第1章|为什么用 Mac M2 Ultra 做家庭电商 AI 主机:把“算力”变成“可交付的产线”
本文探讨了选择Mac M2 Ultra作为家庭电商AI主机的核心逻辑,强调从“单点性能”转向“产线指标”的工程思维。作者提出电商AI的关键在于稳定批量处理(7×24运行、多SKU并发)、一致性输出(风格/规格可控)和资产化管理(归档/回滚/安全访问),而非单纯追求模型参数。M2 Ultra的优势在于低维护、统一内存的稳定并发及家庭友好性,搭配64GB内存和2TB存储实现多服务协同(如ComfyUI

第1章|为什么用 Mac M2 Ultra 做家庭电商 AI 主机:把“算力”变成“可交付的产线”
很多人选“电商 AI 主机”,第一反应是堆显卡、看跑分。但当你把目标明确为一条可交付的生产线——ComfyUI 内容工厂 + RAG 智能运营 + Cloudflare Tunnel 零端口暴露 + Make AI Agents 编排审计——你需要的不是“最快的一台”,而是“最像机房的一台”:稳定常开、维护省心、服务可治理、入口安全。
这一章我们把对比以下可能考虑的方案:
- Mac Studio M2 Ultra:国补后 ¥18,000(24+60 核 / 64G / 1T)
- Mac(M2 Max):国补后 ¥19,000(12+30 核 / 32G / 4T)
- ROG 枪神9 Plus 超竞版:国补后 ¥16,000(U9-14900HX + RTX 5070Ti / 32G / 1T)
- 金河田电脑主机:京东 ¥12,000(i9 + RTX 4090 / 32G / 1T)
