收藏必备!5种主流LLM-based Agent方案全解析(小白&程序员入门指南)
对于已经有规范工具调用接口的应该使用ToolUniverse(ToolUniverse已经具备sciToolAgent中最重要的ToolKG功能),对于需要更灵活使用工具的场景应该使用CodeAct。近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式!据行业招聘数据显示,具备3-5年大模型相关经
本文将系统拆解5种主流LLM-based Agent实现方案,涵盖核心设计、执行逻辑、适用场景及实操要点,助力小白快速入门、程序员精准选型。这5种方案分别是:ReAct(推理与行动协同)、Reflexion(多模型自我反思框架)、SciToolAgent(知识图谱驱动科学工作流)、CodeAct(代码执行增强动作能力)、ToolUniverse(标准化工具交互协议)。其中,已有规范接口的场景优先选ToolUniverse,需灵活拓展工具使用边界的场景推荐CodeAct,下文将逐一深入解析。
ReAct
ReAct方法的具体设计与实现机制如下:ReAct通过扩展智能体的行动空间,将推理轨迹(reasoning traces) 与具体行动(actions) 结合在同一个任务解决流程中。其关键设计包括:
- 行动空间扩展:在传统行动空间 的基础上,增加语言空间 ,允许模型生成自由形式的推理文本(即“思考”)。
- 动态上下文更新:每一步的推理文本不会直接影响环境,但会更新模型的内部上下文,指导后续行动或推理。
例如,在问答任务中,模型可能先生成思考:“我需要先搜索X实体,验证其属性,再结合Y实体回答”,再执行搜索操作,并根据返回结果调整下一步计划。
任务适配的推理-行动节奏
1. 知识密集型任务(如多跳问答、事实验证):
- 采用密集推理模式,每一步行动前均生成推理(Thought-Action-Observation循环)。
- 例如,在HotpotQA中,模型通过推理引导Wikipedia API的调用,避免因内部知识过时或错误导致的幻觉问题。
2. 决策型任务(如文本游戏、网页导航):
- 采用稀疏推理模式,仅在关键节点(如目标分解、状态转换时)生成推理。
- 例如,在ALFWorld中,模型在寻找物体前推理其可能位置(“台灯通常在书桌或架子上”),再执行导航行动。
密集推理与稀疏推理分别看图1d和2b:
提示设计:基于少量示例的上下文学习
-
示例构造:从训练集中随机选取少量任务实例,人工编写包含推理、行动和观察的完整轨迹作为提示示例。
-
自然语言格式:无需设计特定模板,直接使用自然语言描述推理和行动(例如,“思考:我需要先找到X;行动:搜索X”)。
-
泛化性:同一范式可适配多种任务(如问答、游戏、网页导航)。
协同优势:推理指导行动,行动增强推理
1. 推理指导行动(Reason to Act):
- 通过语言推理分解复杂目标、跟踪进度、处理异常(如“盐用完了,改用酱油和胡椒”)。
- 在ALFWorld中,推理显著提升动作规划准确率(ReAct成功率71% vs. 仅行动是45%)。
2. 行动支持推理(Act to Reason):
- 通过与环境交互(如调用Wikipedia API)获取实时信息,减少模型内部知识幻觉。
- 在Fever任务中,检索最新数据验证事实,准确率(60.9%)优于纯推理方法(56.3%)。
混合策略与扩展优化
1. 结合内部知识与外部检索:
- 当ReAct在限定步数内无法解决任务时,回退至思维链自洽性(CoT-SC)方法,利用模型内部知识补充推理。
- 例如,在HotpotQA中,ReAct与CoT-SC结合后,仅需3-5个样本即可达到纯CoT-SC需21个样本的性能。
2. 微调提升性能:
- 用ReAct生成的轨迹微调较小模型(如PaLM-8B),使其学会推理-行动协同策略。微调后的模型在HotpotQA上显著优于基于提示的方法。
3. 人工干预与可控性:
- 支持实时编辑推理轨迹(如修正错误假设),引导模型调整行为。例如,在ALFWorld中,通过修改模型思考中的错误描述(如“水槽中没有胡椒瓶”),可快速纠正模型行为。
Reflexion
Reflexion框架的pipeline涉及了多个大型语言模型(LLM)的协同工作。其核心设计包含三个独立的模型组件,每个组件承担不同的职责,共同构成了一个完整的自我反思和强化学习循环。
