第22章—数据结构篇:Hash迭代器实现思想
这一节,我们首先重点介绍了 dict 迭代器的事情,说明了迭代器本身的核心结构,梳理清楚了 dict 迭代器的核心工作原理。然后深入讲解了 dictScan() 函数,弄清了“最高位加 1,向低位方向进位”这个算法的核心思想以及关键实现。最后,还分析了 dictScan() 函数的核心实现以及 fn() 回调、privdata 的含义。用两次 listAddNodeTail() 函数的,就是把取出
在上一节中,我们详细分析了哈希表基础操作的实现,主要涉及如何增删改查哈希表中的数据以及渐进式 rehash 的核心原理。
在这一节,我们来分析一下 dict 的迭代器实现,HSCAN 命令底层就直接依赖 dict 迭代器进行实现。先来考虑一下 dict 迭代器出现的原因,是不是和 quicklist 的情况类似呢?dict 里面有两个 ht_table,而且每个 ht_table 是“数组 + 链表”的结构,所以加个迭代器,屏蔽一下这些底层复杂结构,也是非常合理的选择。
dict 迭代器
如果要我们自己实现一个迭代器的话,需要维护什么信息呢?
我们至少需要知道四个值:自己迭代的是哪个 dict 对象,迭代哪个 ht_table,迭代哪个槽位,迭代到了哪个节点。来看一下 dictIterator 结构体,里面的 d、table、index、entry 就是我们需要的四个值。
typedef struct dictIterator {
dict *d; // 当前迭代的dict实例
long index; // 当前迭代到的槽位
// table是当前迭代到的dictht,取值只能是0或1
// 标识当前迭代器是否为安全模式迭代器
int table, safe;
// 指向当前迭代到的节点以及其下一个节点
dictEntry *entry, *nextEntry;
// 为非安全模式迭代器设计的一个指纹标识
unsigned long long fingerprint;
} dictIterator;
dictIterator 里面还有三个额外的字段,这里简单介绍一下。
- 首先是 nextEntry 字段,它是 entry 的下一个节点。
