深入浅出完整解析ControlNet核心基础知识
和大家一些探讨学习,让我们一起感受ControlNet给AIGC图像生成/AI绘画带来的可控生成的无穷魅力!

欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
AIGC时代的 《三年面试五年模拟》AI算法工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写10万字Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章: 深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
AIGC算法岗/开发岗面试面经交流社群(涵盖AI绘画、AI视频、大模型、AI多模态、数字人等AIGC面试干货资源)欢迎大家加入:https://t.zsxq.com/33pJ0
码字不易,希望大家能多多点赞,给我更多坚持写下去的动力,谢谢大家!
站在2025年的视角来看,Rocky认为AIGC图像生成/AI绘画领域已经经历了“中场时刻”,全面进入新的发展阶段。以Nano Banana Pro、GPT-4o、Seedream 4.5、FLUX.2、FLUX.1 Kontext为代表的原生图像生成&图像编辑大模型的强大性能让2022年-2025年间90%的AIGC可控生成技术成为了AIGC时代历史长河中的数字尘埃,这是传统深度学习时代所不具备的重要特质。
ControlNet作为AIGC可控生成技术的“绝对领袖”,具备在AIGC时代作为跨周期技术工具的能力。其跟随开源生态中主流大模型Stable Diffusion 1.5 -> Stable Diffusion XL -> Stable Diffusion 3 -> FLUX.1 -> FLUX.1 Kontext -> FLUX.2的发展,也持续的完善其算法思想和模型架构。同时ControlNet很多的优化思想也被原生图像生成&图像编辑大模型所借鉴,ControlNet展现出了顽强的技术生命力。
Rocky认为除了ControlNet外,现在和未来的大部分AIGC可控生成技术并不具备长期的技术生命力,故Rocky不会再对其他AIGC可控生成技术进行长篇幅的深入解读,除非它们在长周期中证明了自己的价值。
由于ControlNet系列模型的网络结构比较复杂,不好可视化,导致大家看的云里雾里。因此本文中已经发布SD ControlNet、SDXL ControlNet、SD 3 ControlNet、FLUX.1 ControlNet、FLUX.1 Tool模型的可视化网络结构图,大家可以下载用于学习!
本文已经撰写ControlNet系列模型的训练全流程与详细解读内容,同时发布对应的保姆级训练资源,大家可以愉快地训练属于自己的ControlNet模型了!
本文已经新增对SDXL ControlNet、FLUX.1 ControlNet、FLUX.1 Tool等最新模型的解读!!!
大家好,我是Rocky。
2022年注定伟大,AI行业从传统深度学习时代正式迈向了AIGC时代。在Stable Diffusion、FLUX.1、DeepSeek、Midjourney以及ChatGPT等AIGC大模型井喷式爆发的背景下,AIGC时代的持续发展浪潮进入了不可逆转的时刻。
AIGC图像生成/AI绘画作为AIGC时代的核心方向之一,在开源社区已经形成以Stable Difffusion、FLUX.1为核心,以ConrtolNet和LoRA为辅助模块的繁荣AIGC图像生成/AI绘画工作流(Workflow)生态。
而Rocky在本文将要介绍的ControlNet系列模型正是让AIGC图像生成/AI绘画领域无比繁荣的关键一环,它让AIGC图像生成/AI绘画的生成过程更加的可控,有助于广泛地将AIGC图像生成/AI绘画技术应用到各行各业中,为AIGC产品和解决方案的商业落地奠定坚实的基础。

同时,由于Stable Diffusion/FLUX.1 + LoRA + ControlNet三巨头的强强联合,形成了一个千变万化的AIGC图像生成/AI绘画“兵器库”。在这个大兵器库中,传统图像处理技术和Low-Level算法技术(Canny、Depth、SoftEdge、OpenPose、MLSD、Lineart、Blur等) 再次得到广泛使用,成功“文艺复兴”;传统深度学习技术(人脸识别、人体关键点检测、手部识别、目标检测、图像分割、图像分类等) 也直接过渡到AIGC时代中,成为AIGC图像生成/AI绘画工作流中的重要辅助技术工具。AI计算机视觉历史中的技术沉淀与积累,都在AIGC时代有了相应的位置。
Rocky相信,Stable Diffusion是AIGC时代的“YOLO”,Stable Diffusion XL是AIGC时代的“YOLOv3”,Stable Diffusion 3是AIGC时代的“YOLOv4”,FLUX.1是AIGC时代的“YOLOv5”,LoRA系列模型是AIGC时代的“ResNet”,那么ControlNet系列模型就是AIGC时代的“Transformer”!
因此在本文中,Rocky主要对ControlNet的全维度各个方面都做一个深入浅出的分析总结 (最新ControlNet干货资源分享,ControlNet模型原理解析,ControlNet模型结构解析,ControlNet模型经典应用场景介绍,SDXL ControlNet模型原理解析、FLUX.1 ControlNet等前沿模型原理解析,ControlNet模型在不同AI绘画框架从0到1推理运行保姆级教程,ControlNet模型从0到1保姆级训练教程,以ControlNet模型为核心的商业落地应用案例等) ,和大家一些探讨学习,让我们一起感受ControlNet给AIGC图像生成/AI绘画带来的可控生成的无穷魅力!
1. ControlNet系列资源
- ControlNet论文:Adding Conditional Control to Text-to-Image Diffusion Models
- 官方项目:lllyasviel/ControlNet: Let us control diffusion models
- ControlNet 1.1项目地址:lllyasviel/ControlNet-v1-1-nightly
- FLUX.1 ControlNet项目地址:XLabs-AI/x-flux
- WebUI上的ControlNet插件:Mikubill/sd-webui-controlnet
- ComfyUI上的ControlNet插件:comfyui_controlnet_aux、ComfyUI-Advanced-ControlNet、x-flux-comfyui
- ControlNet全系列模型权重百度云网盘:关注Rocky的公众号WeThinkIn,后台回复:ControlNet,即可获得资源链接,包含ControlNet 1.0官方所有模型权重、ControlNet 1.1官方所有模型权重(原生版本与剪枝版本,其中原生版本(1.35GB)后缀为pth,剪枝版本(689M)后缀为safetensors)、ControlNet SDXL官方所有模型权重、ControlNet SD2.1所有模型权重以及全网最全的ControlNet第三方模型权重(包含二维码生成ControlNet、光影控制ControlNet、手部控制ControlNet等)。
- diffusers框架的ControlNet训练脚本:diffusers/examples/controlnet
- 官方的ControlNet训练脚本:lllyasviel/ControlNet/tutorial_train.py
Rocky会持续把更多ControlNet的资源更新发布到本节中,让大家更加方便的查找ControlNet系列模型的最新资讯。
2. 深入浅出完整解析ControlNet核心基础原理
2.1 零基础深入浅出理解ControlNet的整体架构
ControlNet是一种“辅助式”的神经网络模型结构,通过在Stable Diffusion/FLUX.1模型中添加辅助模块,从而引入“额外条件”来控制AIGC图像/AI绘画的生成过程。
在讲解核心原理前,我们先来了解一下在AIGC图像生成/AI绘画生态中,ControlNet是如何使用的。让大家有一个通俗易懂的直观认识与感受。
在以Stable Diffusion和FLUX.1为核心的AIGC图像生成过程中,想要ControlNet起作用,首先我们需要输入一张参考图,通过预处理器(Preprocessor) 对输入参考图按一定的模式进行预处理,通常是使用传统的计算机视觉算法(如边缘检测、人体姿态估计、深度估计等)来从输入参考图中提取出纯粹的控制信息,也就是我们常说的条件图像(Conditioning Image)。
当然的,我们也可以不使用预处理功能,直接输入一张自己处理好的图片当作预处理图。下面是Rocky构建的ControlNet的条件图像处理流程图示,让大家能够更好的理解: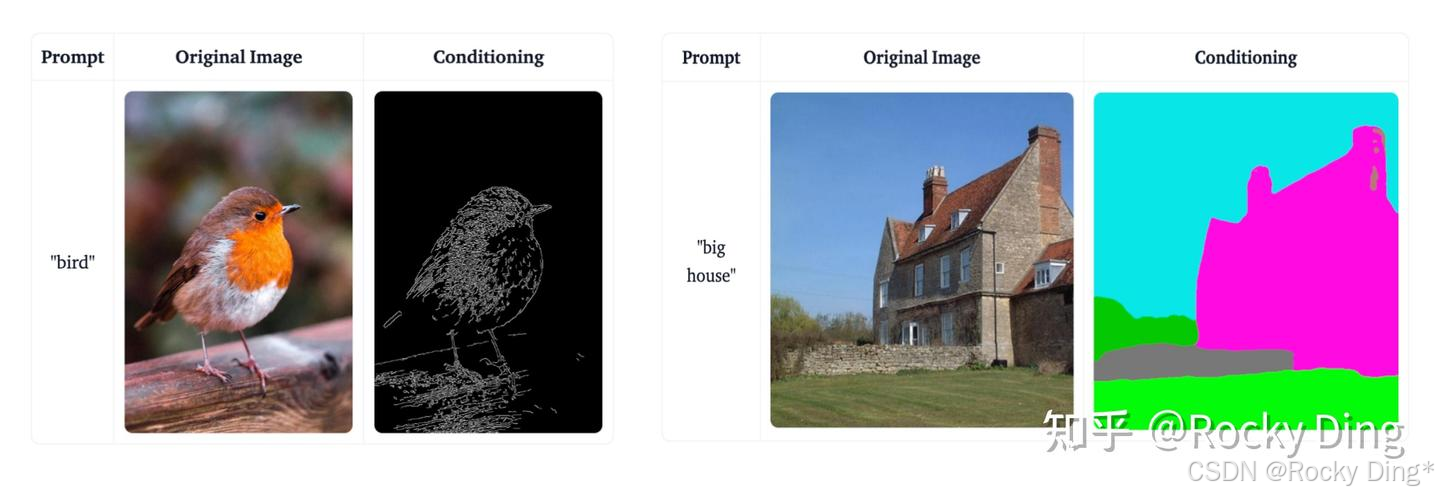
接着条件图像信息通过ControlNet再注入到Stable Diffusion和FLUX.1中,再加上原本就直接注入到Stable Diffusion和FLUX.1中的文本信息和图像信息(可选,进行图生图任务),综合作用进行扩散过程,最终生成受条件信息控制的图像。
总的来说,ControlNet做的就是这样一件事:它为扩散模型(如Stable Diffusion/FLUX.1)提供一种额外的“约束”条件,引导AIGC大模型按照我们期望的构图、姿态或结构来生成图像,减少图像生成的随机性。
为了大家方便的理解,Rocky也制作了ControlNet推理的完整流程图,大家可以直观的学习理解: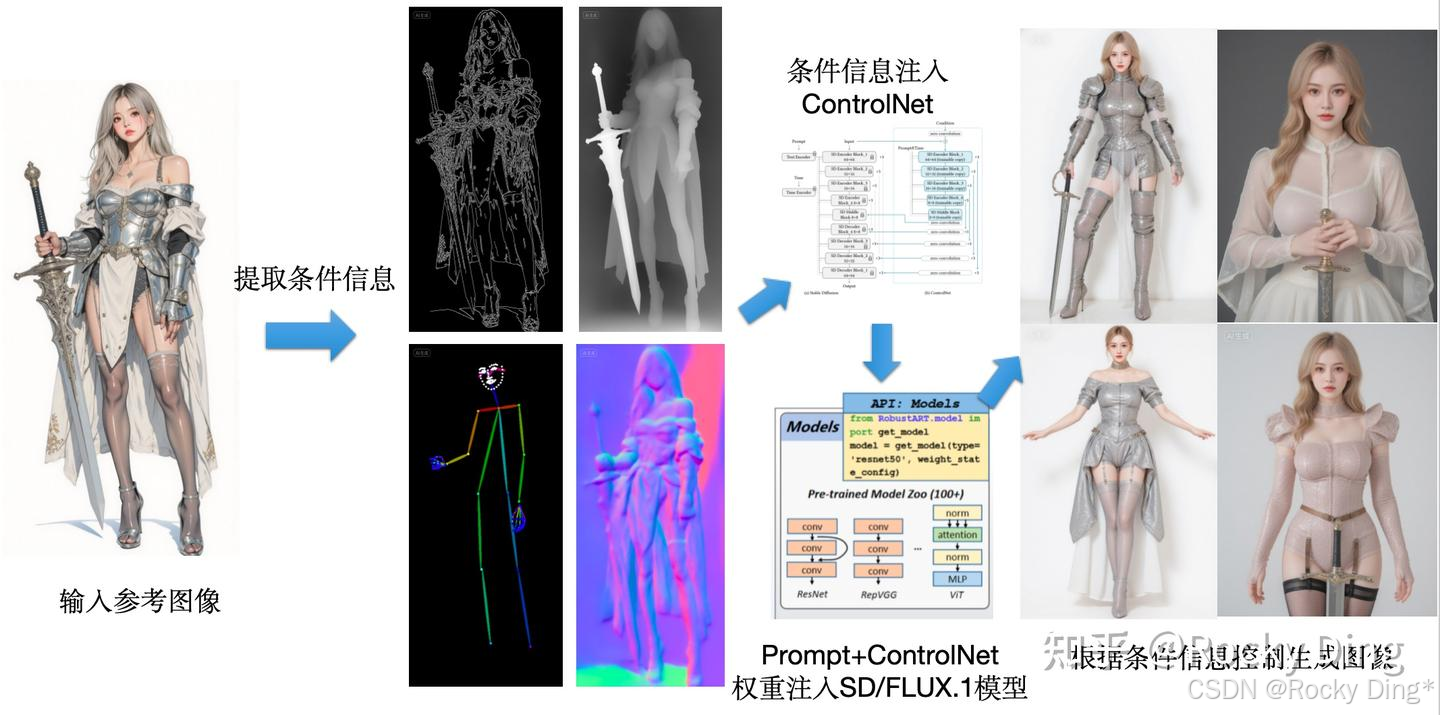
与此同时,在推理阶段需要同时加载Stable Diffusion/FLUX.1模型权重以及ControlNet模型权重,整体参数量要比仅使用Stable Diffusion/FLUX.1大约多0.7B,因此加载ControlNet需要占用更多的显存。
2.2 深入浅出理解ControlNet各模块的核心基础原理
在本章节中,Rocky将带着大家深入理解ControlNet的各个结构的原理。我们先从ControlNet模型的最小单元开始讲起,下图是ControlNet模型的最小单元: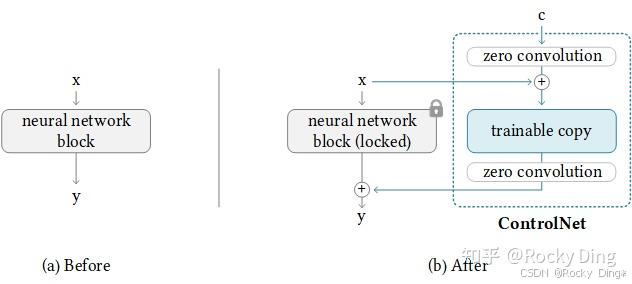
从上图可以看到,在使用ControlNet模型之后,Stable Diffusion/FLUX.1模型的权重被复制出两个相同的部分,分别是“锁定”副本(locked)权重和“可训练”副本(trainable copy)权重。
我们如何理解这两个副本权重呢? Rocky从训练角度和推理角度给大家进行通俗易懂的讲解。
首先不管是训练阶段还是推理阶段,ControlNet都在“可训练”副本上输入控制条件 c c c,然后将“可训练”副本输出结果和原来Stable Diffusion/FLUX.1模型的“锁定”副本输出结果**相加(add)**获得最终的输出结果。
在训练阶段,其中“锁定”副本中冻结参数,权重保持不变,保留了Stable Diffusion/FLUX.1模型原本的能力;与此同时,使用新数据对“可训练”副本进行微调训练,学习数据中的控制条件信息。因为有Stable Diffusion/FLUX.1模型作为预训练权重,复制“可训练”副本而不是直接训练原始权重还能避免数据集较小时的过拟合,所以我们使用常规规模数据集(几K-几M级别)就能对控制条件进行学习训练,同时不会破坏Stable Diffusion/FLUX.1模型原本的能力(从数十亿张图像中学习到的大型模型的能力)。
另外,大家可能发现了ControlNet模型的最小单元结构中有两个zero convolution模块,它们是1×1卷积,并且在微调训练时权重和偏置都初始化为零(zero初始化)。这样一来,在我们开始训练ControlNet之前,所有zero convolution模块的输出都为零,使得ControlNet完完全全就在原有Stable Diffusion/FLUX.1底模型的能力上进行微调训练,这样可以尽量避免训练加入的初始噪声对ControlNet“可训练”副本权重的破坏,保证了不会产生大的能力偏差。
这时大家很可能就会有一个疑问,如果zero convolution模块的初始权重为零,那么梯度也为零,ControlNet模型将不会学到任何东西。那么为什么“zero convolution模块”有效呢?(AIGC算法面试必考点)
Rocky进行下面的推导,相信大家对一切都会非常清晰明了:
我们可以假设ControlNet的初始权重为: y = w x + b y=wx+b y=wx+b,然后我们就可以得到对应的梯度求导:
∂ y ∂ w = x , ∂ y ∂ x = w , ∂ y ∂ b = 1 \frac{\partial y}{\partial w}=x,\frac{\partial y}{\partial x}=w,\frac{\partial y}{\partial b}=1 ∂w∂y=x,∂x∂y=w,∂b∂y=1
如果此时 w = 0 w=0 w=0并且 x ≠ 0 x \neq 0 x=0,然后我们就可以得到:
∂ y ∂ w ≠ 0 , ∂ y ∂ x = 0 , ∂ y ∂ b ≠ 0 \frac{\partial y}{\partial w} \neq 0,\frac{\partial y}{\partial x}=0,\frac{\partial y}{\partial b}\neq 0 ∂w∂y=0,∂x∂y=0,∂b∂y=0
这就意味着只要 x ≠ 0 x \neq 0 x=0,一次梯度下降迭代将使w变成非零值。然后就得到: ∂ y ∂ x ≠ 0 \frac{\partial y}{\partial x}\neq 0 ∂x∂y=0。这样就能让zero convolution模块逐渐成为具有非零权重的卷积层,并不断优化参数权重。
理解了zero convolution模块的训练过程后,我们再对ControlNet整体训练过程进行拆解理解。在我们不使用ControlNet模型时,可以将Stable Diffusion/FLUX.1底模型的图像生成过程表达为: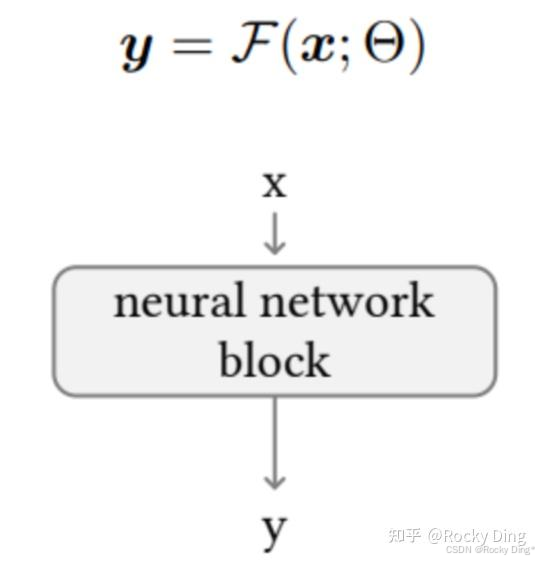
接着,我们在此基础上假设将训练的所有参数锁定在 Θ \Theta Θ中,然后将其复制为可训练的副本 Θ c \Theta_{c} Θc。复制的 Θ c \Theta_{c} Θc使用额外控制条件信息c进行训练。因此在使用ControlNet之后,Stable Diffusion/FLUX.1底模型 + ControlNet模型整体的图像生成表达式转化成为: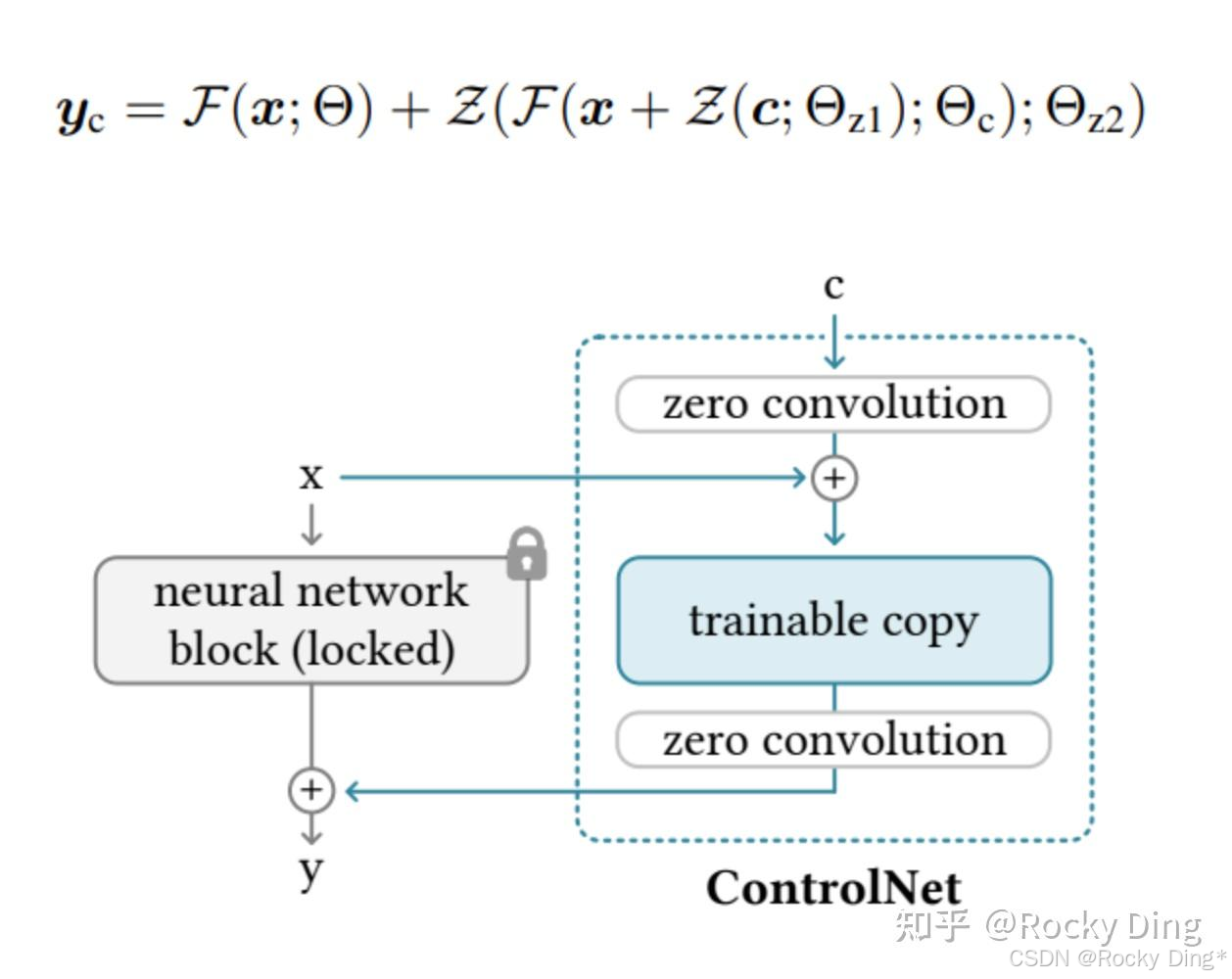
其中 Z = F ( c ; Θ ) Z = F(c; \Theta) Z=F(c;Θ)代表了zero convolution模块, Θ z 1 \Theta_{z1} Θz1和 Θ z 2 \Theta_{z2} Θz2代表了前后两个zero convolution层的参数权重, Θ c \Theta_{c} Θc则代表了ControlNet的参数权重。
由于训练开始前zero convolution模块的输出都为零,所以ControlNet未经训练时的初始输出为0:
{ Z ( c ; Θ z 1 ) = 0 F ( x + Z ( c ; Θ z 1 ) ; Θ c ) = F ( x ; Θ c ) = F ( x ; Θ ) Z ( F ( x + Z ( c ; Θ z 1 ) ; Θ c ) ; Θ z 2 ) = Z ( F ( x ; Θ c ) ; Θ z 2 ) = 0 \begin{cases} \mathcal{Z}\left(\boldsymbol{c};\Theta_{z1}\right) = 0 \\ \mathcal{F}\left(x + \mathcal{Z}\left(\boldsymbol{c};\Theta_{z1}\right);\Theta_{\mathrm{c}}\right) = \mathcal{F}\left(x;\Theta_{\mathrm{c}}\right) = \mathcal{F}(x;\Theta) \\ \mathcal{Z}\left(\mathcal{F}\left(x + \mathcal{Z}\left(\boldsymbol{c};\Theta_{z1}\right);\Theta_{\mathrm{c}}\right);\Theta_{z2}\right) = \mathcal{Z}\left(\mathcal{F}\left(x;\Theta_{\mathrm{c}}\right);\Theta_{z2}\right) = \mathbf{0} \end{cases} ⎩
⎨
⎧Z(c;Θz1)=0F(x+Z(c;Θz1);Θc)=F(x;Θc)=F(x;Θ)Z(F(x+Z(c;Θz1);Θc);Θz2)=Z(F(x;Θc);Θz2)=0
由此可知,在ControlNet微调训练初始阶段对Stable Diffusion/FLUX.1底模型权重是没有任何影响的,能让底模型原本的性能完整保存,之后ControlNet的训练也只是在原Stable Diffusion/FLUX.1底模型基础上进行优化。
总的来说,ControlNet的本质原理使得训练后的模型鲁棒性好,能够避免模型过拟合,并在特定条件场景下具有良好的泛化性,同时能够在小规模数据和消费级显卡上进行训练。
2.3 ControlNet核心网络结构解析(包含详细图解)
在上一章中,Rocky带大家学习了ControlNet核心基础原理与ControlNet最小单元,接下来Rocky将和大家详细讲解ControlNet的完整核心网络结构。
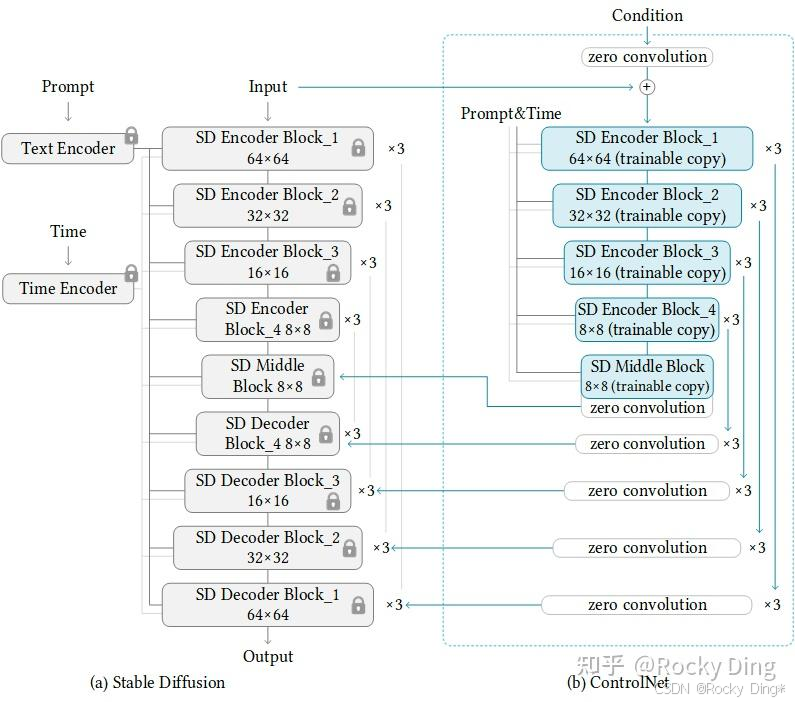
我们从ControlNet整体的模型结构上可以看出,其主要在Stable Diffusion的U-Net和FLUX.1的Transformer中起作用,ControlNet主要将Stable Diffusion U-Net的Encoder部分和Middle部分进行复制训练,并且在Stable Diffusion U-Net的Decoder模块中通过skip connection加入了zero convolution模块处理后的特征,将训练获得的能力注入到最终模型中。
下图是Rocky梳理的Stable Diffusion ControlNet的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习Stable Diffusion ControlNet,相信大家脑海中的思路也会更加清晰: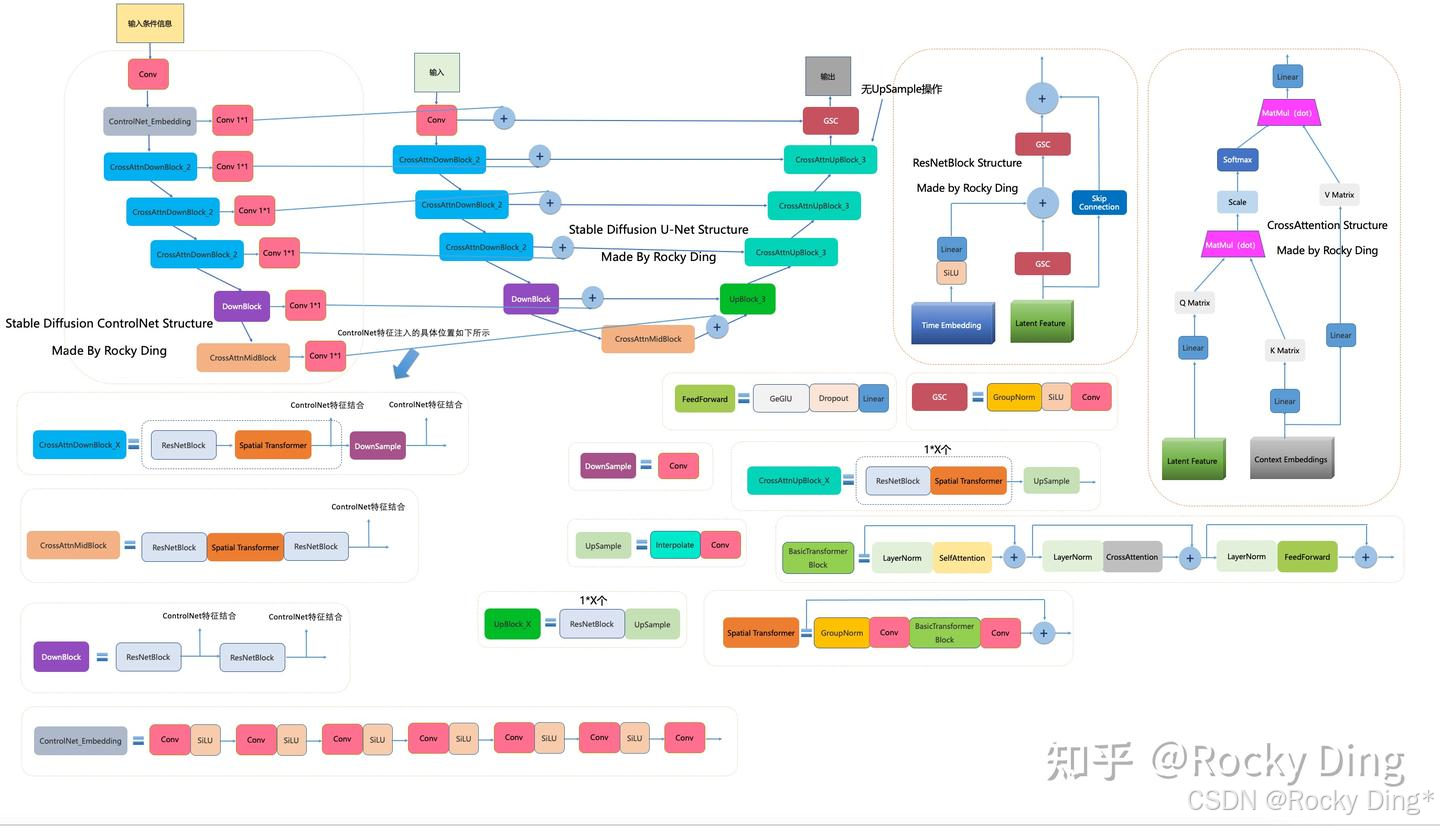
我们在之前的章节中已经知道ControlNet训练时Stable Diffusion U-Net模型权重是冻结,不需要进行梯度计算。这种设计思想减少了ControlNet在训练中一半的计算量,计算效率很高,能够加速训练过程并减少GPU显存的占用。在单个Nvidia A100 PCIE 40G的环境下,实际应用到Stable Diffusion模型的训练中,ControlNet仅使得每次迭代所需的GPU显存增加大约23%,时间增加34%左右。
具体地,ControlNet包含了Stable Diffusion U-Net的12个编码块和1个中间块的“可训练”副本。这12个编码块有4种分辨率,分别是64×64、32×32、16×16和8×8,每种分辨率对应3个编码块。ControlNet的输出被添加到Stable Diffusion U-Net的12个残差结构和1个中间块中。同时由于Stable Diffusion U-Net是经典的U-Net结构,因此ControlNet架构有很强的兼容性与迁移能力,可以用于其他扩散模型中。
ControlNet的输入包括Latent特征、Time Embedding、Text Embedding以及额外的Condition特征。其中前三个和SD的输入是一致的,而额外的Condition特征是ControlNet独有的输入。额外的Condition是和输入图片一样大小的图像,比如边缘检测图、深度信息图、人体骨骼图、轮廓图等。
大家可能会疑惑,ControlNet一开始的输入Condition怎么与SD模型的隐空间特征结合呢? 在这里ControlNet并没有像SD那样通过VAE将Condition进行特征编码,而是在训练过程中添加了一个四层卷积层的小网络,将图像空间Condition转化为隐空间Condition,并将Condition特征加在Latent特征经过第一个卷积后的输出上。这些卷积层的卷积核为4×4,步长为2,通道分别为16,32,64,128,初始化为高斯权重,并与整个ControlNet模型进行联合训练。
由于SD中经过VAE编码后的Latent特征的分辨率降低了8x,所以这个小的卷积网络同样需要将Condition特征下采样8x,并输出和Latent特征同维度的特征(对于SD 1.5,512x512的输入特征维度是64x64x320,SDXL、FLUX.1等同理,对应的SDXL ControlNet和FLUX.1 ControlNet都需要将Condition特征与主模型对齐)。这个小型网络的具体结构如下所示:
input_hint_block = TimestepEmbedSequential(
conv_nd(dims, hint_channels, 16, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 16, 16, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 16, 32, 3, padding=1, stride=2),
nn.SiLU(),
conv_nd(dims, 32, 32, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 32, 96, 3, padding=1, stride=2),
nn.SiLU(),
conv_nd(dims, 96, 96, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 96, 256, 3, padding=1, stride=2),
nn.SiLU(),
zero_module(conv_nd(dims, 256, model_channels, 3, padding=1))
)

ControlNet为什么没有使用VAE来编码Condition特征呢? Rocky认为主要还是因为Condition特征大部分是比较简单的图像比如深度信息图、人体骨骼图、轮廓图、边缘图等,采用一个小型卷积网络来提取特征是性价比比较高的事情,此外通过VAE编码本身也会造成一定的信息损失。
我们已经知道ControlNet是与SD系列模型的Encoder和Middle部分权重相结合训练的,那如何将整个训练成果映射到整个SD模型呢?
