收藏必备!DeepSieve:让RAG系统真正“学会思考“的革命性框架,突破多跳推理与异构知识处理瓶颈
DeepSieve是专为处理异构知识源的RAG框架,解决了传统RAG无法处理多跳推理和异构信息两大痛点。该框架将LLM提升为工作流"总指挥官",通过分解、路由、执行与反思、融合四个步骤,实现智能规划与精准检索。实验证明,DeepSieve在多跳问答基准测试中精度和效率均超越现有方法,为复杂AI应用提供了坚实架构支撑。
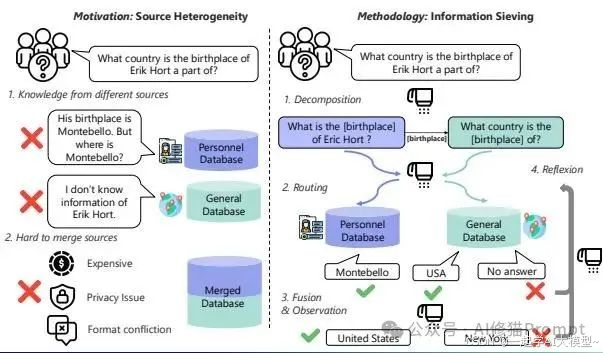
现在的RAG(检索增强生成)系统。您给它一个简单直接的问题,它能答得头头是道;可一旦问题需要稍微拐个弯,或者知识源一复杂,它就立刻“拉胯”,要么返回一堆不相干的东西,要么干脆就开始一本正经地胡说八道。今天来自罗格斯大学的研究者带来了DeepSieve,这是一个专为处理异构知识源的RAG框架,让RAG系统真正“学会思考”。

传统RAG的“天花板”
为什么现在传统的RAG方法会显得如此“脆弱”?根本原因在于它们大多是的单跳(single-hop)检索模式,这种模式在面对真实世界的复杂信息需求时,存在两个致命的底层缺陷。
缺陷一:无法理解多跳(Multi-hop)问题的内在逻辑
**很多有价值的问题,都不是一步就能解决的,而是需要像剥洋葱一样层层递进,这就是“多跳”推理。**但是,传统RAG拿到一个多跳问题后,并不会去拆解其中的逻辑链条,而是试图用一次模糊的语义匹配就找到答案。
举个论文里的例子,问“那个在尼日利亚创立了‘飞行医生’服务的女性,她的丈夫是谁?”,传统RAG会把“丈夫”、“创始人”、“飞行医生”
这些词混在一起进行一次性的模糊搜索,结果很可能因为找不到完美匹配所有信息的文档而彻底懵圈,因为它根本没理解这个问题其实需要两步:第一步,找到创始人是谁;第二步,再去找这位创始人的丈夫是谁。
缺陷二:无法驾驭“异构信息森林”
**现实中的知识库往往是多源、多格式、多模态的,比如SQL表格、私有的JSON日志、需要实时调用的API接口和海量的百科语料。**面对这片“异构信息森林”,传统RAG方法要么是盲目地逐个检索,要么是试图把所有东西“一锅乱炖”塞进同一个向量索引。结果呢?往往是漏检关键证据、导致上下文冲突、还造成了大量的Token浪费。
DeepSieve:给RAG装上“多核大脑”
面对传统RAG的困境,DeepSieve的思路可以说是相当的“釜底抽薪”。研究者们不再把LLM仅仅当作一个检索后的“润色工具”,而是将其提升为整个工作流的“总指挥官”,提出了一套“逐层筛选”的模块化框架,让大模型自己来决定所有关键步骤。
创新机制:让LLM当“知识筛子”
面对上面这些难题,DeepSieve的思路其实挺像人类专家的工作方式:先规划,再分步执行,遇到问题再调整。研究者们通过巧妙的Prompt Engineering,让LLM不再只是一个被动的“回答者”,而是成了一个主动的“指挥官”,整个过程大概分四步,就像给AI装上了“规划大脑”和“智能GPS”。
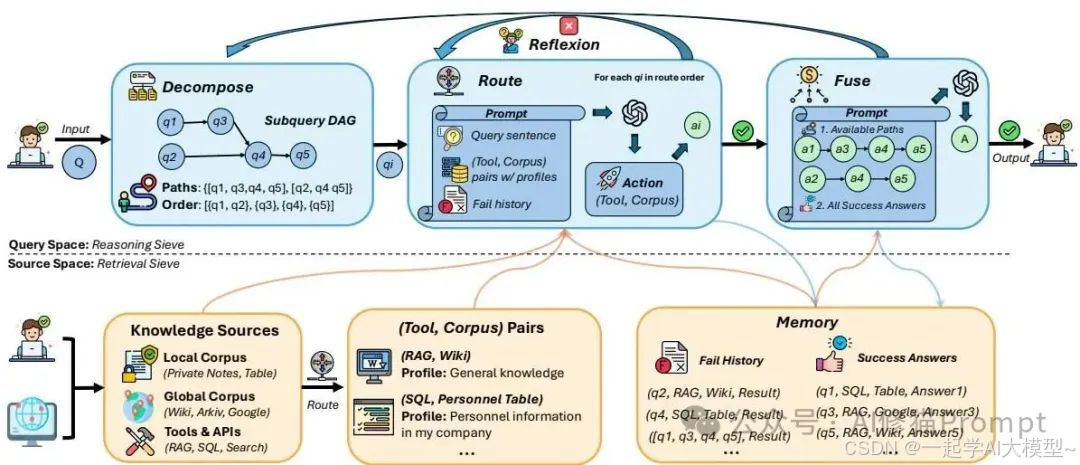
