【小白驯AI日志】机器学习篇01—从零到KNN:一张图看懂ML家谱
如果你也在凌晨两点对着‘RuntimeError: CUDA out of memory’发呆——嗨,同行人你好。我,不久前连 NumPy 都要拼错的小白,决定把这段‘被代码按在地上摩擦’的日常公开记录。不为流量,不为变现,只想证明:普通人也能把 AI 这头巨兽一点点撸顺毛。这篇笔记,写给同样迷路却不想放弃的你,也写给下一个深夜还在改 bug 的自己
不再多言,我们马上开始
机器学习定义
本质上来说,机器学习就是让计算机自己在数据中学习规律,并且根据所得到的规律对未来做预测,总的来讲就是机器学习是通过数据驱动构建模型,让计算机自主学习规律,并据此进行预测或决策
机器学习算法
线性回归、逻辑回归、聚类算法(K均值聚类)、决策树、朴素贝叶斯、深度学习(卷积神经网络CNN、循环神经网络RNN、长短时记忆网络LSTM)等算法,这里举了几个最基本的,后面会慢慢谈到
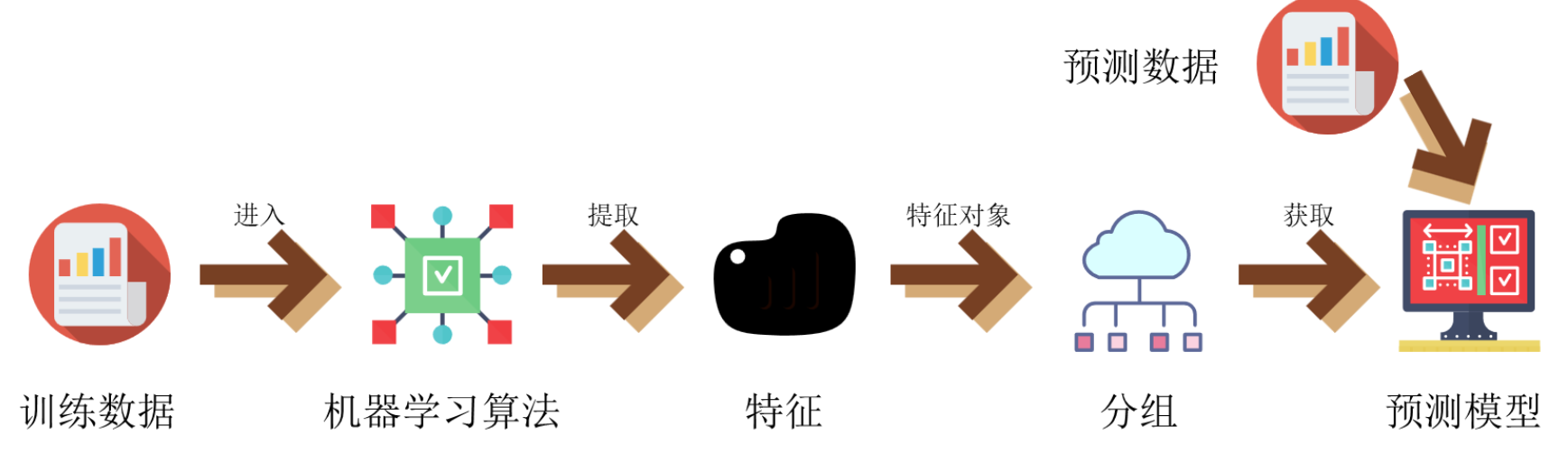
机器学习的简单图解
机器学习的发展历史
1.机器学习的起源
20世纪50年代,人工智能的概念被提出,旨在通过计算机模拟人类的智能行为
20世纪40-50年代:早期理论基础
1943年,心理学家Warren McCulloch和数学家Walter Pitts提出了第一个神经网络数学模型(MCP神经元模型),为机器学习奠定了早期理论基础。1950年,艾伦·图灵在其论文《计算机器与智能》中提出了“机器能否思考”的问题,并暗示了通过数据训练实现智能的可能性。
1956年:人工智能的诞生
达特茅斯会议正式提出“人工智能”概念,标志着包括机器学习在内的AI研究开端。会议上,Arthur Samuel首次明确使用“机器学习”一词,并开发了第一个通过学习提升能力的跳棋程序。
