如何让小模型达到大模型的性能?(模型压缩与蒸馏)
小模型逼近大模型性能的核心是“压缩提效+蒸馏传知”的组合策略:通过剪枝、量化、架构优化精简模型结构,降低部署成本;通过动态蒸馏、链式蒸馏、合成数据迁移大模型知识,弥补参数量差距。在实际落地中,需结合任务场景、硬件资源定制技术方案,同时通过多阶段训练、参数高效微调进一步优化性能,最终实现“小而强”的模型部署目标。相关学习推荐:工业和信息化部电子工业标准化研究院关于开展人工智能从业人员 “人工智能大模
一、核心逻辑:小模型“以质补量”的底层思路
大模型的优势源于千亿级参数对海量知识的拟合能力,但部署时面临显存占用高(如175B参数模型FP16精度需350GB+显存)、推理延迟长(单条请求生成1000token需10秒+)、能耗成本高(单次推理约0.1kWh)等瓶颈。小模型要实现性能对齐,本质是通过“技术赋能”替代“参数堆砌”,核心逻辑包括两点:一是通过压缩技术精简模型结构,提升推理效率;二是通过蒸馏技术迁移大模型的“暗知识”,弥补参数量不足的性能差距。
需注意的是,传统压缩方法对大模型适配性有限——大模型的涌现能力(如上下文学习、工具调用)对参数变化极度敏感,直接压缩易导致性能断崖式下降,且Transformer架构的多头注意力、RoPE位置编码等特殊结构,需针对性优化方法。
二、模型压缩:给大模型“精准瘦身”
模型压缩的核心是移除冗余参数、降低计算复杂度,同时尽可能保留核心特征提取与推理能力,常用方法可分为四大类,适配不同场景需求。
2.1 剪枝(Pruning):移除冗余连接与结构
原理是通过分析参数重要性,剪除对模型性能影响极小的权重、神经元或整层结构,实现“瘦身不丢效”。根据剪枝粒度可分为两种:
- 结构化剪枝:直接删除整个通道、注意力头或网络层,无需稀疏计算支持,适配硬件部署。例如对BERT模型剪枝50%低重要性注意力头,可使模型大小减半,推理速度提升40%,准确率仅下降1%。
- 非结构化剪枝:修剪个别不重要的权重参数,形成稀疏矩阵,需依赖专用稀疏计算框架。2024年研究显示,对LLaMA模型进行深度、宽度、注意力头多维度剪枝后,用不到原数据3%的样本再训练,可压缩2-4倍,性能优于同尺寸未剪枝模型。
关键要点:剪枝后需进行蒸馏式再训练,修复因参数移除导致的性能损失,避免能力退化。
2.2 量化(Quantization):降低参数精度
将模型参数从高精度(如FP32、FP16)转换为低精度(如INT8、INT4),减少内存占用和计算开销,是边缘设备部署的核心技术。
- 静态量化:基于校准数据预先确定量化参数,推理时无需调整,适合对延迟敏感的场景。例如将ResNet模型从FP32量化为INT8,体积缩小75%,推理速度提升2-3倍,精度损失控制在2%以内。
- 动态量化:推理时动态调整量化范围,适配参数分布波动较大的模型(如LSTM),精度损失更低但计算逻辑稍复杂。
进阶方向:混合精度量化,对关键层保留高精度(如FP16),对非关键层使用低精度(如INT8),平衡性能与效率。
