[论文阅读] AI + 软件工程 | DepRadar:AI时代DL库缺陷检测神器,让静默Bug无处遁形
深度学习库(如Transformers、Megatron)已广泛应用于现代AI程序,但这些库引入的缺陷(从静默计算错误到微妙的性能退化)往往难以被下游用户评估影响。此类分析需理解缺陷语义,且需检查客户端代码是否满足含配置标志、运行环境、间接API使用的复杂触发条件。本文提出多智能体协作框架DepRadar,用于DL库更新的细粒度缺陷及影响分析。该框架协调四大专用智能体,分三步完成任务:(1)PR挖
DepRadar:AI时代DL库缺陷检测神器,让静默Bug无处遁形
论文信息
- 论文原标题:DepRadar: Agentic Coordination for Context-Aware Defect Impact Analysis in Deep Learning Libraries
- 主要作者及研究机构:
- Yi Gao(浙江大学区块链与数据安全国家重点实验室)
- Xing Hu*(浙江大学区块链与数据安全国家重点实验室,通讯作者)
- Tongtong Xu(华为杭州)
- Jiali Zhao(华为杭州)
- Xiaohu Yang(浙江大学区块链与数据安全国家重点实验室)
- Xin Xia(浙江大学区块链与数据安全国家重点实验室)
- 引文格式(GB/T 7714):Gao Y, Hu X, Xu T, et al. DepRadar: Agentic Coordination for Context-Aware Defect Impact Analysis in Deep Learning Libraries[C]//2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE ’26). Rio de Janeiro, Brazil: ACM, 2026: 1-13.
- 论文链接:https://doi.org/10.1145/3744916.3787763
- 开源地址:https://github.com/testmigrator/DepRadar
一段话总结
DepRadar是一款针对深度学习(DL)库的多智能体协作框架,通过协调PR挖掘器、代码差异分析器、协调器和影响分析器四大智能体,分三步完成缺陷语义提取、缺陷模式生成和客户端影响分析,整合静态分析与DL领域特定规则提升准确性和可解释性;在Transformers和Megatron两大DL库的227个库更新(157个PR和70个提交) 上评估,缺陷识别精度达90%、F1值95%,在122个客户端程序中影响分析召回率90%、精度80%、F1值85%,显著优于FlatLLM系列和PyCG等基线,能有效解决DL库缺陷表征嘈杂、语义鸿沟、使用场景匹配难等挑战,为下游用户精准识别潜在受影响风险。
研究背景
在AI技术飞速发展的今天,Transformers、Megatron这类深度学习(DL)库早已成为开发者手中的“必备工具”。它们封装了分词、分布式训练、内存管理等复杂功能,让开发者不用从零搭建基础架构,就能高效构建大规模AI模型。
