收藏必备!大模型开发指南:AI代理(Agent)评估全攻略 - 从编码到对话的实战方法
本文系统介绍了四种AI代理的评估方法:编码Agent侧重代码质量和执行过程评估;对话Agent关注任务完成度和交互体验;研究Agent强调搜索全面性和来源可靠性;计算机使用Agent则评估界面操作和后端逻辑。提出了pass@k(潜力)和pass^k(稳定性)两个关键指标,为各类AI代理提供了多维度的性能评估框架,包括代码规范、交互质量、研究深度等具体评估维度,并通过典型案例展示了评估指标的实际应用
文章详细介绍了四种AI代理的评估方法:编码Agent(代码质量和执行过程)、对话Agent(最终状态和交互质量)、研究Agent(搜索全面性和来源可靠性)以及计算机使用Agent(界面操作和后端逻辑)。提出了pass@k(衡量潜力)和pass^k(衡量稳定性)两个关键评估指标,全面评估AI代理的性能和可靠性。
揭秘 AI 代理的评估 - 多种Agent的评估方法
前言:
本文中是具体的几种Agent类型的评估方法,编码Agent、研究搜索Agent、对话聊天Agent、计算机操作Agent等
一、评估编码 Agent 的方法
编码 Agent 的主要任务:编写、测试和调试代码,像人类开发者一样在代码库中检索浏览,所以编码 Agent 是依赖于明确指定的任务,根据这一点,我们可以知道:确定性评分器非常适合编码 Agent
🌴 第一方面的评估要点是:代码能否运行、测试是否通过
这里介绍两种编程基准
-
- SWE-bench Verified
-
- Terminal-Bench
1、Terminal-Bench 这个的理解就是:其不是修复单一的编译错误,而是完成整个编译过程,这个就是端到端的测试,从开始到结束,例如:部署 Web 应用、从零搭建 Mysql 数据库
2、SWE-bench Verified 是一种“单元测试”,常规的使用方法:
- • 给 Agent 一个真实的问题
- • Agent 开始编写修复代码
- • 运行测试套件,保证 Agent 编写的修复代码可以通过测试

🌴 第二方面的评估要点是:Agent 的工作过程是否合理高效
当你有了测试案例集|测试函数来验证编码 Agent 执行的任务的结果的时候,评估编码 Agent 的工作过程也是很有用的,不仅要单一的评估测试结果是否通过,也要观察评估完成任务的过程是否合理以及优雅
这个时候有两种额外的评估方法
-
- 基于启发式规则的代码质量评估:也就是用代码规则来检查代码质量,而不是只看测试结果
- • 代码的复杂度
- • 代码的重复率
- • 命名的规范
- • 安全漏洞
- • 性能问题
- • 代码的可读性
-
- 基于模型的行为评估:用 大模型去评估 Agent 的执行任务的中间过程,也就是行为
例如:任务 A - 查询数据库中的用户信息
AgentA 的做法:直接查询所有用户的信息,在内存中进行过滤
AgentB 的做法:用 where 语句条件查询用户信息,最后返回需要的数据
在这种情况下,虽然 A 与 B 都完成了任务,但是 AgentB 其实是做得更好的,更符合规范的
🌟 结论:编码 Agent 的评估,要评估两个主要方向,编码 Agent 的执行结果和执行过程
案例:这是一个完整的案例,实际使用的时候可以动态调整,不必全部都有
task:
id: "fix-auth-bypass_1" # 任务ID:修复认证绕过漏洞_1
desc: "修复当密码字段为空时的认证绕过漏洞..."
