即插即用系列 | SPL 2024 PFT-SR 详解,融合 Transformer 与注意力机制的新型图像超分辨率
🔥 AI 即插即用 | CV涨点模块"军火库"开源!🔥 本文介绍了一个开源GitHub仓库,汇集了CV领域的即插即用模块、论文解读和SOTA模型创新模块。重点解析了CVPR2025的PFT-SR方法,该文提出渐进式聚焦Transformer,通过跨层传递注意力图实现计算预过滤,显著降低Transformer的计算冗余。核心创新包括:1)渐进式聚焦注意力(PFA)机制;2)稀
论文名称:Progressive Focused Transformer for Single Image Super-Resolution
论文原文 (Paper):https://arxiv.org/abs/2503.20337
官方代码 (Code):https://github.com/LabShuHangGU/PFT-SR
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
本论文的完整复现代码(即插即用版)已更新至专栏
即插即用系列(代码实践) | SPL 2024 PFT-SR 详解,融合 Transformer 与注意力机制的新型图像超分辨率
1. 核心思想
- 本文提出了一种用于图像超分辨率(SR)的渐进式聚焦 Transformer(Progressive Focused Transformer, PFT)。其核心思想是解决标准 Transformer 注意力机制中的计算冗余问题,即模型会浪费大量算力去计算查询(Query)与不相关特征(Key)之间的相似度。
- 为此,本文设计了渐进式聚焦注意力(Progressive Focused Attention, PFA)机制。PFA 的关键创新在于它在相邻的 Transformer 层之间传递和继承注意力图(Attention Map),通过逐层** Hadamard 积(逐元素乘法)**来动态地、渐进地增强重要特征的权重,同时裁剪掉不相关的特征。
- 这种“聚焦”机制不仅能显著降低计算量(允许使用更大的窗口),还能迫使模型更专注于关键纹理,从而实现 SOTA 级别的 SR 性能。
2. 背景与动机
-
Transformer 因其强大的非局部依赖建模能力,在图像超分辨率(SR)任务上取得了巨大成功。然而,这种能力的代价是高昂的计算成本。标准自注意力机制的计算复杂度与 Token 数量(即窗口大小)呈平方关系。
这导致了两个核心问题:
- 计算冗余与性能下降: 为了计算一个查询(Query patch)的输出,模型需要计算它与窗口内所有其他 Token 的相似度。这包含了大量与当前查询完全不相关的 Token。这些无效的相似度计算不仅是巨大的计算浪费,而且这些不相关的 Token 会获得非零的权重,从而干扰最终的特征聚合,导致重建性能下降。
- 窗口大小受限: 由于平方复杂度的限制,大多数模型(如 SwinIR)被迫使用较小的窗口(例如 8 × 8 8 \times 8 8×8 或 16 × 16 16 \times 16 16×16)来控制计算量。这又违背了 Transformer 捕捉“长程依赖”的初衷,限制了模型的感受野和性能上限。
因此,本文的动机是:如何设计一种注意力机制,使其能够自动识别并“跳过”那些不相关的 Token,从而在降低计算成本的同时,允许模型使用更大的窗口来捕捉更丰富的特征?
