录,而不是你期望的位置
原因C:标注文件被清空的原因
out_file = open('D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC%s\\labels\\%s.txt'%(year, image_id), 'w')
-
使用
'w'模式打开文件时,如果XML解析出错或没有找到有效目标 -
文件会被创建但内容为空
-
可能的原因:
- XML文件格式不符合预期
classes列表中的类名与XML中的不匹配difficult标签问题
✅ 问题解决方案
🟢 方案 A:修复路径逻辑 + 增强错误处理(推荐⭐⭐⭐⭐⭐)
这是最稳妥、最全面的解决方案,包含完整的错误处理和日志输出。
import xml.etree.ElementTree as ET
import os
from os.path import join, abspath, dirname
# ==================== 配置区域 ====================
# 定义数据集根目录(使用绝对路径)
VOC_ROOT = r'D:\YOLO\Darknet\scripts\VOCdevkit'
YEAR = '2025'
# 数据集划分
sets = [('2025', 'train'), ('2025', 'val')]
# 类别列表(必须与XML中的name标签完全一致,区分大小写)
classes = ["shu"]
# 输出文件保存位置(建议保存在VOC2025根目录下)
OUTPUT_DIR = join(VOC_ROOT, f'VOC{YEAR}')
# ==================================================
def convert(size, box):
"""
将VOC格式的边界框转换为YOLO格式
Args:
size: (width, height) 图片尺寸
box: (xmin, xmax, ymin, ymax) VOC格式坐标
Returns:
(x_center, y_center, width, height) YOLO格式归一化坐标
"""
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
"""
转换单个XML标注文件为YOLO格式txt
Returns:
bool: 转换是否成功
"""
# 构建文件路径
xml_path = join(VOC_ROOT, f'VOC{year}', 'Annotations', f'{image_id}.xml')
txt_path = join(VOC_ROOT, f'VOC{year}', 'labels', f'{image_id}.txt')
# 检查XML文件是否存在
if not os.path.exists(xml_path):
print(f'❌ 警告: XML文件不存在 -> {xml_path}')
return False
try:
# 解析XML
tree = ET.parse(xml_path)
root = tree.getroot()
# 获取图片尺寸
size = root.find('size')
if size is None:
print(f'❌ 错误: {image_id}.xml 中缺少<size>标签')
return False
w = int(size.find('width').text)
h = int(size.find('height').text)
if w <= 0 or h <= 0:
print(f'❌ 错误: {image_id}.xml 中图片尺寸无效 (w={w}, h={h})')
return False
# 打开输出文件
with open(txt_path, 'w') as out_file:
obj_count = 0
# 遍历所有目标对象
for obj in root.iter('object'):
# 获取difficult存在则默认为0)
difficult_elem = obj.find('difficult')
difficult = int(difficult_elem.text) if difficult_elem is not None else 0
# 获取类别名称
cls_elem = obj.find('name')
if cls_elem is None:
print(f'⚠️ {image_id}.xml 中某个<object>缺少<name>标签,跳过')
continue
cls = cls_elem.text.strip()
# 检查类别是否在定义的类别列表中
if cls not in classes:
print(f'⚠️ {image_id}.xml 中发现未定义的类别: "{cls}",跳过')
continue
# 跳过困难样本
if difficult == 1:
print(f'ℹ️ {image_id}.xml 中类别"{cls}"被标记为difficult,跳过')
continue
cls_id = classes.index(cls)
# 获取边界框坐标
xmlbox = obj.find('bndbox')
if xmlbox is None:
print(f'⚠️ {image_id}.xml 中某个<object>缺少<bndbox>标签,跳过')
continue
try:
xmin = float(xmlbox.find('xmin').text)
xmax = float(xmlbox.find('xmax').text)
ymin = float(xmlbox.find('ymin').text)
ymax = float(xmlbox.find('ymax').text)
except (AttributeError, ValueError) as e:
print(f'⚠️ {image_id}.xml 中边界框坐标解析失败: {e}')
continue
# 验证边界框有效性
if xmin >= xmax or ymin >= ymax:
print(f'⚠️ {image_id}.xml 中边界框无ymin}, ymax={ymax})')