graders: # 评分器
- type: deterministic_tests # 确定性测试
required:
- test_empty_pw_rejected.js # 拒绝空密码的测试
- test_null_pw_rejected.js # 拒绝null密码的测试
- type: llm_rubric # LLM评分标准
rubric: prompts/code_quality.md # 代码质量评分提示词文件
- type: static_analysis # 静态代码分析
commands:
- eslint # 代码风格检查
- tsc # TypeScript类型检查
- type: state_check # 状态检查
expect:
security_logs:
event_type: "auth_blocked" # 期望安全日志中有认证阻止事件
- type: tool_calls # 工具调用检查
required:
- tool: read_file
params:
path: "src/auth/*" # 读取认证代码
- tool: edit_file # 编辑文件
- tool: run_tests # 运行测试
tracked_metrics: # 追踪指标
- type: transcript # 对话记录指标
metrics:
- n_turns # 对话轮数
- n_toolcalls # 工具调用次数
- n_total_tokens # 总token消耗
- type: latency # 延迟指标
metrics:
- time_to_first_token # 首token时间
- output_tokens_per_sec # 输出速度(tokens/秒)
- time_to_last_token # 总完成时间
二、评估对话 Agent 的方法
对话代理在与用户互动时,涉及支持、销售或辅导等领域。与传统聊天机器人不同,它们会保持状态、使用工具,并在对话中途采取行动。
