LiveTalking本地化部署指南
是一个开源的实时交互数字人系统,通过多模态AI技术实现语音驱动的虚拟形象生成,支持低延迟视频流输出,适用于虚拟客服、直播、教育等多种场景。。
LiveTalking 介绍
LiveTalking 是一个开源的实时交互数字人系统,通过多模态AI技术实现语音驱动的虚拟形象生成,支持低延迟视频流输出,适用于虚拟客服、直播、教育等多种场景。
github地址:https://github.com/lipku/LiveTalking
gitee地址:https://gitee.com/lipku/LiveTalking
技术架构与核心功能
系统采用三平面哈希表示进行高效三维空间编码,结合区域注意力模块融合语音与眼部动作信号,实现精准的唇形同步和表情驱动;核心模块包括:
- 语音识别(ASR):支持Whisper、Hubert等模型,将语音实时转为文本。
- 大语言模型(LLM):可接入阿里云Qwen、OpenAI等,处理自然语言理解与生成。
- 文本转语音(TTS):集成GPT-SoVITS、FishSpeech及云服务(如腾讯云TTS),支持声音克隆和多语种播报。
- 视觉驱动:采用MuseTalk、Wav2Lip等模型,实现半身动画与背景替换。
系统通过WebRTC或RTMP输出视频流,端到端延迟低于300ms,单GPU可并发支持16个以上会话。
本地服务器部署实验
部署环境与硬件配置
● 操作系统:Ubuntu
● GPU:NVIDIA GeForce RTX 4090 (24GB 显存)
● 内存:24GB
LiveTalking 数字人项目部署与运行指南
本文档基于 LiveTalking 项目(支持 MuseTalk 模型)的实验环境配置流程整理,旨在帮助开发者快速搭建实时交互式数字人服务。
1. 环境准备
1.1 获取源码
首先,将项目代码克隆至本地环境:
