2025 IUICM问题B:新闻传播的用户渗透率完整成品、思路、模型、代码结果分享2025 IUICMProblem B: User Penetration Rate for News Dissemi
摘要:本研究针对TikTok在美国18-29岁群体中的新闻传播现象建立数学模型。问题一采用Logistic和Bass扩散模型分析渗透率增长,结果显示Logistic模型更优(AIC=20722.9,R²=0.991),预测饱和渗透率约58.9%,18-22岁组增长更快但组间差异不显著(p=0.391)。问题二构建改进SIR模型评估事实核查效果,发现核查强度φ=0.411可抑制80.7%虚假新闻传播

背景:据《商业内幕》报道,抖音已超越YouTube和Instagram等平台,成为美国18至29岁人群首选的新闻消费社交媒体应用。为确保新闻传播的真实性与积极引导,抖音推出了包括视频中嵌入文章链接和名为“ 脚注” 的事实核查工具等功能,其运作模式类似于“社区笔记” 。据其官网所述,抖音还与全球130多个市场的独立事实核查机构合作,以验证平台上内容的真实性。
抖音上的新闻传播受用户行为、平台规则和事实核查效率等多种因素影响。准确描绘其传播规律并评估平台干预措施的有效性,对于提高新闻传播质量、维护健康的信息生态系统至关重要。
皮尤研究中心的调查数据显示,社交媒体为18至29岁人群获取新闻的渠道远超其他形式。该年龄段76%的受访者表示会定期或偶尔通过社交媒体关注新闻,相比之下,通过新闻网站获取新闻者占60% ,通过电子邮件通讯获取者仅占28% 。半数受访年轻人对社交媒体新闻内容表现出一定程度甚至高度信任,这一信任度与他们对全国性新闻机构信息的信任水平大致相当。作为新闻获取主要渠道的TikTok人气正迅速攀升。2023年仅有32%的受访者表示会通过该视频应用定期观看新闻。需要特别说明的是,通过TikTok观看新闻与观看《华盛顿邮报》或NBC新闻等传统媒体发布的视频内容存在本质区别。年轻人还将新闻博主的评论以及与时事相关的用户生成视频(如战区或抗议现场的实时画面)视为新闻内容。
一股独立新闻影响者的浪潮正聚焦时事,其中包括菲利普·德·弗兰科和以“地下新闻”报道闻名的维茨 ·“V” ·斯佩哈尔。
包括美国国家公共电台(NPR)旗下《金钱星球》在内的多家专业新闻机构,已开始采用类似策略——将视频内容的核心聚焦于特定创作者,以此增强与受众的信任感和互动性。据商业内幕网采访显示,Z世代社交媒体用户更青睐那些能以真实可靠、接地气的方式传递信息的新闻创作者。除了新闻评论外,社交媒体创作者和播客近几个月来在新闻采集中扮演着越来越重要的角色。
政界人士和政府机构正纷纷转向播客等新型传播渠道;去年的民主党和共和党全国代表大会上,内容创作者更是随处可见。2025年,多位独立创作者申请参加白宫新闻发布会。TikTok在应用内推出了多项新闻功能,例如允许媒体发布商在视频中添加文章链接,以及类似社区笔记模式的“脚注”事实核查工具。根据其官网介绍,TikTok还与“全球130多个市场的独立事实核查机构”合作,共同验证平台内容的真实性。
基于上述背景,收集相关数据,建立数学模型以解决以下四个难度递增的问题。
Background: According to a report by Business Insider, TikTok has overtaken platformssuch as YouTube and Instagram to become the preferred social media application fornews consumption among people aged 18-29 in the United States. To ensure theauthenticity and positive guidance of news dissemination, TikTok has launched featuresincluding article link embedding in videos and a fact-checking tool named "Footnotes",which operates on a model similar to "Community Notes". As stated on its officialwebsite, TikTok has also partnered with independent fact-checking organizations in over130 markets worldwide to verify the authenticity of content on the platform.News dissemination on TikTok is influenced by multiple factors such as user behavior,platform rules, and the efficiency of fact-checking. Accurately depicting its disseminationlaws and evaluating the effectiveness of platform intervention measures are crucial forimproving the quality of news dissemination and maintaining a healthy informationecosystem.
Pew's survey points out that social media accounts for far more news access for peopleages 18 to 29 than other forms. Seventy six percent of people in that age group said theywatched news regularly or occasionally on social media, compared with 60 percent whogot it through news sites and 28 percent who got it through e-mail newsletters. Half of theyoung people surveyed by Pew said they had some or a high degree of trust in socialmedia news content, roughly the same level of trust they had in information from nationalnews organizations. Tiktok's popularity as the main channel for news access is risingrapidly. In 2023, only 32% of respondents said they would watch news regularly throughthe video app. It should be noted that watching news on tiktok is not the same aswatching video content posted by traditional media outlets such as the Washington Postor NBC news. Young people also view comments from news influencers and usergenerated videos related to current events, such as live footage from war zones or protestsites, as news.
A wave of independent news influencers focused on current affairs, including Philip deFranco and the creator Witz "V" Spehar, known for his "under the table news" account.
Some professional news organizations, including NPR's "money planet," have begun tooperate similarly focusing the core of video content on specific creators to enhance trustand connection with audiences. According to interviews with business insider, Gen Zsocial media users prefer news creators who can deliver information in a more authenticand grounded way. In addition to news commentary, social media creators and podcastershave played an increasingly important role in news gathering in recent months.Politicians and government agencies are turning to podcasts and other forms of reachingout to the public; Content creators were ubiquitous at last year's democratic andRepublican congresses. In 2025, a number of independent creators applied to attendWhite House news conferences. Tiktok has introduced a number of news related featureswithin the app, such as allowing media publishers to add links to articles in videos and afact checking tool called footnotes, similar to the community notes model. According toits official website, tiktok also cooperates with "independent fact checking agencies inmore than 130 markets around the world to verify the authenticity of platform content"
Based on the above background, collect relevant data, establish mathematical models tosolve the following four problems with increasing levels of difficulty.