Reflexion框架中的多LLM组件
1. Actor(行动者)模型
- 职责:这是核心的行动生成模型。它基于当前的环境观察、任务指令以及存储在记忆中的过往反思,来生成文本和具体的行动。
- 实现方式:研究中使用如ReAct(结合推理和行动)和Chain-of-Thought (CoT)(链式思维推理)等提示策略来构建Actor。其策略可以形式化为 ,类似于传统强化学习中的策略函数。
2. Evaluator(评估者)模型
- 职责:评估Actor在单次试验(trial)中产生的轨迹(trajectory)或答案的成功与否,并提供一个反馈信号。这个信号可以是简单的二进制信号(成功/失败),也可以是标量分数。
- 实现方式:评估者的实现非常灵活,可以根据任务类型而变化:
预定义启发式函数:用于决策制定任务。
▪ 精确匹配(Exact Match):用于问答等推理任务。
▪ 另一个LLM实例:甚至可以启用一个独立的LLM作为评估者,为决策或代码生成任务提供奖励分数。
3. Self-Reflection(自我反思)模型
- 职责:这是实现“语言强化”的关键组件。它将Evaluator提供的、信息量较少的标量反馈信号(如“失败”)转化为一段详细、可操作的语言反馈总结。
- 工作流程:该模型会分析失败轨迹,诊断错误原因(例如,“我在步骤i采取了错误行动a_i,导致后续步骤也出错了”),并提出未来应如何改进的具体建议(例如,“下次我应该尝试行动a_i’”)。这段文本化的“经验教训”随后被存储到记忆中。
多模型协同工作流程
这些模型在Reflexion的pipeline中按以下顺序协同工作,形成一个迭代的优化循环:
- 行动生成:Actor模型 与环境交互,产生一个任务轨迹(如一系列行动或一个答案)。
- 效果评估:Evaluator模型对生成的轨迹进行评估,并产生一个奖励分数 。
- 反思总结:如果任务未成功,Self-Reflection模型会介入,将评估信号转化为一段详细的语言反思 。
- 经验存储:这段反思文本被添加到长期记忆(Memory) 缓冲区中。
- 再次尝试:在下一个试验开始时,Actor模型会接收到包含了过去反思经验的记忆内容,从而在新的尝试中做出更明智的决策。
这个循环会持续进行,直到任务成功完成。
因此,Reflexion的pipeline并非依赖单一的LLM,而是通过精心设计的多LLM协作架构来实现自我改进。Actor 负责执行,Evaluator 负责评判,Self-Reflection模型负责从失败中学习并生成指导性经验。这种分工使得Agent能够在不更新模型权重的情况下,仅通过语言反馈和记忆来实现高效的试错学习。其实验结果也证明,这种多模型协作框架在决策制定、推理和代码生成等复杂任务上能显著提升性能。
SciToolAgent
SciToolAgent的方法流程基于一个精心设计的架构,通过科学工具知识图谱(SciToolKG)驱动大语言模型(LLM)来智能集成和编排多工具科学工作流。其核心流程可分为三个主要阶段:规划(Planning)、执行(Execution)和总结(Summarizing),每个阶段均由LLM支持,并辅以安全检查和迭代优化机制。以下是详细的流程解析: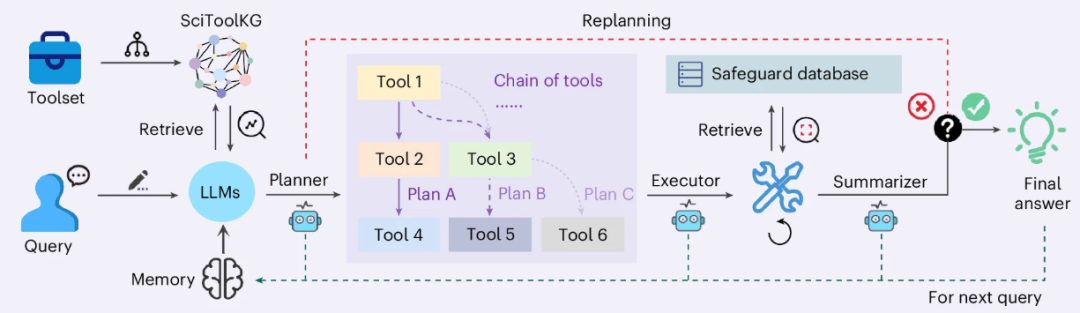
规划阶段(Planning)
• 目标:根据用户查询生成一个有序的工具链(chain of tools),以解决具体科学问题。
• 关键技术:基于SciToolKG的检索增强生成(Retrieve-Augmented Generation, RAG)。
具体步骤:
• 全图检索:计算用户查询与SciToolKG中所有工具功能的语义相似度,检索最相关的 k 个工具。
• 子图探索:以初始工具为中心,扩展其 d 跳邻域(如3跳),挖掘潜在关联工具。
• 工具组合与排序:结合全图检索和子图探索结果,按综合相似度排序,筛选出最相关的 n 个工具。
• 工具链生成:LLM根据工具依赖关系(如输入/输出格式兼容性)生成有序执行计划,例如:工具A → 工具B → 工具C。
执行阶段(Execution)
• 目标:按工具链顺序调用工具,处理输入/输出,并集成安全监控。
关键模块:
• 输入准备:LLM解析查询上下文,提取当前工具所需参数,并格式化(如转换数据类型)。
