Robust Multivariate Time Series Forecasting against Intra- and Inter-Series Transitional Shift
3.

捕获系列内/系列间相关性的一种流行且先进的方法涉及将过渡分布分解为系列内/系列间过渡分布

给定所有序列历史条件下,第 ii 条序列未来值的条件分布分解为两个部分的乘积:
预测分布在JointPGM内即为预测高斯的均值、方差
1. 序列内转移分布
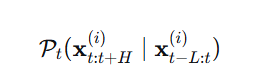
这表示:仅基于第 ii 条序列自身的历史,预测其未来值的分布。它捕捉了序列内部的时间依赖性(如自回归、趋势、周期性等)。
2. 序列间转移分布
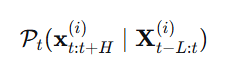
这表示:基于其他所有序列的历史,预测第 ii 条序列未来值的分布。它捕捉了不同序列之间的空间依赖性(如协动性、因果影响等)。
作者认为:观察到的时间序列非平稳性:
①系列内过渡转变
![]()
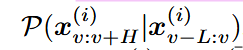
在时间点 u 和 v,给定各自的历史窗口后,未来值的条件分布不相同
JointPGM不直接检验这个不等式,而是直接建模时间变化的条件分布。
核心思想:既然 P(⋅∣⋅) 随时间变化,那就让模型能够学习这种变化。
②系列间过渡转变
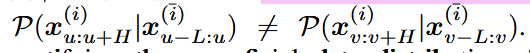
1. 构建序列间依赖图
这个 Wt 表示在时间 t,所有序列间的影响强度。
2. 序列间影响随时间变化
-
在时间 u:得到邻接矩阵 Au
-
在时间 v:得到邻接矩阵 Av
-
如果 Au != Av,说明序列间依赖关系发生了变化
检测到:
序列内变化:相同传感器在不同时间的模式不同
序列间变化:
工作日:传感器 1 和 2 高度相关(都是主干道)
周末:传感器 1 和 3 相关度增加(休闲区域关联)