结论先放在前面:最终选 Mac Studio M2 Ultra。理由不靠“情绪”,靠工程指标。
1)先统一目标:你要搭的是“家庭私有 AI 机房”,不是“单机作图”
你的专栏架构本质上是四层:
- 算力与服务层:ComfyUI、RAG API、资产系统、监控面板
- 安全入口层:Cloudflare Tunnel + Access(零端口暴露、零信任)
- 编排层:Make AI Agents(意图→计划→调用→审计)
- 数据回流层:效果指标、客服对话、知识库更新
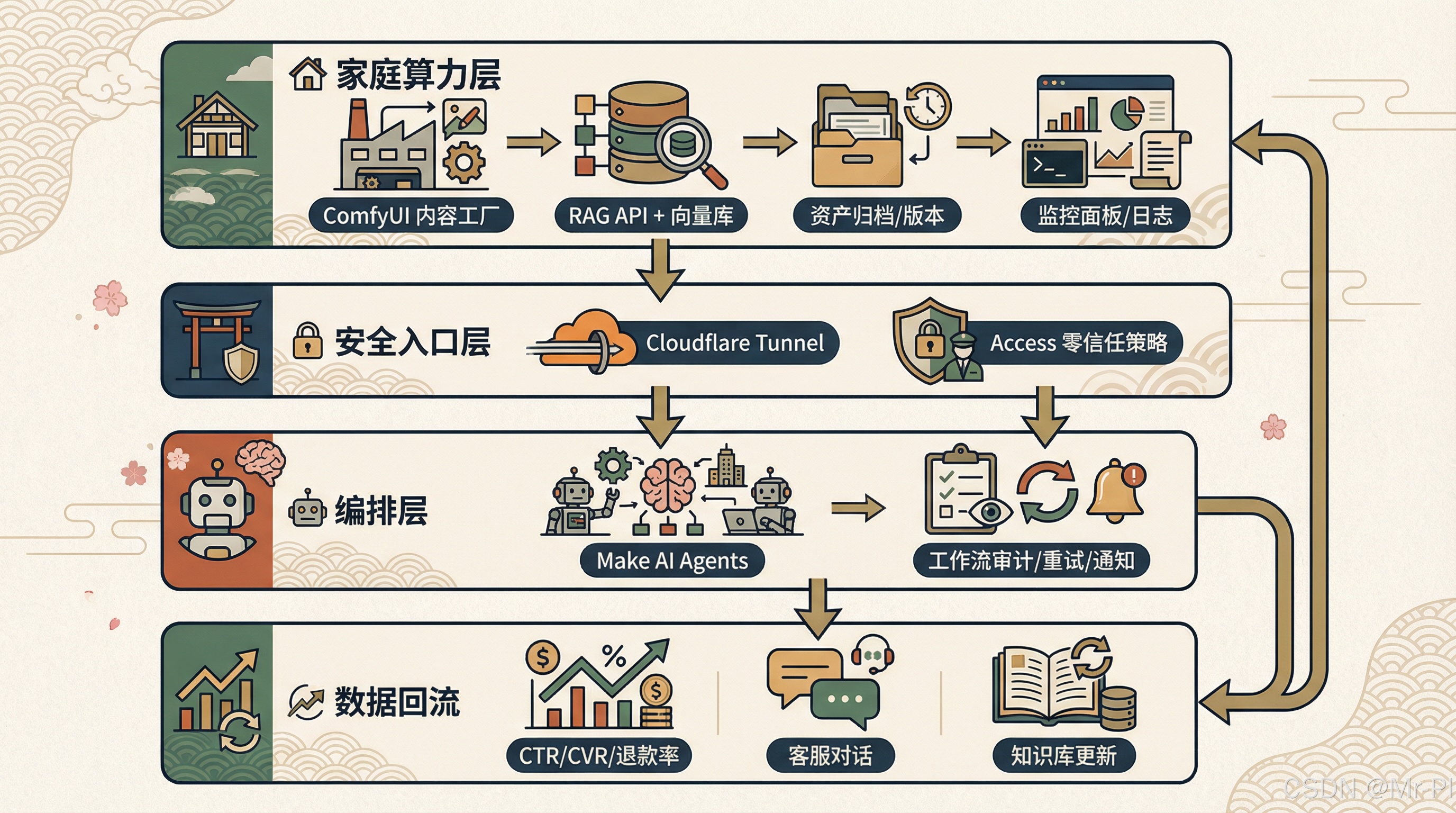
当你的系统以“服务化”存在时,主机的核心 KPI 变成:
可用性(24×7)+ 运维复杂度 + 入口安全 + 成本可控。
2)四台机器的“工程化对比表”
| 设备 | 京东价 | CPU / GPU | 内存 / 硬盘 | 更适合 RAG? | 更适合 ComfyUI? | 工程化关键点评 |
|---|---|---|---|---|---|---|
| Mac Studio M2 Ultra | ¥18,000 | 24 核 CPU / 60 核 GPU | 64G / 1T | 强:多服务并发余量更大 | 强:适合稳定批量出图与资产管线 | 桌面工作站形态,稳定常开;与 Tunnel/Agent 组合更“机房化” (京东) |
| Mac(M2 Max) | ¥19,000 | 12 核 CPU / 30 核 GPU | 32G / 4T | 中:32G 更容易被“多服务常驻”顶满 | 中-强:单任务没问题,但并发余量偏紧 | 存储很香,但你这套“常开服务栈”更吃内存 |