这里主要是借助SD中原本的skip connection设计,将U-Net的Encoder中的中间输出特征以跳跃连接的方式连接(concat操作)到Decoder部分中。ControlNet复制的U-Net的Encoder部分,可以提取出12个特征,只需要将这个12个特征加在原来U-Net的Encoder的12个特征输出上,然后以skip connection的方式就可以嵌入到U-Net的Decoder部分中。由于ControlNet还复制了Middle部分,这也意味着ControlNet共产生了13个skip connection操作。同时这13个skip connection特征输出上分别也加上了之前章节中提到的zero conv来避免初始噪声对模型性能造成的影响。
我们直接看具体的代码实现,便会一目了然:
class ControlledUnetModel(UNetModel):
def forward(self, x, timesteps=None, context=None, control=None, only_mid_control=False, **kwargs):
# 存储编码器各层的特征图(skip connections)
hs = []
# 使用torch.no_grad()确保在计算编码器部分时不计算梯度,节省内存
with torch.no_grad():
# 将时间步转换为嵌入向量
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
# 通过时间嵌入层处理时间嵌入
emb = self.time_embed(t_emb)
# 将输入转换为模型指定的数据类型
h = x.type(self.dtype)
# 前向传播通过编码器(输入块)
for module in self.input_blocks:
h = module(h, emb, context) # 每个模块接收当前特征、时间嵌入和上下文
hs.append(h) # 保存当前层的输出作为skip connection
# 通过中间块(bottleneck)
h = self.middle_block(h, emb, context)
# 注释说明:
# hs是Stable Diffusion UNet编码器产生的12个skip connection特征
# control是ControlNet产生的13个skip connection特征(包括中间层)
# 如果提供了ControlNet的控制信号
if control is not None:
# 将ControlNet中间层的控制信号加到UNet的中间层输出上
# control.pop()从control列表末尾弹出最后一个元素(LIFO栈行为)
h += control.pop() # 添加controlnet中间块的skip connection
# 前向传播通过解码器(输出块)
for i, module in enumerate(self.output_blocks):
# 判断是否只使用中间层控制或没有控制信号
if only_mid_control or control is None:
# 仅使用UNet编码器的skip connection,与当前特征拼接(核心关键部分)
h = torch.cat([h, hs.pop()], dim=1) # 沿通道维度拼接
else:
# 将ControlNet的skip connection加到UNet编码器对应的skip connection上
# 然后将合并后的特征与当前特征拼接(核心关键部分)
h = torch.cat([h, hs.pop() + control.pop()], dim=1)
# 通过当前输出块处理拼接后的特征
h = module(h, emb, context)
# 将输出转换回输入的数据类型
h = h.type(x.dtype)
# 通过输出层得到最终结果
return self.out(h)
总的来说,ControlNet的架构与思想,让其可以对图像的背景、结构、动作、表情等特征进行精准的控制。
2.4 ControlNet官方训练技巧&推理&细节Tricks解析
接下来我们再详细讲解一下ControlNet的官方训练过程和使用到的Tricks策略。在训练ControlNet模型的过程中,Stable Diffusion/FLUX.1底模型权重冻结不更新,只更新ControlNet模型权重。
【ControlNet训练的损失函数和策略】
ControlNet训练时的损失函数依旧采用经典SD系列扩散模型所用的拟合噪声的 L simple L^{\text{simple}} Lsimple,作为ControlNet的总体学习目标:
L simple = E z 0 , t , c t , c f , ϵ ∼ N ( 0 , I ) [ ∥ ϵ − ϵ θ ( z t , t , c t , c f ) ∥ 2 ] L^{\text{simple}}=\mathbb{E}_{\mathbf{z}_{0},t, \mathbf{c}_{t}, \mathbf{c}_{f}, \mathbf{\epsilon}\sim \mathcal{N}(\mathbf{0}, \mathbf{I})}\Big[ \| \mathbf{\epsilon}- \mathbf{\epsilon}_\theta\big(\mathbf{z}_{t},t, \mathbf{c}_{t}, \mathbf{c}_{f}\big)\|^2\Big] Lsimple=Ez0,t,ct,cf,ϵ∼N(0,I)[∥ϵ−ϵθ(zt,t,ct,cf)∥2]
其中给定图像 z 0 z_{0} z0,SD/FLUX.1+ControlNet的扩散过程逐渐向图像中添加噪声并产生噪声图像 z t z_{t} zt,t是添加噪声的时间步长。当t足够大时,图像近似于高斯纯噪声。同时给定一组包括时间步长t、文本prompts c t c_{t} ct以及额外的ControlNet控制条件 c f c_{f} cf,这意味着加上ControlNet的SD/FLUX.1其实变成了双条件扩散模型。SD/FLUX.1扩散过程中学习更新模型参数权重 ϵ θ \epsilon_{\theta} ϵθ,并用来预测添加到噪声图像 z t z_{t} zt中的噪声。
在训练过程中,官方还随机对文本prompts采用50%的drop(设置为空文本),之所以采用比较大的drop,论文中的阐述是想让ControlNet的能力得到充分学习,让SD/FLUX.1模型只依赖ControlNet的额外控制条件(Canny、Depth、SoftEdge、OpenPose等)就能生成符合结构的图像。因为当文本prompts对于SD/FLUX.1模型不可见时,ControlNet模型倾向于从额外控制条件输入中学习更多语义信息,以替代文本prompts。
【ControlNet模型的推理过程详解】
我们知道Stable Diffusion模型在推理阶段会采用classifier-free guidance(CFG)技术:
ϵ pred = ϵ uc + β cfg ( ϵ c − ϵ uc ) \mathbf{\epsilon}_{\text{pred}}=\mathbf{\epsilon}_{\text{uc}}+\beta_{\text{cfg}}(\mathbf{\epsilon}_{\text{c}}-\mathbf{\epsilon}_{\text{uc}}) ϵpred=ϵuc+βcfg(ϵc−ϵuc)
其中 ϵ uc \mathbf{\epsilon}_{\text{uc}} ϵuc和 ϵ c \mathbf{\epsilon}_{\text{c}} ϵc分别无条件扩散模型(文本设置为空)和有条件扩散模型预测的noise。在此基础上增加ControlNet之后,SD + ControlNet的组合就变成了双条件的扩散模型。
ControlNet在推理时采用的默认方式是将Condition特征加在 ϵ uc \mathbf{\epsilon}_{\text{uc}} ϵuc和 ϵ c \mathbf{\epsilon}_{\text{c}} ϵc上,即 ϵ uc = ϵ θ ( z t , t , ∅ , c f ) \mathbf{\epsilon}_{\text{uc}}=\mathbf{\epsilon}_\theta\big(\mathbf{z}_{t},t, \varnothing, \mathbf{c}_{f}\big) ϵuc=ϵθ(zt,t,∅,cf)和 ϵ c = ϵ θ ( z t , t , c t , c f ) \mathbf{\epsilon}_{\text{c}}=\mathbf{\epsilon}_\theta\big(\mathbf{z}_{t},t, \mathbf{c}_{t}, \mathbf{c}_{f}\big) ϵc=ϵθ(zt,t,ct,cf)。这种方式只对文本存在时有效,如果文本为空,那么CFG就失去了意义(无条件模型和有条件模型输出一样),相当于没有使用CFG(如下图中b所示)。一种解决办法是只将Condition加在 ϵ c \mathbf{\epsilon}_{\text{c}} ϵc上,此时 ϵ uc = ϵ θ ( z t , t , ∅ ) \mathbf{\epsilon}_{\text{uc}}=\mathbf{\epsilon}_\theta\big(\mathbf{z}_{t},t, \varnothing) ϵuc=ϵθ(zt,t,∅),但是实验发现这种实现方式会导致引导过强,出现图像的过饱和现象(如下图中c所示)。
为了解决这个问题,ControlNet论文中提出了CFG Resolution Weighting(Guess Mode)概念,就是对ControlNet的13个输出特征根据特征大小设置不同的权重(如下图d所示)。
怎么理解CFG Resolution Weighting呢?Rocky给大家进行通俗易懂的讲解,在没有无文本prompts输入的情况下,在只依靠ControlNet的条件特征来生成图像时,使用Guess Mode模式采用比较长的去噪步数(50步)和采用较低的CFG guidance scale(3~5之间)来进行图像的高质量生成:
model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13)
# Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01
从上面的代码中可以看到,Guess Mode模式对13个特征层权重都进行了调整。从最浅的特征到最深的特征,权重系数从<0.01逐渐增加至1,按照ControlNet论文的说法,这里的参数属于经验值。
【ControlNet模型的强迁移性】
同时,ControlNet模型还具备很强的迁移性,比如说一个ControlNet模型是在SD 1.5上训练的,同时它可以直接应用在基于SD 1.5微调的其他风格底模型上(写实、二次元、中国风、游戏、插画、2.5D、建筑、科幻等)。
比如在下面的例子中,在SD 1.5训练的ControlNet模型能够无缝应用到Comic Diffusion和Protogen 3.4底模型上:
ControlNet的可迁移性大大增加了它的易用性,一个足够好的ControlNet模型能够与开源社区中成千上百的基于SD、SDXL、SD 3、FLUX.1微调而来的底模型组合使用,这也是ControlNet快速在AIGC图像生成/AI绘画开源生态繁荣的一大关键原因。
此外,为了提升ControlNet迁移应用的效果,我们还可以进行权重转换,比如我们想让ControlNet模型在二次元场景的控制效果更好,可以通过下面的规则进行模型转换提炼:
二次元风格的ControlNet = 二次元SD模型 + SD 1.5 ControlNet模型 – SD 1.5模型
ControlNet具备迁移性也是很好理解的,因为ControlNet只是一个外接模型,并没有改变原始SD/FLUX.1模型的结构和权重,而其他经过微调的SD/FLUX.1模型的权重分布也没有偏离原始SD/FLUX.1很远。
同时,ControlNet和LoRA一样具备灵活训练的特点,官方也给出的ControlNet不同结构的训练经验。
比如当算力资源有限且希望加快训练速度、或者希望促进“全局”上下文学习时,可以设置成只训练中间控制模块部分的参数: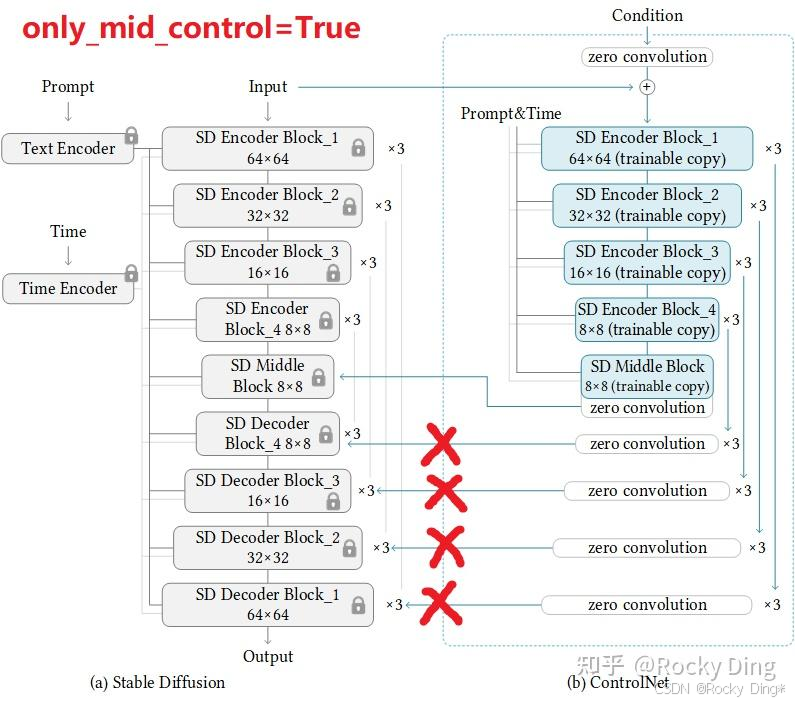
当然的,如果我们有充足的算力资源,我们可以解锁Stable Diffusion(SD)中的一些参数层,从而对ControlNet+Stable Diffusion进行整体训练。
3. 深入浅出完整解析 ControlNet 1.1核心基础知识
ControlNet 1.1与ControlNet 1.0具有完全相同的模型架构。ControlNet 1.1主要是在ControlNet 1.0的基础上进行了优化训练,提高了鲁棒性和控制效果,同时发布了几个新的ControlNet模型。
从ControlNet 1.1开始,ControlNet模型将使用标准的命名规则(SCNNR)来命名所有模型,这样我们在使用时也能更加方便与清晰。具体的命名规则如下图所示: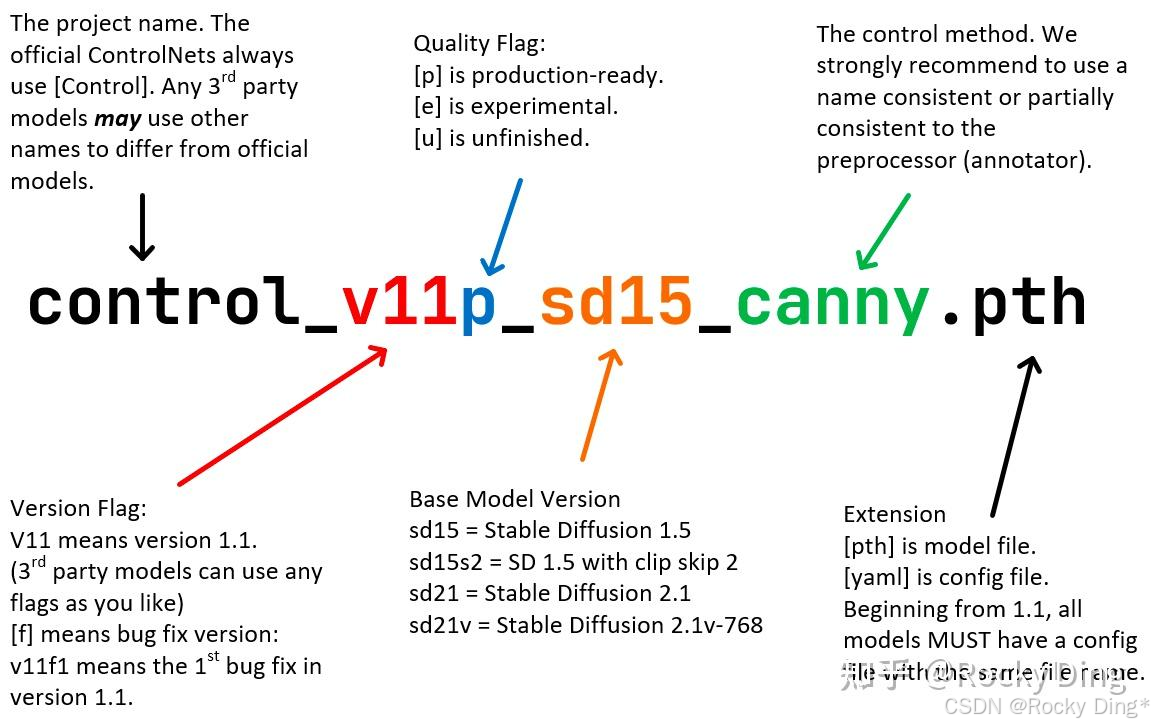
ControlNet 1.1一共发布了14个模型(11个成品模型和3个实验模型):
control_v11p_sd15_canny
control_v11p_sd15_mlsd
control_v11f1p_sd15_depth
control_v11p_sd15_normalbae
control_v11p_sd15_seg
control_v11p_sd15_inpaint
control_v11p_sd15_lineart
control_v11p_sd15s2_lineart_anime
control_v11p_sd15_openpose
control_v11p_sd15_scribble
control_v11p_sd15_softedge
control_v11e_sd15_shuffle(实验模型)
control_v11e_sd15_ip2p(实验模型)
control_v11f1e_sd15_tile(实验模型)
为了大家更好的理解和学习众多ControlNet模型,Rocky从宏观的处理控制条件类型角度入手,对各个不同的ControlNet归为如下清晰、逻辑化的几大类:
| 类别 | 核心功能 | 包含模型 |
|---|---|---|
| 边缘与线条类 | 通过提取图像中的线条、轮廓或边缘信息来控制图像的结构和形状。通常用于精确的形状控制和线稿上色。 | Canny, MLSD, Scribble, Soft Edge, Lineart |
| 几何与3D信息类 | 控制空间深度、立体感、表面朝向 | Depth, Normal |
| 语义与内容信息类 | 使用更高层次的、经过抽象和理解的信息来控制生成内容,例如人体姿态、物体分割区域等 | OpenPose, Segmentation |
| 风格与抽象信息类 | 不关注具体的形状或结构,控制整体风格、颜色、纹理 | Shuffle, Instruct Pix2Pix |
| 重绘类 | 特定的图像放大、细节增强、局部重绘 | Tile, Inpaint |
Rocky相信我们这个分类方式可以帮助更好地理解每个ControlNet模型的控制条件功能个应用场景。接下来,Rocky带着大家一起学习了解ControlNet 1.1系列模型各自的优化点。
3.1 ControlNet 1.1 Canny、MLSD、Scribble、Soft Edge、Lineart(边缘与线条类)的核心优化点详解
【ControlNet 1.1 Canny心优化点详解】
Canny模型是ControlNet系列中最重要(也是使用率最高)的模型之一,ControlNet 1.1 Canny对训练数据与进行了优化,使用随机阈值生成的Canny边缘图进行训练。这种方法能增加模型对不同对比度和细节丰富度图像的适应能力。
ControlNet Canny旧版本的训练数据集存在一些缺陷问题,在1.1新版模型中已彻底修复,使其生成效果更可靠:
- 解决重复图像问题: 原训练数据集中有一小批灰度人像图片被重复了数千次,这导致旧模型存在显著偏见,倾向于生成灰度人像。ControlNet 1.1 Canny全面清洗了训练数据,从根本上纠正了这一偏差。
- 优化图像质量问题: 移除了原数据集中存在的低质量、严重模糊和带有明显JPEG压缩伪影的图像,确保了训练数据的纯净度,有助于模型生成更清晰的结果。
- 解决图文错配问题: 修正了小部分图像与文字描述不匹配对齐的问题,提升了模型根据提示词生成内容的准确性。

同时1.1新模型的训练是在ControlNet 1.0 Canny权重基础上继续进行的,其在一个性能较好的基础模型上进行的二次优化。
【ControlNet 1.1 MLSD的核心优化点详解】
ControlNet 1.1 MLSD模型采用M-LSD(Mobile Line Segment Detection)算法检测出的直线段数据上进行训练。
关于训练数据优化部分,和之前提到的ControlNet 1.1 Canny一样,对重复数据问题、数据质量问题以及图文标签错配问题进行了全面的优化。同时官方还对数据规模进行了扩充,使用MLSD算法从海量图片中筛选出包含超过16条直线的图像,新增了30万张高质量样本。使得模型能够学习更丰富、更复杂的直线结构场景。
在训练过程中使用了随机左右翻转等数据增强技术,提升了模型对不同方向直线结构的识别与生成能力。
【ControlNet 1.1 Scribble的核心优化点详解】
ControlNet 1.1 Scribble采用合成涂鸦数据(Synthesized scribbles) 进行训练,支持多种涂鸦生成方法(如Scribble_HED、Scribble_PIDI等),同时兼容手绘涂鸦作为输入。
官方对粗线条涂鸦进行了专项优化: 在实际应用中常倾向于绘制较粗的涂鸦线条。为此,1.1新版在训练中采用了更积极的随机形态学变换来合成涂鸦数据。
ControlNet 1.1 Scribble模型具备以下特性:
- 训练数据覆盖最大24像素宽度的涂鸦(基于512画布),实际测试表明其对稍宽线条仍保持良好适应性。
- 同时支持最小1像素宽度的精细涂鸦输入。
- 显著提升了对不同粗细程度手绘涂鸦的解析能力。
同时在训练过程采用随机左右翻转等数据增强技术提升模型泛化能力,基于ControlNet 1.0 Scribble进行持续训练,确保性能平稳过渡。
ControlNet 1.1 Scribble在保持与ControlNet 1.0 Scribble兼容性的同时,显著提升了对手绘风格的适应性和生成结果的稳定性。我们可以使用ControlNet 1.1 Scribble更自由地绘制不同粗细的涂鸦轮廓,模型能够准确识别线条意图并生成细节丰富的图像。
【ControlNet 1.1 Soft Edge的核心优化点详解】
ControlNet 1.1 Soft Edge模型的前身为ControlNet 1.0 HED模型,在其基础上实现了显著改进。核心新增功能包括引入了SoftEdge_safe的新型软边缘预处理器。这是为了解决原有HED和PIDI方法中存在的潜在问题——它们往往在生成的边缘图中隐藏了一个受损的灰度版本的原图像,这种隐藏模式会干扰ControlNet的正常控制效果,导致生成效果不佳。解决方法是通过在预处理阶段将边缘图量化为几个层级,从而消除了这类隐藏噪声。
ControlNet 1.1 Soft Edge模型的各预处理器的表现归纳如下:
- 鲁棒性(稳定性): SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
- 最优生成质量(理想条件下的细节上限): SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
综合考虑鲁棒性与生成质量,官方推荐默认使用SoftEdge_PIDI,它在大多数情况下就能取得非常理想的生成效果了。
官方测试发现,ControlNet 1.1 Soft Edge在几乎所有情况下(接近100%)都显著优于之前的ControlNet 1.0 HED模型。性能提升的主要原因在于,通过采用75%的“safe”过滤机制,有效去除了控制图中隐藏的受损灰度图像信息。这使得模型不再过度拟合于还原这些隐藏噪声,而是真正专注于进行边界感知的图像生成,极大地提升了模型的鲁棒性。
经官方评估,ControlNet 1.1 Soft Edge模型已达到与ControlNet 1.1 Depth模型相近的实用程度,并具备更广泛的应用潜力。
【ControlNet 1.1 Lineart的核心优化点详解】
ControlNet 1.1 Lineart模型包含了ControlNet 1.1 Lineart和ControlNet 1.1 Anime Lineart两个版本,前者主要用于写实场景,而后者主要用于二次元场景。
ControlNet 1.1 Lineart模型专为高质量的线稿提取与生成而设计,能够将真实图像精准转换为不同风格的线条艺术图,或根据用户的手绘线稿生成细节丰富的图像。ControlNet 1.1 Lineart模型基于精选的awacke1/Image-to-Line-Drawings数据集进行训练。该数据集包含了大量高质量的图像-线稿配对样本,为模型学习复杂的边缘和轮廓特征奠定了坚实基础。
ControlNet 1.1 Lineart模型支持两种主流的线稿生成预处理器模式,并具备高度的输入灵活性:
- Lineart: 生成精细、细节丰富的线稿,适合保留原图像中的微妙结构和纹理。
- Lineart_Coarse: 生成更粗略、概括性的线稿,强调主体轮廓,忽略部分细节。
- 输入兼容性: 除了使用预处理器自动从图像生成线稿外,模型同样能够出色地处理用户手动绘制的线稿,为艺术创作提供了极大的自由度。
ControlNet 1.1 Lineart在训练过程中进行了充分的数据增强,显著提升了模型对不同画风、线条粗细和输入变化的鲁棒性与泛化能力。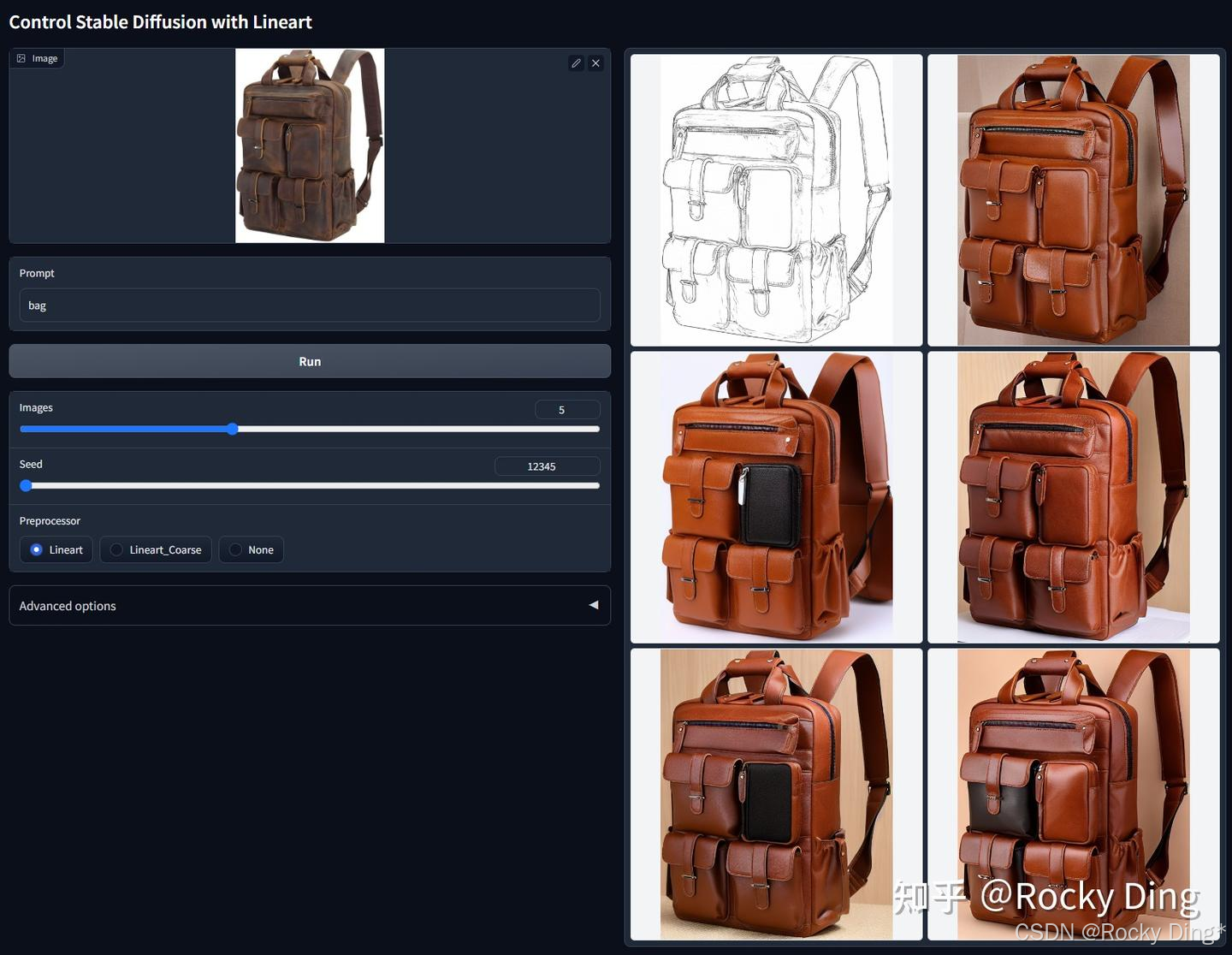
接下来,Rocky再为大家讲解ControlNet 1.1 Anime Lineart的核心基础知识。
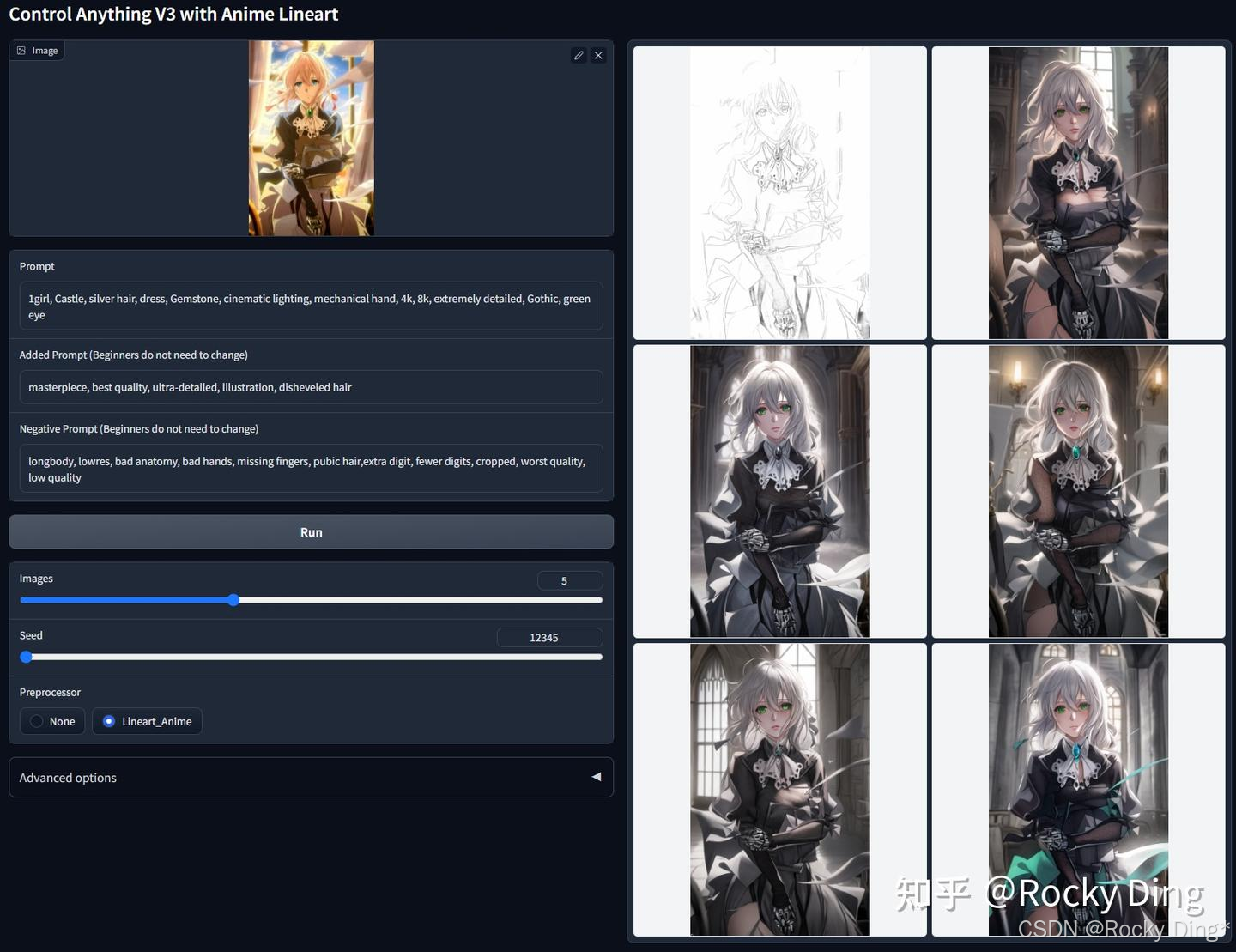
ControlNet 1.1 Anime Lineart模型专为动漫风格图像生成而设计,能够接受真实的手绘动漫线稿或从图像中提取的线稿作为输入,并生成高质量的对应图像。
ControlNet 1.1 Anime Lineart模型特点:
- 长提示词优化: 模型训练时使用了3倍于常规长度的提示词并采用Clip Skip 2技术。因此,除非使用LoRA,否则使用详细的长提示词通常会获得更佳效果。
- 不支持Guess Mode。
3.2 ControlNet 1.1 Depth、Normal(几何与3D信息类)的核心优化点详解
【ControlNet 1.1 Depth核心优化点详解】
ControlNet 1.1 Depth采用了Midas深度图(分辨率256/384/512)+ Leres深度图(分辨率256/384/512)+ Zoe深度图(分辨率256/384/512)的混合数据集进行训练,使用多个不同分辨率的深度图还能起到数据增强的作用。
ControlNet 1.1 Depth模型在推理阶段可接受的预处理条件同样也是Depth_Midas、Depth_Leres、Depth_Zoe三种。整体上ControlNet 1.1 Depth模型具备高度的鲁棒性,能够处理来自渲染引擎的真实深度图。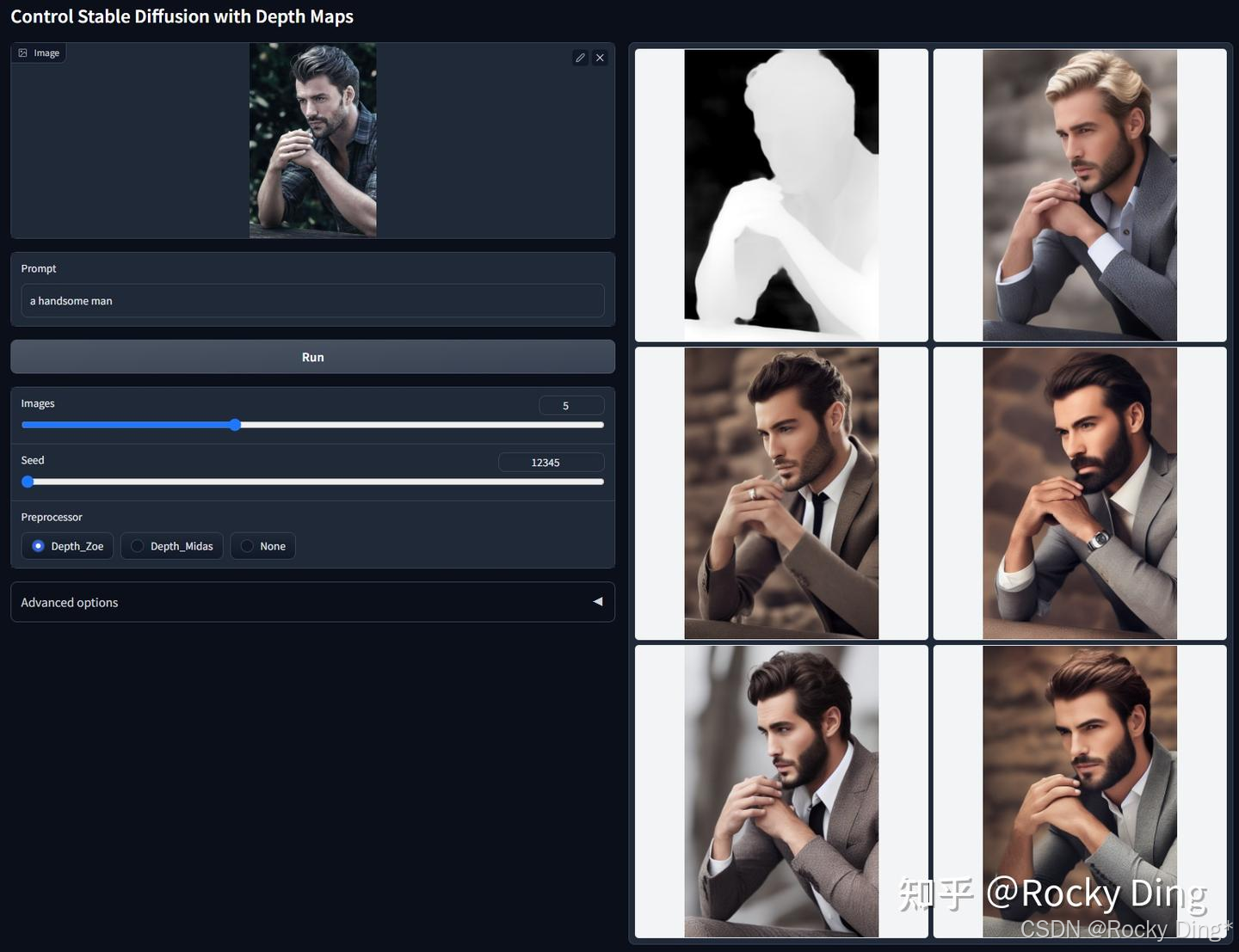
ControlNet Depth 1.1的优化点主要包含以下几个部分:
- 对之前ControlNet 1.0版本训练数据中的缺陷进行修复,和之前提到的ControlNet 1.1 Canny一样,对重复数据问题、数据质量问题以及图文标签错配问题进行了全面的优化。
- ControlNet 1.1 Depth是一个相对“无偏见”的更通用、更强大的模型。不依赖于特定深度估计算法:ControlNet 1.0版本的旧模型有时会过拟合于某一种深度图生成算法(例如Midas)。而ControlNet 1.1 Depth在训练时并未局限于某一种深度估计方法或某种特定风格的深度图。兼容多种预处理器和分辨率: ControlNet 1.1 Depth模型能够更好地适配不同的深度估计算法(如Midas, LeReS, ZoE)和不同的预处理分辨率(如384p, 512p),甚至能很好地处理由3D引擎生成的真实深度图。这意味着我们在使用时有了更大的灵活性。
- 训练过程的优化包括数据增强策略:在训练中应用了随机左右翻转等合理的数据增强技术。这相当于让模型从更多角度学习同一物体的深度结构,有效提升了模型的鲁棒性和泛化能力。模型迭代基础: ControlNet 1.1 Depth是在ControlNet 1.0 Depth的权重基础上继续训练(resume training) 的。这意味着它完全保留了1.0版本的所有优点。在ControlNet 1.0 Depth表现良好的所有场景下,1.1版本能够表现同样出色甚至更好。
【ControlNet 1.1 Normal的核心优化点详解】
ControlNet 1.1 Normal的训练数据来源主要是采用Bae’snormalmap estimation法线贴图估计算法(比ControlNet 1.0中基于Midas深度图推导法线的方法(”normal-from-midas”)更为合理)生成的数据。
只要法线贴图遵循ScanNet的色彩协议,即颜色效果如下图的第二列所示,本模型不仅可以处理由Normal BAE预处理器生成的图像,也能正确解析3D渲染引擎直接输出的真实法线贴图。
比起ControlNet 1.0版本中使用的“normal-from-midas”方法,ControlNet 1.1 Normal版本有了显著改进,主要有以下原因:
- 所使用的预处理器本身是依据相对正确的协议(NYU-V2可视化方法)进行训练,旨在估算出符合规范的法线贴图。
- 只要法线贴图的色彩编码正确(蓝色代表正面/Z轴,红色代表左侧/X轴,绿色代表顶部/Y轴),ControlNet Normal 1.1模型就能够有效解读来自渲染引擎的真实法线贴图。
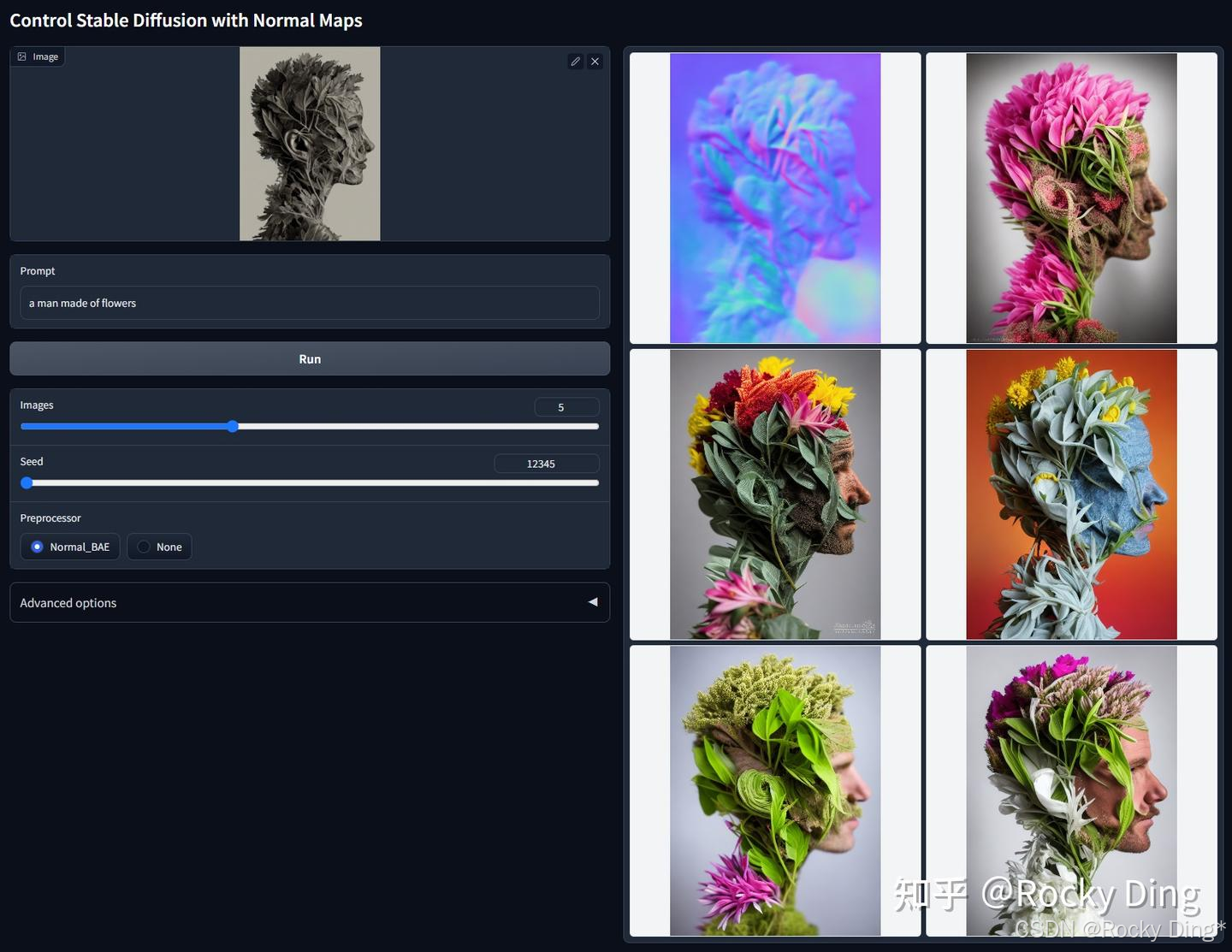
根据官方的测试结果,ControlNet 1.1 Normal模型鲁棒性良好,其表现可与ControlNet Depth 1.1模型相媲美。
3.3 ControlNet 1.1 OpenPose、Segmentation(语义与内容信息类)的核心优化点详解
【ControlNet 1.1 OpenPose核心优化点详解】
ControlNet 1.1 Openpose版本可以说是一个重要的升级,其改进主要体现在预处理器的准确性和训练数据集的质量两个方面。
- 更精准的预处理器: 1.1新版改进了人体关键点检测的实现方式,这使得姿态识别,尤其是对手部关键点的检测更加准确。
- 更纯净的训练数据: 1.1新版模型修复了之前训练数据集中存在的几个关键问题,和之前提到的ControlNet 1.1 Canny一样,对重复数据问题、数据质量问题以及图文标签错配问题进行了全面的优化。
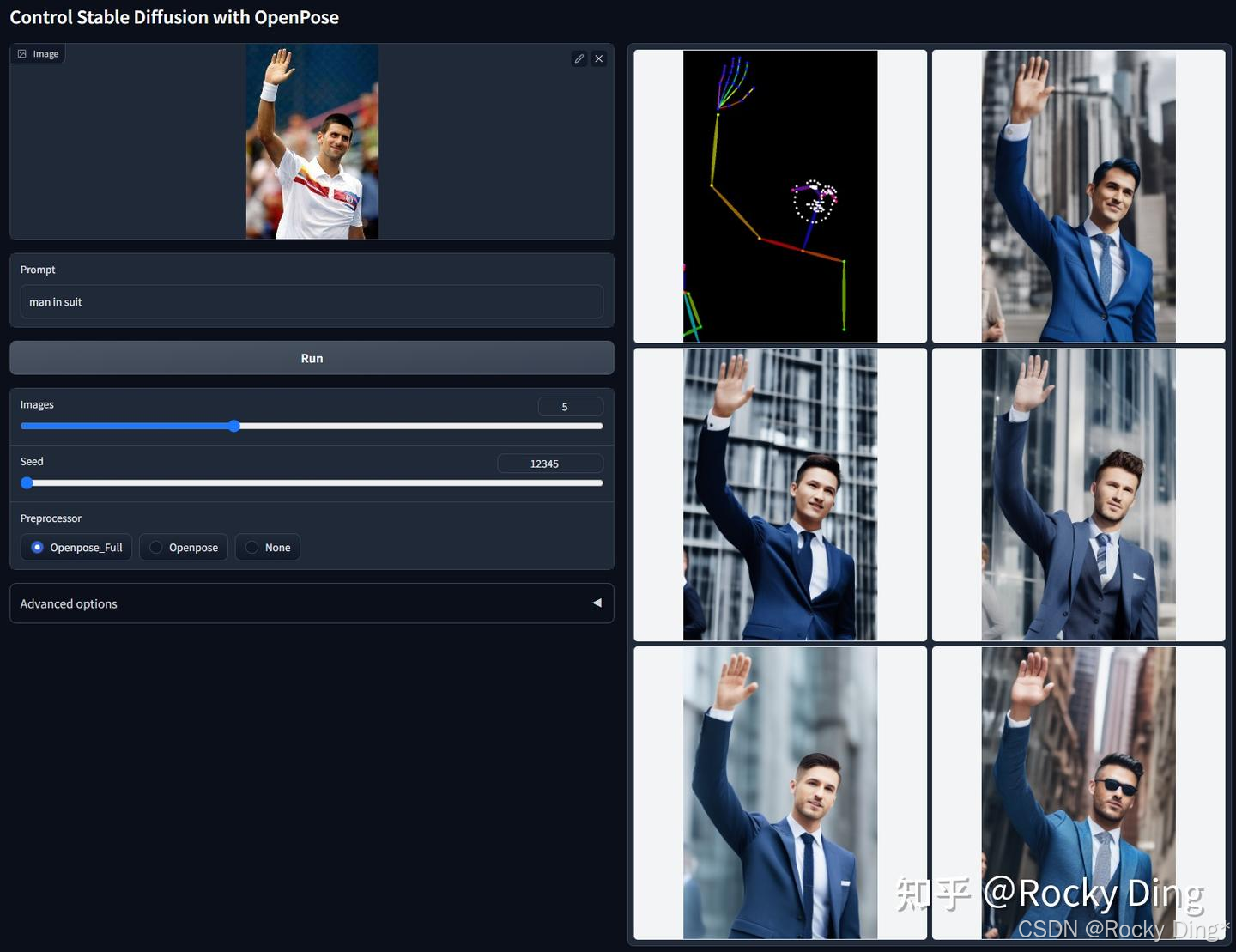
官方给出了较多的预处理器,为了更直观地理解不同预处理器的区别,Rocky在下表中对它们进行了归纳总结:
| 预处理器名称 | 检测内容 | 特点与适用场景 |
|---|---|---|
| openpose | 身体姿态 | 基础选项,仅检测和控制身体姿态 |
| openpose_full (推荐) | Openpose body + Openpose hand + Openpose face=身体+手部+面部 | 控制全面,准确性高,适合需要精细控制的表情和手势 |
| dw_openpose_full | 身体+手部+面部 | 识别准确性通常比openpose_full更高 |
| openpose_faceonly | 仅面部 | 专注于面部表情,不干预身体姿态 |
【ControlNet 1.1 Segmentation核心优化点详解】
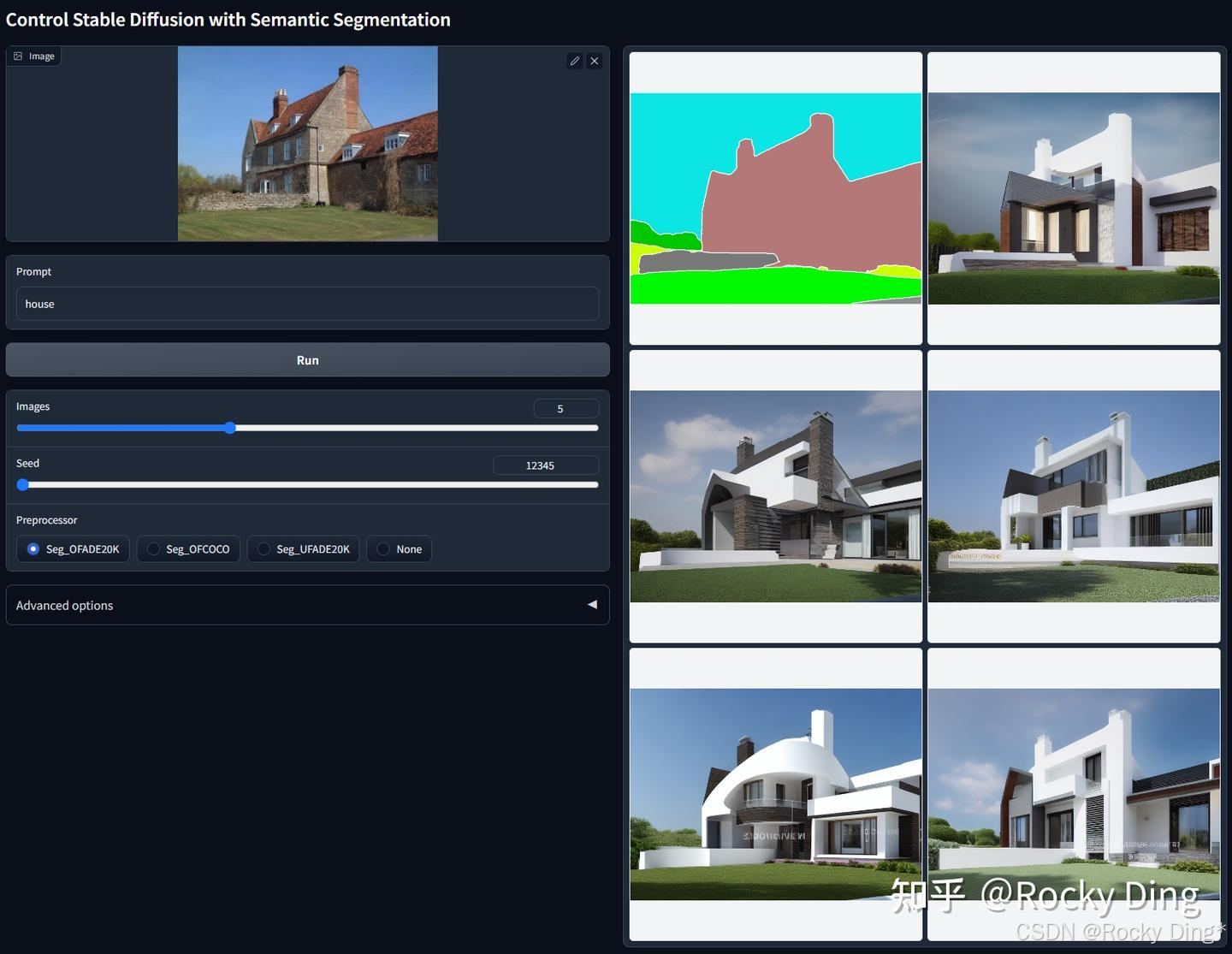
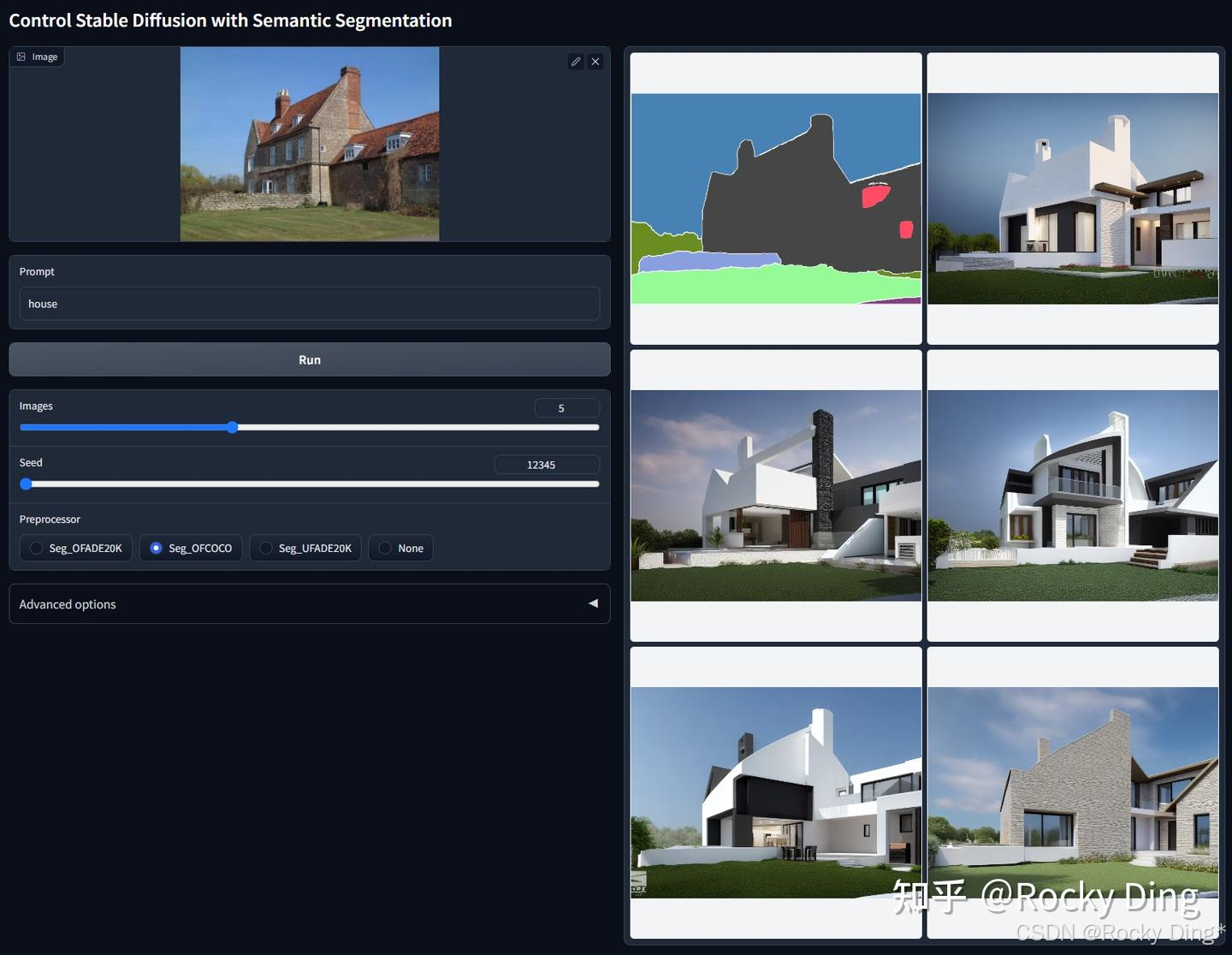
ControlNet 1.1 Segmentation在融合COCO与ADE20K的数据集进行训练。可用预处理器包括Seg_OFADE20K(基于Oneformer的ADE20K分割)、Seg_OFCOCO(基于Oneformer的COCO分割)、Seg_UFADE20K(基于Uniformer的ADE20K分割)以及用户手动创建的语义分割掩码。
ControlNet 1.1 Segmentation的核心改进点:
- 支持多协议分割输入: 模型现可同时识别ADE20K与COCO两种标注体系的语义分割图。让ControlNet编码器学习多种分割协议不仅易于实现,还能有效提升模型的泛化能力和整体表现。
- 扩展色彩标签库: 相比仅支持约150种颜色的Segmen-tation 1.0,Segmentation 1.1新增了来自COCO数据集的182种颜色标签,显著增强了模型对复杂场景的解析能力。
- 保持旧版本兼容: 模型基于ControlNet 1.0 Segmentation权重继续训练,完全兼容所有旧版输入,用户无需担心现有工作流程受到影响。
3.4 ControlNet 1.1 Shuffle、Instruct Pix2Pix(风格与抽象信息类)的核心优化点详解
【ControlNet 1.1 Shuffle核心优化点详解】
ControlNet 1.1 Shuffle模型是1.1版本新发布的控制生成模型,旨在实现对图像风格化迁移。其核心原理是:首先通过随机生成的流场(Random Flow)对输入图像进行打乱,然后作为Condition引导Stable Diffusion模型将打乱的图像重组回合理的画面。
在训练阶段这个ControlNet模型训练的目的其实根据打乱的图像来生成原来的图像。这个ControlNet模型在实现上会对ControlNet的特征输出做一个global average pooling。此外,在做CFG时,ControlNet只加在有条件的那一边。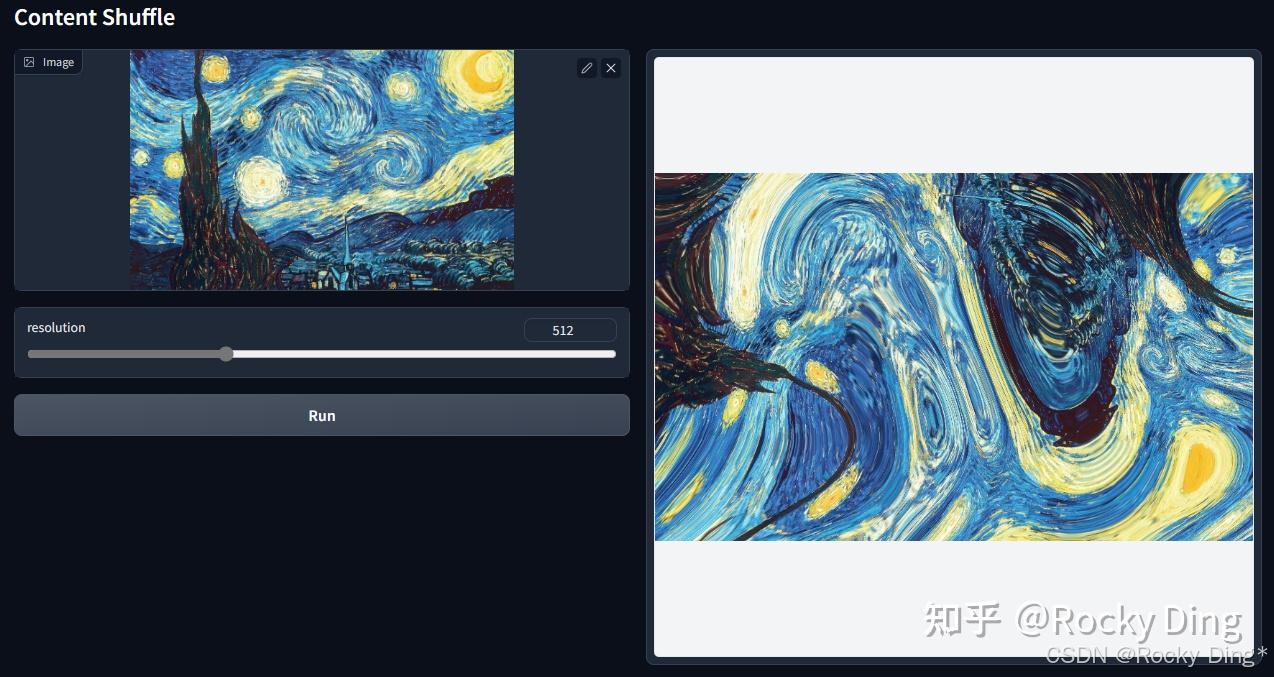
如下图右侧六宫格图示,左上角为经过打乱的输入图像,其余图像均为模型的生成结果。模型通过学习“打乱-重组”这一过程,掌握了图像内容的结构化重组能力。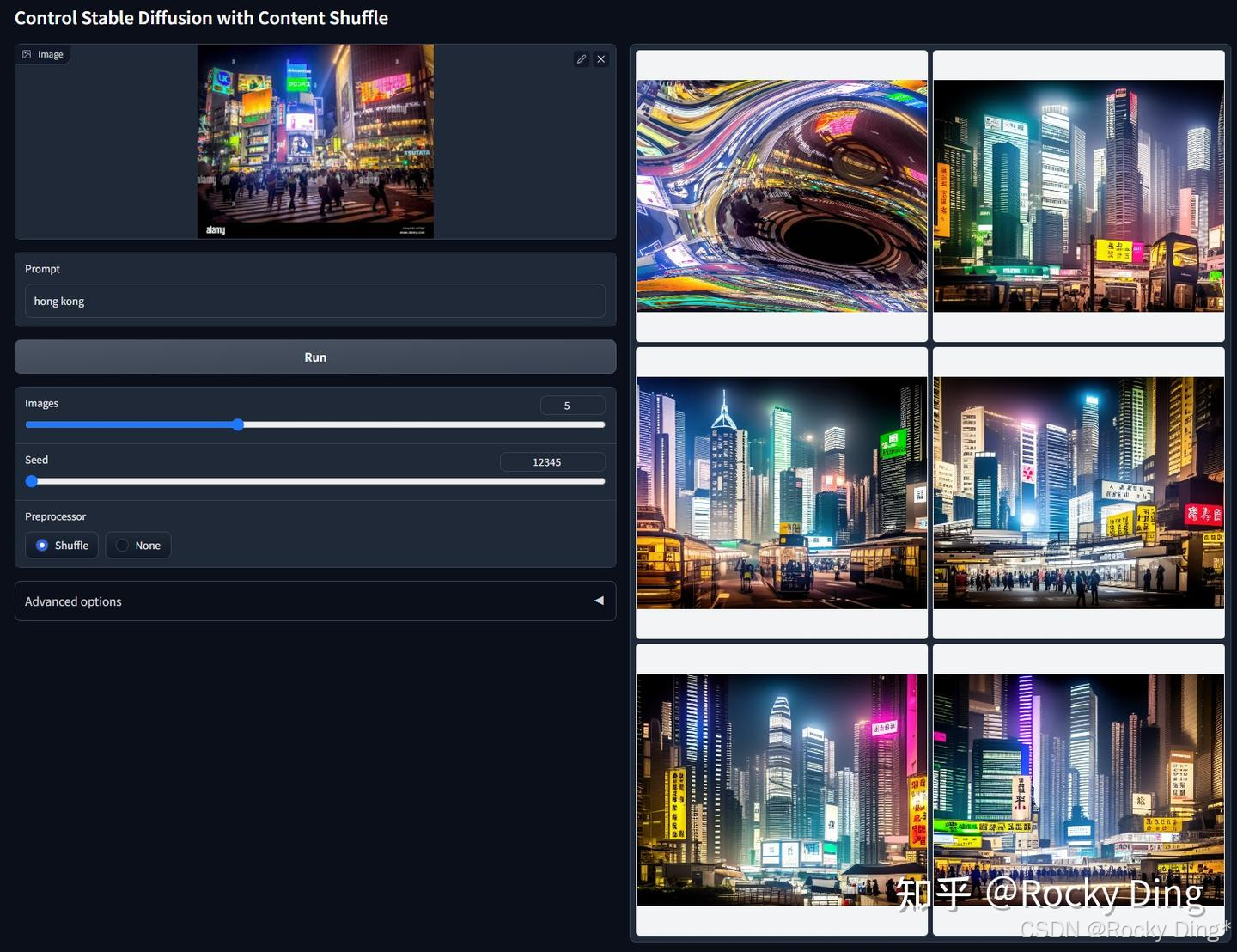
由于模型本质上是学习如何将视觉元素合理重组,因此我们甚至可以不进行图像打乱,而直接将原始图像作为输入。在这种模式下,ControlNet 1.1 Shuffle可以配合提示词或其他ControlNet共同作用,从而实现图像风格的转换。值得注意的是,ControlNet 1.1 Shuffle是一个纯粹的、基于图像控制的ControlNet。
【ControlNet 1.1 Instruct Pix2Pix的核心优化点详解】
这是一个基于Instruct Pix2Pix数据集训练的ControlNet模型。与官方Instruct Pix2Pix实现不同,ControlNet 1.1 Instruct Pix2Pix模型在训练时使用了50%的描述型提示词和50%的指令型提示词。例如,“一个可爱的男孩”属于描述型提示词,而“把男孩变可爱”则属于指令型提示词。
ControlNet 1.1 Instruct Pix2Pix模型的核心改进:
- 无需复杂调参: 由于采用ControlNet架构,我们无需像使用原版Instruct Pix2Pix那样进行复杂的双重CFG调节。这大大简化了使用流程,降低了操作门槛。
- 广泛的模型兼容性: 可以灵活应用于任何基础SD、SDXL、FLUX模型之上,为我们提供更大的创作自由度。
- 优化的指令格式: 根据官方的测试观察,使用“将其变为X”类型的指令(如“变为水彩画风格”)比“将Y变为X”类型的指令效果更佳。建议在实际使用中优先采用这种指令结构。在编写指令时,推荐使用简洁的直接指令格式,例如“变为油画风格”或“调整成夜晚效果”。可以结合描述型提示词与指令型提示词共同使用,以获得更精确的控制效果。