虽然编程和研究代理也可能涉及与用户的多次互动,但对话代理呈现出一个独特的挑战:互动本身的质量也是你评估的一部分。
对话代理的有效评估通常依赖于可验证的最终状态结果和能够捕捉任务完成与互动质量的评分标准。
与其他大多数评估不同,它们通常需要第二个 LLM 来模拟用户。我们使用这种方法在我们的对齐审计代理中,通过长时间的对抗性对话来测试模型。
🌴 第一方面的评估要点:可验证的最终状态,也就是对话 Agent 最终要完成的任务,例如:客服退款、修改收货地址、生成报价单等
🌴 第二方面的评估要点:相比其他类型 Agent 的独特的挑战:互动本身的质量也是你评估的一部分
例如:场景 - 客服退款
Agent A:
用户:“我要退款”
Agent:“订单号?”
用户:“12345”
Agent:“已退款”
任务完成 但态度生硬
Agent B:
用户:“我要退款”
Agent:“很抱歉给您带来不便。请问是哪个订单呢?”
用户:“12345”
Agent:“我查到了您的订单,符合退款条件。我现在为您处理,预计3-5个工作日到账。还有其他需要帮助的吗?”
任务完成 交互体验好
结论:所以对话 Agent 的评估标准是:最终状态验证 + 交互质量的评估
一个对话 Agent 是否有效的标准可以是多维度的:
-
- 用户的问题和诉求是否解决(状态检查)、
-
- 是否在 10 轮对话中完成(文本上下文的约束)、
-
- 语气是否恰当(LLM 来评估)
有两个多维度的测试基准,其模拟了零售支持和航空预订等领域的多轮交互,其中使用了一个 LLM 扮演用户角色,这两个测试基准:𝜏-Bench 及其后续版本τ2-Bench
在开发类似场景和领域的客服对话 Agent,可以使用这两个测试基准来评估自己开发的 Agent 是否有效
一个测试评估案例,对话 Agent 处理沮丧用户的退款
graders:
# 1. LLM评分标准
- type: llm_rubric
rubric: prompts/support_quality.md # 客服质量评分提示词文件
assertions: # 列出来的评分的重点角度
- "Agent对客户的沮丧表现出同理心"