- 然后是 safe 字段,它是 1 的话,就表示这个迭代器是一个安全模式迭代器,在迭代过程中可以调 dictAdd()、dictDelete() 之类的函数来修改 dict 实例;如果 safe 是 0 ,就是一个不安全模式的迭代器,在用这个迭代器迭代的过程中,只能调用 dictNext() 函数迭代数据,不能调用 dictAdd() 或 dictDelete() 去修改 dict。
- 最后 fingerprint 字段是一个指纹,这个值是在迭代器刚创建的时候,把 dict 里面比较关键的字段,全部进行一次异或计算,得到的一个 long 值。使用非安全的迭代器的时候,会在迭代开始和迭代结束计算两次 指纹,要是两次指纹不一样,就说明在迭代过程中,dict 发生了变更,就要报错了。注意一下,在迭代过程中,如果调用了 dictFind() 函数,可能会触发渐进式 reahash,那 dict 也发生了变化,这也会导致 fingerprint 值发生改变。
说完了 dict 迭代器的结构之后,我们就来看怎么用这个迭代器。
首先就是创建迭代器,我们可以用 dictGetIterator() 函数创建一个非安全模式的迭代器,也可以用 dictGetSafeIterator() 函数创建安全模式迭代器,两个的区别就是 safe 是否设置成了 1。
然后就是用 dictNext() 函数进行迭代,这里我们重点看 dictNext() 函数是怎么推进迭代继续的。
首次调用 dictNext() 函数的时候,会初始化迭代器。
- 对于非安全模式迭代器来说,会计算并初始化 fingerprint。
- 然后,把迭代器的 table 和 index 都设置 0,表示从 ht_table[0] 的第一个槽位开始迭代。
- 最后是 entry 和 nextEntry 两个指针,entry 会指向第一个槽位的第一个节点,nextEntry 指向 entry 的下一个节点,大概就如下图所示:
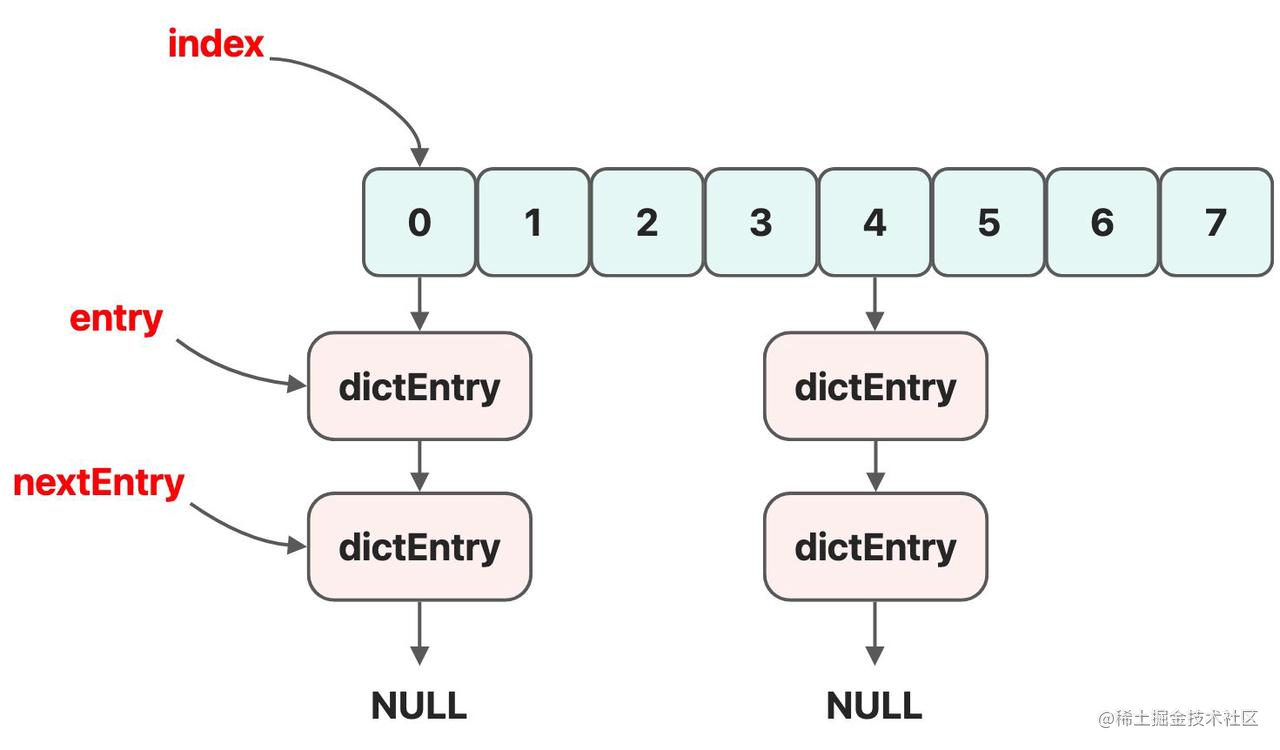
在迭代过程中,每次调用 dictNext() 函数时,都会将迭代器的 entry 和 nextEntry 指针后移,然后将 entry 指向的节点返回。之所以需要 nextEntry 指针,是为了保证在迭代过程中删除 entry 节点,后续迭代也能正常进行。
随着迭代过程的推进,entry 最终会走到 NULL,这个时候就需要注意此时的三个处理分支。
- 情况 1:如果 entry 所在槽位的链表迭代完毕,则 index 会后移,如果碰到空槽位,会继续后移,直至找到可以遍历的链表,然后将 entry 指向链表头节点,继续后面的迭代。