continue
# 转换为YOLO格式
b = (xmin, xmax, ymin, ymax)
bb = convert((w, h), b)
# 写入文件
out_file.write(f"{cls_id} {' '.join([f'{a:.6f}' for a in bb])}\n")
obj_count += 1
if obj_count == 0:
print(f'⚠️ {image_id}.xml 中没有找到有效的标注对象')
return False
else:
print(f'✅ {image_id}.txt 转换成功,共{obj_count}个对象')
return True
except ET.ParseError as e:
print(f'❌ XML解析错误 {image_id}.xml: {e}')
return False
except Exception as e:
print(f'❌ 未函数"""
print("=" * 70)
print("🚀 开始VOC数据集转换为YOLO格式")
print("=" * 70)
# 统计信息
total_images = 0
success_images = 0
for year, image_set in sets:
print(f"\n📂 处理数据集: VOC{year} - {image_set}")
print("-" * 70)
# 创建labels目录
labels_dir = join(VOC_ROOT, f'VOC{year}', 'labels')
if not os.path.exists(labels_dir):
os.makedirs(labels_dir)
print(f"✅ 创建目录: {labels_dir}")
# 读取图片ID列表
image_sets_file = join(VOC_ROOT, f'VOC{year}', 'ImageSets', 'Main', f'{image_set}.txt')
if not os.path.exists(image_sets_file):
print(f"❌ 错误: 找不到文件 {image_sets_file}")
continue
with open(image_sets_file, 'r') as f:
image_ids = [line.strip() for line in f.readlines() if line.strip()]
print(f"📊 共找到 {len(image_ids)} 张图片")
# 生成路径列表文件
list_file_path = join(OUTPUT_DIR, f'{year}_{image_set}.txt')
with open(list_file_path, 'w') as list_file:
for i, image_id in enumerate(image_ids, 1):
# 图片路径(使用绝对路径)
image_path = join(VOC_ROOT, f'VOC{year}', 'JPEGImages', f'{image_id}.jpg')
# 检查图片是否存在
if not os.path.exists(image_path):
print(f"⚠️ [{i}/{len(image_ids)}] 图片不存在: {image_id}.jpg")
continue
# 转换标注
total_images += 1
if convert_annotation(year, image_id):
# 写入图片路径(使用绝对路径)
list_file.write(f'{image_path}\n')
success_images += 1
else:
print(f"⚠️ [{i}/{len(image_ids)}] 标注转换失败: {image_id}")
print(f"\n✅ 生成路径列表文件: {list_file_path}")
# 合并train和val文件
print("\n" + "=" * 70)
print("🔗 合并训练和验证集...")
train_file = join(OUTPUT_DIR, f'{YEAR}_train.txt')
val_file = join(OUTPUT_DIR, f'{YEAR}_val.txt')
merged_file = join(OUTPUT_DIR, 'train.txt')
try:
with open(merged_file, 'w') as outfile:
# 合并train文件
if os.path.exists(train_file):
with open(train_file, 'r') as infile:
outfile.write(infile.read())
# 合并val文件
if os.path.exists(val_file):
with open(val_file, 'r') as infile:
outfile.write(infile.read())
print(f"✅ 合并完成: {merged_file}")
except Exception as e:
print(f"❌ 合并文件时出错: {e}")
# 输出统计信息
print("\n" + "=" * 70)
print("📊 转换完成统计")
print("=" * 70)
print(f"总图片数: {total_images}")
print(f"成功转换: {success_images}")
print(f"失败数量: {total_images - success_images}")
print(f"成功率: {success_images/total_images*100:.2f}%" if total_images > 0 else "N/A")
print("=" * 70)
if __name__ == '__main__':
main()
方案A的优势:
- 完善的错误处理:每一步都有异常捕获和友好提示
- 详细的日志输出:实时显示转换进度和问题
- 路径管理优化:使用
os.path.join避免路径拼接错误 - 数据验证:检查XML格式、边界框有效性、片存在性
- 统计信息:显示转换成功率和详细统计