• 工具调用:通过API接口执行工具,实时监控运行状态并捕获输出。
• 错误处理与重试:若执行失败,自动调整输入或切换备用工具,最多重试3次。
• 安全检测模块:对高风险工具(如化学合成)的输出进行安全检查:
◦ 化合物安全:计算与有害物质数据库(如PubChem)的相似度(Tanimoto/Dice/Cosine系数),阈值δ=0.95。
◦ 蛋白质安全:使用Smith-Waterman算法比对毒性蛋白数据库(UniProtKB)。
◦ 若检测到风险,立即终止流程并发出警告。
总结与迭代阶段(Summarizing)
• 目标:整合各工具输出,生成最终答案,并评估解决方案质量。
核心步骤:
• 输出合成:LLM汇总所有工具结果,消除矛盾信息,结构化呈现答案。
• 质量评估:判断当前工具链是否成功解决问题。若失败,向规划器反馈以重新生成工具链(如增删工具或调整顺序)。
• 记忆存储:将成功的工作流存入记忆模块,为后续查询提供上下文。
CodeAct
CodeAct旨在通过生成和执行Python代码来增强LLM代理(Agent)的动作能力。其核心流程可分为四个关键阶段,具体如下:
框架初始化:定义角色与交互模式
CodeAct基于一个通用的多轮交互框架,涉及三个核心角色:
- Agent:LLM代理,负责生成代码动作。
- User:用户,提供自然语言指令(如任务描述)。
- Environment:外部环境(如Python解释器、工具API),执行代码并返回结果。
多轮交互执行流程
步骤1: 接收观察(Observation)
Agent从用户或环境获取输入:
• 用户指令(如“查询某商品价格”)。
• 环境反馈(如代码执行结果、错误信息)。
步骤2: 生成代码动作(Action)
Agent生成可执行的Python代码作为动作,而非静态的JSON或文本。代码动作的优势包括:
• 控制流支持(如循环、条件判断)。
• 数据流管理(中间结果存储为变量)。
• 直接调用现有软件库(如Pandas、Scikit-Learn)。
步骤3: 执行与反馈
代码通过Python解释器执行,环境返回结果(如计算值、错误消息)。若执行失败,Agent根据错误信息自我调试(Self-debug),动态调整代码。
步骤4: 终止或继续
交互持续直到:
• 任务成功(如输出正确答案)。
• 达到最大交互轮次(默认10轮)。
流程优势与关键特性
- 动态调整能力
• 通过多轮交互,Agent可基于环境反馈(如错误信息)修正动作,而非依赖单次生成。
• 例:若代码因库未导入报错,Agent在下一轮中添加import语句。 - 无需预定义工具
• 直接利用Python生态(如sqlite3处理数据库、matplotlib绘图),无需为特定任务定制工具。 - 零样本泛化
• 无需提供上下文示例,依赖LLM预训练的代码知识直接生成动作。
实例演示
用户请求“训练一个机器学习模型”,CodeActAgent的流程如下:
- 回合1:Agent生成代码安装所需库(!pip install pandas)。
- 回合2:加载数据并调用Scikit-Learn进行模型训练。
- 回合3:根据训练错误(如数据维度不匹配)调整代码。
- 最终回合:输出训练结果及可视化图表。
CodeAct的流程本质是将LLM代理的动作空间统一为代码,通过多轮交互实现动态规划、自我调试和工具组合。这一设计显著提升了复杂任务(如科学实验)的解决能力,同时降低了对预定义工具的依赖(无需注册tool,可以借助生成code去pip install以及import调用)。
ToolUniverse
ToolUniverse 的方法流程围绕构建“AI科学家”这一核心目标,通过一套标准化的协议和组件,实现从工具发现、调用到组合优化的全生命周期管理。其整体流程可归纳为以下几个关键环节。
AI工具交互协议
这是ToolUniverse的核心基础,类似于HTTP在互联网通信中的作用,它定义了AI科学家与工具之间的标准化交互方式。该协议包含两个核心操作:
- • Find Tool(查找工具):将自然语言描述映射为工具规范,使AI科学家能理解并选择适合的工具。
- • Call Tool(调用工具):执行选定的工具并返回结果(如文本、嵌入或JSON对象)。
这一协议屏蔽了后端工具的复杂性,使得AI模型无需关心具体实现细节即可调用工具。
核心组件协同工作流程