- 情况 2:整个 ht_table[0] 迭代完了,但是,当前 dict 处于 rehash 的状态,这个情况就要去迭代 ht_table[1] 这个哈希结构了。比如说下面这张图,这里会将 table 设置为 1,开始迭代 ht_table [1] 这个哈希结构,index 会从 0 开始,找 ht_table[1] 里面第一个有数据的槽位,然后迭代其中链表,然后重复情况 1。
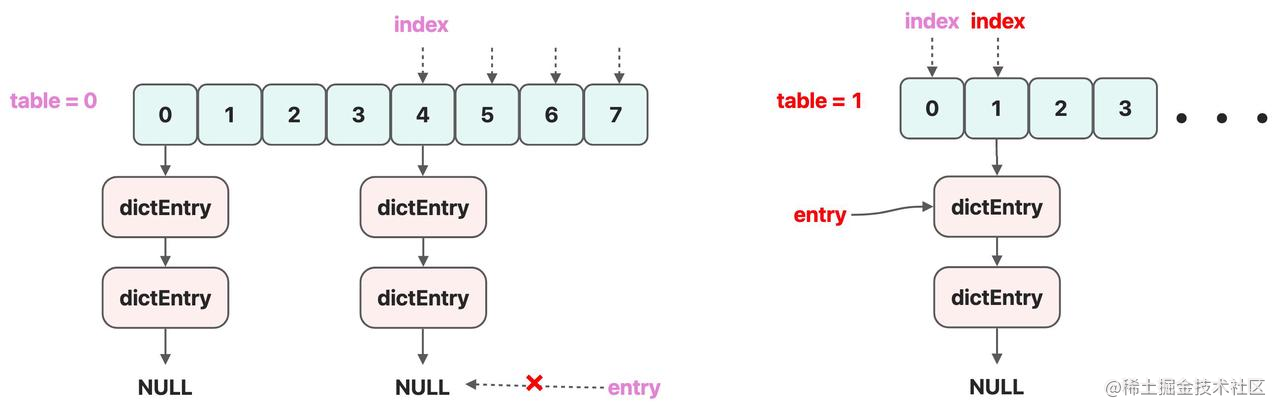
- 情况 3:整个 ht_table [1] 迭代完的时候,整个 dict 也就迭代完了,dictNext 直接返回 NULL 就行了。
在完成迭代之后,需要调用 dictReleaseIterator() 函数销毁迭代器。对于非安全的迭代器,这里会重新计算一下 fingerprint 值,看看有没有发生变化,要是发生变化了,就要抛异常。对于安全模式的迭代器,会把 pauserehash 值减 1(pauserehash 在前面第 20 讲《数据结构篇:深入 Hash 实现》中提到,是用来控制渐进式 rehash 行为的开关)。要是 pauserehash 减成了 0,dict 的 rehash 状态就恢复了,之后再增删改查的时候,就可以触发渐进式 rehash 了。
dictScan 迭代
说完 dict 迭代器之后,你可能觉得用迭代器来实现 HGETALL 命令,是个不错的选择呢?但是,别忘了,碰到一个非常大的 dict 实例的时候,我们应该选择 HSCAN 命令进行分批扫描,那个 HSCAN 命令是怎么实现的呢?
HSCAN 对应的实现在 dictScan() 函数里面,它的特性可以简单总结成下面几点。
- 支持分批迭代。
- 在分批迭代的过程中,还允许其他命令触发渐进式 rehash。
- 只要数据在迭代的开始到结束期间,没有被删除,一定能被迭代到;要是在迭代过程中间被删除了,那就不一定了。
- 在迭代过程中,可能返回重复数据,但是这种可能已经降到最低了。
好,我们先来关注 dictScan() 函数里面各个参数的含义:
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
- 参数 d 是我们要扫的 dict 实例。