该模型在保留Instruct Pix2Pix图像编辑能力的基础上,通过ControlNet架构解决了原版方法的调参复杂性問題,同时提升了指令理解的灵活性,为用户提供了一种更便捷、更高效的图像编辑解决方案。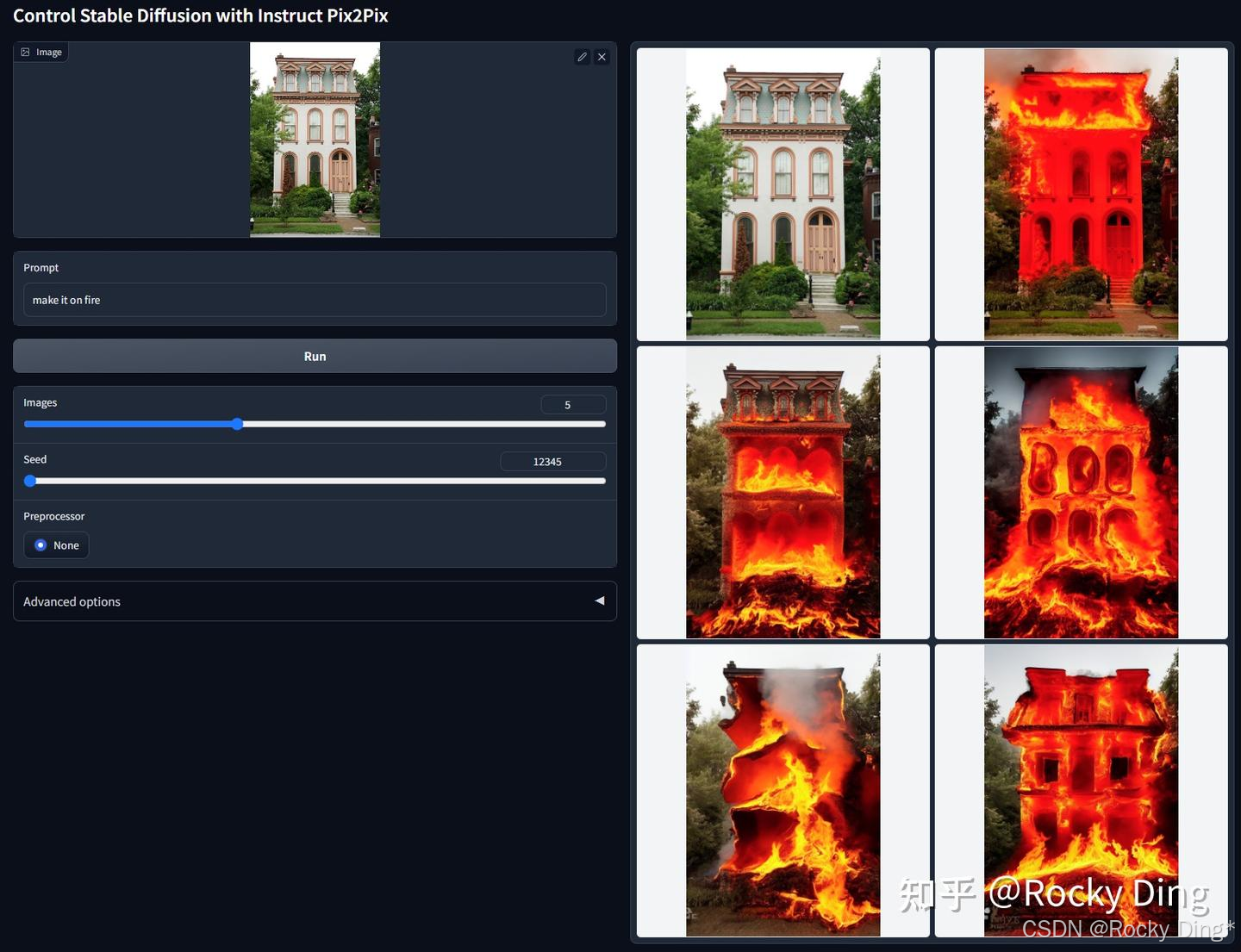
3.5 ControlNet 1.1 Inpaint、Tile(重绘类)的核心优化点详解
【ControlNet 1.1 Inpaint核心优化点详解】
ControlNet 1.1 Inpainti模型采用混合训练策略,训练数据中包含50%的随机掩码以及50%的基于光流估计生成的遮挡掩码。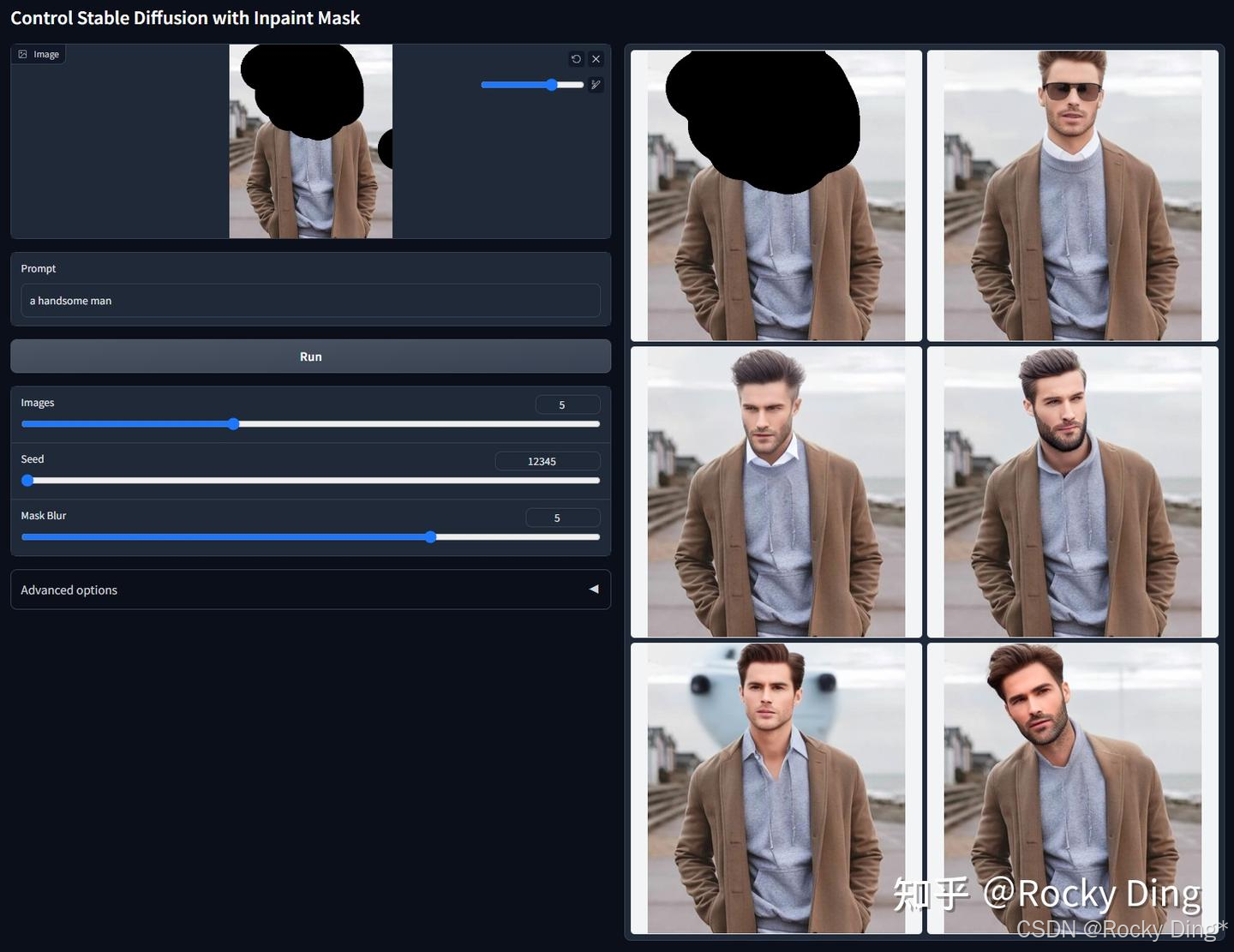
Stable Diffusion和FLUX.1系列模型本身具备inpaint的能力,再结合专门的inpaint控制模型,其整体效果将大幅提升。
【ControlNet 1.1 Tile的核心优化点详解】
ControlNet 1.1 Tile模型的核心价值在于它能智能地处理图像细节,尤其在进行高分率放大或局部修复时,能有效避免传统超分存在的常见问题。下面Rocky总结了它的核心机制与独特优势,方便大家快速了解学习:
| 核心特点 | 说明 | 带来的优势 |
|---|---|---|
| 在原图细节基础上,生成新细节 | 不单纯放大像素,而是基于理解重新生成更合理的细节。 | 有效修复因放大导致的模糊、伪影,实现质量提升而不仅是尺寸增大。 |
| 智能忽略不匹配的全局提示词 | 当局部内容(如一块树叶)与全局提示词(如“一个英俊的男人”)不符时,会减弱全局提示词影响,优先根据局部语义生成内容。 | 解决大图分块绘制时的内容重复问题(如生成16个女孩),确保画面逻辑合理、协调统一。 |
| 与传统图生图 (I2I) 的对比 | 即使在高重绘强度(如denoising_strength=1.0)下,也能更好地保持图像的整体结构和构图,不易产生不可控的扭曲或变异。 | 让细节重构过程更稳定、更可控,降低了使用门槛。 |
基于上述特点,ControlNet 1.1 Tile模型特别适用于以下场景:
- 图像高清放大与修复: 这是最经典的应用。它可以为低分辨率或模糊的图片添加精细的新细节,而不是简单地锐化,从而获得真正的高清图像。
- 超大分辨率图像生成: 通过与Tiled Diffusion或Ultimate SD Upscale等技术配合,可以将图像分割成多个小块分别渲染,再拼接成完整的4K甚至8K大图。Tile模型在此过程中的关键作用就是确保每个区块内容与周围环境协调,不会因全局提示词而产生重复主体。
- 无损细节替换: 如果我们希望保留一张图片的构图和色彩,但对其纹理、质感等细节不满意,可以使用Tile模型进行重绘,它能在保持整体的前提下替换掉粗糙或不良的细节。
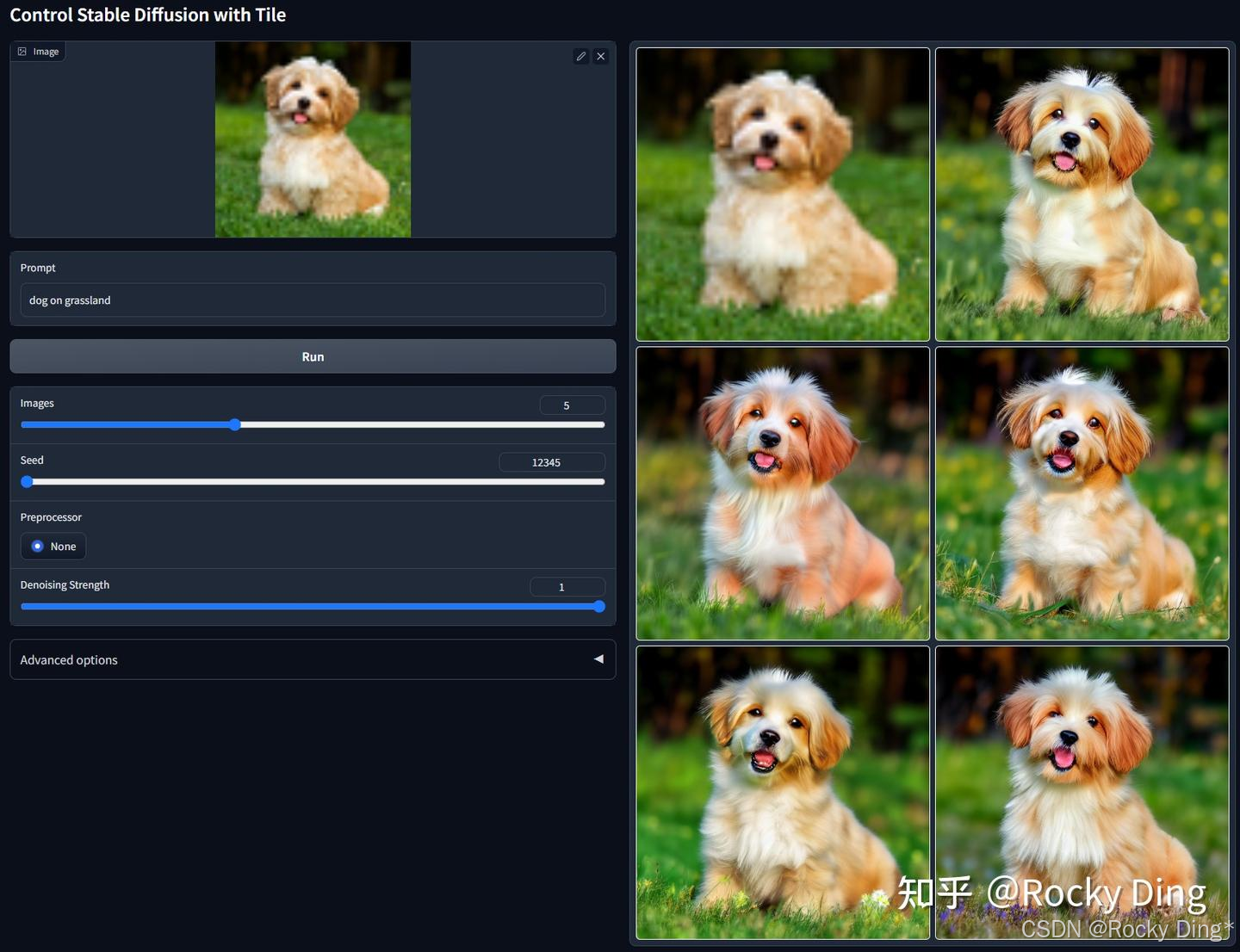
在进行分块放大时,由于Tile模型会智能处理局部语义,全局提示词可以更侧重于描述整体氛围(如“杰作,最佳质量,细节丰富”),而无需过度描述可能出现在每个区块的细节。
4. 深入浅出完整解析SDXL ControlNet核心基础知识
在Stable Diffusion XL(SDXL)问世后,ControlNet官方并未发布任何版本的SDXL ControlNet模型 , 不过开源社区的研发者们非常积极和热情,积极的训练开源SDXL ControlNet模型, 弥补了SDXL没有ControlNet模型可用的窘境,极大的繁荣了SDXL的完整开源生态。
这些开源的 SDXL ControlNet模型和ControlNet 1.1一样,包含了Canny、Depth、Normal、OpenPose、Tile、Scribble、Soft Edge、Segmentation、Lineart、Shuffle、Instruct Pix2Pix、Inpaint、MLSD等控制功能。
并且在此基础上, 第一次出现了集多种ControlNet控制功能于一身的SDXL Controlnet Union模型,其简洁高效的控制生成方式,为原生图像生成和图像编辑统一大模型的发展趋势隐隐埋下伏笔,后续的FLUX.2、FLUX.1 Kontext、Nano Banana Pro、Seedreamn、GPT-4o中都有其思想的体现。
Rocky认为以ControlNet为代表的可控生成技术在发展到Stable Diffusion XL的阶段时,可以总结以下的一些洞见,大家可以作为跨周期的AIGC技术经验:
- 当AIGC核心大模型从Stable Diffusion向Stable Diffusion XL升级时,以ControlNet为代表的可控生成技术也要同步进行升级迭代。
- 在ControlNet升级迭代过程中,十几种模型的成本是非常高的,这也是为什么ControlNet官方没有跟进的原因。
- 这时开源生态和开源社区的支持就显得尤为重要了,SDXL ControlNet就是开源社区一起支持迭代更新的。
- 一个ControlNet模型只能控制一种条件在AIGC时代是不够优雅的, 一个ControlNet能够支持多种条件的控制,是大势所趋 ,因此才会有SDXL Controlnet Union模型的发布。这也为后来FLUX.2、FLUX.1 Kontext、Nano Banana Pro、即梦、GPT-4o等原生图像生成和图像编辑大模型提供了灵感与铺垫。
下图是Nano Banana Pro的图像控制生成效果,可以说非常惊艳:
4.1 SDXL ControlNet系列模型汇总&性能特点详解
由于SDXL ControlNet是由开源社区的研发者们一起共建的,所以出现了各式各样的版本与模型,Rocky在这里对这些模型进行汇总,大家可以按需取用。
目前主流的开源SDXL ControlNet模型有如下:
- Lvmin’s collection :其中包含了diffusers ControlNet、Controllllite、Stability AI Control LoRA以及T2I Adapter等模型。
- Qinglong’s Controllllite SDXL models :其中包含了Normal Dsine(NEW)、Tile realistic、Tile anime、MLSD、DW pose、Normal、Recolor Luminance、Softedge、Segment animeface等模型。
- Kataragi’s SDXL models:其中包含了 Inpaint、 Recolor、 Lineart、 Line2Color 等模型。
- Xinsir’s SDXL models:其中包含了 Canny、 Openpose、 Scribble、 Scribble-Anime 等模型。
由于SDXL ControlNet种类丰富,既有ControlNet经典形式的,也有基于LoRA形式的,还有不同的量化版本(模型大小在50MB、400MB、 800MB、2500MB等), 因此我们可以根据实际应用场景的需求,选择性能、速度、效果、资源占用最匹配的模型进行使用 。
4.2 SDXL ControlNet Union(ControlNet++)模型原理详解(包含详细图解)
在本章节中,Rocky将带着大家详细讲解SDXL Controlnet Union的核心基础知识。
首先,我们来看一下SDXL ControlNet Union(controlnet-union-sdxl-1.0)的模型结构: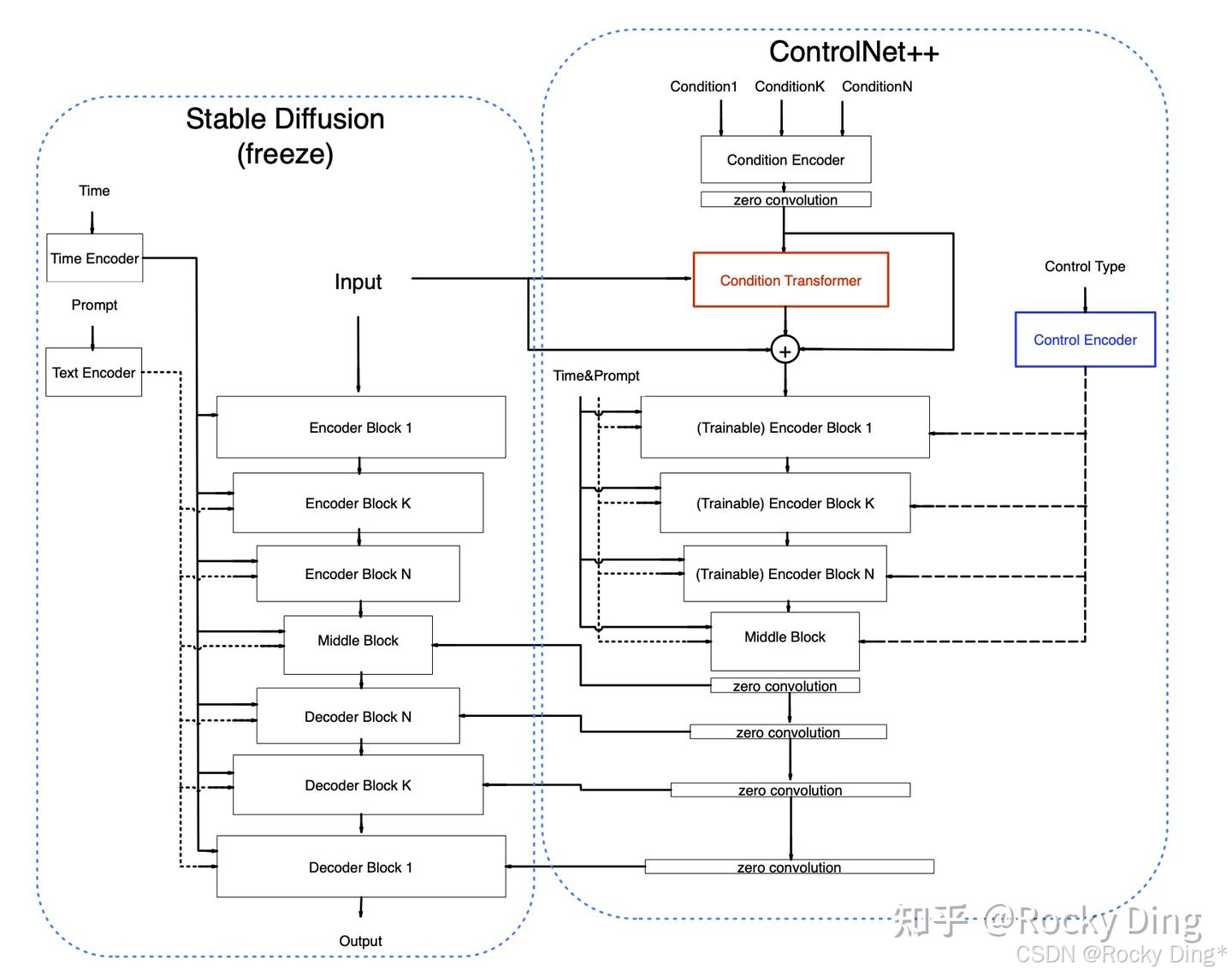
我们可以看到,SDXL ControlNet Union模型基于原始ControlNet架构,同时提出了 Control Encoder(控制编码器) 和 Condition Transformer(条件变换器) 两个新模块。
在控制编码器中, 每个控制条件都被赋予一个特定的 控制类型标识符 。例如,OpenPose 对应标识符 (1, 0, 0, 0, 0, 0),深度图对应 (0, 1, 0, 0, 0, 0)。 当存在多个条件时,例如同时使用 OpenPose 和深度图,其标识符将合并为 (1, 1, 0, 0, 0, 0) 。在控制编码器中,这些标识符通过正弦位置编码转换为Embedding嵌入向量,随后通过线性层将其投影至与Time Embedding时间嵌入相同的维度。 控制类型特征会与时间嵌入相加(add),从而在网络中传递不同控制类型的全局信息 。这一简洁设计有助于SDXL ControlNet Union区分各类控制条件, 因为时间嵌入通常对整体模型具有广泛影响 。无论是单一条件还是多条件组合,均对应唯一的控制类型标识符。总的来说, 不同条件共享同一条件控制编码器,从而使网络结构更为简洁与轻量。
实际的控制类型标识符如下所示:
0 -- openpose
1 -- depth
2 -- thick line(scribble/hed/softedge/ted-512)
3 -- thin line(canny/mlsd/lineart/animelineart/ted-1280)
4 -- normal
5 -- segment
在条件变换器中, 对原生SDXL ControlNet进行了扩展,使其能够同时处理多个控制条件的输入。条件变换器的作用在于整合不同图像条件的特征。
同时针对多条件的同时控制,对ControlNet的条件编码器(Condition Transformer)也做了改进。 ControlNet原有的条件编码器由多个卷积层与Silu激活函数堆叠而成。 在保持其架构不变的基础上,SDXL ControlNet Union增加了卷积通道数,构建了一个更“宽”的编码器,这一改进显著提升了网络的表现能力 。原因在于,所有图像条件共享同一编码器,因此需要编码器具备更强的特征表示能力。原有结构对于单一条件可能足够,但在处理十余种条件时则显得力不从心。同时并未直接采用Transformer的输出,而是利用其预测原始条件特征的残差值, 这种设计类似于 ResNet的残差思想,实验表明该结构能显著提升模型性能 。
下图是Rocky梳理的Stable Diffusion XL ControlNet Union的完整结构图 ,大家可以感受一下其魅力,看着这个完整结构图学习Stable Diffusion XL ControlNet Union,相信大家脑海中的思路也会更加清晰: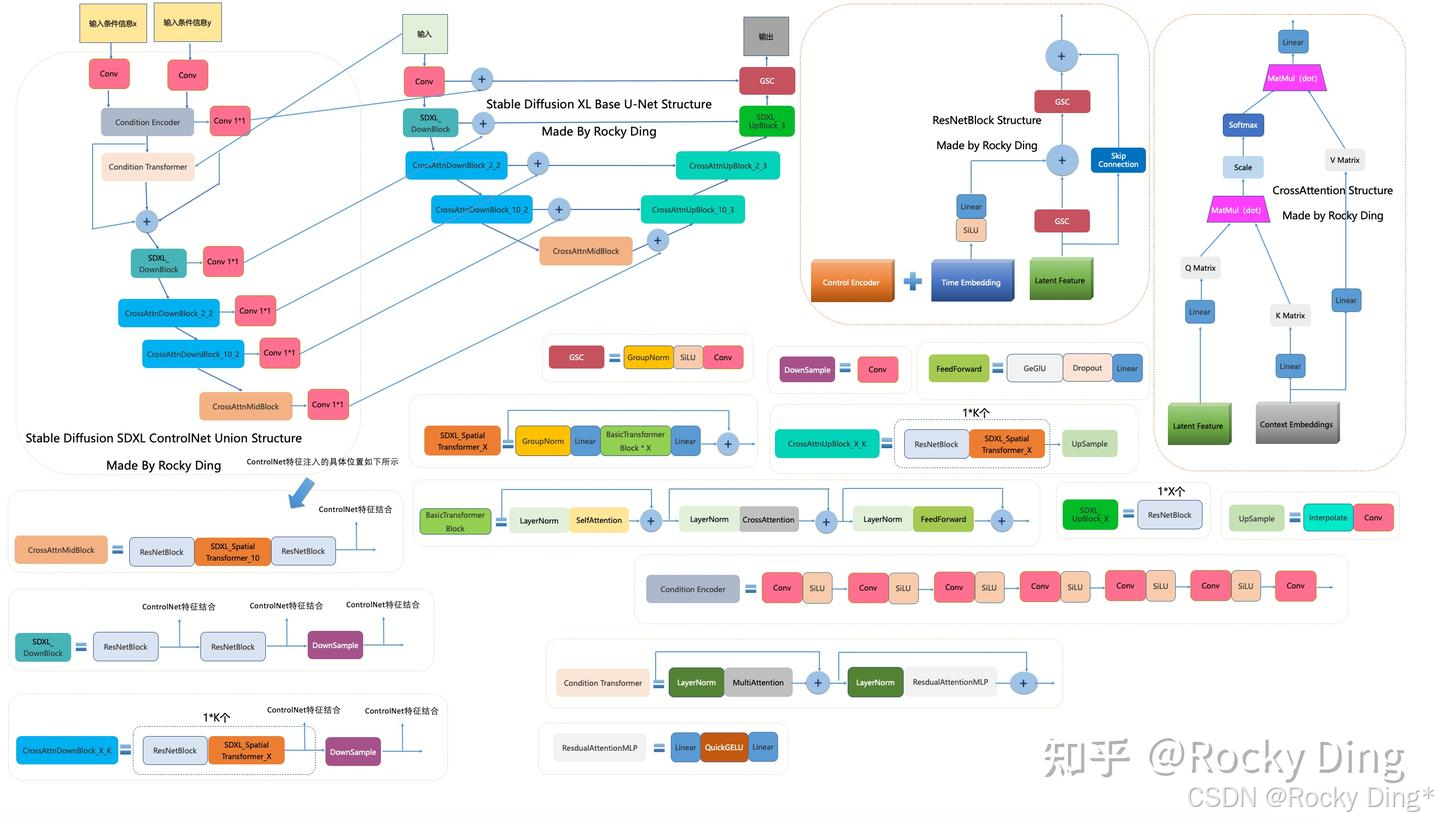
SDXL ControlNet Union模型的优化策略主要有:
- 采用分桶训练技术 :对不同分辨率数据采用分桶训练策略,这样在推理时能够生成任意宽高比的高分辨率图像。
- 海量高质量训练数据 :使用超过10M张高质量图像,数据集覆盖多样化的场景和内容。
- 采用高质量标注提示词 :使用CogVLM模型生成详细的Caption描述作为训练标签,使得模型具备优秀的提示词遵循能力。
- 集成多种训练技巧 :包括但不限于数据增强、多目标损失函数、多分辨率训练、统一训练策略(Unified Training Strategy)进行多条件训练等。
- 参数效率高 :与原始SDXL ControlNet相比,参数量几乎未增加,网络参数和计算量无明显上升。
- 支持多种控制条件 :兼容12种控制方式+5种高级编辑功能,每种条件的控制效果均不逊色于独立训练的SDXL ControlNet模型。
- 支持多条件融合生成 :支持在推理时同时使用多条件的控制能力,多条件融合机制在训练中学习得到,无需手动设置超参数或设计提示词。
- 兼容性强 :可与业界主流的SDXL模型、LoRA模型兼容使用。
4.3 SDXL ControlNet Union(ControlNet++)模型的控制生成功能详解
接下来,让我们一起看看SDXL ControlNet Union模型12种控制方式+5种高级编辑功能的效果。
SDXL ControlNet Union模型的Canny控制生成效果:
SDXL ControlNet Union模型的Depth控制生成效果:
SDXL ControlNet Union模型的Openpose控制生成效果:
SDXL ControlNet Union模型的Lineart控制生成效果:
SDXL ControlNet Union模型的MLSD控制生成效果:
SDXL ControlNet Union模型的Scribble控制生成效果:
SDXL ControlNet Union模型的Hed控制生成效果:
SDXL ControlNet Union模型的Pidi(Soft edge)控制生成效果:
SDXL ControlNet Union模型的Segment控制生成效果:
SDXL ControlNet Union模型的Normal控制生成效果:
4.4 SDXL ControlNet Union(ControlNet++)模型的编辑生成功能详解
上一章节中,我们已经了解学习了SDXL ControlNet Union模型的12种控制生成方式,我们在本章节中接着再学习一下5种高级编辑生成功能。
SDXL ControlNet Union的Tile Deblur图像去模糊编辑功能:
SDXL ControlNet Union的Tile variation图像细节变换编辑功能:
SDXL ControlNet Union的Tile Super Resolution超分辨率重建编辑功能,下面的例子展示了从100万分辨率到900万分辨率的效果:
SDXL ControlNet Union的Image Inpainting编辑功能:
SDXL ControlNet Union的Image Outpainting编辑功能:
接下来, 我们再看看SDXL ControlNet Union模型的多条件控制效果。
SDXL ControlNet Union的Openpose + Canny的组合控制生成效果:
SDXL ControlNet Union的Openpose + Depth的组合控制生成效果:
SDXL ControlNet Union的Openpose + Scribble的组合控制生成效果:
SDXL ControlNet Union的Openpose + Normal的组合控制生成效果:
SDXL ControlNet Union的Openpose + Segment的组合控制生成效果:
5. 深入浅出完整解析 FLUX.1 ControlNet核心基础知识
FLUX.1官方Black Forest Labs发布了FLUX.1 ControlNet和FLUX.1 Tools两大系列的生成可控模型配套工具。
前者包含的是常规的FLUX.1 ControlNet配套控制生成模型,一共有 flux-canny-controlnet 、 flux-depth-controlnet 、 flux-hed-controlnet 三种。每个FLUX.1 ControlNet都是在1024x1024分辨率下训练,能够适用于1024x1024分辨率及以上级别的高分辨率图控制生成任务。
同时开源社区的贡献者也发布了 FLUX.1-dev-ControlNet-Union-Pro,这是一个集多条件控制于一身的模型,能够同时支持canny、soft edge、depth、pose、gray等条件控制生成 。
而FLUX.1 Tools则包含四个 拥有“FLUX.1+ControlNet”组合能力的图像编辑生成大模型:
- FLUX.1 Fill :性能强大的inpainting和outpainting模型,可以根据文本描述和二值蒙版编辑和扩展图像内容。
- FLUX.1 Depth :能够根据从输入图像中提取的深度图和文本提示词来提供结构性指导。
- FLUX.1 Canny :能够根据从输入图像中提取的Canny边缘和文本提示词来提供结构性指导。
- FLUX.1 Redux :一个Adapter,允许混合输入图像和文本提示词来生成新的图像。

FLUX.1 ControlNet和FLUX.1 Tools都可以让FLUX.1系列模型的生成过程增加强可控性,极大的促进了FLUX.1开源生态的繁荣。
在接下来的章节中,Rocky将为大家一一讲解各个模型的原理和用法。
5.1 FLUX.1 ControlNet系列模型架构详解(包含详细图解)
FLUX.1 ControlNet分别复制了FLUX.1模型的5个单流模块和5个双流模块作为主体 ,用于训练和推理。下面是FLUX.1 ControlNet系列模型的模型架构图:
FluxControlNetModel(
(pos_embed): FluxPosEmbed()
(time_text_embed): CombinedTimestepGuidanceTextProjEmbeddings(
(time_proj): Timesteps()
(timestep_embedder): TimestepEmbedding(
(linear_1): Linear(in_features=256, out_features=3072, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=3072, out_features=3072, bias=True)
)
(guidance_embedder): TimestepEmbedding(
(linear_1): Linear(in_features=256, out_features=3072, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=3072, out_features=3072, bias=True)
)
(text_embedder): PixArtAlphaTextProjection(
(linear_1): Linear(in_features=768, out_features=3072, bias=True)
(act_1): SiLU()
(linear_2): Linear(in_features=3072, out_features=3072, bias=True)
)
)
(context_embedder): Linear(in_features=4096, out_features=3072, bias=True)
(x_embedder): Linear(in_features=64, out_features=3072, bias=True)
(transformer_blocks): ModuleList(
(0-4): 5 x FluxTransformerBlock(
(norm1): AdaLayerNormZero(
(silu): SiLU()
(linear): Linear(in_features=3072, out_features=18432, bias=True)
(norm): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
)
(norm1_context): AdaLayerNormZero(
(silu): SiLU()
(linear): Linear(in_features=3072, out_features=18432, bias=True)
(norm): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
)
(attn): Attention(
(norm_q): RMSNorm()
(norm_k): RMSNorm()
(to_q): Linear(in_features=3072, out_features=3072, bias=True)
(to_k): Linear(in_features=3072, out_features=3072, bias=True)
(to_v): Linear(in_features=3072, out_features=3072, bias=True)
(add_k_proj): Linear(in_features=3072, out_features=3072, bias=True)
(add_v_proj): Linear(in_features=3072, out_features=3072, bias=True)
(add_q_proj): Linear(in_features=3072, out_features=3072, bias=True)
(to_out): ModuleList(
(0): Linear(in_features=3072, out_features=3072, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
(to_add_out): Linear(in_features=3072, out_features=3072, bias=True)
(norm_added_q): RMSNorm()
(norm_added_k): RMSNorm()
)
(norm2): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(ff): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=3072, out_features=12288, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): Linear(in_features=12288, out_features=3072, bias=True)
)
)
(norm2_context): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(ff_context): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=3072, out_features=12288, bias=True)
)
(1): Dropout(p=0.0, inplace=False)
(2): Linear(in_features=12288, out_features=3072, bias=True)
)
)
)
)
(single_transformer_blocks): ModuleList()
(controlnet_blocks): ModuleList(
(0-4): 5 x Linear(in_features=3072, out_features=3072, bias=True)
)
(controlnet_single_blocks): ModuleList()
(controlnet_x_embedder): Linear(in_features=64, out_features=3072, bias=True)
)
我们可以看到, FLUX.1 ControlNet在复制了5个transformer_blocks和5个single_transformer_blocks作为主体 进行训练后,和SD ControlNet一样在推理时加载到FLUX.1模型中,起到控制生成的作用。
5.2 FLUX.1 Canny ControlNet、FLUX.1 Depth ControlNet、FLUX.1 Hed ControlNet模型核心基础知识详解
【FLUX.1 Canny ControlNet模型核心基础知识详解】
官方训练FLUX.1 Canny ControlNet(FLUX.1-dev-Controlnet-Canny)模型时,在1024*1024分辨率的基准下使用了多分辨率策略,并设置8x8的Batch_Size迭代训练了30k steps。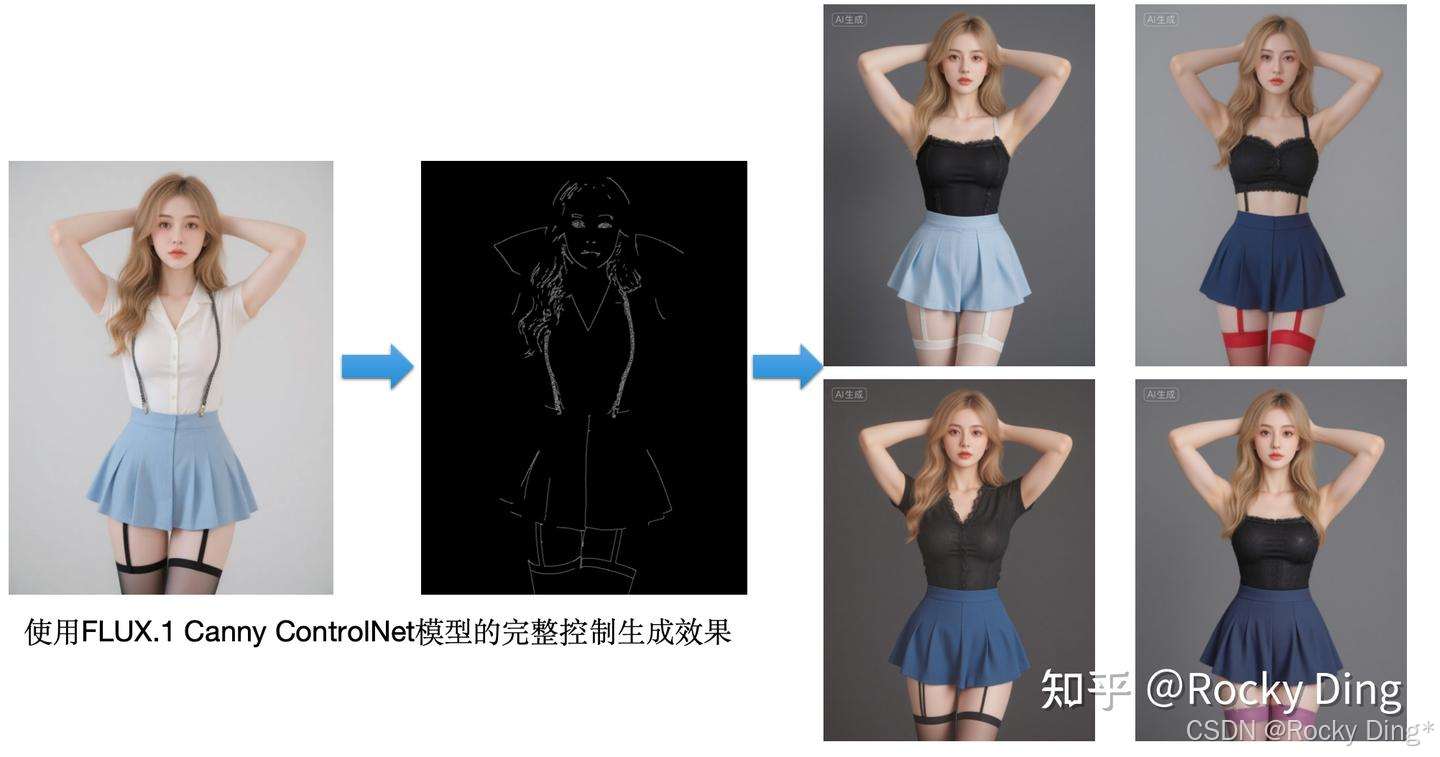
【FLUX.1 Depth ControlNet模型核心基础知识详解】
FLUX.1 Depth ControlNet模型由 4个FluxTransformerBlock和1个FluxSingleTransformerBlock组成 。在真实和生成的图像数据集上进行训练,批次大小为16(16个A*800)×4=64,一共训练了70K steps,训练分辨率为1024,学习率设置为5e-6。官方使用Depth-Anything-V2来提取深度图。
在推理时,推荐设置controlnet_conditioning_scale值为0.3-0.7。
我们可以方便的在ComfyUI中构建FLUX.1 Depth ControlNet对应的工作流: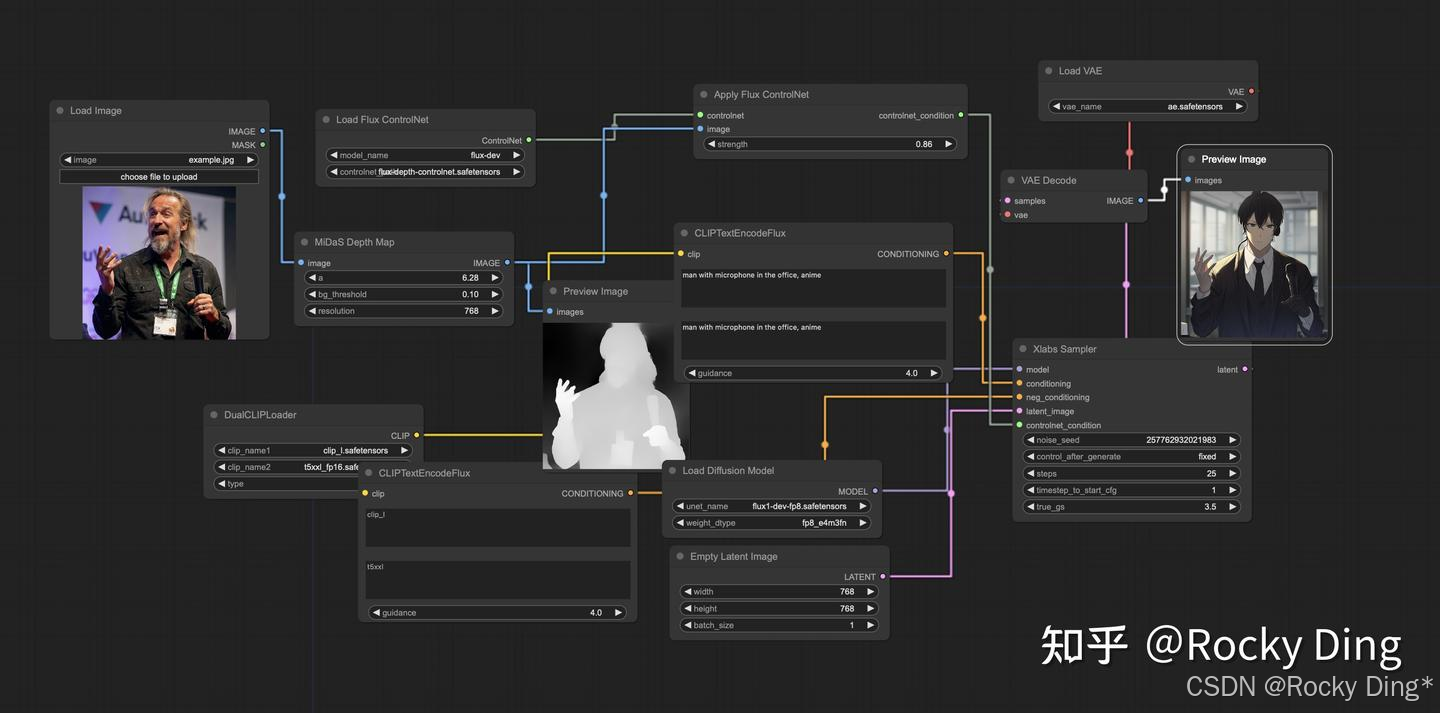
【FLUX.1 Hed ControlNet模型核心基础知识详解】
FLUX.1 Hed ControlNet模型同样是在 1024x1024 分辨率下训练的 ,能够支持1024x1024及以上分辨率图像的控制生成。
我们可以方便的在ComfyUI中构建FLUX.1 Hed ControlNet对应的工作流: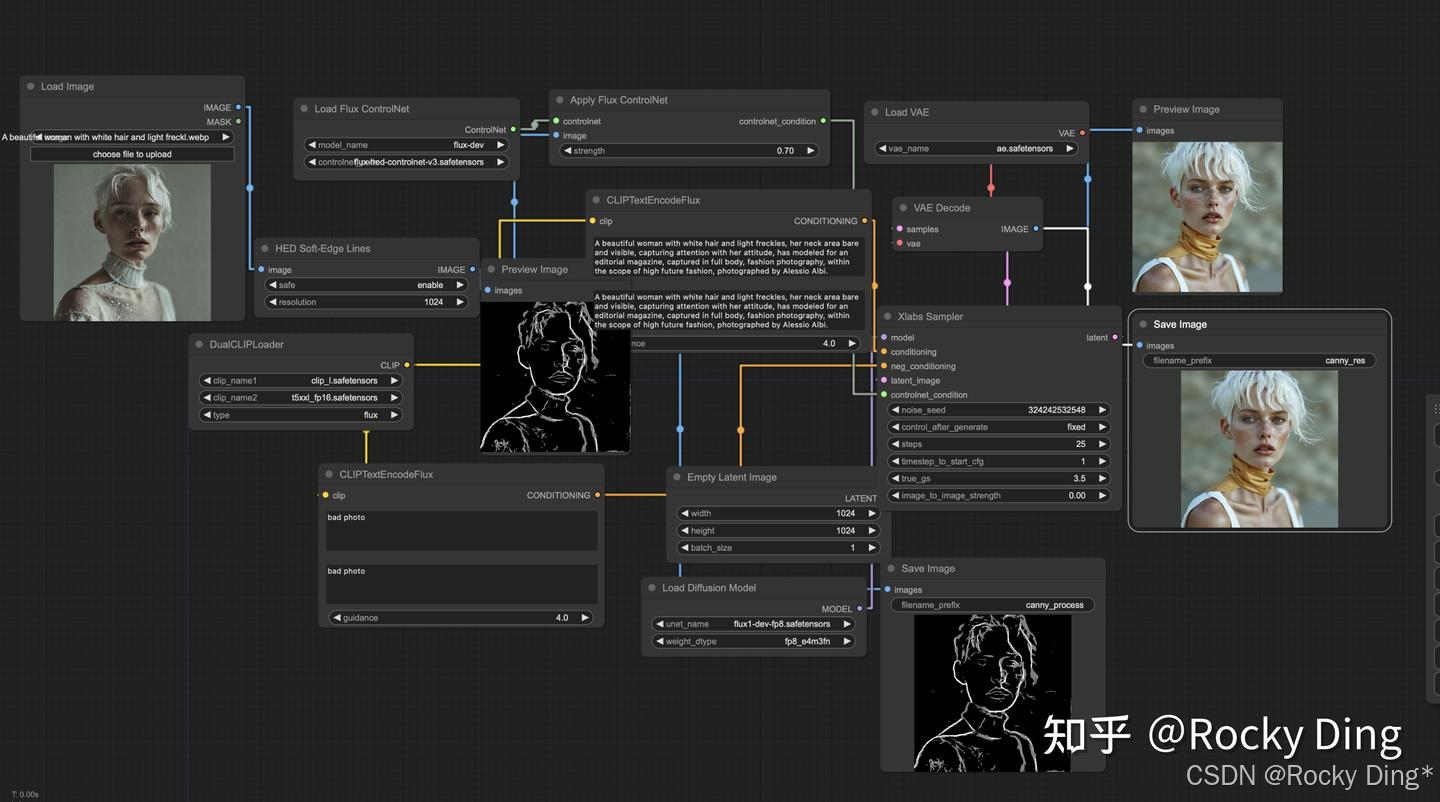
5.3 FLUX.1 ControlNet Union模型核心基础知识详解
FLUX.1 ControlNet Union是一款为FLUX.1设计的多功能ControlNet模型。和SDXL Controlnet Union一样,该模型整合了多种控制模式, 如边缘检测、深度图、人体骨骼关键点、模糊处理等,能够在生成图像时提供更精细的控制。
其中FLUX.1-dev-Controlnet-Union第一代模型由InstantX发布, 官方也解释了其是一个测试版本,效果性能仍存在优化空间 。紧接着InstantX联合 Shakker实验室共同发布了 第二代FLUX.1-dev-ControlNet-Union-Pro版本,比起第一代,使用了更大规模的训练数据和训练迭代次数,效果和性能上均有大幅提升, 同时官方推荐将参数controlnet_conditioning_scale设置为0.3-0.8效果为佳。
InstantX FLUX.1 ControlNet Union支持七种不同的控制模式 ,分别为 canny、tile、depth、blur、pose、gray 和 low quality,每种模式对应特定的图像处理功能:
- Canny :该模式基于Canny边缘检测算法,能够有效识别并提取图像中的轮廓与结构信息。
- Tile :平铺模式可用于生成具有重复排列单元的图像效果,增强画面的节奏与秩序感。
- Depth :深度感知模式能够推断并重建图像中物体的空间关系,生成对应的深度图以表现场景的立体层次。
- Blur :该模式可对图像施加模糊处理,减弱细节以突出主体或营造柔和视觉效果。
- Pose :姿态控制模式支持对图像中人物或物体的动作和姿态进行识别与调整。
- Gray :灰度转换模式将彩色图像转换为黑白图像,仅保留明度信息,突出光影结构。
- Low Quality :低画质模式可生成分辨率较低或压缩感较强的图像,适用于对计算资源有限制或追求特定风格输出的场景。
不久之后,Shakker实验室再次发布了FLUX.1-dev-ControlNet-Union-Pro-2.0版本,与FLUX.1-dev-ControlNet-Union-Pro 相比,做了如下的优化:
- 移除了模式嵌入 (Mode Embedding) ,在使用时不再需要输入特定的控制模式序号(比如Canny=0)因此模型体积更小更轻量化了。
- 在 Canny(边缘检测)和 Pose(姿态)控制上进行了改进 ,控制效果更好,生成图像的审美质量更高。
- 新增了对 Soft Edge(软边缘)的支持,同时移除了对 Tile(平铺)的支持。
FLUX.1-dev-ControlNet-Union-Pro-2.0模型包含了 6 个“双流模块”(double blocks)和 0 个“单流模块”(single block)作为核心架构 。Shakker实验室使用一个包含 2000 万(20M)张高质量通用和人物图像 的数据集, 从零开始(scratch)训练了 30 万步(300k steps) 。训练分辨率为 512x512 ,使用 BFloat16 混合精度, 批大小(batch size)为 128, 学习率(learning rate)为 2e-5,guidance scale 从 [1, 7] 的范围中均匀采样,同时设置将 文本丢弃比率(text drop ratio)为 0.20 (即20%的概率忽略文本提示)。
最终FLUX.1-dev-ControlNet-Union-Pro-2.0模型可以进行控制的模式包括 canny(边缘图)、 soft edge(软边缘图) 、 depth(深度图)、 pose(姿态图)、 gray(灰度图)。
同时官方也给出了调整controlnet_conditioning_scale(ControlNet条件缩放比例)和control_guidance_end(控制引导结束时机)参数的建议,以增强控制效果并更好地保留细节。具体参数建议如下:
- Canny边缘检测 :使用cv2.Canny算法,建议参数:controlnet_conditioning_scale=0.7,control_guidance_end=0.8
- 软边缘检测 :使用AnylineDetector,建议参数:controlnet_conditioning_scale=0.7,control_guidance_end=0.8
- 深度图 :使用depth-anything模型,建议参数:controlnet_conditioning_scale=0.8,control_guidance_end=0.8
- 姿态识别 :使用DWPose模型,建议参数:controlnet_conditioning_scale=0.9,control_guidance_end=0.65
- 灰度图 :使用cv2.cvtColor转换,建议参数:controlnet_conditioning_scale=0.9,control_guidance_end=0.8

目前我们可以在ComfyUI和Diffusers上方便的进行FLUX.1-dev-ControlNet-Union-Pro-2.0模型的部署推理。
下面是使用Diffuser框架进行推理的详细例子:
import torch
from diffusers.utils import load_image
from diffusers import FluxControlNetPipeline, FluxControlNetModel
base_model = '本地路径/FLUX.1-dev'
controlnet_model_union = '本地路径/FLUX.1-dev-ControlNet-Union-Pro-2.0'
controlnet = FluxControlNetModel.from_pretrained(controlnet_model_union, torch_dtype=torch.bfloat16)
pipe = FluxControlNetPipeline.from_pretrained(base_model, controlnet=controlnet, torch_dtype=torch.bfloat16)
pipe.to("cuda")
# replace with other conds
control_image = load_image("./conds/canny.png")
width, height = control_image.size
prompt = "A young girl stands gracefully at the edge of a serene beach, her long, flowing hair gently tousled by the sea breeze. She wears a soft, pastel-colored dress that complements the tranquil blues and greens of the coastal scenery. The golden hues of the setting sun cast a warm glow on her face, highlighting her serene expression. The background features a vast, azure ocean with gentle waves lapping at the shore, surrounded by distant cliffs and a clear, cloudless sky. The composition emphasizes the girl's serene presence amidst the natural beauty, with a balanced blend of warm and cool tones."