但随着这些库的规模和复杂度不断提升,一个棘手的问题逐渐凸显:缺陷难以察觉且影响难评估。和普通软件Bug不同,DL库的缺陷往往不会直接导致程序崩溃,而是以“静默”形式存在——可能是训练时的数值微小偏差,可能是资源利用效率降低,也可能是模型收敛速度变慢。
比如Megatron的某个提交曾存在一个缺陷,导致多用户训练结果出现偏差,却在数月后才被发现;还有些缺陷会在特定硬件(如Ascend NPU)、特定配置(如启用Flash Attention v2)下才触发,下游开发者根本无从知晓自己的项目是否“中招”。
更麻烦的是,依赖升级成本极高。在DL领域,更新一次库版本可能需要重新训练模型,不仅耗时耗力,还可能引发兼容性问题。而库的发布说明通常含糊其辞,只写“修复稳定性问题”,却不说明影响哪些模块、需要什么触发条件。传统工具要么只做简单的代码语法分析,要么只能生成通用总结,无法跨越库内部修复和用户实际使用之间的“语义鸿沟”,让开发者陷入“不升级怕有Bug,升级又怕出问题”的两难境地。
创新点
- 多智能体协作架构:创新性地设计四大专用智能体分工协作,分别负责缺陷元数据提取、代码差异分析、缺陷模式合成和客户端影响验证,打破单一工具的能力局限。
- 上下文感知的渐进式分析:引入渐进式上下文增强机制,动态扩展或压缩输入信息,既解决LLM长文本处理限制,又能完整捕捉分散在PR讨论、代码差异中的缺陷信号。
- 领域规则+静态验证双保险:融合DL领域特定规则(如实体提升、参数暴露),将库内部低层级修复映射为用户可见的使用场景;同时通过AST静态验证,大幅降低LLM生成结果的“幻觉”问题。
- 兼顾PR和提交场景:不仅能处理含丰富讨论的PR,还能应对信息有限的提交记录,通用性强,适配不同DL库的开发流程。
研究方法和思路
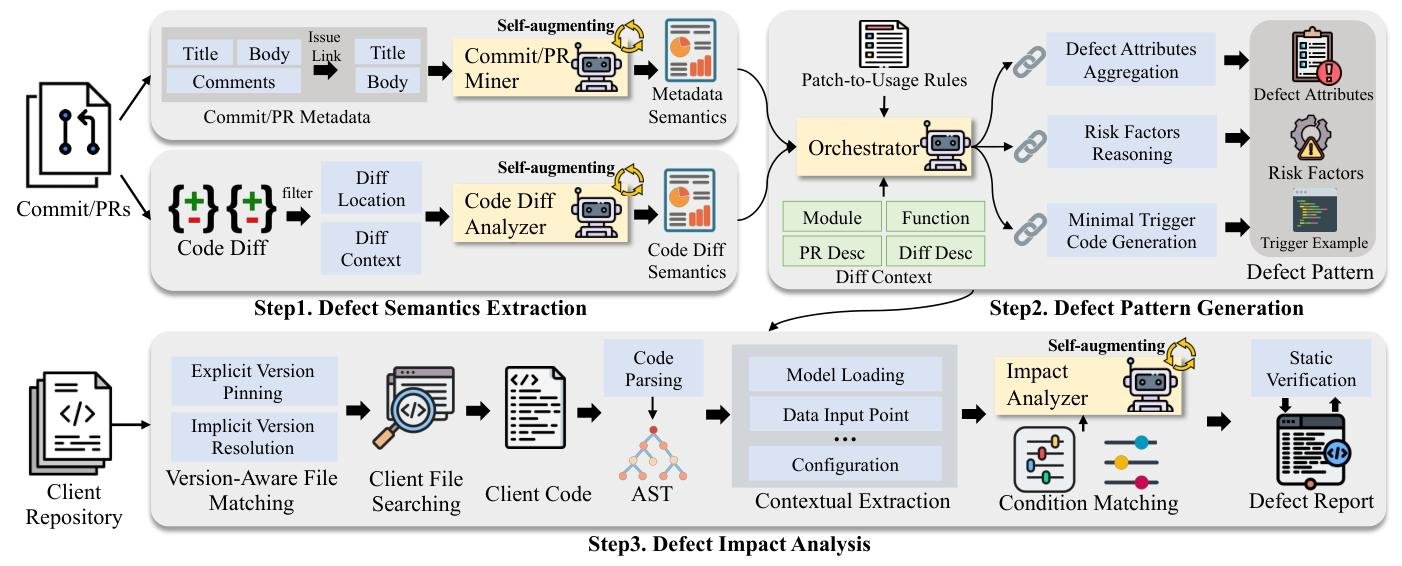
DepRadar的核心思路是“三步走”,通过四大智能体的协同配合,完成从缺陷提取到影响分析的全流程自动化,具体步骤如下:
第一步:缺陷语义提取(双智能体协作)
- PR/Commit挖掘器:先通过关键词过滤(如“fix”“bug”)筛选出可能涉及缺陷修复的PR/提交,再从标题、正文、开发者评论中提取结构化元数据,包括缺陷背景、影响范围、触发条件。
- 代码差异分析器:对代码补丁进行去噪处理(剔除注释、格式调整等无功能变更),解析修改的函数/模块、缺陷根因(如缺少边界检查),以及与触发条件相关的关键参数和方法名。
- 协调器在此阶段负责验证提取信息的完整性,若信息不足则触发渐进式上下文扩展,确保语义提取全面。
第二步:缺陷模式生成(协调器主导)
- 协调器整合前一步的输出结果,应用DL领域规则进行推理。比如将库内部的“_flash_kernel”函数映射为用户常用的“generate()”API,将分散的触发条件(如硬件类型+参数配置)合成最小可执行代码示例。