- 参数 v 是迭代开始的槽位索引,每次 dictScan() 函数的返回值,就是下一次 dictScan() 调用需要传入的参数 v。第一次调用 dictScan() 的时候,v 初始值为 0,在一次 dictScan() 函数调用的时候,可能扫一个槽位,也可能扫多个槽位,扫完之后会返回一个新游标值,也就是下一次扫描的起始槽位,最终 dictScan() 函数返回 0 表示整个迭代结束。
- 参数 fn 是一个函数指针,迭代到的每个节点都会由该函数进行处理,就类似于 Java 里面传入了一个 Callback,里面有一些回调逻辑。
- 参数 bucketfn 也是一个函数指针,在迭代一个新槽位的时候,触发相应的回调逻辑。
- privdata 参数是一个数组,它是 fn 这个回调函数的参数。privdata 里面会放两个东西:一个 adlist 链表,一个是当前迭代的对象是什么东西。
先不用关心 fn 函数和 privdata、adlist 的实现,现在就当 fn 是个黑盒就行,我们分析完 dictScan 函数之后,会回头来看 fn 函数。
1. 核心原理
通过对 dictScan 参数分析,我们可以看出,游标 v 的演变过程就是 dictScan() 函数的关键所在。这里游标 v 的演变采用了 reverse binary iteration 算法,简单点说,就是每次向游标 v 的二进制最高位加 1,并向低位方向进位。
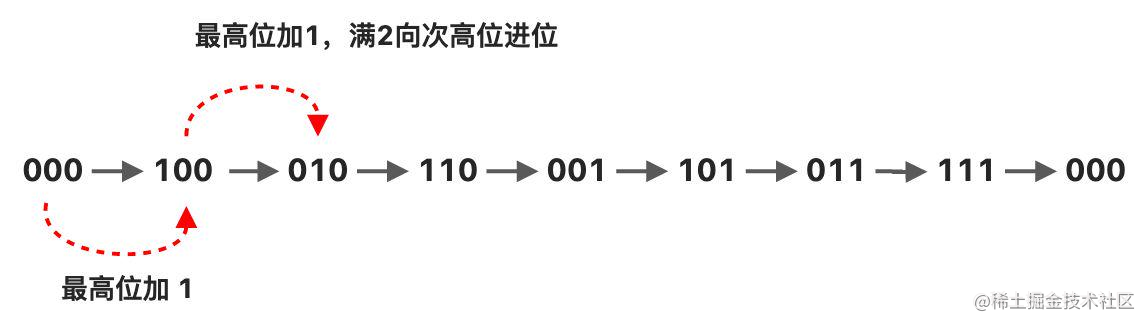
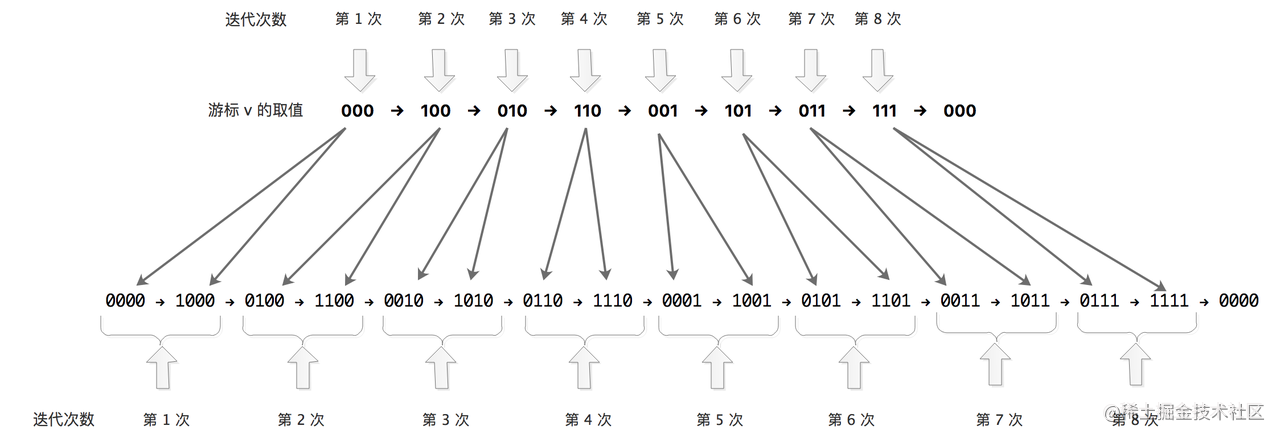
假设哈希表的 size 为 8,其索引的取值范围为 [0,7],二进制表示就是 [000, 111],游标 v 的变化流程如下:
再举个例子,假设哈希表的 size 为 16,其索引的取值范围为 [0,15],二进制表示就是 [0000, 1111],游标 v 的变化流程如下:
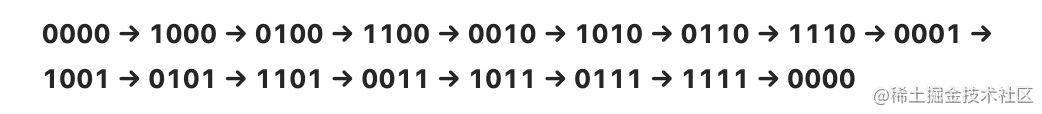
从上面这个示例可以清晰地看出,每次都是向游标 v 的最高位加 1,并向低位方向进位,比如,0000 的下一个游标是 1000,最高位加 1;1000 的下一个游标是 0110,在最高位加 1 并且向低位进位,得到 0110。
那为什么要设计这种迭代顺序,而不是按照 0, 1, 2, 3……这样的递增顺序进行迭代呢?