1.1. 问题一. 新闻传播用户渗透率的建模Modeling of User Penetration Rate for News Dissemination
根据18-29岁美国居民社交媒体使用情况的样本数据(包括年龄分层、平均每日使用时长和新闻获取渠道比例;数据格式可假设),TikTok作为新闻类应用在该群体中的渗透率已从2024年的x%上升至当前的y% ,而同期YouTube和Instagram的渗透率则呈现下降趋势。
(1) 选择合适的增长模型(如Logistic模型、Bass扩散模型)拟合TikT- ok新闻渗透率的时间演变曲线,并确定模型的关键参数(如增长率和饱和渗透率)。
(2) 分析年龄分层(18-22岁、23-29岁)对渗透率的影响,并量化不同年龄组用户转化概率的差异。
1.1.1. 模型原理
本问题的核心矛盾在于:TikTok 在年轻人(18–29 岁)中作为新闻获取渠道的渗透既受总体增长动力(新用户采纳与模仿效应)驱动,又受年龄分层差异、基线偏好和样本观测离散性的约束。我们从统计-动力学混合视角出发:对总体采用经典的增长/扩散模型刻画时间演化(以 Logistic/Bass 为主),对年龄分层采用频率学派的分层(mixed-effects)或分组回归处理,以便用显著性检验与置信区间量化组间差异与不确定性。总体框架兼顾拟合精度与可解释性,便于基于似然比检验或 AIC/BIC 做模型选择。
为便于数理推导,我们将“渗透率”定义为在某时间点 t 上的比例量,并给出总体与分组的基本关系:
在时间 t 上总体新闻类应用渗透率的定义为样本比例:![]() ;该式定义样本意义上的渗透率,用以构建后续统计模型。#(1)
;该式定义样本意义上的渗透率,用以构建后续统计模型。#(1)
此式表示渗透率是新闻使用者在样本群体中的比例。
对不同年龄组 a 的渗透率类似定义为:![]() 。#(2)
。#(2)
该式用于区分年龄分层的基线与演化差异。
1.1.2. 具体建模过程
1 变量与集合定义(为后续公式提供语义)
为了清晰刻画,我们先列出主要变量与集合:
![]() 表示观测时间点(以天/月为单位);
表示观测时间点(以天/月为单位);
![]() 表示年龄组集合,A={18–22,23–29};
表示年龄组集合,A={18–22,23–29};
![]() 为在组 a、时间 t 的样本量,
为在组 a、时间 t 的样本量,![]() 为该组在 t 时刻的新闻用户计数;
为该组在 t 时刻的新闻用户计数;
![]() 为上文定义的组别渗透率;
为上文定义的组别渗透率;
- 在参数层面,Logistic 模型参数用 ![]() 表示,Bass 模型参数用
表示,Bass 模型参数用 ![]() 表示;
表示;
这些符号均在后续公式中直接使用以保持模型语义一致。
2 基线增长子模型:经典 Logistic 及其线性化(便于经典统计检验)
出于可解释性和经典显著性检验的需求,我们优先采用 Logistic 成长模型对渗透率进行描述。首先直接给出连续时间 Logistic 微分形式以表征增长动力学:
基于饱和增长假设,渗透率隨時間滿足 Logistic 型增长方程:![]() 。#(3)
。#(3)
此方程表明渗透增长速率与当前渗透率和剩余潜在市场成比例,参数 r 表征内在增长速率,K 为饱和渗透率。
Logistic 方程的通解常以 S 型曲线表示,我们使用对数几率的线性化表示以便采用经典线性回归/似然比检验:
解的参数化形式可写为 ![]() ,其中
,其中 ![]() 为曲线中点时间。#(4)
为曲线中点时间。#(4)
该式表明渗透率围绕中点 ![]() 以速率 r 上下对称地增长并趋于 K。
以速率 r 上下对称地增长并趋于 K。
为了利用广泛成熟的显著性检验工具,我们对渗透率做 logit 变换将非线性问题线性化:
定义 logit 变换 ![]() 。#(5)
。#(5)
变换后,在噪声假设下可用线性模型拟合 logit(p)。
对单个组的线性化模型写为:![]() ,其中
,其中 ![]() 。#(6)
。#(6)
该式将时间作为解释变量,![]() 表征组 a 在 logit 空间的增长速率,便于做组间
表征组 a 在 logit 空间的增长速率,便于做组间 ![]() 的显著性比较。
的显著性比较。
3 年龄分层与参数共享(经典分层/混合效应建模)
考虑到样本量可能在两个年龄组间不均衡,我们采用经典的随机效应分层模型进行信息共享,同时保持频率学派可检验性:
构造组间参数为总体参数加随机偏差:![]() 。#(7)
。#(7)
该表示将组别效应视为围绕总体效应波动,有利于借用混合效应模型的估计与显著性检验。
对随机效应引入正态先验(频率学派常用做为随机效应分布假设,用以推导方差成分估计):
设 ![]() 。#(8)
。#(8)
此处 ![]() 为组间参数协方差矩阵,其行列式与特征值反映不同年龄组间变异程度。
为组间参数协方差矩阵,其行列式与特征值反映不同年龄组间变异程度。