注意:这里的时间不是物理时间,而是时间模式
混淆点澄清:
-
物理时间:确实是固定的,不受外界影响(2024 年 12 月 25 日 14:00 就是那个时刻)
-
时间特征(Time Factors):隐藏在数据中的时间相关模式
时间特征 = 数据在特定时间表现出的规律性模式
例子 1:餐厅客流
-
物理时间:每天中午 12:00
-
时间特征:
-
工作日中午:白领午餐高峰(客流模式 A)
-
周末中午:家庭聚餐高峰(客流模式 B)
-
节假日中午:可能异常火爆或冷清(客流模式 C)
-
这里的 "时间特征" 是指:在 "中午 12:00" 这个物理时间点上,不同日期类型下的客流模式特征。
在论文中,时间特征 Zt 是通过时间因子编码器(TFE)学习的,
1. 周期性模式
M_t = sin(2πBt) | cos(2πBt) | ... # 公式(3)
论文是如何将时间信息输入之后进去zt的?
傅里叶基函数如何捕捉周期性?
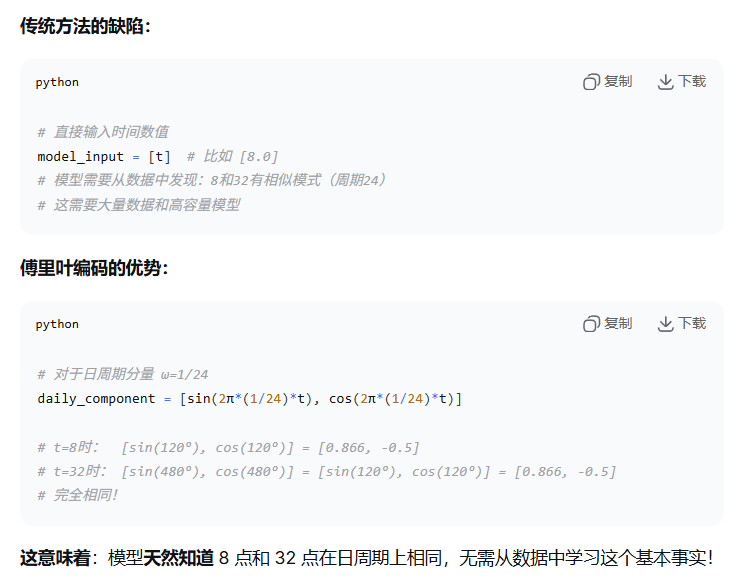
在 Transformer 位置编码的基础上增加了多尺度,Transformer上采取正弦函数但是固定,频率预定义不灵活,不可学习不可适应数据,单一尺度
一、核心困境:时间编码的根本难题
问题 1:时间的离散数值 vs 连续周期性
输入时间点:
t=8(数值)现实要求:
t=8和t=32(第二天 8 点)应该相似(都有早高峰)但数值上:8 和 32 相差很大!
问题 2:多尺度周期性的表示
一个时间点同时具有:
日位置:在 24 小时周期中的位置(早上/下午/晚上)
周位置:在 7 天周期中的位置(周一 / 周末)
月位置:在 30 天周期中的位置(月初 / 月末)
年位置:在 365 天周期中的季节位置
如何用一个特征向量同时表示所有这些?
问题 3:非平稳性下的时间语义变化
同样时间
t=8,在不同条件下含义不同:
工作日 8 点:通勤高峰
周末 8 点:休闲时间
节假日 8 点:特殊模式
疫情期 8 点:居家状态
如何让时间编码能适应这种语义变化?
核心思想:任何周期性函数都可以分解为不同频率的正弦波和余弦波的组合,将时间映射到周期性空间的坐标
通过多尺度傅里叶基函数,模型能同时学习和利用从小时到年的各种周期性模式,让预测既考虑 "此刻的数据",也考虑 "这个时间通常的模式"。
傅里叶基函数(使用正弦余弦信号编码时间特征)实现了时间点到特征向量的映射,通过多个频率分量的组合编码时间特征
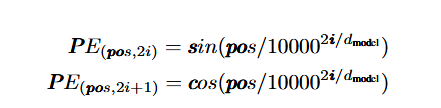

为什么用多个尺度 B_s?
物理意义:
σ_s 小(如 0.01)→ B 的元素值小 → 频率 ω = B・t 小 → 长周期
捕捉:年趋势、季度变化
σ_s 大(如 100)→ B 的元素值大 → 频率 ω 大 → 短周期
捕捉:小时波动、分钟级变化
这建立了多尺度时间感知的基础设施!
作用 1:显式编码周期性(最核心!)
作用 2:多时间尺度统一表示
一个时间点
t的傅里叶特征包含所有时间尺度信息:
作用 3:平滑的时间邻近性
傅里叶特征具有局部平滑性,但又不是完全线性:
作用 4:解耦时间表示与数据表示
分离的好处:
模块化:时间处理和数据处理解耦
可解释:可以单独分析时间特征的作用
灵活:可以更换不同的时间编码方案
作用 5:适应非平稳性的时间语义变化
通过可学习的 B 矩阵,傅里叶基函数可以适应数据的时间模式变化:
作用 6:提供丰富的归纳偏置
傅里叶基函数提供的归纳偏置:
1. 周期性假设
假设数据变化具有周期性成分
引导模型关注周期性模式
2. 多尺度假设
假设不同时间尺度都有影响
引导模型同时考虑短期和长期模式
3. 平滑性假设
假设时间变化是平滑的
避免对时间噪声过度敏感
4. 线性可分离假设
假设不同频率的影响可以线性叠加
简化模型学习过程