- 第一步:分解(Decomposition),这是“规划大脑” 拿到一个复杂问题后,DeepSieve做的第一件事不是急着去搜,而是先让LLM扮演“首席规划师”的角色。它会通过一个精心设计的Prompt,要求LLM把原始问题拆解成一个逻辑清晰、带依赖关系的子任务列表,并输出成一个程序可读的JSON格式。比如,它会把一个大问题拆成“q1”、“q2”等多个步骤,并明确指出“q2”的执行需要用到“q1”的答案作为变量,这就完成了一次谋定而后动的战略规划。
- 第二步:路由(Routing),这是“智能GPS” 规划好了路线图,下一步就是决定每个步骤该走哪条路、用什么交通工具了。DeepSieve会让LLM扮演“智能GPS”的角色,它看着当前的子任务,再看看手头上有哪些可用的知识源(比如“本地个人数据库”、“全局维基百科”),然后根据每个知识源的“简介”,动态地为这个子任务选择最合适的工具。这一步的成本极低,LLM只需要返回一个“local”或“global”的单词,却实现了对庞大知识体系的精准导航。
- 第三步:执行与反思(Execution & Reflexion),这是“纠错与学习” 但万一GPS指错了路怎么办?这正是DeepSieve最亮眼的地方,它有一个叫“反思”的机制。在执行每个子任务时,它会要求LLM在给出答案的同时,也给出一个“success”为1或0的标志,来判断这次检索是否真的找到了靠谱的信息。如果失败了(success为0),系统并不会就此放弃,而是会把这次失败的尝试(比如“我刚才选了‘local’库,但没找到信息”)记录下来,在下一次重试时告诉LLM,从而引导它“换条路试试”,比如这次去查“global”库。
- **第四步:融*合(*Fusion),这是“汇总报告” 最后,当所有的小问题都通过上述步骤找到了答案后,系统会把整个推理链——也就是所有子问题的“问题-答案-理由”——全部汇总起来。它会把这些完整的“证据”一次性提交给LLM,让它扮演“总结陈词者”的角色,基于这些坚实可靠的中间步骤,生成一个逻辑连贯、有理有据的最终答案。
方法亮点:LLM驱动的规划与执行
这套方法最核心的亮点,在于将规划和执行的权力完全交给了LLM,实现了前所未有的灵活性和智能性。
- 子问题级别的精准路由:它不是简单地召回一堆文档,而是实现了“去哪查+查什么+查几次”的完整规划。
- 原生支持异构知识源:无论是SQL数据库里的结构化数据,还是Wikipedia里的非结构化文本,甚至是用户行为的JSON日志,都能被无缝地纳入同一个查询体系。
- 强大的自我纠错能力:独特的“反思”(Reflexion)机制允许系统在一次尝试失败后,主动分析失败原因,并重新规划查询策略,而不是简单地放弃或返回错误。
DeepSieve的工程实现亮点
理论的优雅最终需要靠坚实的工程实现来承载,这一点在研究者们开源的项目中体现得淋漓尽致。对于工程师而言,这份代码不仅是一个算法的复现,更是一个优秀的AI系统设计范本,其中有几个亮点我觉得特别值得咱们关注。
https://github.com/MinghoKwok/DeepSieve