🟡 方案 B:快速修复版(适合急用)
如果你只想快速解决问题,可以用这个简化版本:
import xml.etree.ElementTree as ET
import os
# ========== 配置 ==========
VOC_ROOT = r'D:\YOLO\Darknet\scripts\VOCdevkit'
sets = [('2025', 'train'), ('2025', 'val')]
classes = ["shu"]
# ==========================
def convert(size, box):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0 * dw
y = (box[2] + box[3]) / 2.0 * dh
w = (x, y, w, h)
def convert_annotation(year, image_id):
xml_file = os.path.join(VOC_ROOT, f'VOC{year}', 'Annotations', f'{image_id}.xml')
txt_file = os.path.join(VOC_ROOT, f'VOC{year}', 'labels', f'{image_id}.txt')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
with open(txt_file, 'w') as out_file:
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(f"{cls_id} {' '.join([str(a) for a in bb])}\n")
for year, image_set in sets:
labels_dir = os.path.join(VOC_ROOT, f'VOC{year}', 'labels')
os.makedirs(labels_dir, exist_ok=True)
image_sets_file = os.path.join(VOC_ROOT, f'VOC{year}', 'ImageSets', 'Main', f'{image_set}.txt')
image_ids = open(image_sets_file).read().strip().split()
# 修正:输出文件保存在VOC2025目录下
list_file_path = os.path.join(VOC_ROOT, f'VOC{year}', f'{year}_{image_set}.txt')
with open(list_file_path, 'w') as list_file:
for image_id in image_ids:
# 修正:使用绝对路径
img_path = os.path.join(VOC_ROOT, f'VOC{year}', 'JPEGImages', f'{image_id}.jpg')
list_file.write(f'{img_path}\n')
convert_annotation(year, image_id)
print(f'✅ 完成: {list_file_path}')
# 合并文件
train_txt = os.path.join(VOC_ROOT, 'VOC2025', '2025_train.txt')
val_txt = os.path.join(VOC_ROOT, 'VOC2025', '2025_val.txt')
merged_txt = os.path.join(VOC_ROOT, 'VOC2025', 'train.txt')
with open(merged_txt, 'w') as outfile:
for fname in [train_txt, val_txt]:
if os.path.exists(fname):
with open(fname) as infile:
outfile.write(infile.read())
print(f'✅ 合并完成: {merged_txt}')
🔴 方案 C:诊断模式(排查问题用)
如果上面两个方案还不能解决,使用这个诊断脚本找出问题根源:
import os
import xml.etree.ElementTree as ET
VOC_ROOT = r'D:\YOLO\Darknet\scripts\VOCdevkit'
YEAR = '2025'
print("=" * 70)
print("🔍 VOC数据集诊断工具")
print("=" * 70)
# 检查1:目查目录结构...")
required_dirs = [
f'VOC{YEAR}',
f'VOC{YEAR}/Annotations',
f'VOC{YEAR}/JPEGImages',
f'VOC{YEAR}/ImageSets/Main',
f'VOC{YEAR}/labels'
]
for dir_name in required_dirs:
dir_path = os.path.join(VOC_ROOT, dir_name)
exists = os.path.exists(dir_path)
print(f"{'✅' if exists else '❌'} {dir_path}")
# 检查2:数据文件
print("\n📄
split_file = os.path.join(VOC_ROOT, f'VOC{YEAR}', 'ImageSets', 'Main', f'{split}.txt')
if os.path.exists(split_file):
with open(split_file, 'r') as f:
lines = f.readlines()
print(f"✅ {split}.txt 存在,共 {len(lines)} 行")
# 检查前5个样本
print(f" 前5个样本: {[line.strip() for line in lines[:5]]}")
else:
print(f"❌ {split}.txt 不存在")
# 检查3:XML文件采样检查
print("\n🔬 采样检查XML文件...")