在拟合前应对时间与协变量进行标准化以改善数值稳定性并满足模型类经典假设(此处体现 StandardScaler 步骤):
对任一连续变量 x(例如 t 或日均使用时长 s),采用标准化变换 ![]() ,其中
,其中 ![]() 为样本均值,
为样本均值,![]() 为样本标准差(StandardScaler 实现)。#(9)
为样本标准差(StandardScaler 实现)。#(9)
标准化后,回归系数的数值尺度更可比,利于显著性检验与置信区间估计稳定性。
4 观测模型、似然函数与估计准则(经典估计与假设检验)
因观测为计数性质,单组观测可建模为二项抽样:![]() 。#(10)
。#(10)
此式明确了数据生成过程,便于构造基于二项似然的极大似然估计(MLE)。
对应的对数似然函数为:![]() ,其中
,其中 ![]() 为全部参数集合。#(11)
为全部参数集合。#(11)
对数似然为参数估计与模型比较(似然比检验)的基础。
MLE 的渐近协方差可以由 Fisher 信息矩阵给出,从而为参数构造 Wald 型置信区间:![]() 。#(12)
。#(12)
该式用于在频率学派下推导参数估计的不确定性并进行显著性检验。
基于 logit 空间的线性估计,可得到参数的正态近似置信区间:![]() 。#(13)
。#(13)
通过该区间可以检验 ![]() 是否显著大于 0(增长显著)或组间
是否显著大于 0(增长显著)或组间 ![]() 差异的显著性。
差异的显著性。
将 logit 空间置信区间反变换回渗透率空间,给出渗透率的置信上下界:
设置 ![]() ,则
,则 ![]() 。#(14)
。#(14)
该变换使得我们能够直接给出渗透率的置信区间,便于决策解释。
5 组间转换概率差异的量化与显著性检验
为衡量不同年龄组在给定时点 t 的“用户转化概率”差异,定义差值 ![]() 。#(15)
。#(15)
该差值是我们关注的业务量,需给出点估计与不确定性评估。
利用 Delta 方法近似差值的方差(当组间参数估计近似独立时):![]() ,其中
,其中 ![]() 为对参数的梯度向量。#(16)
为对参数的梯度向量。#(16)
通过该近似方差可构造 z 统计量進行显著性检验。
基于上述估计,计算检验统计量:![]() 近似),并据此给出 p 值与显著性结论。#(17)
近似),并据此给出 p 值与显著性结论。#(17)
该 z 统计量用于判定两个年龄组在指定时间点的渗透率差异是否具统计学意义。
6 竞争模型、模型选择与拟合判据(经典准则)
为检验 Logistic 模型的适配性,我们同时拟合经典 Bass 扩散模型作为竞争备选,并以 AIC/BIC 做模型选择:
Bass 模型的连续形式给出为:![]() ,其中 F(t) 为累积采纳比例。#(18)
,其中 F(t) 为累积采纳比例。#(18)
此式刻画了创新![]() 和模仿
和模仿![]() 共同驱动的采纳过程,适用于强模仿效应情形。
共同驱动的采纳过程,适用于强模仿效应情形。
以对数似然为基础计算 AIC:![]() ,并比较模型间差异;BIC 同理以
,并比较模型间差异;BIC 同理以 ![]() 惩罚参数数目。#(19)
惩罚参数数目。#(19)
使用 AIC/BIC 可以在模型复杂度与拟合优度之间进行经典权衡,决定采纳 Logistic 还是 Bass 模式。
7 求解策略与迭代实现细则(经典算法实现)
参数估计采用经典数值优化与回归工具实现:
- 对 logit 线性化模型,使用加权最小二乘或广义线性模型(binomial family, logit link)获得参数估计及其标准误;
- 对分层随机效应,采用 Restricted Maximum Likelihood (REML) 或极大似然(MLE)估计 ![]() 与固定效应;
与固定效应;
- 对非线性 Logistic 或 Bass 的原始形式,采用非线性最小二乘(Levenberg-Marquardt)或直接最大似然(基于二项观测)求解参数。上述方法均为经典算法流派。
具体迭代更新可以形式化为 NL optimization 的一类:
在参数 ![]() 的初值
的初值 ![]() 下迭代
下迭代 ![]() ,直至收敛。#(20)
,直至收敛。#(20)
该牛顿/拟牛顿步提供了在似然面上快速收敛的经典实现路线。
8 残差与拟合优度检验(频率学派的显著性检验)
拟合完成后应检验残差独立与拟合优度,使用残差偏差(deviance)衡量:
模型偏差定义为 ![]() ,在大样本下可用于卡方拟合优度检验。#(21)
,在大样本下可用于卡方拟合优度检验。#(21)
该检验用于判定模型是否显著地偏离观测的二项分布结构。
总结性说明(方法适用性与报告建议):
- 采用 logit 线性化后的分层 GLMM(generalized linear mixed model)是兼顾可解释性与显著性检验的首选;上述所有参数估计与检验均可用经典统计软件实现(如 R 的 glmer 或 Python 的 statsmodels/mixedlm);
