OpenCSG开源数据贡献:构建AI时代的中文数据基石
OpenCSG的Chinese Fineweb Edu系列数据集,不仅仅是两个数据集的发布,更代表了一种以质量为先、以应用为导向的开源理念。从v1到v2的迭代,我们看到OpenCSG对数据质量的持续追求——从90M到188M条数据,从10万到100万条训练样本,从单一打分模型到更强大的V2版本。每一次升级,都是对"如何构建高质量中文教育数据"这一问题的深入探索。开源的力量在于共建共享。
引言:为什么大模型需要"好数据"?
在人工智能快速发展的今天,一个有趣的发现正在改变大模型的训练方式:LLM从教育内容中学习会更好更快。这并非凭空猜测,而是Llama3、Phi3等顶尖模型训练过程中验证的核心经验。
想象一下,如果让一个学生同时阅读教科书和充斥广告、垃圾信息的网页,哪种内容更能帮助他建立系统的知识体系?答案显而易见。对于大语言模型来说,道理完全相同。普通的互联网爬取内容价值参差不齐——奇怪的数据转储、广告垃圾邮件、无关的股票行情更新,这些"噪音"会分散模型的"注意力",影响其学习效果。
教育级数据的价值在于:它们结构清晰、逻辑连贯、知识密集,能够帮助模型更高效地学习推理能力和知识表达方式。正如AI大牛Andrej Karpathy所说,挑战在于从海量互联网内容中挑出"钻石"——那些真正有价值的教育内容。
OpenCSG正是基于这一理念,推出了Chinese Fineweb Edu系列数据集,为中文大模型提供了高质量的"教科书级"训练素材。
Fineweb系列的起源:开创性的教育数据筛选
HuggingFace的FineWeb-Edu
2024年5月,HuggingFace团队推出了FineWeb数据集——一个包含15万亿token(44TB磁盘空间)的大规模预训练数据集,源自96个CommonCrawl快照。更重要的是,他们在此基础上发布了FineWeb-Edu子集,这是一个专注于教育内容的1.3万亿token数据集。
FineWeb-Edu的创新之处在于:使用Llama-3-70B-Instruct大模型对50万条样本进行教育价值评分,然后训练一个专用分类器,将这一评估能力扩展到整个数据集。实验结果令人振奋:在MMLU基准测试上,使用FineWeb-Edu训练的模型准确率从33%提升到37%(相对提升约12%);在ARC推理基准上,性能从46%跃升至57%(提升24%)。
这一工作证明了教育数据筛选的巨大价值,也为OpenCSG团队提供了重要启发。
中文教育数据的空白
然而FineWeb-Edu主要针对英文内容。中文领域长期面临高质量教育数据稀缺的问题——虽然国内有CCI2-Data、SkyPile-150B等数据集,但质量参差不齐,缺乏系统的教育价值筛选。这一空白直接制约了中文大模型在教育、知识密集型任务上的表现。
OpenCSG算法团队决定填补这一空白,将FineWeb-Edu的成功经验引入中文领域,构建了Chinese Fineweb Edu系列数据集。
数据集整合了国内外优质中文网络资源:
Chinese Fineweb Edu v1:国内首个教育级预训练数据集
数据集核心特点
2024年9月,OpenCSG正式发布Chinese Fineweb Edu v1,这是国内首个对标国际标准的高质量中文教育预训练数据集。
核心指标:
-
数据规模:约9000万条(90M)高质量中文文本
-
总容量:约300GB精选内容
-
数据来源:融合CCI2-Data、SkyPile-150B、IndustryCorpus、TeleChat-PTD、MAP-CC五大权威数据集
-
教育价值:专为教育领域NLP任务和大模型预训练优化
为什么要做教育筛选?