- 最终生成结构化的缺陷模式,包含三大核心内容:缺陷属性(是否为Bug、背景、影响)、风险因素(用户可见的方法和参数)、最小触发示例(客户端可复现的代码片段)。
第三步:客户端影响分析(影响分析器主导)
- 版本匹配:验证客户端依赖的库版本是否包含该缺陷,支持显式版本固定(如transformers==4.30.2)和隐式版本推断(如transformers>=4.0)。
- 上下文搜索:构建客户端代码的AST树,精准定位与缺陷模式中风险因素匹配的代码片段,提取最小上下文(如模型构造函数、函数调用)。
- 触发条件验证:判断客户端代码是否满足缺陷的触发条件,支持同义词归一化(如enable_flash_attn_v2和use_flash_attention2视为同一配置)和灵活参数排序。
- 静态验证+报告生成:通过AST验证LLM预测的参数/方法是否真实存在于客户端代码,最终输出结构化影响报告,明确客户端是否受影响及判断依据。
主要成果和贡献
DepRadar在两大主流DL库(Transformers、Megatron)上经过了227个库更新(157个PR+70个提交)和122个客户端程序的严格验证,核心成果如下:
核心性能指标(表格归纳)
| 评估任务 | 关键指标 | 结果 | 对比优势 |
|---|---|---|---|
| 缺陷识别 | 精确率/召回率/F1值 | 90%/99%/95% | 远超FlatLLM(Base:81%/92%/86%)、PyCG等基线 |
| 缺陷模式字段质量 | 平均得分(满分2分) | 1.6分 | 缺陷背景、影响范围的完全准确率分别达71%、84% |
| 客户端影响分析 | 精确率/召回率/F1值 | 80%/90%/85% | 比FlatLLM(Base)精确率提升17个百分点,特异性提升28个百分点 |
| 提交场景适配(缺陷模式) | 精确率/召回率/F1值 | 96%/90%/93% | 即使缺少PR讨论上下文,仍保持高准确性 |
| 计算成本 | 总 tokens/总成本/总耗时 | 1.29M/$0.5/221.5分钟 | 成本低廉,适合实际部署 |
实际应用价值
- 精准识别静默缺陷:成功发现12个开发者确认的真实影响案例,包括4个高风险缺陷(如梯度缩放异常、视觉权重不一致),这些缺陷此前难以通过传统测试检测。
- 降低依赖升级成本:帮助开发者判断自身项目是否受上游库缺陷影响,避免盲目升级导致的重训练和兼容性问题,可针对性地局部修复。
- 提升缺陷分析效率:全流程自动化,无需人工梳理PR/提交信息和客户端代码,大幅减少开发者排查缺陷的时间成本。
核心贡献
- 提出首个针对DL库的多智能体协作缺陷影响分析框架,打通“缺陷提取-模式生成-影响验证”的全链路。
- 解决DL库缺陷分析的三大核心挑战(表征嘈杂、语义鸿沟、场景匹配难),提供了兼顾准确性和可解释性的解决方案。
- 开源代码和复现包,为后续相关研究提供基础工具和数据集支持。
思维导图
详细总结
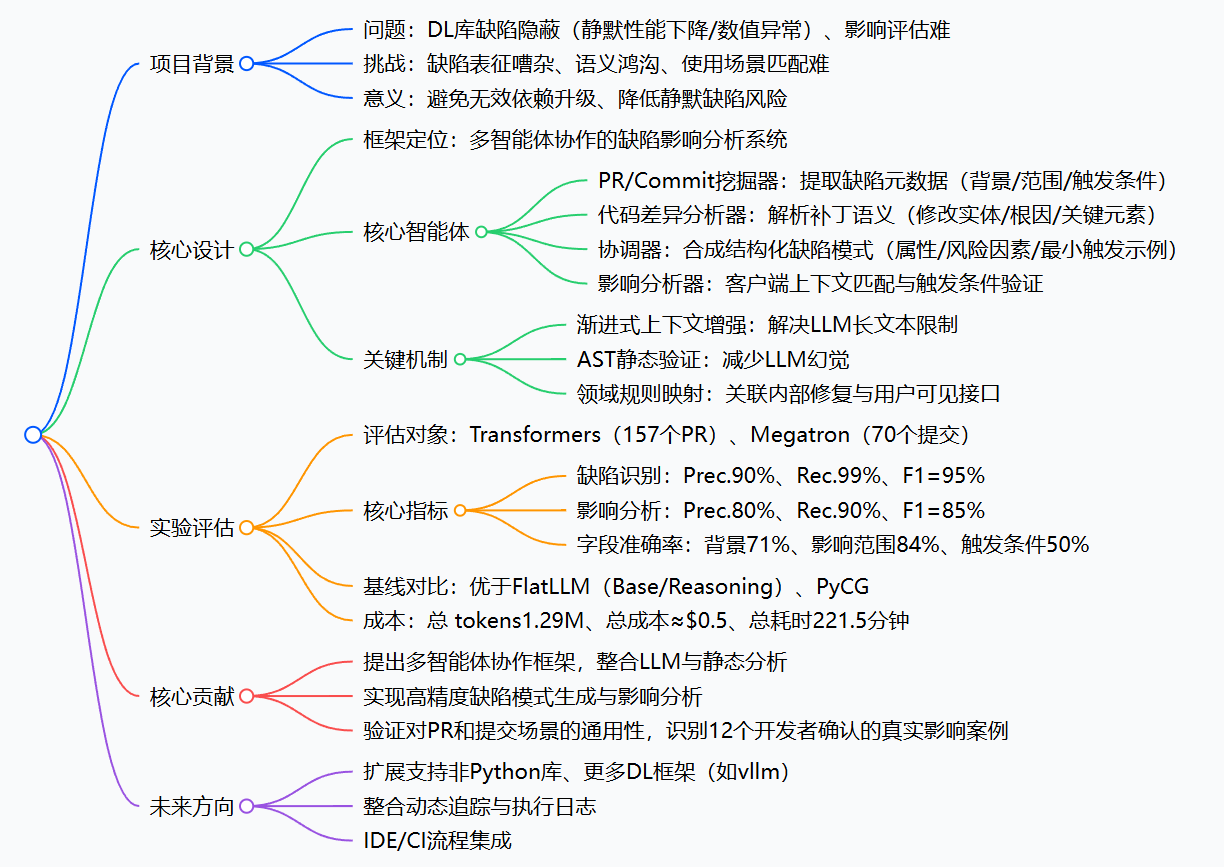
一、项目背景与挑战
