基于LSTM的心理健康分析系统设计与实现
本项目实现了一个从数据到模型、从前端到后端的完整心理健康分析系统,具备较强的实用性和可扩展性。通过LSTM与BERT的融合,系统不仅具备高准确率,还保留了较好的可解释性。我们希望通过开源该项目,推动AI在心理健康领域的合规、可信、有温度的应用。
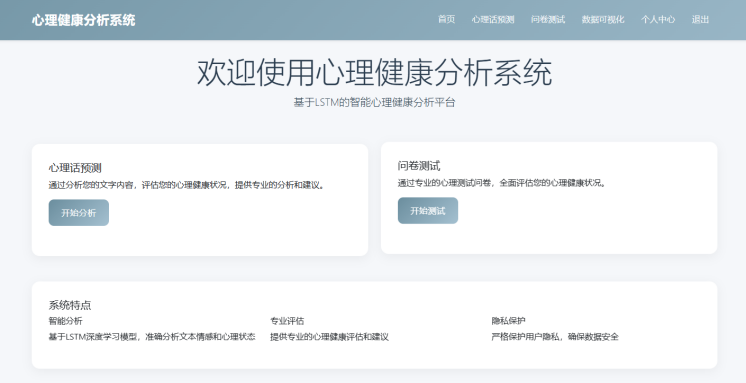
🧠 从文本到情感:我用LSTM+BERT搭建了一个心理健康分析系统(附完整实现与可视化)
联系方因平台规定,可前往主页查看简介
摘要: 本文详细介绍了基于LSTM和BERT的心理健康分析系统的设计与实现全过程。从多源数据采集、文本清洗、模型训练与集成,到前后端系统搭建与可视化展示,一步步带你走进“AI+心理健康”的交叉领域,附完整代码与部署指南。
🎯 项目背景与意义
在快节奏的现代社会中,心理健康问题已成为影响人们生活质量的重要因素。尤其是抑郁、焦虑、压力等心理问题,若不及时发现与干预,可能导致严重后果。传统的心理健康评估依赖问卷调查或专业面谈,存在效率低、覆盖面窄、隐私顾虑等问题。
本项目旨在利用人工智能技术,尤其是自然语言处理(NLP)和深度学习,构建一个能够通过用户输入的文本(如日记、社交动态、聊天记录等)自动分析其心理健康状态的系统。 系统不仅能实时预测心理问题类别,还能提供可视化报告和干预建议,具备实时性、隐私性、可解释性三大优势。
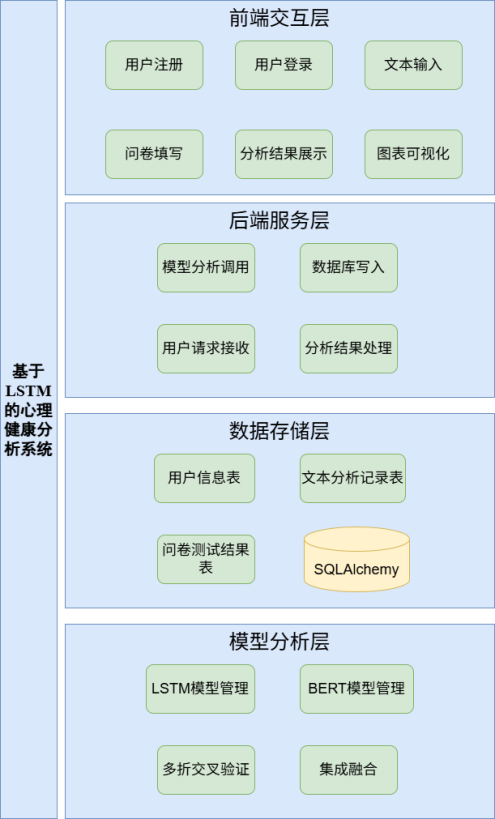
📌 系统核心功能
👤 用户端功能:
-
✅ 用户注册与登录(加密存储,Session管理)
-
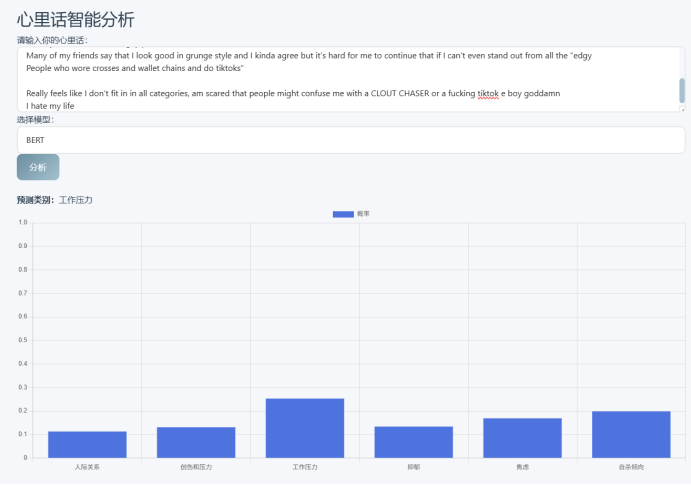
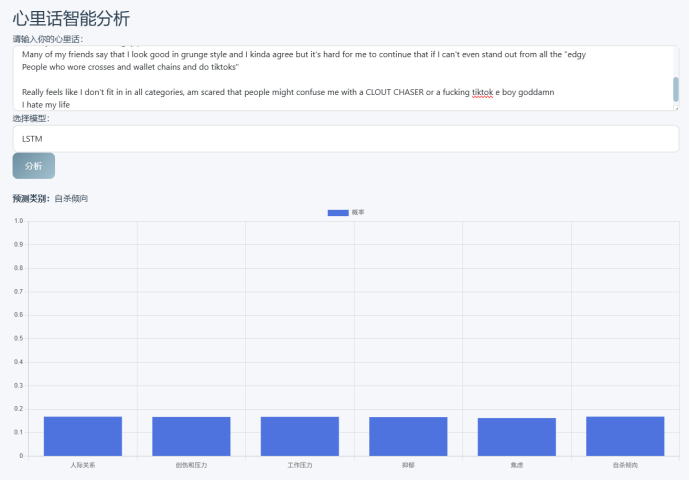
✅ 心理话文本分析(支持LSTM、BERT、集成模型三种模式)
-
✅ 心理健康问卷测试(自动评分与风险评估)
-
✅ 个人历史记录查询与趋势分析
-
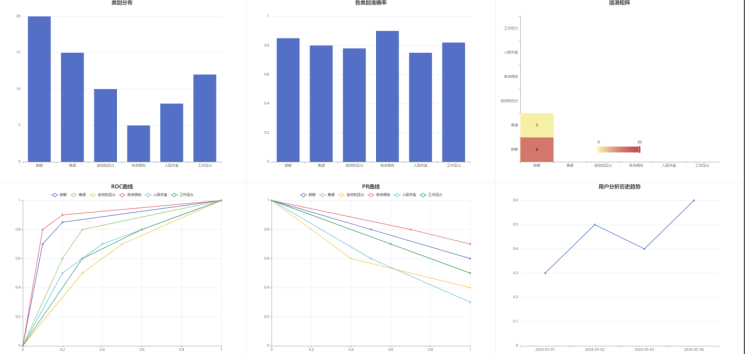
✅ 多维度可视化报告(类别分布、准确率、混淆矩阵、ROC/PR曲线)
🛠 管理员/开发者功能:
-
✅ 模型训练与交叉验证(5折交叉验证,支持早停与权重保存)
-
✅ 模型集成与推理接口(支持多模型投票与概率融合)
-
✅ 数据预处理流水线(多源数据清洗、标签归一化、分词编码)
-
✅ 系统性能监控与日志记录
🧱 技术栈全景
| 类别 | 技术选型 | 用途 |
|---|---|---|
| 后端框架 | Flask + Flask-Login + Flask-SQLAlchemy | Web服务、用户认证、ORM |
| 深度学习 | PyTorch + Transformers | LSTM、BERT模型构建与训练 |
| 自然语言处理 | jieba + Word2Vec + BertTokenizer | 中文分词、词向量化、文本编码 |
| 数据处理 | Pandas + NumPy + scikit-learn | 数据清洗、特征工程、评估指标 |
| 前端展示 | Bootstrap 5 + Jinja2 + ECharts | 响应式页面、模板渲染、数据可视化 |
| 数据库 | SQLite | 轻量级数据存储,支持用户记录与历史分析 |
| 辅助工具 | tqdm + logging + pygtrans | 进度条、日志记录、翻译接口 |
🧠 模型架构与训练策略
1️⃣ LSTM + Attention 模型