2.3 架构优化:重构高效网络结构
通过轻量化设计或稀疏化架构,让有限参数发挥更大效能,从根源上提升小模型性能上限。
- 轻量化模块设计:采用参数共享、窄通道、浅层数等策略,例如ALBERT通过跨层参数共享大幅减少参数量,DistilBERT将BERT参数削减40%,仍保留97%的语言理解能力,推理速度提升60%。视觉领域的EfficientNet系列通过AutoML优化深度、宽度、分辨率组合,以低计算量实现高精度。
- 稀疏化架构(MoE及衍生):引入“专家子模型+门控机制”,模型总参数量大但每次推理仅激活部分专家,兼顾性能与效率。例如Switch Transformer通过门控选择文本/图像专用专家,Mixture-of-Depth(MoD)模型动态跳过冗余层,以更少FLOPs达到深层Transformer性能。
2.4 神经架构搜索(NAS):自动探索最优结构
通过算法自动搜索适配任务的小模型结构,替代人工设计,往往能找到参数效率更高的网络。例如MobileNet系列、EfficientNet均通过NAS优化,在移动端场景下,自动搜索的小模型性能常超越人工设计的大模型。
三、知识蒸馏:让小模型“复刻”大模型能力
知识蒸馏(KD)的核心是让小模型(学生)模仿大模型(教师)的行为,不仅拟合最终标签,更学习教师模型的中间推理过程和概率分布,实现“知识迁移”。针对大模型的蒸馏需重点关注三类知识和前沿方法。
3.1 蒸馏的核心知识类型
|
知识类型 |
来源 |
作用与示例 |
|
输出层知识 |
教师模型的logits(概率分布) |
通过KL散度损失让学生模仿token生成概率,捕捉标签之外的不确定性,例如模仿GPT-4生成下一个token的分布。 |
|
中间层知识 |
教师模型的隐状态(如Transformer隐藏层特征) |
对齐师生模型的特征表征,保留深层语义理解能力,避免仅拟合表面答案。 |
|
推理链知识 |
教师模型的思维链(CoT)与工具调用路径 |
让学生模仿“问题→思考→工具调用→答案”的完整流程,提升推理和工具使用能力,例如模仿教师调用计算器的格式与逻辑。 |
3.2 前沿蒸馏方法:解决大模型蒸馏痛点
大模型蒸馏面临输出分布稀疏、长序列依赖、工具调用对齐三大难题,需采用针对性方法:
- 动态蒸馏:根据学生模型能力动态调整目标,早期聚焦教师Top-5 token分布(避免稀疏干扰),后期引入温度缩放(Temperature Scaling)优化全分布蒸馏,缓解梯度消失问题。
- 链式蒸馏(CoT Distillation):蒸馏推理链而非仅最终答案,例如教师生成“计算3^5→用计算器→结果243”,学生需模仿完整逻辑,大幅提升推理能力。Hsieh等提出的“Distilling Step-by-Step”方法,让770M参数T5模型超越5400亿参数PaLM的少样本表现。