- DL库的重要性与缺陷隐患:Transformers、Megatron等DL库封装核心功能(分词、分布式训练等),是大规模AI项目的基础,但随着复杂度提升,易引入静默缺陷(如梯度更新错误、内存低效),这类缺陷无明显崩溃表现,难以被下游用户察觉。
- 现有解决方案不足:依赖升级成本高(触发重训练/兼容性问题)、发布说明粗糙(缺乏关键触发条件)、传统工具仅关注语法分析或通用总结,无法解决DL库特有的语义鸿沟问题。
- 三大核心挑战:
- 缺陷表征嘈杂:PR/提交的描述非结构化、包含冗余信息,根因与触发条件不明确;
- 语义鸿沟:库内部低层级修复(如CUDA图、通信缓冲区)与用户高层API使用存在认知差距;
- 使用场景匹配难:需同时理解库修复逻辑与客户端配置、函数调用等上下文。
二、DepRadar核心设计
(一)整体流程(三步法)
| 步骤 | 核心任务 | 负责智能体 | 输出结果 |
|---|---|---|---|
| 1. 缺陷语义提取 | 从PR/提交中提取结构化信息 | PR/Commit挖掘器 + 代码差异分析器 | 缺陷元数据、补丁语义解析结果 |
| 2. 缺陷模式生成 | 整合信息,生成用户视角的缺陷特征 | 协调器 | 结构化缺陷模式(属性/风险因素/最小触发示例) |
| 3. 客户端影响分析 | 验证客户端是否满足触发条件 | 影响分析器 | 影响报告(是否受影响/匹配依据/推理过程) |
(二)关键组件与机制
- 四大智能体功能:
- PR/Commit挖掘器:过滤非缺陷PR(基于关键词 heuristic),通过渐进式上下文增强提取3类元数据(bug_background、impact_scope、trigger_conditions);
- 代码差异分析器:去除非功能性修改(注释/格式),解析补丁的修改实体、缺陷根因(如边界检查缺失)、触发相关关键元素(参数/方法名);
- 协调器:应用领域规则(实体提升、参数暴露、触发合成等),将低层级修复映射为用户可见的缺陷模式,包含最小可执行触发代码示例;
- 影响分析器:先进行版本匹配(显式版本固定/隐式版本推断),再通过AST语法感知提取客户端上下文,验证触发条件是否满足。
- 核心优化机制:
- 渐进式上下文增强:分块处理PR/补丁内容,迭代补充上下文,避免LLM token超限;
- AST静态验证:验证LLM生成的参数/方法是否真实存在于客户端代码,减少幻觉;
- 领域规则集:4类核心规则(表1),解决内部API与用户接口的映射问题。
三、实验设计与结果
(一)实验设置
| 维度 | 细节 |
|---|---|
| 评估对象 | Transformers(Q2 2025合并的157个缺陷PR)、Megatron(70个缺陷提交) |
| 客户端数据 | 122个依赖Transformers的开源项目、Megatron下游项目MindSpeed |
| 基线模型 | FlatLLM(Base):零样本总结;FlatLLM(Reasoning):DeepSeek-R1自推理;PyCG:静态调用图分析 |