image = pipe(
prompt,
control_image=control_image,
width=width,
height=height,
controlnet_conditioning_scale=0.7,
control_guidance_end=0.8,
num_inference_steps=30,
guidance_scale=3.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
同时,我们也可以同时使用 多个控制条件进行控制生成:
import torch
from diffusers.utils import load_image
# use local files for this moment
from pipeline_flux_controlnet import FluxControlNetPipeline
from controlnet_flux import FluxControlNetModel
base_model = '本地路径/FLUX.1-dev'
controlnet_model_union = '本地路径/FLUX.1-dev-ControlNet-Union-Pro-2.0'
controlnet = FluxControlNetModel.from_pretrained(controlnet_model_union, torch_dtype=torch.bfloat16)
pipe = FluxControlNetPipeline.from_pretrained(base_model, controlnet=[controlnet], torch_dtype=torch.bfloat16) # use [] to enable multi-CNs
pipe.to("cuda")
# replace with other conds
control_image = load_image("./conds/canny.png")
width, height = control_image.size
control_image_2 = load_image("./conds/depth.png")
width, height = control_image.size
prompt = "A young girl stands gracefully at the edge of a serene beach, her long, flowing hair gently tousled by the sea breeze. She wears a soft, pastel-colored dress that complements the tranquil blues and greens of the coastal scenery. The golden hues of the setting sun cast a warm glow on her face, highlighting her serene expression. The background features a vast, azure ocean with gentle waves lapping at the shore, surrounded by distant cliffs and a clear, cloudless sky. The composition emphasizes the girl's serene presence amidst the natural beauty, with a balanced blend of warm and cool tones."
image = pipe(
prompt,
control_image=[control_image, control_image_2], # try with different conds such as canny&depth, pose&depth
width=width,
height=height,
controlnet_conditioning_scale=[0.35, 0.35],
control_guidance_end=[0.8, 0.8],
num_inference_steps=30,
guidance_scale=3.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
5.4 FLUX.1 Tool系列模型架构详解(包含详细图解)
FLUX.1 Tool系列模型是AIGC图像可控生成技术领域的一次大胆尝试,开创了AIGC图像生成大模型直接进行图像可控&编辑生成的先河。
下图是Rocky梳理的FLUX.1 Tool ControlNet的完整结构图 ,其中FLUX.1 Fill、FLUX.1 Depth、FLUX.1 Canny、FLUX.1 Redux都具备相同的模型架构。大家可以感受一下其魅力,看着这个完整结构图学习FLUX.1 Tool ControlNet,相信大家脑海中的思路也会更加清晰: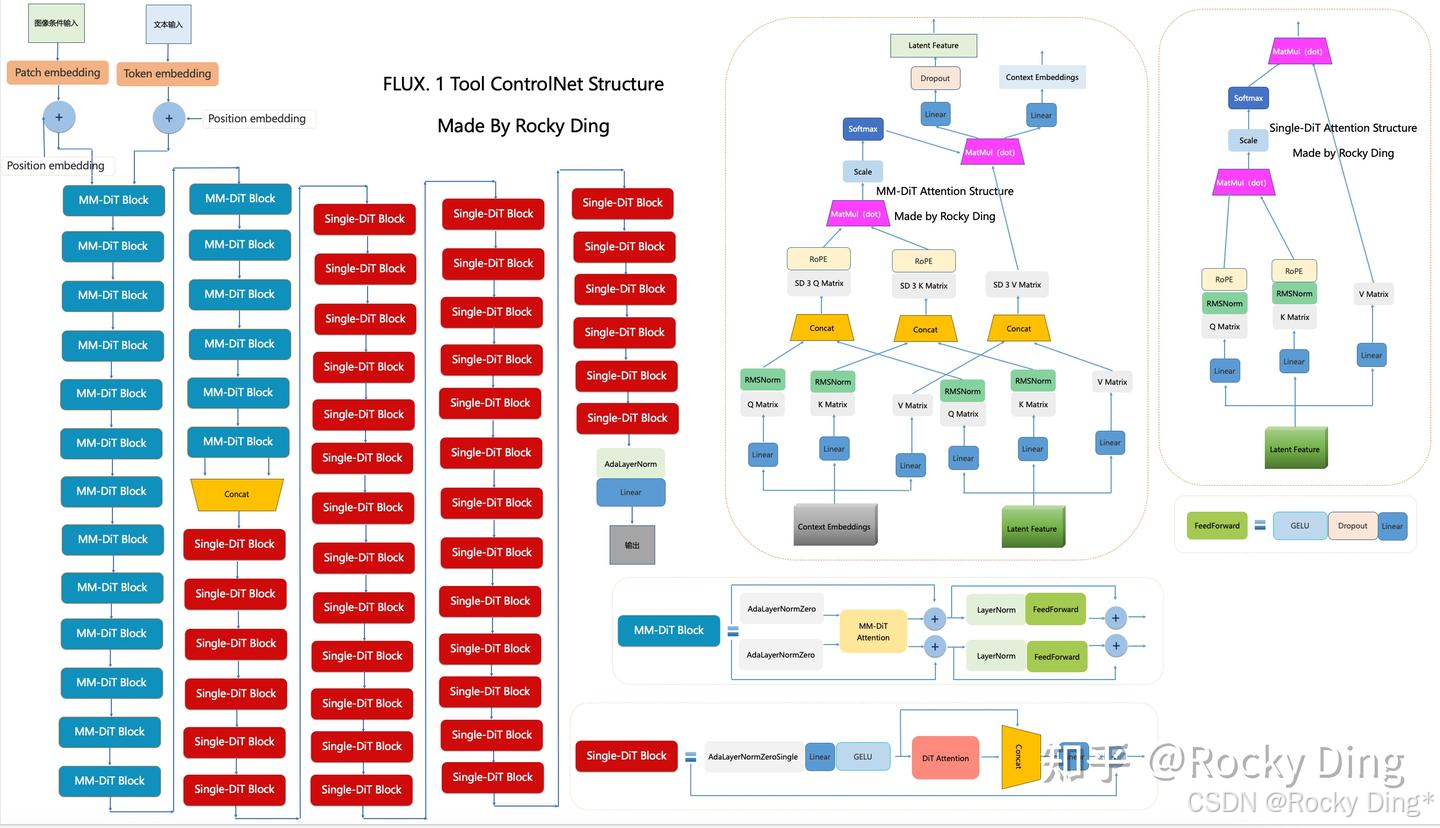
可以看到,FLUX.1 Tool系列模型的架构和FLUX.1一致, 核心是MM-Single-DiT架构 ,包含了19层MM-DiT Block结构和38层Single-DiT Block结构:
- MM-DiT Block:由两个AdaLayerNormZero层+一个MM-DiT Attention Structure模块+两个LayerNorm层+两个FeedForward层组成。
- Single-DiT Block:由一个AdaLayerNormZero层+一个Single-DiT Attention Structure(DiT Attention)模块+两个Linear层+一个GELU激活函数组成。
- MM-DiT Attention Structure:FLUX.1 Tool的MM-DiT Block中的核心组件,将文本信息和图像信息以同等重要的级别进行Attention机制。
- Single-DiT Attention Structure:FLUX.1 Tool的Single-DiT Block中的核心组件,将文本信息和图像信息的特征融合后,进行经典的DiT-Attention机制。
- FeedForward:由GELU激活函数+Dropout层+Linear层组成。
与FLUX.1不同的是,FLUX.1 Tool系列模型的图像侧输入不再是常规图像的特征,而是Fill、Canny、Depth、Redux等条件特征。
5.5 FLUX.1 Tool Fill、FLUX.1 Tool Canny/Depth、FLUX.1 Tool Redux编辑生成模型核心基础知识详解
【FLUX.1 Tool Fill编辑生成模型核心基础知识详解】
FLUX.1 Fill编辑生成模型是一款基于FLUX.1架构的图像修复模型,本质上是将inpainting和outpainting功能在FLUX.1上原生实现。将FLUX.1 ControlNet模型的能力深度集成,不需要再额外外接一个单独的ControlNet模型,简化了AIGC图像生成领域的可控生成的流程。
FLUX.1 Fill能够 选择图像中的特定区域并进行无缝编辑(inpainting), 对图像的选中部分区域(mask)进行变换,同时保留周围的上下文,自然地更改对象、增强细节或移除不需要的元素,与现有图像自然融合。
FLUX.1 Fill的inpainting的实际案例如下所示,在图像上半部分的例子中,通过对编辑部分施加mask,用不同风格的夹克替换了原来的夹克。而在图像下半部分的例子中,将霓虹灯招牌上的文字进行了编辑:
除了上述的例子,FLUX.1 Fill还能通过inpainting思想实现如下的应用功能:
- 智能移除 :移除照片中不想要的物体、人物、水印、瑕疵等。
- 瑕疵修复 :修复老照片的划痕、破损,或补充图像中缺失的角落。
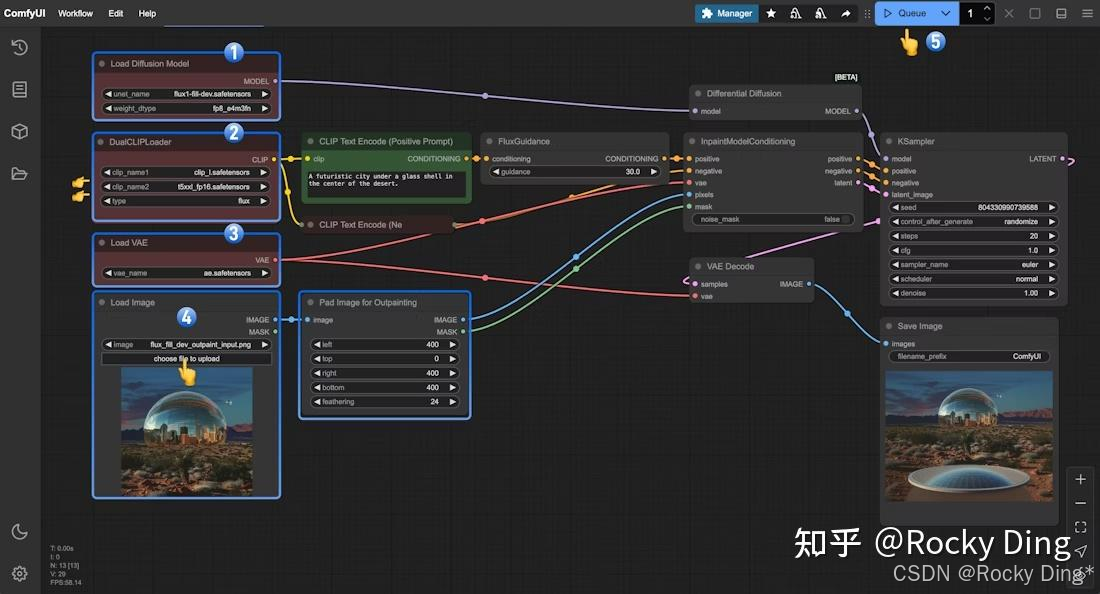
同时FLUX.1 Fill还可以 在图像边缘添加新像素(outpainting), 将图像扩展到其原始边界之外,以提高分辨率或改变纵横比,非常适合扩展场景或调整内容以适应不同格式:
- 扩展视野 :将一张肖像图扩展成全景图,为风景照增添更广阔的天空或草地。
- 改变比例 :将一张方形图片扩展成适合做桌面壁纸的宽屏比例,自动智能地填充左右两侧的内容。
- 创意构图 :为已有的画作或设计图添加新的元素和背景,开拓创作边界。

目前我们可以在ComfyUI和Diffusers上方便的进行FLUX.1 Fill模型的部署推理。
下面是FLUX.1 Fill在Diffusers上运行推理的完整代码:
import torch
from diffusers import FluxFillPipeline
from diffusers.utils import load_image
image = load_image("https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/cup.png")
mask = load_image("https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/cup_mask.png")
pipe = FluxFillPipeline.from_pretrained("black-forest-labs/FLUX.1-Fill-dev", torch_dtype=torch.bfloat16).to("cuda")
image = pipe(
prompt="a white paper cup",
image=image,
mask_image=mask,
height=1632,
width=1232,
guidance_scale=30,
num_inference_steps=50,
max_sequence_length=512,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"flux-fill-dev.png")
下面是FLUX.1 Fill在ComfyUI上的完整工作流(inpainting):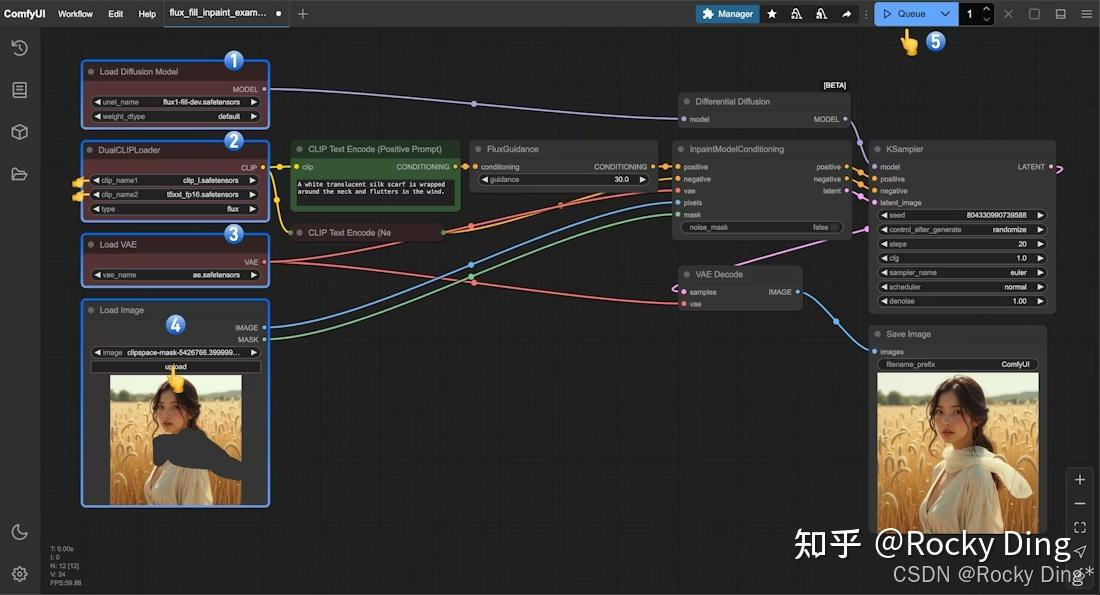
最后, FLUX官方还构建一个基准测试用于对FLUX.1 Fill模型进行性能评估 。结果显示,Flux.1 Fill [pro]版本的性能超越了所有其他主流方法,使其成为迄今为止最先进的AIGC图像修复模型。排在第二位的是Flux.1 Fill [dev],它在推理时更高效,同时超越了专有解决方案,如Ideogram 2.0和一些开源模型。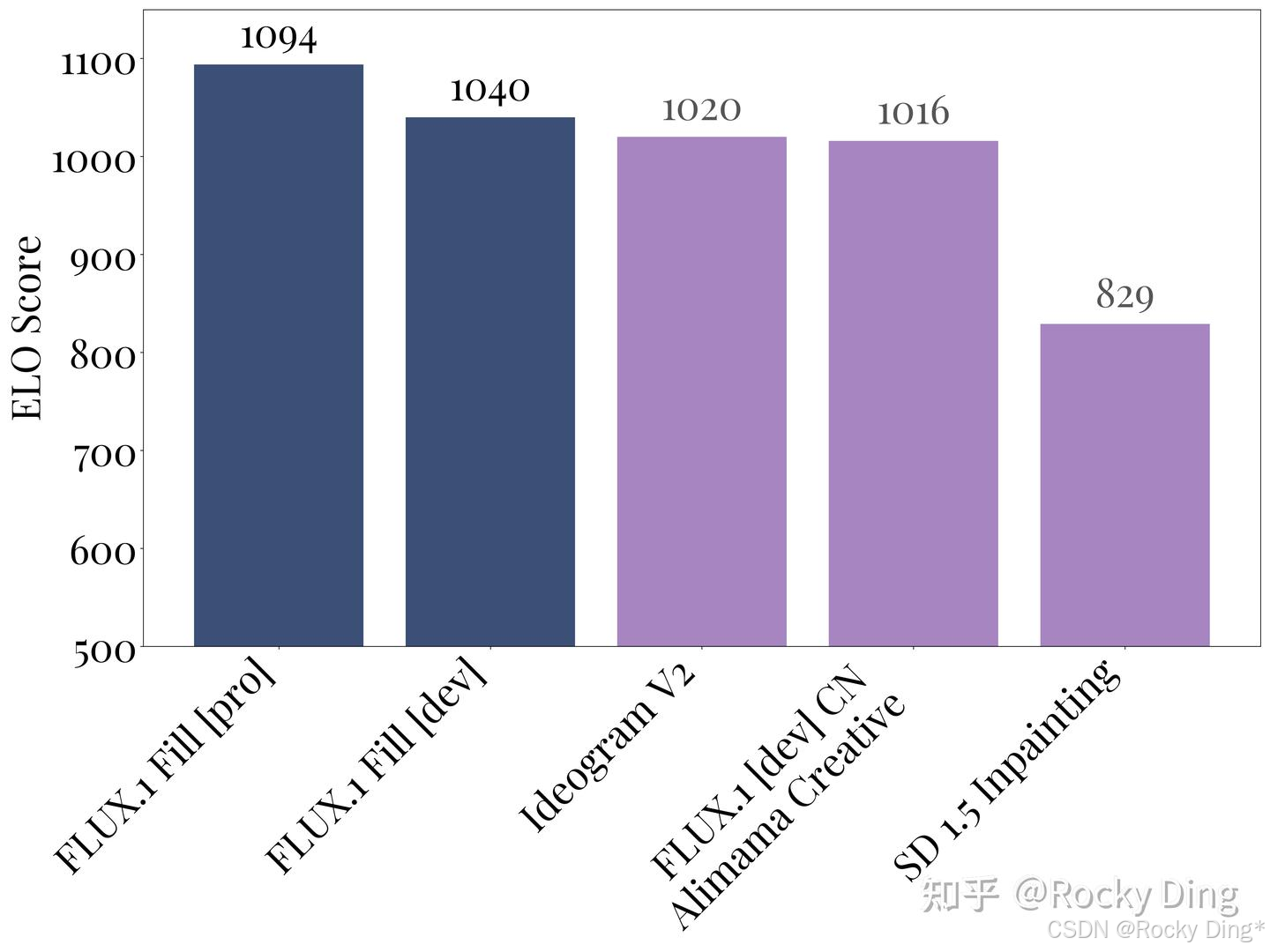
【FLUX.1 Tool Canny/Depth编辑生成模型核心基础知识详解】
FLUX.1 Canny/Depth是将Canny/Depth这两个结构性条件控制能力融合进FLUX.1中 ,不再需要在外接额外的ControlNet,只需输入Canny边缘检测或Depth深度检测条件信息,结合Prompt提示词在保持核心构图完整的情况下进行文本引导的编辑,从而在图像转换过程中保持精确控制,特别适用于重新纹理化图像生成的场景。
在官方的基准测试评估中,FLUX.1 Depth的性能表现优于Midjourney ReTexture等专有模型。特别是FLUX.1 Depth [pro]具有更高的输出多样性,而FLUX.1 Depth的开发版(Dev)在深度感知任务中能提供更一致的结果。对于Canny边缘控制生成模型,FLUX.1 Canny [pro]是同类中的佼佼者,其次是FLUX.1 Canny [dev]。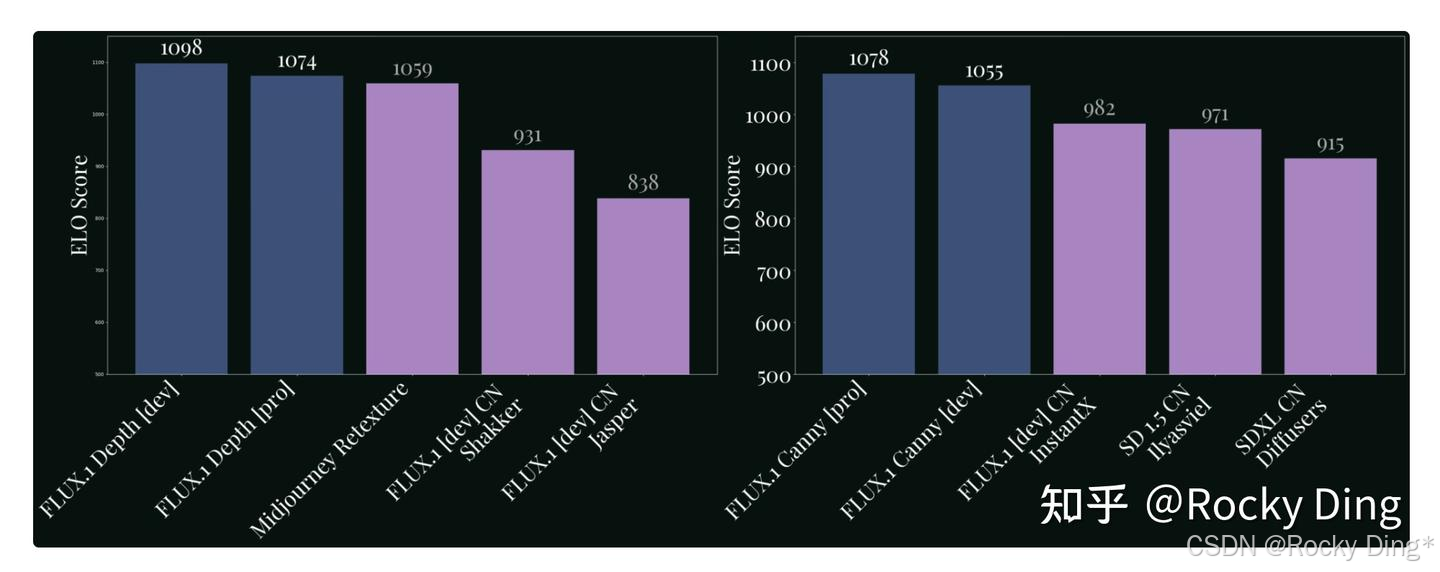
目前我们可以在ComfyUI和Diffusers上方便的进行FLUX.1 Canny/Depth模型的部署推理。
下面是在Diffusers上运行FLUX.1 Canny推理的完整代码:
import torch
from controlnet_aux import CannyDetector
from diffusers import FluxControlPipeline
from diffusers.utils import load_image
pipe = FluxControlPipeline.from_pretrained("black-forest-labs/FLUX.1-Canny-dev", torch_dtype=torch.bfloat16).to("cuda")
prompt = "A robot made of exotic candies and chocolates of different kinds. The background is filled with confetti and celebratory gifts."
control_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/robot.png")
processor = CannyDetector()
control_image = processor(control_image, low_threshold=50, high_threshold=200, detect_resolution=1024, image_resolution=1024)
image = pipe(
prompt=prompt,
control_image=control_image,
height=1024,
width=1024,
num_inference_steps=50,
guidance_scale=30.0,
).images[0]
image.save("output.png")
下面是在Diffusers上运行FLUX.1 Depth推理的完整代码:
import torch
from diffusers import FluxControlPipeline, FluxTransformer2DModel
from diffusers.utils import load_image
from image_gen_aux import DepthPreprocessor
pipe = FluxControlPipeline.from_pretrained("black-forest-labs/FLUX.1-Depth-dev", torch_dtype=torch.bfloat16).to("cuda")
prompt = "A robot made of exotic candies and chocolates of different kinds. The background is filled with confetti and celebratory gifts."
control_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/robot.png")
processor = DepthPreprocessor.from_pretrained("LiheYoung/depth-anything-large-hf")
control_image = processor(control_image)[0].convert("RGB")
image = pipe(
prompt=prompt,
control_image=control_image,
height=1024,
width=1024,
num_inference_steps=30,
guidance_scale=10.0,
generator=torch.Generator().manual_seed(42),
).images[0]
image.save("output.png")
下面是在ComfyUI上运行FLUX.1 Canny推理的完整工作流: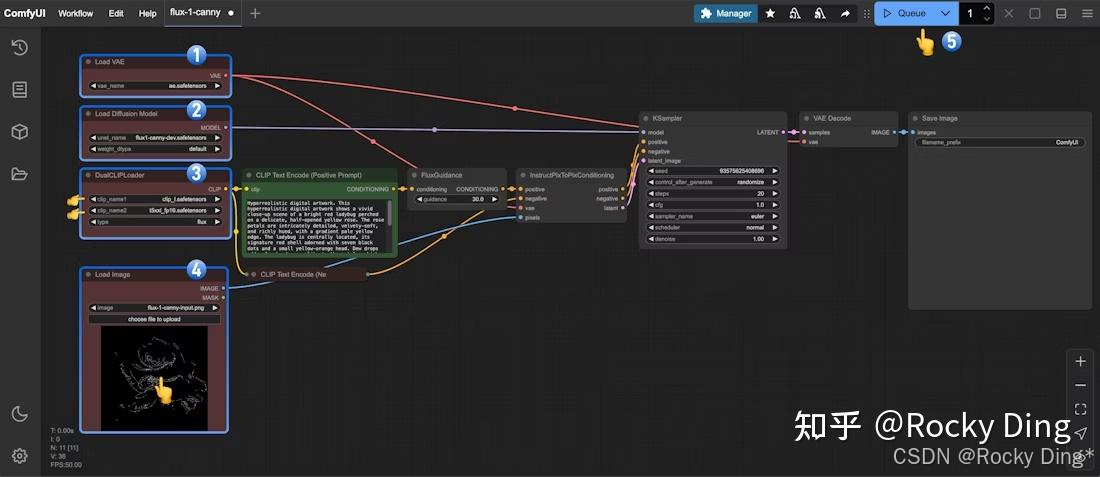
下面是在ComfyUI上运行FLUX.1 Depth推理的完整工作流: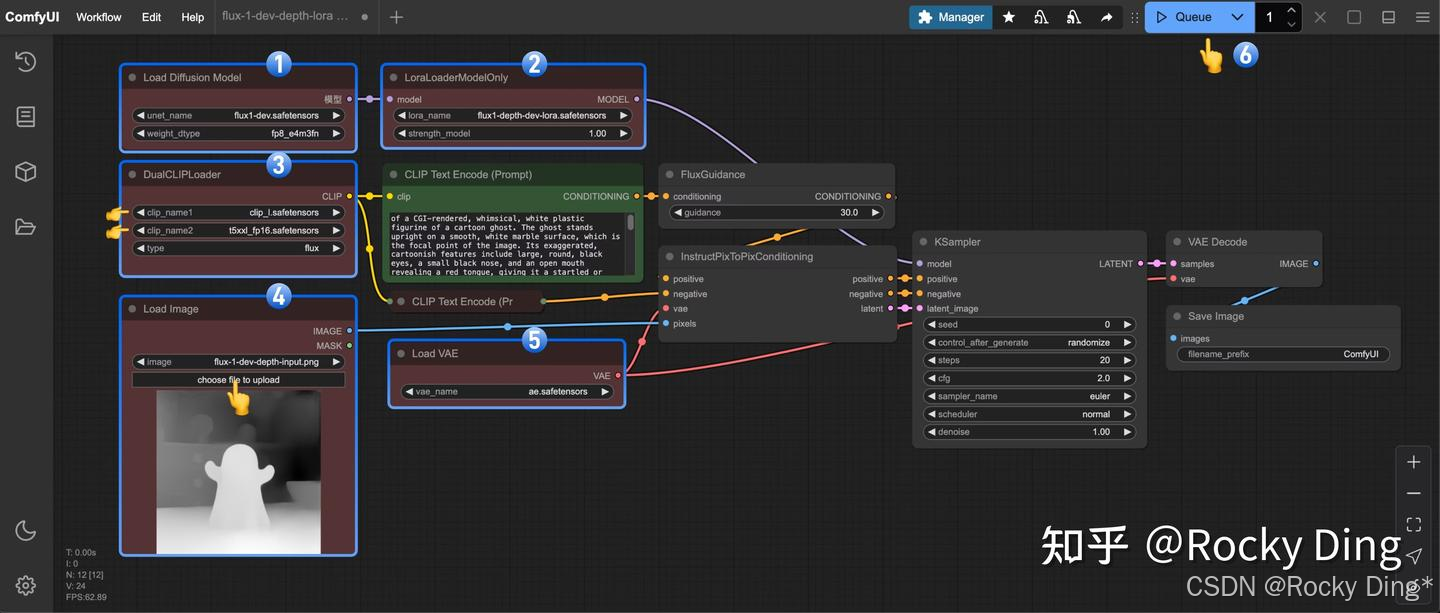
【FLUX.1 Tool Redux编辑生成模型核心基础知识详解】
FLUX.1 Redux模型可以进行图像变体生成与风格重塑。具体来说,给定一张输入图像,FLUX.1 Redux能够生成该图像的细微变体,从而实现对给定图像的优化。
我们可以将FLUX.1 Redux看作是FLUX.1基础模型的Adapter,类似IP-Adapter,用于生成图像变化。
它能自然地融入更复杂的工作流节点(Workflow),通过提示词实现图像风格重塑。
在官方的基准测试评估中,FLUX.1 Redux在图像变体方面实现了最先进的性能: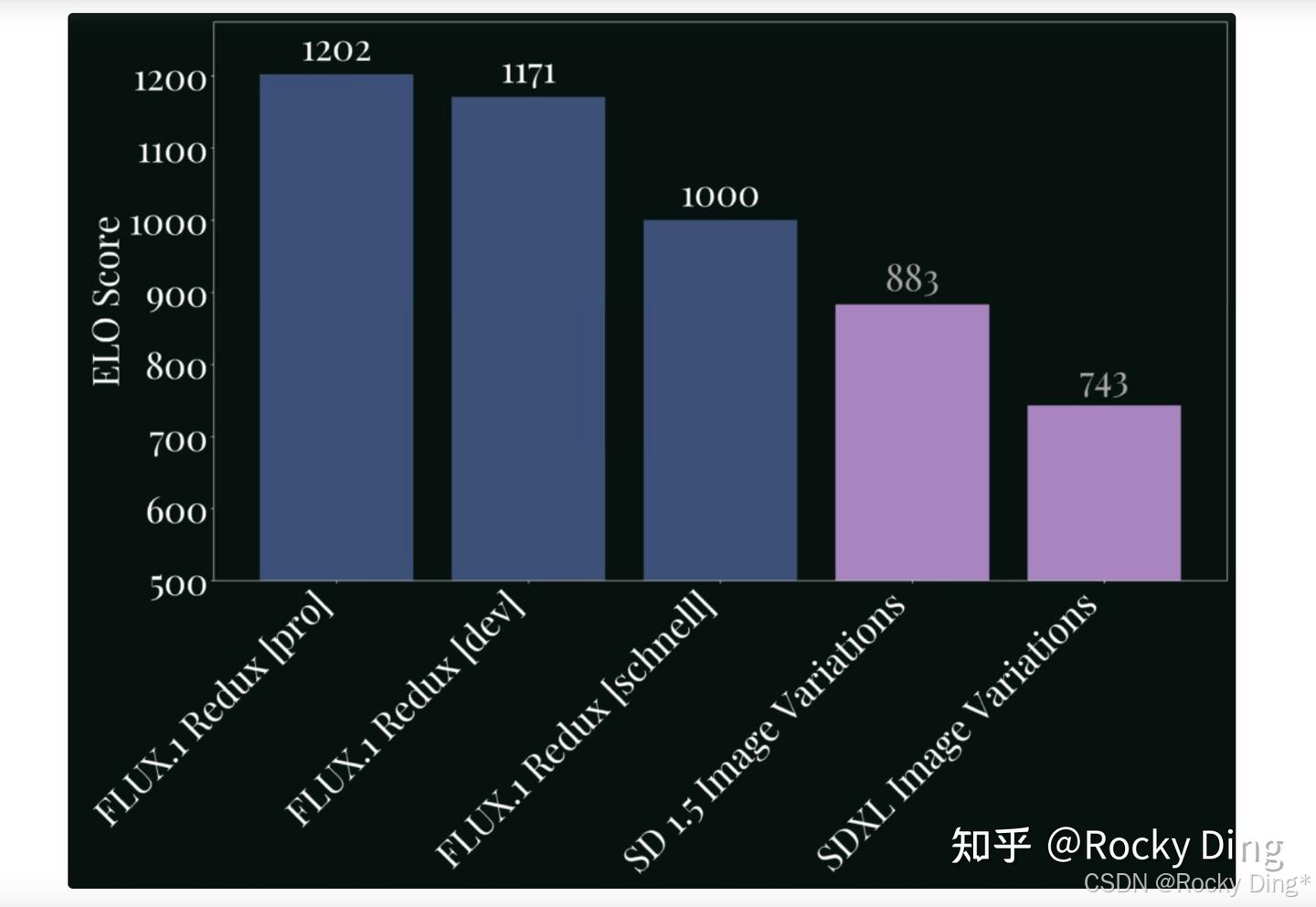
目前我们可以在ComfyUI和Diffusers上方便的进行FLUX.1 Redux模型的部署推理。
下面是在Diffusers上运行FLUX.1 Redux推理的完整代码:
import torch
from diffusers import FluxPriorReduxPipeline, FluxPipeline
from diffusers.utils import load_image
pipe_prior_redux = FluxPriorReduxPipeline.from_pretrained("black-forest-labs/FLUX.1-Redux-dev", torch_dtype=torch.bfloat16).to("cuda")
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev" ,
text_encoder=None,
text_encoder_2=None,
torch_dtype=torch.bfloat16
).to("cuda")
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/robot.png")
pipe_prior_output = pipe_prior_redux(image)
images = pipe(
guidance_scale=2.5,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0),
**pipe_prior_output,
).images
images[0].save("flux-dev-redux.png")
下面是在ComfyUI上运行FLUX.1 Redux推理的完整工作流: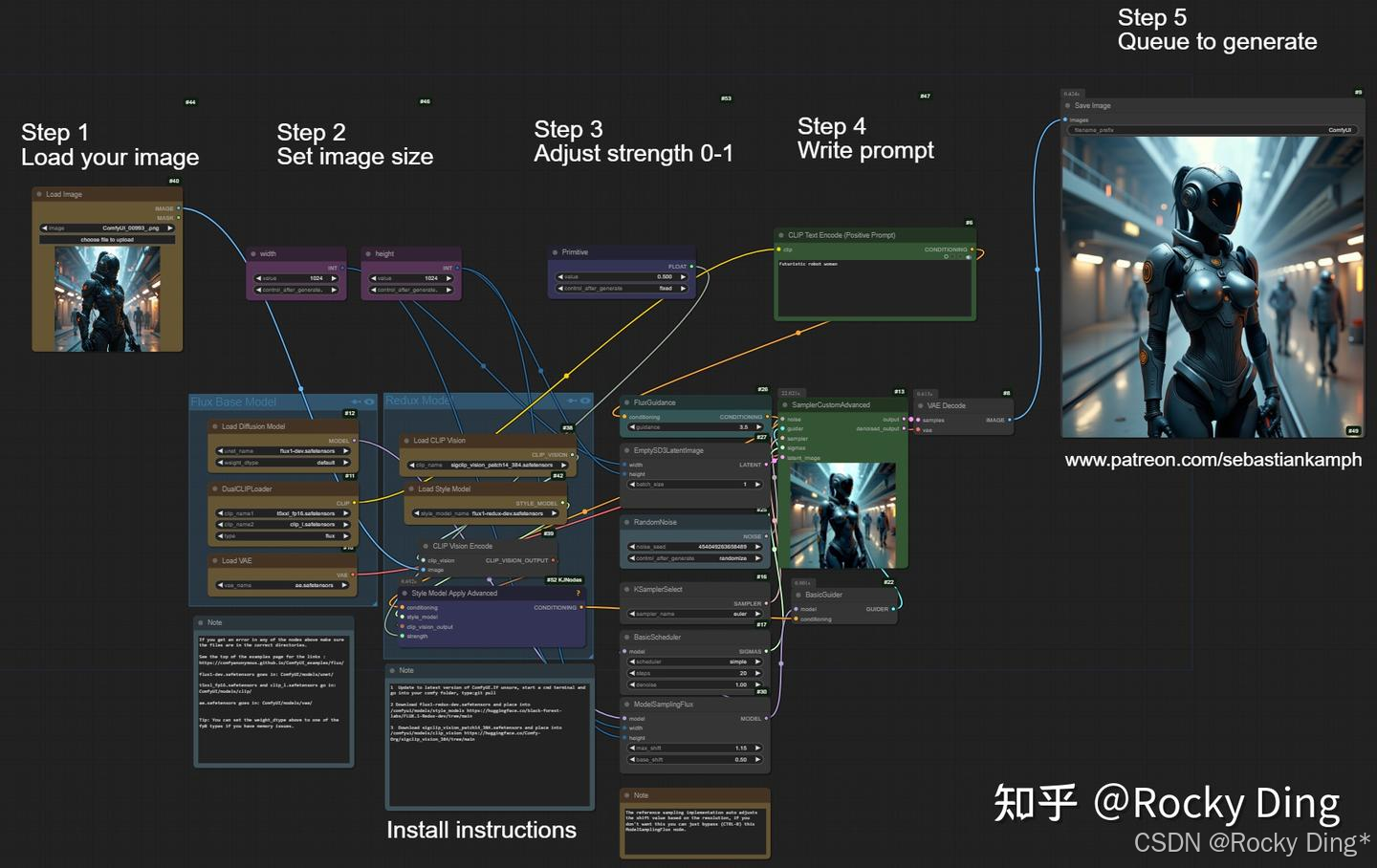
到这里, 我们就完整讲解了基于FLUX.1可控生成技术生态,可以说在SDXL的基础上,又向前迈进了一大步:
- 开始尝试基于AIGC图像生成大模型构建原生的图像控制生成和编辑生成能力,这样能够极大简化未来AIGC图像可控生成领域的复杂度与生产成本。FLUX.1 Tools就是一次很好的尝试。