首先回归到计算一个 key 所在槽位本质,实际上就是 hash(key)&mask 的结果值。当哈希表槽位数为 8 时,mask 为 111,那一个 Key 所在槽位就取决于哈希值的低 3 位。我们现在假设一个 Key 的哈希值后三位是 010,然后扩容了,哈希表槽位数扩容到了 16,mask 就成了 1111,这个 Key 的 hash 不变,扩容后这个 key 可能在 0010 这个槽,也可能在 1010 这个槽。
还是这个例子,我们在 dict 槽位是 8 的时候,按照 “高位加 1,向低位进位” 的方式迭代,看下面这张图,这个时候我们已经迭代了两次,迭代完了 000、 100 槽位,第三次要迭代的槽位是 010。恰巧这个时候发生扩容了,槽位个数扩容成了 16 个。000 这个槽位里面的 Key 会 rehash 到 0000、1000,100 槽里面的 Key 会 rehash 到 0100、1100 这两个槽里面,看图里面的虚线圈出来的部分,在槽个数为 8 时,已经迭代过了 000、100 两个槽,扩容之后也就没有必要再迭代 0000、1000、0100、1100 这四个槽了。
要是在开始第三次迭代之前,我们的 rehash 操作就完成了,那下次迭代的时候,就直接从 0010 这个槽位开始就行了。
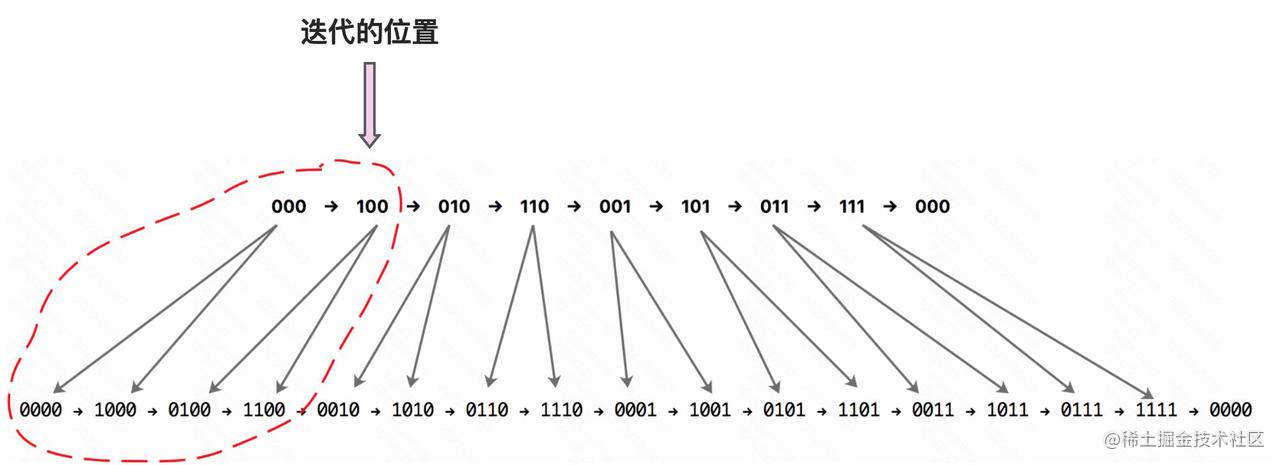
那如果在第三次迭代时,rehash 还没完成,dict 还处于 rehash 状态呢?下面还是以 dict 槽位个数从 8 扩容到 16 且在整个迭代过程中 dict 都处于 rehash 为例进行介绍,看下面这张图:
- 第一次调用 dictScan() 函数时,游标 v 传入 000,dictScan() 函数会迭代 ht_table[0] 的 000 槽位以及 ht_table[1] 的 0000 槽位以及 1000 槽位;
- 第二次调用 dictScan() 函数时,游标 v 传入 100,dictScan() 函数会迭代 ht_table[0] 的 100 槽位以及 ht_table[1] 的 0100 槽位以及 1100 槽位;
- 依次类推,直至整个 dict 实例迭代完毕。
也就是说,一次 dictScan 会同时迭代 ht_table[0] 和 ht_table[1],而且同时迭代的这些槽位也是对标的。
上面说的这些例子都是以扩容为主,缩容的场景也是一样的,这里就不再展开举例了,感兴趣的小伙伴可以自己举例试试。
2. 核心代码解析
介绍完底层原理之后,我们开始逐步介绍 dictScan() 函数的实现。首先是“最高位加 1,向低位方向进位”这个算法的关键代码,片段如下:
// htidx0是ht_table数组的下标
htidx0 = 0;
unsigned long m0 = DICTHT_SIZE_MASK(d->ht_size_exp[htidx0]); // m0是t0的sizemask
v |= ~m0; // 用于保留游标v的低n位数,其余位全置为1
v = rev(v); // 将游标v的二进制进行翻转,使得v的低n位数成了高n位数
v++; // 递增v
v = rev(v); // 再次将游标v的二进制进行翻转
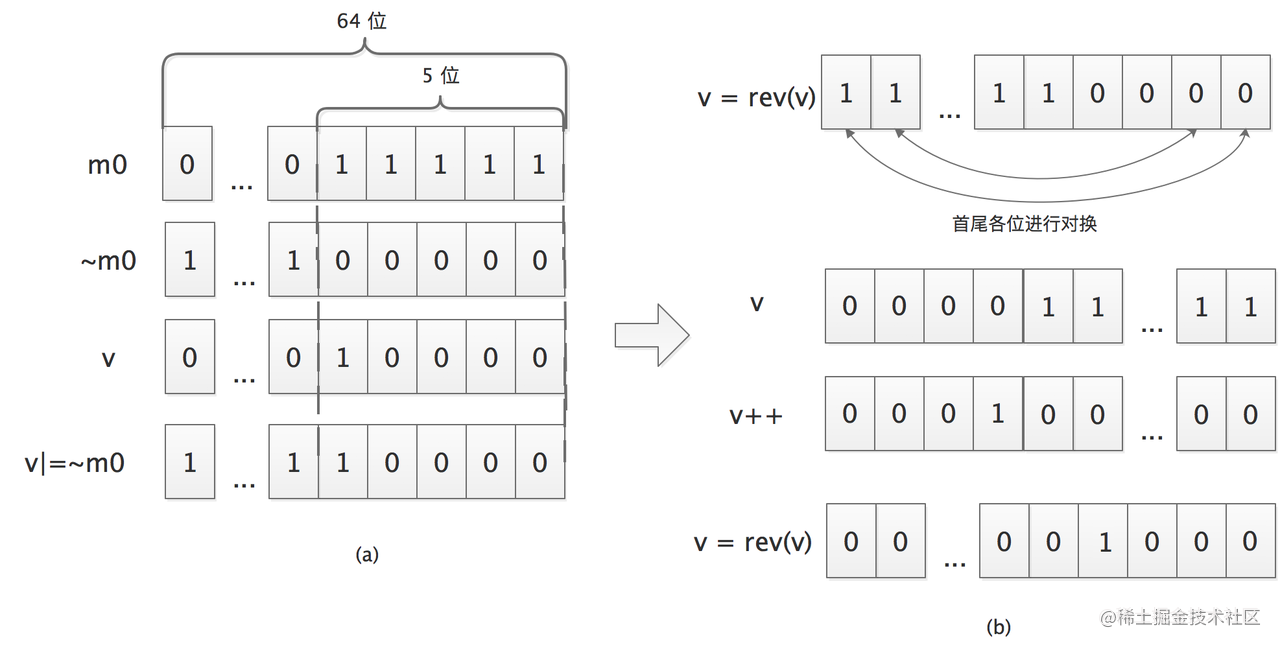
上面这段代码看起来比较抽象,我们这里以 ht_table[0] 中槽位数为 32 进行举例说明。
看下图里面的(a)部分,m0 是一个 64 位的整型,低 5 位为 1,高位全部为 0,~m0 就是低 5 位为 0,高位全部为 1。这里假设游标 v 的二进制表示为 10000,经过 v|=~m0 这行或操作之后,低 4 位为 0,高位全部为 1。