为什么需要前馈神经网络进一步处理?
傅里叶特征 M_t^(0) 是通用但冗余 的:
维度高(频率数 ×2)
包含所有频率,但很多可能对当前任务无用
神经网络的作用:
特征选择:突出重要的频率分量
降维:压缩到更紧凑的表示
非线性组合:学习频率间的复杂交互
任务适应:为具体预测任务优化时间表示
非平稳性的自然处理
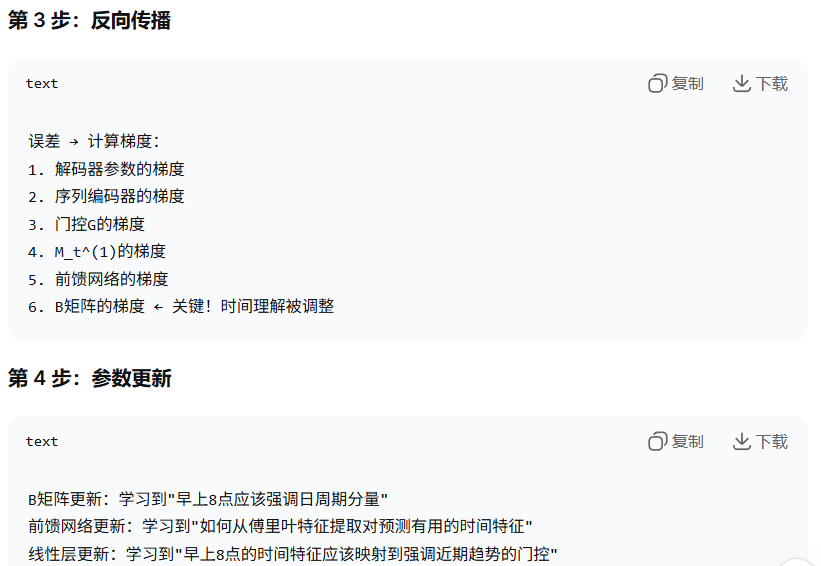
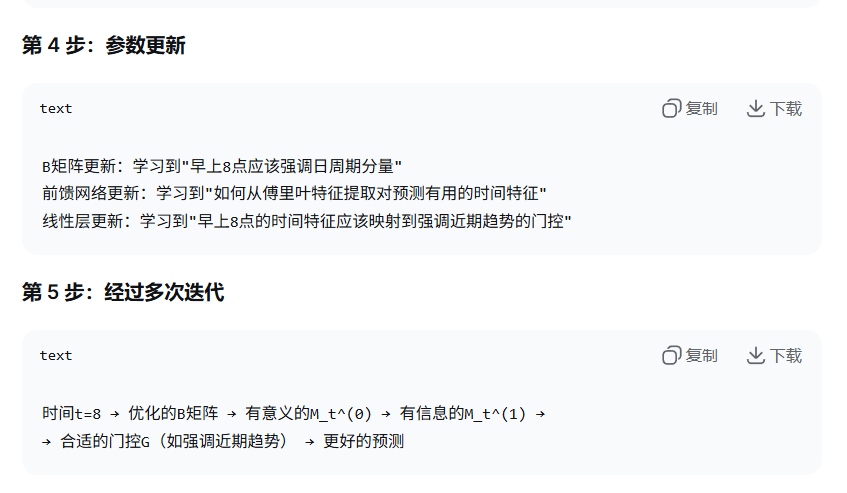
当分布漂移时:
时间特征 M_t^(1) 会变化(因为 B 和前馈网络调整)
门控 G 随之变化
模型自动适应新的时间模式
例如疫情后:
早上 8 点的数据模式变了 → B 矩阵调整频率理解
M_t^(1) 编码新的 "8 点特征"
门控 G 学习新的调节策略(如更关注长期趋势而非近期高峰)