git clone https://github.com/lipku/LiveTalking.git
cd LiveTalking
1.2 创建虚拟环境
建议使用 Conda 创建独立的 Python 3.10 环境:
conda create -n livetalk python=3.10
1.3 激活虚拟环境后,安装依赖库
根据你的 CUDA 版本安装对应的 PyTorch 及项目依赖。注意: 本示例基于 CUDA 12.8 环境。
| 组件 | 版本/配置 |
|---|---|
| CUDA | 12.8 |
| PyTorch | 2.8.0 |
| Torchvision | 0.23.0 |
| Torchaudio | 2.8.0 |
执行安装命令:
conda activate livetalk
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu128
pip install -r requirements.txt
💡 提示:若你的服务器 CUDA 版本不同,请移步 PyTorch 官网 获取对应版本的安装命令。
2. 模型配置
在启动服务前,需确保模型权重文件已准备就绪。
- 操作步骤:
- 访问 Hugging Face 或项目指定的模型库。
- 下载 MuseTalk 模型所需的核心权重文件(如 sd-vae-ft-mse 等)。
- 将下载的文件放置于项目根目录下的 models/ 文件夹中。
注:虽然项目支持自动下载,但鉴于网络环境,推荐手动下载并放置文件以确保完整性。
最终下载的模型文件如下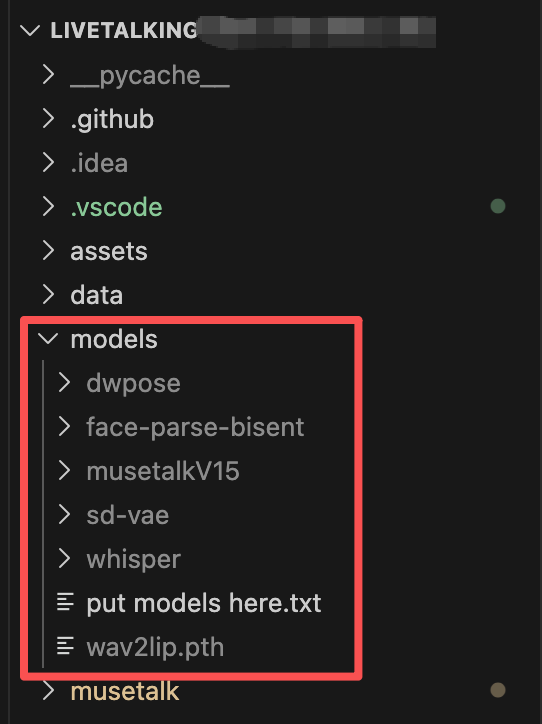
下载模型文件可以使如下bash代码
#!/bin/bash
# Set the checkpoints directory
CheckpointsDir="models"