再来看(b)部分,首先展示了 rev() 函数的功能,它是将 v 的首尾各位对调,此时得到的 v 值高 4 位为 0,低位全部为 1。接下来,对 v 进行加 1 操作,得到 v 值高 4 位为 0001,低位全部为 0。最后,再次调用 rev() 函数进行对调,实现在最高位加 1、向低位进位的效果。
理解了游标 v 的计算方式之后,我们再来看 dictScan() 函数的核心流程:
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn,
dictScanBucketFunction* bucketfn, void *privdata){
int htidx0, htidx1;
const dictEntry *de, *next;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
dictPauseRehashing(d); // 步骤1.暂停rehash
// 步骤2.dict是否处于 rehash 状态,然后进入不同的处理分支
if (!dictIsRehashing(d)) { // 步骤2.a.未处于rehash状态
htidx0 = 0;
m0 = DICTHT_SIZE_MASK(d->ht_size_exp[htidx0]);
// 触发bucketfn这个回调,处理单个槽位
if (bucketfn) bucketfn(d, &d->ht_table[htidx0][v & m0]);
de = d->ht_table[htidx0][v & m0];
while (de) {
next = de->next;
fn(privdata, de); // 步骤3.回调fn,处理每个元素
de = next;
}
v |= ~m0; // “最高位加1,向低位方向进位”这个算法的关键代码
v = rev(v);
v++;
v = rev(v);
} else { // 步骤2.b.处于rehash状态的处理分支
htidx0 = 0;
htidx1 = 1;
if (DICTHT_SIZE(d->ht_size_exp[htidx0]) > DICTHT_SIZE(d->ht_size_exp[htidx1])) {
htidx0 = 1;
htidx1 = 0;
}
m0 = DICTHT_SIZE_MASK(d->ht_size_exp[htidx0]);
m1 = DICTHT_SIZE_MASK(d->ht_size_exp[htidx1]);
// 触发bucketfn这个回调,处理单个槽位
if (bucketfn) bucketfn(d, &d->ht_table[htidx0][v & m0]);
de = d->ht_table[htidx0][v & m0];
while (de) {
next = de->next;
fn(privdata, de); // 步骤3.回调fn,处理每个元素
de = next;
}
do {
if (bucketfn) bucketfn(d, &d->ht_table[htidx1][v & m1]);
de = d->ht_table[htidx1][v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
v |= ~m1; // “最高位加1,向低位方向进位”这个算法的关键代码
v = rev(v);
v++;
v = rev(v);
} while (v & (m0 ^ m1));
}
dictResumeRehashing(d); // 步骤4.渐进式 rehash
return v; // 步骤5.返回游标v
}
- 首先是把 pauserehash 字段加 1,暂停迭代过程中的所有 rehash 操作。这里暂停的是在 dictScan() 函数执行过程中的渐进式 rehash,两次 dictScan() 函数调用之间是允许渐进式 rehash 的。
