AI基石 | 机器学习基础(二):不以成败论英雄 —— 准确率、F1 分数与 ROC/AUC,谁才是真正的评判标准?
评估机器学习模型需超越准确率,掌握混淆矩阵、精确率、召回率、F1分数及ROC/AUC等多维度指标。
AI基石 | 机器学习基础(二):不以成败论英雄 —— 准确率、F1 分数与 ROC/AUC,谁才是真正的评判标准?
前言
在上一篇,我们学会了用逻辑回归。假设你训练好了一个预测癌症模型,跑了一下测试集,发现准确率(Accuracy)高达 99.9%。
你兴冲冲地拿着结果去找医生:“看,我的 AI 神医,误诊率只有 0.1%!”
医生看了一眼你的模型逻辑,冷冷地说:“你这个模型是个垃圾,它会害死人的。”
为什么?
因为在 1000 个人里,可能只有 1 个人真正得了癌症。你的模型只要闭着眼睛全部预测‘没病’,准确率就能达到 99.9%。
但是,那个唯一的病人被你漏掉了,因为延误治疗而死亡。
这就是 AI 领域最著名的 “准确率陷阱”。今天,我们要学会一套 “不以(单一)成败论英雄” 的评判体系,彻底看懂混淆矩阵、F1 分数和 ROC/AUC。
一、 万恶之源:混淆矩阵 (Confusion Matrix)
所有的指标,都源自这个简单的 2×22 \times 22×2 表格。不理解它,就别谈评估。
假设我们在进行 新冠病毒检测(正样本=阳性=有病):
| AI 预测:阳性 (Positive) | AI 预测:阴性 (Negative) | |
|---|---|---|
| 真实:阳性 (True) | TP (真阳性) 恭喜,抓住了病人! | FN (假阴性) 💀 漏诊! 病人跑了,最危险的情况。 |
| 真实:阴性 (False) | FP (假阳性) ⚠️ 误诊! 吓唬健康人,但这只是虚惊一场。 | TN (真阴性) 没事,大家都健康。 |
- 记忆口诀:
- 第一个字母(T/F):AI 猜对了(True)还是猜错了(False)?
- 第二个字母(P/N):AI 猜的是阳性(Positive)还是阴性(Negative)?
核心结论:不同的业务场景,对 FP 和 FN 的容忍度是完全不同的。
- 癌症筛查:FN (漏诊) 是不可接受的,宁可错杀一千 (FP),不可放过一个。
- 垃圾邮件:FP (误杀) 是不可接受的,你不想老板的重要邮件被扔进垃圾箱。
二、 精确率与召回率:鱼与熊掌的博弈
因为准确率((TP+TN)/总数(TP+TN)/总数(TP+TN)/总数)在样本不平衡时会失效,我们引入两个更专一的指标。
1. 精确率 (Precision) —— “神枪手”
Precision=TPTP+FP Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
- 含义:在你开枪打中的人里,有多少个是坏人?
- 心态:宁缺毋滥。我不敢轻易开枪,但只要我开枪,就必须保证打中坏人。
- 适用:垃圾邮件过滤、视频推荐(推错用户会烦)。
2. 召回率 (Recall) —— “大撒网”
Recall=TPTP+FN Recall = \frac{TP}{TP + FN} Recall=TP+FNTP
- 含义:在所有的坏人里,你到底抓住了几个?
- 心态:宁错杀不放过。不管是好人坏人我先抓起来再说,绝对不能让坏人跑了。
- 适用:地震预测、传染病筛查、金融反欺诈。
3. F1 分数 (F1 Score) —— “端水大师”
很多时候,老板既要马儿跑(高召回),又要马儿不吃草(高精确)。这时候看 F1。
F1=2×Precision×RecallPrecision+Recall F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
- 它是精确率和召回率的调和平均数。
- 为什么不是算术平均?
- 假设 Precision=100%, Recall=0%(一个坏人都没抓到)。
- 算术平均 = 50%(看起来还行?错!)。
- 调和平均 (F1) = 0(直接判定模型失效)。
- 结论:F1 能惩罚严重的偏科。
三、 ROC 与 AUC:不看脸色的硬核指标
上面讲的指标,都有一个共同的缺陷:它们都依赖于一个固定的阈值(Threshold)。
逻辑回归输出的是概率(比如 0.6)。通常我们以 0.5 为界,大于 0.5 算阳性。
但如果我们把门槛提高到 0.9(严防误报),或者降低到 0.1(严防漏报),Precision 和 Recall 就会剧烈波动。
有没有一个指标,不管你门槛怎么变,都能衡量模型够不够硬?
有,这就是 AUC (Area Under Curve)。
1. ROC 曲线怎么画?
我们让阈值从 0 滑动到 1,记录每一刻的:
- 横轴:假阳性率 (FPR) —— 好人被误抓的比例(代价)。
- 纵轴:真阳性率 (TPR/Recall) —— 坏人被抓住的比例(收益)。

2. AUC (曲线下面积) 的物理意义
AUC = 0.8 表示什么?