- FLUX ControlNet Union在SDXL ControlNet Union的基础上,能够在一个ControlNet中进行多种条件的控制生成,同时更新了模型架构,使其不再需要模式嵌入 (Mode Embedding)。
正是这些探索,给了后来者以灵感。在2025年AIGC图像生成领域进入“中场时刻”后,出现了像Nana Banana Pro、GPT-4o、Seedream、FLUX.1 Kontext、FLUX.2这样的原生图像生成和图像编辑大模型,可控生成效果和整体图像生成质量达到了新的高度 :
6. 从0到1搭建使用ControlNet进行AI绘画(全网最详细讲解)
6.1 零基础使用ComfyUI搭建ControlNet推理流程(包含SD ControlNet、SDXL ControlNet、FLUX.1 ControlNet)
关于ComfyUI的安装和搭建流程,大家可以阅读Rocky一直在撰写的ComfyUI全维度解析文章:
深入浅出完整解析主流AI绘画框架(ComfyUI、Stable Diffusion WebUI、Fooocus)核心基础知识
在ComfyUI中,我们需要构建基于ControlNet的工作流来进行推理,这种模式各个节点十分灵活,互相解耦,可以说ComfyUI具备跨周期的AIGC图像生成框架的潜质。
首先,我们看看SD ControlNet的ComfyUI推理运行工作流: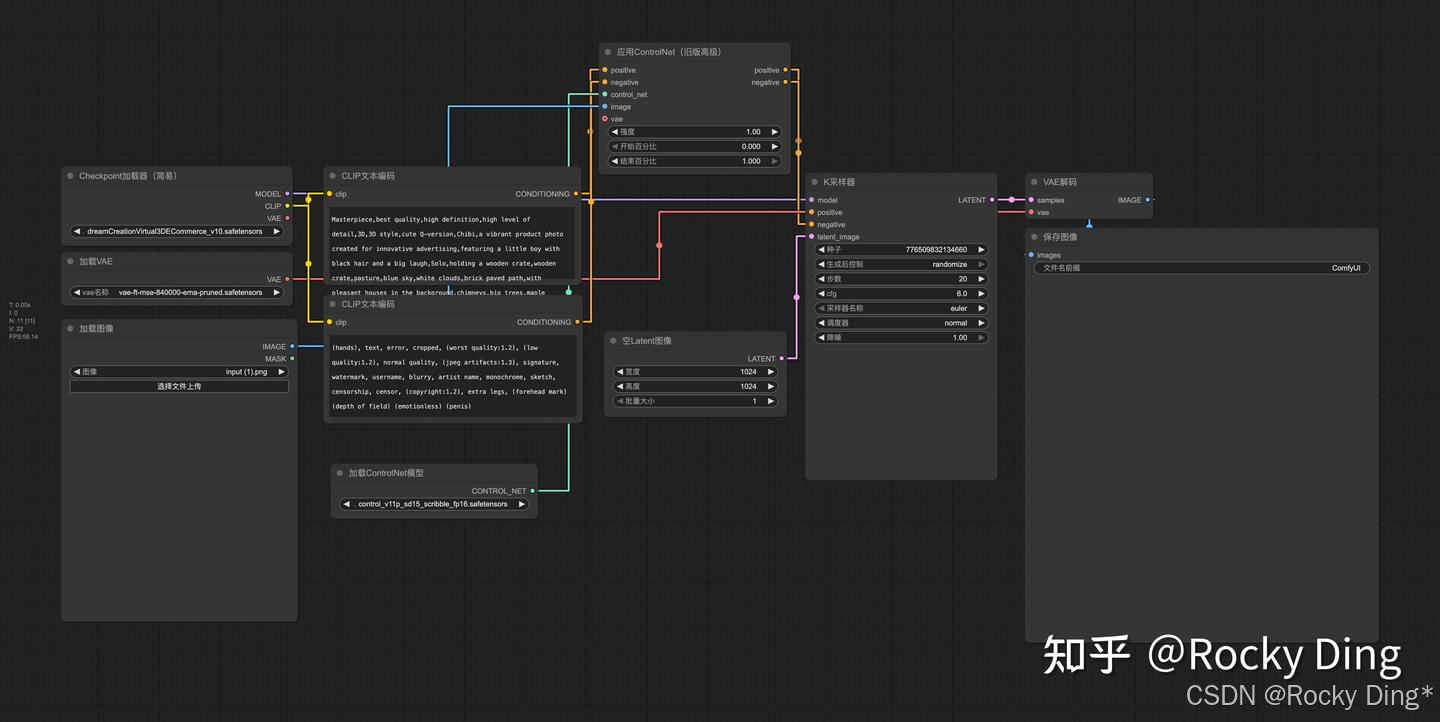
接着,我们那再看看SDXL Controlnet的ComfyUI推理运行工作流: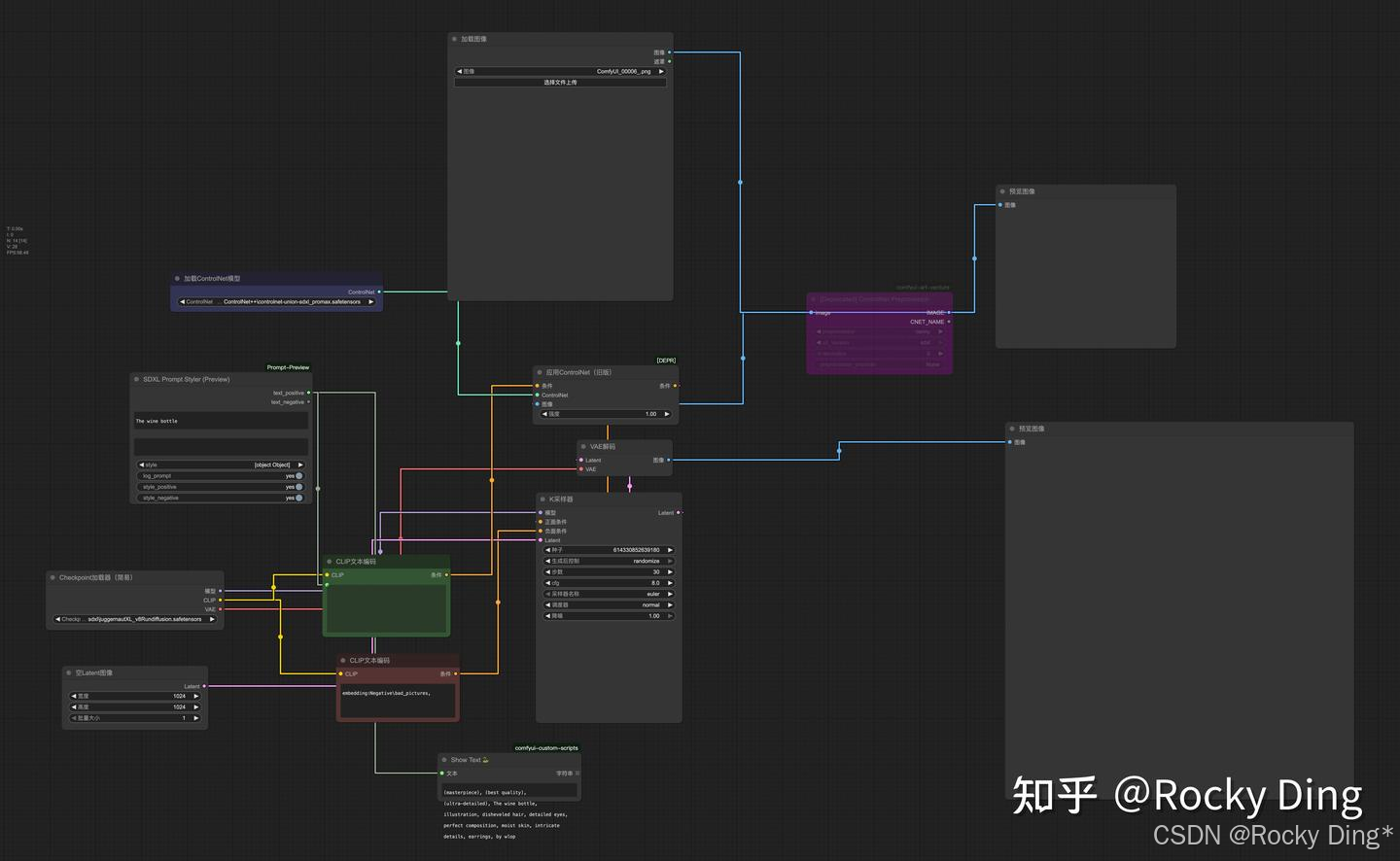
然后,我们再看看FLUX.1 ControlNet的ComfyUI推理运行工作流: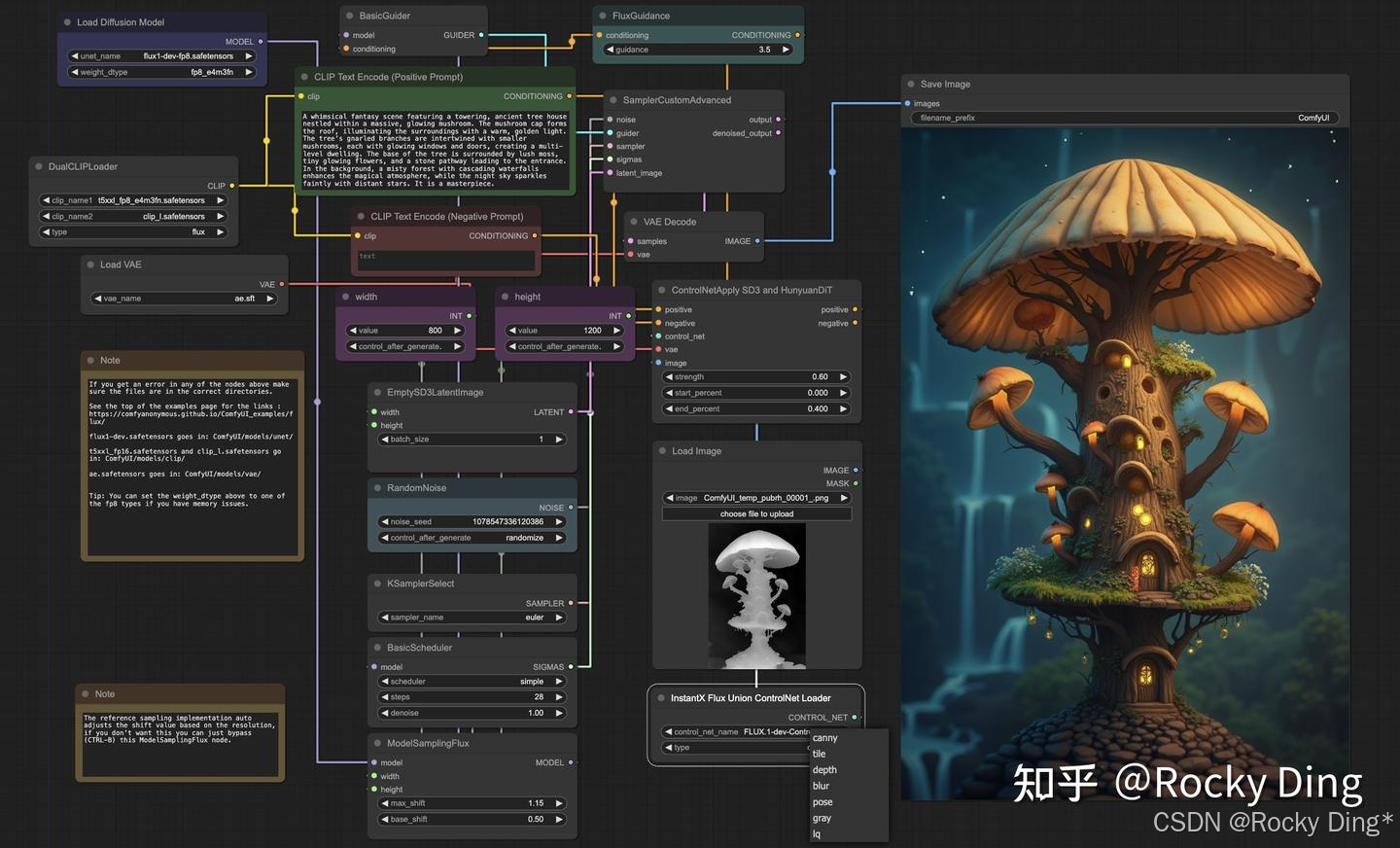
6.2 零基础使用Stable Diffusion WebUI搭建ControlNet推理流程(包含SD ControlNet、SDXL ControlNet)
首先,我们进入WebUI的extensions目录下,并在命令行输入一下命令即可安装ControlNet插件:
cd stable-diffusion-webui/extensions/
git clone https://github.com/Mikubill/sd-webui-controlnet.git
安装完毕后,重启WebUI即可看到ControlNet插件面板: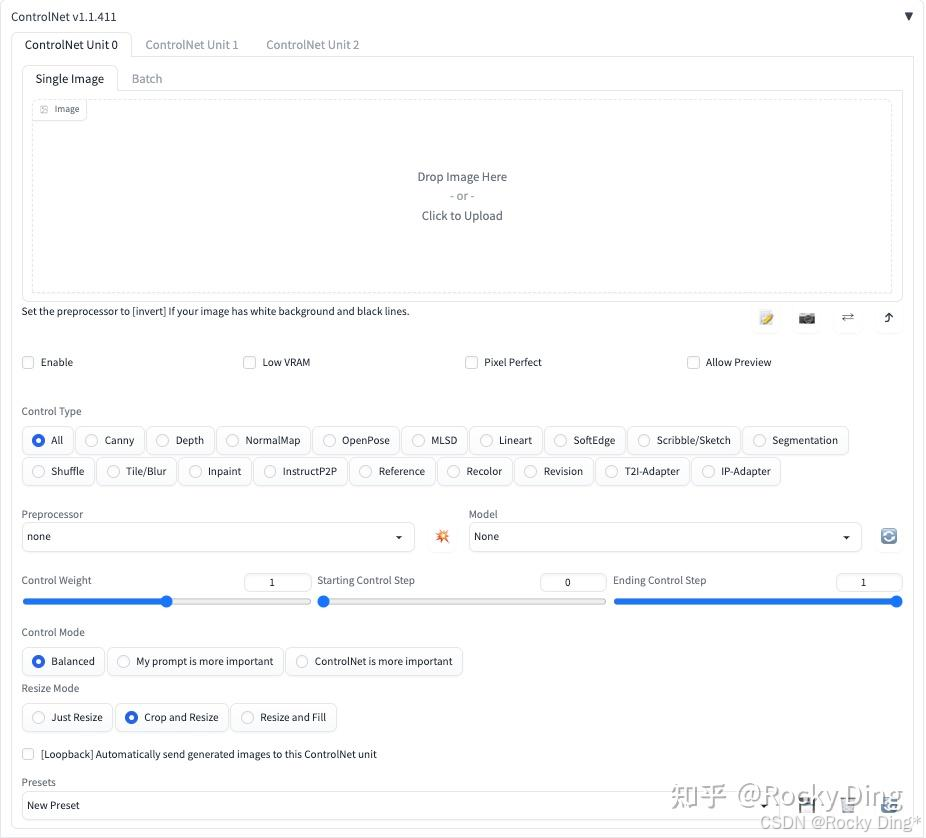
接下来Rocky为大家详细介绍ControlNet插件面板中各个参数的具体作用,大家可以点赞收藏本文,在使用时可以方便的找到:
ControlNet插件面板第一行中的ControlNet Unit 0-3表示默认设置为三个ControlNet选项界面,能够在Stable Diffusion生成过程中使用三个ControNet模型,可以手动增加或减少ControlNet选项界面。
ControlNet插件面板第二行有Single Image和Batch两个选项卡,表示使用一张图片或一个Batch的图片进行预处理,用于ControlNet过程。
Enable(启用): 点击选择Enable后,点击WebUI中的Generate按钮时,将会加载ControlNet模型辅助控制图像的生成过程。如果不点击选择Enable按钮不生效。
Low VRAM(低显存模式): 如果我们的显卡显存小于4GB,可以开启此选项降低生成图片时ControlNet的显存占用。
Pixel Perfect(完美像素模式): 开启完美像素模式之后,ControlNet 将自动计算选择预处理器分辨率,不再需要我们手动设置分辨率。通过自动进行这些调整,它可以保证最高的图像质量和清晰度。Rocky在这里打一个不太恰当的比喻,ControlNet的Pixel Perfect功能,就如同YOLOv5的自适应anchor一样,自动化为我们的参数调整免去了很多麻烦。
Allow Preview(预览展示模式): 启用后将会把图片经过Preprocessor预处理后的结果展示出来,比如图片的边缘信息,深度信息,关键点信息等。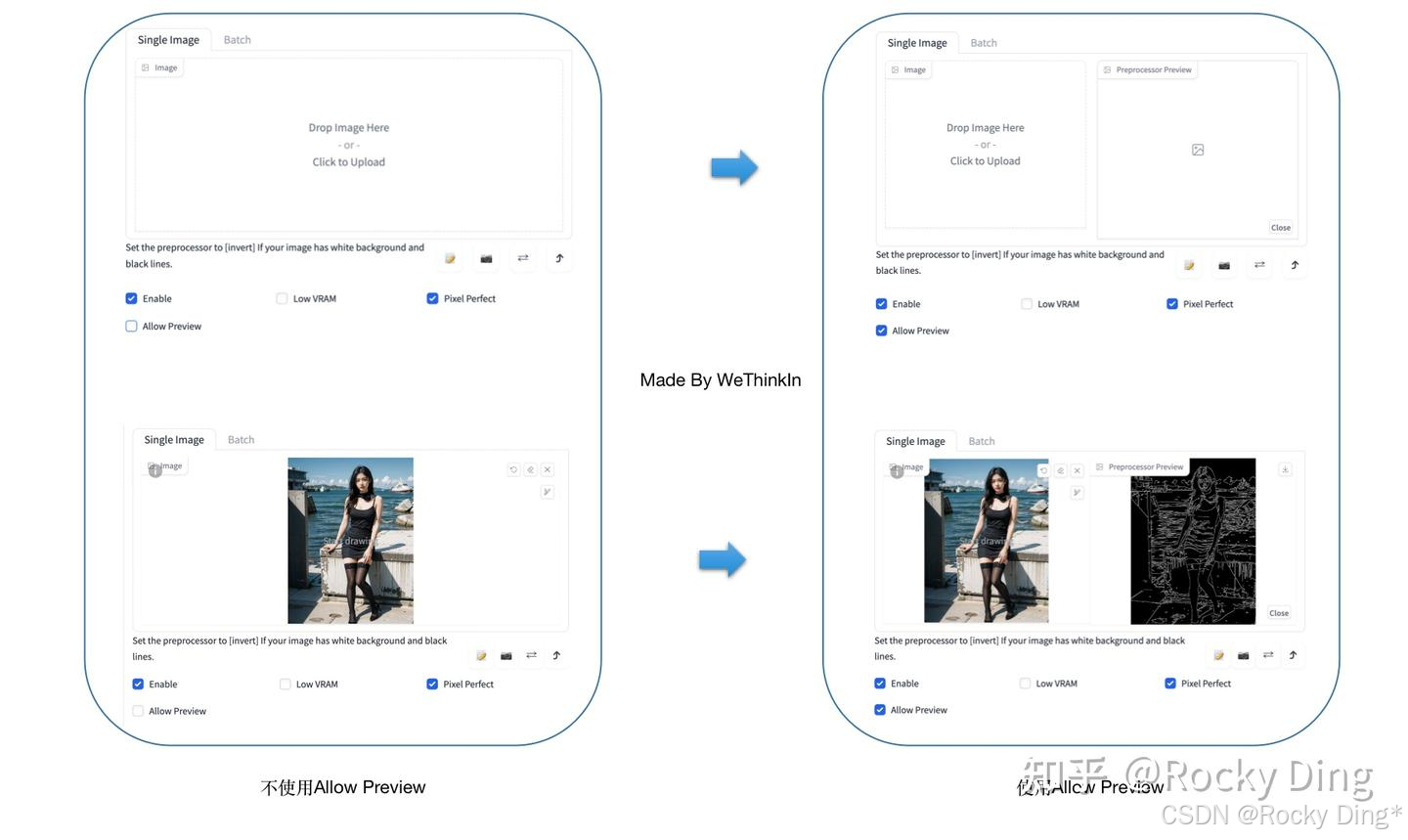
Control Type(控制类型): 一共有18种控制类型可以选择,选择一个Control Type后,Preprocessor和Model栏里也会限定只能选择与Control Type相匹配的算法和模型,非常方便。
Preprocessor(预处理器): 在Preprocessor栏里我们可以选择需要的预处理器,每个预处理器都有不同的功能。选择的预处理器会先将上传的图片进行预处理,例如Canny会提取图片的边缘特征信息。如果图片不需要进行预处理,设置Preprocessor为none即可。
Model(模型): Model栏里我们可以选择ControlNet模型,用于SD生成图片时进行控制。
Control Weight(ControlNet权重): 代表使用ControlNet模型辅助控制SD生成图片时的权重。
Starting Control Step(引导介入时机): 表示在图片生成过程中的哪一步开始使用ControlNet进行控制。如果设置为0,就表示从一开始就使用ControlNet控制图片的生成;如果设置为0.5就表示ControlNet从50%的步数时开始进行控制。
Ending Control Step(引导推出时机): 表示在图片生成过程中的哪一步结束ControlNet的控制。和引导介入时机相对应,如果设置为1,表示使用ControlNet进行控制直到完成图片的生成。Ending Control Step默认为1,可调节范围0-1,如果设置为0.8时表示到80%的步数时结束控制。
Control Mode(控制模式): 在使用ControlNet进行控制时,有三种控制模式可以选择,用于确定ControlNet于Prompt之间的配比。我们可以选择平衡二者 (Balanced),或是偏重我们的提示词 (My prompt is more important),亦或者是偏重ControlNet (ControlNet is more important)。
Rocky为大家详细讲解一下三种控制模式的原理:
- “Balanced”(平衡): ControlNet的能力在CFG Scale中均衡的使用,一般我们默认可以选择Balanced。
- “My prompt is more important”(我的提示更重要): ControlNet的能力在CFG Scale中使用,但逐渐减少在SD U-Net模型的注入(layer_weight *= 0.825 I 0.825^I 0.825I,其中0<=I<13,13表示ControlNet注入了SD 13次)。在这种情况下,提示词Prompt在图像的生成过程中占据更大的比重。
- “ControlNet is more important”(ControlNet更重要): ControlNet仅在CFG Scale的条件控制部分使用。这意味着如果我们设置的CFG Scale是X,那么ControlNet的控制强度将是X倍(如果我们设置CFG Scale为7,那么ControlNet的强度将是7倍)。需要注意的是,这里的X倍强度与“Control Weights”(控制权重)不同,因为ControlNet的权重没有被修改。这种“更强”的效果通常会产生较少的人工痕迹,并且给ControlNet更多空间去猜测我们的提示词中缺少的内容(在之前的版本,这个模式被称为"Guess Mode")。
下图是是三种控制模式的效果对比:
Resize Mode(缩放模式): 用于调整图像大小模式,一共三个选项:Just Resize,Crop and Resize和Resize and Fill。
我们拿512x500的图像为例,使用三个缩放模式生成一个 1024x1024的图像,看看主要经过了哪些过程:
Just Resize: 不考虑宽高比,直接将图像拉伸成1024x1024分辨率。
Crop and Resize: 考虑宽高比,先将图片裁剪至 500x500,然后缩放至1024x1024分辨率,会造成左右两侧的一些数据丢失。
Resize and Fill: 通过添加噪声的方式将图像填充至512x512,然后缩放到1024x1024分辨率。
Loopbac按钮: [Loopback] Automatically send generated images to this ControlNet unit。点击开启后,在视频生成等持续性生成过程中,每一帧的结果都会进行ControlNet控制。
Presets: 用于保存已经配置好的ControlNet参数,以便后续快速加载相关参数。
6.3 零基础使用diffusers搭建ControlNet推理流程(包含SD ControlNet、SDXL ControlNet、FLUX.1 ControlNet)
Diffusers框架原生支持ControlNet各个版本的推理应用,大家可以方便的进行构建。
首先是SD ControlNet的推理流程:
from transformers import pipeline
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from PIL import Image
import numpy as np
import torch
from diffusers.utils import load_image
depth_estimator = pipeline('depth-estimation')
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-depth/resolve/main/images/stormtrooper.png")
image = depth_estimator(image)['depth']
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained(
"本地路径/sd-controlnet-depth", torch_dtype=torch.float16
)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"本地路径/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
image = pipe("Stormtrooper's lecture", image, num_inference_steps=20).images[0]
image.save('./images/stormtrooper_depth_out.png')
接着是SDXL ControlNet的推理流程:
from diffusers import ControlNetModel, StableDiffusionXLControlNetPipeline, AutoencoderKL
from diffusers.utils import load_image
from PIL import Image
import torch
import numpy as np
import cv2
prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
negative_prompt = 'low quality, bad quality, sketches'
image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png")
controlnet_conditioning_scale = 0.5 # recommended for good generalization
controlnet = ControlNetModel.from_pretrained(
"本地路径/controlnet-canny-sdxl-1.0",
torch_dtype=torch.float16
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"本地路径/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
torch_dtype=torch.float16,
)
pipe.enable_model_cpu_offload()
image = np.array(image)
image = cv2.Canny(image, 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
image = Image.fromarray(image)
images = pipe(
prompt, negative_prompt=negative_prompt, image=image, controlnet_conditioning_scale=controlnet_conditioning_scale,
).images
images[0].save(f"hug_lab.png")
然后是FLUX.1 ControlNet的推理流程:
import torch
from diffusers.utils import load_image
from diffusers.pipelines.flux.pipeline_flux_controlnet import FluxControlNetPipeline
from diffusers.models.controlnet_flux import FluxControlNetModel
base_model = '本地路径/FLUX.1-dev'
controlnet_model = '本地路径/FLUX.1-dev-Controlnet-Canny' # "Shakker-Labs/FLUX.1-dev-ControlNet-Depth"
controlnet = FluxControlNetModel.from_pretrained(controlnet_model, torch_dtype=torch.bfloat16)
pipe = FluxControlNetPipeline.from_pretrained(base_model, controlnet=controlnet, torch_dtype=torch.bfloat16)
pipe.to("cuda")
control_image = load_image("https://huggingface.co/InstantX/FLUX.1-dev-Controlnet-Canny/resolve/main/canny.jpg")
# control_image = load_image("https://huggingface.co/Shakker-Labs/FLUX.1-dev-ControlNet-Depth/resolve/main/assets/cond1.png")
prompt = "A girl in city, 25 years old, cool, futuristic"
image = pipe(
prompt,
control_image=control_image,
controlnet_conditioning_scale=0.6,
num_inference_steps=28,
guidance_scale=3.5,
).images[0]
image.save("image.jpg")
7. 深入浅出完整解析不同控制条件的ControlNet使用原理(全网最详细讲解)
目前ControlNet有18种Control Type,分别是Canny,Depth,NormalMap,OpenPose,MLSD,Lineart,SoftEdge,Scribble/Sketch,Segmentation,Shuffle,Tile/Blur,Inpaint,InstructP2P,Reference,Recolor,Revision,T2I-Adapter,IP-Adapter。
从上面的Control type可以看出,ControlNet无疑引领了CV领域的“文艺复兴”,很多传统图像处理时代的算子和Low-Level算法(Canny,Depth,SoftEdge等)在AIGC时代中再次展现它们的能量。
下面,Rocky将为大家讲解如何使用不同控制条件的ControlNet模型,并且详细讲解18种Control type的用法。
7.1 Canny ControlNet使用详解
Canny边缘检测算法能够检测出输入的条件图片中各对象的边缘轮廓特征,提取生成线稿图,作为SD/FLUX模型生成时的条件特征。
接着再设置提示词,让SD/FLUX模型生成构图相同但是内容不同的新图像,也可以用来给线稿图重新上色。
Canny算法中一共有2种Preprocessor,分别是Canny和invert (from white bg & black line)。
如果输入的图像具有白色背景和黑色线条,我们可以使用invert,其效果如下图所示: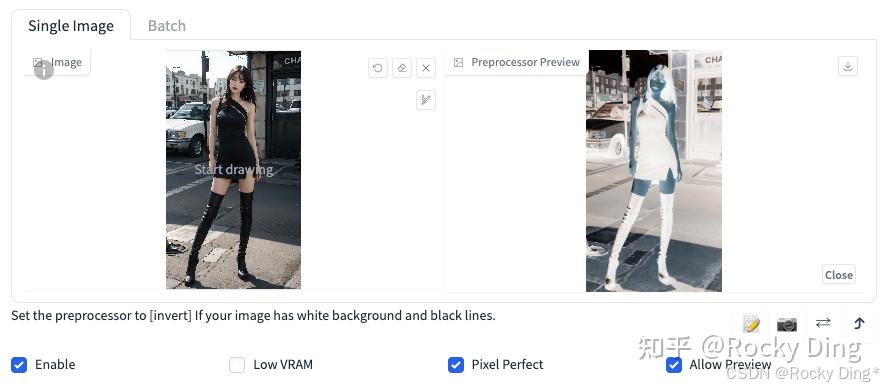
下面是ControlNet Canny的具体控制生成效果:
7.2 Depth ControlNet使用详解
Depth算法通过提取输入的条件图片中的深度信息,能够生成和原图一样深度结构的深度图。其中图片颜色越浅(白)的区域,代表距离镜头越近;越是偏深色(黑)的区域,则代表距离镜头越远。
Depth算法一共有五种预处理器,分别是depth_leres,depth_leres++,depth_midas、depth_zoe和depth_anything。
这五种预处理器的效果分别如下所示:
(1)depth_leres预处理器效果
depth_leres预处理器的成像焦点在中间景深层,这样的好处是能有更远的景深,且中距离物品边缘成像会更清晰,但近景图像的边缘会比较模糊。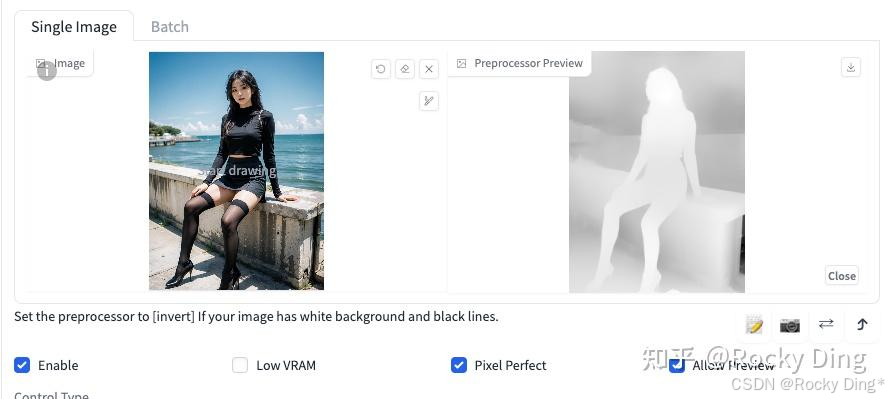
(2)depth_leres++预处理效果
depth_leres++预处理器在depth_leres预处理器的基础上做了优化,能够有更多的细节。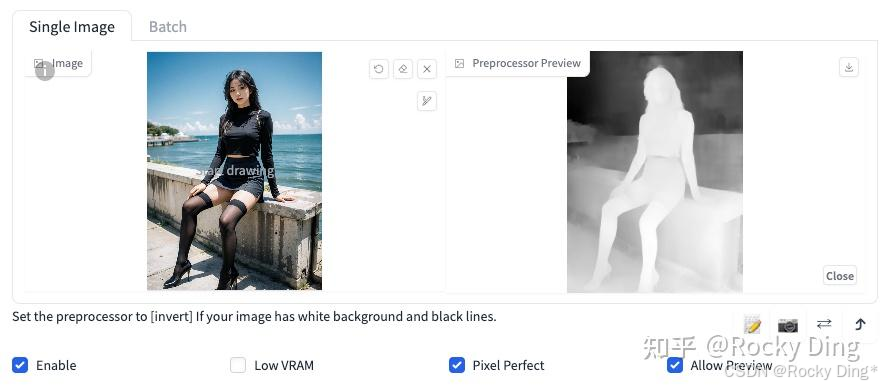
(3)depth_midas预处理效果
depth_midas预处理器是经典的深度估计器,也是最常用的深度估计器。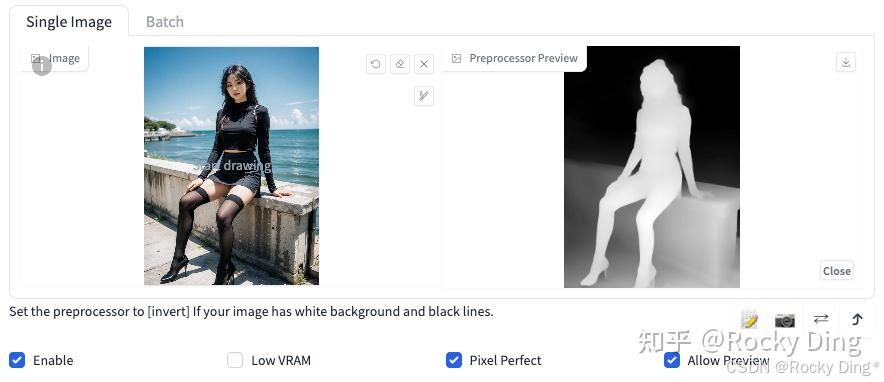
(4)depth_zoe预处理效果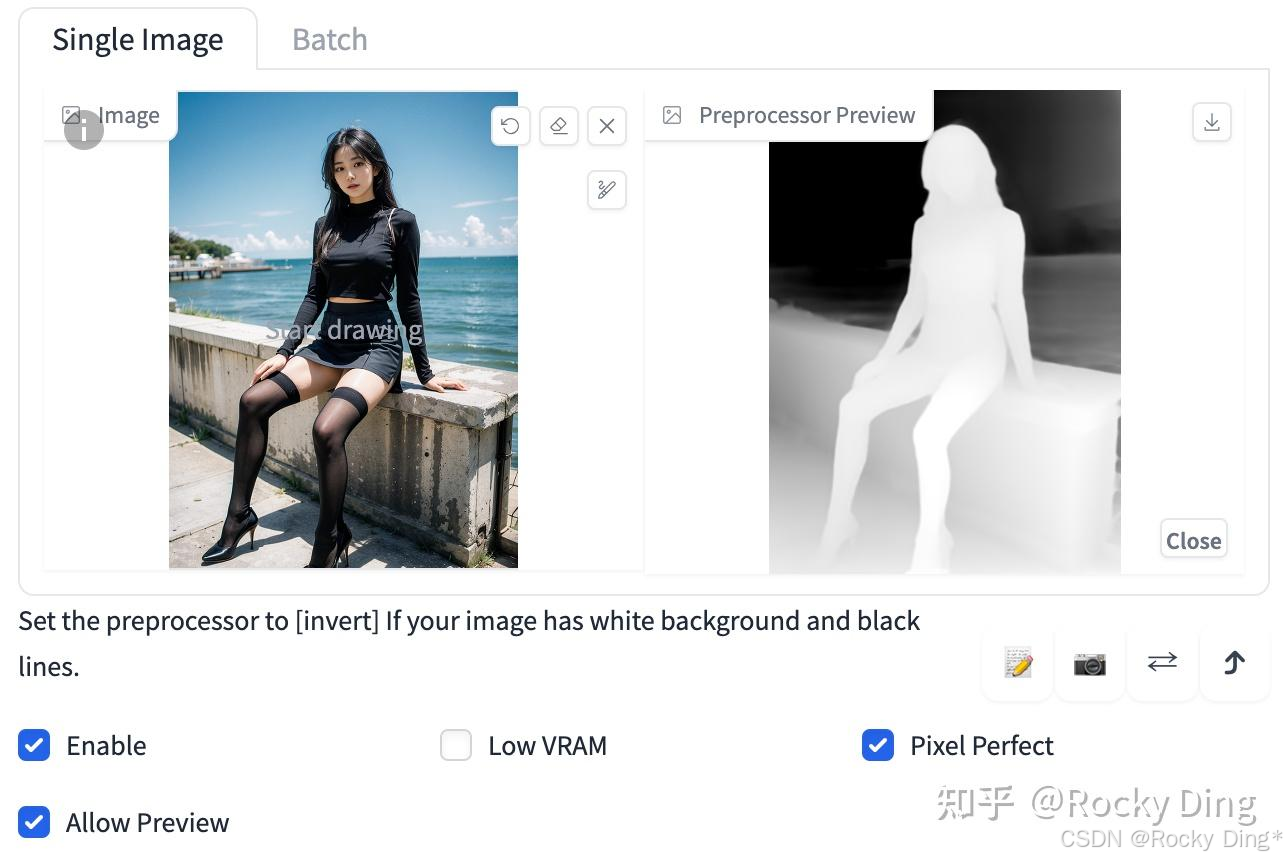
(5)depth_anything预处理器效果
7.3 NormalMap ControlNet使用详解
NormalMap算法根据输入图片生成一张记录凹凸纹理信息的法线贴图,通过提取输入图片中的3D法线向量,并以法线为参考重新生成一张新图,同时给图片内容进行更好的光影处理。法线向量图指定了一个表面的方向,在ControlNet中,它是一张指定每个像素所在表面方向的图像,法线向量图像素代表的不是颜色值,而是表面的朝向。