| LLM配置 | DeepSeek-V3,temperature=0,top-p=1.0(确定性解码) |
(二)核心实验结果
-
缺陷模式生成性能(RQ1):
- 缺陷识别:Prec.90%、Rec.99%、F1=95%,特异性62%,显著优于FlatLLM(Base:F1=86%)和FlatLLM(Reasoning:F1=90%);
- 结构化字段质量:bug_background完全准确率71%、impact_scope 84%、trigger_conditions 50%,平均字段得分1.6/2;
- 缺陷类型覆盖:支持7类缺陷(语义逻辑错误占比最高56%、兼容性问题23%等),97%为非崩溃类静默缺陷。
-
客户端影响分析性能(RQ2):
- 核心指标:Prec.80%、Rec.90%、F1=85%,特异性72%;
- 基线对比:FlatLLM(Base:F1=68%)、FlatLLM(Reasoning:F1=74%)、PyCG(F1=47%);
- 有效性验证:50个随机TP案例经实测确证存在预期缺陷(内存膨胀/数值漂移等)。
-
组件消融实验(RQ3):
系统变体 缺陷识别F1值 影响分析F1值 关键结论 完整版本 95% 85% - 无自适应上下文 91% - 上下文增强对分散缺陷信号提取至关重要 无多智能体协作 68% - 单LLM难以处理结构化分解与语义歧义 无验证层 - 75% 静态验证可降低假阳性(Prec.从80%→66%) 无领域映射 - 73% 领域规则可提升召回率(Rec.从90%→76%) -
提交场景通用性(RQ4):
- 缺陷模式生成:Prec.96%、Rec.90%、F1=93%;
- 影响分析:Prec.60%、Rec.71%、F1=65%;
- 实际价值:识别12个开发者确认的受影响客户端案例(含4个高风险缺陷,如梯度缩放异常)。
-
成本分析(RQ5):
任务类型 平均Tokens 总Tokens 平均时间(分钟) 总时间(分钟) 缺陷模式(PR) 5K 785K 0.5 78.5 缺陷模式(提交) <2K 140K <0.3 21 影响分析(客户端) 3K 366K 1.0 122 总计 - 1.29M - 221.5 - 经济成本:基于DeepSeek-V3定价,总成本≈$0.5(< $1)。
四、核心贡献与未来方向
-
核心贡献:
- 提出首个针对DL库的多智能体协作缺陷影响分析框架,整合LLM与静态分析、领域规则;
- 实现高精度的结构化缺陷模式生成与上下文感知的影响分析,显著优于现有基线;
- 验证了对PR和提交两种场景的通用性,在工业级项目中识别出真实受影响案例,具备实用价值。
-
未来方向:
- 扩展支持非Python DL库(如TensorFlow C++)和更多框架(如vllm);
- 整合动态追踪与执行日志,提升 runtime 相关缺陷的分析能力;
- 开发IDE/CI集成工具,提供实时缺陷风险提示;
- 探索多LLM模型对比与优化,降低幻觉率。
4. 关键问题与答案
问题1:DepRadar如何解决DL库缺陷影响分析中的“语义鸿沟”问题?
