AI模型推理场景中GPU参数如何影响关键性能指标,如何选择合适的GPU卡
GPU在推理场景中的表现,并非由单一参数决定,而是如同一个“木桶”,其效能取决于多项参数协同作用下的最短木板。通过建立参数与性能指标的关联模型,并结合典型业务场景分析,为不同推理需求下的GPU选型提供了明确的优先级指导与决策框架。:生成第一个Token前,GPU需将整个模型的参数从显存加载至芯片上的高速缓存。等分布式推理时,更多GPU核心和更高的互联带宽(如NVLink)能有效分摊计算负载,降低延
在AI模型推理部署中,GPU的选型直接决定了服务性能、用户体验与总体拥有成本。本文系统性地分析了GPU核心参数——显存容量、显存带宽、计算算力及其他相关指标——如何分别作用于首Token延迟(TTFT)、持续生成速度(Token/s) 和系统吞吐量(Throughput) 这三大关键性能指标。通过建立参数与性能指标的关联模型,并结合典型业务场景分析,为不同推理需求下的GPU选型提供了明确的优先级指导与决策框架。
一、核心参数系统解析:GPU的“木桶理论”
GPU在推理场景中的表现,并非由单一参数决定,而是如同一个“木桶”,其效能取决于多项参数协同作用下的最短木板。下图清晰地展示了从GPU硬件参数,到核心性能指标,再到典型应用场景的完整决策链条:
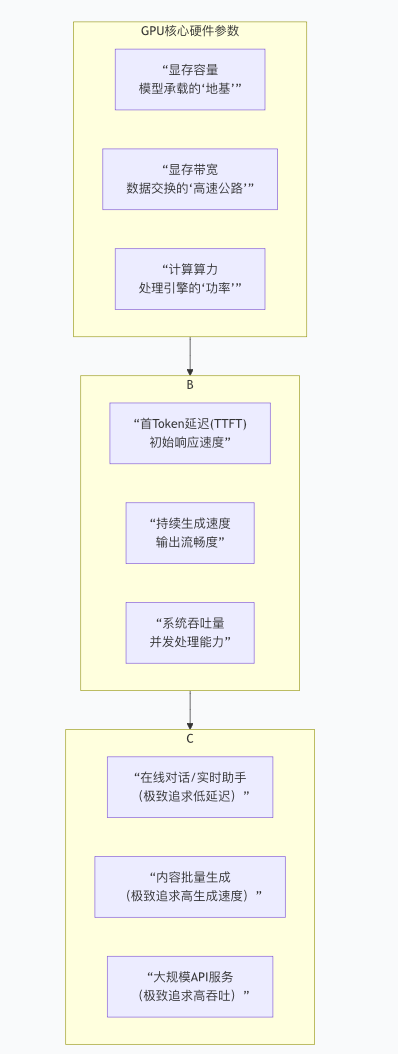
1. 显存容量:模型运行的硬性前提
显存容量是模型能否运行的基础前提,它决定了能够加载的模型规模上限。其关系可大致估算为:所需显存 ≈ 模型参数量 × 精度位数(字节)。
-
例如:以FP16(2字节)精度加载一个700亿(70B)参数的模型,至少需要约140GB显存。若采用更节省显存的量化技术(如INT8),可大幅降低此需求。
-
影响:容量不足将直接导致模型无法加载。但容量远超需求,通常不会带来直接的性能提升,仅为未来升级预留空间。
2. 显存带宽:数据吞吐的速率瓶颈
显存带宽指GPU芯片与显存之间数据交换的速度,是影响推理延迟和吞吐的关键瓶颈。正如相关技术分析指出,“显存带宽是决定GPU处理速度和效率的关键因素之一” ,它直接制约了从显存中读取模型权重和中间结果的速度。
-
对TTFT的影响(关键):生成第一个Token前,GPU需将整个模型的参数从显存加载至芯片上的高速缓存。此过程速度完全受限于显存带宽。带宽越高,初始化越快,首响应时间越短。
-
对吞吐量的影响(高):高带宽允许GPU在处理大批量并发请求时,能更快地在不同任务间切换和供给数据,从而提升整体服务能力。
3. 计算算力:决定持续生成速度的引擎