train_file = os.path.join(VOC_ROOT, f'VOC{YEAR}', 'ImageSets', 'Main', 'train.txt')
if os.path.exists(train_file):
with open(train_file, 'r') as f:
sample_ids = [line.strip() for line in f.readlines()[:3]] # 检查前3个
for img_id in sample_ids:
print(f"\n 📝 检查样本: {img_id}")
# 检查图片
jpg_path = os.path.join(VOC_ROOT, f'VOC{YEAR}', 'JPEGImages', f'{img_id}.jpg')
print(f" 图片: {'✅ 存在' if os.path.exists(jpg_path) else '❌ 不存在'}")
# 检查XML
xml_path = os.path.join(VOC_ROOT, f'VOC{YEAR}', 'Annotations', f'{img_id}.xml')
if os.path.exists(xml_path):
print(f" XML: ✅ 存在")
try:
tree = ET.parse(xml_path)
root = tree.getroot()
# 检查尺寸
size = root.find('size')
if size is not None:
w = size.find('width').text
h = size.find('height').text
print(f" 尺寸: {w}x{h}")
# 检查对象
objects = root.findall('object')
print(f" 对象数: {len(objects)}")
for obj in objects:
name = obj.find('name').text if obj.find('name') is not None else 'None'
difficult = obj.find('difficult')
diff_val = difficult.text if difficult is not None else '0'
print(f" - 类别: {name}, difficult: {diff_val}")
except Exception as e:
print(f" ❌ XML解析失败: {e}")
else:
print(f" XML: ❌ 不存在")
print("\n" + "=" * 70)
print("诊断完成!请根据上述信息排查问题。")
print("=" * 70)
运行这个诊断脚本,它会告诉你:
- 哪些目录缺失
- 哪些文件有问题
- XML格式是否正确
- 类别名称是否匹配
✅ 问题延伸
🧩 相关知识点深度拓展
1️⃣ VOC与YOLO标注格式对比
VOC Pascal格式(XML):
<annotation>
<size>
<width>640</width>
<height>480</height>
</size>
<object>
<name>shu</name>
<bndbox>
<xmin>100</xmin>
<ymin>150</ymin>
<xmax>300</xmax>
<ymax>350</ymax>
</bndbox>
<difficult>0</difficult>
</object>
</annotation>
YOLO格式(TXT):
0 0.3125 0.520833 0.3125 0.416667
# 格式:class_id x_center y_center width height(归一化到0-1)
2️⃣ 坐标转换数学原理
# VOC格式 -> YOLO格式转换公式
x_center = (xmin + xmax) / 2 / image_width
y_center = (ymin + ymax) / 2 / image_height
width = (xmax - xmin) / image_width
height = (ymax - ymin) / image_height
关键点:
- YOLO使用的是相对坐标(归一化到0-1)
- 中心点坐标而非左上角坐标
- 宽高也是归一化的比例值
3️⃣ YOLO数据集目录结构最佳实践
VOC2025/
├── Annotations/ # XML标注文件
│ ├── 1.xml
│ ├── 2.xml
│ └── ...
├── JPEGImages/ # 原始图片
│ ├── 1.jpg
│ ├── 2.jpg
│ └── ...
├── ImageSets/