TFE 输出的具体是什么信息?
TFE 输出 = 基于历史数据学习到的时间先验
具体包含:
-
确定性部分:周期性位置(来自傅里叶变换)
-
学习性部分:时间语义(来自训练数据统计)
1. 周期性位置编码
2. 时间语义的统计摘要
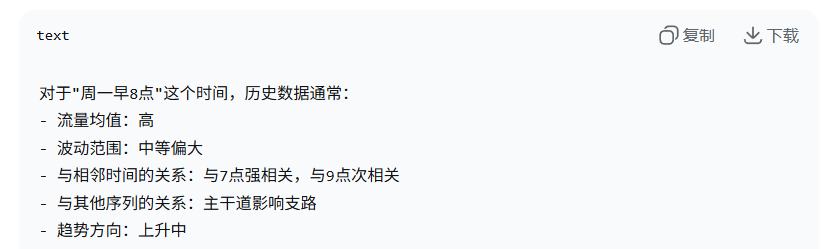
3. 时间的 "指纹特征"
每个时间点有独特的组合特征:

-
时间指纹:[0.9, 0.1, 0.8, 0.2, 0.7]
-
语义: "通勤高峰开始,流量快速上升"->*这完全是基于"周一早8点"这个标签推导出来的,还没看实际数据

反向传播学习: 当输入是"周一早8点"时,输出特征能让模型想到"通勤高峰" - 当输入是"周六早8点"时,输出特征能让模型想到"休闲出行"
TFE 不是一个简单的数学函数,而是一个 "时间知识库":
-
建造知识库(训练):需要看大量数据
-
查询知识库(推理):只需要输入时间
数据分布:某个时间点 t 的数据值 x_t 的概率分布
-
例子:周一早上 8 点的交通流量值的分布
转移分布 : P (x_{t:t + H} | x_{t-L:t}),给定过去 L 个时间点的观测值,未来 H 个时间点的条件概率分布
-
例子:给定过去 2 小时的交通流量,预测未来 1 小时流量的分布
数据分布具有局限性,如果现在是异常的周一早 8 点(比如下暴雨),这个知识就没用了
转移分布考虑具体的上下文,如果过去 2 小时流量异常低,即使时间是周一早 8 点,也会预测低流量
分布漂移的影响:
对转移分布 P (未来|历史):
如果分布漂移了: P_old(未来|历史) ≠ P_new(未来|历史) 但可以通过分析历史-未来的映射变化来理解漂移: - 是序列内动态变了?(每个序列自身的演化规律变了) - 还是序列间关系变了?(序列间的影响模式变了)
JointPGM 的核心思路:通过分解转移分布为序列内转移和序列间转移,来理解和建模分布漂移!
PGM可以有原则有效的可解释的表示变量间的复杂的分布和统计关系
GaussianSampling
没有高斯采样:
模型输出:确定性的预测值,比如"明天流量=800"
有高斯采样:
模型输出:概率分布,比如"明天流量~N(800, 50²)"
→ 最可能800,但有波动范围
目的 1:表示不确定性:
均值μ:最可能的预测值(点估计)预测的 "中心" 方差σ²:不确定性的程度,预测的 "信心区间半径"
目的 2:实现变分推断框架

目的 3:处理非平稳性的关键机制
分布漂移下的不确定性变化:
当分布漂移发生时:
1.模型对旧模式的不确定性增加

2.通过 σ 的变化检测异常

自适应调整:
模型学习到:当数据模式异常时,应该输出大的方差 这样即使均值预测不准,大方差也能"覆盖"真实值 损失函数中的KL项会平衡: - 方差不能太小(否则重建损失大) - 方差不能太大(否则KL惩罚大) → 学习到"合适"的不确定性程度
目的 4:实现多峰分布的近似
高斯分布虽然单峰,但可以通过潜变量采样近似多峰性:
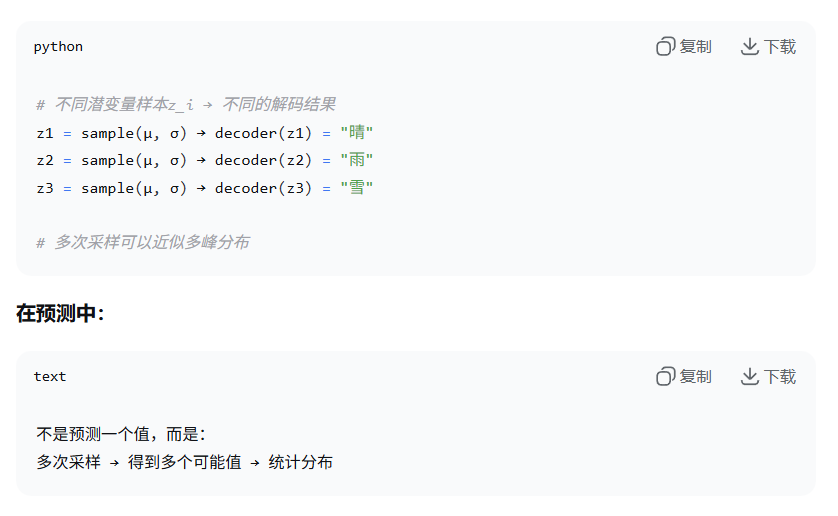
目的 5:改善梯度流动和训练稳定性