1957-1969年:算法与模型的突破
1957年,Frank Rosenblatt提出感知机(Perceptron),成为最早的监督学习算法之一。1967年,最近邻算法(k-NN)诞生,为无监督学习提供了基础方法。
20世纪70-80年代:统计学习与反向传播
统计学家开始将概率模型引入机器学习,如线性判别分析(LDA)。1986年,反向传播算法(Backpropagation)的普及推动了神经网络的复兴,为深度学习埋下伏笔。
2.神经网络的探索
20世纪80年代,神经网络(BP)的研究开始兴起,旨在通过模拟人脑神经元网络来处理信息。
20世纪80年代是神经网络研究的重要转折点。在这个时期,以反向传播算法(Backpropagation,简称BP)为代表的神经网络研究开始蓬勃发展。科学家们希望通过模拟人脑神经元网络的信息处理机制,来构建能够自主学习的人工智能系统
3.算法的出现
随着机器学习的发展,支持向量机、朴素贝叶斯等算法相继出现,将机器学习从知识驱动转变为数据驱动的思路
1970年代-1980年代:统计学习理论奠基
- 1970年:线性判别分析(LDA)被广泛应用于分类问题。
- 1980年:决策树算法(如ID3)由Ross Quinlan提出,推动了基于规则的机器学习。
- 1986年:反向传播算法(Backpropagation)的普及使得多层神经网络训练成为可能。
1990年代:经典算法成熟
- 1992年:支持向量机(SVM)由Vapnik等人提出,基于统计学习理论,成为小样本学习的标杆。
- 1995年:AdaBoost算法诞生,推动了集成学习方法的发展。
- 1997年:朴素贝叶斯(Naive Bayes)在文本分类领域得到广泛应用,因其高效和简单性。