- "解决方案被清晰地解释"
- "Agent的回复基于fetch_policy工具的结果"
# 2. 状态检查
- type: state_check
expect: # 期望的最终状态
tickets:
status: resolved # 工单状态:已解决
refunds:
status: processed # 退款状态:已处理
# 3. 工具调用检查
- type: tool_calls
required: # 必须调用的工具
- tool: verify_identity # 验证身份
- tool: process_refund # 处理退款
params:
amount: "<=100" # 金额必须 ≤ 100
- tool: send_confirmation # 发送确认
# 4. 对话记录约束
- type: transcript
max_turns: 10 # 最大对话轮数:10轮
tracked_metrics: # 追踪指标
# 1. 对话记录指标
- type: transcript
metrics:
- n_turns # 对话轮数
- n_toolcalls # 工具调用次数
- n_total_tokens # 总token消耗
# 2. 延迟指标
- type: latency
metrics:
- time_to_first_token # 首token时间
- output_tokens_per_sec # 输出速度(tokens/秒)
- time_to_last_token # 总完成时间
三、评估研究 Agent 的方法
研究 Agent 的主要任务是:研究代理收集、综合和分析信息,然后产生输出,如答案或报告
该 Agent 的评估无法类似于编码 Agent 单元测试那么确定,研究 Agent 的输出质量的评估只能是相对任务进行判断,主要是:
- • 全面的搜索和研究
- • 有良好的且正确的来源
并且不同领域的任务,评估的标准也是不一样的,例如:市场研究和技术调研是需要不同的标准