ToolUniverse通过六大组件协同运作,支撑AI科学家的全流程构建:
- • 1.Tool Finder(工具查找器):像sciToolAgent中的KG一样,从600+工具中快速定位相关工具。方法是:a.基于TF-IDF算法,匹配工具名称和描述。b.利用大模型理解复杂语义需求。c.通过语义向量相似度匹配(基于GTE-Qwen2-1.5B模型)。
- • 2.Tool Caller(工具调用器):流程为:a.动态加载工具(避免全量加载的开销);b.验证输入参数是否符合工具规范;c.执行工具并返回结构化结果;d.错误处理与反馈。
- • 3.Tool Manager(工具管理器):本地工具注册:通过装饰器(如@register_tool)快速集成Python工具。远程工具集成:基于Model Context Protocol(MCP)连接私有或依赖复杂的工具。
- • 4.Tool Composer(工具组合器):功能是将多个工具组合成复合工作流。有以下模式:a.顺序执行(如先文献检索后摘要生成);b.并行执行(如同时调用多个数据库);c.反馈循环(如基于结果动态调整下一步工具)。
- • 5.Tool Optimizer(工具优化器):流程是:a.生成测试用例;b.分析工具执行结果;c.通过多轮迭代优化工具描述的清晰度和准确性;d.终止条件:达到质量阈值(如8/10分)或最大迭代次数。
- • 6.Tool Discoverer(工具发现器):功能是从自然语言描述自动生成新工具。步骤包括:a.语义搜索相似工具作为参考;b.生成工具规范(名称、参数、返回模式);c.自动生成可执行代码;d.质量评估与迭代优化。
构建AI科学家的实践流程
ToolUniverse支持三种方式构建AI科学家:
(1)基于LLM的构建,步骤:
- • 安装ToolUniverse(pip install tooluniverse);
- • 配置LLM(如Claude)连接ToolUniverse的MCP服务器;
- • 用户提供科学问题,AI科学家自动规划工具使用流程。
(2)基于智能体(如Gemini CLI)的构建
- • 特点:智能体可直接调用Tool Finder和Tool Caller,支持多轮工具使用与推理。
(3)基于领域专用智能体(如TxAgent)的构建
- • 训练阶段:使用ToolUniverse作为强化学习环境,学习工具使用策略(这就是当前热门的Agentic RL);
- • 推理阶段:直接调用工具解决领域问题(如药物设计)。
总结
对于已经有规范工具调用接口的应该使用ToolUniverse(ToolUniverse已经具备sciToolAgent中最重要的ToolKG功能),对于需要更灵活使用工具的场景应该使用CodeAct。
最后
近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式!据行业招聘数据显示,具备3-5年大模型相关经验的开发者,在大厂就能拿到50K×20薪的高薪待遇,薪资差距肉眼可见!
业内资深HR预判:不出1年,“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下,“温水煮青蛙”式的等待只会让自己逐渐被淘汰,与其被动应对,不如主动出击,抢先掌握AI大模型核心原理+落地应用技术+项目实操经验,借行业风口实现职业翻盘!
深知技术人入门大模型时容易走弯路,我特意整理了一套全网最全最细的大模型零基础学习礼包,涵盖入门思维导图、经典书籍手册、从入门到进阶的实战视频、可直接运行的项目源码等核心内容。这份资料无需付费,免费分享给所有想入局AI大模型的朋友!

👇👇扫码免费领取全部内容👇👇

部分资料展示
1、 AI大模型学习路线图

2、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 大模型学习书籍&文档

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。


6、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
-
👇👇扫码免费领取全部内容👇👇
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献426条内容
已为社区贡献426条内容

所有评论(0)