MCP保姆级详解和实战案例(附完整代码)
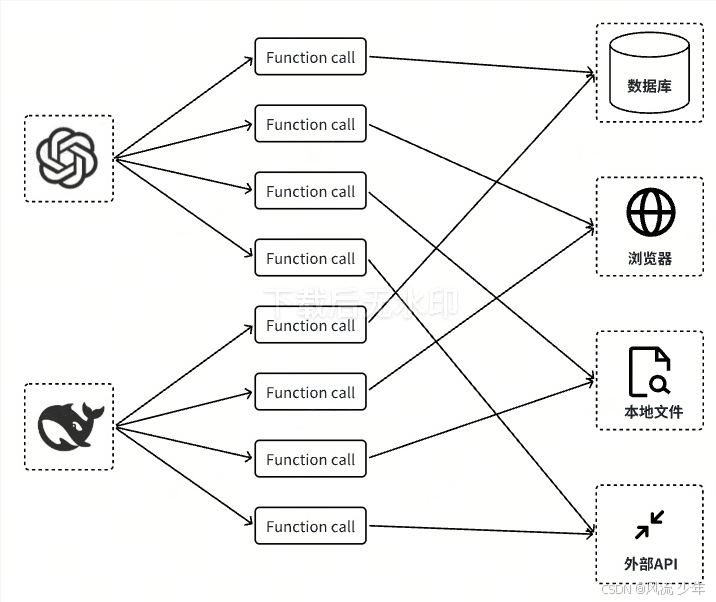
Function Call是大模型基于意图识别触发预设函数的机制,其本质是模型与外部工具的“点对点”交互。平台依赖性强:对于不同大模型(如GPT、Claude),Function Call的实现差异显著,开发者需要为每个大模型编写适配的相关代码。扩展性不足:新增工具需调整模型接口或重新训练,难以支持复杂多轮任务。从模型调用工具的流程来看,MCP 跟 Function Call 是调用链上的两个环节
一:简介
MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司推出的开放标准协议,旨在为大语言模型LLM(Large Language Model)与外部数据源、工具及服务提供统一的交互接口规范。
MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
1.1 MCP架构
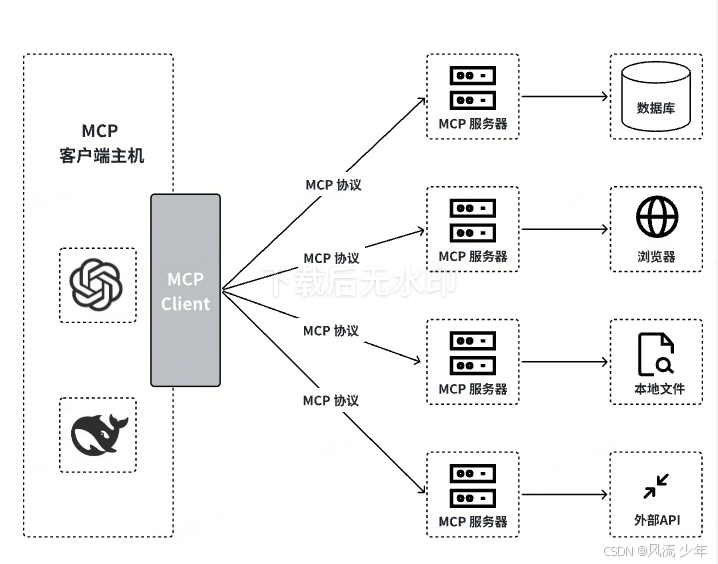
- MCP主机(host):如Claude Desktop、IDE等AI工具,负责发起请求。
- MCP客户端(client):与服务器一对一连接,管理协议通信。
- MCP服务器(server):轻量级程序,通过标准化协议安全访问本地或远程资源(如数据库、API、文件系统)。 MCP 原语包括:
- 资源(Resources):公开数据(如文件、数据库记录),支持文本和二进制格式。
- 提示(Prompts):定义可复用的交互模板,驱动工作流。
- 工具(Tools):提供可执行功能(如 API 调用、计算),由模型控制。
- 采样(Sampling):服务器通过客户端请求 LLM 推理,保持安全隔离。
- 根(Roots):定义服务器操作范围(如文件路径、API 端点)。
可以将 MCP 视为 AI 应用的 USB-C 端口。正如 USB-C 提供了一种将设备连接到各种外围设备和配件的标准化方式一样,MCP 提供了一种将 AI 模型连接到不同数据源和工具的标准化方式。
MCP hosts --> client.py --> MCP --> MCP Server --> 数据库、API、文件、浏览器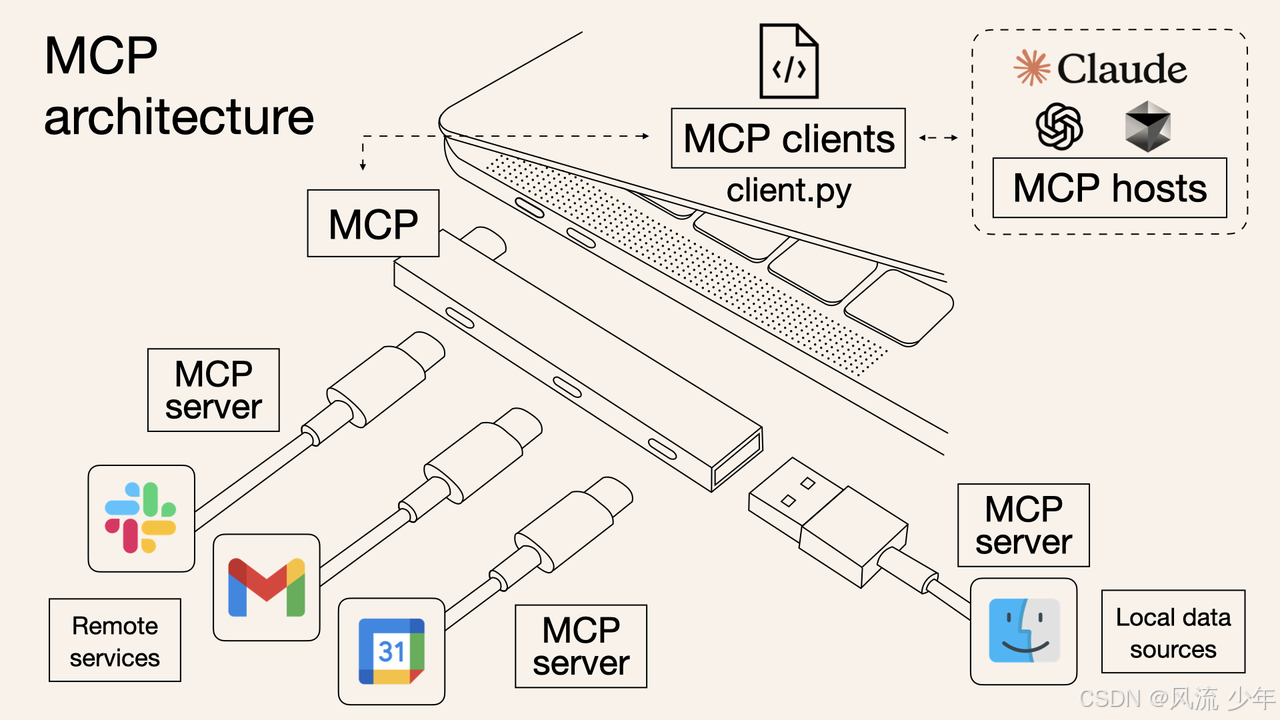
MCP Server 的官方描述:
一个轻量级程序,每个程序都通过标准化模型上下文协议公开特定功能。简单理解,就是通过标准化协议与客户端交互,让模型调用特定的数据源或工具功能。常见的 MCP Server 有:
- 文件和数据访问类:让大模型能够操作、访问本地文件或数据库,如 File System MCP Server。
- Web 自动化类:让大模型能够操作浏览器,如 Pupteer MCP Server。
- 三方工具集成类:让大模型能够调用三方平台暴露的 API,如 高德地图 MCP Server。
MCP Server 的获取途径:
- 官方收集和分享的MCP Server: https://github.com/modelcontextprotocol/servers
- mcp.so
- MCP市场 - 国内最全MCP Servers收录平台 https://mcpmarket.cn/
- ModelScope - MCP 广场 https://modelscope.cn/mcp
1.2 MCP特点