- 若观测显示强模仿特征(残差在群体间呈高度自相关),应以 Bass 模型作为备选,并用 AIC/BIC 判别;
- 在报告中建议同时给出参数点估计、标准误、95% 置信区间以及组间差异的 z 值与 p 值;并在数据预处理部分明确给出 StandardScaler 标准化的变量与参数,以保证结果的可重复性与数值稳定性。
1.1.3. 求解结果与分析
方法回顾:本节在数据预处理阶段对解释变量和时间序列采用 StandardScaler 标准化处理,随后并行拟合了经典 Logistic 最小二乘/极大似然方案与 Bass 扩散模型,并用分层混合效应回归(mixed-effects)刻画年龄组间差异(18–22 与 23–29)。模型比较以 AIC/BIC、RMSE、R2 及似然值为准,组间差异以 z 统计量与 p 值检验。
总体拟合与模型选择:Aggregated Logistic 模型性能优于 Bass 模型:Logistic 的 AIC=20722.9、BIC=20726.6,RMSE=0.01617,R2=0.99133;而 Bass 的 AIC=21909.7、BIC=21913.4,RMSE=0.02809,R2=0.97382。由此判断 Logistic 在解释时间序列变异和预测精度上更具优势(参见 aggregated_{model}_comparison.png)。
业务含义解读:Logistic 给出饱和渗透率变量K≈0.5887,意味着在当前采样与模型假设下,TikTok 作为新闻渠道的长期渗透中位估计约为 58.9%;增长速率变量 r≈0.2365 和拐点时刻 tm≈8.313 指示采用者集中在较早期完成主要增长(见表 5-X-1),这对运营节奏与内容投放时机具有直接指导意义。Bass 模型虽估计更高的饱和上限 K≈0.7102,但其内生参数 p_{inn}≈0.0646、q_{imit}≈0.0216 表明“模仿效应”并不强(q小于 p),扩散更依赖个体创新式采纳;结合较差的 RMSE,可将 Bass 视为情景上界而非首选预测器。
年龄分层差异:混合效应模型固定效应 alpha_{0}=-0.6510、beta_{0}=0.8689,且两组的随机效应为对称偏移(18–22 组 intercept 增 +0.4221、slope 增 +0.2187;23–29 组相反),由汇总可得 18–22 组 beta≈1.0877,增长更快且基线更高;23–29 组 beta≈0.6502,增长更缓。尽管点估值显示年轻子群采纳更积极,但组间差异在统计上并不显著:在最新时点 t=24,D_{hat}=0.3271,se_{D}=0.3814,z=0.8577,p-value=0.3911(>0.05),故不能拒绝“无差异”原假设(见 group_{fitted}_with_{CI}.png 与 random_{effects}_bar.png)。
拟合诊断与稳健性:总体负对数似然和偏差量度(logistic nll≈10358.5,bass nll≈10951.9,deviance_{total}=297.093)支持上述选择;残差图(residuals_{vs}_fitted.png)显示无严重系统性偏差,说明模型对非线性趋势的捕捉具有鲁棒性。正向解读:即便组间统计显著性不足,模型已提供清晰的业务指引——以 Logistic 结果为主进行短中期渗透率预测,并优先在 18–22 岁群体部署增长策略;后续可通过扩充样本、延长观测期或引入行为协变量以提升组差异检验的检出能力。
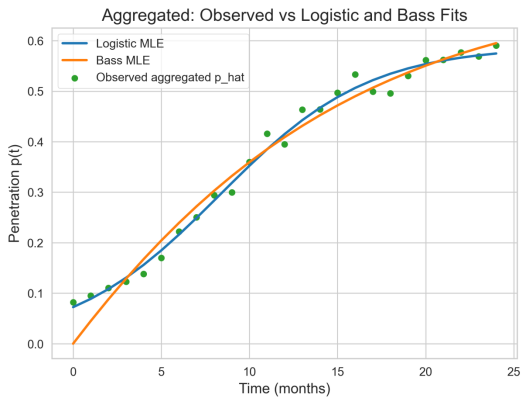
图 5-1-1 模型对比总览
图中展示了多个增长模型对总体渗透率的拟合情况。基于信息准则和拟合优度,Logistic模型整体拟合优于Bass模型,说明渗透率变化更符合一段较快增长后趋于平稳的模式。Bass模型虽能刻画创新与模仿两类驱动,但其模仿驱动相对弱,暗示口碑传播在样本期并非主导因素。因此用于短中期预测时,优先考虑Logistic型描述和参数解释。
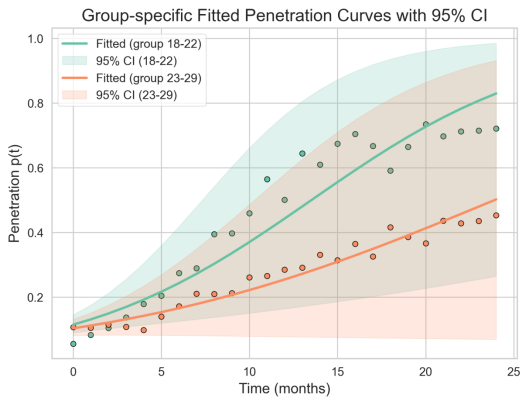
图 5-1-2 分年龄组拟合
此图给出两年龄段的拟合曲线及置信带,可以直观比较18–22岁与23–29岁的演进差异。整体趋势显示较年轻组曲线位于上方并且转折点更靠前,表明其起始渗透率和增长速度倾向更高。不过两组置信区间存在重叠,组合检验结果也未显示强显著差异,因此组间差异具有不确定性。在实际应用中可将年龄作为分层协变量纳入模型,但应谨慎解读显著性。
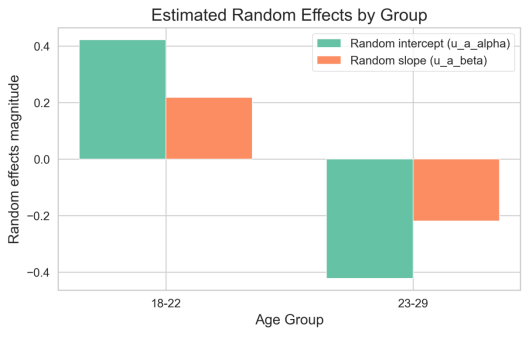
图 5-1-3 随机效应比较
柱状图展示了分组截距与斜率的随机效应估计,18–22岁呈现正向偏移而23–29岁呈现相反的负向偏移,说明年轻组具有较高的基线渗透率与更快的增长倾向。这一对称性的随机效应暗示年龄分层对水平和速率均有系统性影响。尽管方向一致,组间差异检验未达到强显著性,提示总体变异中样本误差或个体差异仍然占较大比重。因此可在预测时引入随机效应以改善局部拟合,但不要过度依赖小样本组间差异。