研究 Agent 评估面临独特挑战:专家可能对综合是否全面存在分歧,真实情况会随着参考内容不断变化,而更长、更开放式的输出会为错误创造更多空间
比较有名的测试基准是:BrowseComp
这样的基准测试 AI 代理能否在开放网络中找到针子——这些问题设计得容易验证但难以解决。
BrowseComp 是 OpenAI 发布的一个 AI 代理浏览能力基准测试,专门评估 AI 能否在开放网络中找到"难以发现"的信息。但是答案非常好验证,一般都是一个词或短语,方便开发者进行评估
例如: “在悉尼歌剧院附近的植物园里有一座铜雕塑,雕塑中的男人手里拿着什么物体?”
这个问题需要:
定位悉尼歌剧院附近的植物园
找到该植物园的铜雕塑信息
识别雕塑细节(男人手持物体)
所以构建研究 Agent 的评估的一般方式是:组合多种评分器类型
-
- 基础性检查:检查验证每一个声明都有来源支持吗?
-
- 覆盖性检查:来源里面的关键信息都包含了吗?都使用了吗?
-
- 来源质量检查:引用的资料是否权威,不能因为在网络搜索排名第一就使用它
我们使用一个例子来说明这三种检查的主要方向:
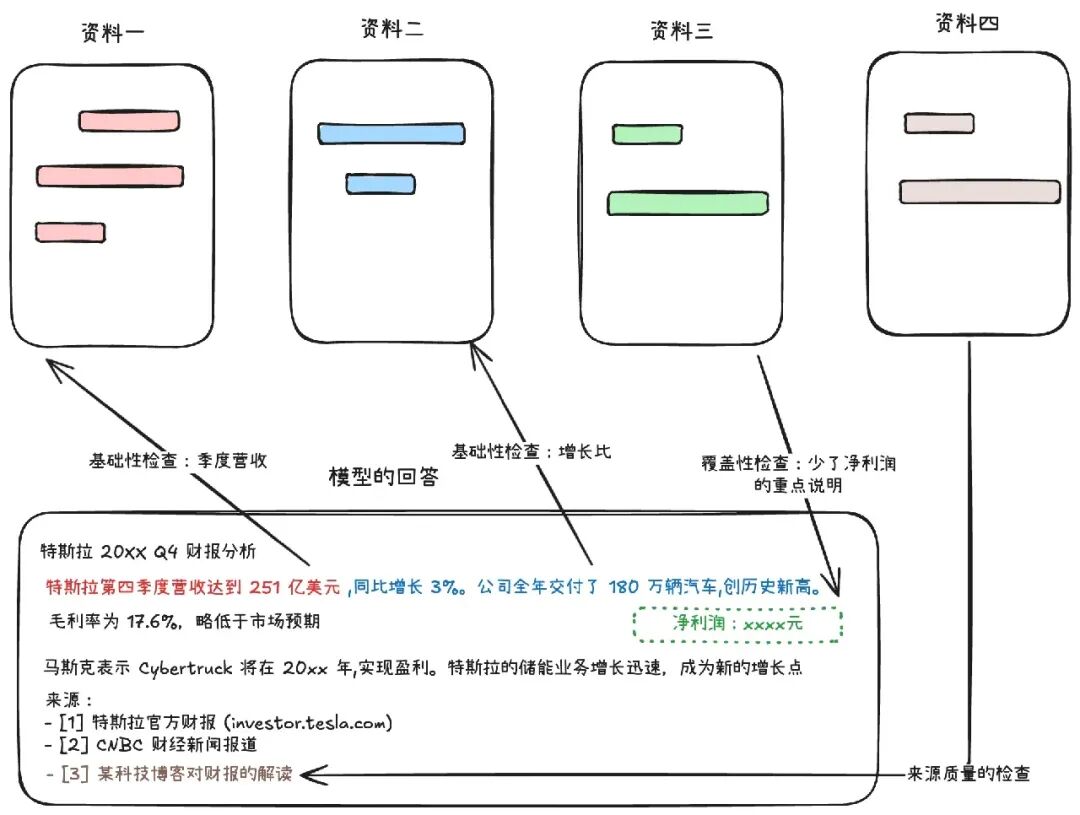
研究Agent的评估
四、评估计算机使用 Agent 的方法
计算机使用 Agent 通过与人类相同的界面与软件交互
- • 屏幕截图
- • 鼠标点击
- • 键盘输入和滚动
而不是通过 API 或代码执行和软件交互,计算机 Agent 可以使用任何带有图像用户界面的程序
那么评估这种类型的 Agent,不仅仅是评估界面是否出现,还要评估软件后面的逻辑是否正确执行,例如:
-
- WebArena 测试基于浏览器的任务,使用 URL 和页面状态检查来验证代理是否正确导航,同时对修改数据的任务进行后端状态验证(确认订单确实已下单,而不仅仅是确认页面出现了)
-
- OSWorld 将此扩展到完整的操作系统控制,评估脚本在任务完成后检查各种产物:文件系统状态、应用程序配置、数据库内容和 UI 元素属性
🌟这一个设计思路非常重要,引用官方原文:
浏览器使用代理需要在 token 效率和延迟之间取得平衡。基于 DOM 的交互执行速度快但消耗大量 token,而基于屏幕截图的交互速度较慢但 token 效率更高。
例如,当要求 Claude 总结维基百科时,从 DOM 中提取文本更高效。当在亚马逊上寻找新笔记本电脑保护套时,截图更高效(因为提取整个 DOM会消耗大量 token)。在我们的 Claude for Chrome 产品中,
我们开发了评估方法来检查代理是否为每个场景选择了正确的工具。这使我们能够更快、更准确地完成基于浏览器的任务
如果要开发一个浏览器的 Agent,那么在执行的行为中可以考虑这个方向:操作 DOM 还是网页截图
-
- 如果网页的文本较多,那么直接读取 DOM 元素回更加的高校,并且信息密度很大,无用的网页标签会大大减少
-
- 如果网页的 DOM 很多,文本信息非常的分散,典型的就是电商网站,商品推荐任务,可以考虑截图,截图会更高效和清晰
五、总结
无论智能体类型如何,智能体行为在每次运行中都会变化,这使得评估结果比最初看起来更难解释。
每个任务都有其自身的成功率可能在某个任务上达到 90%,在另一个任务上只有 50% 一个在某个评估运行中通过的任务,在下一个运行中可能会失败。
有时,我们想要测量的是智能体在某个任务上成功的频率(即试验的比例)
有两个指标有助于捕获这种细微的差异:
1、pass@k 衡量代理在 k 次尝试中至少获得一个正确解决方案的可能性。
🌟 随着 k 的增加,pass@k 分数会上升——更多的“射门机会”意味着至少 1 次成功的几率更高。
50% 的 pass@1 分数意味着模型在评估中第一次尝试就成功完成了半数任务。在编程中,我们通常最关心代理第一次就找到解决方案——pass@1。在其他情况下,只要有一个解决方案有效,提出许多解决方案也是可以的。
例如: pass@3 的案例解释
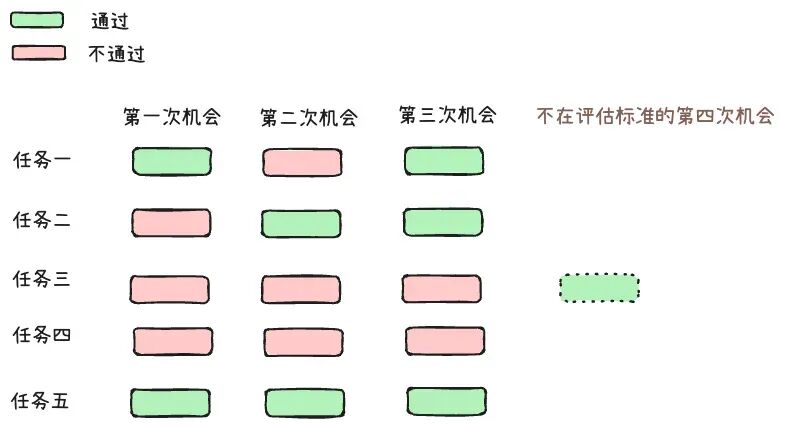
总共有 5 个任务,在 3 次机会里面至少成功一次的有 3 个任务,所以 pass@3 = 60%,可以注意到在任务三中,Agent 在第四次机会执行成功了,但是不作为 pass@3 的判断标准里面了,所以无效