标准化接口:MCP定义统一的通信协议,开发者仅需按规范实现MCP Server(如天气查询服务,行程规划服务,数据库查询服务等等),即可被任何支持MCP的Host(如Claude Desktop、Cursor)调用,无需关注底层模型差异。
- 分层处理能力:MCP将工具调用拆分为资源、工具、提示词三层,支持复杂任务的上下文传递与多步推理。例如:通过MCP Server访问GitHub API时,模型可动态解析代码库结构并生成操作指令,而无需硬编码适配逻辑。
- 生态开放性:MCP的开放协议吸引了大量社区贡献的现成插件(如Git、Slack、AWS服务),开发者可直接复用,显著降低开发门槛。
1.3 Function Call简介
Function Call是大模型基于意图识别触发预设函数的机制,其本质是模型与外部工具的“点对点”交互。然而其存在两大核心局限性:
- 平台依赖性强:对于不同大模型(如GPT、Claude),Function Call的实现差异显著,开发者需要为每个大模型编写适配的相关代码。
- 扩展性不足:新增工具需调整模型接口或重新训练,难以支持复杂多轮任务。
-
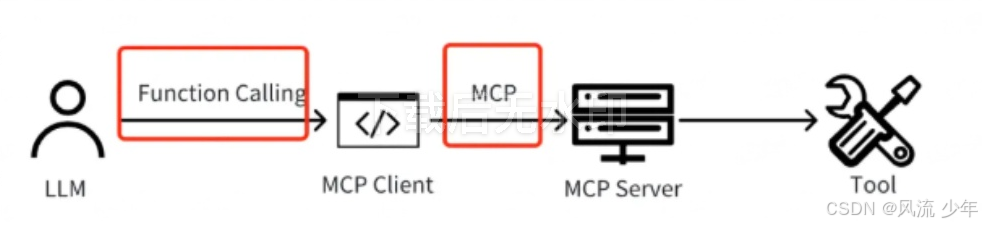
从模型调用工具的流程来看,MCP 跟 Function Call 是调用链上的两个环节。
- MCP 是指协议本身(Client 和 Server 的连接),MCP 协议只关心调用 Tool 时的通信方式。
- Function Call 是模型调用工具的主流手段之一(纯靠系统提示词也可以),关心的是模型怎么用这些工具
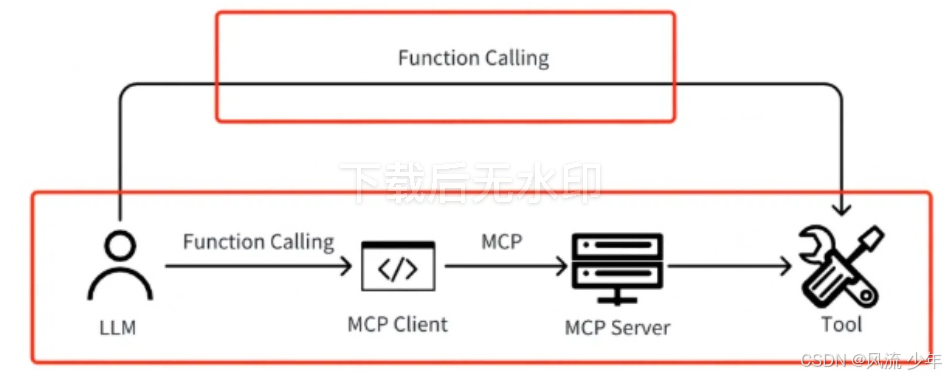
-
从agent(模型+工具)整体来看,MCP 是对 Function Call 的封装
- MCP 此时指的是整个让模型调用工具的整体手段(即图中下面这个红框)
- Function Call 是指 Host 里的 LLM 向 MCP Client 调用工具的手段
1.4 MCP 对比 Function Call
| 对比维度 | Function Call | MCP |
|---|---|---|
| 协议标准 | 私有协议(各个大模型自定规则) | 开放协议(JSON-RPC 2.0) |
| 工具发现 | 动态获取(initialize请求) | 静态预定义 |
| 调用方式 | 同进程函数 或 API | STDIO / SSE / 同进程 |
| 扩展成本 | 高(新增工具需重新调试模型) | 低(工具热插拔,模型无需改动) |
| 适用场景 | 简单任务(单次函数调用) | 复杂流程(多工具协同 + 数据交互) |
| 生态协作 | 工具与大模型强绑定 | 工具开发者与 Agent 开发者解耦 |
1.5 MCP与RAG
1.5.1 MCP直连数据库的范式革新
MCP最革命性的应用场景之一是大模型与数据库的直接交互。传统RAG(检索增强生成)依赖向量检索技术,存在检索精度低、文档切片局部性强、多轮推理能力弱等缺陷。而MCP通过以下方式实现更高效的数据访问:
- 结构化查询能力:
MCP Server可暴露数据库Schema并支持自然语言转SQL(Text-to-SQL)。例如,用户提问“商品表中价格最高的车型是什么?”时,MCP自动生成并执行SQL查询,返回结构化结果供模型生成自然语言响应。相较于RAG的模糊匹配,这种基于Schema的精准查询显著提升答案可靠性。 - 动态上下文管理:
MCP支持跨会话的上下文传递。例如,在数据分析场景中,模型可先通过MCP获取数据库表结构,再根据用户后续提问动态调整查询策略(如关联多表、聚合统计),而RAG因缺乏全局视图难以实现此类复杂操作。 - 安全与效率平衡:
MCP默认提供只读接口,并支持本地化部署。开发者可通过权限控制(如仅开放特定表或视图)避免敏感数据泄露,同时减少因全量数据上传导致的延迟与成本。
1.5.2 MCP能否替代传统RAG?
尽管MCP在结构化数据场景中展现优势,但RAG在以下场景仍不可替代:
- 非结构化文本处理:RAG擅长从海量文档(如PDF、网页)中提取片段信息,而MCP更适用于数据库、API等结构化资源;
- 低成本长文本处理:直接向大模型输入超长文本(如千万字级)会导致响应延迟与成本激增,而RAG通过精准检索切片可大幅降低开销;
- 动态知识更新:RAG可通过实时更新向量库快速纳入新知识,而MCP需依赖后端系统(如数据库)的数据更新机制。
1.5.3 未来趋势
MCP与RAG可能走向协同。例如,MCP可调用RAG服务作为其“知识检索工具”,或通过智能体架构将两者整合:MCP处理结构化查询,RAG补充非结构化知识,形成互补的混合增强方案。
MCP通过协议标准化重新定义了AI与外部系统的交互范式,其直连数据库的能力为结构化数据场景提供了更高效、精准的解决方案。然而,技术演进的终局并非“替代”,而是生态融合——MCP与RAG、Agent等技术的协同,将共同推动大模型从“封闭的知识库”进化为“开放的智能体”。
二:第三方MCP服务(百度地图API)
想要使用 MCP 技术,首先需要找到一个支持 MCP 协议的客户端,然后就是找到符合我们需求的 MCP 服务器,然后在 MCP 客户端里调用这些服务。
2.1 准备
2.1.1 申请百度地图access-key
在百度地图开放平台创建应用获取AK(需要实名认证)。
MCP Server 提供商 选择的是 ModelScope 的 MCP广场https://modelscope.cn/mcp,提供了非常丰富的 预部署的 MCP Server,这里尝试使用 百度地图 MCP服务,实现AI大模型的行程规划能力。在ModelScope - MCP 广场 中搜索“百度地图”,然后将上面获取到的访问应用(AK)粘贴到BAIDU_MAPS_API_KEY中进行连接测试API KEY是否可用,连接成功后会返回相应的mcpServer配置。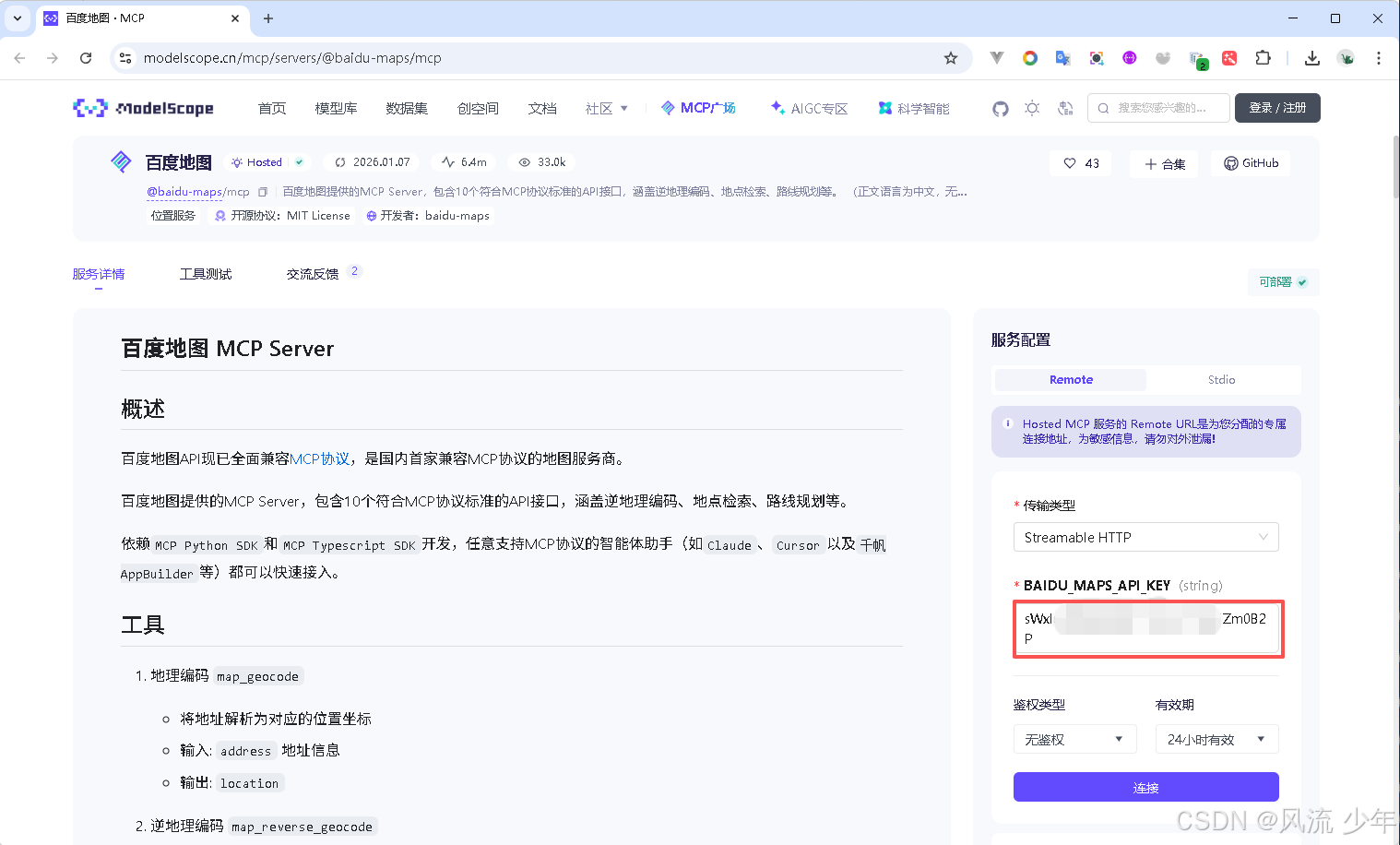