# Create necessary directories
mkdir -p models/musetalk models/musetalkV15 models/syncnet models/dwpose models/face-parse-bisent models/sd-vae models/whisper
# Install required packages
pip install -U "huggingface_hub[cli]"
pip install gdown
# Set HuggingFace mirror endpoint
export HF_ENDPOINT=https://hf-mirror.com
# Download MuseTalk V1.0 weights
huggingface-cli download TMElyralab/MuseTalk \
--local-dir $CheckpointsDir \
--include "musetalk/musetalk.json" "musetalk/pytorch_model.bin"
# Download MuseTalk V1.5 weights (unet.pth)
huggingface-cli download TMElyralab/MuseTalk \
--local-dir $CheckpointsDir \
--include "musetalkV15/musetalk.json" "musetalkV15/unet.pth"
# Download SD VAE weights
huggingface-cli download stabilityai/sd-vae-ft-mse \
--local-dir $CheckpointsDir/sd-vae \
--include "config.json" "diffusion_pytorch_model.bin"
# Download Whisper weights
huggingface-cli download openai/whisper-tiny \
--local-dir $CheckpointsDir/whisper \
--include "config.json" "pytorch_model.bin" "preprocessor_config.json"
# Download DWPose weights
huggingface-cli download yzd-v/DWPose \
--local-dir $CheckpointsDir/dwpose \
--include "dw-ll_ucoco_384.pth"
# Download SyncNet weights
huggingface-cli download ByteDance/LatentSync \
--local-dir $CheckpointsDir/syncnet \
--include "latentsync_syncnet.pt"
# Download Face Parse Bisent weights
gdown --id 154JgKpzCPW82qINcVieuPH3fZ2e0P812 -O $CheckpointsDir/face-parse-bisent/79999_iter.pth
curl -L https://download.pytorch.org/models/resnet18-5c106cde.pth \
-o $CheckpointsDir/face-parse-bisent/resnet18-5c106cde.pth
echo "✅ All weights have been downloaded successfully!"
里面有些没必要下载,所以我去huggingface上下载对应的权重文件的。
