【AI大模型前沿】Depth Anything 3:字节跳动推出的高效视觉空间重建模型
Depth Anything 3(DA3)是字节跳动Seed团队推出的一种视觉空间重建模型,能够从任意数量的视觉输入(包括单张图片、多视角图像或视频流)中恢复出三维空间的几何结构。该模型采用单一的Transformer架构,无需复杂的多任务训练或定制化架构设计,通过“深度-射线”表征法,实现了从单目深度估计到多视角几何重建的统一。
系列篇章💥
目录
前言
在计算机视觉领域,深度估计和三维空间重建一直是极具挑战性的任务。随着人工智能技术的不断发展,研究人员一直在探索更高效、更准确的解决方案。近期,字节跳动Seed团队推出的Depth Anything 3(DA3)模型,以其创新的单一Transformer架构和“深度-射线”表征法,为这一领域带来了新的突破。
一、项目概述
Depth Anything 3(DA3)是字节跳动Seed团队推出的一种视觉空间重建模型,能够从任意数量的视觉输入(包括单张图片、多视角图像或视频流)中恢复出三维空间的几何结构。该模型采用单一的Transformer架构,无需复杂的多任务训练或定制化架构设计,通过“深度-射线”表征法,实现了从单目深度估计到多视角几何重建的统一。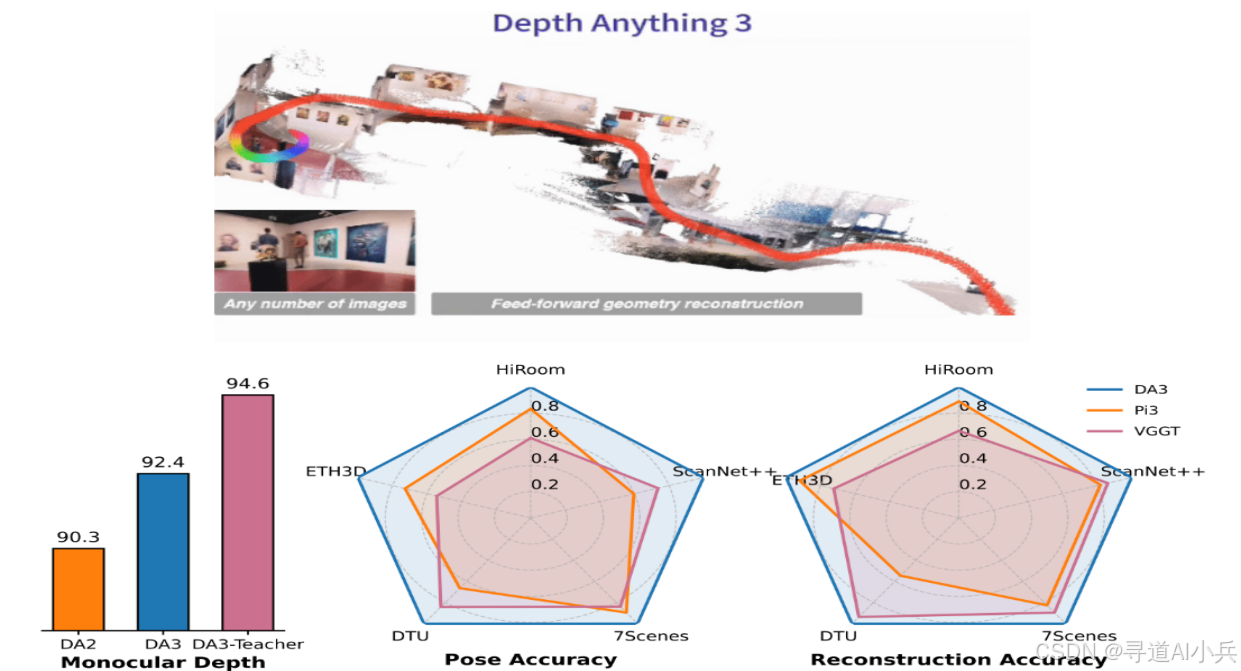
二、核心功能
(一)多视角空间重建
DA3能够处理从单目到多视角的各种输入场景,生成一致的三维空间几何结构,适用于自动驾驶、机器人导航、虚拟现实等领域。
(二)相机姿态估计
模型可以准确估计输入图像的相机姿态,即使在没有已知相机参数的情况下,也能实现高精度的三维重建。
(三)单目深度估计
DA3在单目深度估计任务上表现出色,能够从单张图像中预测出像素级的深度信息,为三维场景理解提供基础支持。
(四)新视角合成
通过与3D高斯渲染技术结合,DA3能够生成从未知视角观察的高质量图像,适用于虚拟现实和增强现实中的视角渲染任务。
(五)高效推理与部署
DA3的简洁架构设计使其在推理速度和资源消耗上具有显著优势,能够快速处理大规模场景,适用于移动端和嵌入式设备的部署。
三、技术揭秘
(一)单一Transformer架构
DA3采用单一的Transformer模型(如DINOv2)作为基础架构,无需复杂的定制化设计。Transformer的自注意力机制能够灵活处理任意数量的输入视图,动态交换跨视图信息,实现高效的全局空间建模。
(二)深度-射线表征法
DA3提出一种“深度-射线”表征法,通过预测深度图和射线图来完整描述三维空间。深度图提供像素到相机的距离,射线图描述像素在三维空间中的投影方向。这种表征方式自然解耦了空间几何与相机运动,简化了模型输出,同时提高了精度和效率。
(三)输入自适应的跨视图自注意力机制
DA3引入输入自适应的跨视图自注意力机制,通过动态重排输入视图的token,实现高效的跨视图信息交换。这种机制使模型能灵活处理从单目到多视图的各种输入场景。
(四)双DPT头设计
为联合预测深度和射线图,DA3设计了双DPT头结构。两个预测头共享特征处理模块,在最终融合阶段分别优化深度和射线图的输出,增强两个任务之间的交互和一致性。
(五)教师-学生训练范式
DA3采用教师-学生训练范式,通过在合成数据上训练的教师模型生成高质量的伪标签,为学生模型提供更准确的监督。
四、应用场景
(一)自动驾驶
DA3能够从车辆摄像头拍摄的多视角图像中快速重建三维环境,帮助自动驾驶系统更准确地感知周围物体的距离和位置,提升决策的可靠性和安全性。
(二)机器人导航
通过实时重建环境的三维结构,DA3能够为机器人提供精确的地形和障碍物信息,支持其在复杂环境中进行高效导航和路径规划。
(三)虚拟现实(VR)和增强现实(AR)
DA3可以将现实场景快速转换为高精度的三维模型,用于虚拟现实中的场景重建或增强现实中的虚拟物体融合,提升用户的沉浸感。
(四)建筑测绘与设计
DA3能够从建筑场景的多视角图像中重建出详细的三维点云,为建筑测绘、室内设计和虚拟建筑漫游提供高效的数据支持。
(五)文化遗产保护