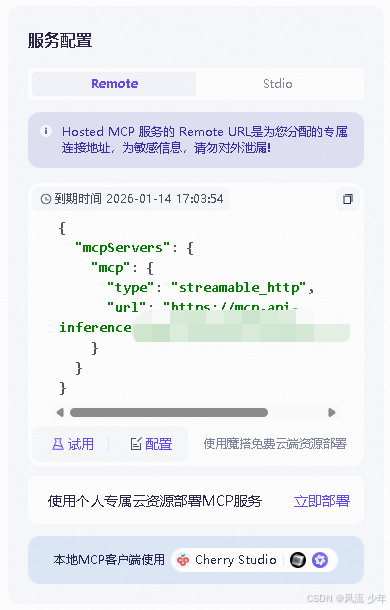
2.1.2 申请大模型API Key
阿里云百炼 模型广场 新增密钥Api-key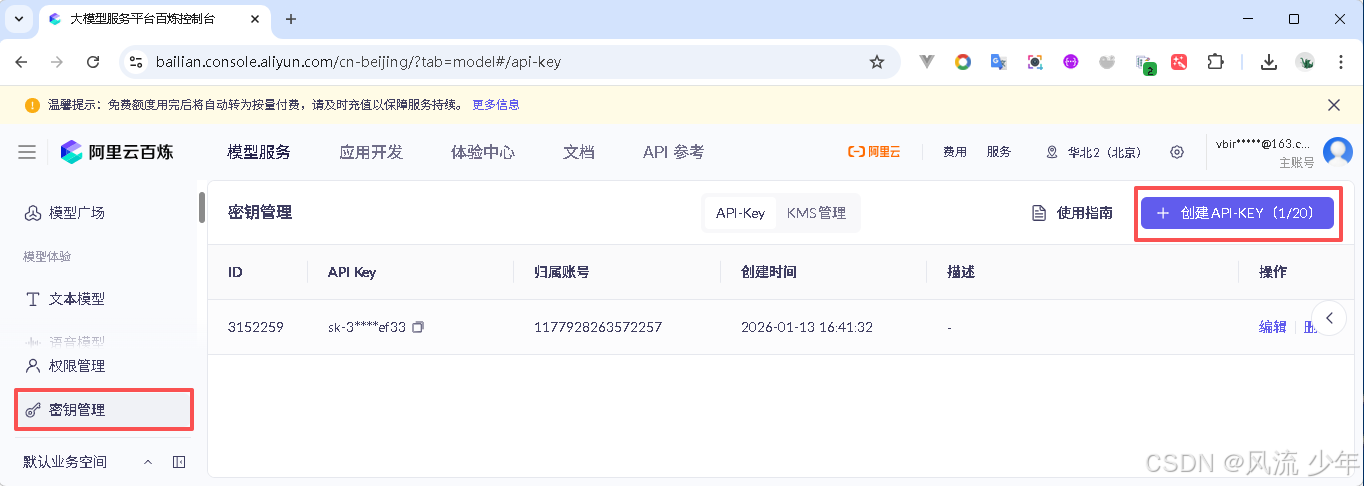
2.2 MCP 客户端( Cherry Studio )
2.2.1 下载Cherry Studio
https://www.cherry-ai.com/,用于测试MCP Server。
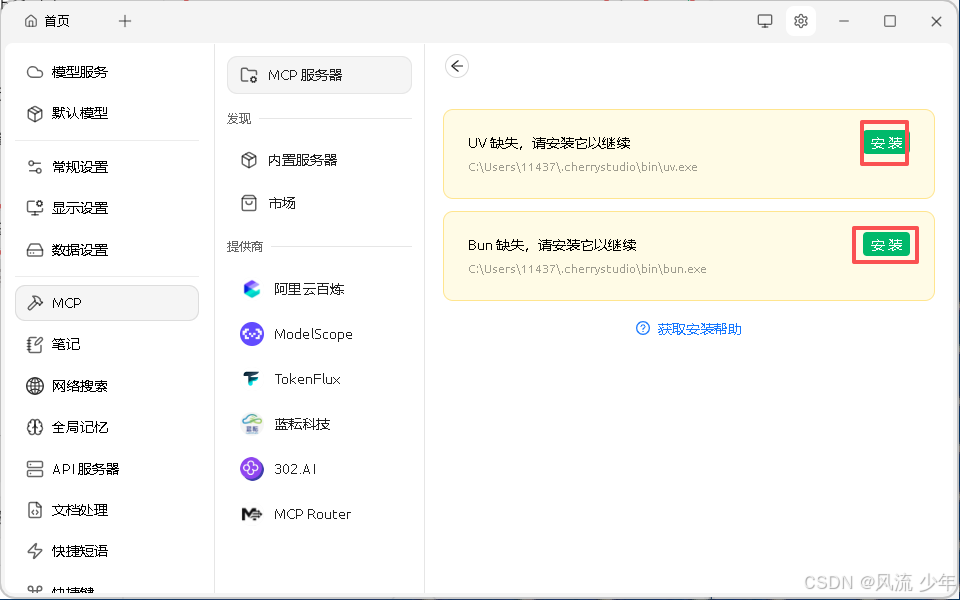
点击设置-MCP,如果有三角形红色警告,把缺失的安装完成。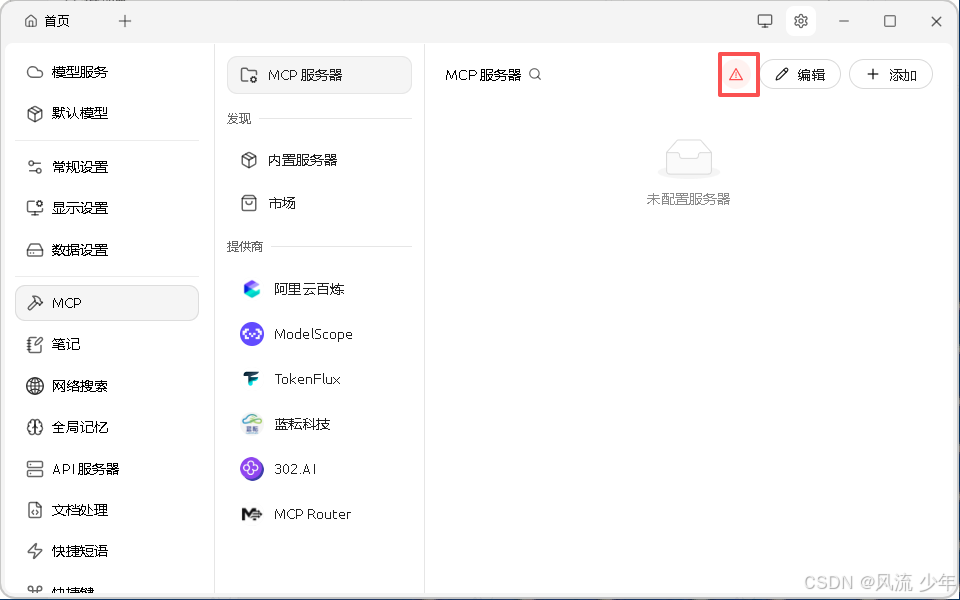
2.2.2 配置阿里云百炼模型
将大模型服务平台中的API Key粘贴到API秘钥中并进行检测。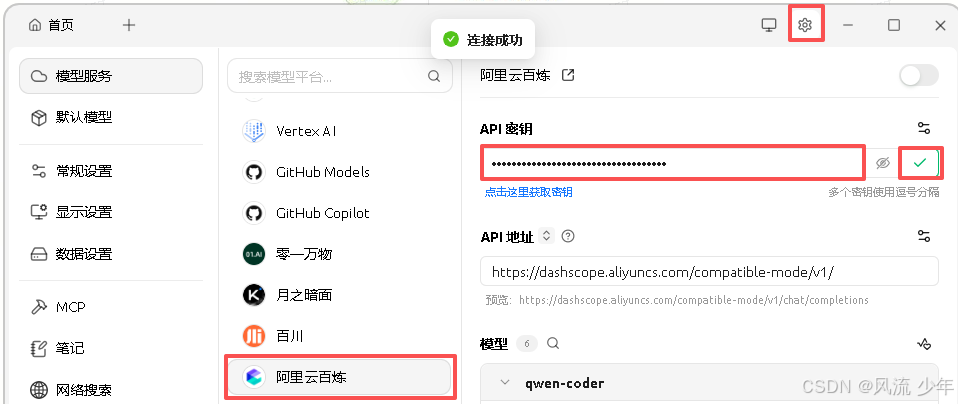
2.2.3 配置百度地图 MCP
添加-从JSON导入,导入成功后可以修改一下名称。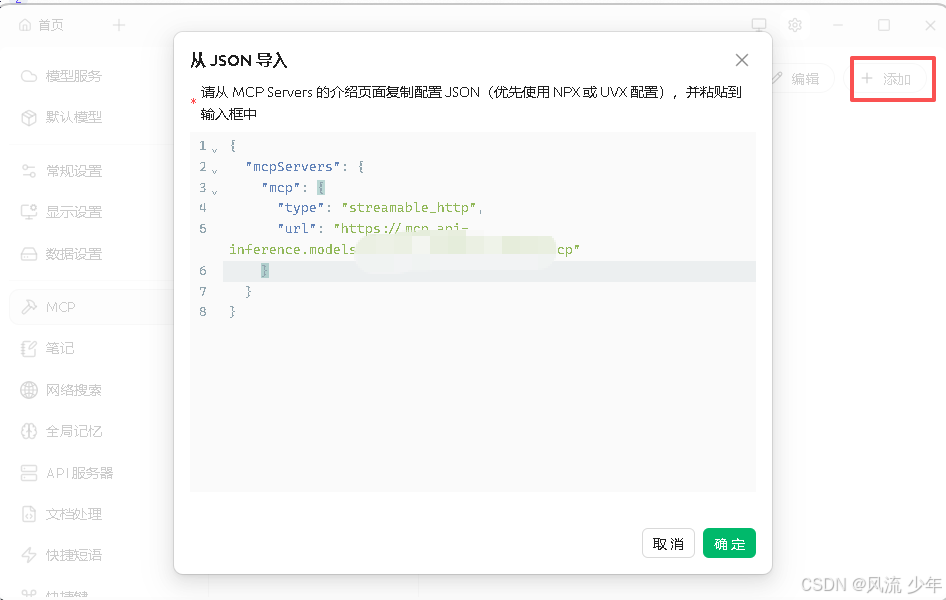
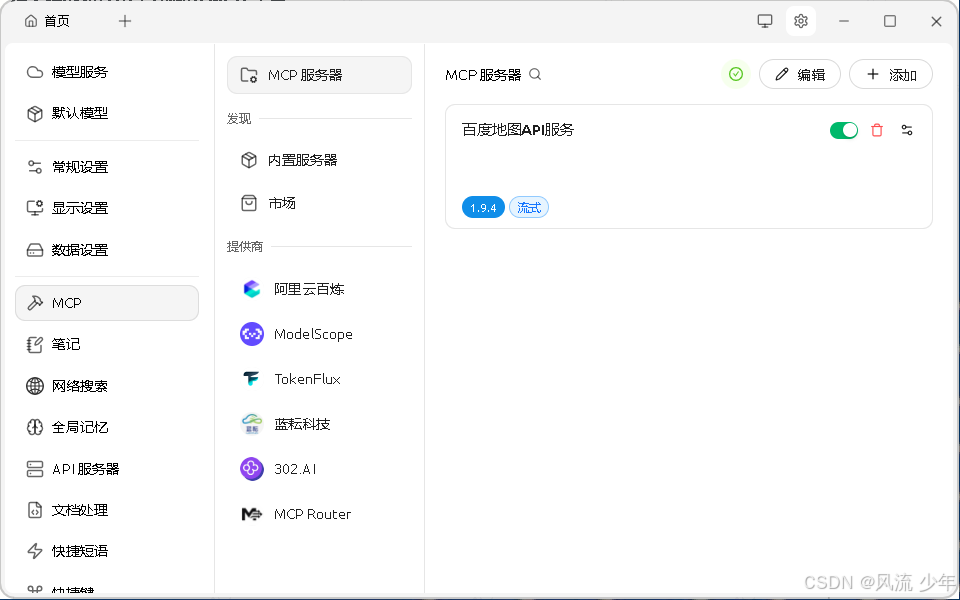
2.3 使用百度地图MCP
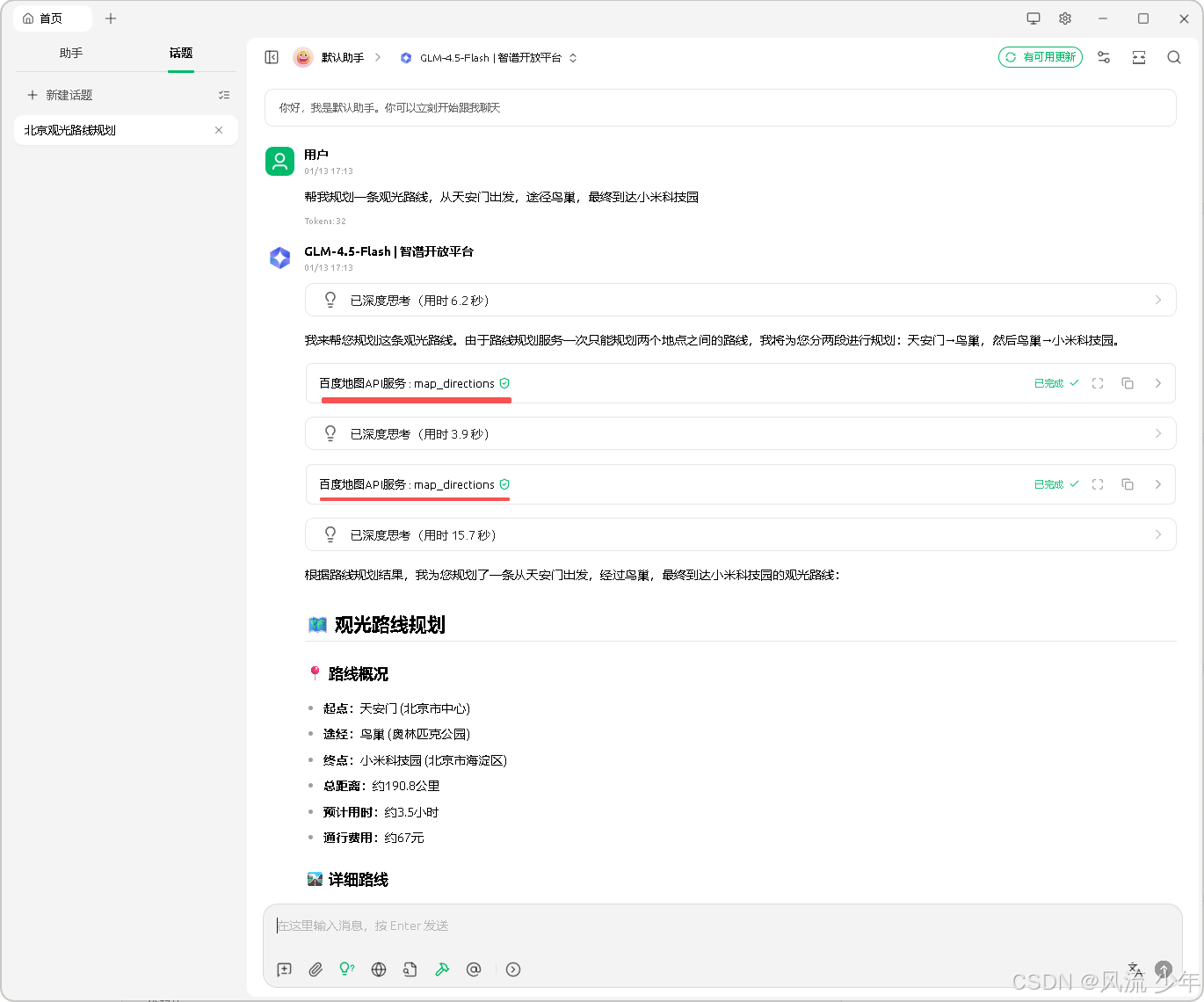
在首页中测试百度地图的MCP。发送,可以看到已经调用百度地图API服务了(先使用大模型进行语义分析获取每个地点,再调用百度地图获取 每个地点的位置,再使用大模型进行路线规划)。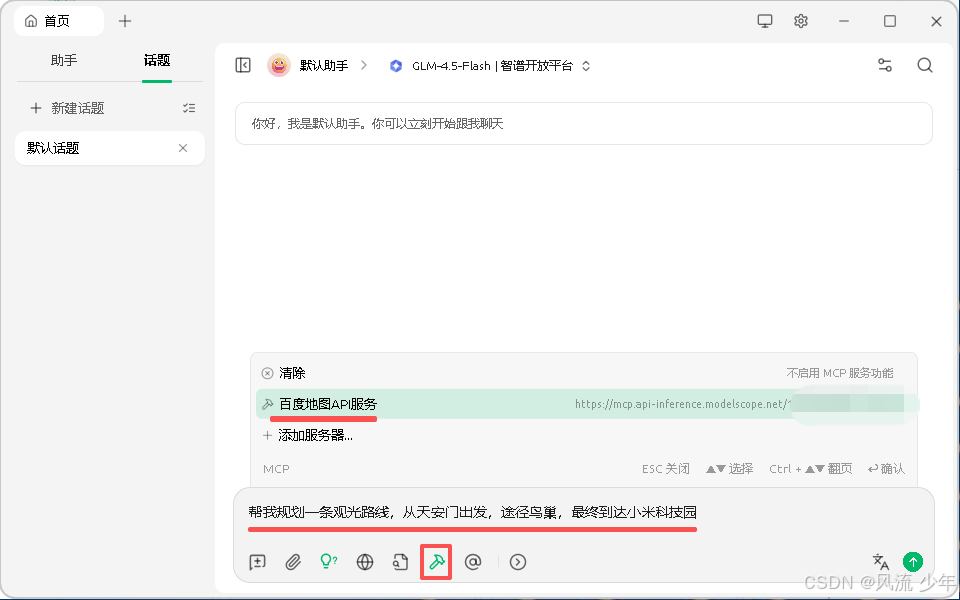
三:自定义MCP服务(和风天气API)