教育内容vs普通网页的价值差异体现在:
教育内容的特征:
-
结构清晰,逻辑连贯
-
知识密集,信息价值高
-
语言规范,表达准确
-
适合系统性学习
普通网页的问题:
-
充斥广告和宣传材料
-
内容碎片化,缺乏深度
-
大量重复和无关信息
-
语言质量参差不齐
OpenCSG采用六级教育价值评分体系(0-5分),对每条数据进行精细评估:
-
0分:无任何教育价值,完全由广告等无关信息组成
-
1分:提供基本教育相关信息,但包含较多无关内容
-
2分:涉及教育元素,但与标准不太吻合,内容浅显或不连贯
-
3分:适合教育使用,介绍了与学校课程相关的关键概念,内容连贯但可能不全面
-
4分:高度相关且有益于中学水平教育,写作风格清晰,提供大量教育内容,极少无关信息
-
5分:教育价值卓越,完全适合小学或中学教学,推理详细,易于理解,提供深刻全面的见解
只有得分4分以上的数据才会被保留,这确保了数据集的高质量标准。
三层质量保障体系
Chinese Fineweb Edu v1采用“大模型+专用模型+去重”三层筛选机制:
第一层:大模型教育价值评估使用OpenCSG自研的csg-wukong-enterprise企业版大模型作为打分模型,对海量样本进行初步教育价值评分。从中选取约10万条高分样本作为种子数据。
第二层:专用BERT模型规模化筛选将10万条标注数据用于训练fineweb_edu_classifier_chinese专用BERT模型。这个轻量级模型继承了大模型的评判标准,可以高效处理TB级数据,仅保留得分>4的高质量内容。
第三层:MinHash去重处理采用MinHash算法对筛选后的数据进行去重,确保数据独特性和多样性,避免重复内容对模型训练产生负面影响。
如何用于模型训练?
Chinese Fineweb Edu v1主要应用于以下场景:
-
大模型预训练 作为预训练阶段的主要或辅助数据源,帮助模型建立扎实的知识基础和推理能力。相比使用普通网页数据,教育数据能让模型更快收敛,学到更系统的知识表达方式。
-
知识密集型任务 特别适合训练需要深度理解和推理的模型,如:教育问答系统、知识图谱构建、学术文本生成、智能辅导应用
-
领域迁移学习 当将通用模型微调到特定领域时,使用教育数据可以减缓模型"遗忘"通用能力的速度,保持推理能力的同时适应新领域。
训练效果验证:消融实验
OpenCSG团队进行了严格的消融实验来验证数据集质量。实验设计如下:
实验设置:
-
模型规模:2.1B参数
-
训练步数:65,000步
-
对比数据集:
-
实验组:Chinese Fineweb Edu v1
-
对照组:从五大数据集随机抽取相同比例样本(chinese-random-select)
-
-
评测基准:CEval和CMMLU(两大中文评测标准)
实验结果:
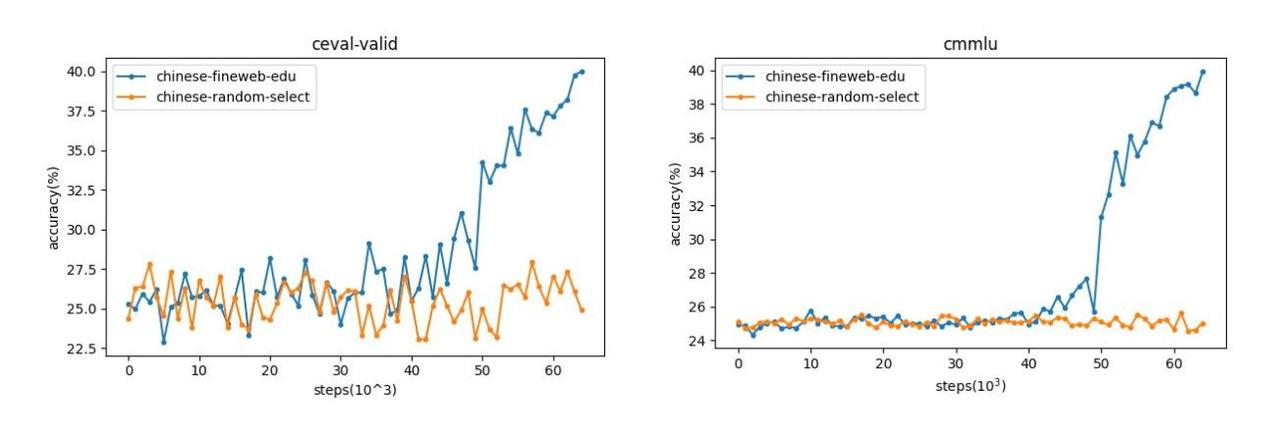
在训练初期,两组数据表现相近。但进入训练后期(第2个epoch,学习率快速下降阶段),使用Chinese Fineweb Edu训练的模型准确率显著上升,而使用随机数据训练的模型停滞在较低水平。