3. 服务启动与访问
3.1 启动应用
配置完成后,运行以下命令启动服务:
python app.py --model musetalk --transport webrtc --avatar_id musetalk_avatar1
当出现以下页面时,访问网址http://serverip:8010/webrtcapi.html

3.2 获取服务地址
服务启动后,需获取服务器的局域网 IP 地址(serverip):
ip a
在输出结果中找到 eth0 网卡下的 inet 字段,即为你的服务器 IP。
3.3 Web 端交互
打开浏览器,访问以下地址:
- 基础演示页面:
http://:8010/webrtcapi.html- 点击 Start 按钮加载数字人。
- 在文本框输入内容并提交,数字人将实时播报。
- 进阶仪表盘(推荐):
http://:8010/dashboard.html- 对话模式:集成大语言模型,支持智能问答交互。
- 朗读模式:输入文本进行播报。
- 语音交互:支持通过麦克风按钮进行实时语音对话。
打开web页面如下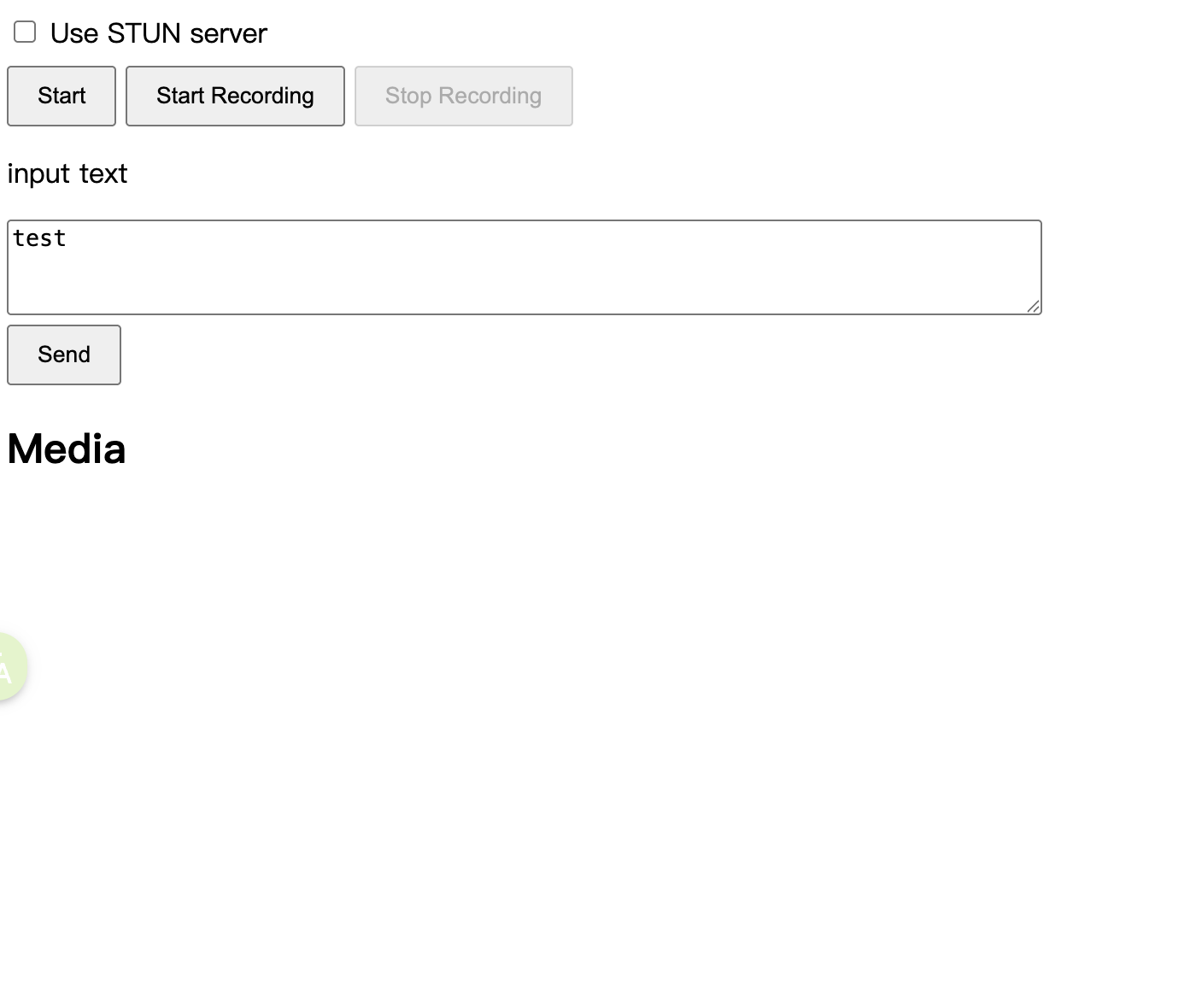
点击start,会显示数字人,在input text中输入要朗读的文本,数字人就会进行播报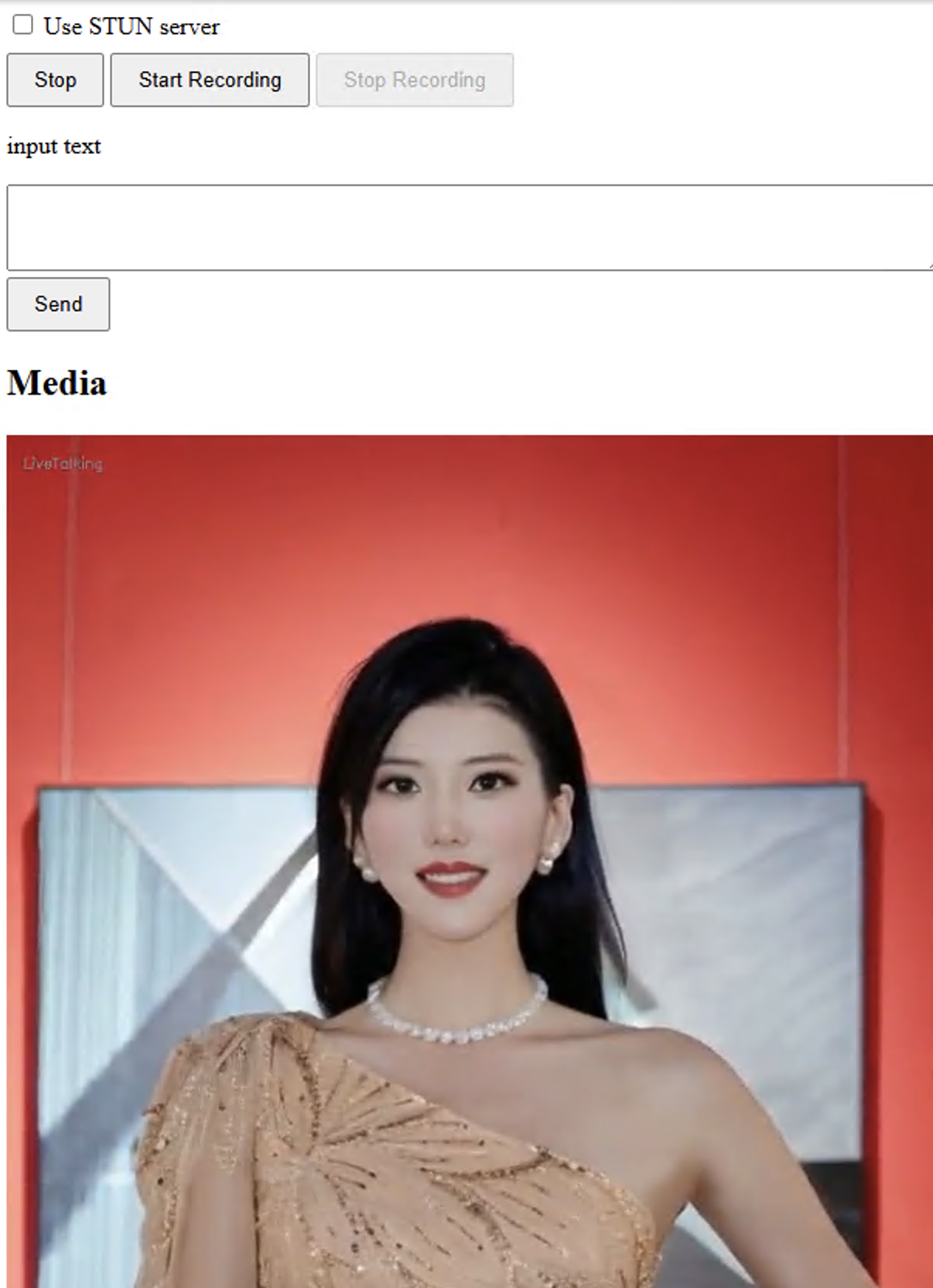
如果要体验更完整功能的Web页面,推荐访问链接:http://serverip:8010/dashboard.html
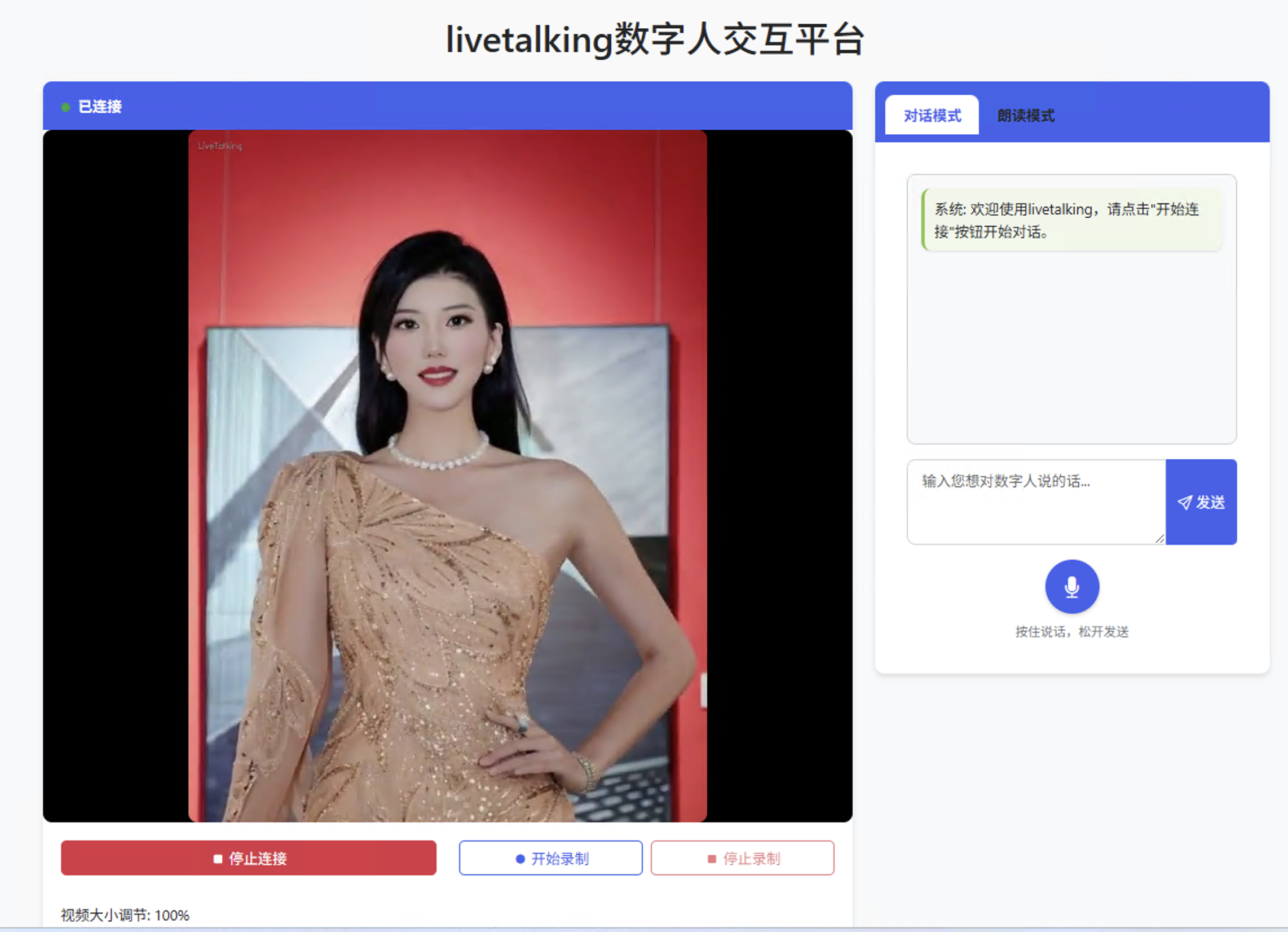
如上图所示,有对话模式和朗读模式,对话模式接了大模型,可以进行智能问答。下面的语音按钮还支持语音对话。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)