3.0 环境准备
安装UV
官方推荐使用 uv 进行python项目管理,当然也提供了 pip 依赖的安装方式。
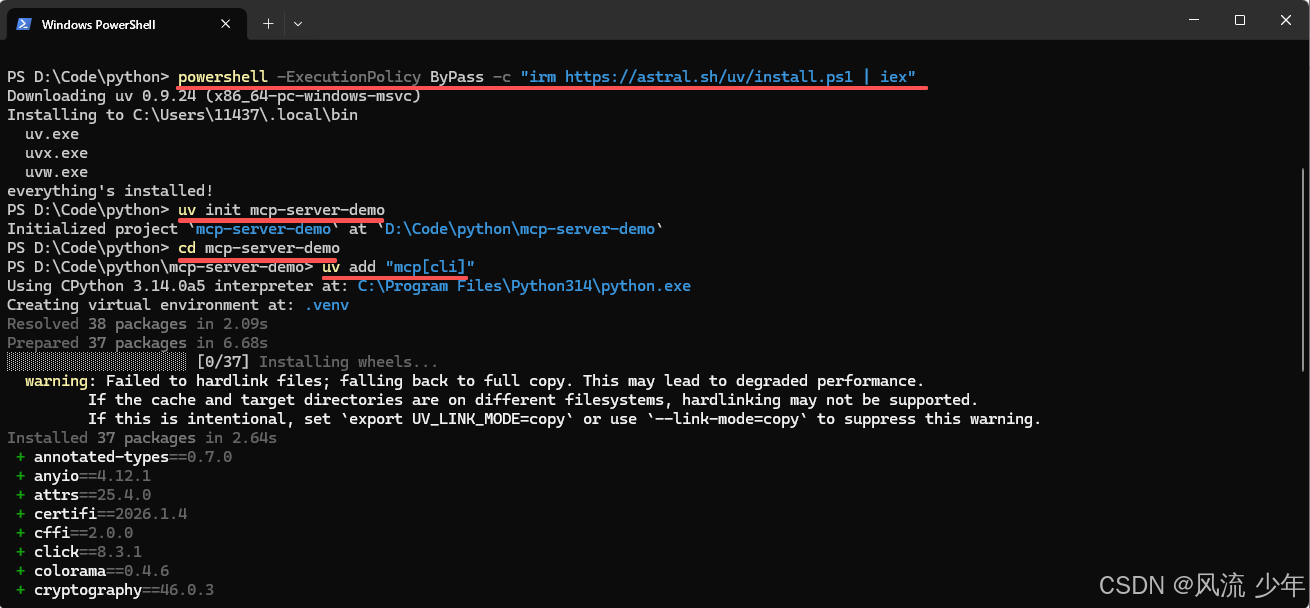
# macOS 以及 Lunux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
初始化项目
uv init mcp-server-demo
cd mcp-server-demo
uv init mcp-server-demo 会在当前目录下创建 mcp-server-demo 文件夹,并初始化项目,包括main.py,uv.lock,.python-version等项目管理需要的文件。
安装依赖
# uv方式
uv add "mcp[cli]"
# pip方式
pip install "mcp[cli]"
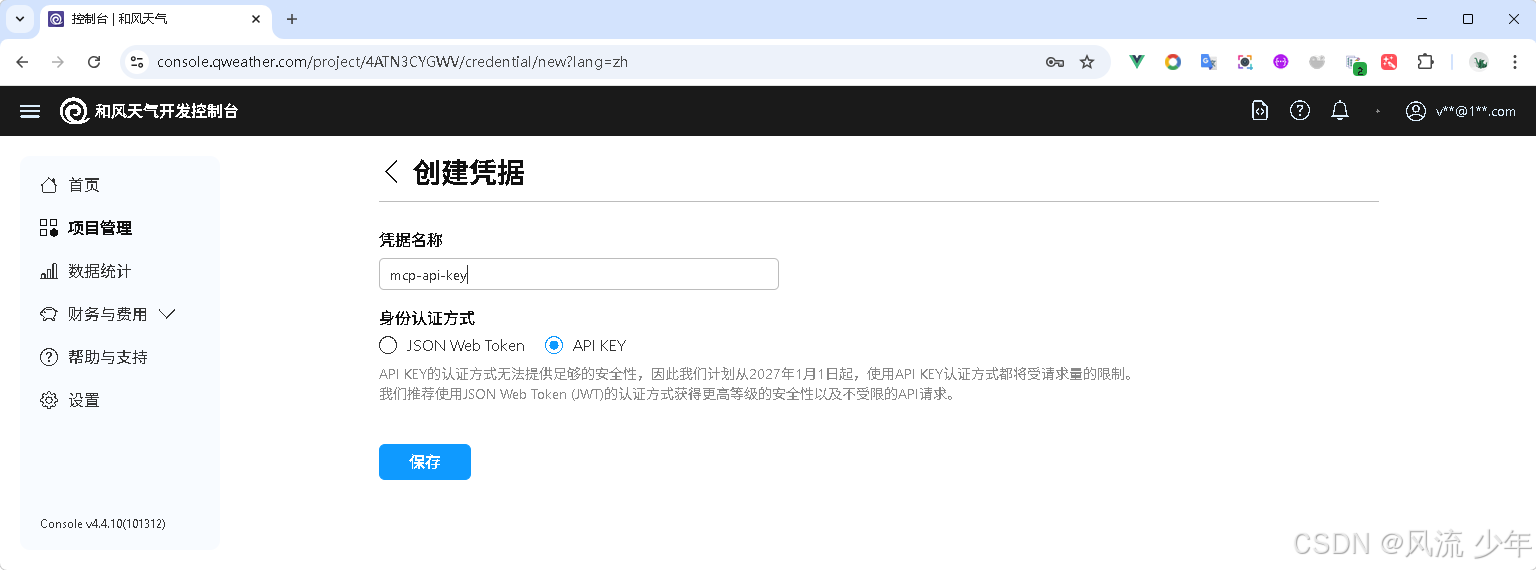
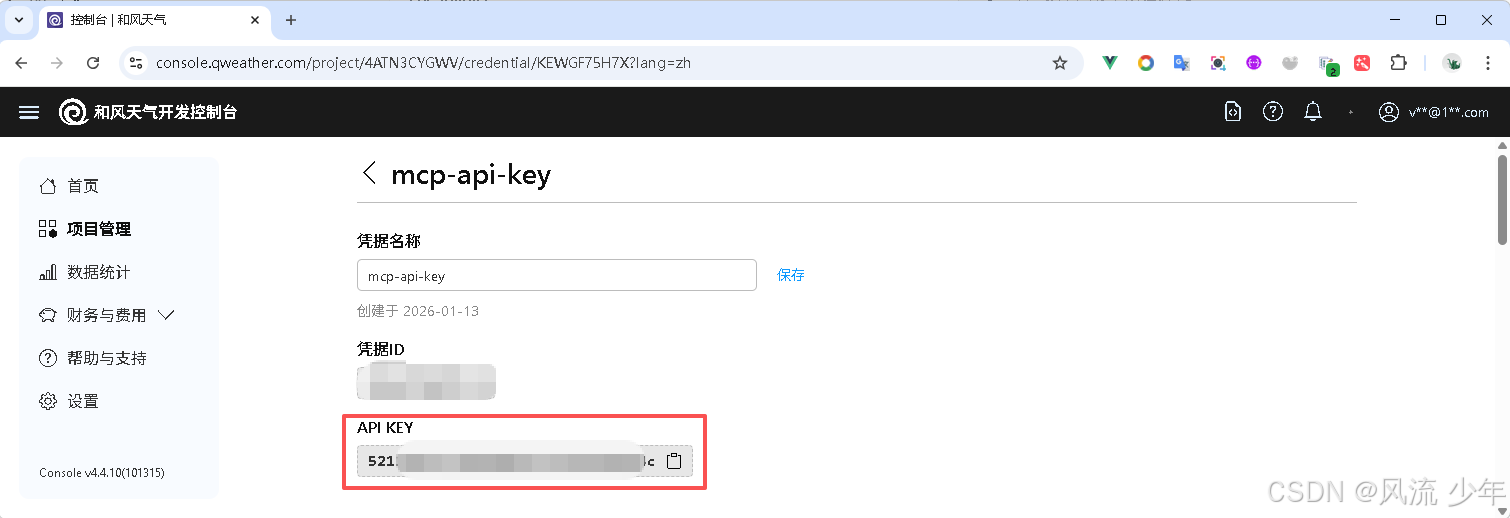
申请和风天气
https://console.qweather.com/ 创建项目,获取API Host和API KEY
设置 - 开发者信息 - API Host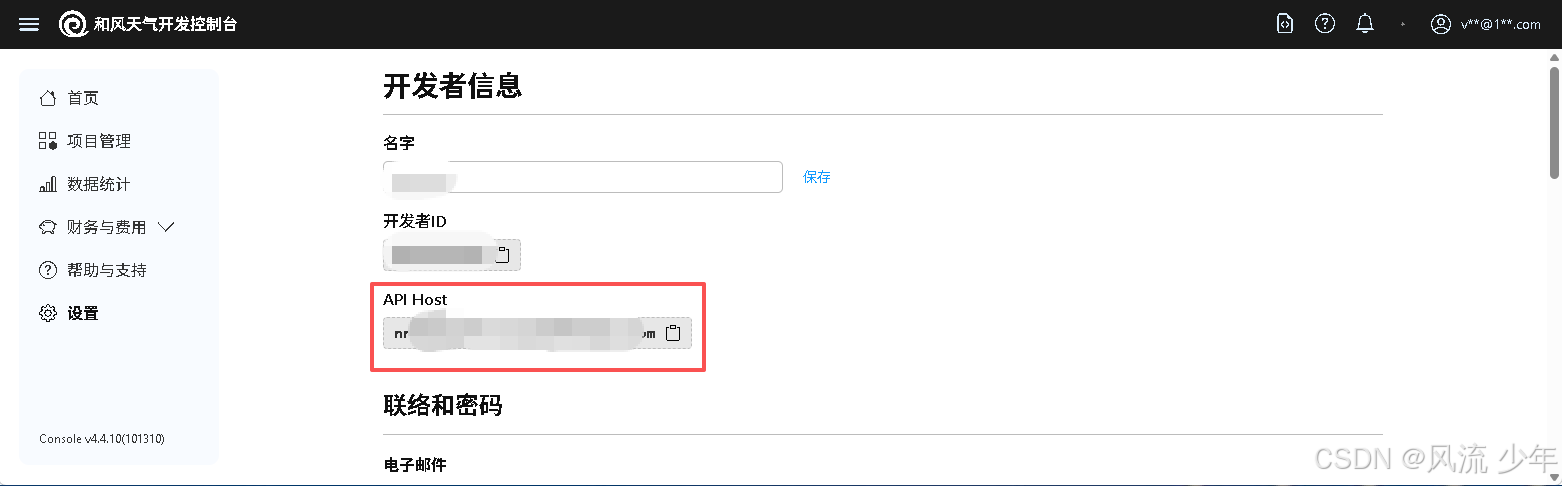
3.1 MCP Server
3.1.1 server.py
HeFeng_BASE_URL 和 HeFeng_API_KEY 需要替换上面的API Host、API KEY。
import json
import os
from mcp.server.fastmcp import FastMCP
import requests
HeFeng_BASE_URL = "https://xxxx.re.qweatherapi.com"
HeFeng_API_KEY = "5211e0??????????????????34c"