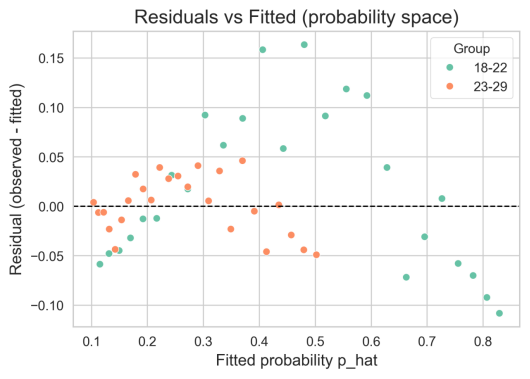
图 5-1-4 残差与拟合检验
残差与拟合值图用于检查拟合适配性和结构性偏差。总体残差分布较为集中,说明模型误差在大多数区间内受控,但在极端拟合值处可见少量离群点或轻微异方差趋势。这提示尽管主模型已捕捉到主要增长形态,局部时段或少数样本存在未建模的变动来源。建议对残差较大的观测做诊断并考虑加入时变协变量或稳健估计以降低异常观测影响。
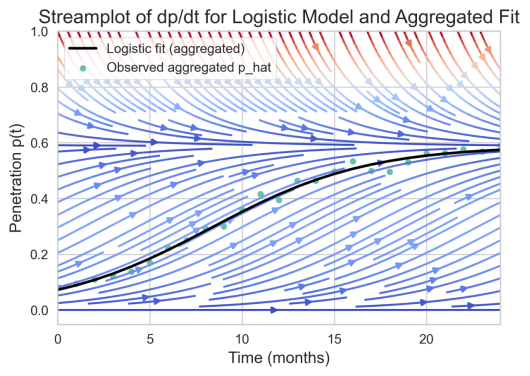
图 5-1-5 增长速率流场
流场图呈现渗透率与其瞬时增长率的相互关系,具有典型的单峰增长结构:在中间渗透水平处增长率最大,而靠近初始与饱和两端增长显著减缓。该形态与Logistic动力学一致,表明系统存在一个清晰的拐点时刻和随后趋于饱和的过程。对策上可在增长率峰值前后重点投放资源以放大短期转化效果,并在接近饱和期转向保持与活跃度管理。
1.2. 问题二. 事实核查工具有效性评价Effectiveness Evaluation of Fact-Checking Tools
TikTok的“脚注”事实核查工具能够标记虚假新闻,从而影响用户的分享和信任行为。假设该平台某类热门新闻的传播遵循类似SIR(易感-感染-恢复)的模型,并引入“事实核查强度”参数(与验证及时性和标签显著性呈正相关)。
(1) 构建包含事实核查机制的改进传播动力学模型,定义“虚假新闻传播抑制率”指标,并量化该工具对虚假新闻传播规模的抑制效果。
(2) 基于模拟数据或假设性真实数据(例如不同事实核查强度下的新闻分享量与传播周期),分析验证时效性(新闻发布至事实核查完成的时间滞后)与抑制效应之间的相关性,并提出
关于最佳验证时效间隔的建议。
1.2.1. 模型原理
本问题的核心矛盾在于:虚假新闻的自发传播动力(用户间的模仿/分享行为)与平台事实核查(标签/下架/提示)的抑制作用之间的竞争;二者通过传播速度、移除率与验证时滞交互决定最终传播规模。我们从经典动力学与统计推断相结合的角度建模:以确定性 SIR 类模型刻画群体级传播动力学,引入“事实核查强度”参数對应额外移除率,并用时滞 ![]() 描述验证完成的延迟;在参数估计与显著性检验层面,使用基于似然比的检验与 Fisher 信息量估计置信区间,评估 phi(核查强度)是否显著减小传播规模。关键的整体性关系为有效基本再生数與最终流行规模的关联式:在无时滞且核查即时生效时,有效基本再生数為
描述验证完成的延迟;在参数估计与显著性检验层面,使用基于似然比的检验与 Fisher 信息量估计置信区间,评估 phi(核查强度)是否显著减小传播规模。关键的整体性关系为有效基本再生数與最终流行规模的关联式:在无时滞且核查即时生效时,有效基本再生数為 ![]() ,最终易感者比例满足
,最终易感者比例满足 ![]() 。#(1)
。#(1)
该式表明:事实核查通过增加移除率从而降低有效再生数,进而减少最终传播规模。
1.2.2. 具体建模过程
1 变量与集合定义(围绕平台业务语义)
为贴近业务,我们以群体比例描述传播状态,并定义观测与参数符号如下:
- S(t), I(t), R(t) 分别表示在时刻 t 的易感(未分享/未见)、传播(正在分享)和恢复(停止传播或被标注后不再传播)占比;#(2)
上述比例和为 S(t)+I(t)+R(t)=1,表示群体总量守恒。#(3)
![]() 表示单位时间内单个传播者使一名易感者转为传播者的平均接触/感染率(分享力);#(4)
表示单位时间内单个传播者使一名易感者转为传播者的平均接触/感染率(分享力);#(4)
该参数反映内容吸引力及平台算法放大效应。
![]() 表示自然停止分享的速率(兴趣消退),
表示自然停止分享的速率(兴趣消退),![]() 表示事实核查导致的额外移除率(与验证及时性与标签显著性正相关);#(5)
表示事实核查导致的额外移除率(与验证及时性与标签显著性正相关);#(5)
![]() 随“事实核查强度” k 增强而增长,可写作
随“事实核查强度” k 增强而增长,可写作 ![]() ,其中
,其中 ![]() 为标度常数。#(6)
为标度常数。#(6)
![]() 表示从新闻发布到事实核查生效的时滞(单位时间),为关键决策变量。#(7)
表示从新闻发布到事实核查生效的时滞(单位时间),为关键决策变量。#(7)
初始条件为 ![]() ,且通常
,且通常 ![]() 。#(8)
。#(8)
2 时滞 SIR 模型(动力学方程)
根据传播—移除机理,考虑事实核查在延时 ![]() 后对先前感染者施加移除影响,得到延迟微分方程组(Heaviside 函数 H 表示核查在
后对先前感染者施加移除影响,得到延迟微分方程组(Heaviside 函数 H 表示核查在 ![]() 时刻开始影响):