2、pass^k 衡量所有 k 次试验成功的概率。
🌟 随着 k 的增加,pass^k 会下降,因为要求在更多试验中保持一致性是一个更难达到的标准。
如果你的代理每次试验的成功率为 75%,而你运行了 3 次试验,那么全部 3 次试验成功的概率是 (0.75)³ ≈ 42%。这个指标对于面向用户的代理尤其重要,因为用户期望每次都能获得可靠的行为
这两个指标可以作为捕获 Agent 的差异,
-
- 一个表示可用性,pass@k,说明 Agent 的潜力是多少,给足够的机会,它可以做些什么,它的边界在哪里
-
- 一个表示稳定性,pass^k 说明Agent 有多可靠,衡量这个 Agent 在任务中的靠谱性
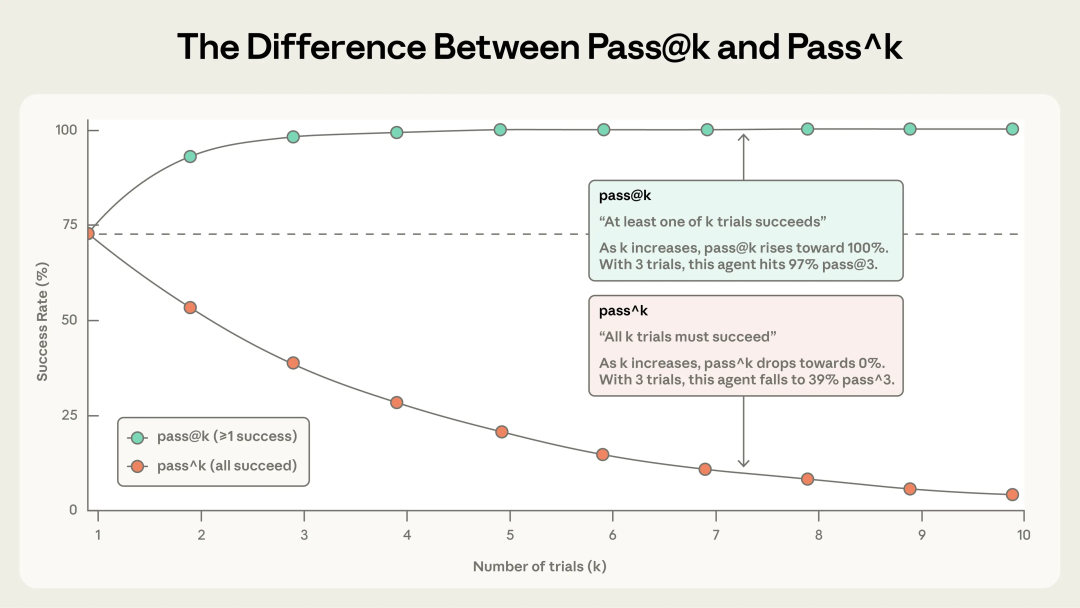
随着试验次数的增加,pass@k 和 pass^k 出现分化。在 k=1 时,它们是相同的(都等于每次试验的成功率)。到 k=10 时,它们呈现出截然相反的情况:pass@k 接近 100%,而 pass^k 降至 0%。
两种指标都很有用,使用哪种取决于产品需求:对于工具,一个成功就很重要,使用 pass@k;对于代理,一致性是关键,使用 pass^k。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
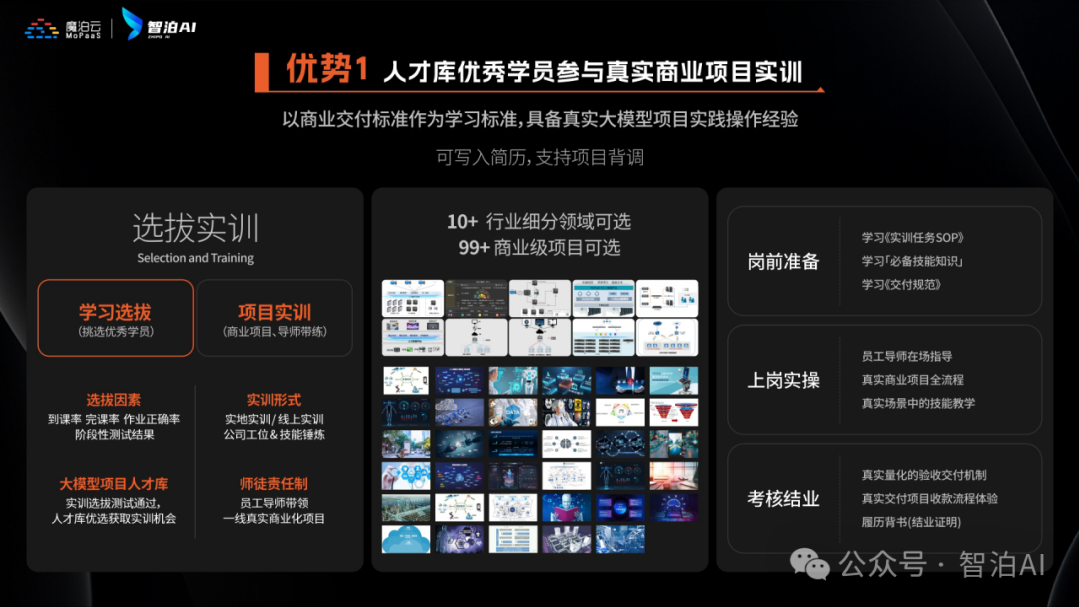
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
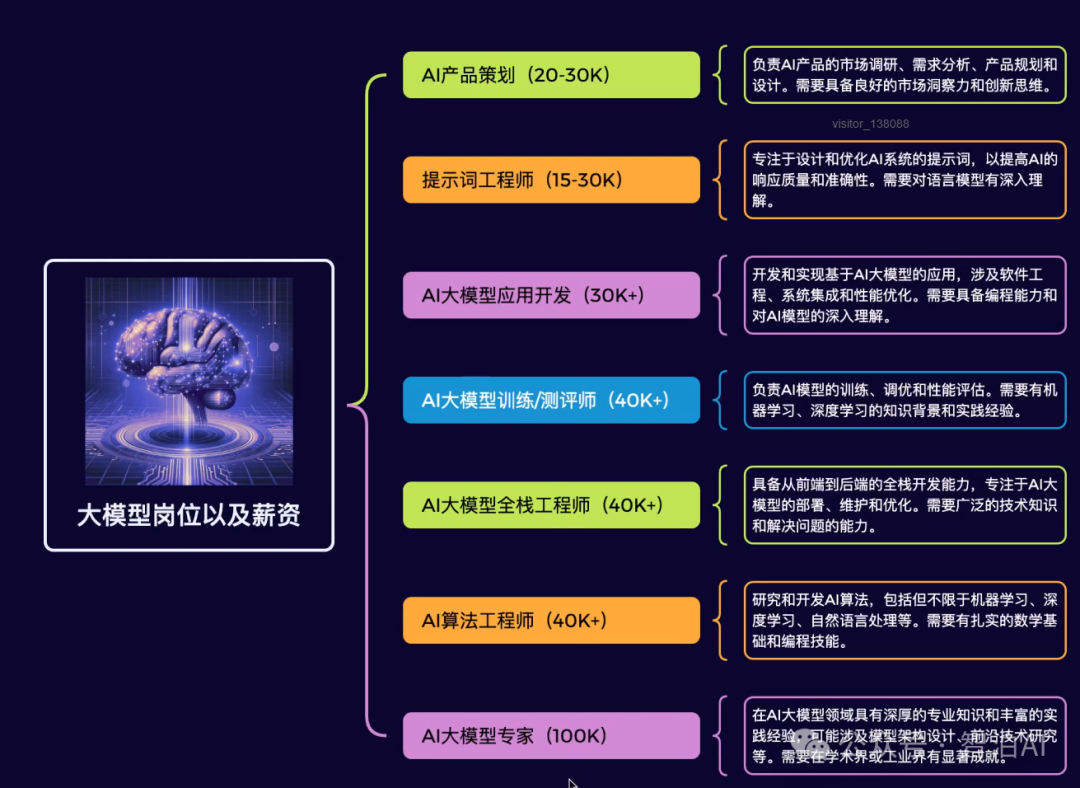
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

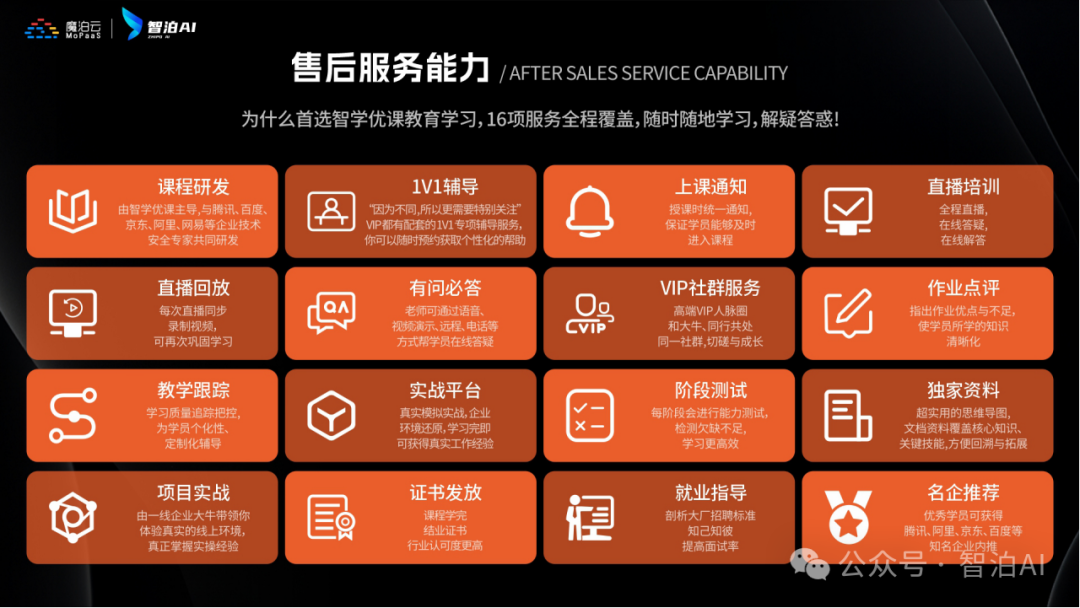
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献224条内容
已为社区贡献224条内容

所有评论(0)