-
然后,就是检查 rehashidx 字段,确定 dict 是否处于 rehash 状态,然后进入不同的处理分支。
- 如果dict 实例未处于 rehash 状态,则迭代游标 v 指向槽位中的链表。
- 如果 dict 实例处于 rehash 状态,则先根据游标 v 迭代较小 dictht 实例(扩容场景中就是ht_table[0],缩容场景中就是ht_table[1];完成较小 dictht 实例的迭代之后,再根据游标 v 迭代较大 dictht 实例(扩容场景中就是ht_table[1],缩容场景中就是ht_table[0])。迭代到的每个节点都由 fn() 函数进行处理。
- 这里迭代到的每个节点都由 fn() 函数进行处理。
- dictScan 调用结束之后,就把 pauserehash 减 1,允许渐进式 rehash。
- 最后,返回游标 v,给下次 dictScan 调用的时候用。
3. fn() 回调和 privdata
dictScan 函数的核心逻辑说完之后,我们回来填个坑。
通过对 dictScan() 代码的分析我们知道,fn() 函数是处理每个节点的回调,具体是怎么处理的呢?我们看一下 dictScan 的调用链,发现只有一个调用方,看这个调用方的调用是:
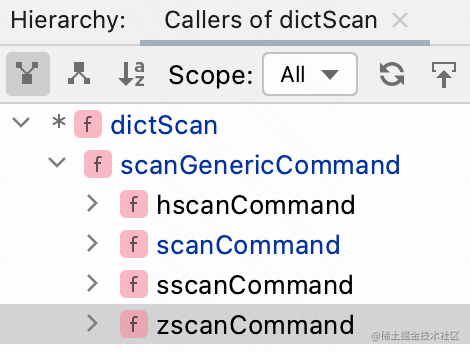
scanGenericCommand() 函数中调用 dictScan() 函数的关键代码如下:
cursor = dictScan(ht, cursor, scanCallback, NULL, privdata);
fn 指向的函数就是 scanCallback。点进 scanCallback 里面看一下,这里面是把扫到的 Key 和 value 添加到一个 adlist 里面的,就是这个 key 指针,也就是 privdata 数组里面的第一个元素。
这 adlist 定义在 adlist.h 文件里面,后面都会称之为 adlist。这个 adlist 非常简单,就是纯纯的链表实现,我们点进去看一下,里面有 head、tail 指针,然后每个 listNode 里面有 prev、next 之后,还有一个 value 指针来存数据,定义非常简单。
typedef struct list { // adlist的定义
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
typedef struct listNode { // adlist的节点
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
回到 scanCallback 这个回调里面,privdata 数组里面的第二个元素用于识别当前迭代的是什么结构。比如说,我们用 HSCAN 命令扫 HASH 表的话,就走 OBJ_HASH 这个分支,其中会把当前迭代到的键值对都当作 sds 字符串取出来;如果我们用 SSCAN 命令扫一个 SET 集合的话,就走 OBJ_SET 这个分支,其中只会拿 Key,毕竟 Set 集合里面只有 Key,没有 Value;如果我们用的 SCAN 命令,扫整个 Redis DB 这个大哈希表的话,就走 NULL 这个分支,也是只取 Key,因为 Value 是个复杂类型,取出来也没法给客户端。
void scanCallback(void *privdata, const dictEntry *de) {
void **pd = (void**) privdata;
list *keys = pd[0]; // 第一个元素是adlist
robj *o = pd[1]; // 第二个元素用于识别当前迭代的是什么结构
robj *key, *val = NULL;