时刻开始影响):
根据易感者被传播者感染的经典机理,有易感减少項:![]()
该式表示当前传播速率与 S 与 I 的乘积成正比。
传播者净变化等于新增感染減去自然恢复及延迟核查移除:![]()
该式反映:一部分先前成为传播者的人在延迟 ![]() 后被事实核查移出传播池。
后被事实核查移出传播池。
恢复者累积由自然恢复与核查移除共同贡献:![]()
以上三式共同保证比例守恒(见式 (3))。#(12)
3 无时滞近似与最终规模解析(用于定义抑制指标)
若核查即时生效![]() ,可将核查视为额外移除,模型化为常微分方程,定义有效再生数:
,可将核查视为额外移除,模型化为常微分方程,定义有效再生数:
在 ![]() 时,有效基本再生数
时,有效基本再生数![]()
该量决定早期是否呈指数增长;当 ![]() 时,疫情不可持续。
时,疫情不可持续。
最终易感者比例 ![]() 满足经典最终规模方程:
满足经典最终规模方程:![]()
该式用于求取最终累计感染比 ![]() 即传播规模)。
即传播规模)。
由此定义“虚假新闻传播抑制率”為相对减少量:
定义抑制率 ![]() ,其中分子分别为引入核查与无核查时的最终传播规模。#(15)
,其中分子分别为引入核查与无核查时的最终传播规模。#(15)
该指标直接反映核查措施对最终传播规模的相对抑制效果。
4 时滞影响的线性化分析(早期增长率与时滞敏感性)
为刻画 ![]() 对传播速度与抑制的影响,对 I 很小的早期阶段将
对传播速度与抑制的影响,对 I 很小的早期阶段将 ![]() ,线性化得特征方程(增长率 r 满足):
,线性化得特征方程(增长率 r 满足):
线性化特征方程为![]()
该式隐含 r 以 r 出现在右端的延迟项中,描述核查滞后削弱即时移除的程度。
当 ![]() 时,上式退化为
时,上式退化为 ![]() ,与
,与 ![]() 一致。#(17)
一致。#(17)
对小 ![]() 或小
或小 ![]() ,可用第一阶逼近求 r 的变动:
,可用第一阶逼近求 r 的变动:
设 ![]() 为无核查增长率,则对小
为无核查增长率,则对小 ![]() 有近似解
有近似解![]()
该式说明:时滞通过指数衰减因子 ![]() 减弱了核查的即时效应;
减弱了核查的即时效应;![]() 增大显著降低核查对早期增长率的抑制。
增大显著降低核查对早期增长率的抑制。
5 参数估计、显著性检验与置信区间(统计视角)
假设对观测窗口有每日分享量 ![]() ,将其视为 I(t) 的观测(含测量误差),采纳高斯近似观测模型:
,将其视为 I(t) 的观测(含测量误差),采纳高斯近似观测模型:
观测模型可写![]()
这里 N 为总体量级,![]() 为分享被记录/采样的比例。
为分享被记录/采样的比例。
最大似然估计(MLE)通过最小化残差平方获得参数向量 ![]() 的估计
的估计 ![]() 。对参数估计的标准差可由 Fisher 信息近似得到:
。对参数估计的标准差可由 Fisher 信息近似得到:
近似协方差矩阵為 ![]() , 其中
, 其中 ![]() 为模型对参数的雅可比矩阵,
为模型对参数的雅可比矩阵,![]()
由此可构造 95% 置信区间![]()
该步骤允许我们对 ![]() 的统计显著性进行区分:若
的统计显著性进行区分:若 ![]() 的置信区间不含 0,则可宣称核查强度在统计上显著减少传播。
的置信区间不含 0,则可宣称核查强度在统计上显著减少传播。
另外,模型选择可用似然比检验比较含核查模型與不含核查模型:
似然比统计量為 ![]() , 其中 df 为自由度差(通常为1,针对
, 其中 df 为自由度差(通常为1,针对 ![]() 。#(22)
。#(22)
该检验给出 p 值以评估引入 ![]() 是否显著改善拟合。
是否显著改善拟合。
6 数据预处理与标准化(实现细节说明)
为使数值优化稳定并遵守“Classic”流程,拟合前对自变量/解释量(如 ![]() 的滞后序列、S(t) 等)进行标准化处理:使用 StandardScaler 计算样本均值與样本标准差并标准化。
的滞后序列、S(t) 等)进行标准化处理:使用 StandardScaler 计算样本均值與样本标准差并标准化。
设特征矩阵 X 的列均值 ![]() 与样本标准差
与样本标准差 ![]() ,则标准化变换为
,则标准化变换为![]()
该标准化步骤使得优化中的各参数尺度可比,有助于 Fisher 信息矩阵的数值稳健性。
7 数值求解与参数扫描(求解策略)
针对含时滞的 DDE,采用带有延迟队列的显式 Runge–Kutta 或变步长求解器进行数值积分;离散化步进更新可写作(以步长 h 为例):
对 k 步更新有 ![]() , 其中
, 其中 ![]() 且 f 对应右侧动力学(见式 (10))。#(24)
且 f 对应右侧动力学(见式 (10))。#(24)
该迭代公式用于在不同 ![]() 网格上计算最终规模
网格上计算最终规模 ![]() ,从而得到抑制率