2000年代:数据驱动与大规模应用
- 2001年:随机森林(Random Forest)由Breiman提出,结合了决策树和Bagging思想。
- 2006年:深度学习复兴,受限玻尔兹曼机(RBM)和深度信念网络(DBN)推动神经网络新一轮发展。
2010年代至今:深度学习主导
- 2012年:AlexNet在ImageNet竞赛中获胜,标志着卷积神经网络(CNN)的崛起。
- 2014年:生成对抗网络(GAN)提出,推动了无监督学习的发展。
- 2017年:Transformer架构出现,彻底改变了自然语言处理领域
4.深度学习主导发展
2012年,随着算力提升和海量训练样本的支持,深度学习成为机器学习研究热点,并带动了产业界的广泛应用
2012年
- AlexNet在ImageNet竞赛中夺冠,首次显著超越传统方法,标志着深度学习在计算机视觉领域的突破。
2013年
- 谷歌收购DeepMind,布局深度学习与人工智能研究。
- Word2Vec模型发布,推动自然语言处理(NLP)领域的词向量技术发展。
2014年
- 生成对抗网络(GAN)由Ian Goodfellow提出,开启生成模型研究热潮。
- VGGNet和GoogLeNet相继发布,进一步优化图像识别性能。
2015年
- ResNet问世,通过残差连接解决深层网络训练难题,成为后续模型的基础架构。
- TensorFlow开源,降低深度学习技术应用门槛。
2016年
- AlphaGo击败围棋世界冠军李世石,引发公众对深度学习的广泛关注。
- Transformer架构提出,为后续大语言模型(如GPT、BERT)奠定基础。
2017年
- 注意力机制和Transformer在机器翻译中取得突破,推动NLP领域变革。