目的 6:实现分布对齐和一致性约束

这强迫模型学习:
-
时间信息和数据信息的一致性
-
如果不一致(分布漂移),KL 散度增大
GaussianSampling在 JointPGM 架构中的具体角色
1. 时间因子编码器(TFE)中的高斯采样
目的:将确定性的时间特征转化为概率性的时间表示,便于与数据推断的分布比较。
2. 序列内学习器中的高斯采样
目的:为每个序列学习不确定性的序列内表示。
3. 序列间学习器中的高斯采样
目的:学习不确定性的序列间协同表示。
高斯采样如何帮助处理分布漂移?
1. 不确定性作为漂移指示器

2. 通过重采样适应新分布
当分布漂移时: # 旧均值μ_old可能不准 # 但通过采样不同z,可能"撞到"正确区域 # 多次采样得到多个预测
3. 分布对齐实现漂移适应

在分布漂移 的环境中:
-
固定的确定性模型容易失效
-
概率模型可以通过调整不确定性程度来适应
-
当模型 "不确定" 时(σ 大),提示可能需要人类干预或重新学习
简单说:学习高斯采样的均值和方差,是让模型从 "只回答是什么" 升级到 "回答是什么,并且对这个答案有多确信,可能的范围是什么"。这对于在变化莫测的真实世界中进行可靠预测,至关重要
TFE的输入为什么要包含到 t + h?
传统思维的局限:
"要预测未来,只需要知道过去和现在" "未来是未知的,怎么能用未来的信息?"JointPGM 的突破性见解:
"要预测未来,需要理解'从现在到未来'这个过程" "虽然不知道未来的数据值,但知道未来的时间属性" "时间本身就有信息!"目的 1:建立时间锚点框架
关键理解:预测需要参考系
t + H 就是这个 "目的地" 的时间坐标!
目的 2:编码预测跨度的时间语义
预测的关键信息:时间距离
只包含历史时间的缺陷:
# 假设L=24, H=24 输入时间:[t-23, t-22, ..., t] # 过去24小时 TFE输出:过去24小时的时间特征 # 问题: # 1. 不知道要预测多远的未来 # 2. 可能用"过去24小时"的模式来预测"未来24小时" # → 如果过去是白天,要预测夜晚,就会大错!包含 t + H 的解决方案:
输入时间:[t-23, ..., t, ..., t+24] # 完整48小时窗口 TFE看到: - 历史部分:过去24小时(已知时间模式) - 未来部分:未来24小时(时间位置已知,数据未知) # TFE可以学习: "从这样的历史时间模式,到那样的未来时间位置, 应该有什么样的预测模式"目的 3:对齐多周期相位
当前:周三下午3点 预测:下周三下午3点 没有t+H: 模型只知道"现在是周三下午3点" 但不知道"要预测的是下周三下午3点" → 可能错误地用"明天下午3点"的模式来预测 包含t+H: TFE看到完整时间窗口: [本周三3点, ..., 下周三3点] 傅里叶编码自然体现: - 周周期:正好完整一周(相位变化2π) - 日周期:同样的下午3点位置(相位相同) → 完美对齐周期相位!目的 4:处理非平稳时间动态
分布漂移下的特殊价值:
当时间模式发生变化时,历史与未来的时间关系也在变化
这允许 TFE 学习:不是固定的时间特征,而是时间关系的特征
输入时间关系:[t, t+H] 输出特征编码:"从时间t到时间t+H的典型演变模式"目的 5:实现多步预测的一致性
多步预测的特殊要求:预测的多个时间点之间应该有协调性