-
动机图解分析(Figure 1 & 3):
-
图表 A (Figure 1):揭示“无效计算”问题
- “看图说话”: 这张图对比了三种注意力机制。
- (a) Self-Attention (标准自注意力): 展示了问题的根源。Query patch(蓝色星标)需要与窗口内的所有 Token(灰色网格)进行计算。其注意力图(Attention weight,红色热图)显示,即使是完全不相关的区域(如天空)也会获得非零权重,并在多层传递中持续干扰。
- (b) Sparse Attention (稀疏注意力): 这是现有的解决方案之一(如 top-k)。它能在计算后过滤掉权重小的 Token(变为白色),但其计算过程(Attention calculation region)仍然是密集的,即它还是需要计算 Query 与所有 Token 的相似度,计算成本并未降低。
- © Progressive Focused Attention (PFA, 本文方案): 这展示了本文的核心动机。PFA 机制通过从前一层(Layer 2)继承注意力图,提前“预知”哪些区域是不相关的。因此,在计算 Layer 3 时,它只计算少数几个“可能相关”的块(灰色块),跳过了(skip)大量不相关的计算。随着层数加深(Layer 4, n),这个“计算区域”变得越来越稀疏和聚焦。
- 结论: Figure 1 明确指出,PFA 要解决的核心问题是降低注意力的“计算”复杂度,而不仅仅是“聚合”复杂度,从而允许模型使用更大的窗口(如图中 32 × 32 32 \times 32 32×32)。
-
图表 B (Figure 3):验证“聚焦”效果
- “看图说话”: 这张图在真实图像上验证了 Figure 1 的理念。
- 分析:
SA(标准自注意力)和Top-k的注意力热图都非常弥散,权重分布在许多不相关的区域(例如,Query是窗户,但SA却关注了天空和远处的建筑)。 - 结论:
PFA(本文方法)的注意力热图则极其干净和聚焦。它从第一层开始就逐渐过滤掉了无关背景,到了第18层,注意力权重几乎只集中在具有相似结构(其他窗户)的 Token 上。这证明了 PFA **“渐进聚焦”**的有效性。
-
3. 主要贡献点
-
提出 PFA(渐进式聚焦注意力)机制:
- 这是核心创新。PFA 的关键在于跨层连接注意力图。
- 它通过将当前层计算出的注意力图 A c a l l A_{cal}^{l} Acall 与前一层继承的注意力图 A l − 1 A^{l-1} Al−1 进行 Hadamard 积(逐元素乘法)。
- 这种“渐进式”的乘法操作有两个好处:1) 权重增强: 持续相关的 Token 权重会被累积增强;2) 噪声抑制: 不相关的 Token 权重会迅速衰减至零。
-
实现计算预过滤(Pre-filtering):
- PFA 最大的优势在于节省计算量。它利用前一层的注意力图 A l − 1 A^{l-1} Al−1 作为“索引”( I l − 1 I^{l-1} Il−1)。
- 在计算第 l l l 层的相似度 A c a l l A_{cal}^{l} Acall 时,模型只计算 A l − 1 A^{l-1} Al−1 中标记为“重要”(非零)的 Token。
- 这使得 PFA 能够跳过(skip)大量不必要的相似度计算,从而在计算量不变的情况下,支持更大的窗口尺寸(例如 32 × 32 32 \times 32 32×32)。
-
开发 SMM 高效 CUDA 算子:
- 上述的“预过滤”机制如果用标准的 PyTorch 矩阵乘法(GEMM)来实现会非常低效。
- 作者为此专门开发了高效的 CUDA 核(Kernels) 来实现稀疏矩阵乘法(Sparse Matrix Multiplication, SMM)。
- 这个工程上的贡献是 PFT 模型能够达到与 SOTA 方法相媲美的实际推理速度(Inference speed)的关键。
-
构建 PFT(渐进式聚焦 Transformer)架构:
- 论文基于 PFA 模块构建了完整的 PFT 网络。
- 该架构一个关键设计是逐层递减的保留率 K l K^l Kl。在浅层(Layer 1), K 1 K^1 K1 很大(保留所有 Token),随着层数 l l l 加深, K l K^l Kl 逐渐减小。
- 这种设计使得网络在浅层探索所有可能性,在深层则聚焦于最关键的特征,系统性地安排了计算资源。
4. 方法细节
-
整体网络架构(Figure 2):
- 模型名称: PFT (Progressive Focused Transformer)
- 数据流: 整体架构遵循了(如 SwinIR, HAT 等)标准的 SR Transformer 流程,主要由三部分组成:
- 浅层特征提取: 一个
Conv层从 LR 图像中提取浅层特征。 - 深层特征提取(核心): 主体是一个堆叠了 N 个
PFA Block的残差块。 - 图像重建(Upsample): 一个
Conv层和一个Upsample(通常是 Pixel Shuffle)模块将深层特征重建为 HR 图像。
- 浅层特征提取: 一个
- PFA Block (Figure 2 中间):
- 这是 PFT 的基本单元,它包含 M 个渐进式聚焦注意力层(PFAL)。
- 特征流 x x x 和继承的 PFA 图 A l − 1 A^{l-1} Al−1(红色虚线)同时输入到
PFAL中。 PFAL的结构遵循标准的 Pre-Norm Transformer Layer:- x 1 = P F A ( L a y e r N o r m ( x ) , A l − 1 ) + x x_1 = PFA(LayerNorm(x), A^{l-1}) + x x1=PFA(LayerNorm(x),Al−1)+x
- x o u t = M L P ( L a y e r N o r m ( x 1 ) ) + x 1 x_{out} = MLP(LayerNorm(x_1)) + x_1 xout=MLP(LayerNorm(x1))+x1
- PFA 块的输出是增强后的特征 x o u t x_{out} xout 和新的 PFA 图 A l A^{l} Al(红色虚线), A l A^{l} Al 将被传递给下一个 PFA 块。
-
核心创新模块详解:
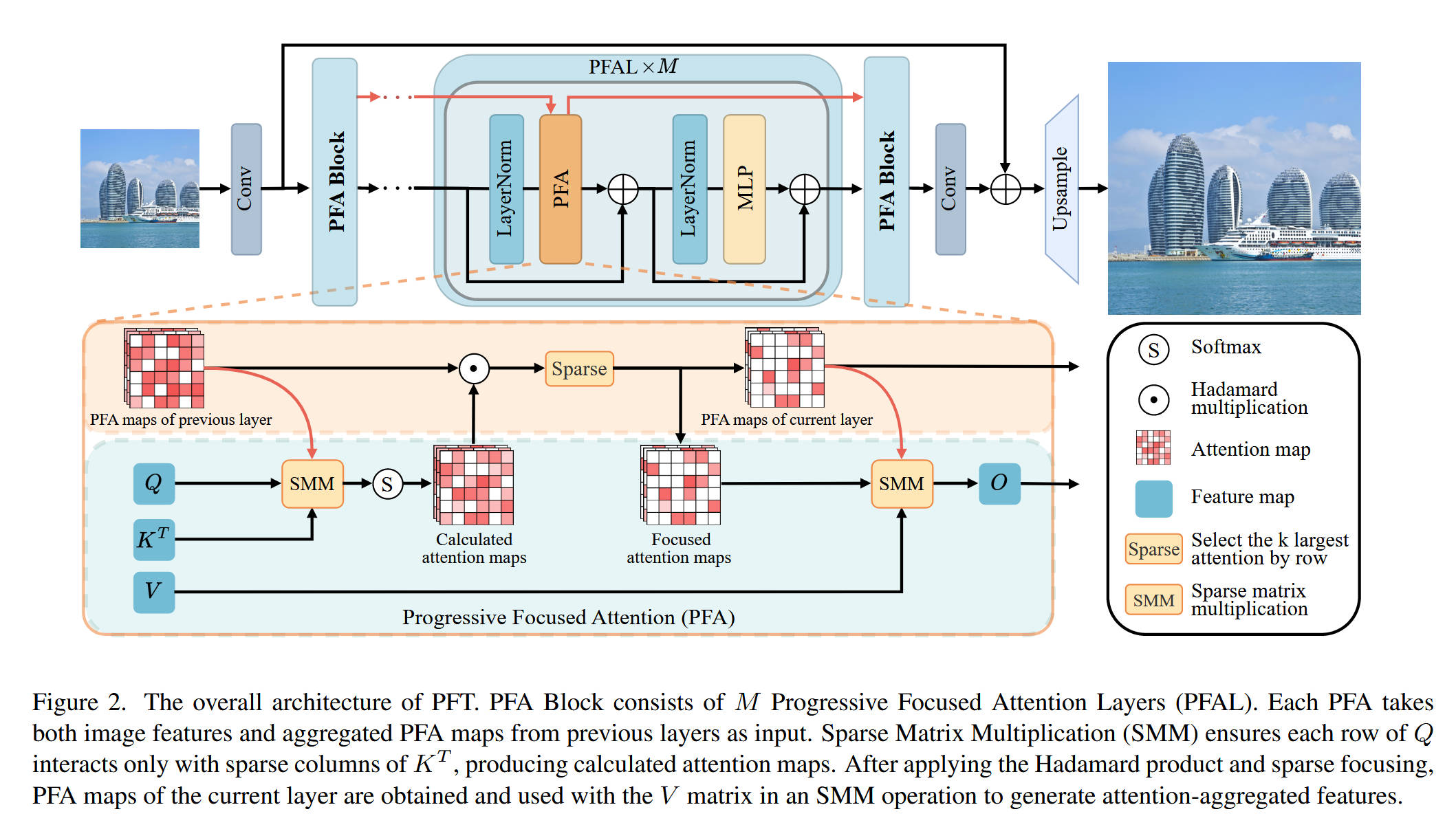
- 对于 模块 A:Progressive Focused Attention (PFA) 层
- 理念: 核心是“继承”和“聚焦”。它接收上一层的注意力图 A l − 1 A^{l-1} Al−1(即
PFA maps of previous layer),并生成当前层的 A l A^l Al(即PFA maps of current layer)。 - 内部结构(数据流):
- 输入: Q , K , V Q, K, V Q,K,V 矩阵和上一层的 A l − 1 A^{l-1} Al−1。