│ └── Main/
│ ├── train.txt # 训练集图片ID列表
│ └── val.txt # 验证集图片ID列表
├── labels/ # YOLO格式标注
│ ├── 1.txt
│ ├── 2.txt
│ └── ...
├── 2025_train.txt # 训练集完整路径列表
├── 2025_val.txt # 验证集完整路径列表
└── train.txt # 合并后的训练数据路径
4️⃣ 常见的XML解析陷阱
# ❌ 错误做法:不检查元素是否存在
difficult = obj.find('difficult').text # 如果没有这个标签会报错
# ✅ 正确做法:先判断再取值
difficult_elem = obj.find('difficult')
difficult = int(difficult_elem.text) if difficult_elem is not None else 0
5️⃣ 路径处理的跨平台最佳实践
# ❌ 错误:硬编码路径分隔符
path = 'D:\\YOLO\\data\\' + filename
# ✅ 正确:使用os.path.join
path = os.path.join('D:', 'YOLO', 'data', filename)
# ✅ 更好:使用pathlib(Python 3.4+)
from pathlib import Path
path = Path('D:/YOLO/data') / filename
✅ 问题预测
🔮 可能遇到的后续问题及预防
⚠️ 问题1:训练时报错 “Image not found”
原因:train.txt 中的路径与实际图片位置不匹配
解决方案:
# 在生成train.txt时使用绝对路径
image_path = os.path.abspath(os.path.join(VOC_ROOT, f'VOC{year}', 'JPEGImages', f'{image_id}.jpg'))
list_file.write(f'{image_path}\n')
验证脚本:
# 验证train.txt中的路径是否有效
with open('train.txt', 'r') as f:
for line in f:
img_path = line.strip()
if not os.path.exists(img_path):
print(f'❌ 图片不存在: {img_path}')
⚠️ 问题2:训练时mAP很低或为0
可能原因:
- 标注文件为空(本次遇到的问题)
- 类别数量配置错误
- anchor尺寸不匹配
预防措施:
# 在转换后检查labels目录
labels_dir = 'VOC2025/labels'
empty_files = []
for txt_file in os.listdir(labels_dir):
txt_path = os.path.join(labels_dir, txt_file)
if os.path.getsize(txt_path) == 0:
empty_files.append(txt_file)
if empty_files:
print(f'⚠️ 发现 {len(empty_files)} 个空标注文件:')
print(empty_files[:10]) # 显示前10个
⚠️ 问题3:类别名称不匹配
症状:转换后所有txt文件都是空的
排查方法:
# 扫描所有XML文件,统计出现的类别
from collections import Counter
all_classes = []
annotations_dir = 'VOC2025/Annotations'
for xml_file in os.listdir(annotations_dir):
tree = ET.parse(os.path.join(annotations_dir, xml_file))
root = tree.getroot()
for obj in root.iter('object'):
cls_name = obj.find('name').text
all_classes.append(cls_name)
class_counts = Counter(all_classes)
print('📊 数据集中的类别分布:')
for cls, count in class_counts.items():
print(f' {cls}: {count} 个样本')
⚠️ 问题4:Windows路径反斜杠问题
现象:在Linux服务器训练时找不到文件
解决方案:
# 生成跨平台兼容的路径
import platform
