【AI 风向标】联邦学习是什么?一篇从白话到原理的完整科普
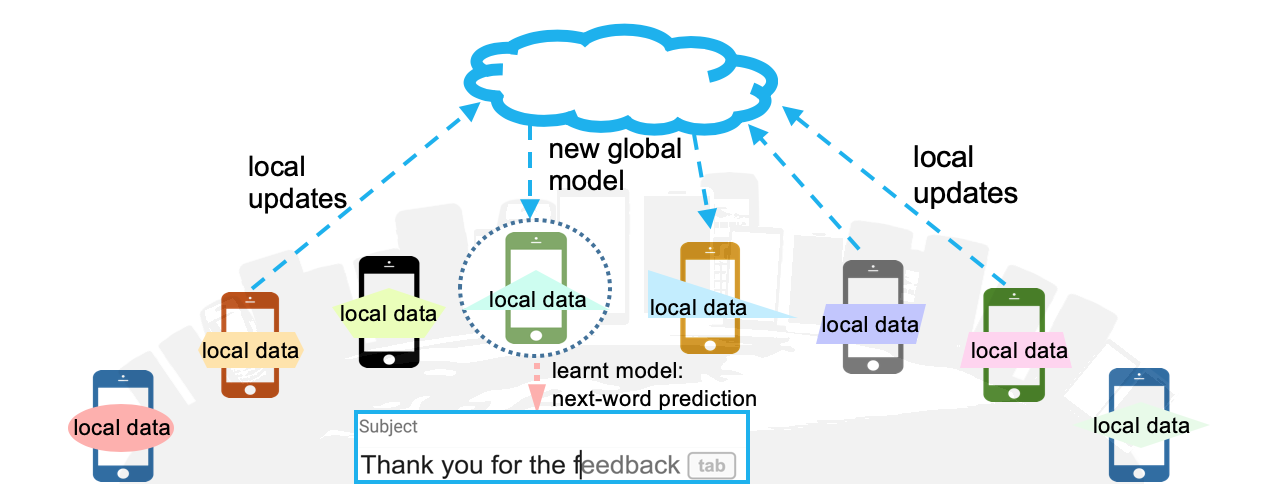
联邦学习是一种分布式机器学习技术,让多方在不共享原始数据的情况下共同训练模型。其核心是数据保留在本地,仅交换模型参数更新。通过"下发模型-本地训练-聚合更新"的循环机制,解决医疗、金融等领域的数据隐私问题。关键技术挑战包括数据分布不均、通信瓶颈和隐私保护。该技术实现了"数据不出门,模型来学习"的协作模式,平衡了模型效果与数据边界的需求。
本文原创作者:姚瑞南 AI-agent 大模型运营专家/音乐人/野生穿搭model,先后任职于美团、猎聘等中大厂AI训练专家和智能运营专家岗;多年人工智能行业智能产品运营及大模型落地经验,拥有AI外呼方向国家专利与PMP项目管理证书。(转载需经授权)
目录
联邦学习(Federated Learning),用一句大白话解释就是:
数据不出门,模型来学习。
一、联邦学习的严格定义
联邦学习(Federated Learning, FL)是一种分布式机器学习范式,其核心目标是:
在 数据本地保留(data locality) 的约束下,通过 多方协同优化 的方式训练一个共享模型。
与传统分布式训练的本质区别在于:
- 优化对象是全局模型
- 训练数据始终不离开本地参与方
二、先用一个生活例子理解
假设有 100 家医院:
- 每家医院都有病人数据
- 数据 不能外传(隐私、合规)
- 但大家又想训练一个更聪明的诊断模型
传统做法:
👉 把所有数据集中到一个地方(风险高 ❌)
联邦学习的做法:
👉
- 模型发到每家医院
- 在本地学一学
- 只把“学习结果”(参数更新)传回去
- 服务器把大家的经验 合并成一个更强的模型
📌 病人数据从头到尾都没离开医院。
三、联邦学习到底在“联”什么?