DA3可以重建历史建筑或文物的三维结构,便于进行数字化保护、修复研究及虚拟展示,帮助文化遗产的传承和推广。
五、快速使用
(一)环境准备
确保已安装Python和PyTorch等基础环境。通过以下命令安装DA3所需的依赖包:
pip install torch>=2 torchvision
pip install -e . # Basic
pip install -e ".[gs]" # Gaussians Estimation and Rendering
pip install -e ".[app]" # Gradio, python>=3.10
pip install -e ".[all]" # ALL
(二)模型加载与推理
以加载预训练的DA3NESTED-GIANT-LARGE模型为例,进行基本的深度和相机姿态估计:
import glob
import os
import torch
from depth_anything_3.api import DepthAnything3
device = torch.device("cuda")
model = DepthAnything3.from_pretrained("depth-anything/DA3NESTED-GIANT-LARGE")
model = model.to(device=device)
example_path = "assets/examples/SOH"
images = sorted(glob.glob(os.path.join(example_path, "*.png")))
prediction = model.inference(images)
# 输出预测结果
print(prediction.depth.shape) # 深度图的形状
print(prediction.extrinsics.shape) # 相机外参的形状
(三)命令行工具使用
DA3提供强大的命令行工具,支持批量处理和多种输出格式。例如,使用CLI进行视频处理并导出为glb格式:
export MODEL_DIR=depth-anything/DA3NESTED-GIANT-LARGE
export GALLERY_DIR=workspace/gallery
mkdir -p $GALLERY_DIR
da3 video assets/examples/robot_unitree.mp4 \
--fps 15 \
--export-dir ${GALLERY_DIR}/TEST_BACKEND/robo \
--export-format glb-feat_vis \
--feat-vis-fps 15 \
--process-res-method lower_bound_resize \
--export-feat "11,21,31"
(四)Web UI可视化
DA3还提供了一个基于Gradio的Web UI,用户可以通过浏览器直观地查看模型的输入和输出结果,方便进行模型调试和结果比较。
六、结语
Depth Anything 3作为字节跳动Seed团队在视觉空间重建领域的最新成果,以其创新的技术架构和卓越的性能,为相关应用提供了强大的技术支持。其单一Transformer架构和“深度-射线”表征法的结合,不仅简化了模型设计,还显著提高了模型的效率和精度。无论是自动驾驶、机器人导航,还是虚拟现实等领域的开发者,都可以从DA3中受益,快速实现高精度的三维空间重建。
七、项目地址
- 项目官网:https://depth-anything-3.github.io/
- GitHub仓库:https://github.com/ByteDance-Seed/depth-anything-3
- arXiv技术论文:https://arxiv.org/pdf/2511.10647
- 在线体验Demo:https://huggingface.co/spaces/depth-anything/depth-anything-3

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)