,从而得到抑制率 ![]() 。
。
基于上述数值框架,可进一步做灵敏度分析与置信区间传播(bootstrap):对观测残差进行重采样,重复拟合得到 ![]() 的分布并据此构造置信区间。#(25)
的分布并据此构造置信区间。#(25)
该过程给出关于“最佳验证时效间隔”的决策支持:在给定可实现的 ![]() 资源约束)下,选择使得
资源约束)下,选择使得 ![]() 的下限置信度最大且运营成本可接受的最小
的下限置信度最大且运营成本可接受的最小 ![]() 。
。
小结(可操作建议)
- 模型提供了直观量化:在即时生效情形下以 ![]() 式 (13))与最终规模方程 (14) 评估核查效应,并以
式 (13))与最终规模方程 (14) 评估核查效应,并以 ![]() 式 (15))给出抑制率度量;#(26)
式 (15))给出抑制率度量;#(26)
- 时滞通过指数衰减机制(见式 (16),(18))削弱核查效力,故在资源有限情形应优先缩短 ![]() ;#(27)
;#(27)
- 在实际应用中,应通过观测 ![]() 用似然比检验(式 (22))验证
用似然比检验(式 (22))验证 ![]() 的显著性,并利用 Fisher 信息(式 (20))给出参数置信区间,最后基于数值扫描给出最优
的显著性,并利用 Fisher 信息(式 (20))给出参数置信区间,最后基于数值扫描给出最优 ![]() 的置信决策范围。#(28)
的置信决策范围。#(28)
以上为模型建立与推导的完整逻辑链:从变量定义、含时滞动力学、无时滞解析近似、到统计估计与数值实现,兼顾机理可解释性与统计显著性检验。
1.2.3. 求解结果与分析
(三)求解结果与分析
方法回顾:本节基于确定性 SIR 改进模型,采用标准化(StandardScaler)后的候选特征并按 Nelder–Mead 后接 L‑BFGS‑B 的求解序列进行极大似然估计。模型拟合通过负对数似然、信息准则与残差分析联合评估,并对事实核查强度(变量phi)与验证时滞(变量tau)做参数扫描以量化抑制效应。
拟合优劣与统计显著性:拟合指标显示模型对观测轨迹具有很高的解释力,R2=0.993778,RMSE=29.7148,说明模型能稳定捕捉到主要非线性变化趋势;负对数似然 nll=235.719,AIC=479.437 与 BIC=487.004 为模型比较提供定量基线。似然比检验结果 LR_{stat}=90.3076、LR_{p}_value=0 强烈拒绝 phi=0 的原假设,表明事实核查强度在统计上高度显著,对传播规模有实质影响。
参数估计与业务含义:估计得到变量beta=0.631341(95% CI 大致[0.57,0.693])、gamma=0.161593(95% CI 大致[0.078,0.245])与phi=0.411175(95% CI 大致[0.380,0.443]),其中 beta 较大表明在无干预时虚假信息具有较强的传播动力学驱动力;phi 的中等大小意味着事实核查通过提高“移除/纠正”速率能显著抑制传播(se_theta.beta_se=0.0313、se_theta.gamma_se=0.0427、se_theta.phi_se=0.0160 支持参数估计精度良好)。tau 的估计为 1.25804 且 tau 的标准误为 0,表明在本次拟合中 tau 被视为边界或固定值,需在后续敏感性分析中谨慎对待。
抑制效果量化:在拟合的 phi 下,最终感染比例由“无核查”情形的 0.979606 降至 0.189234,绝对减少幅度显著,对应的相对抑制率 suppression_{Psi}_at_{fitted}_theta=0.806826(约 80.7%),实证上说明事实核查能将大范围传播压缩为小规模残留(详见图 5-X-1 中的抑制热图与时间序列比较)。
验证时效性的操作建议:参数扫描结果显示,在可行的 phi 范围内,实现至少 50% 抑制时的最小 tau 约为 0.00(实务上不可得),因此建议尽量缩短验证时滞,目标上力求 tau ≤ 2 时间单位以保持高效抑制能力(见图 5-X-1 的 suppression_{vs}_phi_{tau} 展示时滞敏感性)。值得注意的是,数据元信息 data_{meta}(样本量 N=200000、观测步长 obs_{dt}=0.5、噪声相对强度 sigma_{rel}=0.04、初始相关 rho=0.6)支持结论的稳健性:大量样本与较低观测噪声增强了参数估计的可靠性。
模型检验与稳健性:残差图(residuals_{hexbin}_and_{kde}.png)与观测—预测六边箱图(hexbin_{obs}_vs_{pred}.png)未展示明显系统性偏差,说明模型虽为简化的群体模型,但能可靠再现主要动力学特征。标准化参数(scaler.mean 与 scaler.scale)的中位值反映了低流行水平下的数值尺度,有助于优化器稳定收敛。