不是联数据,而是联这三样:
- 模型结构(大家用同一个模型)
- 训练经验(参数更新 / 梯度)
- 学习成果(聚合后的模型)
四、它解决的核心问题
一句话总结:
想一起变聪明,但又不能共享数据。
适合场景:
- 医疗、金融、政务
- 手机输入法、个性化推荐
- 企业之间“既合作又防泄密”
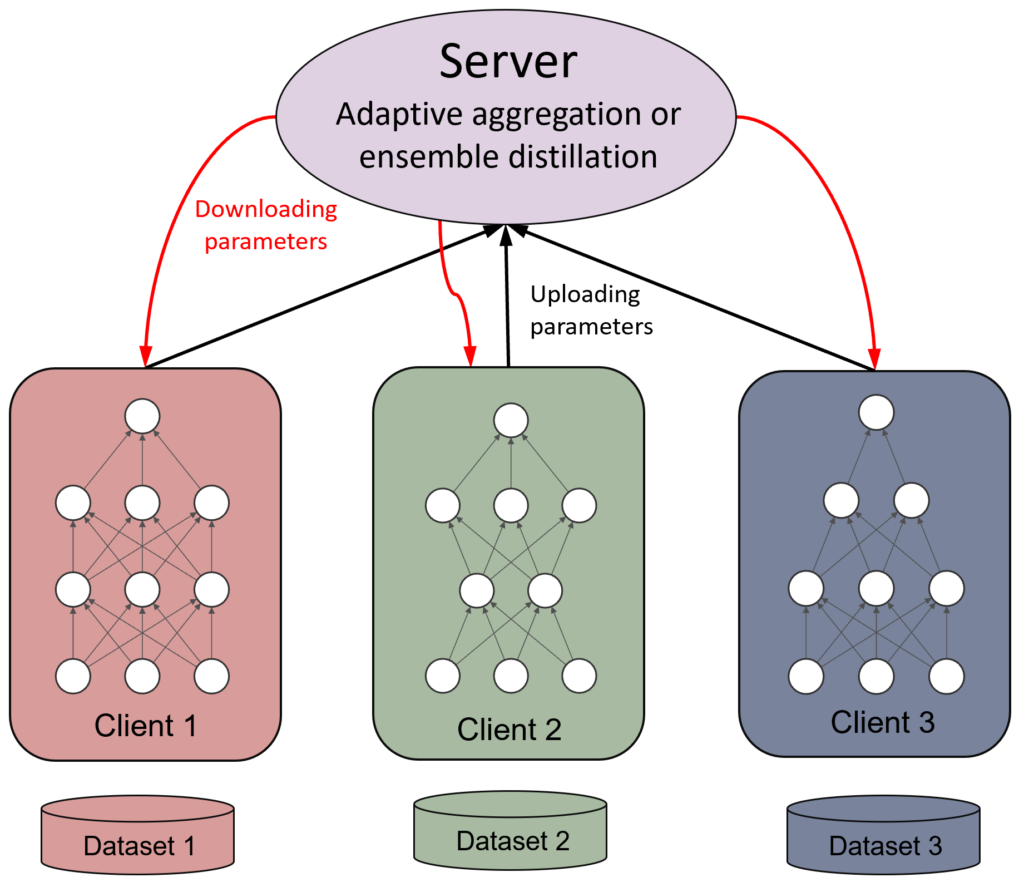
五、基本系统结构(不讲公式)
一个典型联邦学习系统包括:
- 中心协调方(Server) 初始化模型
- 聚合各方训练结果
- 多个参与方(Clients) 使用本地数据训练模型
- 上传参数更新或梯度
整体是一个 “下发模型 → 本地训练 → 聚合更新” 的循环。
六、它是怎么“学”的?(核心机制)
最经典的方法叫 Federated Averaging(FedAvg),过程是:
- 服务器发一个初始模型
- 各客户端在本地跑几轮训练
- 上传更新后的参数
- 服务器按权重做平均,得到新模型
从数学角度看,本质是在解决一个问题:
在非独立同分布(Non-IID)数据条件下,如何最小化全局损失函数。
七、联邦学习的关键技术挑战
联邦学习并不是“简单的分布式训练”,主要难点包括:
1️⃣ 数据分布异质性(Non-IID)
- 各客户端数据分布差异大
- 导致模型收敛慢、不稳定甚至偏置
2️⃣ 通信瓶颈
- 客户端数量大
- 网络不稳定
- 参数同步成本高
3️⃣ 系统异构
- 不同设备算力、存储、在线时长差异显著
4️⃣ 隐私与安全风险
- 参数更新可能被反推出原始数据
需结合:
- 安全聚合(Secure Aggregation)
- 差分隐私(Differential Privacy)
- 同态加密(部分场景)
八、一句话总结(科普用)
联邦学习是一种在不集中原始数据的前提下,让多个参与方通过参数协作共同训练模型的技术,其价值在于平衡“模型效果”和“数据边界”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)