NormalMap算法的用法与Depth算法类似,都是用于传递参考图像的三维结构特征。
NormalMap算法与Depth算法相比在保持几何形状方面有更好的效果,在深度图中很多细微细节并不突出,但在法线图中则比较明显。
法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果,非常适合CG建模师使用。
NormalMap算法一共有两种预处理器,分别是normal_bae预处理器和normal_midas预处理器,具体效果如下所示:
(1)normal_midas预处理效果
Normal_Midas预处理方法是经典的预处理方法,在NormalMap算法中指的是从Midas方法获得的深度贴图估计法线贴图的过程。法线贴图详细说明了表面的方向,对于ControlNet来说,它决定了图像中每个像素所代表的表面的方向。虽然Midas主要用于深度估计,在ControlNet中,它被用来推导法线贴图,Midas法线图擅长将主体从背景中分离出来。
(2)normal_bae预处理效果
Normal_Bae预处理器用于估计法线贴图,重点是解决了aleatoric不确定性问题,对图像的背景和前景都进行细节的渲染,这样能够较好完善法线贴图中的细节内容,建议默认使用这个预处理器。
NormalMap ControlNet模型的控制生成效果如下所示:
7.4 OpenPose ControlNet使用详解
OpenPose算法包含了实时的人体关键点检测模型,通过姿势识别,能够提取人体姿态,如人脸、手、腿和身体等位置关键点信息,从而达到精准人体动作控制。除了生成单人的姿势,它还可以生成多人的姿势,此外还有手部骨骼模型,解决手部绘图不精准问题。
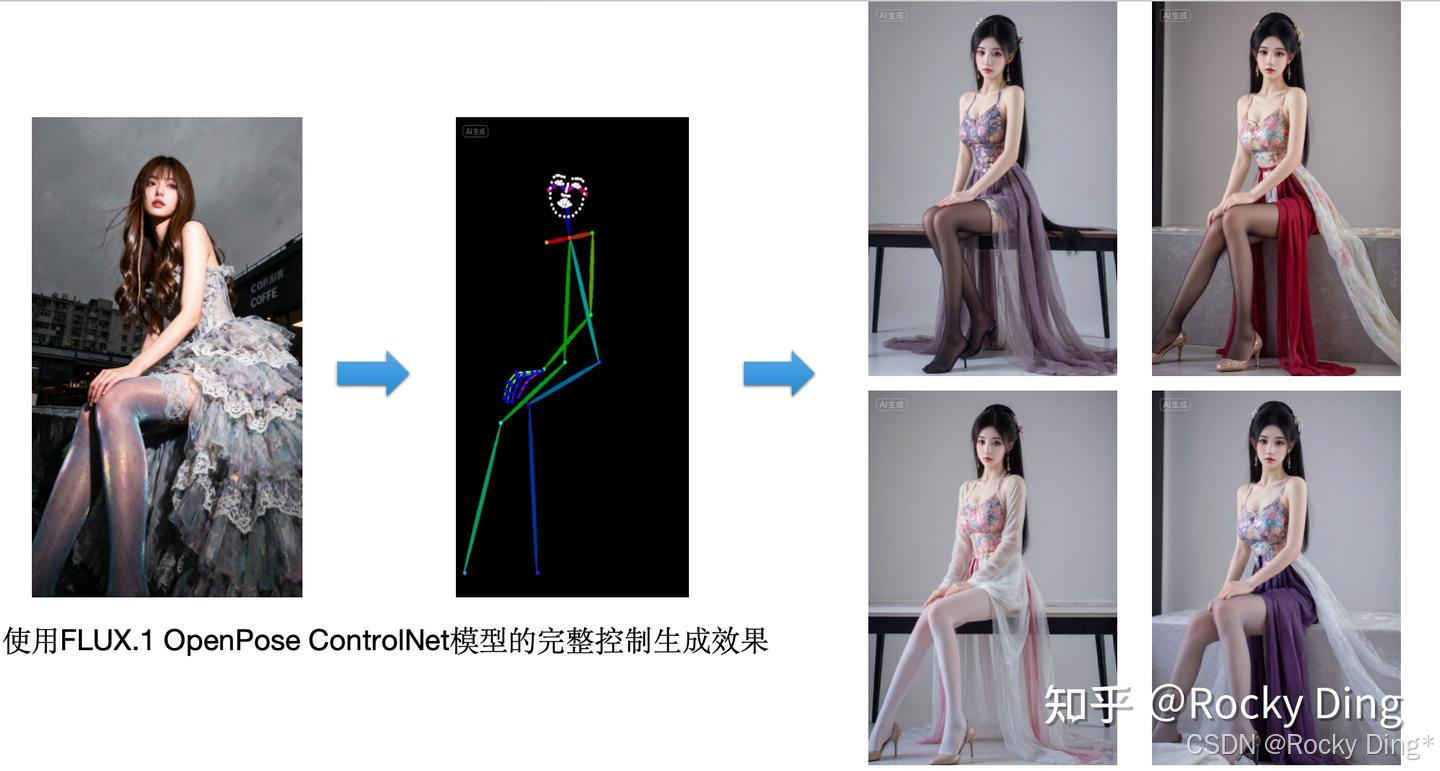
如下图所示,我们输入条件图像和Prompt,通过OpenPose算法精准识别后,得到骨骼姿势图,再用SD/FLUX模型的文生图功能,通过Prompt描述主体内容、场景细节和画风后,就能得到一张同样姿势,但风格完全不同的人物图片: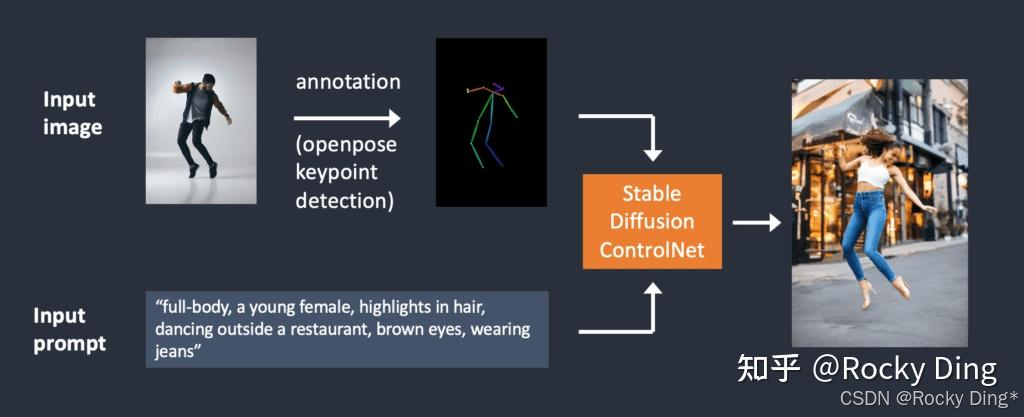
OpenPose算法一共有六种预处理器,分别是OpenPose,OpenPose_face,OpenPose_faceonly,OpenPose_full,openpose_hand,dw_openpose_full。
每种OpenPose预处理器的具体效果如下:
(1)OpenPose预处理器效果
OpenPose预处理器是OpenPose算法中最基础的预处理器,能够识别图像中人物的整体骨架(眼睛、鼻子、眼睛、脖子、肩膀、肘部、腕部、膝盖和脚踝等),效果如下图所示: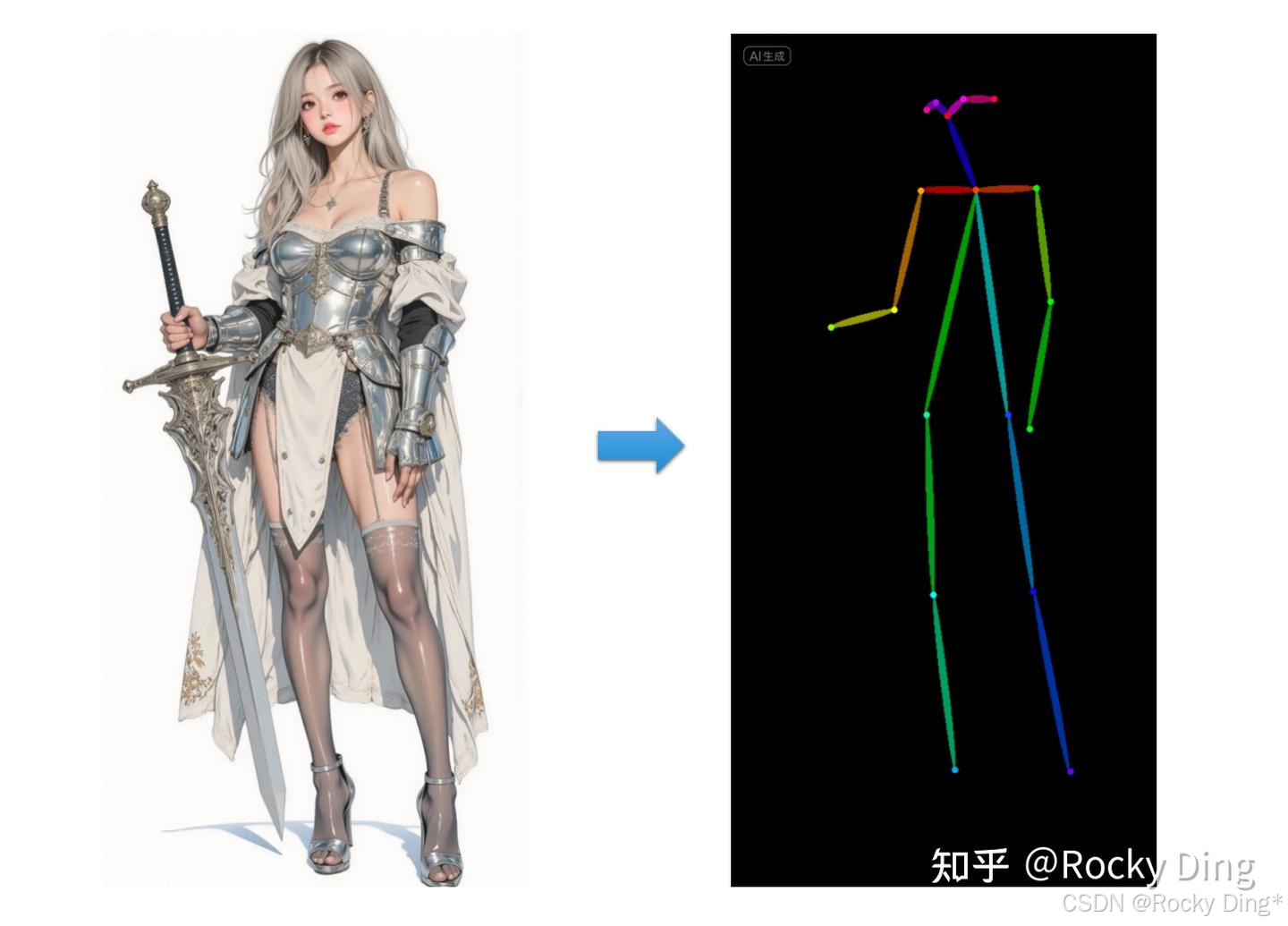
(2)OpenPose_face预处理器效果
OpenPose_face预处理器是在OpenPose预处理器的基础上增加脸部关键点的检测与识别,效果如下所示:
(3)OpenPose_faceonly预处理器效果
OpenPose_faceonly预处理器仅检测脸部的关键点信息,如果我们想要固定脸部,改变其他部位的特征的话,可以使用此预处理器,效果如下图所示:
(4)OpenPose_full预处理器效果
openpose_full预处理器能够识别图像中人物的整体骨架+脸部关键点+手部关键点,是一个非常全面的预处理器,其效果如下所示: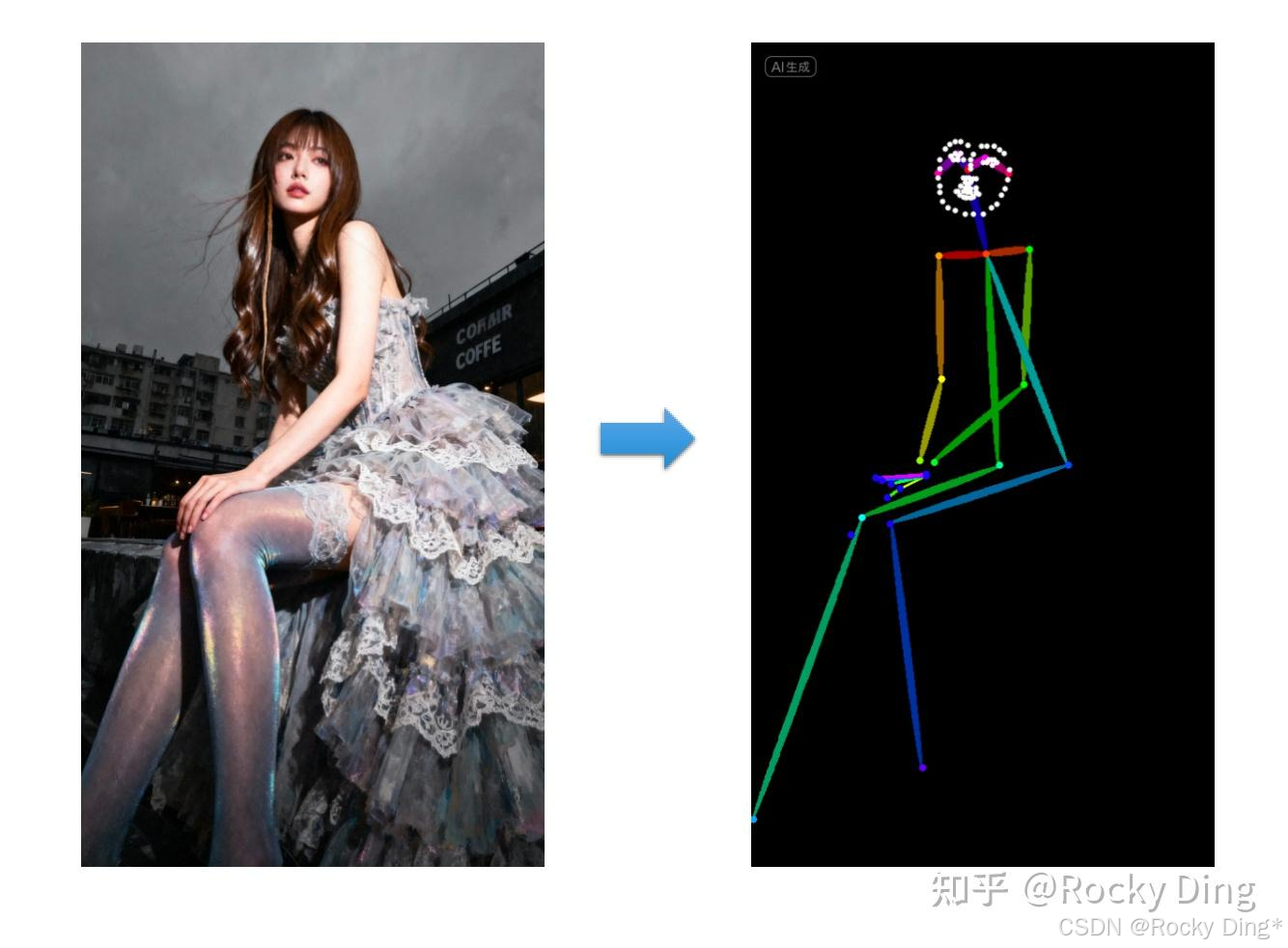
(5)openpose_hand预处理器效果
openpose_hand预处理器能够识别图像中人物的整体骨架+手部关键点,效果如下所示: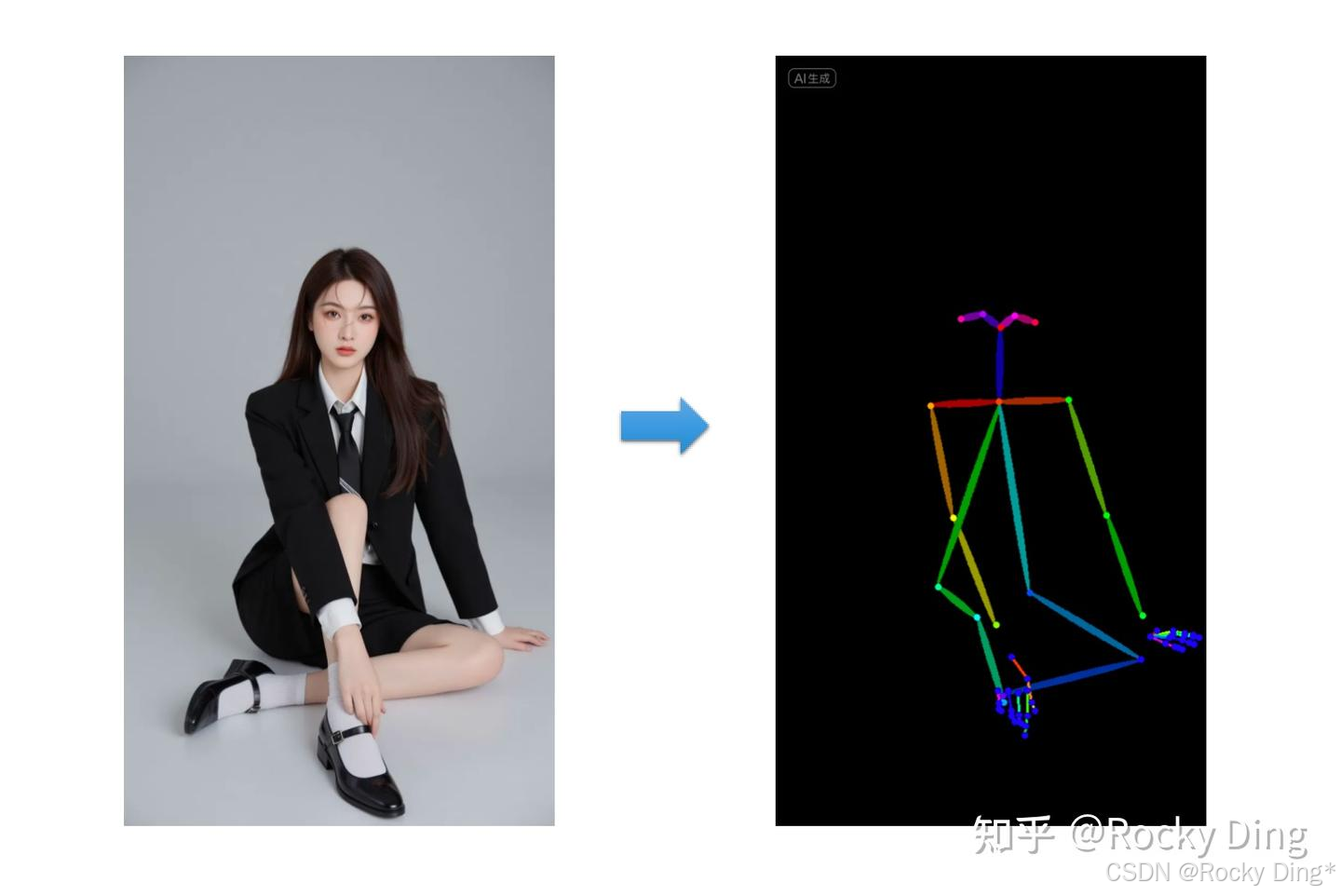
(6)dw_openpose_full预处理器效果
dw_openpose_full预处理器是目前OpenPose算法中最强的预处理器,是OpenPose_full预处理器的增强版,使用了传统深度学习中的王牌检测模型yolox_l作为人体关键点的检测base模型,其不但能够人物的整体骨架+脸部关键点+手部关键点,而且精细程度也比openpose_full预处理器更好,其效果如下图所示: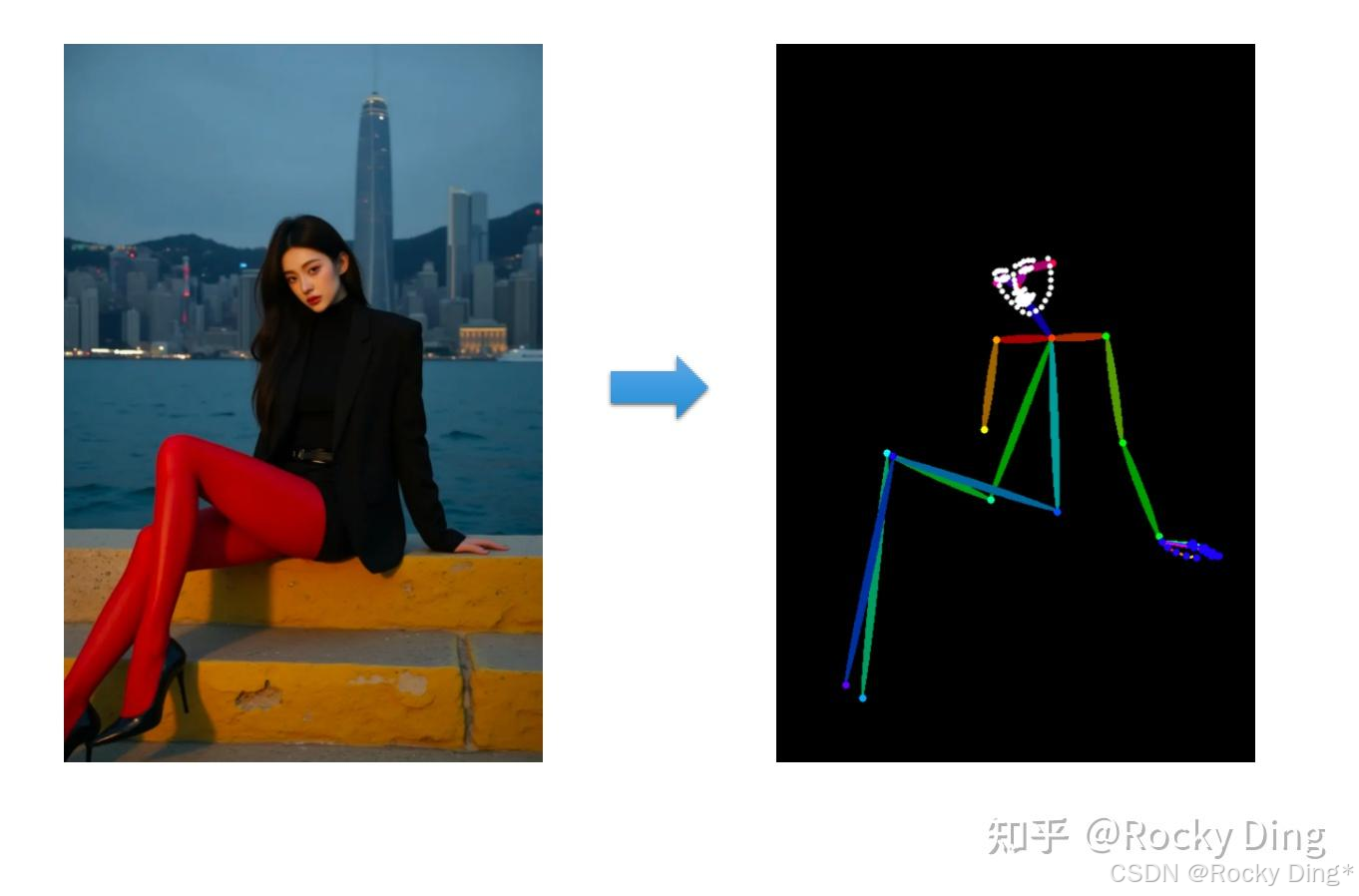
dw_openpose_full预处理器中使用的DWPose模型 + ControlNet OpenPose模型的效果如下,能够达到实时视频生成的能力:
ControlNet OpenPose算法使用效果:
7.5 MLSD ControlNet使用详解
MLSD是一种线条检测算法,通过分析图片的线条结构和几何形状来构建出建筑外框(直线),它对于提取具有直边的轮廓非常有用,例如室内设计、建筑物、街景、相框和纸张边缘,但是对人或其它有弧度的物体边缘提取效果很差。
如果我们想要对室内、建筑等输入图片进行重构,原图环境中有人物出现,但是新生成的图片中不希望有人物,那么使用MLSD算法就可以很好的避开人物线条的检测,从而能够生成纯建筑的新图片。
总的来说,ControlNet MLSD算法非常适合用于室内设计、建筑设计等场景。
(1)mlsd预处理效果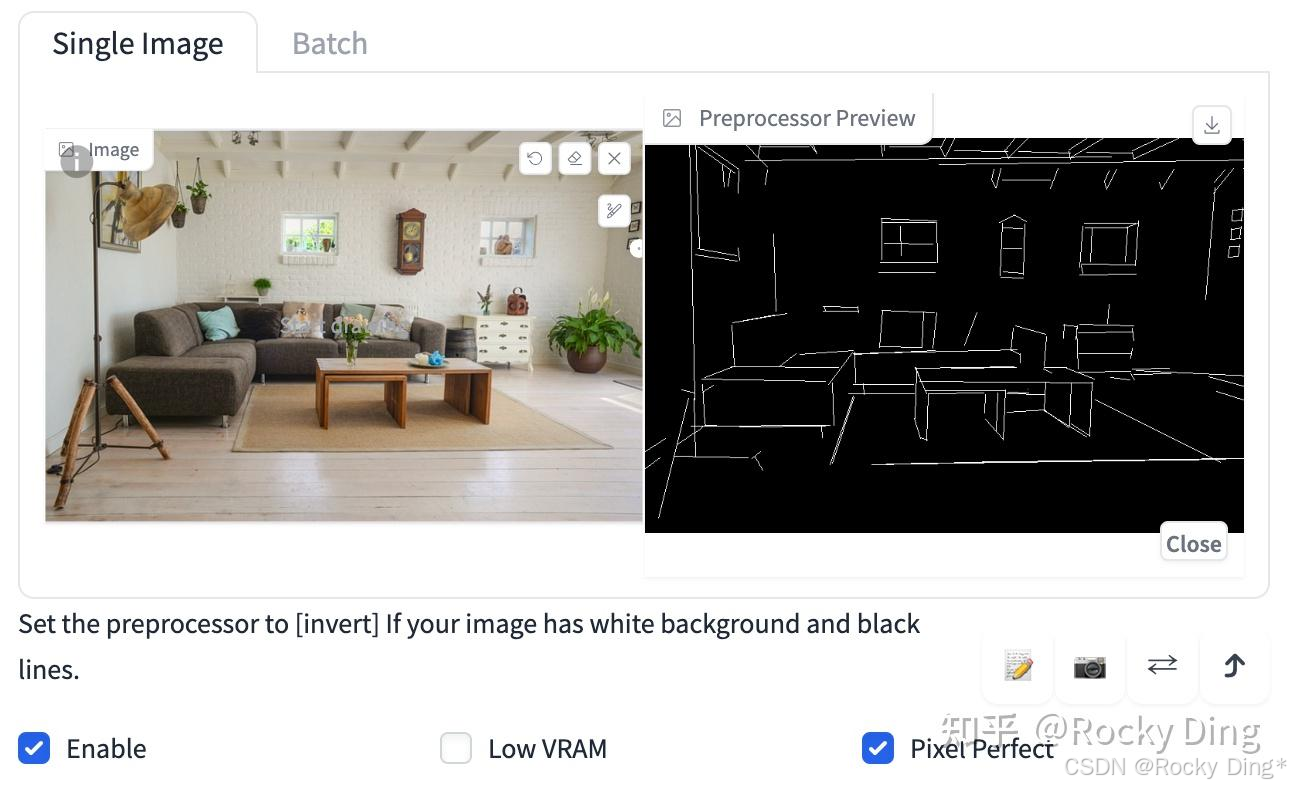
(2)mlsd_invert预处理效果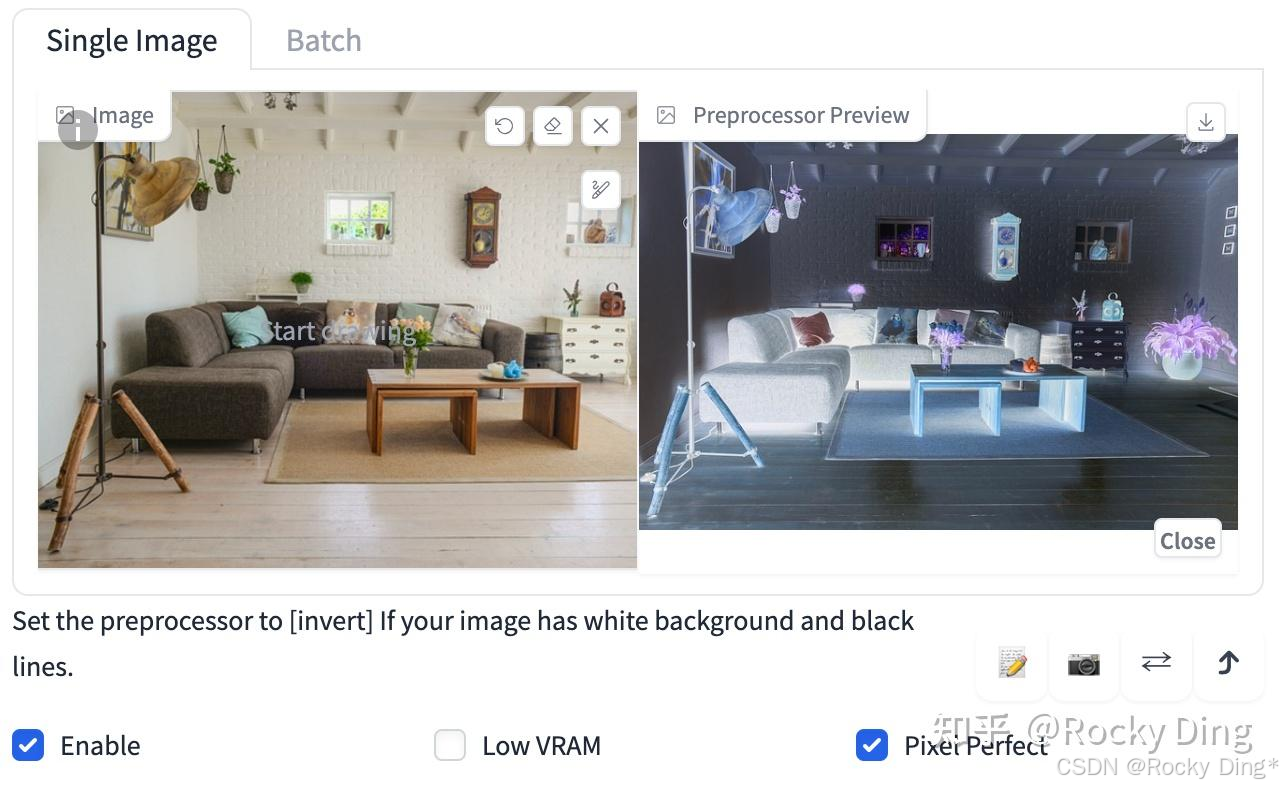
目前ControlNet官方发布的MLSD模型一共有两个,分别是control_sd15_mlsd模型和control_v11p_sd15_mlsd模型,下面我们看看用control_v11p_sd15_mlsd模型+二次元SD模型和真实场景SD模型的控制生成效果:
7.6 Lineart ControlNet使用详解
ControlNet Lineart算法(线稿模型)与Canny算法大同小异,可以检测出输入图像中的线稿信息。
Lineart算法一共有五种预处理器,分别是lineart_anime预处理器、lineart_anime_denoise预处理器、lineart_coarse预处理器、lineart_realistic预处理器和lineart_standard预处理器。
下面是Lineart算法各预处理器的具体效果:
- Lineart_anime预处理器: 用于生成动漫风格的线稿/素描信息。
- Lineart_anime_denoise预处理器: Lineart_anime预处理器的优化版,在提取动漫风格线稿/素描信息的同时进行降噪处理。
- Lineart_coarse预处理器: 用于生成粗糙线稿/素描,线条相比较于其它预处理器,的确更粗一些,效果也很不错,生成的图像则趋于真实。
- Lineart_realistic预处理器: 能较好地提取人物线稿部分。
- Lineart_standard(from white bg&black line)预处理器: 是一种特殊模式,将白色背景和黑色线条的图像转换为线稿或素描,能较好的还原场景中的线条,跟原图较为相似。
(1)lineart_anime预处理效果-动漫线稿提取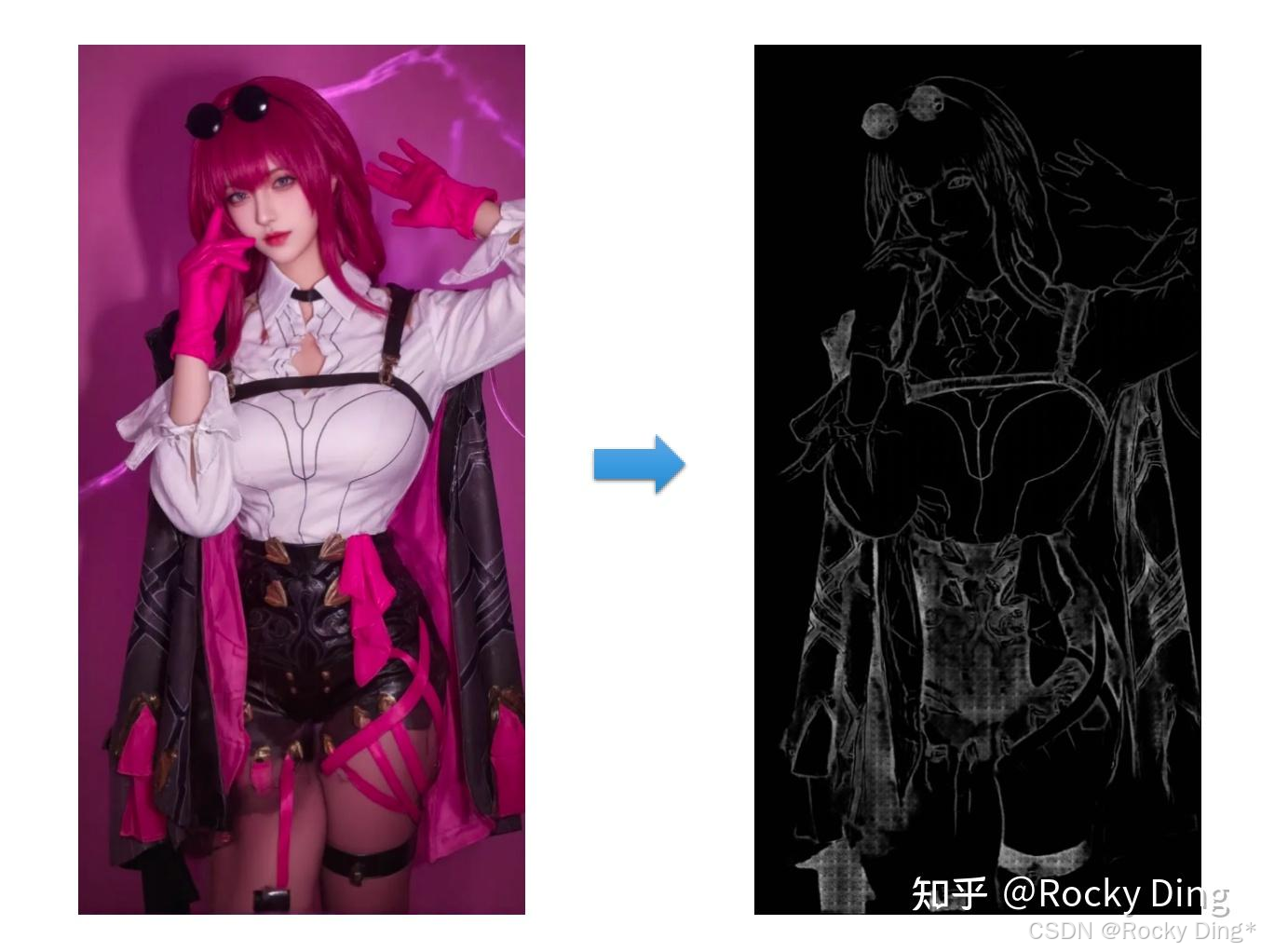
(2)lineart_anime_denoise预处理效果-动漫线稿提取和去噪
(3)lineart_coarse预处理效果-粗略线稿提取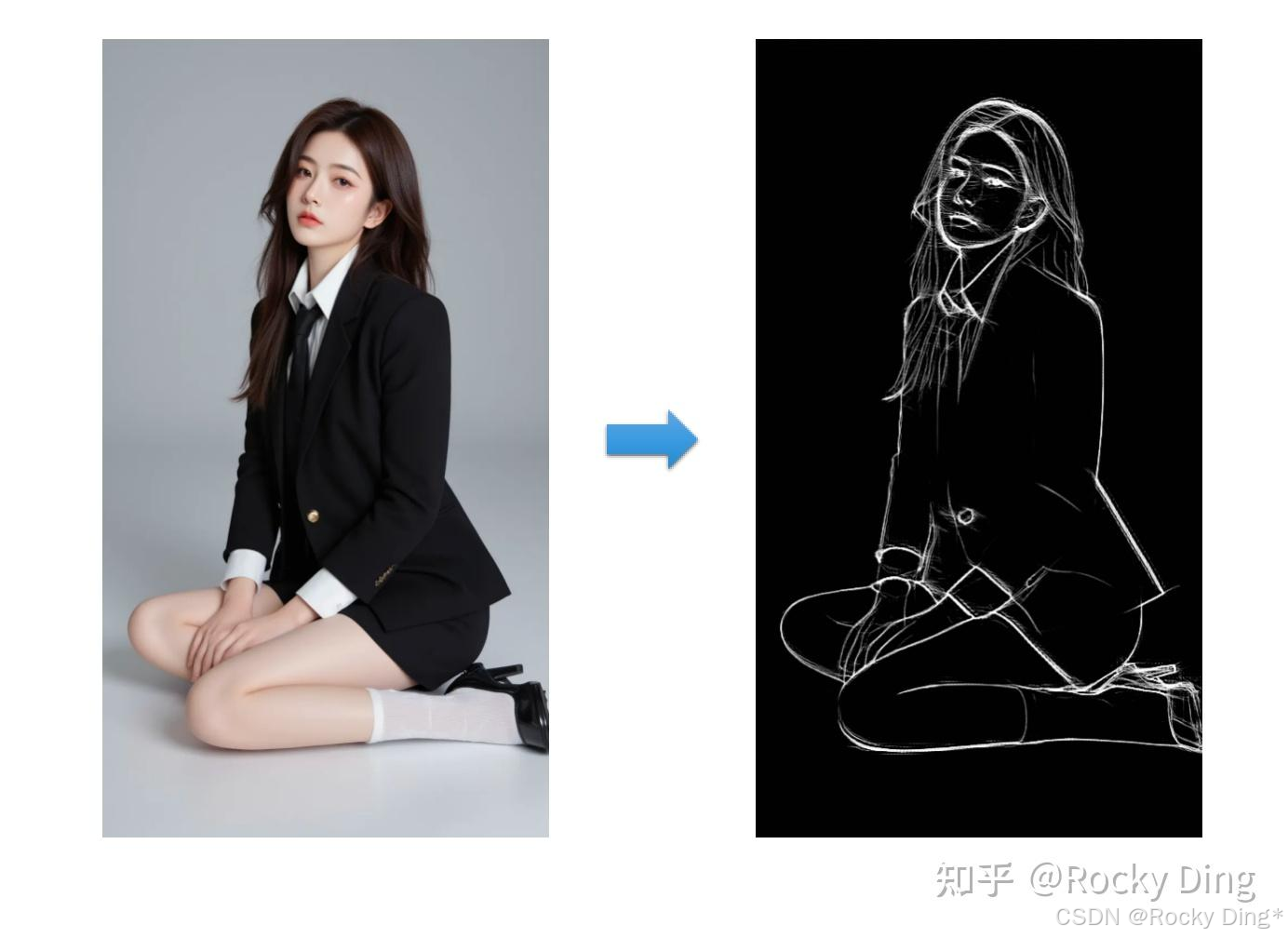
(4)lineart_realistic预处理效果-写实线稿提取
(5)lineart_standard 预处理效果-标准线稿提取
(6)lineart_invert预处理效果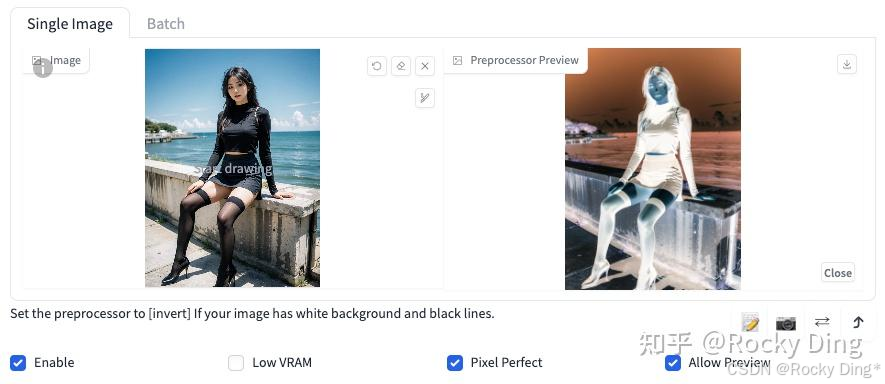
7.7 SoftEdge ControlNet使用详解
ControlNet SoftEdge算法的主要作用是检测图像的软边缘轮廓,与Canny算法相比检测出的边缘轮廓没有那么细致和严格,相对比较宽松和柔性,让我们在AIGC图像生成/AI绘画过程中有更大的灵活性与更多的创意空间。在传统图像处理领域,图像边缘指的是图像中颜色或亮度变化显著的地方,对应着物体与背景之间、或者物体与物体之间的交界。通过检测出图像边缘信息,我们可以提取出图像中的形状、纹理、结构等重要信息,进一步用于AIGC图像生成/AI绘画、传统深度学习、自动驾驶等领域的后续任务。
SoftEdge算法一共有四种Preprocessor,分别是softedge_hed预处理器、softedge_hedsafe预处理器、softedge_pidinet预处理器以及softedge_pidinetsafe预处理器,其中带有“safe”字样的表示精简版。
softedge_hed预处理器跟Canny算法类似,也是一种边缘检测算法,可以把Canny算法理解为用铅笔提取边缘,而softedge_hed预处理器则是换用毛笔,被提取的图像边缘将会非常柔和,细节也会更加丰富,绘制的人物明暗对比明显,轮廓感更强,适合在保持原来构图的基础上重新着色和对画面风格进行改变。
如果是生成棱角分明或者机甲一类的图像,推荐使用Canny预处理器及其模型。如果是想要生成人物和动物等图像,那么使用softedge_hed预处理器效果会更好。
同样的,softedge_pidinet预处理器也是一种边缘检测算法,比起softedge_hed预处理器,它的泛化性与鲁棒性更强。
下面是基于softedge_hed预处理器的图像控制生成过程:
(1)softedge_hed预处理效果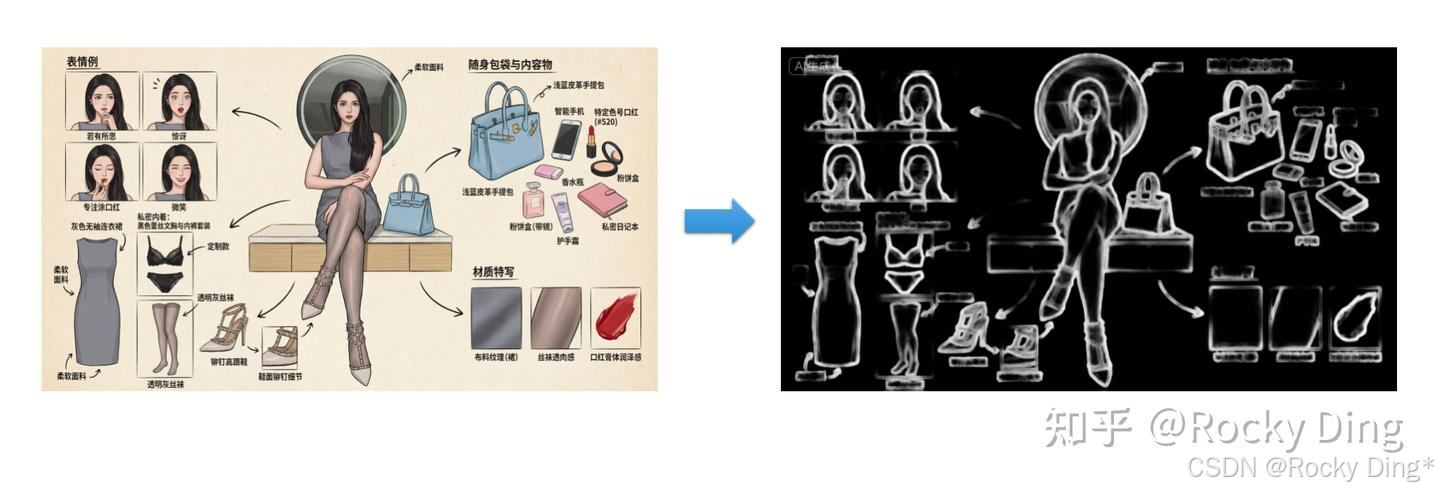
(2)softedge_hedsafe预处理效果
(3)softedge_pidinet预处理效果
(4)softedge_pidisafe预处理效果
总的来说,SoftEdge算法的所有预处理器的性能表现如下所示:
鲁棒性: SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
最好效果上限: SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
一般情况下,我们默认使用 SoftEdge_PIDI,大多数情况下它的效果都很好。
7.8 Scribble/Sketch ControlNet使用详解
Scribble/Sketch算法能够提取图片中曝光对比度比较明显的区域,生成黑白稿,涂鸦成图,其比Canny算法的自由度更高,也可以用于对手绘线稿进行着色处理。
从下图可以看到提取的涂鸦,不但保留了曝光度对比较大的部分,而且细节保留的也很不错。细节保留的越多,那么SD重新生成图片时所能更改的部分就越少。
当然的,我们也可以直接上传涂鸦,然后通过Scribble/Sketch算法进行补充绘图。
ControlNet Scribble/Sketch算法一共有四种预处理器,分别是:scribble_hed预处理器、scribble_pidinet预处理器、scribble_xdog预处理器以及t2ia_sketch_pidi预处理器。
-
scribble_hed预处理器: 由Holistically-Nested Edge Detection(HED) 边缘检测器构成,擅长生成像真人一样的轮廓,能够配合SD系列模型进行图像进行重新着色和重新设计样式等任务。
-
scribble_pidinet预处理器: 由Pixel Difference network(Pidinet) 网络构成,能够检测图像中曲线和直线边缘等特征。其结果与scribble_hed预处理器类似,但通常会产生更清晰的线条和更少的细节。
-
scribble_xdog预处理器: 由EXtendedDifferenceofGaussian(XDoG)技术构成,同样是一种图像边缘检测算法。与其他预处理器不同的是,scribble_xdog预处理器附带一个XDoG Threshold参数可供我们调整阈值,这让我们的控制效果更佳精细化。
-
t2ia_sketch_pidi预处理器: t2ia_sketch_pidi预处理器在处理涂鸦图像时考虑一些特定的因素,例如涂鸦的形状、颜色、纹理等,以帮助算法更好地理解和利用图像中的信息。
接下来我们再看看各个预处理器的效果,具体如下所示:
(1)scribble_hed预处理效果
(2)scribble_pidinet预处理效果
(3)scribble_xdog预处理效果
(4)t2ia_sketch_pidi预处理效果
下面是Scribble/Sketch ControlNet模型的控制生成效果: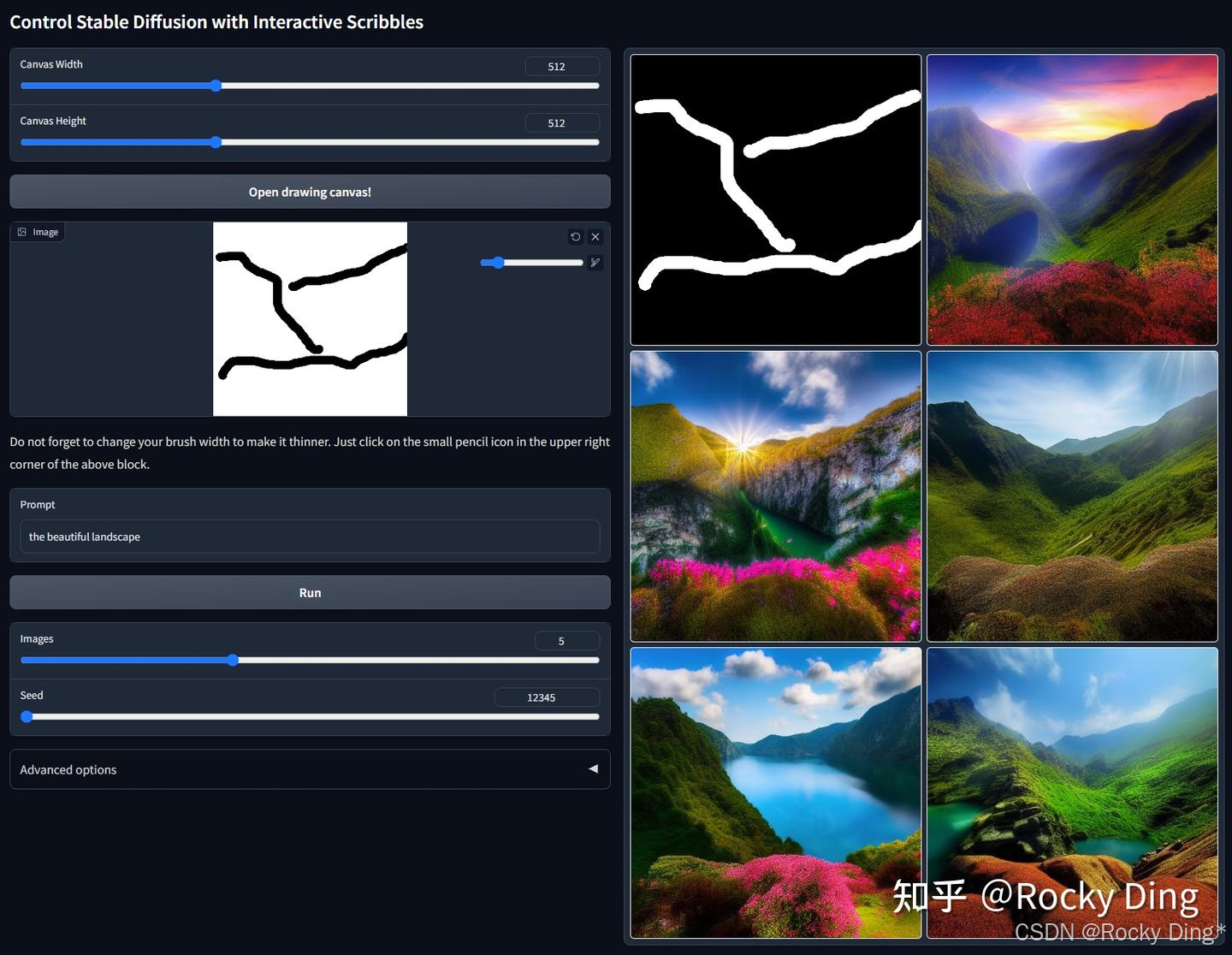
7.9 Segmentation ControlNet使用详解
Segmentation算法是传统深度学习三大支柱(分类,分割,检测)核心之一,主要通过对图片内容(人物、背景、建筑等)进行语义分割,可以区分画面色块,适用于大场景的画风更改。
但是输入图像的所有精细细节和深度特征都会丢失,与此同时会生成多个与输入图像中的物体的形状基本保持一致的mask(掩膜)。ControlNet中的Segmentation算法天然地能够与SD系列模型的inpatinting相结合使用,后者需要输入mask,并对mask部分进行局部重绘,而Segmentation算法就能够自动提供相应的mask部分。
Segmentation算法一共有三种预处理器,分别是seg_ofade20k预处理器、seg_ofcoco预处理器和seg_ufade20k预处理器。下面是三种预处理器的效果:
(1)seg_ofade20k预处理效果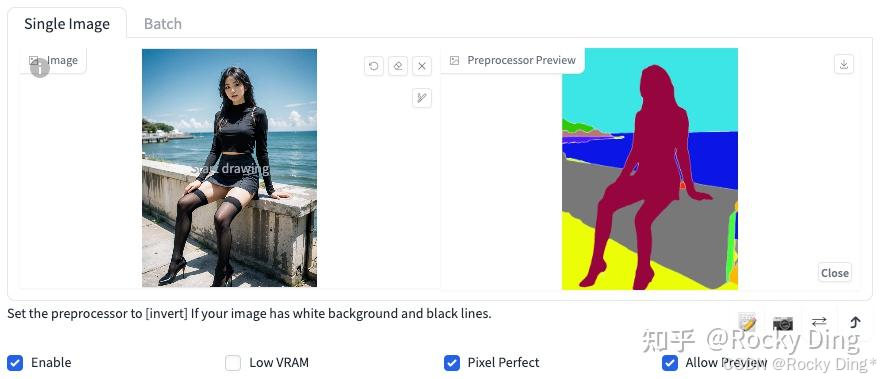
(2)seg_ufade20k预处理效果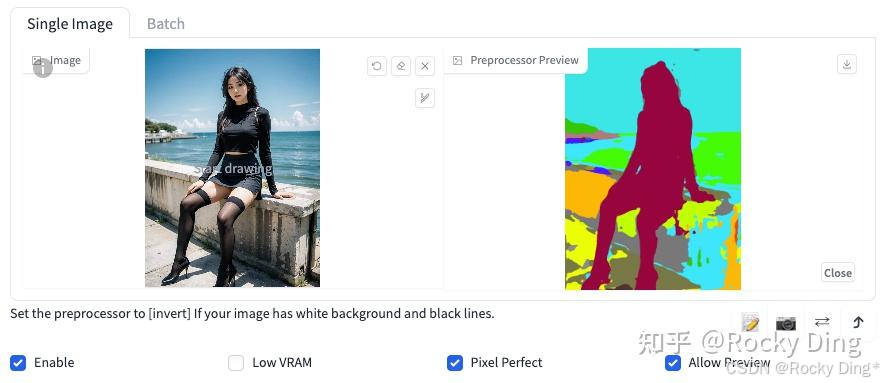
(3)seg_ofcoco预处理效果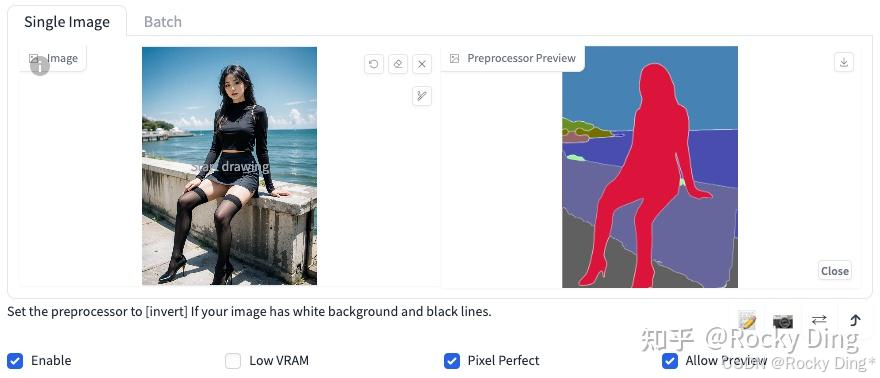
从上图可以看到,整体上seg_ofade20k预处理器的效果是最好的。
接下来我们ControlNet Segmentation模型进行控制生成:
7.10 Shuffle ControlNet使用详解
ControlNet中的Shuffle算法能够获取输入的参考图像的配色,并控制SD/SDXL模型生成相似配色方案的图像,从而实现风格迁移的效果。与ControlNet其他的预处理方法相比,Shuffle算法非常简洁明了。
它主要是采用random flow来打乱图像的内容,然后作为Condition特征送入ControlNet中。所以这个ControlNet模型训练的目的其实根据打乱的图像来生成原来的图像。同时在实现上会对ControlNet的特征输出做一个global average pooling。
目前Shuffle算法有一个预处理器:shuffle预处理器;同时有两个对应的ControlNet模型:control_v11e_sd15_shuffle.pth和control_v11e_sd15_shuffle.safetensors(FP16)。
Shuffle预处理效果
接下来,我们一起实际操作一下Shuffe算法的生成控制效果:
从上图可以看到,使用Shuffle算法后,生成的每一张图片都有参考图像的配色特征,参考图像的画风一定程度上融合进了生成图像中。
7.11 Tile/Blur ControlNet使用详解
【1】ControlNet中的Tile算法
ControlNet中的Tile算法和超分算法部分类似,能够增大图像的分辨率。但不同的是,ControlNet Tile算法在增加图像分辨率的同时,还能生成大量的细节特征而不是简单地进行插值。用官方的介绍来说,ControlNet Tile算法可以实现如下功能:
it can do 2x, 4x, or 8x super resolution。
it can add, or change, or re-generate image details in an image。
it can fix, refine, and improve bad image details obtained by any other super resolution methods like bad details or blurring from RealESRGAN。
it can guide SD to diffuse in tiles, "one beautiful girl" will not generate 16 girls if you use 16 tiles and denoising strength 1.0。
it can finish unfinished artwork drafts if those drafts are drawn by color blocks。
总的来说,ControlNet中Tile算法有两种使用方法:
- 在图片尺寸不变的情况下,优化生成图片的细节。
- 在对图片尺寸进行超分的同时,生成相应的细节,完善超分后的图片效果。
由于Tile算法可以生成新的细节,因此我们可以使用该算法去除不良细节并添加更精致的细节。例如,消除因图像超分或者尺寸变化而导致的图像细节模糊的问题。
目前Tile算法一共有三种预处理器,分别是tile_resample预处理器、tile_colorfix+sharp预处理器以及tile_colorfix预处理器。
Tile/Blur ControlNet的具体效果如下图所示:
总的来说,Tile算法的功能主要有:
- 优化模糊、细节较差的图片。这个功能在图生图中也可以使用,区别在于图生图更改细节的同时,也会变更主体,加上Tile算法进行控制后,生成过程中主体不变。
- Tile算法+特定提示词来微调图像细节。
- 对图片进行超分辨率重建的同时,补充生成细节特征。
【2】ControlNet中的Blur算法
Blur算法是一个非常经典的图像处理算法,早在传统深度学习时代之前,其就在图像处理领域中被广泛用,在AIGC时代来临后,其作为ControlNet中的一个组件,继续发挥积极的作用。
Blur算法通常用于降噪、图像平滑、简化图像细节、柔化边缘等。Blur算法有多种,每种都有其特定的应用和效果,常见的Blur算法有:均值Blur、高斯Blur、中值Blur、运动Blur等。
ControlNet中的Blur算法主要是用了高斯Blur作为预处理器,可以通过模糊输入图像的特征,从而进行重新生成质量更的图像,整体效果与用法和Tile算法类似。
blur_gaussian预处理效果如下所示:
ControlNet中的Blur算法具体效果如下所示:

7.12 Inpaint ControlNet使用详解
ControlNet Inpaint算法与Stable DIffusion/FLUX系列模型原生的Inapinting操作一样,使用mask对需要重绘的部分进行遮盖,然后进行局部的图像重新生成。
ControlNet Inpaint模型是用50%随机mask和50%随机光流mask共同训练的。这意味着模型不仅支持常规的图像重绘应用,还可以处理视频光流变形任务。