这一结果清晰证明:Chinese Fineweb Edu具有更高的数据质量,能够在相同训练时间下更快提升模型的推理和知识能力。这与英文版FineWeb-Edu的表现完全一致,验证了教育数据筛选方法的有效性。
性能表现
使用Chinese Fineweb Edu v1训练的1.8B参数模型在多个中文基准测试上表现优异:
Chinese Fineweb Edu v2:数据规模与质量的双重飞跃
重磅升级亮点
2024年10月,OpenCSG推出Chinese Fineweb Edu v2,这是对v1的全面升级,实现了数据规模和质量的双重突破。
核心升级指标:
-
数据规模:从90M条增至188M条,翻倍增长
-
Token数量:约420B tokens,是v1的显著提升
-
数据来源:新增Industry2、CCI3、michao、wanjuan1.0、wudao、ChineseWebText等高质量数据集
-
打分模型:升级为更强大的csg-wukong-enterprise V2
-
训练数据:打分模型训练数据从10万条增至100万条,涵盖书籍、新闻、博客等多种文本类型,包含25%英文数据
更强大的打分模型
v2版本的核心突破在于打分模型的全面升级。新的csg-wukong-enterprise V2模型具有:
-
更大参数量:提升语义理解深度
-
更丰富训练数据:100万条多类型文本,覆盖面更广
-
更精准评估能力:特别在中文文本理解和教育价值判断上表现出色
-
更细致的分析:能够捕捉文本结构、内容质量和深层语义信息
这意味着v2的数据筛选更加精准,能够识别出更多真正具有教育价值的内容,同时过滤掉更多低质量数据。
Prompt优化与评分标准
v2版本对评分Prompt进行了优化,新的评分标准更加明确地强调了写作水平、教育价值和实用性三个维度:
评分过程会综合考虑:文本的结构化程度、知识的系统性和深度、语言的规范性和易理解性、内容对教育场景的适配性
通过csg-wukong-enterprise V2模型评分后,v2选取了3分以上的文本(相比v1的4分以上),这一调整在保证质量的同时,进一步扩大了数据规模,最终达到188M条数据、420B tokens的规模。
数据来源的大幅扩展
v2在v1的五大数据源基础上,新增了六个高质量数据集:
新增数据源:
-
Industry2:扩展的行业语料,覆盖更多垂直领域
-
CCI3:升级版的高质量安全数据
-
michao:专业领域数据补充
-
wanjuan1.0:多样化的中文语料
-
wudao:大规模知识图谱相关数据
-
ChineseWebText:优质中文网页文本
这种多源融合策略确保了数据集的广泛适用性和内容多样性,使模型能够学习到更全面的知识和更丰富的语言表达方式。
更智能的双模型评分系统
v2版本采用创新的双模型协同评分机制:
实际应用场景
Chinese Fineweb Edu v2的高质量和大规模特性,使其在多个实际场景中发挥重要作用:
教育AI应用:智能辅导系统、自动作业批改、个性化学习、推荐教育内容生成
知识服务:智能客服(教育、医疗、法律等专业领域)、知识问答系统、文档智能处理、内容摘要与理解
模型开发:中文大模型预训练、领域模型微调、多模态模型训练(配合视觉数据)、对话系统优化
模型训练价值:为什么选择教育数据?