CITY_CODE_FILE = "city_code.json"
SERVER_PORT = 9001
MODE="stdio" # stdio or sse
# Create an MCP server
if (MODE == "sse"):
mcp = FastMCP("Weather", port=SERVER_PORT)
else:
mcp = FastMCP("Weather")
# 工具,获取城市码
def get_city_code(city: str) -> str:
API = "/geo/v2/city/lookup?location="
try:
# 首先尝试从本地文件读取
city_code_dict = {}
if os.path.exists(CITY_CODE_FILE):
with open(CITY_CODE_FILE, "r", encoding='utf-8') as f:
city_code_dict = json.load(f)
# 如果城市代码存在,直接返回
if city in city_code_dict:
return city_code_dict[city]
# 如果城市代码不存在,从网络获取
url = HeFeng_BASE_URL + API + city
headers = {
"X-QW-Api-Key":HeFeng_API_KEY
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
if data['code'] == '200' and data['location']:
city_code = data['location'][0]['id']
# 更新本地文件
city_code_dict[city] = city_code
with open(CITY_CODE_FILE, "w", encoding='utf-8') as f:
json.dump(city_code_dict, f, ensure_ascii=False, indent=4)
return city_code
else:
raise Exception(f"未找到城市 {city} 的代码")
else:
raise Exception("网络请求失败")
except Exception as e:
raise Exception(f"获取城市代码失败: {str(e)}")
# MCP服务方法,获取城市的当前天气
@mcp.tool()
def get_current_weather(city: str) -> str:
"""
输入指定城市的中文名称,返回城市的当前天气信息
:param city: 城市的中文名称
:return: 城市的当前天气信息
"""
API = "/v7/weather/now?location="
city_code = get_city_code(city)
url = HeFeng_BASE_URL + API + city_code
headers = {
"X-QW-Api-Key":HeFeng_API_KEY
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
if data['code'] == '200' and data['now']:
weather_info = data['now']
responseStr = f"当前城市: {city}"
responseStr += f"\n天气: {weather_info['text']}"
responseStr += f"\n温度: {weather_info['temp']}°C"
responseStr += f"\n体感温度: {weather_info['feelsLike']}°C"
responseStr += f"\n风力风向: {weather_info['windDir']} {weather_info['windScale']}级"