与此同时,ControlNet Inpaint算法也可以进行扩充重绘(outpainting),比如说将人物半身图片扩充重绘成全身图片,将风景画的内容扩展补充,得到一个更大尺寸的图像。社交平台上时不时火一阵的AI扩图,其核心技术就是通过ControlNet Inpaint来实现。
目前ControlNet Inpaint算法中包含了三个预处理器,分别是inpaint_global_harmonious预处理器,inpaint_only预处理器以及inpaint_only+lama预处理器。
当我们使用ControlNet Inpaint算法进行图像重绘时,我们需要在原图上添加掩膜,用于指示ControlNet算法重绘的区域,整体流程如下图所示:
当我们使用ControlNet Inpaint算法进行扩充重绘(outpainting)时,需要注意目前只能向两个方向扩充(上下或者左右),如果按图片整体比例扩充,结果就会是原图比例放大,没有太多重绘效果。
并且需要将Control Mode设置为ControlNet is more important,因为扩充重绘需要借助ControlNet的创造力;与此同时,我们需要将Resize Mode设置为Resize and Fill,来配合图片向外填充,为重绘打下尺寸基础。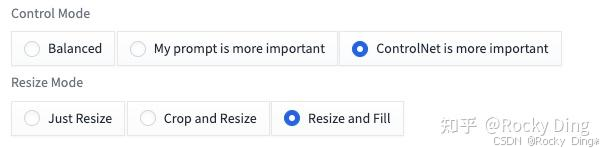
接下来,我们就可以上传图片,然后开始我们想要的扩充重绘(outpainting)了。
首先我们使用三个预处理器对原始图片进行左右方向的outpainting:
(1)使用inpaint_only算法进行outinapainting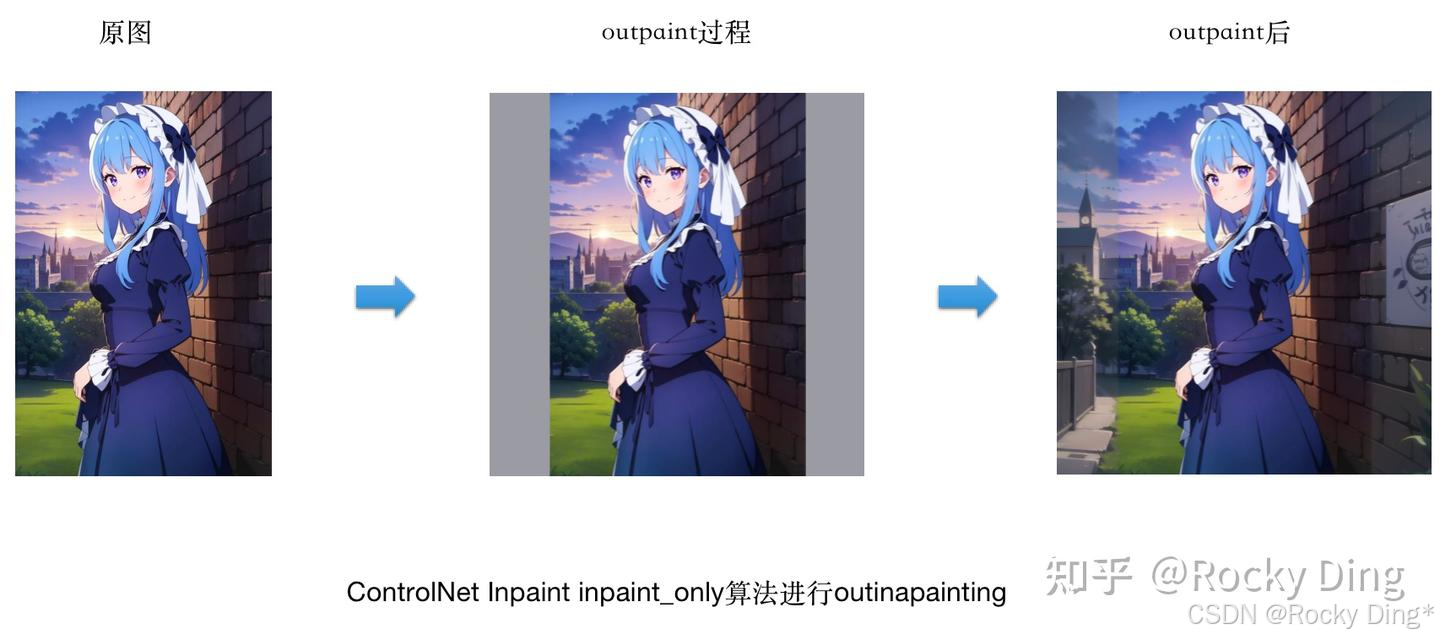
(2)使用inpaint_global_harmonious算法进行outinapainting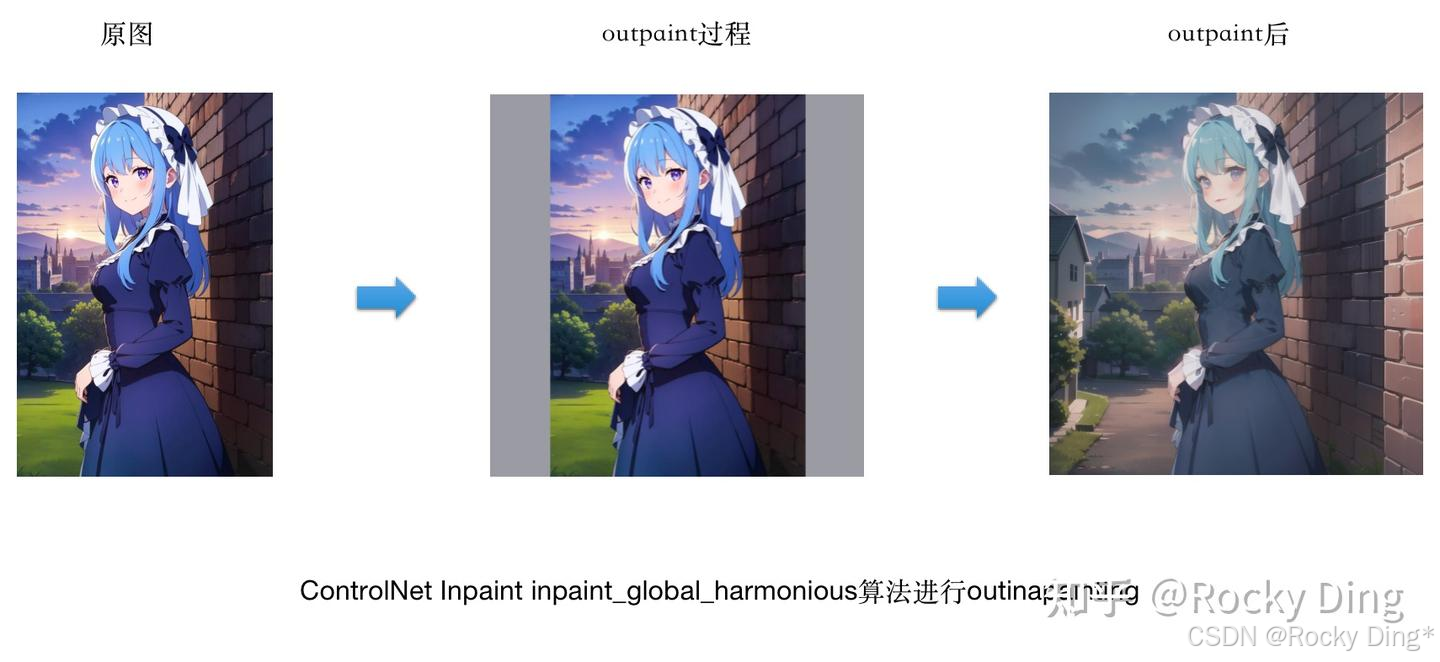
(3)使用inpaint_only+lama算法进行outinapainting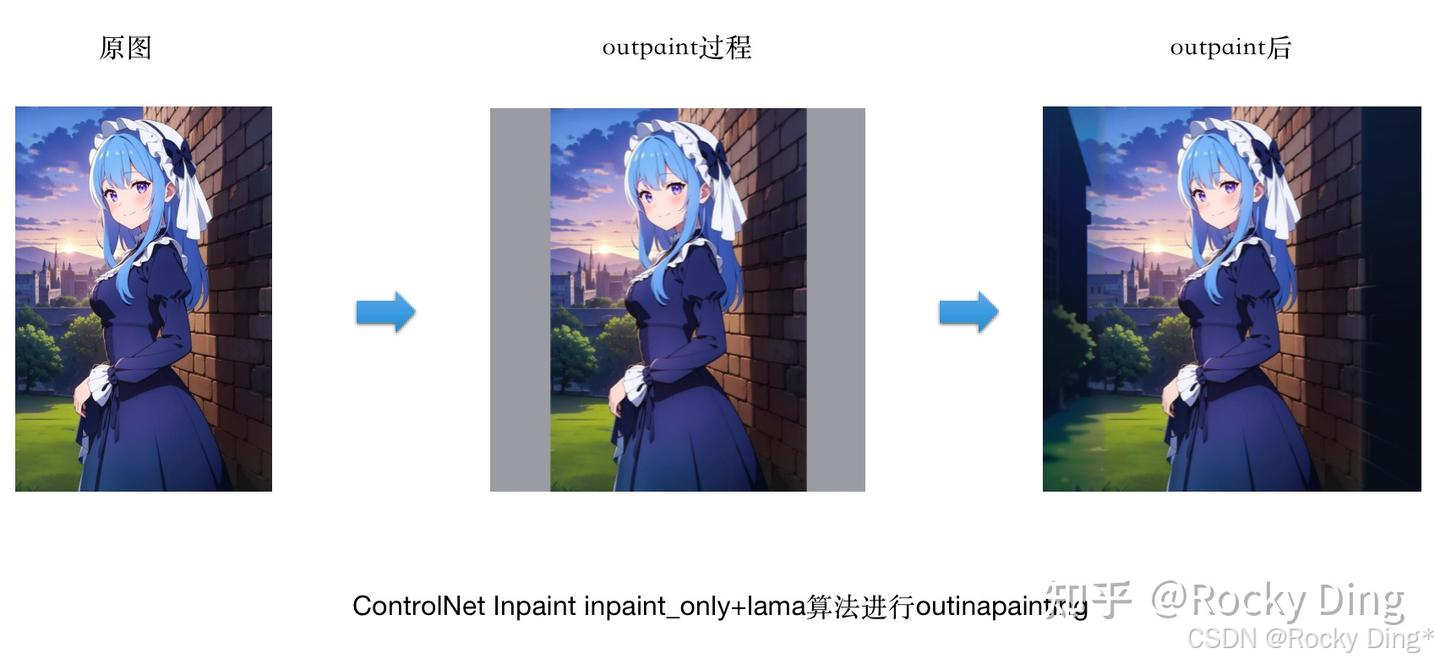
可以看到,使用三个预处理器都能将原图人物两侧的风景建筑进行扩图补充,整体上效果不错。
接着我们使用三个预处理器对原始图片进行上下方向的outpainting,看看会有什么效果:
(1)使用inpaint_only算法进行outinapainting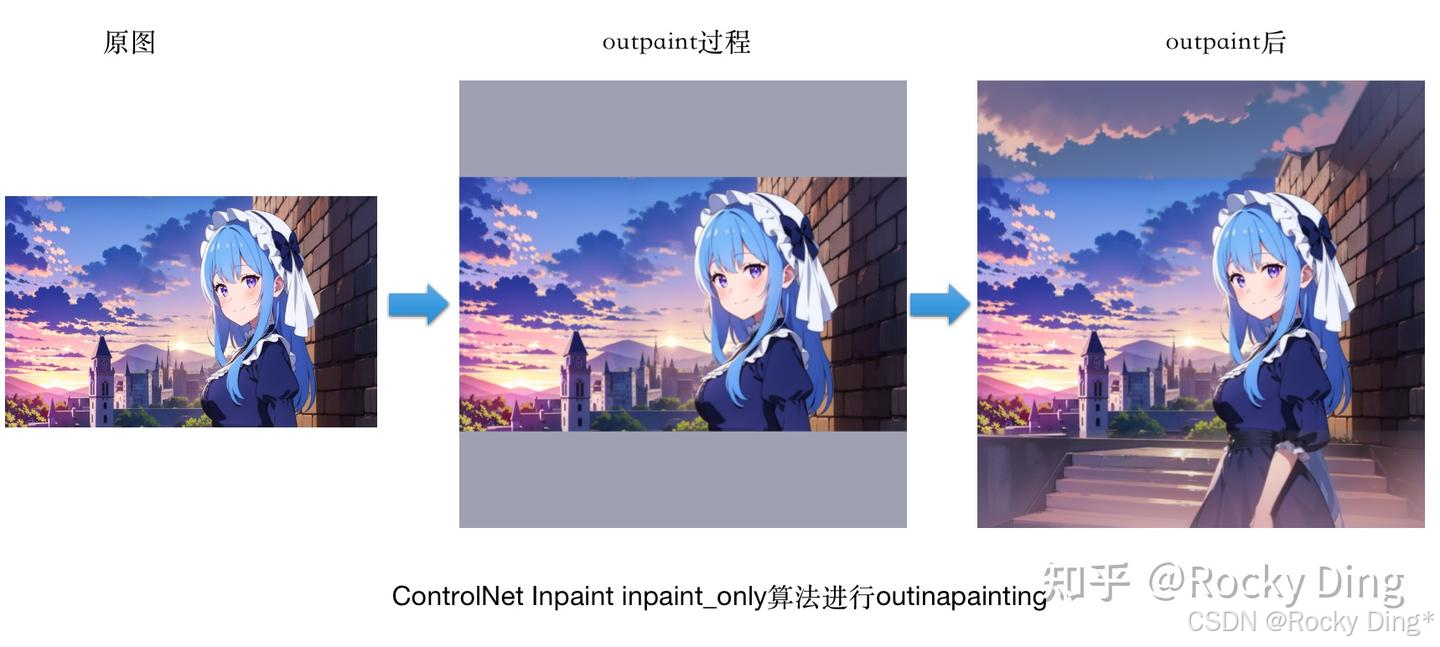
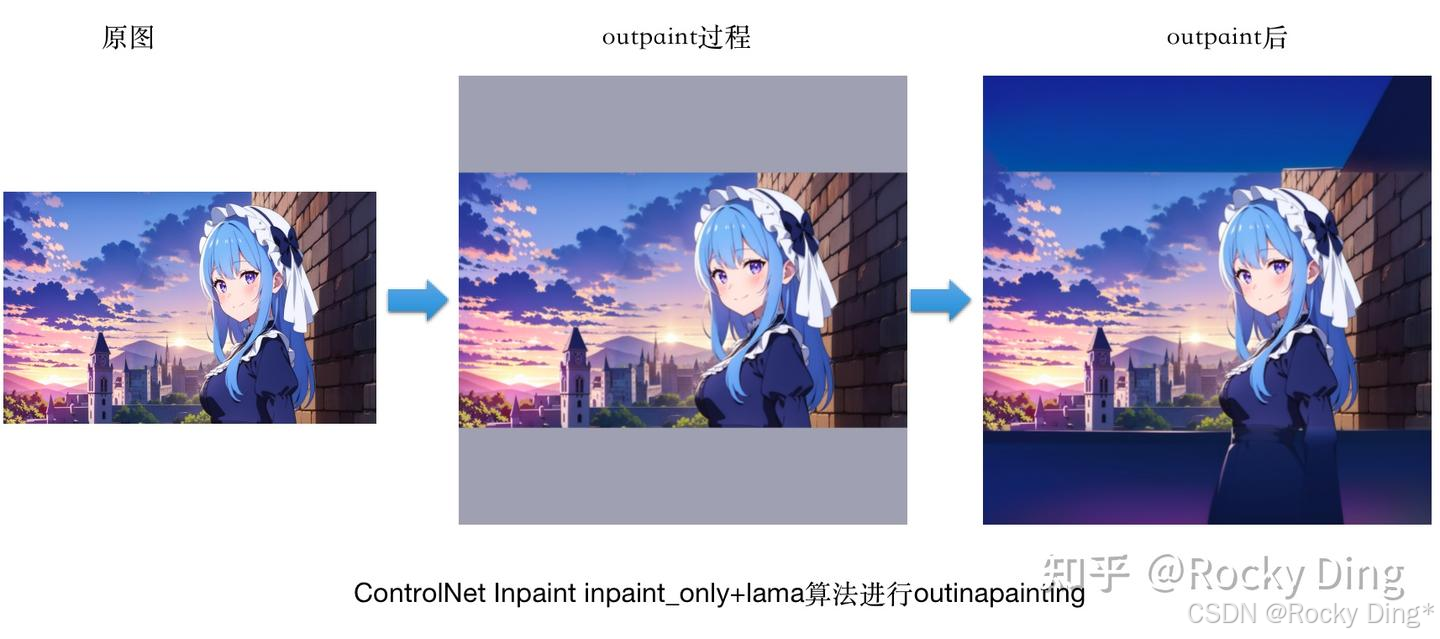
(2)inpaint_only+lama算法进行outinapainting
(3)inpaint_global_harmonious算法进行outinapainting
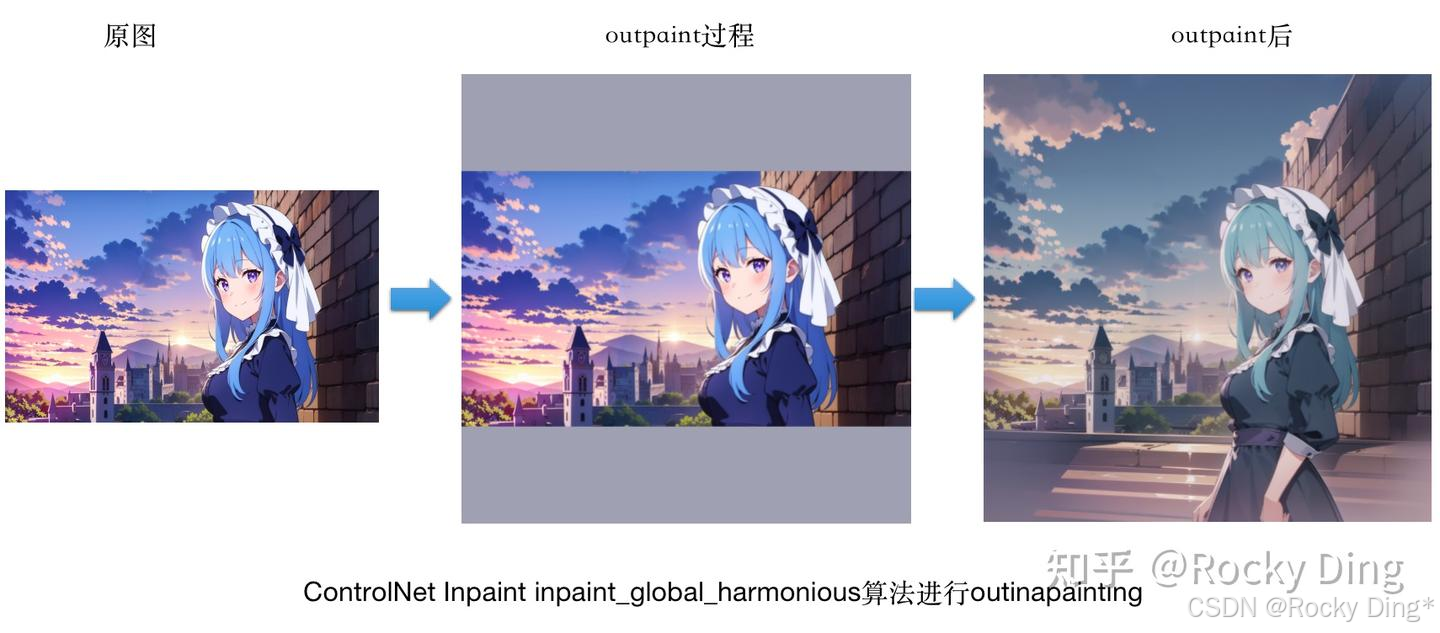
可以看到,当我们使用三个预处理器都能将原图人物上下侧的人物和风景进行扩图补充时,整体上效果不错,其中inpaint_global_harmonious算法的效果最好。
7.13 InstryctP2P ControlNet使用详解
ControlNet InstryctP2P算法是一种通过提示词编辑图像的算法,在传统深度学习时代,著名的以GAN为核心的Pix2Pix模型就是图像编辑算法的代表。
ControlNet InstryctP2P模型是在Instruct Pix2Pix数据集上进行训练的。不过不同于原生的Instruct Pix2Pix模型,ControlNet InstryctP2P模型是使用50%的指令提示和50%的描述提示进行训练的。举个例子,“一个可爱的男孩”是一个描述提示,而“让这个男孩变得可爱”是一个指令提示。同时ControlNet InstryctP2P算法不包含预处理器。
接下来,我们测试一下ControlNet InstryctP2P算法的效果:
从上图的结果可以看到,我们可以根据提示词较好的对输入图像进行特定的编辑。
7.14 Reference-only ControlNet算法使用详解
Reference-only算法可以说是CotrolNet系列中的一个“异类”,因为它只有预处理器,没有对应的ControlNet模型。也就是说这是一个不需要进行训练就能即插即用的纯算法功能。
Reference-only算法的预处理器能够直接使用额外的参考图 (图像提示词) 来控制Stable Diffusion系列模型的生成过程,类似于inpainting操作,但是不会导致图像内容变得无序和不可控,从而可以生成与参考图相似风格或者内容的图像。与此同时,SD系列模型在图像生成过程中仍会受到Prompt的约束与引导。
Reference-only算法的实现原理是通过将SD U-Net中的自注意力(Self-Attention)模块与参考图特征进行融合来实现的,Cross-Attention层则保持不变。我们先将参考图加噪声送入U-Net中,提取在Self-Attention模块中的keys和values并与SD模型原本的特征叠加,这样就将自身特征和参考图特征进行了融合,从而实现了无训练的参考图特征作为图像提示词的功能逻辑。下面是Reference-only算法的实现流程图: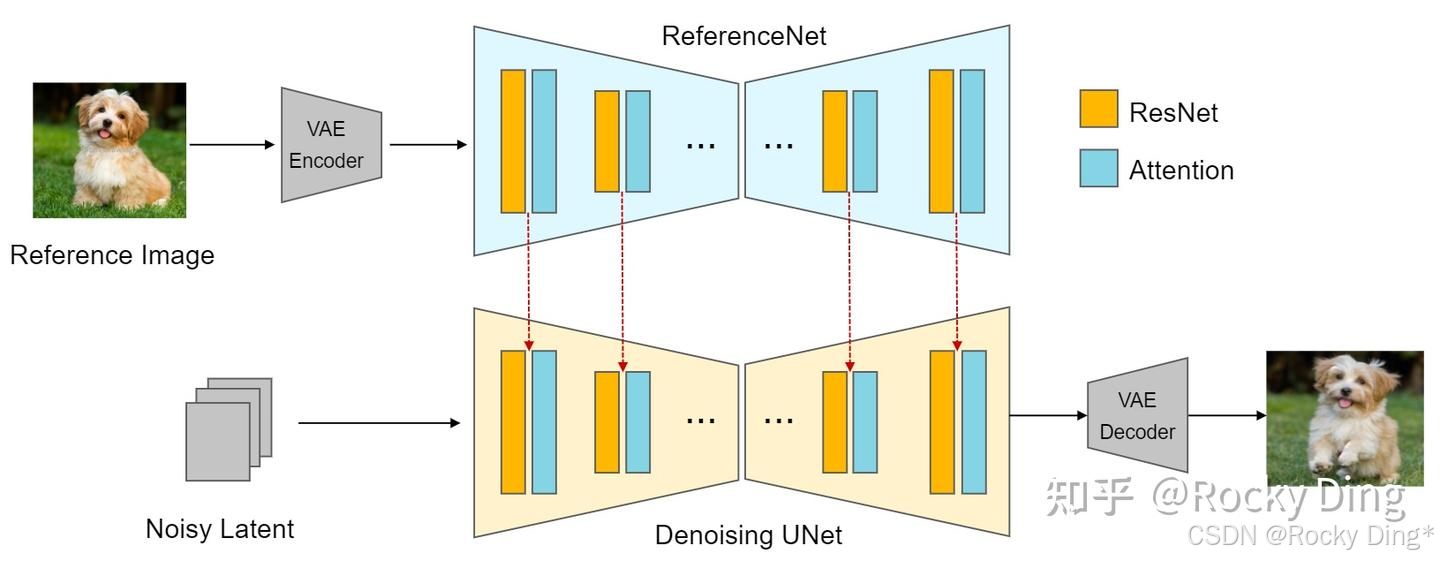
上面的示意图中为了方便观察设计了两个U-Net结构,实际上我们也可以用同一个U-Net实现,这样就不需要额外的ReferenceNet。在SD模型的Denoising循环中每一步先走上半部分的Reference过程,把需要“关联”的中间数据存起来,再走下半部分常规的Denoising过程,所以ControlNet中Reference-only算法不需要额外的模型支持。
总的来说,ControlNet Reference-only算法的整体流程完整包括:
- 输入参考图,使用VAE提取参考图的Latent特征。
- 使用SD系列模型进行文生图或者图生图任务,同时往U-Net架构中注入参考图的Latent特征。
- 参考图只在U-Net的Self-Attention层起作用,不影响Cross-Attention层。
- 调整参考图Latent特征与SD系列模型本身的图像特征之间的权重,逐步去噪生成图像。
ControlNet Reference-only算法中主要通过设计Style Fidelity参数,来控制参考图Latent特征与SD系列模型本身的图像特征之间的权重:
融合的自注意力机制 = style_fidelity * 融合自注意力机制 + (1.0 - style_fidelity) * 原始自注意力机制
下面我们看看ControlNet Reference-only算法分别在写实场景和二次元场景的控制效果: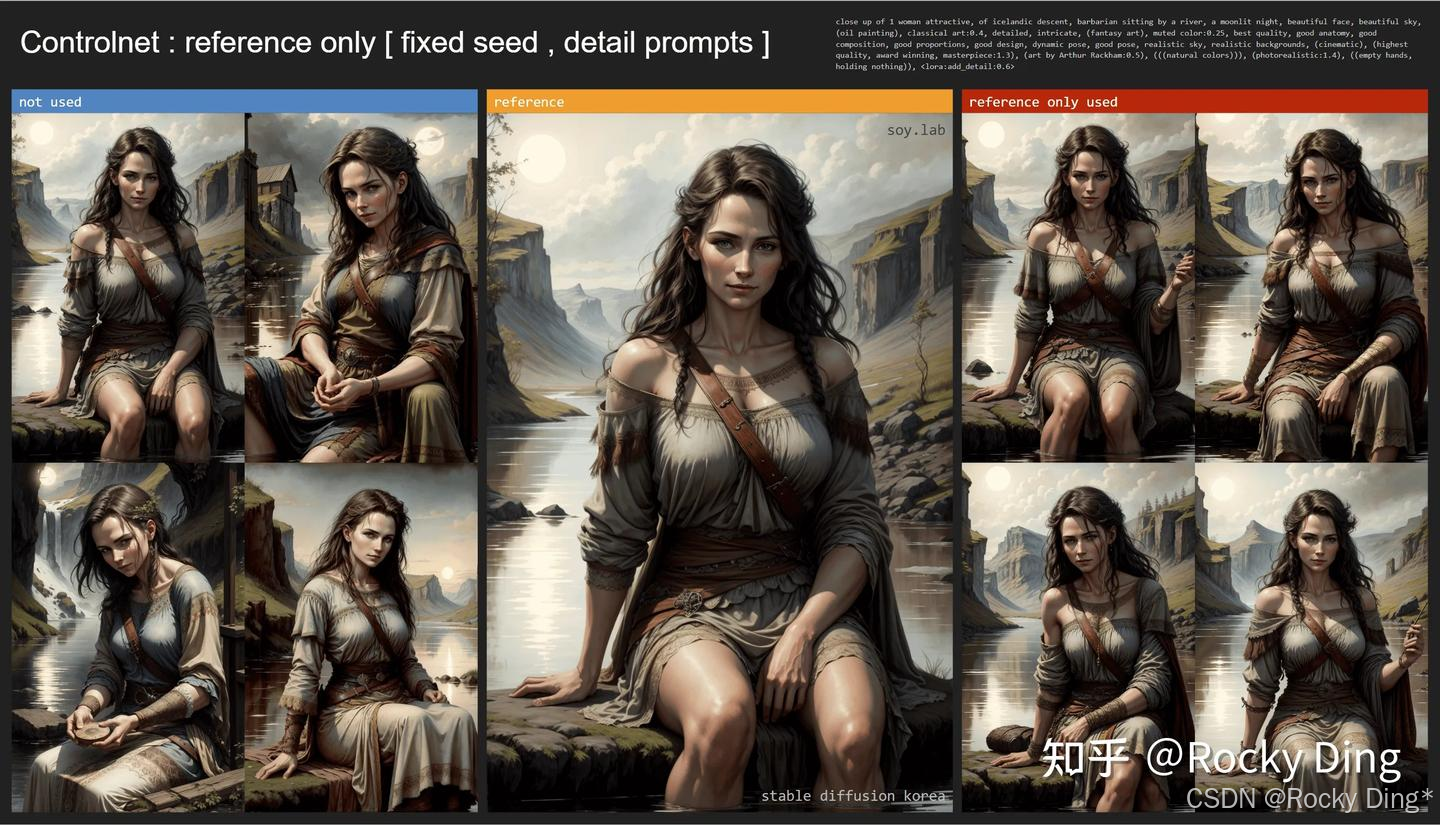
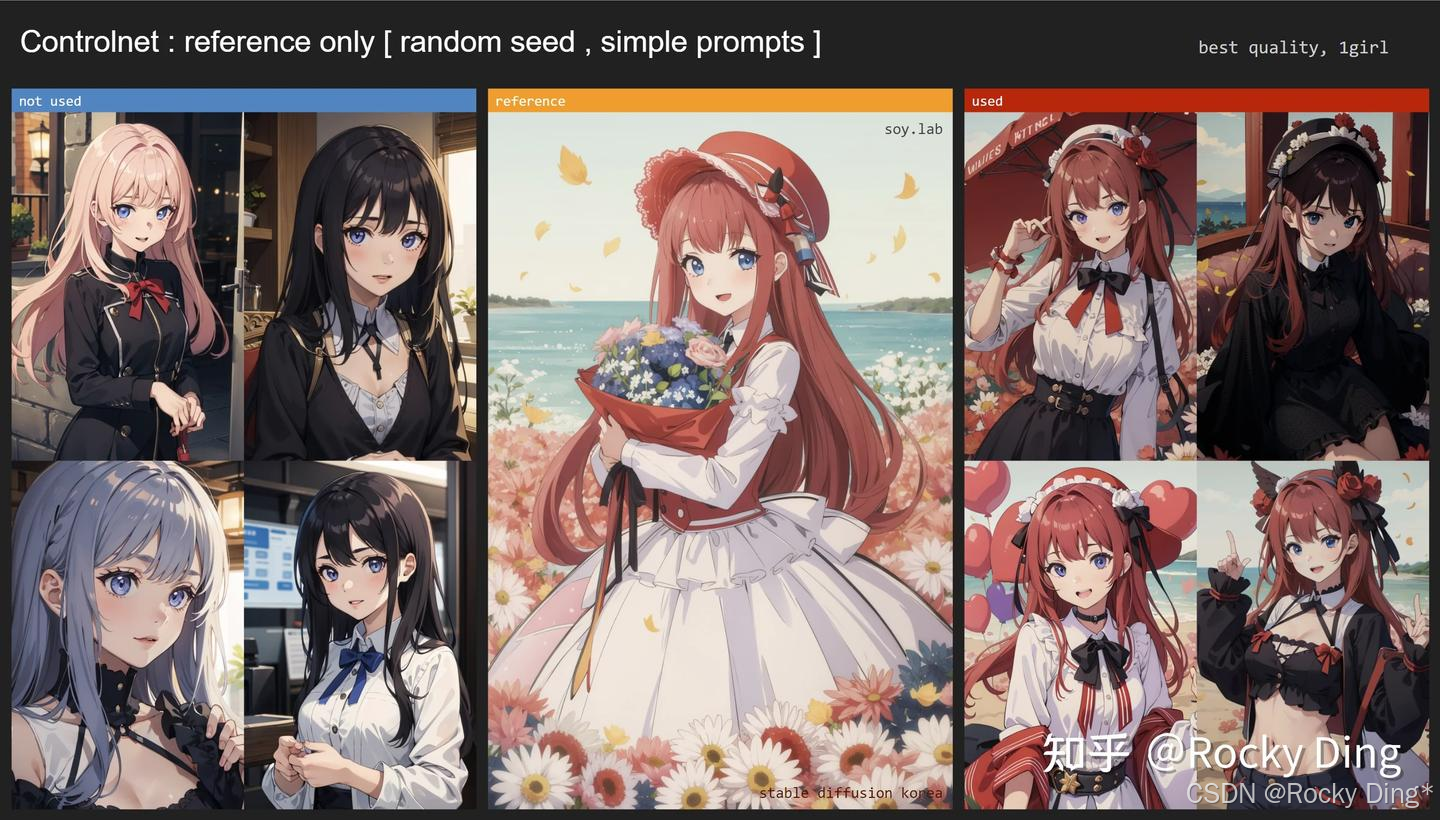
上面的示例中使用的都是reference_only预处理器,目前Reference-only算法一共包含三种预处理器,分别是reference_only预处理器、reference_adain预处理器和reference_adain+attn预处理器。接下来Rocky就为大家讲解不同Reference-only预处理器的原理,并展示它们的控制效果:
(1)ControlNet reference_only预处理器原理讲解和控制生成效果展示
reference_only预处理器就是我们上面讲的Reference-only算法中最基本的预处理器,整个预处理过程与控制生成过程就是我们上面讲的在参考图像和自注意力层之间进行Concat,从而进行融合生成。
(2) ControlNet reference_adain预处理器原理讲解和控制生成效果展示
reference_adain预处理器采用了Adaptive Instance Normalization(AdaIN)技术,将参考图像的风格特征融合到生成图像中。这个在传统深度学习时代的GAN模型中用于风格参考与迁移的技术,终于在AIGC时代重新繁荣。
在ControlNet中,reference_adain预处理器的作用主要是在SD系列模型做Normalization操作的时候,使用参考图的均值、方差作为Norm系数,从而实现参考图风格的注入。具体的实现方式如下:
AdaIN ( x , y ) = σ ( y ) ⋅ x − μ ( x ) σ ( x ) + μ ( y ) \text{AdaIN}(x,y) = \sigma(y) \cdot \frac{x - \mu(x)}{\sigma(x)} + \mu(y) AdaIN(x,y)=σ(y)⋅σ(x)x−μ(x)+μ(y)
其中各个符号的含义:
- x x x: 代表SD模型本身的特征;
- y y y: 代表参考图的特征;
- μ ( ⋅ ) \mu(\cdot) μ(⋅):计算特征图的实例均值(Instance Mean),即对每个特征图的 H × W H\times W H×W 空间维度求平均
- σ ( ⋅ ) \sigma(\cdot) σ(⋅):计算特征图的实例标准差(Instance Standard Deviation),公式为 σ ( z ) = Var ( z ) + ϵ \sigma(z)=\sqrt{\text{Var}(z)+\epsilon} σ(z)=Var(z)+ϵ, ϵ \epsilon ϵ 是防止分母为 0 的极小值

(3)ControlNet reference_adain+attn预处理器效果原理讲解和控制生成效果展示
reference_adain+attn预处理器结合了reference_only预处理器和reference_adain预处理器的特点。它在将参考图的特征注入自SD模型的自注意力层的同时运用了AdaIN- Normalization技术,更精细地融合参考图像的特征。
目前Reference-only算法能够完美兼容Stable Diffusion 1.x-2.x和Stable Diffusion XL模型。对于Stable Diffusion 3和FLUX.1系列模型,由于是基于Transformer架构,所以暂时还不适用,不过相信未来开源社区会及时跟进适配。
更多关于Reference-only算法的干货知识,Rocky为大家进行了汇总梳理,大家可以直接阅读:
- Reference-only/discussions
- https://github.com/huggingface/diffusers/blob/main/examples/community/stable_diffusion_reference.py
- [New Preprocessor] The “reference_adain” and “reference_adain+attn” are added · Mikubill/sd-webui-controlnet · Discussion #1280
在ControlNet的Reference-only算法开源后,AIGC时代的很多领域都借鉴了其“即插即用”的思想,比如说视频动作控制、语音驱动的人像视频生成、虚拟试装、保ID人像生成、人像多视角合成等,逐渐成为了AIGC时代可控生成方法中的基石思想。
7.15 Recolor ControlNet使用详解
Recolor算法主要起到对输入图像进行重新上色的效果。
目前Recolor算法有两个预处理器,分别是recolor_intensity预处理器和recolor_luminance预处理器。
recolor_intensity预处理器在提取图像特征时更注重颜色的饱和度。而recolor_luminance预处理器在提取图像特征时更注重颜色的亮度,通常情况下选用recolor_intensity预处理器效果更好。
目前Recolor算法一共包含了三个ControlNet模型,分别是ioclab_sd15_recolor,sai_xl_recolor_128lora和sai_xl_recolor_256lora。
其中sai_xl_recolor_128lora和sai_xl_recolor_256lora模型是两个匹配SDXL的control-LoRA模型。通过将低秩参数高效微调加入到ControlNet中,训练了Control-LoRAs模型。Control-LoRAs模型比起原生的ControlNet模型推理速度更快。
同时Recolor算法还有一个关键参数Gamma Correction(伽玛校正)。Gamma Correction(伽马校正)是一种在成像系统中用于校正或调整图像亮度或颜色的非线性操作。其主要目的是优化图像数据的使用,以符合人类对亮度和颜色的感知,确保图像在不同显示设备上的准确呈现。Gamma Correction默认设置为1,如果感觉生成的图像较暗就调小一点,如果感觉生成的图像过亮,就调大一点。
(1)recolor_intensity预处理器+ioclab_sd15_recolor模型效果
先来看看单个recolor_intensity预处理器的效果,如下所示我们可以从彩色图像中获取灰度图: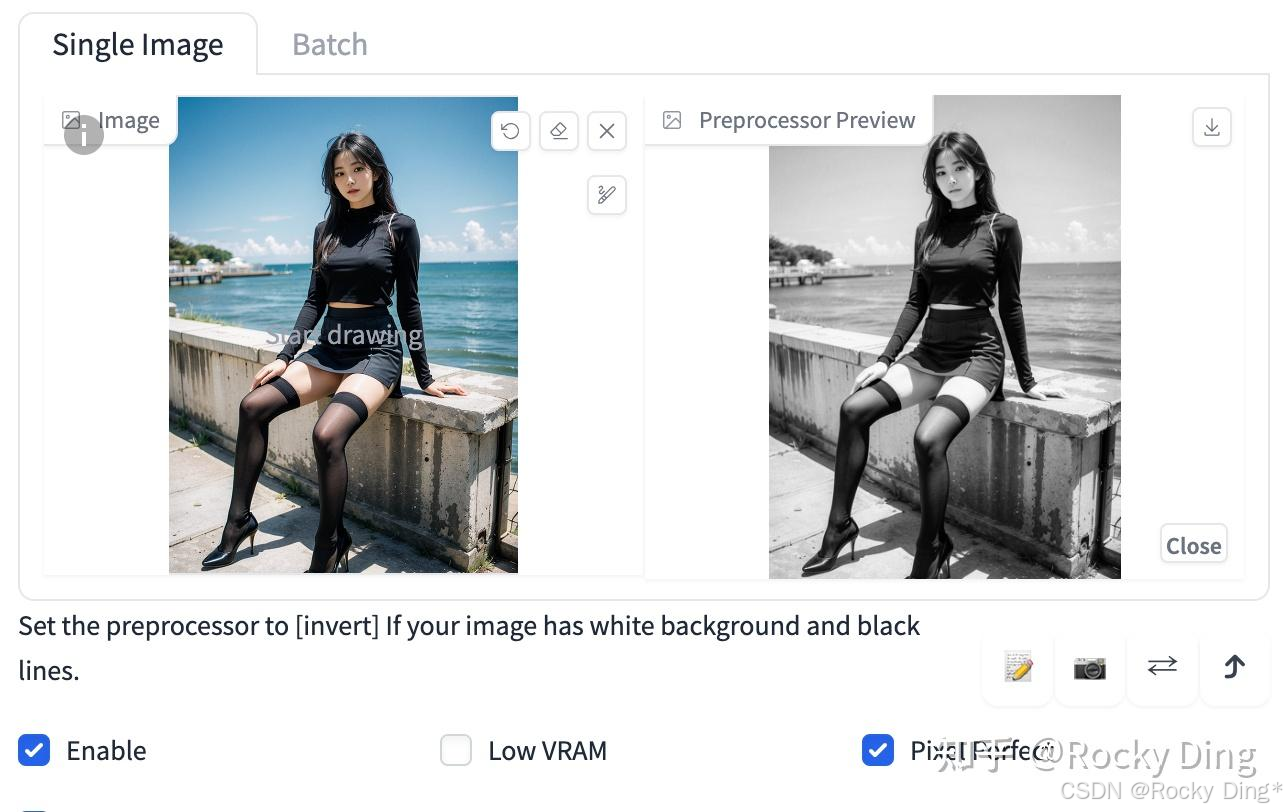
接下来我们再来看看recolor_intensity预处理器+ioclab_sd15_recolor模型的完整效果,我们尝试修改图像中美女的发色,从黑色转变成红色:
(2)recolor_luminance预处理效果+ioclab_sd15_recolor模型效果
先来看看单个recolor_luminance预处理器的效果,如下所示同样的我们可以从彩色图像中获取灰度图: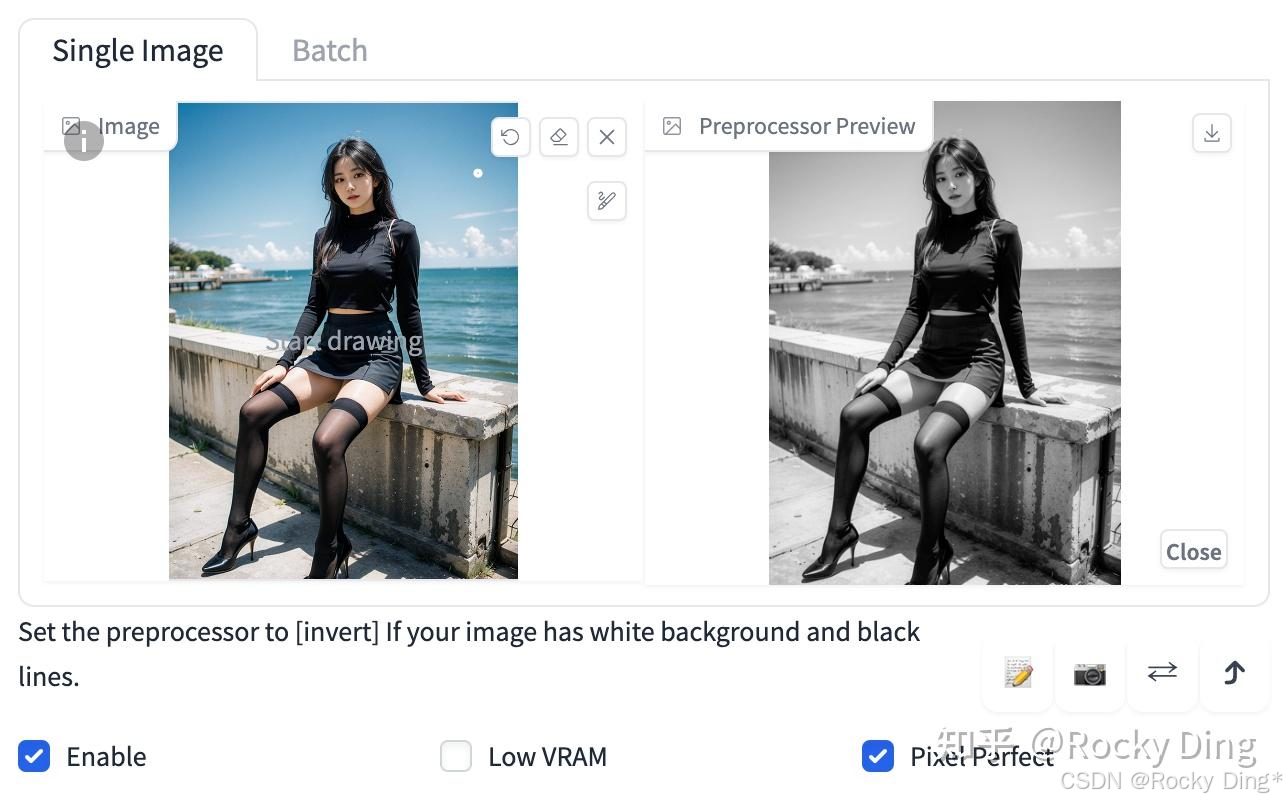
接下来我们再来看看recolor_luminance预处理器+ioclab_sd15_recolor模型的完整效果,我们尝试修改图像中美女的发色,从黑色转变成红色:
可以看到,ControlNet的Recolor算法用在颜色滤镜、老照片上色,局部颜色调整等领域非常有价值。
7.16 Revision ControlNet使用详解
ControlNet里的Revision算法主要是在控制的过程中加入的“底图”,它用池化的CLIP Embedding来生成与输入“底图”概念相似的图像。Revision算法可以单独使用于SD系列模型的生成,也可以与提示词Prompt组合使用。
需要注意的是:Revision算法兼容Stable Diffusion和Stable Diffusion XL模型。
目前Revision算法一共有两种预处理器,分别是revision_clipvision预处理器和revision_ignore_prompt预处理器。
与此同时,Revision算法并不需要对应的ControlNet模型,因为其主要是对输入的图像进行处理,提取Embedding特征。
首先我们来看看两个预处理器的效果:
(1)revision_clipvision预处理器的控制效果
(2)revision_ignore_prompt预处理器的控制效果
Revision算法不仅能提取一张图片的特征作为参考,也能将多张图片的特征提取后进行融合,接下来我们看看多图像融合的效果: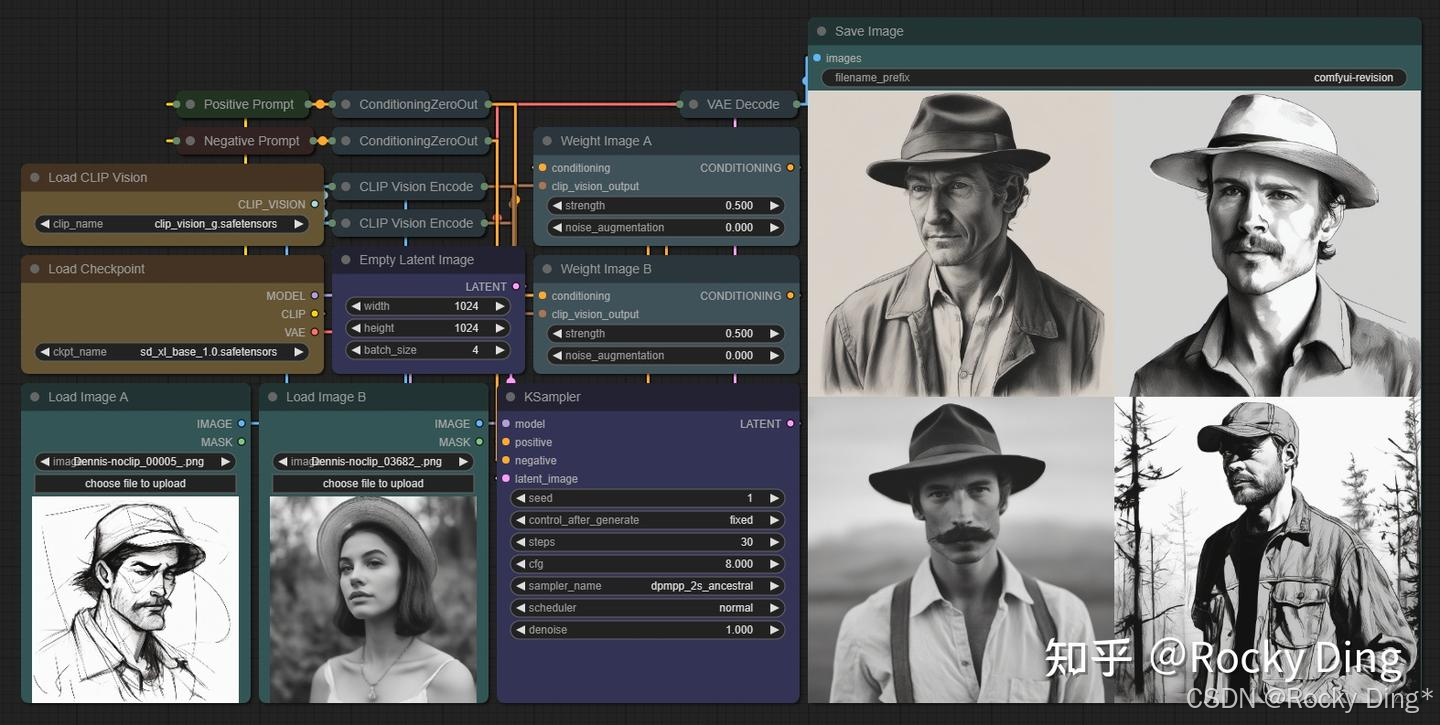
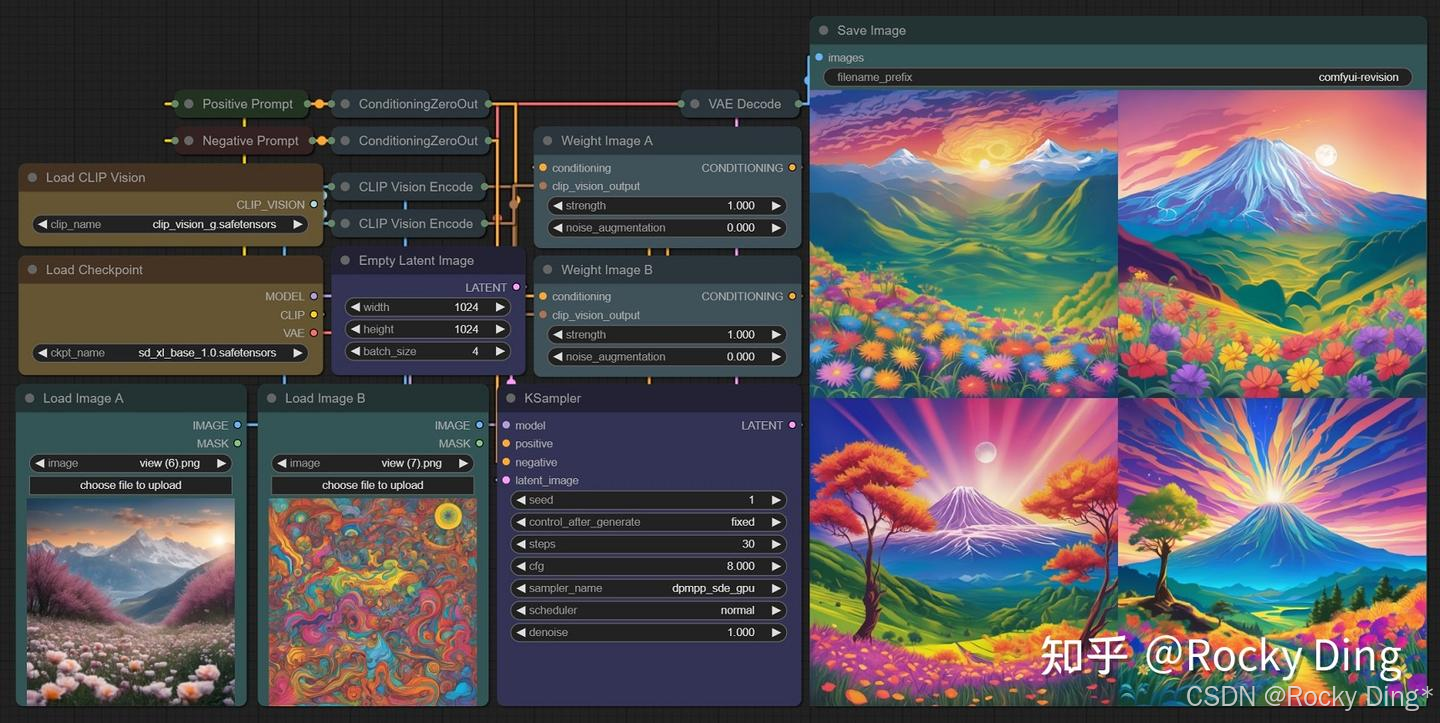
可以看到,使用Revision算法进行多图像融合的效果很好,不过多图像融合时各个图像的权重需要配置好,某个图像的权重配置的越高,那么其特征在融合生成后的图像中就越明显。
7.17 T2l-Adapter ControlNet使用详解
T2I-Adapter算法是由腾讯发布,和ControlNet模型一样,能够输入控制条件控制SD模型生成图片的过程。
下面是T2I-Adapter算法发挥作用的示意图: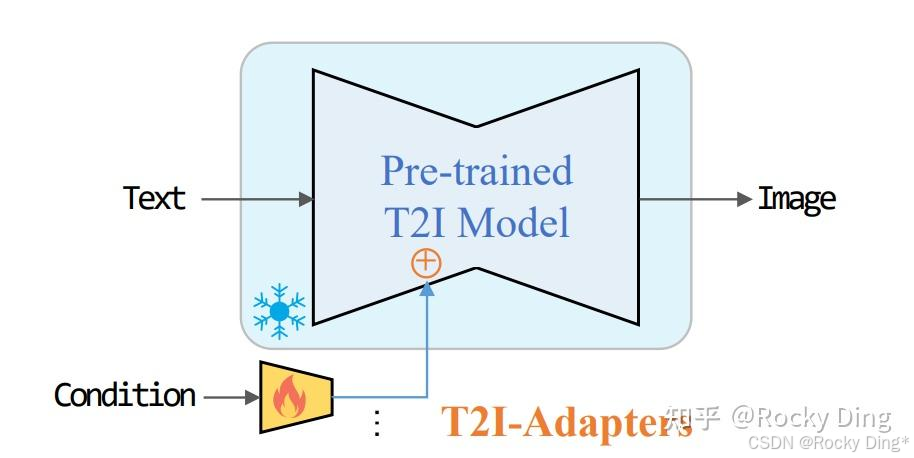
T2I-Adapter算法的详细结构: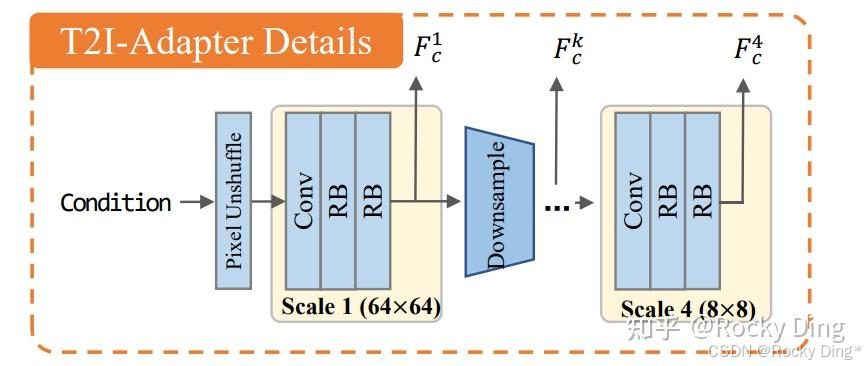
T2I-Adapter算法的一些特征:
- 即插即用: T2I-Adapter算法不会影响SD模型原本的生成能力。
- 简单且小巧: 它们可以轻松地与SD模型结合,T2I-Adapter模型大约只有77M的参数和大约300M的存储空间。
- 灵活组合: 可以轻松与多个ControlNet模型组合使用,以实现多条件控制。
- 泛化能力: 在不同的SD模型上具备较好的泛化控制性能。
因为T2l-Adapter算法与ControlNet算法有很多相似的功能,所以在ContorlNet中一共集成了三种T2l-Adapter算法预处理器,分别是t2ia_color_grid,t2ia_sketch_pidi和t2ia_style_clipvision。
(1)t2ia_color_grid预处理效果
t2ia_color_grid预处理器将输入参考图像缩小到原始大小的1/64,然后再将其扩大至回原始尺寸。最终效果是呈现出网格状的局部平均颜色块。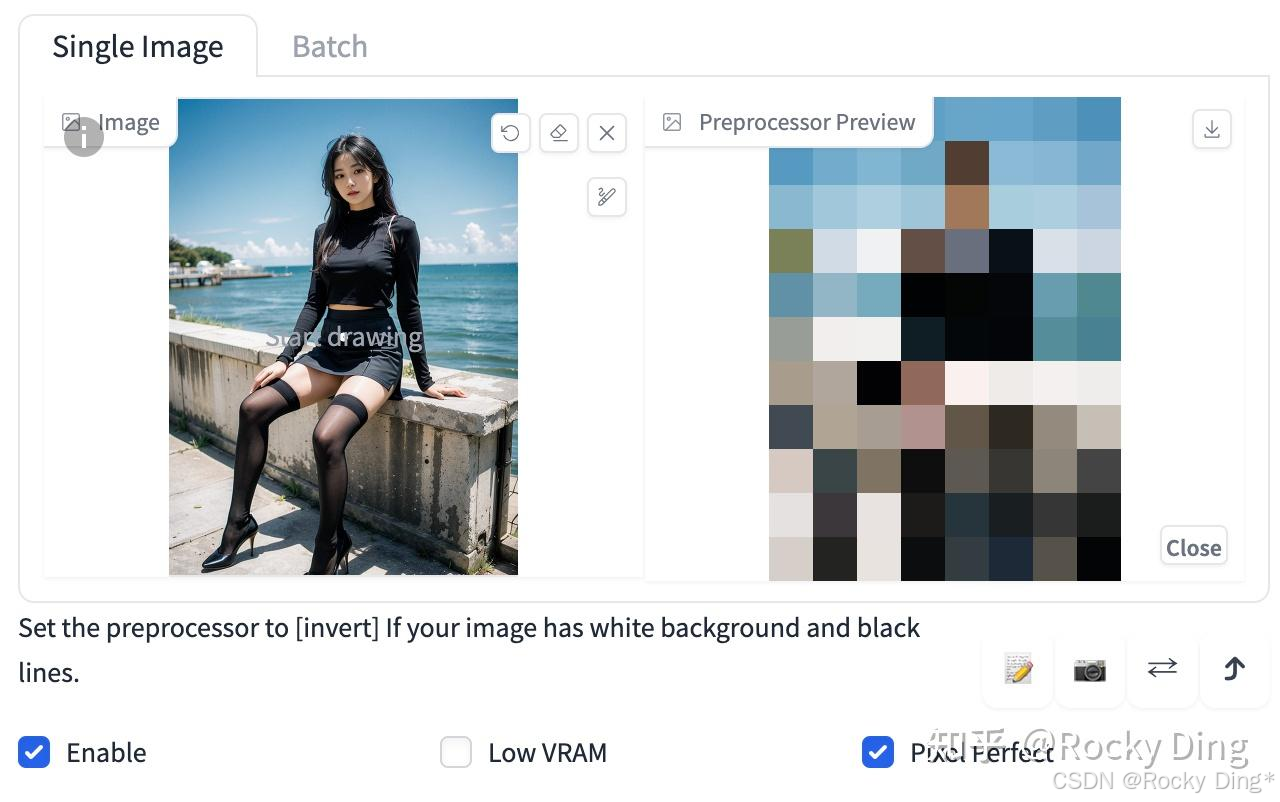
t2ia_color_grid完整的效果:
(2)t2ia_sketch_pidi预处理效果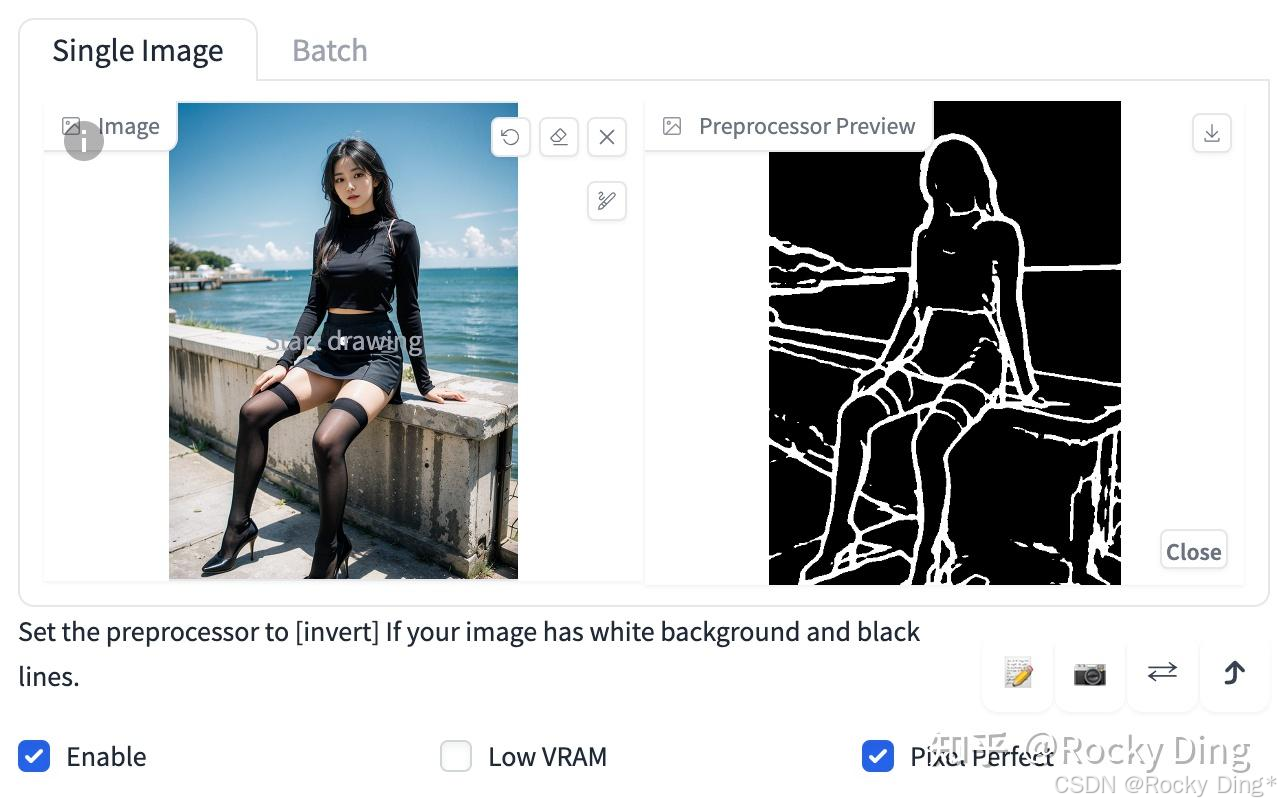
t2ia_sketch_pidi的完整效果:
(3)t2ia_style_clipvision预处理效果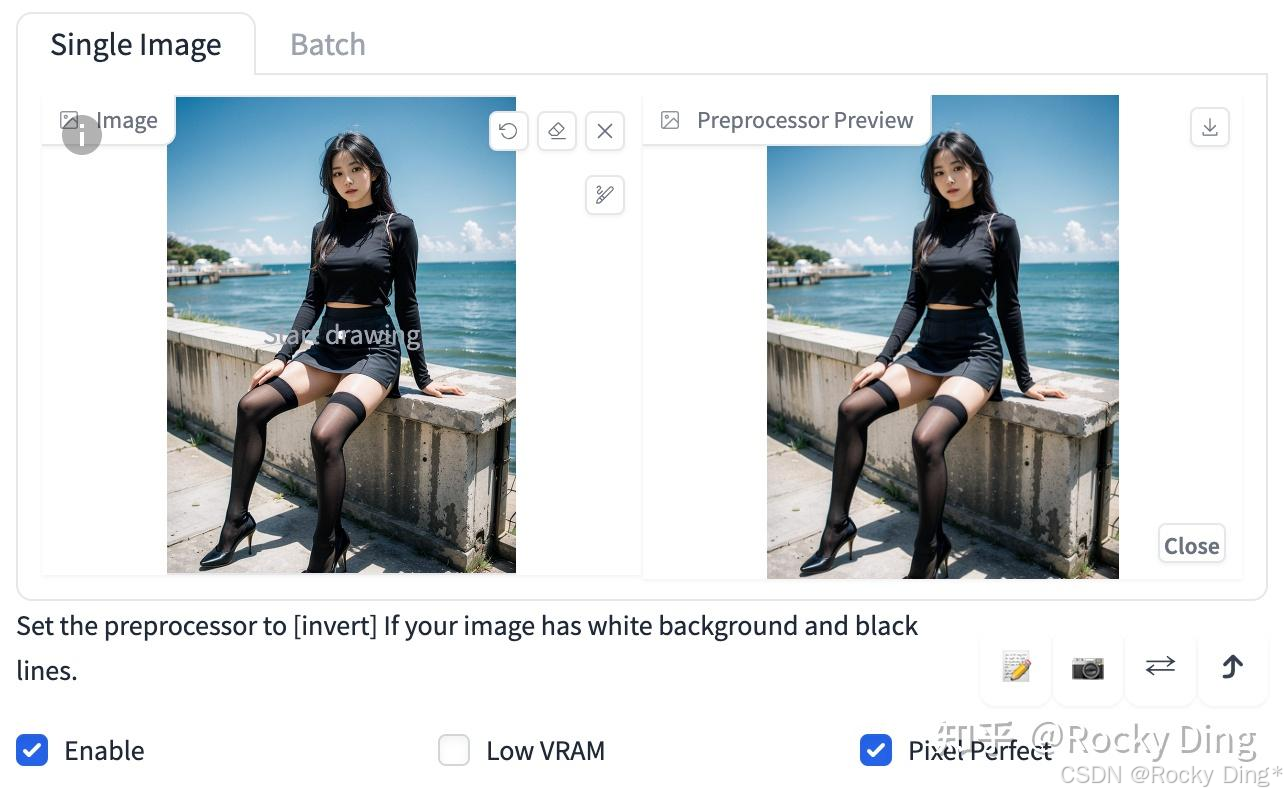
t2ia_style_clipvision的完整效果:
7.18 IP-Adapter ControlNet使用详解
Stable Diffusion系列模型在正常情况下是只支持文本提示词的输入,而IP-Adapter算法能够在SD模型的图像生成过程中引入图像提示词(Image Prompt),从而能够识别输入图像的风格和内容,然后控制SD模型生成相似风格或者内容的图片,同时也可以搭配其他类型的ControlNet一起使用。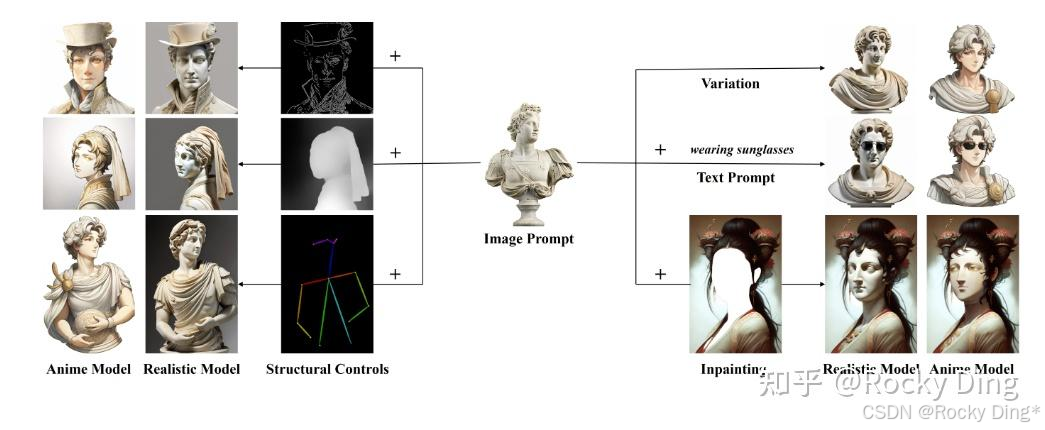
可以说IP-Adapter能让SD模型临摹艺术大师的作品,并且用在我们生成的图片中,在AI绘画开源社区中,大家给IP-Adapter算法的功能起了一个形象的名字:“垫图”。
接下来我们再看一下IP-Adapter算法的整体流程: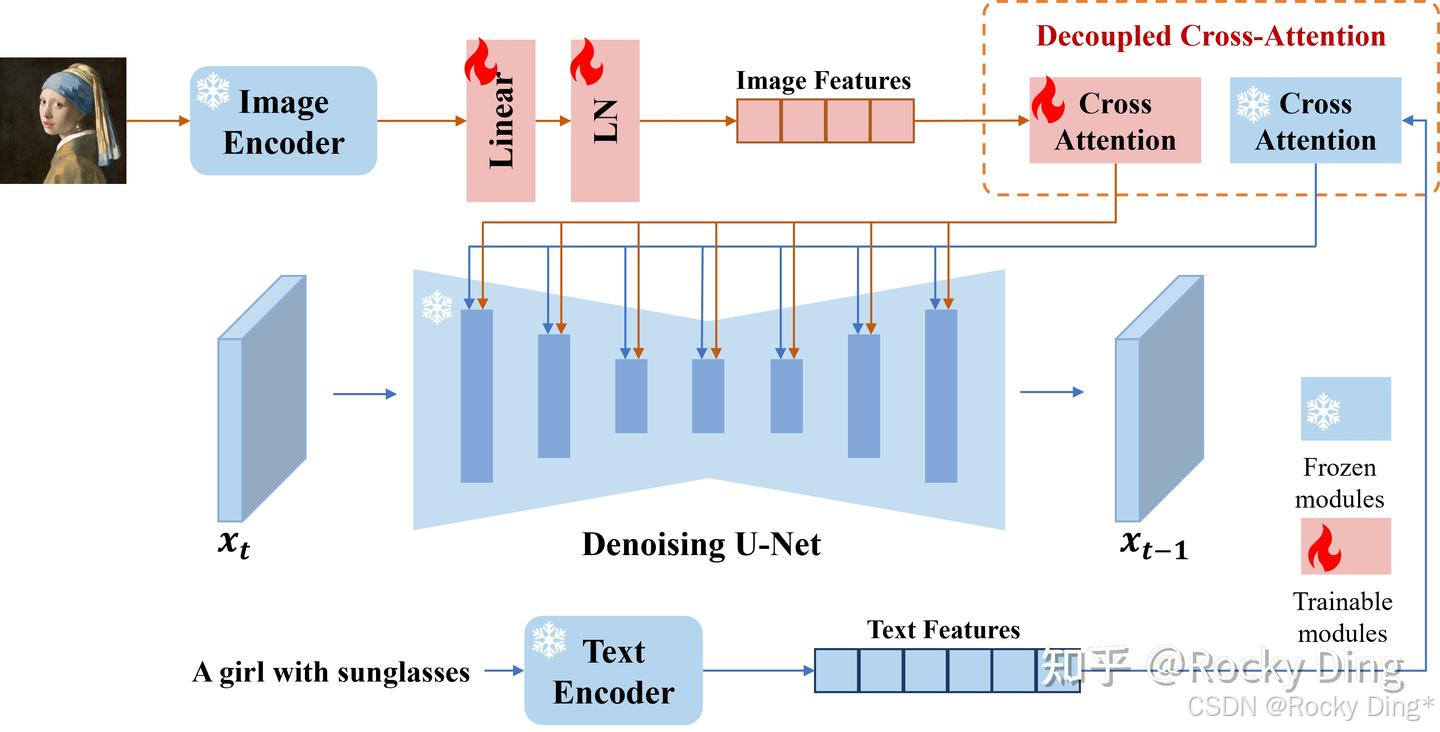
从上图可以看到,IP-Adapter算法主要分为三个步骤:
- 使用CLIP的Image Encoder模块提取图像特征。
- 使用CLIP的Text Encoder模块提取文本特征。
- 通过Cross Attention机制将图像特征和文本特征注入Stable Diffusion的U-Net中,用于引导图像的生成过程。
IP-Adapter算法的关键设计是解耦的交叉注意机制,它将文本特征和图像特征的交叉注意层分开。
知道了IP-Adapter算法的核心基础知识和整体流程,那么IP-Adapter算法和Stable Diffusion模型结合主要能干哪些有价值的事情呢?