可插拔、接口统一的RAG后端
代码库中提供了NaiveRAG(经典向量检索)和GraphRAG(知识图谱与向量混合检索)两种模式。最巧妙的是,尽管这两种模式内部的实现逻辑天差地别,但它们对外都暴露了完全相同的rag_qa接口。这意味着上层的总指挥官(subquery_executor)可以无缝地切换使用不同的检索“武器”,而无需改动任何上层代码,这充分体现了代码的高度模块化和可扩展性。
工业级的健-壮性与为实验而生的灵活性
底层的API调用代码内置了非常完善的自动重试和指数退避机制,确保了系统在面对网络波动时的稳定性。同时,整个项目的执行入口设计了高度可配置的命令行参数,
实验结果
研究者们设计了一系列非常严苛的实验,来验证DeepSieve是否真的有效。
实验设计:在最硬核的场景下进行测试
- 数据集:研究者选择了MuSiQue、2WikiMultiHopQA和HotpotQA这三个业内公认的、专门为测试多跳问答能力而设计的“硬骨头”基准。
- 场景模拟:为了模拟真实世界的“信息孤岛”挑战,他们将每个数据集的知识库都人为地切分成了
local(本地/私有)和global(全局/公开)两部分,这就逼着系统必须智能地决定去哪里查找正确的信息,而不是在一个统一的库里瞎找。
正面交锋的对手
DeepSieve的比较对象,覆盖了当前RAG和Agent领域的顶尖方法。
- 经典RAG代表:包括了像ColBERTv2、HippoRAG、RAPTOR这样的知名框架。
- 前沿Agent方法:也囊括了ReAct、ReWOO、Reflexion这些大名鼎鼎的智能体框架。
精度、效率双丰收
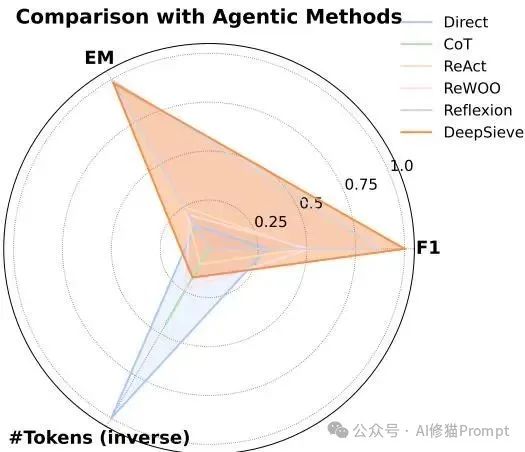
实验结果真的挺猛的,DeepSieve在所有维度上都展现了其优越性。
- 精度:在所有基准测试中,DeepSieve的平均F1分数和EM(精确匹配)分数,都显著超越了所有这些强大的对手。
- 效率:并且在取得更高精度的同时,Token消耗量(也就是计算成本)却远低于ReAct和Reflexion这类复杂的Agent方法,有时成本甚至不到后者的十分之一。
模块价值:通过“拆零件”式的消融实验,研究者证明了框架中每一个模块的不可或-缺性。“分解”和“反思”是保证高精度的绝对核心,而“路由”则是在复杂场景下提升系统鲁棒性的关键。

从“数据搬运工”到“任务指挥官”
DeepSieve 不仅在多跳问答基准测试中展现出卓越性能,更重要的是,它为复杂 AI 应用的落地开辟了新路径。面对需要联动多个内部系统(如ERP、CRM、文档库)才能回答的复杂业务问题,无论是构建能整合企业多源数据、提供深度业务洞察的智能助手,还是打造能统一管理个人异构知识、实现高效信息挖掘的下一代个人知识库,DeepSieve 都提供了坚实的架构支撑。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 44
44 0
0- 0



 已为社区贡献504条内容
已为社区贡献504条内容

所有评论(0)