它的含义极其直观:
随机挑一个正样本(病人)和一个负样本(健康人)。
你的模型给“病人”打的分数 高于 给“健康人”打分的概率,是 80%。
- AUC = 0.5:瞎猜(抛硬币)。
- AUC = 1.0:神级模型,完美区分。
- AUC < 0.5:反向毒奶(你猜它是阴性,那它大概率是阳性)。
四、 实战:用代码戳穿“高准确率”的谎言
我们来构造一个极度不平衡的数据集(98个好人,2个坏人),看看 Accuracy 是怎么骗人的。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.dummy import DummyClassifier
from sklearn.metrics import (accuracy_score, f1_score, roc_auc_score,
confusion_matrix, ConfusionMatrixDisplay,
RocCurveDisplay)
# --- 1. 制造极度不平衡数据 ---
# 权重 0.98(负类/健康) : 0.02(正类/生病)
X, y = make_classification(n_samples=1000, n_features=20,
weights=[0.98, 0.02], random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# --- 2. 训练模型 ---
# A. 傻子模型:永远预测“0”(多数类)
# 策略:不管输入什么,永远预测“0” (没病/正常)
dummy = DummyClassifier(strategy="most_frequent")
dummy.fit(X_train, y_train)
y_pred_dummy = dummy.predict(X_test)
# B. 正经模型:逻辑回归
# class_weight='balanced' 是一个关键参数!告诉模型要重视少数类
model = LogisticRegression(class_weight='balanced', random_state=42)
model.fit(X_train, y_train)
y_pred_model = model.predict(X_test)
y_prob_model = model.predict_proba(X_test)[:, 1]
# 3. 对比时刻
print("--- 傻子模型表现 ---")
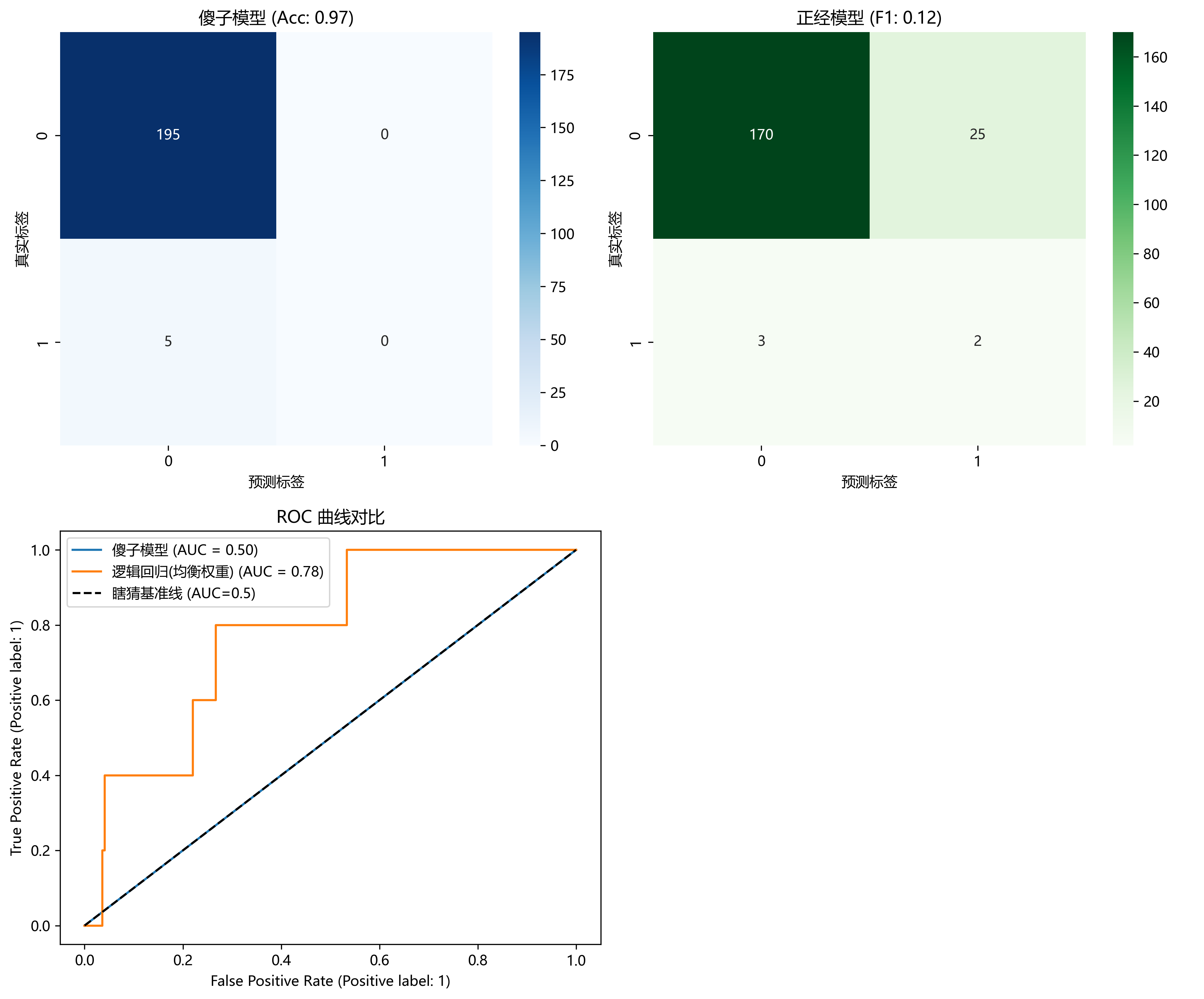
print(f"准确率: {accuracy_score(y_test, y_pred_dummy):.4f} (看起来很高!)")