- IP-Adapter算法可以同时使用图像提示词和文本提示词,引导图像的生成。
- IP-Adapter算法可以用于图生图以及图像inpainting。
- IP-Adapter算法与Stable Diffusion和Stable Diffusion XL模型同时适配,并且可以与其他ControlNet模型组合使用(包括ControlNet、T2I-Adapter等)。
IP-Adapter算法一共有两个预处理器,分别是ip-adapter_clip_sd15预处理器(用于SD模型)和ip-adapter_clip_sdxl预处理器(SDXL模型)。
如下图所示,我们在ControlNet栏中上传图片作为图像提示词: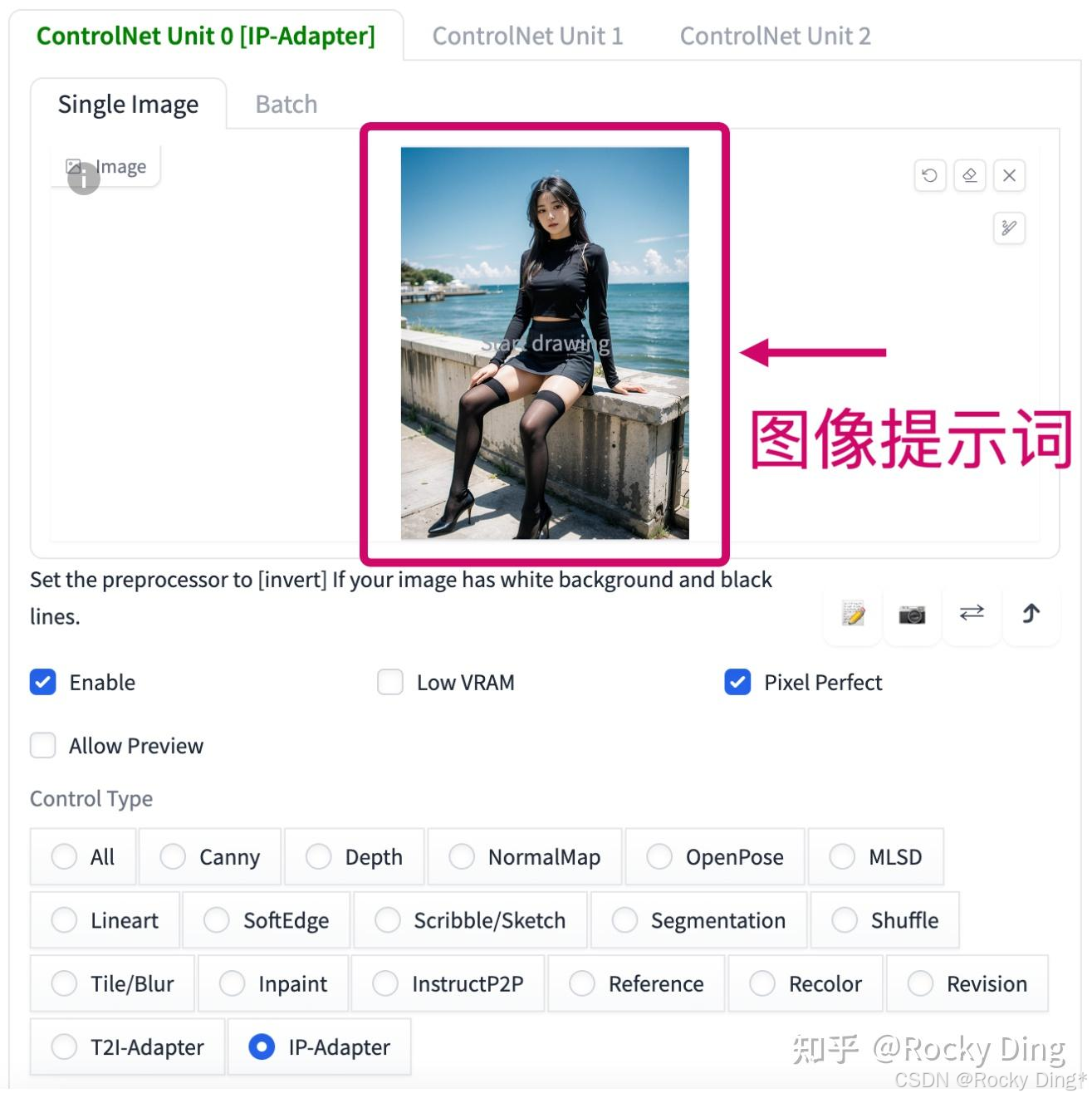
IP-Adapter模型一共有三个,分别是:
- ip-adapter_sd15:适用于Stable Diffusion 1.5模型。
- ip-adapter_sd15_plus:适用于 Stable Diffusion 1.5模型,能够细节更丰富的图像提示词,生成的图片和图像提示词的内容和风格更相似。
- ip-adapter_xl:适用于 Stable Diffusion XL模型。
下面我们来看看,我们以ip-adapter_clip_sd15预处理器和ip-adapter_sd15_plus模型为例,实现各种好玩的效果:
(1)只使用IP-Adapter算法进行文生图任务
(2)IP-Adapter算法+其他ControlNet进行文生图任务
(3)IP-Adapter算法进行换脸
(4)IP-Adapter算法对图像元素进行编辑
想要使用IP-Adapter算法对图像元素进行编辑,我们就需要文本提示词+图像提示词一起发挥作用。
我们可以看到下面的两个例子,在图生图中,使用IP-Adapter算法给第一幅图中的人物增加一顶帽子,将第二幅图片的背景设置为沙滩。
(5)IP-Adapter算法将图片主体特征相融合
7.19 多个ControlNet(Multi ControlNet)使用详解
之前章节讲到的ControlNet应用,都是只使用一个ControlNet模型进行控制。
当然的,我们还可以叠加多个ControlNet模型有助于更加精细化的控制,从而有助于更好的提升SD/FLUX生成图像的效果。同时我们需要注意的是多个ControlNet并不需要联合训练,都是独立训练即可。所以我们在实际使用中,可以开启多个ControlNet对图像的生成过程进行多条件的控制(本质上将多个ControlNet的输出特征相加并送入SD的Decoder中)。
假如我们想对一张图片中的人物姿态和背景分别进行控制,就可以分别配置OpenPose模型和Depth模型对人物姿态和背景结构进行提取与控制,并生成相同姿态和背景结构的新人物内容与新背景风格。
除此此外,我们在保持种子(seed)相同的情况下,固定出画面结构和风格,然后定义人物不同姿态,渲染后进行多帧图像拼接,就能生成一段动画啦。
下面是一个简单的使用多个ControlNet的例子:
并且ControlNet还可以与其他的Adapter组合在一起使用,比如IP-Adapter、PULID、InstantID、AnimateDiff等。
8. 从0到1上手基于Stable Diffusion/FLUX.1训练自己的ControlNet模型(全网最详细讲解)
在本章节中,Rocky将带着大家完整走通ControlNet的训练流程。首先,我们了解一下官方训练ControlNet模型所需的数据量和算力资源: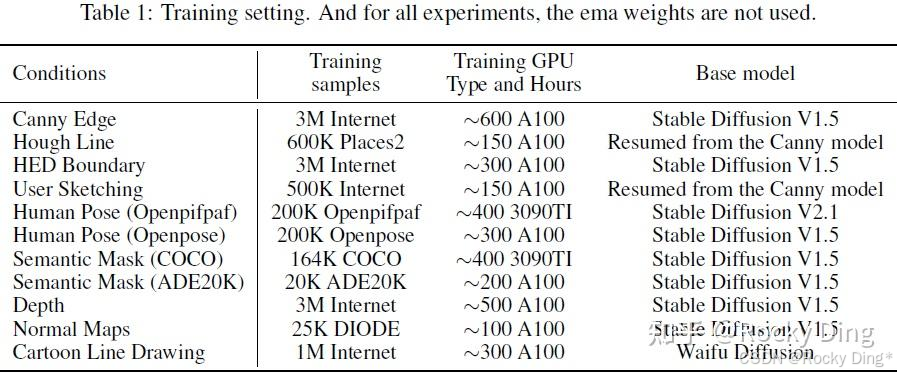
我们可以看到,与直接训练Stable Diffusion(SD)模型相比,ControlNet的训练并不需要非常大规模的数据量,从最少的20K到最多的3M,这相比SD的训练数据量(B级别)要少很多。同时训练成本也不是很高,训练时间最长的Canny Edge模型也只需要600 A100卡时,如果我们有一台8卡A100机器,则只用训练3天左右。从训练数据量和训练时长看,ControlNet的训练是非常高效的。
此外, ControlNet论文中还发现ControlNet的训练并不是渐进的,而是存在突变点。 如下图所示,在Batch_Size设置为4的情况下, 在训练了6133个step后,ControlNet模型突然学到了Condition条件控制能力 。这大概率和zero初始化有关,ControlNet模型需要一定的时间让这些zero初始化的模块进行参数的学习适配,总的来说大约在3k到7k步时就能得到一个基本可用的ControlNet模型: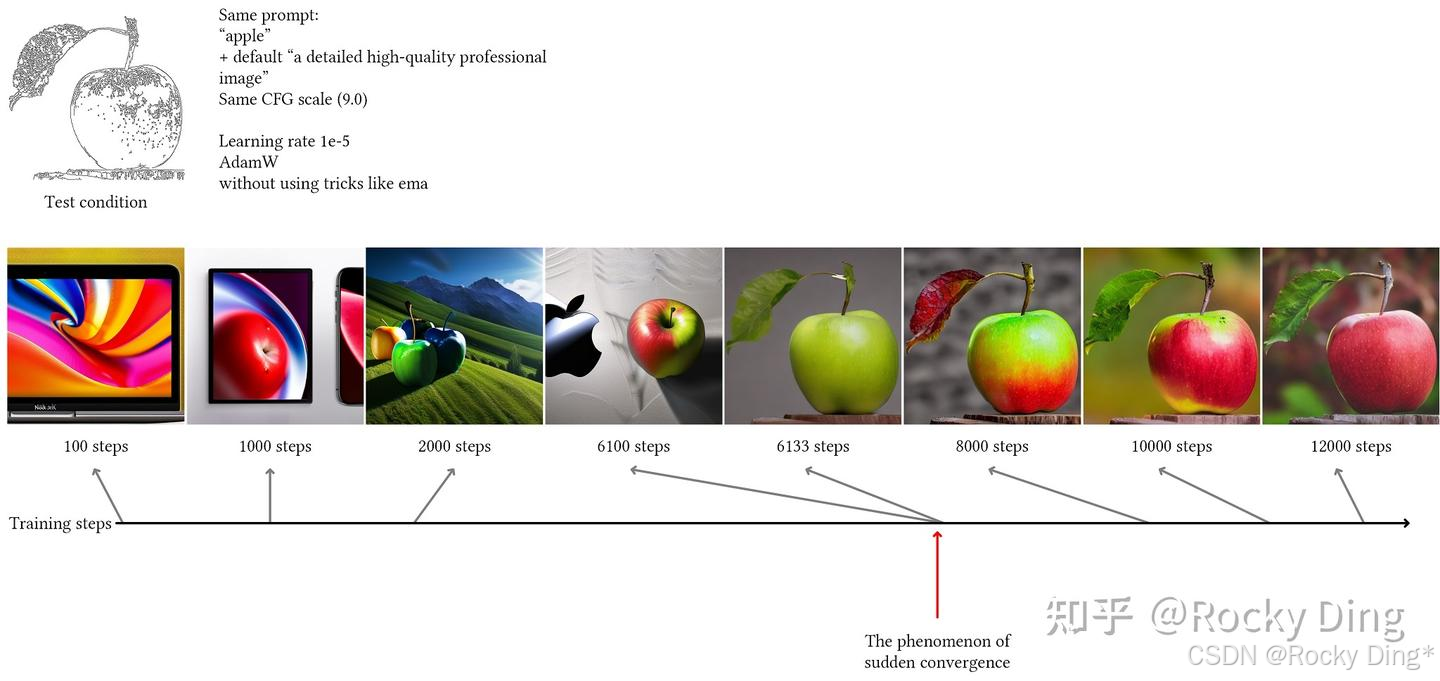
同时, 官方在训练过程中发现相比于训练迭代次数,增大Batch_Size(64、96、128或者256)更有助于ControlNet模型整体性能的提升 。
好的,到目前为止,我们已经了解了训练ControlNet模型所需的数据规模、算力资源以及训练特点。总体上看, 我们可以发现训练ControlNet模型和在传统深度学习时代中训练一个pix2pix模型有着相似的逻辑 。
接下来如果我们想要训练自己的ControlNet模型,我们首先需要固定一个Stable Diffusion/FLUX.1作为底模型。就让大家跟随着Rocky的脚步,一起来完成完整的ControlNet训练过程。
8.1 ControlNet训练资源分享
- Diffusers框架的ControlNet训练脚本: diffusers/examples/controlnet
- 官方ControlNet训练脚本: lllyasviel/ControlNet/train.md
- FLUX.1 ControlNet训练脚本: XLabs-AI/x-flux/train_flux_deepspeed_controlnet.py
- ControlNet模型训练数据集 百度云网盘 :关注Rocky的公众号 WeThinkIn, 后台回复: ControlNet训练数据集 ,即可获得干货数据集资源。
8.2 ControlNet模型训练脉络初识
ControlNet系列模型的训练流程主要分成以下几个步骤:
- 设计我们想要的额外控制条件: 除了上面章节中讲到的控制条件,我们还可以根据实际需求自定义一些控制条件,从而使用ControlNet控制Stable Diffusion/FLUX.1朝着我们想要的 细粒度方向生成内容 。
- 构建训练数据集: 确定好额外控制条件后,我们就可以开始构建训练数据集了。ControlNet数据集中 需要包含三个维度的信息:Ground Truth图片、作为控制条件(Conditional)的图片,以及对应的Caption标签 。
- 训练我们自己的ControlNet模型: 训练数据集构建好后,我们就可以开始训练自己的ControlNet模型了,我们需要一个至少8G显存的GPU才能满足ControlNet模型的训练要求。
在接下来的章节中,Rocky将为大家讲解上述每个流程的核心知识。
8.3 设计ControlNet的额外控制条件
我们设计ControlNet额外控制条件的过程可以说是整个训练流程中最重要的一环了, 因为控制条件设计的好与坏,直接影响到我们训练的ControlNet模型的易用性以及在开源社区爆火的可能性 。
我们可以从以下两方面思考如何设计ControlNet的额外控制条件:
- 我们需要哪些控制条件?哪些控制条件可以满足我们的实际需求? 比如电商场景的模特图控制,我们需要设计手部生成的控制条件;再比如泛娱乐场景,我们需要根据热点信息,设计对应的生成控制条件。
- 在确定好控制条件后, 我们需要确定将Ground Truth图片(原图)转换成控制条件(Conditional)图片的算法和模型 。
在这里,Rocky拿人脸关键点作为控制条件举例。
人脸关键点控制可以应用在AIGC图像生成/AI绘画领域几乎所有的场景中,是一个穿越周期的经典计算机视觉任务,所以训练人脸关键点ControlNet模型是有价值的 。接下来我们需要获取训练数据中的人脸关键点信息,作为控制条件(Conditional)数据,我们可以使用传统深度学习时代的人脸关键点检测模型(InsightFace等)来提取人脸关键点信息。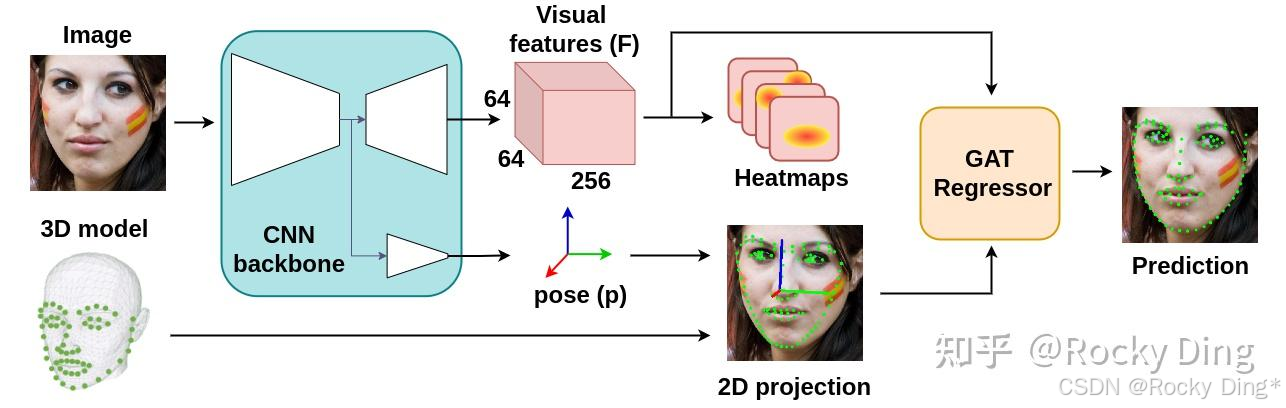
8.4 构建ControlNet训练数据集
在之前我们已经讲到ControlNet的训练数据集需要包含Ground Truth图片、作为控制条件(Conditional)的图片,以及对应的Caption标签三个方面。
我们已经了解了如何在Ground Truth原图的基础上设计额外控制条件和对应的控制条件(Conditional)的图片,接下来,我们需要对这些数据进行Caption标注,来形成完整的ControlNet训练数据集。
当前主流的Caption自动化标注模型有joy-caption、Florence、Moondream2、WD14、BLIP、Janus等 ,大家可以选择与自己细分领域匹配的模型进行标注。
8.5 ControlNet模型训练
在我们完成了ControlNet的额外控制条件设计和ControlNet训练数据集构建后,我们就可以训练我们自己的ConttrolNet模型了!
我们需要先下载diffuser项目,并且安装相应的依赖库:
pip transformers accelerate xformers==0.0.16
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
pip install -r requirements.txt
然后我们进入diffusers项目的 “/本地路径/diffusers/tree/main/examples/controlnet”路径下 ,运行train_controlnet.py脚本即可进行ControlNet模型的训练。
当然的,我们需要配置一些训练参数并传入这个脚本中,才能让我们的训练过程取得一个较好的效果,具体的训练参数如下所示:
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="/本地路径/stable-diffusion-v1-5" \
--output_dir="WeThinkIn_ControlNet_model" \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=1024 \
--learning_rate=1e-5 \
--validation_image "./face_landmarks1.jpeg" "./face_landmarks2.jpeg" "./face_landmarks3.jpeg" \
--validation_prompt "High-quality close-up dslr photo of man wearing a hat with trees in the background" "Girl smiling, professional dslr photograph, dark background, studio lights, high quality" "Portrait of a clown face, oil on canvas, bittersweet expression" \
--train_batch_size=4 \
--num_train_epochs=3 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000
我们可以将上述的代码与参数写到后缀为Train_ControlNet.sh的shell文件中,并且命令行使用如下命令启动训练脚本,这样更加方便,修改参数也更加灵活:
sh Train_ControlNet.sh
下面Rocky为大家依次讲解上面各个超参数的作用:
- pretrained_model_name_or_path: 指定Stable Diffusion主模型的路径,可以选择Stable Diffusion 1.x、Stable Diffusion 2.x、Stable Diffusion XL系列,未来还将支持Stable Diffusion 3和FLUX.1系列模型。
- output_dir: 这个路径用于保存训练好的ControlNet模型。
- dataset_name: 指定用于训练的数据集名称。
- conditioning_image_column、image_column和caption_column: 这三个超参数分别用于指定数据集中的控制条件图像、GroundTruth图像和数据标签这三列的名称。训练过程中将使用这些条件数据用于ControlNet模型的学习。
- resolution: 设置训练图像(包含GroundTruth图像和条件图像)的分辨率。一般来说,分辨率设置的越大,训练效果越好;同时也会增加显存占用。
- learning_rate: ControlNet训练时的学习率。默认设置为1e-5。根据训练任务的复杂度不同,我们也可以在1e-4到2e-6之间进行调整。
- validation_image和validation_prompt: 这两个超参数用于中途验证ControlNet模型的训练效果。可以通过定期的验证来检查ControlNet模型是否出现过拟合的情况。每隔
validation_steps步的训练后,会使用当前的最新ControlNet模型和验证提示词生成验证图片,我们可以直观的查看当前的训练效果。 - train_batch_size: 设置训练batch size的大小。当显存较小(比如8GB)时,可以设batch size=1。
- num_train_epochs: 设置ControlNet模型训练的Epoch。
- checkpointing_steps: 如果设置checkpointing_steps=5000,那么每训练5000步就会保存一次模型的中间结果。
- validation_steps: 设置训练时模型验证的频率。
使用上述的参数配置进行训练,需要38G左右的显存 。对于一些算力资源较为紧张的读者,Rocky这边推荐一些优化显存的超参数配置,可以让我们在16G的算力资源上从容的进行ControlNet训练:
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
首先我们可以减小train_batch_size,同时使用4步的梯度累计(gradient_accumulation_steps),这样等同于我们使用了batch size为4进行训练。 其中的主要原理是通过多次前向传播(4次)累积梯度,然后再进行一次反向传播,从而减少显存占用 。除此之外,我们开启了gradient_checkpointing和8bit的Adam优化器进行训练。经过上述的优化, 我们可以在16G左右的显卡上进行ControlNet训练 。
接下来我们还能再进行优化, 让我们在12G的显存上进行ControlNet的训练 ,还需要使用下面的一些优化技术:
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="/本地路径/stable-diffusion-v1-5" \
--output_dir="WeThinkIn_ControlNet_model" \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none
训练完成后,我们就可以使用自己的ControlNet模型进行图像的控制生成了!
ControlNet基于ComfyUI、Diffusers以及Stable Diffusion WebUI的完整推理流程,Rocky在第六章节中已经详细阐述,大家可以按需学习取用。
9. 从0到1上手构建ControlNet高级应用(100大商用案例)
在本章节中, Rocky将持续为大家讲解分享最前沿高价值的包含类ControlNet的AIGC图像生成/AI绘画商业落地应用案例,不管是工业界、学术界、竞赛界还是应用界,都能从中获得更多灵感和启发 。
Rocky将会持续补充本章内容,大家敬请期待,希望大家能点个赞,支持一下Rocky的义务劳动!
9.1 专业AIGC人像控制生成
【AIGC人像美颜/精修/磨皮/美白】
可以基于AIGC图像生成/AI绘画工作流(Workflow)实现人像美颜/精修/瘦脸/磨皮/美白/祛痘等后期人脸修复/精修/增强的算法功能。
一般想要实现这个系统性AIGC图像生成算法功能, 我们需结合了多个AIGC大模型和配套AIGC辅助技术工具 ,来综合实现对人物面部的精细化修复/精修/增强,比如:
- 智能面部遮罩生成: 包含图像分割技术、皮肤提取技术、人脸五官提取技术等。
- 局部重绘: 图像裁剪和重采样技术、Stable Diffusion/FLUX大模型重绘、图像融合技术等。
- ControlNet控制: 姿态控制、细节控制、图像结构控制、与LoRA相结合增强美颜效果、与PULID、IP-Adapter、Instant-ID等可控生成技术相结合等。
- 超分辨率重建增强: GAN技术、SUPIR超分增强技术、UltimateSDUpscale细节增强技术等。
- 提示词工程: 文本翻译技术、自动提示词生成技术、正面/负面提示词撰写技术等。
- AIGC核心大模型: FLUX.2、FLUX.1 Kontext、FLUX.1、SD 3、SDXL、SD1.5等多种模型选型,核心大模型微调训练、核心大模型架构优化等。
【AIGC人像换脸/人像写真】
我们想要构建一个高度专业化、自动化的 AIGC人像换脸/人像写真算法功能 ,依旧可以 基于ComfyUI工作流实现 ,其 核心目标 是: 将一张“人脸参考图”中的面部身份(Identity),精准、高质量地“嫁接”到另一张“电商/场景/海报/宣传图”中的人物面部上,同时保持原始海报的整体构图、风格、光照和细节不被破坏,其整个功能逻辑包含:
- 身份替换 : 将目标图像中人物的面部,替换为用户指定人物的面部(来自参考图)。
- 高保真度 : 生成的面部不仅形似,还要在 皮肤质感、高清细节 上达到专业级水准。
- 无缝融合 : 换脸后,新面部的 颜色、光影、色调 必须与原海报环境完美融合,无粘贴感。
- 构图保持 : 绝对保留原图像的 姿势、角度、发型轮廓、背景及艺术风格 ,仅改变面部身份。
- 流程自动化 : 用户只需提供两张输入图(人脸图 + 原图),即可全自动输出高质量成品,极大简化操作。
AIGC人像换脸/人像写真的核心技术模块梳理:
- 输入与预处理: 人脸参考图提供身份来源; 目标场景图作为 被替换脸部的原始图像;预处理用于参考图和场景图的特征提取等。
- 智能人脸交换与身份注入(核心): InsightFace系列模型、InstantID系列模型、ControlNet系列模型、 IP-Adapter技术、PULID技术。
- AIGC核心大模型: FLUX.2、FLUX.1 Kontext、FLUX.1、SD 3、SDXL、SD1.5等多种模型选型,核心大模型微调训练、核心大模型架构优化等。
- 精准面部蒙版生成与局部重绘: 智能语义分割;脸部区域蒙版、蒙版裁剪、扩展、模糊边缘等后处理;图像生成。
- 颜色校正与融合: 将换脸后的结果图,与 原始目标海报图 进行颜色匹配(使用 LAB 色彩空间),它使新脸部的肤色、色调与环境光统一,消除颜色差异导致的“不真实感”。
- 高清超分辨率修复: GAN技术、SUPIR超分增强技术、UltimateSDUpscale细节增强技术、ColorMatch等。
9.2 专业AIGC虚拟换装控制生成
【AIGC模特虚拟换装】
AIGC模特虚拟换装(Virtual Try-on) 一直是AI行业落地应用的痛点,我们想要构建一个AIGC 虚拟试衣解决方案 ,需要通过复杂精细的多阶段处理流程(精确抠图、图像融合、纹理修复、高清放大鞥)和先进的AIGC大模型共同构建,力求在 保持模特原有姿势和背景的前提下 ,实现 高质量、无违和感的服装替换 。
AIGC模特虚拟换装工作流核心技术模块梳理:
- 加载模特图和服装图: 输入模特图像和服装透底图( 白底、清晰、无褶皱 的服装图片)。
- 智能抠图与融合 : 图像分割技术、图像抠图技术、制作遮罩、视觉大模型、风格模型等,进行高质量的局部修复和服装融合。
- 纹理修复 : 分块采样技术解决深色服装常见的横纹问题、色彩调整技术等。
- 高清超分辨率修复: GAN技术、SUPIR超分增强技术、UltimateSDUpscale细节增强技术、ColorMatch等。
- 自动化提示词 : 文本翻译技术、自动提示词生成技术、正面/负面提示词撰写技术等。
【AIGC模特一键换背景】
AIGC模特一键换背景算法功能基于 ComfyUI工作流构建后,其核心是在 一键换背景的同时保留人物服饰细节 。
AIGC模特一键换背景算法功能核心技术模块梳理:
- 模特人物提取: BrushNet模型、分割模型、抠图模型等。
- 新背景生成: 生成 与人物服装细节匹配 的新背景。
- 光影效果生成: ICLight、ControlNet等技术 模拟环境光照,生成 光影统一、融合自然 的背景。
- 模特与背景智能合成: CintrolNet控制生成、背景细节修复技术、风格迁移技术等。
- AIGC核心大模型: FLUX.2、FLUX.1 Kontext、FLUX.1、SD 3、SDXL、SD1.5等多种模型选型,核心大模型微调训练、核心大模型架构优化等。
- 高清超分辨率修复: GAN技术、SUPIR超分增强技术、UltimateSDUpscale细节增强技术等。
9.3 专业AI泛娱乐热门应用案例
【AIGC扩图应用】
AIGC扩图应用的核心技术是Outpainting ,与 Inpainting 相反,可以根据现有图像的内容、风格和上下文,生成与原图相协调的新内容,从而扩展图像的语意范围。
关于AI扩图的详细工作流,Rocky已经在本文的7.12章节详细讲解,感兴趣的读者可以到对应章节学习了解。
目前AI扩图技术时常在社交媒体上火爆出圈,带来很多流量。但整体上看,AI扩图应用的实时处理能力还有待提升,并且想要生成的图像质量越高,需要的时间就更多。与此同时,不过AI扩图后的新图片整体内容是否符合逻辑,目前还是比较随机的。 但有时候正是这种离谱的结果,也是AI扩图“创造性”的体现,给网友们带来了不少的欢乐 。
【AIGC图像超分放大/增强】
这里包含了两种任务逻辑,分别是超分放大和超分增强。是两个紧密相关但目标不同的核心任务,简单来说:
- 图像超分辨率: 主要解决 “尺寸小” 的问题,目标是 增大图像的像素尺寸 。
- 图像增强: 主要解决 “质量差” 的问题,目标是 提升图像的视觉质量或信息价值 。
图像超分辨率的 核心目标:从低分辨率图像生成高分辨率图像。 这里的“高分辨率”直接指代 更多的像素数量 (例如从 256x256 放大到 1024x1024)。
图像增强的 核心目标:改善图像的视觉外观或为后续分析任务优化图像。 它不必然改变图像尺寸,而是针对图像存在的 各种退化问题 进行处理。根据缺陷不同,增强的目标也不同:
- 去噪:去除图像中的随机噪声。
- 去模糊:恢复因相机抖动或对焦不准导致的模糊。
- 去雾/去雨:消除天气因素造成的对比度下降和干扰。
- 对比度/亮度增强:改善整体观感。
- 色彩校正:修复颜色偏差。
- 锐化:增强边缘清晰度。
在传统深度学习时代, 超分 和 增强 是界限相对清晰的两个子方向。但在 ControlNet 为代表的AIGC时代,两者的界限正在模糊。AIGC时代的“超分增强”更像是一个 感知驱动、内容生成 的任务——它不只是“恢复”丢失的信息,更是利用强大的生成先验,去“创造”出令人信服的高质量细节,最终输出一张 既大又美 的图像。
| 特性 | 图像超分辨率 | 图像增强 | 图像超分增强(联合任务) |
|---|---|---|---|
| 首要目标 | 增加像素数量(放大尺寸) | 提升视觉/信息质量(去噪、去模糊等) | 同时达成:大尺寸 + 高质量 |
| 处理对象 | 主要是干净的LR图像 | 有特定质量问题的图像(尺寸可能不变) | 质量差且尺寸小的图像 |
| 输出焦点 | 全局结构保真,生成合理的新像素 | 修复现有像素的质量问题 | 生成全新的、高质量的细节,局部“重绘” |
| 核心挑战 | 解决从低维到高维映射的不适定性 | 逆向特定的退化过程 | 联合建模多重退化与细节生成 |
| 主流模型 | AuraSR、SUPIR、R-ESRGAN | ControlNet Tile+ SD/SDXL/SD 3/FLUX.1-2 | AuraSR、SUPIR、R-ESRGAN + ControlNet Tile + SD/SDXL/SD 3/FLUX.1-2 |
| 类比 | 把小邮票内容画到大画布上 | 把旧照片清洁、修复 | 根据一张小破草图,重新绘制一幅精美的大画 |
10. 推荐阅读
Rocky会持续分享AIGC的干货文章、实用教程、商业应用/变现案例以及对AIGC行业的深度思考与分析,欢迎大家多多点赞、喜欢、收藏和转发,给Rocky的义务劳动多一些动力吧,谢谢各位!
10.1 深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
和Rocky一起学习探究扩散模型的本质原理与和核心基础知识,同时不断跟进扩散模型的最新发展。Rocky在本文中对扩散模型的本质做了全面系统的梳理与讲解:
深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
10.2 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2025年可以说是AI Agent全面落地应用的元年,因此Rocky在持续撰写对AI Agent的全维度解析文章:
深入浅出完整解析AI Agent(AI智能体)的核心基础知识
10.3 深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
Rocky也对FLUX.1 Kontext和FLUX.1 Krea的核心基础知识作了全面系统的梳理与解析:
深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
10.4 深入浅出完整解析DeepSeek系列核心基础知识
Rocky也对DeepSeek系列模型的核心基础知识作了全面系统的梳理与解析:
10.5 深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
Rocky也对Stable Diffusion 3和FLUX.1的核心基础知识作了全面系统的梳理与解析:
深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
10.6 深入浅出完整解析Stable Diffusion XL核心基础知识
在此之前,Rocky也对Stable Diffusion XL的核心基础知识作了比较系统的梳理与总结:
深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
10.7 深入浅出完整解析Stable Diffusion核心基础知识
当然的,Rocky也对Stable Diffusion的核心基础知识作了比较系统的梳理与总结:
深入浅出完整解析Stable Diffusion(SD)核心基础知识
10.8 深入浅出完整解析Stable Diffusion中U-Net核心基础知识
同时对Stable Diffusion中最为关键的U-Net结构进行了深入浅出的分析,包括其在传统深度学习中的形态和AIGC中的形态:
深入浅出完整解析Stable Diffusion中U-Net的前世今生与核心知识
10.9 深入浅出完整解析LoRA核心基础知识
对于AIGC时代中的“ResNet”——LoRA,Rocky也进行了讲解,大家可以按照Rocky的步骤方便的进行LoRA模型的训练,繁荣整个AIGC生态:
深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
10.10 深入浅出完整解析Sora等AI视频大模型核心基础知识
AI绘画和AI视频是两个互相促进、相互交融的领域,2024年无疑是AI视频领域的爆发之年,Rocky也对AI视频领域核心的Sora等大模型进行了全面系统的梳理与解析:
深入浅出完整解析Sora、Wan2.1、AnimateDiff、CogVideoX等AI视频大模型核心基础知识
10.11 深入浅出完整解析AIGC时代Transformer核心基础知识
在AIGC时代中,Transformer为AI行业带来了深刻的变革。Transformer架构正在一步一步重构所有的AI技术方向,成为AI技术架构大一统与多模态整合的关键核心基座,大有一统“AI江湖”之势。Rocky也对Transformer模型进行持续的深入浅出梳理与解析:
深入浅出完整解析AIGC时代Transformer核心基础知识
10.12 深入浅出完整解析主流AI绘画框架核心基础知识
AI绘画框架正是AI绘画“工作流”的运行载体,目前主流的AI绘画框架有Stable Diffusion WebUI、ComfyUI以及Fooocus等。在传统深度学习时代,PyTorch、TensorFlow以及Caffe是传统深度学习模型的基础运行框架,到了AIGC时代,Rocky相信Stable Diffusion WebUI就是AI绘画领域的“PyTorch”、ComfyUI就是AI绘画领域的“TensorFlow”、Fooocus就是AI绘画领域的“Caffe”:
深入浅出完整解析主流AI绘画框架(ComfyUI、Stable Diffusion WebUI、Fooocus)核心基础知识
10.13 手把手教你如何成为AIGC算法工程师,斩获AIGC算法offer!
在AIGC时代中,如何快速转身,入局AIGC产业?成为AIGC算法工程师?如何在学校中学习AIGC系统性知识,斩获心仪的AIGC算法offer?
Don‘t worry,Rocky为大家总结整理了全维度的AIGC算法工程师成长秘籍,为大家答疑解惑,希望能给大家带来帮助:
手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2025年版)
10.14 AIGC产业深度思考与分析
2023年3月21日,微软创始人比尔·盖茨在其博客文章《The Age of AI has begun》中表示,自从1980年首次看到图形用户界面(graphical user interface)以来,以OpenAI为代表的科技公司发布的AIGC模型是他所见过的最具革命性的技术进步。
Rocky也认为,AIGC及其生态链,会成为AI行业重大变革的主导力量。AIGC会带来一个全新的红利期,未来随着AIGC的全面落地和深度商用,会深刻改变我们的工作,生活,学习以及交流方式,许多行业都将被重新定义,过程会非常有趣。
2023年的“疯狂三月”,世界上主要科技公司与研究机构们争先恐后发布关于AIGC的最新进展,让人目不暇接,吃瓜群众们纷纷惊呼不已。那么,在狂欢过后,我们该如何更好的审视AIGC的未来?我们该如何更好地拥抱AIGC引领的革新?接下来Rocky准备从技术,产品,长期主义等维度分享一些个人的核心思考与观点,希望能帮助各位读者对AIGC有一个全面的了解。
深入浅出全面解析AIGC时代核心价值与发展趋势(2025年版)
10.15 算法工程师的独孤九剑秘籍
为了便于大家实习,校招以及社招的面试准备与技术基本面的扩展提升,Rocky将符合大厂和潜力独角兽价值的算法高频面试知识点撰写总结成《三年面试五年模拟之独孤九剑秘籍》,并制作成pdf版本,大家可在公众号WeThinkIn后台【精华干货】菜单或者回复关键词“三年面试五年模拟”进行取用。
【三年面试五年模拟】AIGC时代的算法工程师的求职面试秘籍(持续更新中)
10.16 深入浅出完整解析AIGC时代中GAN系列模型的前世今生与核心知识
GAN网络作为传统深度学习时代的最热门生成式Al模型,在AIGC时代继续繁荣,作为Stable Diffusion系列模型的“得力助手”,广泛活跃于Al绘画的产品与工作流中:
深入浅出完整解析AIGC时代中GAN(Generative Adversarial Network)系列模型核心基础知识
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于AI行业话题的讨论与研究,包括但不限于算法、开发、竞赛、科研以及工作求职等。群里有很多AI行业的大牛,欢迎大家入群一起交流探讨~(请备注来意,添加小助手微信Jarvis8866,邀请大家进群~)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)