| ROG 枪神9 Plus 5070Ti | ¥16,000 | U9-14900HX / RTX 5070Ti(Laptop) | 32G / 1T | 中:能跑,但长期常开不如台式形态省心 | 强:CUDA生态友好(但要接受噪音与功耗墙) | 笔记本形态更像“移动算力”,不是最佳“机房基座” (京东) |
| 金河田主机(i9+4090) | ¥12,000 | i9 / RTX 4090(Desktop) | 32G / 1T | 中:RAG OK,但要考虑服务栈维护 | 极强:4090 对 ComfyUI 吞吐非常友好 | 性能强、价格香;但“工程化维护/驱动/故障面/噪音功耗”成本要算进去 (京东) |
你会发现:金河田4090主机的“纯ComfyUI吞吐/性价比”非常吸引人,但你这专栏卖的是“能交付的系统”,而不是“能跑的显卡”。
3)把“RAG vs ComfyUI”的真实负载讲清楚:为什么你更需要 64G
3.1 RAG 更像“常驻服务”,吃的是并发与稳定
典型 RAG 生产态会常驻:
- API 服务(FastAPI/Streamlit 管理页)
- 向量库与索引(本地或容器)
- 日志、评测、审计、任务队列
- 监控面板(Grafana/自研)
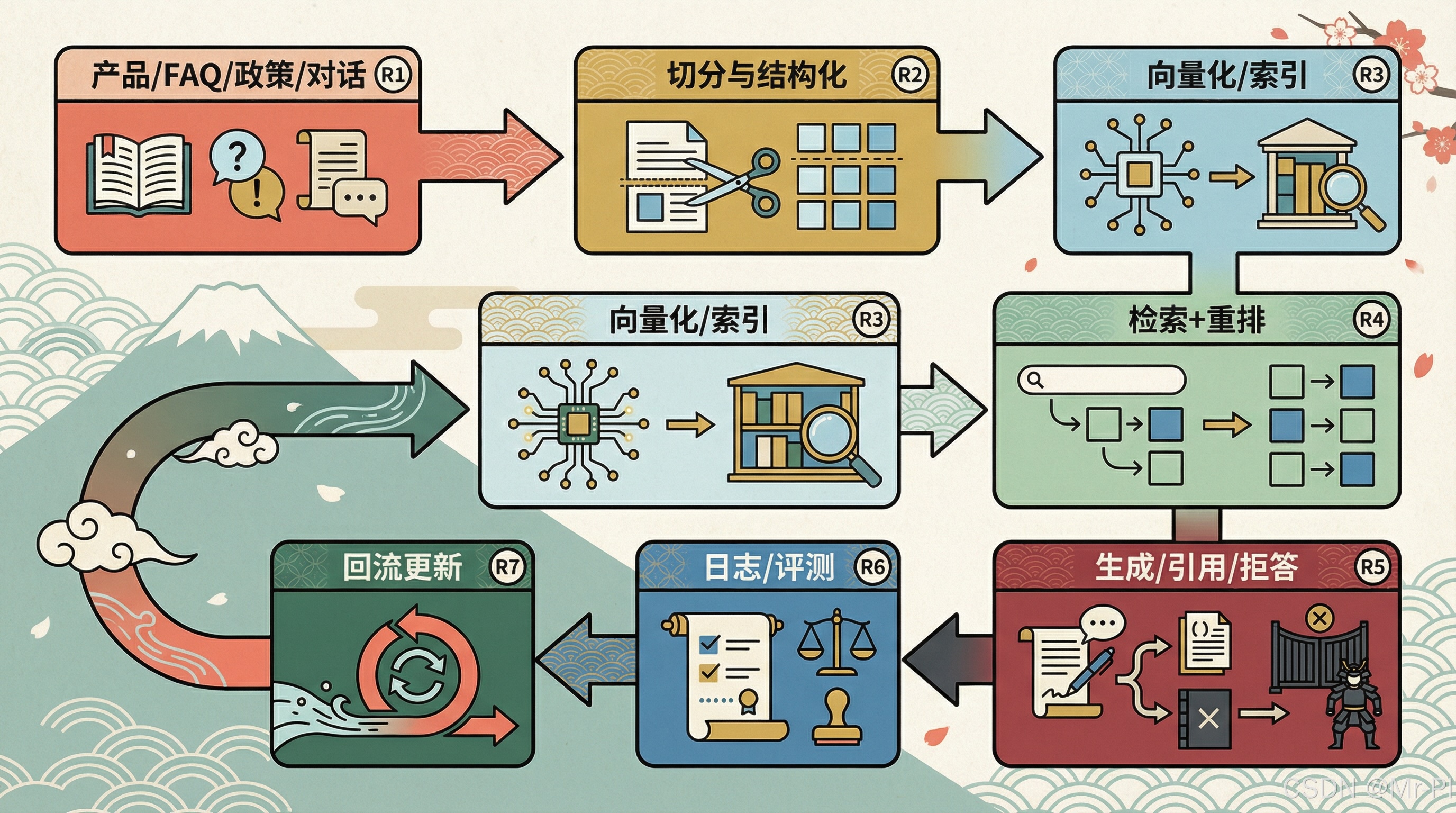
这会把机器的压力从“峰值”变成“基线”,32G 很容易被服务常驻 + 缓存 + 并发顶满,尤其当你还要同时跑 ComfyUI 队列。