输入X:只包含历史数据 X_{t-L:t} 输入时间:包含完整窗口 {t-L+1, ..., t+H}为什么?时间知识:关于"时间本身"的规律 - 周期性、趋势性、时间关系 - 这些是**先验的**,可以从时间标签本身推导 数据知识:关于"具体数值"的规律 - 如何从历史数据推断未来 - 这些是**后验的**,需要实际观测1:时间信息是确定性先验:时间信息与数据值无关,完全可以提前知道!
2:防止信息泄漏的巧妙平衡:
绝对不能泄漏的是:未来时间点的**数据值** 可以安全提供的是:未来时间点的**时间属性**理由 3:为多步预测建立时间坐标系:
一个完整的参考系来协调各个预测点理由 4:让模型专注学习真正的动态
如何从有限的历史数据 + 完整的时间上下文 推断完整的未来序列理由 5:处理分布漂移的关键机制
理由 6:实现真正的条件预测
给定历史条件,推测未来


TFE 不是在 "学习 t + H 的数据信息",而是在 "学习 t 到 t + H 的时间关系信息"
这是利用时间的结构性和规律性来做出更好预测的关键机制。
DI的作用:

JointPGM focuses on a probabilistic manner to account for the underlying causes of distribution shift in MTS forecasting.理解
概率化方式:
确定性方式:输出 = f(输入) # 输出一个具体值 预测值 = 25.3°C # 使用:直接相信这个值 概率化方式:输出 ∼ P(输出|输入) # 输出一个分布 预测分布 = N(μ=25.3, σ=1.5) # 意思是:温度可能在23.8-26.8°C之间,最可能是25.3°C具体体现在:
隐变量是分布:
Z ∼ N(μ, σ²),不是固定向量预测是分布:给出未来值的概率分布,不只是点估计
不确定性量化:模型知道 "自己有多不确定"
为什么重要?:分布漂移本质上就是不确定性增加,概率化方式能自然表达这种不确定性
将时间戳特征嵌入MLPs在学习高频模式时可能存在局限性,通常称为"谱偏倚"。
核心问题:MLP 学不好高频模式
频谱偏差:MLP 天生倾向于学习低频成分,忽略高频成分。
用 MLP(多层感知机)直接学习时间戳特征时:
能很好地学习平滑的、低频的模式(如季节性趋势)
但很难学习快速变化的、高频的模式(如小时内的波动)
假设要学习一天内的温度变化:
低频模式:早上冷 → 中午热 → 晚上冷 (容易学习)
高频模式:每分钟的微小波动 (很难学习)神经网络本质上是一个平滑函数逼近器。它的激活函数(ReLU 等)和层结构使得它,
偏好变化缓慢的函数,惩罚快速振荡的函数
JointPGM 的做法:
不用 MLP 直接学,而是先用傅里叶基函数把时间坐标映射到高频空间:
为什么有效?
显式提供高频基:傅里叶基本身就包含高频振荡
MLP 只需要组合:不用从头学习振荡,只需学会组合现有基函数
解决频谱偏差:高频信息已经存在于输入中
这就解释了为什么使用启发式正弦映射,目的是使得时间戳显式的包含高频信息,方便MLP学习
为什么高频模式重要?
突发事件检测:突然的跳变(高频)可能表示异常
精细调度:电网需要 15 分钟级的预测,不只是小时级
模式识别:某些模式只在高频显现(如交易中的短线信号)
分布漂移可能以高频发生:
突然的政策变化
突发事件影响
市场情绪快速转变
MLP 学习如何加权组合这些不同尺度的特征:
y(t) = sin(2π f t)其中:
f:频率(单位:赫兹 Hz,即每秒周期数)
t:时间
2π f:角频率(单位:弧度 / 秒)
ω = 2π f f = ω / (2π)
B_s:论文中从N(0, σ_s²)采样的值
B_s:实际上就是频率 f!更准确的表述:
σ_s控制频率的分布范围:
小 σ_s → B_s 集中在 0 附近 → 低频特征
大 σ_s → B_s 分散在大范围 → 高频特征
σ_s是频率分布的标准差。典型周期长度 ≈ 2π/σ_s
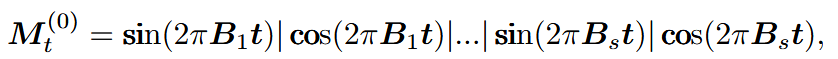
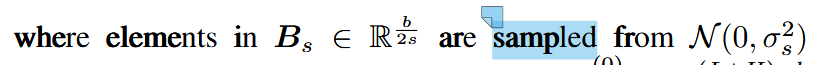