def get_image_path(voc_root, year, image_id):
path = os.path.join(voc_root, f'VOC{year}', 'JPEGImages', f'{image_id}.jpg')
# 如果要在Linux上使用,转换路径格式
if platform.system() == 'Windows':
# 保存时使用正斜杠(跨平台兼容)
path = path.replace('\\', '/')
return path
更好的方案:使用相对路径
# 将train.txt保存在项目根目录
# 图片路径使用相对路径
relative_path = os.path.relpath(image_path, start=os.getcwd())
list_file.write(f'{relative_path}\n')
⚠️ 问题5:中文路径导致训练失败
现象:路径中包含中文字符,OpenCV读取失败
解决方案:
# 方法1:避免使用中文路径
# 将数据集放在纯英文路径下,如:
# D:/YOLO/datasets/VOC2025/
# 方法2:如果必须使用中文路径,用cv2.imdecode
import cv2
import numpy as np
def imread_chinese(img_path):
"""支持中文路径的图片读取"""
return cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), cv2.IMREAD_COLOR)
⚠️ 问题6:difficult标签导致样本丢失
现象:某些明明打了标签的图片,转换后txt是空的
原因:XML中<difficult>1</difficult>的对象被跳过了
建议:
# 如果你的数据集很小,建议保留difficult样本
if difficult == 1:
# continue # 注释掉这行
pass # 改为保留
✅ 小结
📋 核心要点回顾
🎯 本次问题的根本原因
- 路径拼接错误:
'%sD:\\...'导致生成的路径无效 - 文件位置错误:生成的txt文件不在预期位置
- 错误处理缺失:XML解析失败时静默创建空文件
- 类别名称:可能与XML中的不匹配(需要验证)
🔧 解决方案总结
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 🟢 方案A | 正式使用 | 完善的错误处理、详细日志 | 代码较长 |
| 🟡 方案B | 快速修复 | 简洁、易理解 | 错误处理较少 |
| 🔴 方案C | 问题排查 | 帮助定位具体问题 | 不直接解决问题 |
💡 最佳实践建议
-
路径管理
- ✅ 使用
os.path.join()拼接路径 - ✅ 使用绝对路径避免相对路径混乱
- ✅ 统一使用正斜杠
/增强跨平台兼容性
- ✅ 使用
-
错误处理
- ✅ 检查文件是否存在再操作
- ✅ 使用
try-except捕获XML解析错误 - ✅ 验证数据有效性(边界框、图片尺寸等)
-
调试技巧
- ✅ 添加详细的打印信息
- ✅ 先在小数据集上测试
- ✅ 转换后验证生成文件的内容
-
数据验证
# 转换完成后必做的检查 # 1. 检查txt文件数量 # 2. 检查是否有空文件 # 3. 验证train.txt中的路径 # 4. 随机抽查几个样本的标注
🚀 操作步骤(推荐流程)
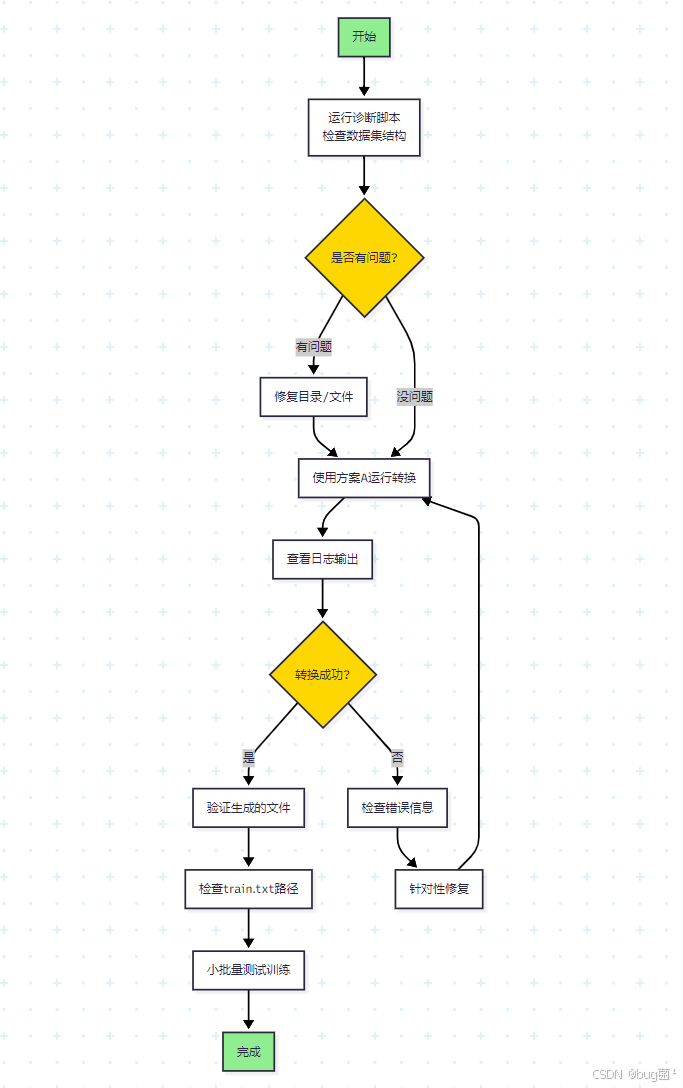
📝 执行清单
转换前:
- 确认XML文件都在
Annotations/目录 - 确认图片都在
JPEGImages/目录 - 确认
train.txt和val.txt在ImageSets/Main/ - 确认
classes列表与XML中的类名一致 - 运行诊断脚本检查数据集
转换中:
- 观察日志输出,注意警告和错误
- 记录失败的样本ID
- 确认转换进度正常
转换后:
- 检查
labels/目录下txt文件数量 - 检查是否有0KB的空文件
- 验证
2025_train.txt、2025_val.txt、train.txt都已生成 - 随机打开几个txt文件查看内容格式
- 用文本编辑器打开
train.txt验证路径正确
训练前:
- 修改YOLO配置文件中的
classes数量 - 修改
.data文件中的train路径 - 修改
.names文件中的类别名称 - 小批量测试(如10张图片)
🎁 额外赠送:一键检查脚本
import os
def quick_check(voc_root='D:/YOLO/Darknet/scripts/VOCdevkit', year='2025'):
"""快速检查数据集转换结果"""
print("🔍 快速检查...")