3.2 ComfyUI 更像“批处理工厂”,吃的是吞吐与磁盘组织
ComfyUI 的工程化痛点通常不是“能不能出一张图”,而是:
- 一次要跑 50/100/500 张
- 要有一致性(风格、光照、构图)
- 要可回溯(参数、模型版本、素材版本、质检评分)
- 要可归档(SKU→素材→上架包)
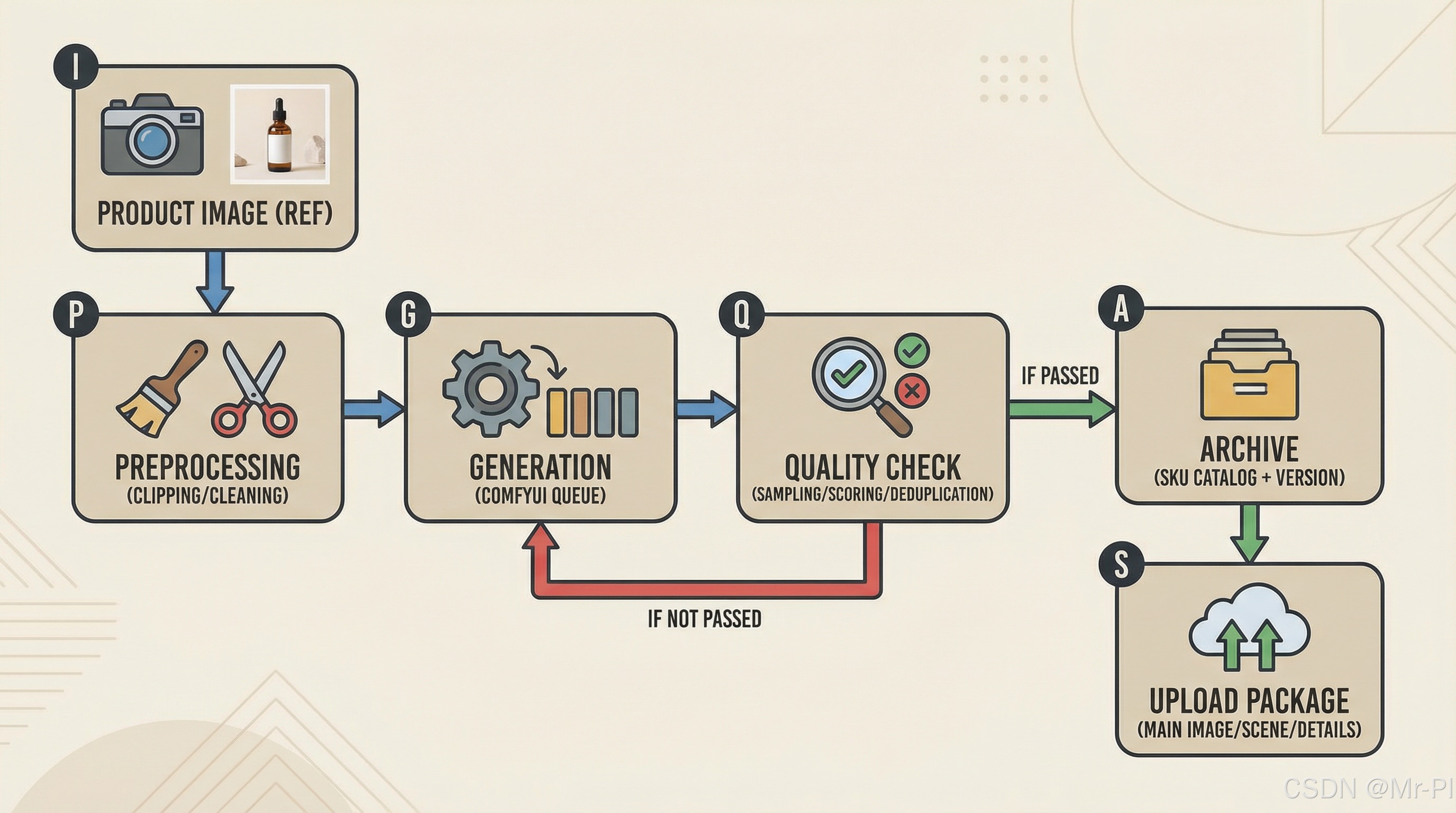
在这个“内容工厂”模式里,稳定常开 + 任务队列可控比“单次峰值”更重要;同时,RAG 与 ComfyUI 并行时,内存余量就是稳定性。
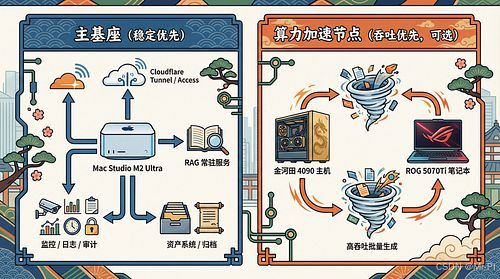
4)为什么“4090 台式机很香”,但仍不作为本专栏的主基座
我建议你在专栏中用一句工程化的定义来区分:
- 主基座:负责“入口安全、服务常驻、审计与资产治理”,要求低维护、低故障面、7×24可用
- 算力加速节点:负责“高吞吐生成任务”,允许阶段性高维护(驱动/模型/兼容/超频/风道)
金河田 4090 主机在“算力加速节点”上非常强;但作为“主基座”,你需要额外承担:
- Windows/Linux 驱动与 CUDA 生态维护成本
- 机箱风道、噪音、功耗、硬件稳定性(尤其 24×7)
- 故障时的排查链路更长(硬件、驱动、依赖、容器、网络)
而 Mac Studio M2 Ultra 更像“家用机房 appliance”:稳定在线、管理简单、与你的 Tunnel/Agent 编排路线高度契合。(京东)
5)为什么不是 M2 Max:4T 诱人,但你这条生产线更看重“并发余量”