均值 μ_t
方差 σ² 的三种作用:
作用 1:训练时的 "探索导师":目的:让模型探索不同 z 值,学习更好的 μ 和 σ
作用 2:不确定性的量化器
作用 3:损失函数的调节器
训练阶段:方差驱动学习,推理阶段:均值用于预测,方差用于诊断
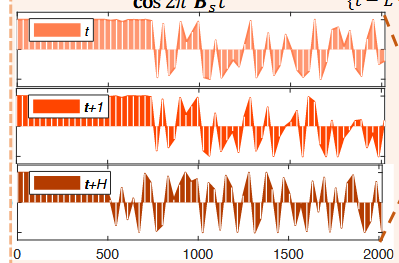
可以体现时间顺序:
相似的时间顺序产生相似的表示( e.g. , t , t + 1的图),
并且时间顺序越大,表示中的值越早在- 1和+ 1 ( e.g. , t , t + H的作图)之间振荡。
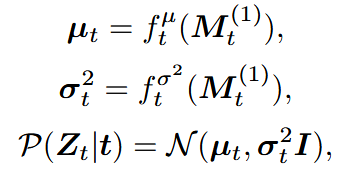
对Mt进行映射,分别映射为Zt的均值分方差(即这个预测的中心值以及波动幅度(波动大就代表没把握))
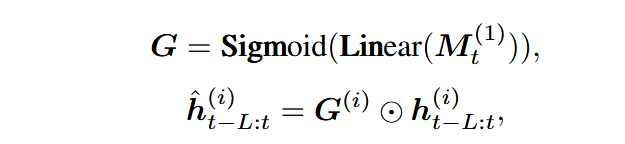
M_t^(1) 本质上就是各种时间模式在当前时间点的影响权重。
假设 d=128,就是有 128 种不同的 "时间味道"(时间模式)。


针对不同的模式对h进行加权
时间门 G 的作用:
-
它根据全局时间情境 M,决定回顾窗口特征 h 中哪些部分更重要。
-
例如:如果是 “早高峰”,就强调 “拥堵相关特征”;如果是 “夜间”,就强调 “平稳特征”。
这样,虽然 h 本身只有过去信息,但被 G 调制后,它变成了 “时间情境感知的过去表示”。
G 也是基于跨窗口时间信息动态调整的

M 提供 “时间情境”,h 提供 “数据内容”
-
M 告诉你:现在处于一天中的什么时间、季节、是否是特殊日期等时间情境。
-
h 告诉你:过去 L 步具体发生了什么数据内容。