issues = []
# 检查关键文件
files_to_check = [
(f'VOC{year}/{year}_train.txt', '训练集路径文件'),
(f'VOC{year}/{year}_val.txt', '验证集路径文件'),
(f'VOC{year}/train.txt', '合并后的训练文件')
]
for file_path, desc in files_to_check:
full_path = os.path.join(voc_root, file_path)
if os.path.exists(full_path):
size = os.path.getsize(full_path)
print(f"✅ {desc}: {size} bytes")
else:
print(f"❌ {desc}: 不存在")
issues.append(f"{desc}缺失")
# 检查labels目录
labels_dir = os.path.join(voc_root, f'VOC{year}', 'labels')
if os.path.exists(labels_dir):
all_labels = os.listdir(labels_dir)
empty_labels = [f for f in all_labels if os.path.getsize(os.path.join(labels_dir, f)) == 0]
print(f"\n📊 Labels统计:")
print(f" 总数: {len(all_labels)}")
print(f" 空文件: {len(empty_labels)}")
if empty_labels:
print(f"⚠️ 前5个空文件: {empty_labels[:5]}")
issues.append(f"{len(empty_labels)}个标注文件为空")
# 总结
print("\n" + "="*50)
if issues:
print("❌ 发现问题:")
for issue in issues:
print(f" - {issue}")
else:
print("✅ 一切正常!可以开始训练了!")
print("="*50)
# 运行检查
quick_check()
🎉 最后
这个问题虽然看起来复杂,但本质上是:
- 路径处当
- 缺少错误检查
- 没有验证输出
通过我提供的方案A(推荐),你可以:
- ✅ 看到详细的转换过程
- ✅ 立即发现哪里出错
- ✅ 得到准确的统计信息
- ✅ 避免后续训练问题
现在就试试方案A吧! 如果遇到任何问题,把错误日志发给我,我再定位分析下。
🌹 结语 & 互动说明
希望以上分析与解决思路,能为你当前的问题提供一些有效线索或直接可用的操作路径。
若你按文中步骤执行后仍未解决:
- 不必焦虑或抱怨,这很常见——复杂问题往往由多重因素叠加引起;
- 欢迎你将最新报错信息、关键代码片段、环境说明等补充到评论区;
- 我会在力所能及的范围内,结合大家的反馈一起帮你继续定位 👀
💡 如果你有更优或更通用的解法:
- 非常欢迎在评论区分享你的实践经验或改进方案;
- 你的这份补充,可能正好帮到更多正在被类似问题困扰的同学;
- 正所谓「赠人玫瑰,手有余香」,也算是为技术社区持续注入正向循环
🧧 文末福利:技术成长加速包 🧧
文中部分问题来自本人项目实践,部分来自读者反馈与公开社区案例,也有少量经由全网社区与智能问答平台整理而来。
若你尝试后仍没完全解决问题,还请多一点理解、少一点苛责——技术问题本就复杂多变,没有任何人能给出对所有场景都 100% 套用的方案。
如果你已经找到更适合自己项目现场的做法,非常建议你沉淀成文档或教程,这不仅是对他人的帮助,更是对自己认知的再升级。
如果你还在持续查 Bug、找方案,可以顺便逛逛我专门整理的 Bug 专栏:《全栈 Bug 调优(实战版)》。
这里收录的都是在真实场景中踩过的坑,希望能帮你少走弯路,节省更多宝贵时间。
✍️ 如果这篇文章对你有一点点帮助:
- 欢迎给 bug菌 来个一键三连:关注 + 点赞 + 收藏
- 你的支持,是我持续输出高质量实战内容的最大动力。
同时也欢迎关注我的硬核公众号 「猿圈奇妙屋」:
获取第一时间更新的技术干货、BAT 等互联网公司最新面试真题、4000G+ 技术 PDF 电子书、简历 / PPT 模板、技术文章 Markdown 模板等资料,统统免费领取。
你能想到的绝大部分学习资料,我都尽量帮你准备齐全,剩下的只需要你愿意迈出那一步来拿。
🫵 Who am I?
我是 bug菌:
- 热活跃于 CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等技术社区;
- CSDN 博客之星 Top30、华为云多年度十佳博主/卓越贡献者、掘金多年度人气作者 Top40;
- 掘金、InfoQ、51CTO 等平台签约及优质作者;
- 全网粉丝累计 30w+。
更多高质量技术内容及成长资料,可查看这个合集入口 👉 点击查看 👈️
硬核技术公众号 「猿圈奇妙屋」 期待你的加入,一起进阶、一起打怪升级。

- End -

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)