计算算力通常以TFLOPS或PFLOPS衡量,代表GPU执行浮点运算的峰值能力。它直接决定了单个计算任务的处理速度。
决策者应在明确自身核心业务场景(延迟敏感、吞吐敏感或成本敏感)的基础上,首先确保显存容量满足模型要求,再依据带宽与算力的优先级进行选择,并充分考虑功耗成本与软件生态的成熟度,从而做出最具性价比和前瞻性的技术决策。
四、结论与展望
为AI推理任务选择GPU是一项需要精准权衡的系统工程。不存在“通用最优”的显卡,只有“场景最适”的选择。
-
对Token/s的影响(关键):生成每个新Token都需要进行一系列矩阵运算。更高的算力意味着每个计算步骤完成得更快,从而直接提升Token/s,让输出更流畅。
-
对TTFT的影响(中等):首Token生成同样需完整计算,算力有贡献,但此阶段常受数据搬运(带宽)限制。
-
对吞吐量的影响(高):是高并发处理的基础算力保障。
-
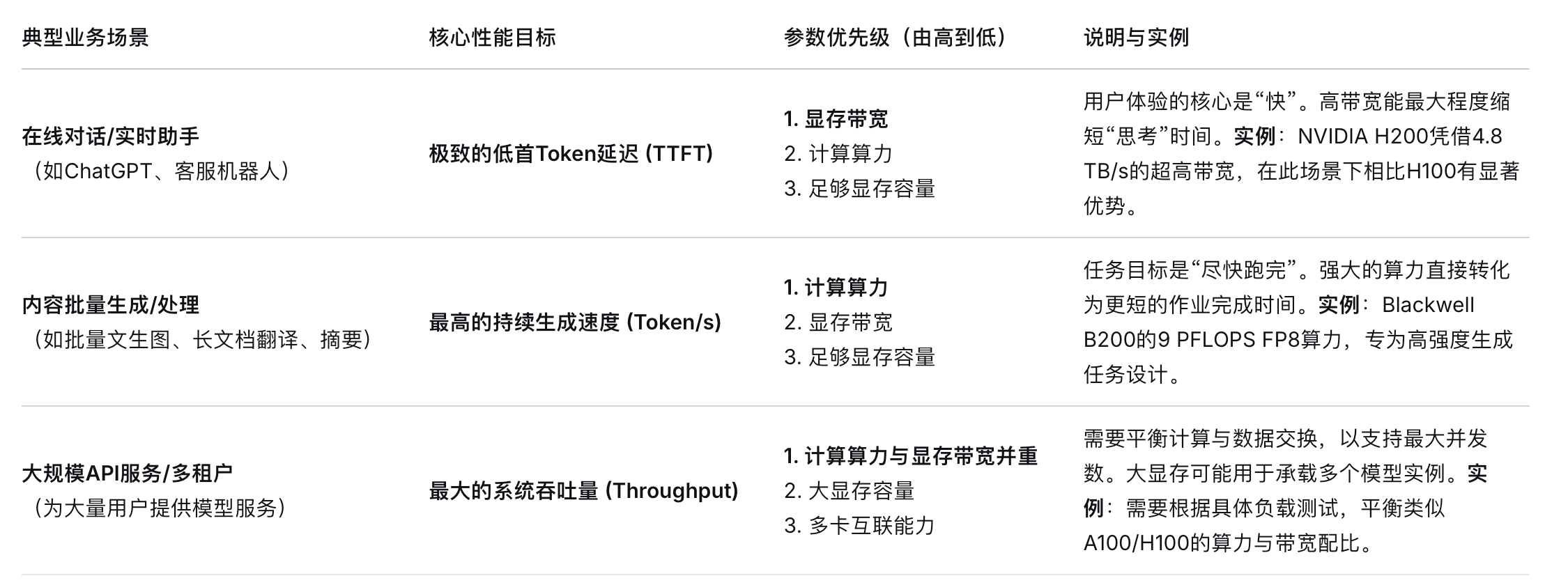
二、场景化选型指南:明确优先级
不同的业务场景对性能指标的侧重点截然不同,因此GPU参数的优先级也需相应调整。
-
-
其他重要考量因素:
-
核心数量与多卡互联:在实施Tensor并行等分布式推理时,更多GPU核心和更高的互联带宽(如NVLink)能有效分摊计算负载,降低延迟,提升吞吐。
-
功耗与能效:更高的性能往往伴随更高的功耗(如700W TDP)。这不仅关乎电费,更直接影响数据中心机架功率密度和散热方案的设计。
-
三、进阶考量:真实世界中的复杂性与权衡
在实际部署中,性能表现还受到以下因素的复杂影响,这些因素常与硬件参数交织作用:
-
模型优化与量化:采用INT8/INT4量化技术,能在几乎不损失精度的情况下,显著降低对显存容量和显存带宽的需求,并提升有效计算算力。这是成本效益极高的优化手段。
-
推理引擎优化:成熟的推理框架(如TensorRT-LLM, vLLM)通过算子融合、持续批处理(Continuous Batching)和KV缓存优化等技术,能更充分地“压榨”硬件潜力,尤其是提升显存带宽利用率和计算效率,从而优化TTFT和吞吐量。
-
上下文长度与KV缓存:处理长文本时,KV缓存会占用大量显存。此时,显存容量可能成为限制上下文长度的关键,并间接影响性能。
-
当前部署:若追求极致的在线推理低延迟,应优先关注显存带宽指标突出的型号(如H200)。
-
前沿与未来:若为下一代大规模、高复杂度的AI训练与推理基础设施布局,则应关注在计算算力和显存子系统上均有代际飞跃的新架构(如Blackwell B系列)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)