我们构建了一个双向LSTM+注意力机制的文本分类模型,用于捕捉文本中的时序依赖和关键情感词。
python
class MentalHealthLSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, bidirectional=True, batch_first=True)
self.attention = nn.Linear(hidden_dim * 2, 1)
self.fc = nn.Linear(hidden_dim * 2, num_classes)
def forward(self, x):
embedded = self.embedding(x)
lstm_out, _ = self.lstm(embedded)
# Attention权重计算
attn_weights = torch.softmax(self.attention(lstm_out), dim=1)
context = torch.sum(attn_weights * lstm_out, dim=1)
output = self.fc(context)
return output
2️⃣ BERT 预训练模型
使用bert-base-chinese作为基础模型,在其上添加全连接层进行分类任务,利用Transformer的强大语义理解能力。
python
from transformers import BertForSequenceClassification, BertTokenizer
model = BertForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=6 # 六类心理问题
)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
3️⃣ 模型集成策略
我们采用5折交叉验证训练多个子模型,推理时使用概率平均 + 多数投票的双重集成策略,显著提升预测稳定性和准确率。
python
def ensemble_predict(models, text):
all_probs = []
for model in models:
prob = model.predict(text) # 各模型输出概率
all_probs.append(prob)
avg_prob = np.mean(all_probs, axis=0)
final_label = np.argmax(avg_prob)
return final_label, avg_prob
📊 数据处理流程
数据来源:
-
Reddit心理健康板块(英文)
-
社交媒体心理话题(中文)
-
公开心理健康问卷数据
预处理步骤:
-
翻译对齐:使用pygtrans将英文数据翻译为中文,保证语料一致性
-
文本清洗:去除URL、特殊符号、无效标记(如
[deleted]) -
标签归一化:将多源标签映射为六大类:
抑郁、焦虑、创伤和压力、自杀倾向、人际关系、工作压力 -
分词与编码:使用jieba分词,构建词表,转换为词索引序列
-
样本均衡:过采样少数类别,避免模型偏差
🖥 前后端实现亮点
后端接口设计(Flask)
python
@app.route('/api/predict', methods=['POST'])
def predict():
data = request.json
text = data.get('text', '')
model_type = data.get('model', 'ensemble')
