为什么 AI 视频总是换脸?字节跳动StoryMem,解决 AI 视频角色一致性
现在的 AI 视频模型就像只有“7 秒记忆”的小金鱼 。:上一秒主角还是个穿红裙子的金发女孩,下一秒镜头一换,她居然变成了穿牛仔裤的棕发御姐 。这种“角色大变脸”的尴尬,就是目前 AI 视频生成的最大痛点。
现在的 AI 视频模型就像只有“7 秒记忆”的小金鱼 。:上一秒主角还是个穿红裙子的金发女孩,下一秒镜头一换,她居然变成了穿牛仔裤的棕发御姐 。这种“角色大变脸”的尴尬,就是目前 AI 视频生成的最大痛点。

它们生成单个镜头很惊艳,但一旦要拍长一点的故事,就会把前面的设定忘得精光。不过,字节跳动(ByteDance)最近发布了一个叫 StoryMem的黑科技,彻底给 AI 装上了一个“超级大脑”!

AI 也会记笔记?揭秘 StoryMem 的“长效记忆”
StoryMem 的灵感,来自人类本身。人不会记住一整天的每一帧画面,而是记住几个关键画面:人物长什么样、发生了什么、情绪是什么。StoryMem 做的也是同一件事。你可以把它想成:AI 拍一镜,就往口袋里放几张“记忆照片”。下一镜拍摄前,先翻一眼这些照片,再继续拍。这些“照片”就是——从前面镜头里挑选出来的关键帧。
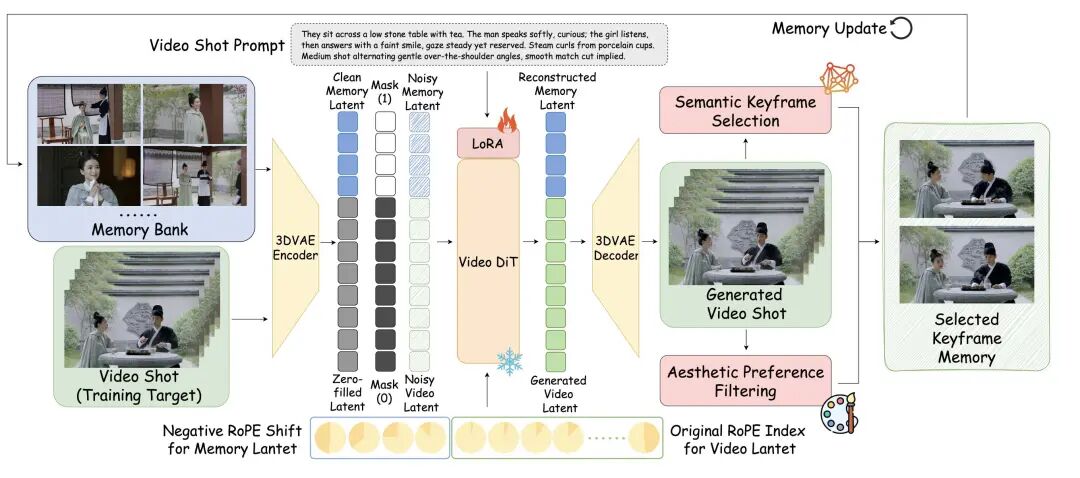
不是随便存,而是精挑细选:
-
内容上:这张图是不是代表了角色或场景的变化
-
质量上:模糊的、不好看的直接淘汰
-
于是 AI 的记忆既少而精,又始终在线
人类导演在拍连贯镜头时,会准备一本“剧组备忘录”,记录角色长相、衣服颜色和场景布置。
StoryMem 也有一本这样的“笔记”,它被称为记忆库(Memory Bank) 。
它不是死记硬背:每次 AI 生成一个新镜头,它不会把几千帧画面全部塞进大脑(那样电脑会爆炸),而是像个精明的摄影师,只挑选最关键、最美观的关键帧存起来 。
它会“往回看”:当 AI 准备拍下一个镜头时,它会先翻翻这本“笔记”,确保新镜头里的主角还是那张脸,背景还是那个公园 。

把“过去”变成“参考”:那个神奇的数学魔术
你可能会问,AI 怎么知道哪些是“以前发生的事”,哪些是“现在要画的画”呢?
这里用到了一个很酷的技术叫 Negative RoPE Shift(负向旋转位置嵌入偏移)。听起来很玄乎?其实很简单:

我们可以把它想象成给照片贴上“时间标签”。AI 给笔记里的旧照片贴上“-1, -2, -3”这样的负数标签,表示这是“过去”;而给正在画的新画布贴上“0, 1, 2”这样的正数标签 。
这样一来,AI 就能清晰地分辨:哦!这些负数标签的是我的“参考资料”,我要照着它们画,但我现在的任务是画出后面那个连续的动作 。

核心技术点
-
多镜头一致性:就像拍电视剧,演员不会每集换脸。StoryMem:靠“记忆照片”让角色一直是同一个人
-
只记关键,不记全部:像旅行相册,只留最重要的几张。StoryMem:只保存信息量大、质量高的画面
-
边拍边记,而不是拍完再修:像边写故事边回看前文。StoryMem:每一镜生成时,都参考已有记忆
-
不推翻原有能力,而是“外挂升级”:像给高手摄影师加了一个记事本。StoryMem:不重训大模型,只做轻量增强

AI 电影时代真的要来了吗?
StoryMem 的出现,标志着 AI 终于可以拍出长达一分钟、逻辑连贯的“真·短片”了 。这意味着以后你只需要给它一个故事剧本,它就能像个专业导演一样,维持着一致的角色和场景,把故事讲完 。
不管是制作个性化的动画,还是快速生成电影预告片,StoryMem 的潜力都让人兴奋 。但它最强的地方在于:即使场景换了,它依然记得主角在第一秒时的模样 。

StoryMem 有两个非常现实的意义:
第一,它真的能落地。它可以直接接入现有的视频生成流程,而不是推倒重来。
第二,它是“开放式”的。论文里不仅给了方法,还给了专门评测多镜头叙事的视频基准,等于在推动整个行业往“讲故事”这件事上前进一步。
这说明一件事:
视频生成,已经从“炫技阶段”,走向“叙事阶段”。

更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 40
40 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)