- 计算预过滤(SMM): PFA 的第一步是使用 A l − 1 A^{l-1} Al−1 作为索引(即 I l − 1 I^{l-1} Il−1),通过稀疏矩阵乘法(SMM) 来计算 Q Q Q 和 K T K^T KT 的相似度。
- 计算注意力图(Calculated attention maps): SMM 的输出经过
Softmax得到 A s c l A_{sc}^{l} Ascl。 - 渐进式融合(Hadamard 积): A s c l A_{sc}^{l} Ascl 与继承来的 A l − 1 A^{l-1} Al−1 进行逐元素相乘(Hadamard multiplication, ⊙ \odot ⊙)。这一步是“渐进式”的关键:它强化了连续被关注的 Token,抑制了偶然被关注的 Token。
- 聚焦与稀疏化(Sparse): 融合后的注意力图经过一个
Sparse操作(即 S K l \mathcal{S}_{K^l} SKl,top-k 选择),只保留 K l K^l Kl 个最大的权重,生成Focused attention maps(即 A l A^l Al)。 - 特征聚合(SMM): PFA 的第二步是使用这个新生成的、稀疏的 A l A^l Al 作为索引,再次通过 SMM 来聚合 V V V(Value)矩阵,生成最终的输出特征 O O O。
- 输出: PFA 层输出 O O O(用于特征路径)和 A l A^l Al(用于下一层的 PFA)。
- 理念: 核心是“继承”和“聚焦”。它接收上一层的注意力图 A l − 1 A^{l-1} Al−1(即
- 对于 模块 A:Progressive Focused Attention (PFA) 层
-
理念与机制总结:
- PFA vs. Sparse Attention (SA):
- Sparse Attention(如图 1b)是“先计算(所有),后过滤”。它计算 N × N N \times N N×N 的相似度,然后取 top-k。计算成本没有减少。
- PFA(如图 1c)是“先过滤(索引),后计算”。它利用 A l − 1 A^{l-1} Al−1 索引,在 l l l 层只计算 N × K l − 1 N \times K^{l-1} N×Kl−1 的相似度。计算成本显著降低。
- 公式总结:
- A s c l = S o f t m a x ( Ψ ( Q l , ( K l ) T , I l − 1 ) ) A_{sc}^{l} = Softmax(\Psi(Q^l, (K^l)^T, I^{l-1})) Ascl=Softmax(Ψ(Ql,(Kl)T,Il−1)) ( Ψ \Psi Ψ 是 SMM 稀疏计算)
- A l = S K l ( N o r m ( A s c l ⊙ A l − 1 ) ) A^l = \mathcal{S}_{K^l}(Norm(A_{sc}^{l} \odot A^{l-1})) Al=SKl(Norm(Ascl⊙Al−1)) (Hadamard 积融合 + Top-k 稀疏化)
- I l = S i g n ( A l ) I^l = Sign(A^l) Il=Sign(Al) (生成下一层的索引)
- 计算复杂度:
- 标准 SA 的注意力计算复杂度为 Ω ( S A ) = ⋯ + 2 W 2 h w L C \Omega(SA) = \dots + 2W^2hwLC Ω(SA)=⋯+2W2hwLC。
