AI(原生)产品中如何平衡自然语言交互与GUI交互?(第二讲)
由于本人做的是教育类的AI产品,以教育中一个更复杂的场景来说,比如通过一堂AI课做到教、学、练等环节,这些环节穿插了AI老师的教学视频、AI老师的实时引导、学生与AI实时问答、以及基于学生的回答或AI老师的引导驱动等流程。在大多数情况,传统的点选、拖拽比“说”更快,更便捷,更稳定,更准确,更高效,性能更好。对于这类产品,输入和输出就限制了它的使用场景和功能,比如只能是对话,可以提供音频输出的知识,
在写完《“提供溢出的情绪价值”是AI产品极具可能性的方向》这篇文章之后,感觉有必要针对“AI产品”从产品视角写一个系列。目的和初衷也很简单,那就是倒逼自己去发现、思考、梳理、探索和输出,同时,也希望能够与同行进行交流,为AI的发展留下一些声音和贡献。
今天这篇文章就暂且作为这个AI产品系列的第二讲,一起聊聊在AI(原生)产品设计当中涉及到的一个考量:如何平衡基于AI(LLM)的自然语言交互与基于图形用户界面(GUI)的交互的关系。
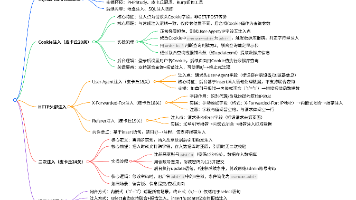
无论是AI原生的APP或者是由AI驱动的机器人硬件(准确来说是软硬件相结合),在进行产品设计时,我们都要有一个考量,那就是产品是基于纯自然语言交互产品,还是基于传统GUI进行交互,还是两者兼具?
这个问题看似简单,却极大的决定的产品发展的方向以及内置功能的技术实现。比如,市面上有这样一款机器人,它没有图形化界面输入输出,只有基于语音的输入和音频的输出,最多再配合一些机器人的表情和简单的肢体动作。
对于这类产品,输入和输出就限制了它的使用场景和功能,比如只能是对话,可以提供音频输出的知识,可以倾向于提供情绪价值的聊天,可以提供陪伴,可以提供其他设备的指令入口等。至于其他更复杂、更确定性的功能,是很难支持的。
再往上层走,就是像豆包、DeepSeek、腾讯元宝这类偏向于ChatBot的产品,往往都提供了多模态输入输出。在这类产品中,根据不同的场景和形态,是有不同的选择的。
以豆包为例,有几种常规的技术实现和产品方案:
- 文字对文字的对话:这个实现最简单,通过用户输入的文字内容,封装一层Prompt,传输给模型,再将模型的内容以文本的形式输出。当然,这期间还会经过文本内容安全审查、RAG增强等等处理。
- 语音对文字:就是用户发语音,模型回复文字。这类功能是在前面的功能上添加了一层ASR(自动语言识别)的处理,其他的保持不变。
- 语音/文字对语音:这种交互形式是在对输出的内容做了一层TTS(文本转语音)的处理。
- 通话模式:基于ASR进行语音识别,基于RTC(实时通信)技术进行语音的采集和输出,基于TTS技术将模型返回的文本转换为语音。
至于其他的延伸功能也都是基于上述技术进一步场景化组合而成。同样是对话,豆包之所以提供了多模态的交互,最核心的就是为了满足用户不同场景下的交互方式,做到最大的用户使用场景的覆盖。
像豆包提供的这一系列的交互形式,虽然只是针对一个简单的Chatbot的场景或其他同类的工具性产品,但这个设计的核心理念其实是可以延伸的其他产品的。
由于本人做的是教育类的AI产品,以教育中一个更复杂的场景来说,比如通过一堂AI课做到教、学、练等环节,这些环节穿插了AI老师的教学视频、AI老师的实时引导、学生与AI实时问答、以及基于学生的回答或AI老师的引导驱动等流程。类似这样的场景下,我们就需要权衡是基于自然语言交互为主,还是基于GUI交互为主的问题。
在真实实践中得出的一些基本的心得:
第一,对准确性要求没那么高,更倾向与“聊”和沟通的场景,使用自然语言交互。这样让用户感觉到更轻松,更方便,更自然,也不用受限于键盘的输入。特别是针对小学生,打字是比较困难的,针对老人的产品也是一样。
第二,针对驱动流程流转的关键环境,尽量采用GUI交互,让用户快速的点选,而不是通过说。一是因为用户很可能不知道说要什么指令,还有可能说了半天AI识别错了,还有语音识别错误,环境音干扰等干扰因素,这会导致原本非常简单明确的交互,变得让人“气恼”。当然,在这类交互流转中,也是可以配合模型的识别来驱动流程流转的,但要避免让用户感觉莫名其妙或者“不可控”,所以建议此场景尽量明确采用GUI交互。
第三,对于常规的点选、查看等类型操作,特别是在移动端设备,毫无疑问,通过GUI操作简单、直接方便、明确、高效。当然,也可以配合一些语音指令去打开或操作某些功能,但像教育场景,完全没必要。
第四,对于有明确操作,比如选择题、下一步、开启/结束等类型的操作,建议就是GUI操作。就拿做选择题为例,用户通过点击,可能只需要几百毫秒就可以完成,但如果通过自然语言沟通,很可能需要几秒,还有判断失败的风险,即增加成本,又损失用户体验。
其实,说了这么多,想表达的核心观点就是:不要为了AI而AI,不要为了单纯炫技而使用自然语言交互。在大多数情况,传统的点选、拖拽比“说”更快,更便捷,更稳定,更准确,更高效,性能更好。当然,针对特定的环境,“懒得动手”或“不方便动手”或“单纯就是在聊”,那么基于自然语言表达就再合适不过了。
有一条真理永远不变,那就是“适合的就是最好的”,在AI原生产品的交互设计中也同样适用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)