- PyTorch发布动态计算图特性,成为研究社区主流框架之一。
2018年
- GPT-1和BERT发布,预训练语言模型开始引领NLP技术方向。
- 深度学习在医疗影像、自动驾驶等产业落地加速。
2020年
- GPT-3展现大规模语言模型的强大能力,引发生成式AI浪潮。
- Vision Transformer(ViT)将Transformer引入计算机视觉,挑战CNN传统优势。
机器学习分类
历经多年的发展,机器学习衍生出了多种分类方法,一般我们按照学习模式的不同,将他们分为监督学习、半监督学习、无监督学习与强化学习
1.监督学习(Supervised Learning)
定义:
我们从已有的训练集(经过标记)单重学习模型,然后根据我们搭建出来的模型进行预测的一种机器学习方法,简单来讲,我们人为的给训练数据集加入标签来辅助计算机学习模型,这就是所谓的“监督”,是需要人参与其中的。
常见算法:
线性回归:通过找到最佳拟合线来预测因变量的值。
逻辑回归:用于二元分类的监督学习算法
决策树:通过构建树状结构来对新的数据进行分类或回归
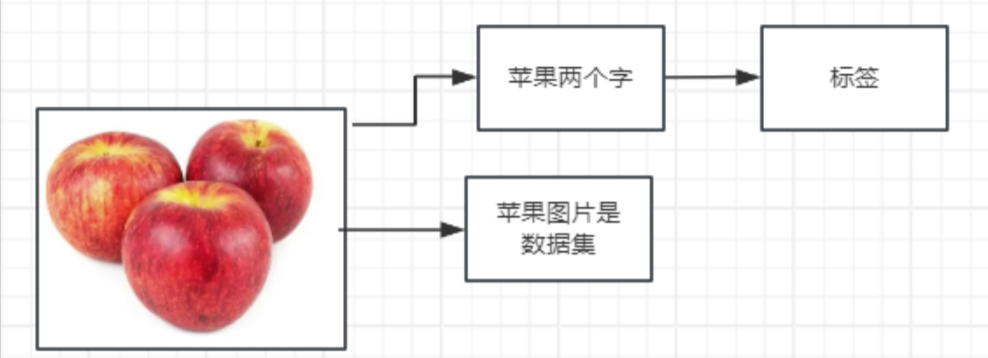
监督学习的简单例子
2.无监督学习(UnSupervised Learning)
定义:
是一种机器学习方法,它通过分析输入数据的特点和结构,自动地找出数据中的模式和规律,而不需要人工标注和干预,简而言之,就是让计算机自己找数据里的规律,不用人告诉它答案。
常见算法:
K-means:用于聚类分析。
DBSCAN:基于密度的算法,发现任意形状的聚类。
层次聚类:基于距离的算法,将数据点按照距离远近进行聚类。
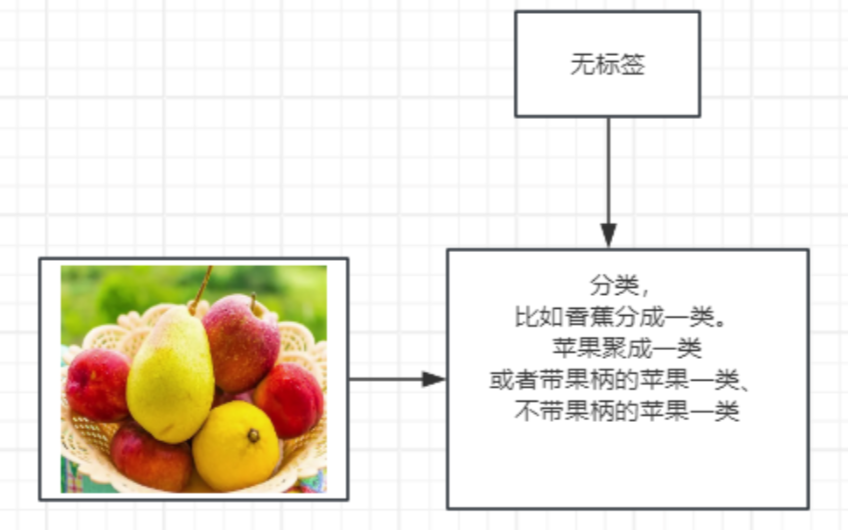
无监督学习的简单例子
3.半监督学习
定义:
一种机器学习方法,它结合了少量标记数据和大量未标记数据来进行训练和预测,旨在利用未标记数据中的信息来提高模型的性能,打比方讲,就像是老师只给了你几个已经标注好的样本(标记数据),然后让你自己去研究更多的未标注样本(未标记数据),通过这些未标注样本中的信息来提高你的学习效果
常见算法:
标签传播:通过迭代地传播标签,使得每个样本的标签都尽可能地一致。
学习算法:通过学习算法可以训练出更好的模型,提高分类准确率。
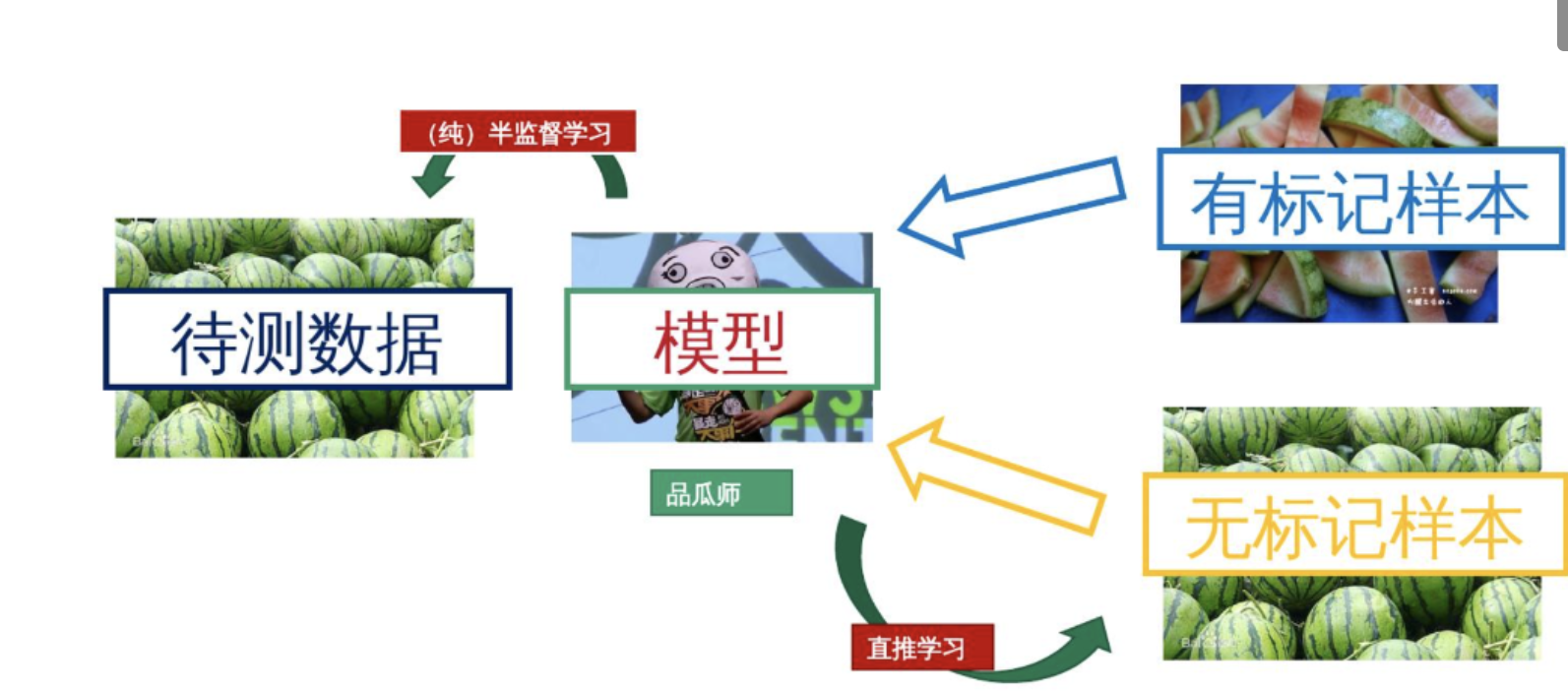
半监督学习的简单例子
4.强化学习
定义:
一种通过智能体与环境的交互来学习最优策略的机器学习方法。它通过奖励机制来指导智能体的行为,目标是最大化累积奖励,简要来讲,就是通过试错的方式让机器学习如何做出最优决策
常见算法:
Q-Learning:构建Q表来对环境进行建模实现决策。
Deep Q Network (DQN):结合深度学习通过训练神经网络来逼近Q函数,实现更高效的学习。
Policy Gradient Methods:优化策略寻找最优解。
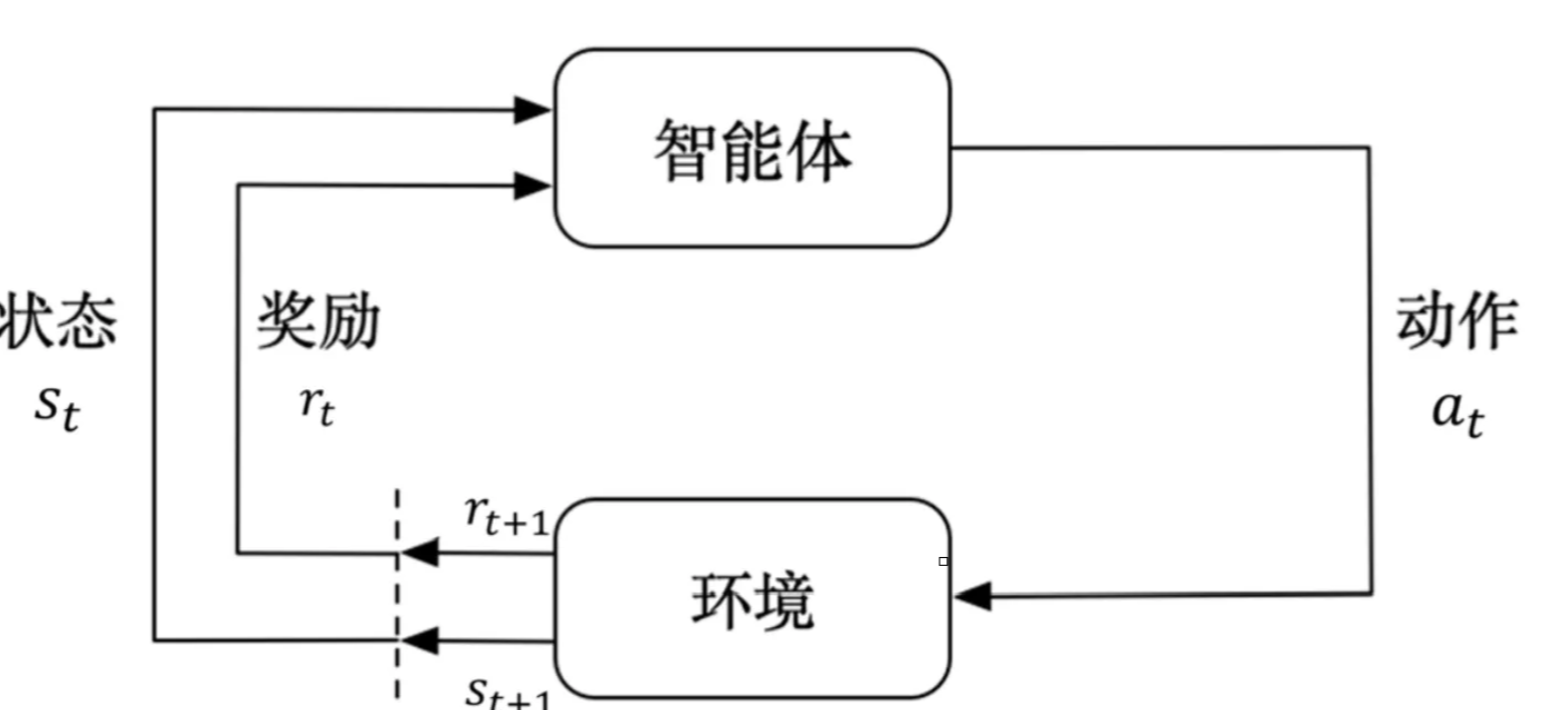
强化学习的简单图示
结语:
本文从“零经验”视角梳理了机器学习的核心概念、发展脉络与四大学习范式,并穿插亲历的踩坑日常。读完你应已明白:ML 是用数据让机器自己找规律的游戏,而深度学习只是其中一条“更深”的路线;无论监督、无监督还是强化学习,本质都是“模型+数据+目标”的三件套。
下一章,我们将了解在研究开发过程中经常用到的第三方库scikit-learn以及第一个算法——KNN(K近邻算法)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)