- PFA 的注意力计算复杂度为 Ω ( P F A ) = ∑ l = 1 L ( ⋯ + 2 α ( l − 1 ) W 2 h w C ) \Omega(PFA) = \sum_{l=1}^{L}(\dots + 2\alpha^{(l-1)}W^2hwC) Ω(PFA)=∑l=1L(⋯+2α(l−1)W2hwC)。
- 随着层数 l l l 增加, α ( l − 1 ) \alpha^{(l-1)} α(l−1) 项呈指数级衰减,导致 PFA 的计算量远低于 SA,这使得 PFT 可以负担 32 × 32 32 \times 32 32×32 的大窗口。
- PFA vs. Sparse Attention (SA):
-
图解总结:
- Figure 1 提出了问题((a) SA 和 (b) Sparse Attention 均存在计算冗余)和解决方案(© PFA 通过继承注意力图来跳过计算)。
- Figure 3 定性验证了 PFA 的有效性:相比 SA 和 Top-k 的弥散注意力,PFA 的注意力图(热图)极其聚焦于相关的纹理。
- Figure 5(附录) 进一步逐层展示了 PFA 的“渐进式”特性:在 Layer 0,注意力是弥散的;随着层数加深(Layer 2 → \rightarrow → 8 → \rightarrow → 14 → \rightarrow → 22),注意力图越来越稀疏、越来越锐利,完美地聚焦到了与 Query Patch(如窗框)具有相同结构(如平行的窗框线)的 Token 上。
- Figure 2 展示了 PFA 如何被集成到PFT 整体架构中,通过 SMM 和 Hadamard 积实现上述的聚焦过程。
5. 即插即用模块的作用
本文的核心创新 PFA(渐进式聚焦注意力) 是一个有状态(stateful)的机制,它被封装在 PFAL (渐进式聚焦注意力层) 和 PFA Block 中。它适用于任何需要堆叠 Transformer 层的深度网络架构。
-
适用场景 1:替代标准 Transformer 块(如 ViT, SwinIR, HAT)
- 应用: 在 SR 任务中,用
PFA Block替换现有的(如SwinIR Block或HAT Block)残差块。 - 优势:
- 更优的性能: PFA 通过跨层注意力相乘,能更精确地识别和增强关键特征,同时抑制不相关特征的干扰,从而提高 SR 重建质量。
- 更高的效率/更大的感受野: PFA 的 SMM 计算预过滤机制显著降低了计算量。这使得模型可以在相似的 FLOPs 下使用更大的窗口尺寸(例如从 16 × 16 16 \times 16 16×16 提升到 32 × 32 32 \times 32 32×32)。Ablation 实验证明,窗口越大,性能越好。
- 应用: 在 SR 任务中,用
-
适用场景 2:计算受限的轻量级 SR 模型
- 应用: 构建
PFT-light轻量级模型。 - 优势: PFA 的指数级计算衰减特性,使其在浅层网络中也能快速聚焦。
PFT-light在 Urban100 (x4) 上比ATD-light快 20.1%,同时 PSNR 更高。
- 应用: 构建
-
适用场景 3:其他视觉任务(未来工作)
- 应用: PFA 的理念(跨层聚焦、跳过无效计算)是通用的。
- 优势: 它可以被应用于其他需要深度 Transformer 且受计算量困扰的高层视觉任务(如检测、分割)或自然语言处理(NLP)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)