Mt 不会、也不应该 “学习” 到未来的具体特征值,但它会编码 “未来的时间结构 / 模式” 作为先验知识。
关键区分:“未来特征” vs “未来时间模式”
1. Mt 不包含未来数据的具体值
-
输入 t 只是归一化的时间位置索引(如 [0, 0.1, 0.2, ..., 1.0])。
-
这些索引是预先已知的(回顾窗口和预测窗口的长度是固定的)。
-
所以 Mt 不会泄露未来的真实值(比如明天股价是多少)
2. Mt 编码的是 “时间模式先验”
-
通过傅立叶基函数,Mt 可以编码:
-
周期性模式(如一天 24 小时、一周 7 天)
-
趋势模式(如季节变化)
-
时间相对位置(如 “预测窗口的第 1 步 vs 最后 1 步”)
-
这些是 “时间结构” 的先验知识,不是未来数据。

Mt 学习时间模式的训练过程
1. 输入:归一化时间索引 t
这是一个预先定义好的、固定的归一化位置编码,不包含任何数据值。
2. 傅立叶特征映射
模型在学习 “哪些频率的时间模式对预测有用”。
3. 训练信号来源:整个预测任务的梯度
梯度更新 B_s 和 FeedForward 权重,让 M_t 逐渐编码能降低预测损失的时间模式。
4. 具体学习机制:通过时间门 G 作为桥梁
M_t^{(1)} → G → 调制 h → 影响隐变量 → 影响预测
如果某种时间模式(如 “24 小时周期”)对预测有帮助,G 就会学会:
在每天同一时间激活相似的模式
调制 h 以突出该时间相关的特征
这种 “帮助预测” 的效果会通过梯度强化 B_s 中对应该频率的参数。
5. 动态推断(DI)的额外监督
M_t 不仅要编码时间模式,还要编码能被数据隐变量反推出来的一致时间模式,这加强了时间编码的 “数据一致性”。
学会了:24 小时周期、7 天周期、趋势变化等对预测有用的模式。
G 学会在合适的时间激活合适的特征提取。
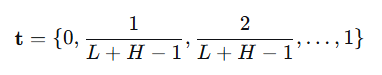
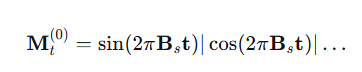

M_t 可以学习到的五类时间模式:
1. 周期性模式(Cyclical Patterns)
2. 趋势模式(Trend Patterns)
3. 事件/节假日模式(Event/Holiday Patterns)
固定假日:春节、国庆节等,每年日期固定或大致固定。
移动假日:复活节、感恩节等,每年日期不同。
特殊事件:奥运会、重大促销日等。
M_t 如何编码:
虽然 t 只是顺序索引,但模型可以通过多个频率的组合 + 非线性变换来近似 “某天是否节假日” 的复杂模式。4. 时间相位模式(Temporal Phase Patterns)
回顾窗口内部:t-L 到 t-1 各点的时间位置。
预测窗口内部:t 到 t + H 各点的时间位置。
窗口间关系:回顾窗口最后一点 vs 预测窗口第一点的连续性。
这是 M_t 最重要的功能之一:
它编码了“现在处于时间序列的哪个相位”,例如:
“刚刚进入早高峰”
“处于午间低谷的末尾”
“即将进入晚高峰”
5. 突变点/状态转移模式(Change Point/Regime Shift Patterns)
快速变化区间:如股市开盘 / 收盘的波动增加。
平稳区间:如深夜时段的稳定状态。
过渡区间:如从平稳到高峰的过渡阶段。
M_t 如何表示:
通过多个频率的叠加 + 非线性激活,M_t 可以编码 “时间变化率” 或 “状态稳定性”。



Decoder 重构 Xt−L:tXt−L:t 看似与预测未来无关,但实际上这是 JointPGM 设计中至关重要的一环
预测损失:确保隐变量包含未来信息
重构损失:确保隐变量保留过去信息
这强制隐变量 Zt−L:tZt−L:t 成为 “信息瓶颈”,必须同时编码过去和未来的相关信息。
防止隐变量 “忘记” 过去细节
这就像考试:
预测未来 = 解新题
重构过去 = 复述学过的例题
两者都做好 = 真正理解了概念
预测 + 重构:气象学家必须:
先准确描述今天的天气(重构:云量、风速、温度等)
然后预测明天

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)