提升推理和知识能力
使用Chinese Fineweb Edu系列训练的模型,在多个维度表现出显著优势:
-
知识密集型基准 在MMLU(大规模多任务语言理解)、ARC(AI2推理挑战)、CMMLU(中文多任务理解)等基准测试中,使用教育数据训练的模型准确率明显高于使用普通数据的模型。
-
推理能力增强 教育内容的结构化和逻辑性,帮助模型学习到更好的推理模式。模型不仅记住知识,更能理解知识之间的关联和推理路径。
-
知识表达规范 教育数据的语言规范性,使模型学会更准确、更专业的表达方式,减少生成内容的错误和不确定性。
教育场景的天然优势
教育数据与教育场景应用存在天然的契合:
智能客服:当用户咨询专业问题时,模型能够提供结构清晰、逻辑严密的回答,而不是碎片化的信息堆砌。
内容生成:无论是生成教学材料、解释复杂概念,还是撰写报告,模型都能保持教育内容应有的严谨性和系统性。
教育AI:从作业批改到学习路径规划,模型对教育内容的深度理解,使其能够更好地服务教育场景。
对比普通数据集的优势
| 维度 | 普通网页数据 | Chinese Fineweb Edu |
| 内容质量 | 参差不齐,噪音多 | 高质量,系统化 |
| 知识密度 | 低,碎片化 | 高,结构化 |
| 训练效率 | 慢,易分散注意力 | 快,学习更聚焦 |
| 模型性能 | 基准测试表现一般 | 显著提升推理和知识能力 |
| 应用适配 | 通用但不精准 | 特别适合教育和知识场景 |
消融实验的数据清楚展示:在相同训练资源下,教育数据能让模型更快达到更好的性能。这对于计算资源有限的团队和研究者来说,意义重大。
高校和业界的认可
Fineweb-Edu-Chinese-V2.1 的卓越品质和实用价值获得了全球顶尖学术机构与行业领导者的高度认可和广泛应用。以下是采纳机构名单:
高校与研究机构: 斯坦福大学(Stanford)、清华大学(Tsinghua)、中国人民大学高瓴人工智能学院、上海人工智能实验室(Shanghai AI Lab)、北京智源研究院(BAAI)等。
企业应用: 英伟达(NVIDIA)、面壁智能(ModelBest)、中国移动、中国联通等。
结语:开源赋能,共建中文AI未来
OpenCSG的Chinese Fineweb Edu系列数据集,不仅仅是两个数据集的发布,更代表了一种以质量为先、以应用为导向的开源理念。
从v1到v2的迭代,我们看到OpenCSG对数据质量的持续追求——从90M到188M条数据,从10万到100万条训练样本,从单一打分模型到更强大的V2版本。每一次升级,都是对"如何构建高质量中文教育数据"这一问题的深入探索。
开源的力量在于共建共享。OpenCSG不仅开源了数据集,还计划开源打分模型(fineweb_edu_classifier_chinese)和标注数据,为整个社区提供完整的工具链。这种开放态度,正是推动中文AI生态发展的关键。
未来的AI,需要更好的"教育"。当我们用高质量的教育数据训练模型时,我们不仅是在提升基准测试分数,更是在让AI真正学会如何系统地理解知识、如何准确地表达思想、如何有效地服务于教育和知识场景。
我们诚邀对AI和开源技术感兴趣的开发者、研究者加入OpenCSG社区。无论是使用这些数据集训练自己的模型,还是贡献改进建议,每一份参与都将推动中文AI生态向前发展。
让我们携手,为中文AI构建更优质的"教育基础"!
数据集下载地址:
-
Chinese Fineweb Edu v1:
-
huggingface地址:https://huggingface.co/datasets/opencsg/chinese-fineweb-edu
-
opencsg社区地址:https://opencsg.com/datasets/OpenCSG/chinese-fineweb-edu
-
Chinese Fineweb Edu v2:
-
huggingface地址:https://huggingface.co/datasets/opencsg/chinese-fineweb-edu-v2
-
Chinese Fineweb Edu v2.1:
-
huggingface地址:https://huggingface.co/datasets/opencsg/Fineweb-Edu-Chinese-V2.1
-
opencsg社区地址:https://opencsg.com/datasets/AIWizards/Fineweb-Edu-Chinese-V2.1
-
OpenCSG社区:https://opencsg.com
-
GitHub组织:https://github.com/OpenCSGs
关于 OpenCSG
OpenCSG (开放传神)是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。
关于 CSGHub
CSGHub是由OpenCSG(开放传神)推出的企业级模型与数据资产管理平台,旨在为组织提供 Hugging Face 式的高效协作体验,同时满足本地化部署、数据安全与法规合规。
平台支持与 Hugging Face 工作流无缝兼容,并提供多源同步、私有镜像、全离线运行等特性,帮助企业在安全可控的环境中实现AI 研发与部署的全生命周期管理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)