print(f"F1 分数: {f1_score(y_test, y_pred_dummy):.4f} (露馅了)")
# 混淆矩阵会显示:TP=0,全是 FN
# --- 傻子模型表现 ---
# 准确率: 0.9750 (看起来很高!)
# F1 分数: 0.0000 (露馅了)
print("\n--- 正经模型表现 ---")
print(f"准确率: {accuracy_score(y_test, y_pred_model):.4f}")
print(f"F1 分数: {f1_score(y_test, y_pred_model):.4f}")
print(f"AUC 分数: {roc_auc_score(y_test, y_prob_model):.4f}")
# --- 正经模型表现 ---
# 准确率: 0.8600
# F1 分数: 0.1250
# AUC 分数: 0.7805
print("\n--- 正经模型的混淆矩阵 ---")
print(confusion_matrix(y_test, y_pred_model))
# --- 正经模型的混淆矩阵 ---
# [[170 25]
# [ 3 2]]
# --- 4. 可视化对比 ---
# 创建画布,一行两列
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
# === 第一行:混淆矩阵对比 ===
# 傻子模型的混淆矩阵
cm_dummy = confusion_matrix(y_test, dummy.predict(X_test))
sns.heatmap(cm_dummy, annot=True, fmt='d', cmap='Blues', ax=axes[0, 0])
axes[0, 0].set_title(f"傻子模型 (Acc: {accuracy_score(y_test, dummy.predict(X_test)):.2f})")
axes[0, 0].set_xlabel('预测标签')
axes[0, 0].set_ylabel('真实标签')
# 正经模型的混淆矩阵
cm_model = confusion_matrix(y_test, model.predict(X_test))
sns.heatmap(cm_model, annot=True, fmt='d', cmap='Greens', ax=axes[0, 1])
axes[0, 1].set_title(f"正经模型 (F1: {f1_score(y_test, model.predict(X_test)):.2f})")
axes[0, 1].set_xlabel('预测标签')
axes[0, 1].set_ylabel('真实标签')
# === 第二行:ROC 曲线对比 ===
# 合并到一个图里画
ax_roc = axes[1, 0]
# 傻子模型的 ROC (几乎是一条直线)
RocCurveDisplay.from_estimator(dummy, X_test, y_test, ax=ax_roc, name="傻子模型")
# 正经模型的 ROC (应该明显拱起)
RocCurveDisplay.from_estimator(model, X_test, y_test, ax=ax_roc, name="逻辑回归(均衡权重)")
# 画出对角线(瞎猜基准线)
ax_roc.plot([0, 1], [0, 1], "k--", label="瞎猜基准线 (AUC=0.5)")
ax_roc.set_title("ROC 曲线对比")
ax_roc.legend()
# 右下角留空或画点别的
axes[1, 1].axis('off')
plt.tight_layout()
plt.show()
代码预警
当你运行这段代码,你会发现:
- 傻子模型的准确率可能高达 98%,但 F1 分数是 0.0。
- 逻辑回归的准确率可能也是 98%,但 F1 分数可能是 0.5,AUC 是 0.8。
- 只有 F1 和 AUC 才能告诉你,谁才是真正有用的模型。
五、 总结:指标选择指南 (Cheat Sheet)
最后,送你一张面试/工作通用的选型指南:
- 数据极度不平衡(欺诈、癌症):
- 千万别看 Accuracy。
- 首选 PR 曲线(Precision-Recall)和 F1。
- 关注 Recall(甚至为了提高 Recall 牺牲 Precision)。
- 正负样本均衡(猫狗分类、手写数字):
- Accuracy 和 AUC 都可以。
- 你需要给出一个确定的 Yes/No:
- 看 F1 分数。
- 你需要给出一个概率/评分(比如信用分):
- 看 AUC。
结语
学会了这套评判标准,你现在拥有的不仅是编程能力,更是数据科学家的直觉。
下一次,当有人拿着 99% 的准确率向你炫耀时,请淡定地问他一句:
“那么,你的 AUC 是多少呢?”
下一篇预告
好了,经典的“小模型”时代我们彻底通关了。
是时候迎接真正的挑战了。下一篇,我们将直面那个改变世界的巨人。
《大模型基石:Transformer 架构 —— GPT 是如何“读懂”你的?》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)