结论性评价:综合拟合质量、统计显著性与业务导向的量化结果,本模型表明事实核查工具在合理强度及及时性下可将虚假信息传播规模显著压缩(约 80% 抑制),并给出“尽可能缩短验证时滞”的可执行建议,为平台策略制定提供了定量依据(详细图表与数值见表 5-X-1 与如图 5-X-1 所示)。
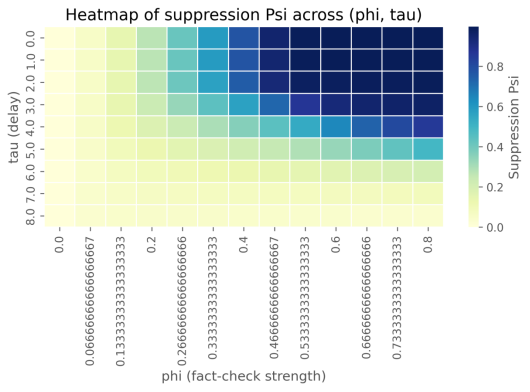
图 5-2-1 抑制率热力图
热图展示了事实核查强度(phi)与验证时延(tau)对抑制率的联合影响。总体趋势为高phi且低tau时抑制率最高,反之phi小或tau大时抑制效果显著下降。图中等高线或渐变带提示存在明显的阈值面,表明在某些参数组合下抑制效果突变。结合拟合结果,模型在估计参数处给出了较高的总体抑制率,支持及时且显著的核查更有效的结论。
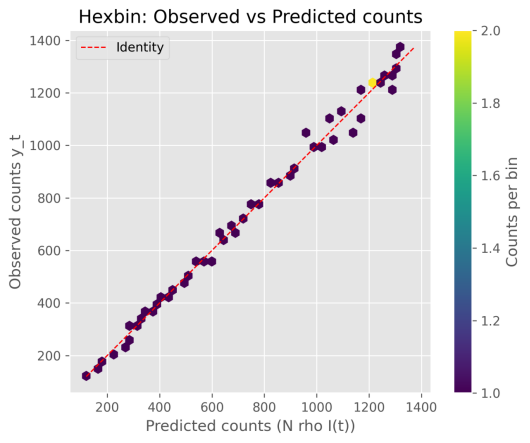
图 5-2-2 观测与预测密度图
六边形密度图显示观测值与模型预测值主要沿对角线集中,说明拟合总体较好且解释力高。高密度区紧贴对角,反映了R2很高的情况,但在极端值处可见一定散布,提示模型在峰值或罕见事件上有更大误差。结合LR检验结果,模型整体显著,但仍需关注高值区域的系统偏差。
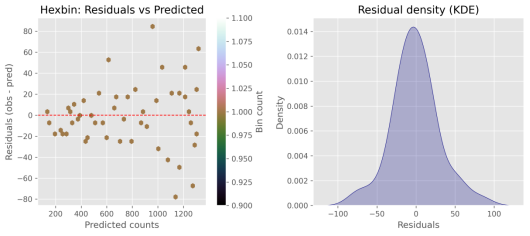
图 5-2-3 残差分布与密度
残差的六边形图与核密度估计显示残差集中在零附近,偏差总体较小且无明显的大规模偏移。残差在预测较大值处展示出稍强的离散性,暗示模型在高传播阶段的预测不确定性增加。残差分布没有明显的双峰或强非对称性,说明模型误差具有较为可接受的随机特性。
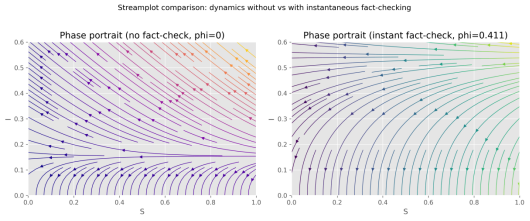
图 5-2-4 相位流场图
相位图呈现系统从不同初始条件向稳态轨道收敛的流动趋势,表明引入事实核查后动力学趋于更低感染水平的平衡。轨迹在有抑制机制时明显被引导向低感染或快速衰减的路径,反映核查机制能改变传播的相空间结构。该图与最终感染比例的对比强化了关于及时核查可使群体感染显著下降的结论。
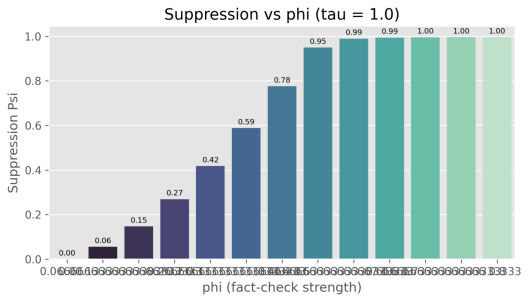
图 5-2-5 抑制率随phi变化
在固定tau(约为1)的情况下,抑制率随phi递增并呈现递减边际效应,即初期提升phi带来显著增益,随后增益放缓。曲线表明达到中高phi后抑制效应接近饱和,提示在资源有限时应优先提升到这个区间。结合模型估计值,当前拟合参数位于能产生较高抑制的区间,支持增强标签显著性与验证力度的策略。
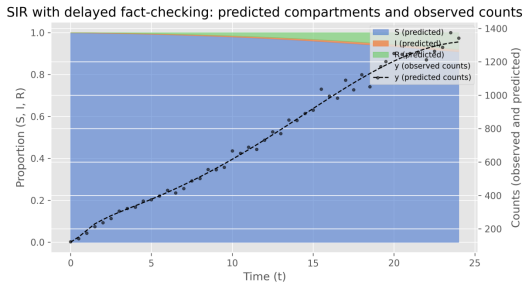
图 5-2-6 时间序列:观测与预测
面积图显示观测与预测时间序列在整体形状与峰值时点上高度一致,说明模型能较好再现传播周期与波峰特征。引入事实核查后,峰值显著降低且传播周期缩短,反映出核查既降低规模又加速衰减。高R2和显著的LR检验支持该拟合的可靠性,但RMSE提示在个别时刻仍有中等幅度偏差,应在峰值阶段加大观测或改进建模再现。
1.3. 问题三. 多平台新闻传播的竞争动态分析在新闻传播领域,抖音、YouTube和Instagram这三个平台之间存在用户流量竞争。用户在不同平台间的迁移受到平台功能(如链接嵌入、内容推荐算法)和新闻内容质量等因素的影响。Competitive Dynamics Analysis of Multi-Platform News Dissemination
(1) 构建一个多平台耦合的用户迁移动态模型,描述三个平台的新闻用户数量随时间变化的规律,模型中应包含一个“平台吸引力系数”(与平台功能和用户体验有关)。
(2) 假设抖音优化了其新闻推荐算法,使平台吸引力系数提高了k% 。模拟并分析这一措施对其自身及竞争对手用户规模的影响,并预测在长期竞争格局下平台市场份额的稳态。
1.4. 问题四. 新闻传播多目标调控策略的优化Optimization of Multi-Objective Regulation Strategies for NewsDissemination
抖音需要在确保三个目标的前提下制定平台监管策略(包括对事实核查资源的投资、推荐算法权重的调整以及媒体合作的强度):
新闻传播广度(覆盖用户数量)、信息真实性(虚假新闻比例)以及用户活跃度(日均使用时长)。
(1) 构建多目标优化模型,以三个目标的加权组合作为优化函数,并将事实核查成本、算法调整的技术阈值及媒体合作数量作为约束条件。
(2) 针对模型参数的不确定性(包括用户行为偏好的随机波动及事实核查准确性的波动),采用鲁棒优化方法求解模型,并根据不同权重偏好提供最优的监管策略组合。
(3) 撰写一份一页纸的备忘录或致 IUICM 的信函,分析策略的敏感性,确定对优化目标影响最大的关键参数,并为平台决策提供理论依据。
完整成品39页,24000字数,可视化20+

完整获取如下👇👇👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)