答案:通过三层核心机制协同解决:① 领域规则映射层:定义实体提升、参数暴露等规则,将库内部低层级修改(如内核函数、缓冲区逻辑)映射到用户可见的高层API(如from_pretrained())和配置参数(如attn_implementation);② 双智能体语义互补:PR/Commit挖掘器提取自然语言描述的缺陷上下文,代码差异分析器解析补丁的技术细节,协调器整合两者生成统一的缺陷模式,搭建从“内部修复”到“用户使用”的语义桥梁;③ 客户端AST语法感知提取:聚焦与缺陷模式相关的最小代码子树,保留语义局部性,确保低层级修复逻辑与客户端高层使用场景的精准匹配。
问题2:DepRadar在缺陷识别和影响分析任务中的性能表现如何?与现有基线相比优势何在?
答案:① 缺陷识别性能:Prec.90%、Rec.99%、F1=95%,结构化字段平均准确率1.6/2(影响范围字段达84%);② 影响分析性能:Prec.80%、Rec.90%、F1=85%;③ 优势显著:相比FlatLLM(Base),缺陷识别F1提升9个百分点,影响分析Prec.提升17个百分点、Spec.提升28个百分点;相比FlatLLM(Reasoning),缺陷识别F1提升5个百分点,影响分析F1提升11个百分点;相比静态分析工具PyCG(F1=47%),影响分析性能翻倍,核心优势在于多智能体协作的结构化推理、领域规则的精准映射以及AST静态验证对幻觉的抑制,解决了单一LLM或静态工具的语义理解不足问题。
问题3:DepRadar的实用价值体现在哪些方面?有哪些实际应用场景?
答案:实用价值与应用场景主要包括:① 下游开发者风险排查:帮助依赖DL库的开发者快速判断自身项目是否受上游缺陷影响,避免盲目升级依赖(减少重训练成本)或忽视静默风险(如数值异常导致模型收敛失败);② 工业级项目缺陷定位:在Megatron下游项目MindSpeed中成功识别12个真实受影响案例,其中4个高风险缺陷(如梯度缩放不稳定)被开发者确认并针对性修复,无需全量升级库版本;③ CI/CD流程集成:可嵌入自动化测试流程,在项目构建阶段自动扫描依赖库的缺陷风险,生成结构化报告(含触发条件、匹配依据),辅助开发者快速响应;④ 开源库维护支持:为DL库维护者提供缺陷影响范围的量化分析,优化发布说明的精准度,帮助社区用户快速定位自身是否属于受影响群体。
总结
DepRadar通过创新的多智能体协作架构,结合渐进式上下文增强、领域规则映射和AST静态验证等机制,实现了深度学习库缺陷影响的精准、自动化分析。它不仅能高效提取PR和提交中的结构化缺陷模式,还能准确判断下游客户端是否受影响,有效解决了DL领域依赖升级成本高、静默缺陷难察觉、缺陷影响评估难等痛点。
该工具在Transformers和Megatron上的优异表现,以及低廉的计算成本,使其具备极强的实际部署价值,能帮助开发者在保障项目稳定性的同时,降低依赖管理成本。未来随着对更多DL库、更多编程语言的适配,以及动态追踪等功能的加入,其应用场景将进一步拓展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献99条内容
已为社区贡献99条内容

所有评论(0)