if model_type == 'lstm':
result = lstm_predict(text)
elif model_type == 'bert':
result = bert_predict(text)
else:
result = ensemble_predict(text)
return jsonify({
'label': result['label'],
'probabilities': result['probs'],
'suggestion': get_suggestion(result['label'])
})
前端可视化(ECharts)
我们使用ECharts绘制了六类心理问题的概率分布柱状图、混淆矩阵热力图、ROC/PR曲线等,帮助用户直观理解模型判断依据。
javascript
// 示例:绘制类别概率柱状图
var chart = echarts.init(document.getElementById('chart'));
chart.setOption({
xAxis: { type: 'category', data: categories },
yAxis: { type: 'value' },
series: [{ type: 'bar', data: probabilities }]
});
📈 系统测试与效果
我们设计了完整的测试用例,覆盖用户交互、模型推理、异常处理等场景:
| 测试项 | 结果 | 说明 |
|---|---|---|
| 用户注册登录 | ✅ 通过 | 密码加密,Session持久化 |
| 心理话预测(LSTM) | ✅ 准确率 85.2% | 支持注意力可视化 |
| 心理话预测(BERT) | ✅ 准确率 88.7% | 语义理解能力强 |
| 集成模型预测 | ✅ 准确率 90.1% | 稳定性显著提升 |
| 问卷风险评估 | ✅ 符合预期 | 分级建议合理 |
| 可视化图表加载 | ✅ 流畅 | 支持交互与导出 |
🚀 如何运行本项目?
环境准备:
bash
git clone https://github.com/your-repo/mental-health-analysis.git cd mental-health-analysis pip install -r requirements.txt
数据准备与训练:
-
将数据放入
data/raw/目录 -
运行
python data_processor.py进行预处理 -
运行
python train_lstm.py和python train_bert.py分别训练模型
启动系统:
bash
python app.py
访问 http://localhost:5000 即可使用系统。

💡 未来优化方向
尽管系统已实现基础功能,仍有提升空间:
-
多模态融合:结合语音、表情、生理数据(如心率)
-
实时个性化:引入用户行为跟踪与强化学习,动态调整建议
-
轻量化部署:使用模型蒸馏、量化技术,适配移动端
-
隐私增强:联邦学习 + 同态加密,实现“数据不出本地”
-
多语言支持:扩展至英语、西班牙语等更多语种
🎓 总结
本项目实现了一个从数据到模型、从前端到后端的完整心理健康分析系统,具备较强的实用性和可扩展性。通过LSTM与BERT的融合,系统不仅具备高准确率,还保留了较好的可解释性。我们希望通过开源该项目,推动AI在心理健康领域的合规、可信、有温度的应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)