- 合成数据蒸馏:用大模型生成高质量指令-响应数据,微调小模型实现离线蒸馏。典型案例如Stanford Alpaca,用GPT-3.5生成52K条数据微调7B LLaMA,性能逼近GPT-3.5,工业界常用此方法训练专用客服小模型。
四、实战策略:组合方法与落地要点
单一技术难以实现性能对齐,需结合压缩、蒸馏、微调等方法,按场景定制流程,以下为通用落地步骤及案例。
4.1 通用落地流程
- 基座选择:优先选用参数效率高的预训练小模型(如DistilBERT、Flan-T5 Small),而非从零训练,减少蒸馏成本。
- 压缩预处理:对教师模型进行结构化剪枝+量化,得到精简版教师模型,降低蒸馏过程的计算开销。
- 多阶段蒸馏:先进行中间层特征对齐,再蒸馏推理链,最后优化输出层概率分布,逐步迁移知识。
- 参数高效微调:用LoRA、Prompt Tuning微调学生模型,冻结大部分参数,仅调整少量参数适配任务,避免过拟合。
- 数据增强:结合高质量标注数据、大模型合成数据、多任务指令数据,丰富训练样本,提升泛化能力。
4.2 典型案例:工具调用小模型蒸馏
目标:将7B LLaMA(教师,带工具调用微调)蒸馏为1.5B学生模型,具备计算器调用能力。
- 数据准备:生成5000条含推理链的样本(如“计算8*12→计算器(8,'*',12)=96→答案96”)。
- 蒸馏训练:用动态蒸馏策略,早期模仿教师Top-3 token分布,后期用温度缩放优化KL散度损失,同时对齐Transformer第8层隐状态。
- 压缩部署:将学生模型量化为INT8,推理速度提升3倍,显存占用降至原教师模型的1/5,工具调用准确率保留92%。
五、关键优化要点与注意事项
- 性能权衡:压缩与蒸馏需平衡精度、速度、显存三者关系,边缘设备优先保证速度,服务器端可适当保留精度。
- 避免能力退化:大模型的涌现能力易因过度压缩丢失,需控制剪枝比例(建议单次不超过50%),蒸馏后必须用任务数据再微调。
- 硬件适配:结构化剪枝、INT8量化更适配ARM芯片等边缘硬件,非结构化剪枝需依赖GPU稀疏计算支持。
- 任务针对性:专用任务(如文本分类)可大幅压缩,通用任务(如多模态生成)需保留更多参数和中间层知识。
六、总结
小模型逼近大模型性能的核心是“压缩提效+蒸馏传知”的组合策略:通过剪枝、量化、架构优化精简模型结构,降低部署成本;通过动态蒸馏、链式蒸馏、合成数据迁移大模型知识,弥补参数量差距。在实际落地中,需结合任务场景、硬件资源定制技术方案,同时通过多阶段训练、参数高效微调进一步优化性能,最终实现“小而强”的模型部署目标。
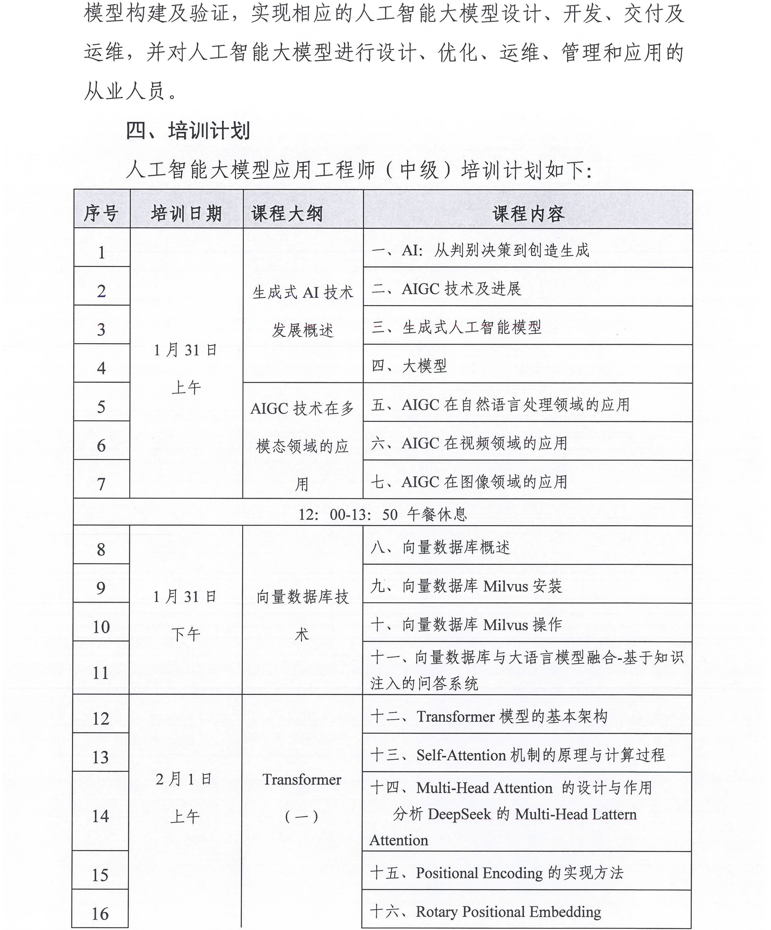
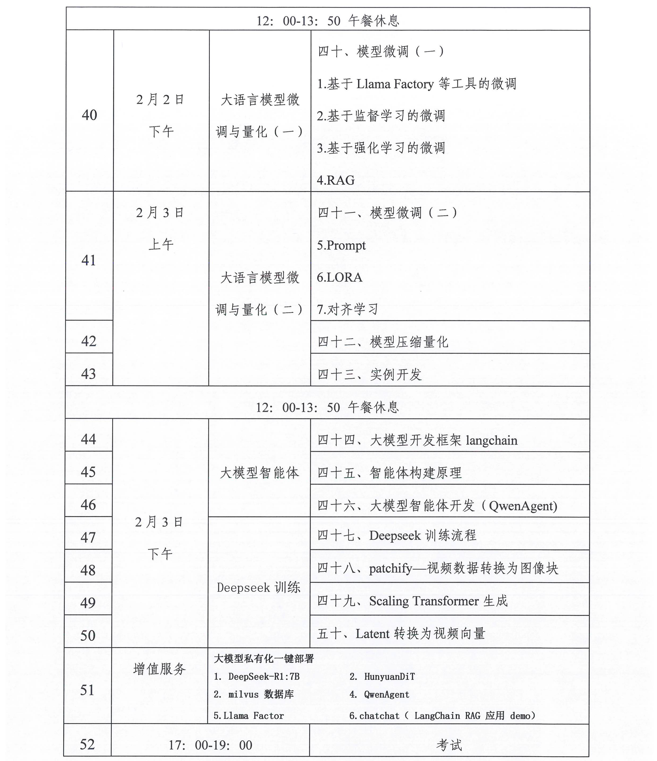
相关学习推荐:工业和信息化部电子工业标准化研究院关于开展人工智能从业人员 “人工智能大模型应用工程师”专项学习课纲



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)