RAID10 单盘失效降级处理实操
目录
RAID10 降级
在日常运维工作中,我曾处理过一起4盘RAID10阵列单盘失效引发的降级告警事件,成功化解了数据丢失风险,现将本次处理经验总结如下,为后续同类故障提供参考。
事件过程
收到「XXXX」节点存储告警,查看后发现RAID 异常。
通过执行storcli64 /call show all和storcli64 /call show all | less命令,拉取阵列全景信息;
同时配合服务器带外网页管理界面,交叉验证故障磁盘状态;
storcli64 /call show all
storcli64 /call show all | less
服务器带外网页排查是否故障本次故障是 4 盘 RAID10 阵列的槽位 252:1 物理盘失效,导致整个阵列降级:通过执行storcli64 /call show all命令查看拓扑信息,能直接看到磁盘组 0 下的 RAID10 虚拟盘状态为 “Dgrd(降级)”,其包含的 2 个 RAID1 镜像对子阵列也同步降级;进一步看物理盘行,可明确槽位 252:1 对应的磁盘状态显示 “Failed(故障)”,其他 3 块盘(槽位 252:0、252:2、252:3)均为 “OnLn(在线)”,以此定位到故障盘并确认阵列降级原因。
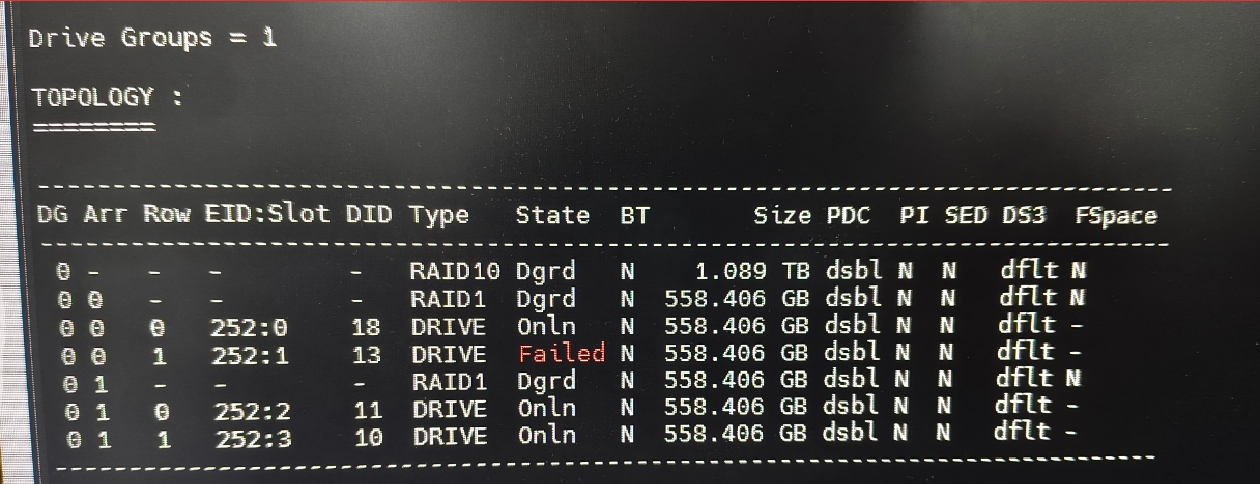
字段拆解 & 故障关联
|
字段 |
内容 |
含义 |
|
DG/VD |
0/0 |
磁盘组 0 下的第 0 个虚拟盘(即当前唯一的虚拟盘) |
|
TYPE |
RAID10 |
虚拟盘的 RAID 类型是 RAID10,和之前拓扑里的配置一致 |
|
State |
Dgrd |
虚拟盘处于降级状态—— 这是因为拓扑中槽位 252:1 的物理盘失效,无热备盘接替 |
|
Access |
RW |
虽然阵列降级,但仍支持正常读写(业务暂时不受影响) |
|
Consist |
Yes |
阵列数据处于一致性状态(降级后数据未损坏,可安全读写) |
|
Size |
1.089 TB |
虚拟盘容量约 1.1TB,符合 4×558GB 磁盘组建 RAID10 的容量(总容量 ÷2) |
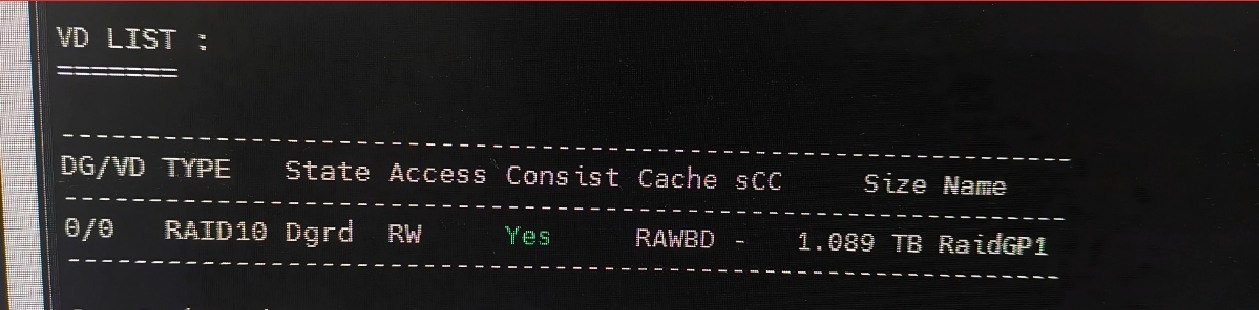
风险评估
整体风险等级:HIGH(橙色)已出现单盘失效 + RAID10 降级,再坏任意一块盘就有丢数据或业务中断的可能;BBU、Patrol Read、Learn Cycle 等后台保护机制均正常,可争取 7天内完成换盘重建。若不能及时更换,风险将升至 CRITICAL。
风险升级阈值:明确若超出时间窗口未完成修复,风险将升级为CRITICAL(红色),需重点关注时间节点。
修复方案
结合RAID10的技术特性,制定针对性修复方案:
RAID10融合了RAID1的镜像冗余和RAID0的条带读写特性,这一特性决定了在仅单盘故障且阵列未损坏的前提下,可支持热插拔操作,无需停机即可完成故障盘更换。
确认现场为raid10,且有一块磁盘故障,允许热插拔。但是4快磁盘的情况下,raid10最多支持任意一块磁盘故障,当两块磁盘故障的时候,需要是具体情况进行分析。
raid10的机制,同时拥有raid1和raid0。所以只要raid没有损坏,在只损坏一块磁盘的前提下支持磁盘热拔插。
降级状态通俗认知:4盘RAID10降级,本质就是“1块盘挂了+没备用盘顶上”,此时阵列虽能正常读写,但“镜像保险”只剩最后一层,再坏任意一块盘(尤其是和坏盘配对的那块),数据会直接丢失,务必在7天内完成换盘重建。
运维前置建议:对于关键业务节点的RAID10阵列,建议配置热备盘,实现故障盘自动接替,降低人工介入成本;同时定期核查BBU、Patrol Read等后台机制,确保其处于正常运行状态,为故障处理预留缓冲时间。
操作禁忌提醒:阵列降级期间,禁止进行大规模数据写入或迁移操作,避免加重阵列负载,引发二次故障;更换新盘时,需严格匹配磁盘型号、容量参数,防止因硬件不兼容导致重建失败。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)