M2 Max 这套(32G + 4T)最容易踩的坑是:存储不紧张,但内存先紧张。
当你同时跑:
- ComfyUI 队列(含模型缓存)
- RAG API + 向量库
- 资产归档与索引
- 监控与审计
你会发现“4T 很舒服”,但“32G 很容易顶满”,然后系统开始交换、延迟抖动,最终影响的是“整体生产线的稳定交付”。
因此本专栏为了“工程可复制”,更推荐先把“基座稳定”做成模板:64G 是更稳的起点。
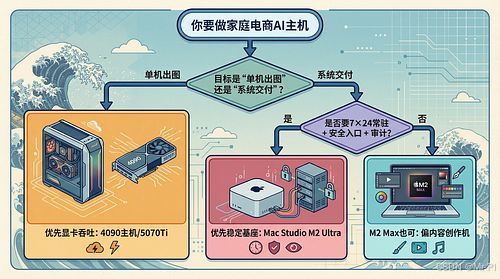
6)本章结论(可直接作为专栏“选型结论段”)
- 金河田 i9+4090(¥12,000):在 ComfyUI 吞吐/性价比上非常有竞争力,更适合作为“算力加速节点”。
- ROG 5070Ti(¥16,000):适合“移动算力/兼顾游戏与生产力”,但不建议作为“家庭机房主基座”。
- M2 Max(¥19,000,32G+4T):存储优势明显,但在“多服务常驻并发”场景下,32G 更容易成为系统级瓶颈。
- 最终选择:Mac Studio M2 Ultra(¥18,000,64G+1T):更符合“家庭私有 AI 生产机房”的工程目标:稳定常开、运维省心、与 Tunnel + Agent 编排的体系协同最好。(京东)
下一章
《第 2 篇:本地目录与资产标准》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 47
47 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)