if (o == NULL) { // 使用ZCAN迭代整个Redis DB的话,会走该分支
sds sdskey = dictGetKey(de);
key = createStringObject(sdskey, sdslen(sdskey));
} else if (o->type == OBJ_SET) { // 用SSCAN命令扫一个SET集合的话,会走该分支
sds keysds = dictGetKey(de);
key = createStringObject(keysds,sdslen(keysds));
} else if (o->type == OBJ_HASH) { // 使用HSCAN迭代哈希表的话,会走该分支
sds sdskey = dictGetKey(de);
sds sdsval = dictGetVal(de);
key = createStringObject(sdskey,sdslen(sdskey));
val = createStringObject(sdsval,sdslen(sdsval));
} else if (o->type == OBJ_ZSET) { // 使用ZSCAN迭代Sorted Set的话,会走该分支
sds sdskey = dictGetKey(de);
key = createStringObject(sdskey,sdslen(sdskey));
val = createStringObjectFromLongDouble(*(double*)dictGetVal(de),0);
} else {
serverPanic("Type not handled in SCAN callback.");
}
listAddNodeTail(keys, key);
if (val) listAddNodeTail(keys, val);
}
最后,这里会调用两次 listAddNodeTail() 函数的,就是把取出来的这些键值对,加入到前面说的这个 adlist 里面,这个 adlist 链表就像是临时存储。等 dictScan 扫完了,这轮扫到的数据也就加到这个 adlist 里面了,后面就可以根据一些规则对 adlist 里面的数据进行过滤,以上就是 fn 和 privdata 两个参数的主要作用。
总结
这一节,我们首先重点介绍了 dict 迭代器的事情,说明了迭代器本身的核心结构,梳理清楚了 dict 迭代器的核心工作原理。然后深入讲解了 dictScan() 函数,弄清了“最高位加 1,向低位方向进位”这个算法的核心思想以及关键实现。最后,还分析了 dictScan() 函数的核心实现以及 fn() 回调、privdata 的含义。
用两次 listAddNodeTail() 函数的,就是把取出来的这些键值对,加入到前面说的这个 adlist 里面,这个 adlist 链表就像是临时存储。等 dictScan 扫完了,这轮扫到的数据也就加到这个 adlist 里面了,后面就可以根据一些规则对 adlist 里面的数据进行过滤,以上就是 fn 和 privdata 两个参数的主要作用。
总结
这一节,我们首先重点介绍了 dict 迭代器的事情,说明了迭代器本身的核心结构,梳理清楚了 dict 迭代器的核心工作原理。然后深入讲解了 dictScan() 函数,弄清了“最高位加 1,向低位方向进位”这个算法的核心思想以及关键实现。最后,还分析了 dictScan() 函数的核心实现以及 fn() 回调、privdata 的含义。
dict 的内容到这里就全部介绍完了。下一节,我们将介绍 intset 对纯数字 Set 集合的优化。
🔥运维干货分享

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)