responseStr += f"\n相对湿度: {weather_info['humidity']}%"
return responseStr
else:
return f"未找到城市 {city} 的天气信息"
else:
return "网络请求失败"
import sys
# 添加启动日志(输出到 stderr,避免干扰 stdio 通信)
print("MCP Server starting...", file=sys.stderr)
print(f"Transport mode: {MODE}", file=sys.stderr)
print(f"Working directory: {os.getcwd()}", file=sys.stderr)
mcp.run(transport=MODE)
3.1.2 启动server.py
# 安装inspector
npm install -g @modelcontextprotocol/inspector
# 如果启动报错直接让AI修复提示词:uv run mcp dev server.py启动没有输出任何内容,并且http://localhost:6274无法访问
# 运行成功后会自动打开浏览器 http://localhost:6274/?MCP_PROXY_AUTH_TOKEN=xxx
mcp dev server.py
注意:一定要看到Starting MCP insepector…
3.1.3 调试工具
点击Connect进行连接,连接成功后为Connected,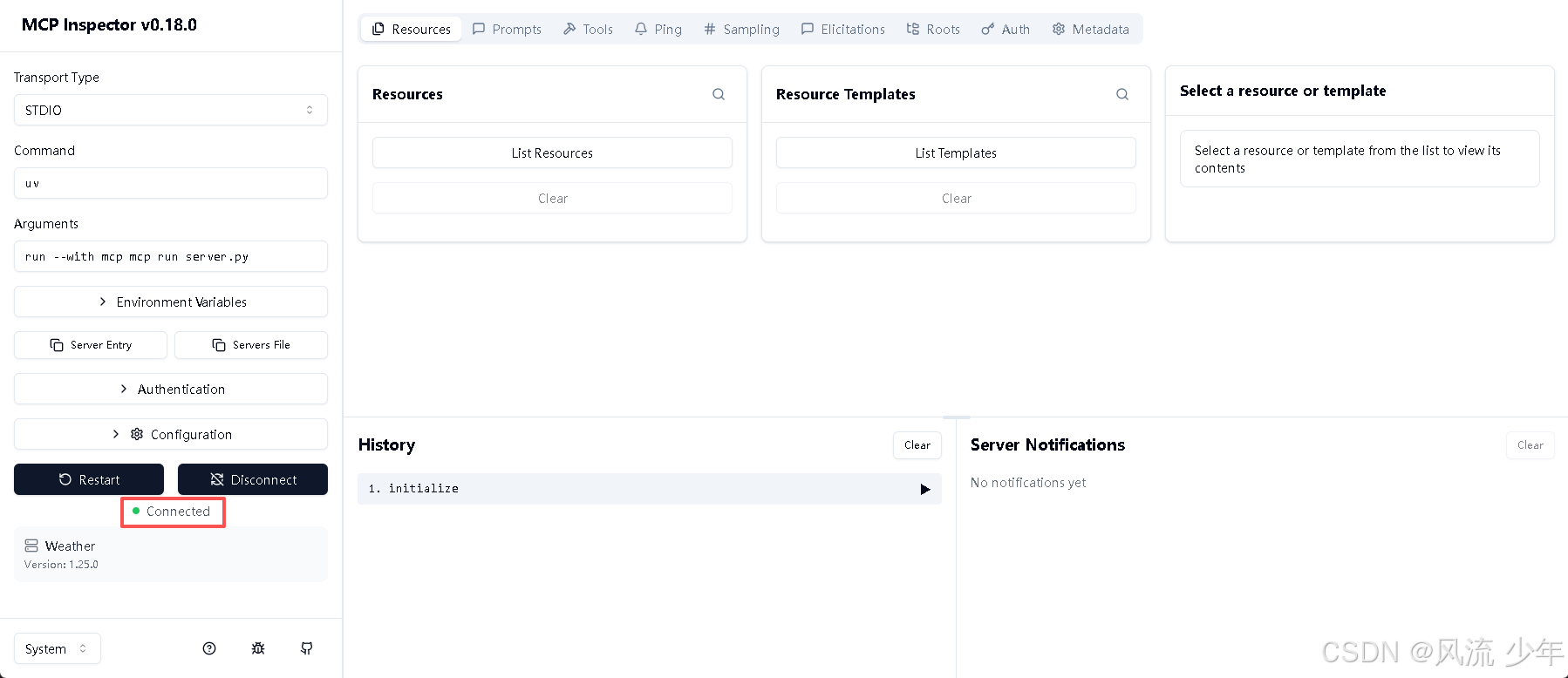
此时MCP Inspector会暴露我们代码中公开的Resources,Prompts和Tools,由于我们目前只定义了一个 @mcp.tool(),所以可以直接进入Tools标签页,点击 List Tools 即可看到我们刚刚创建的工具,以及工具描述。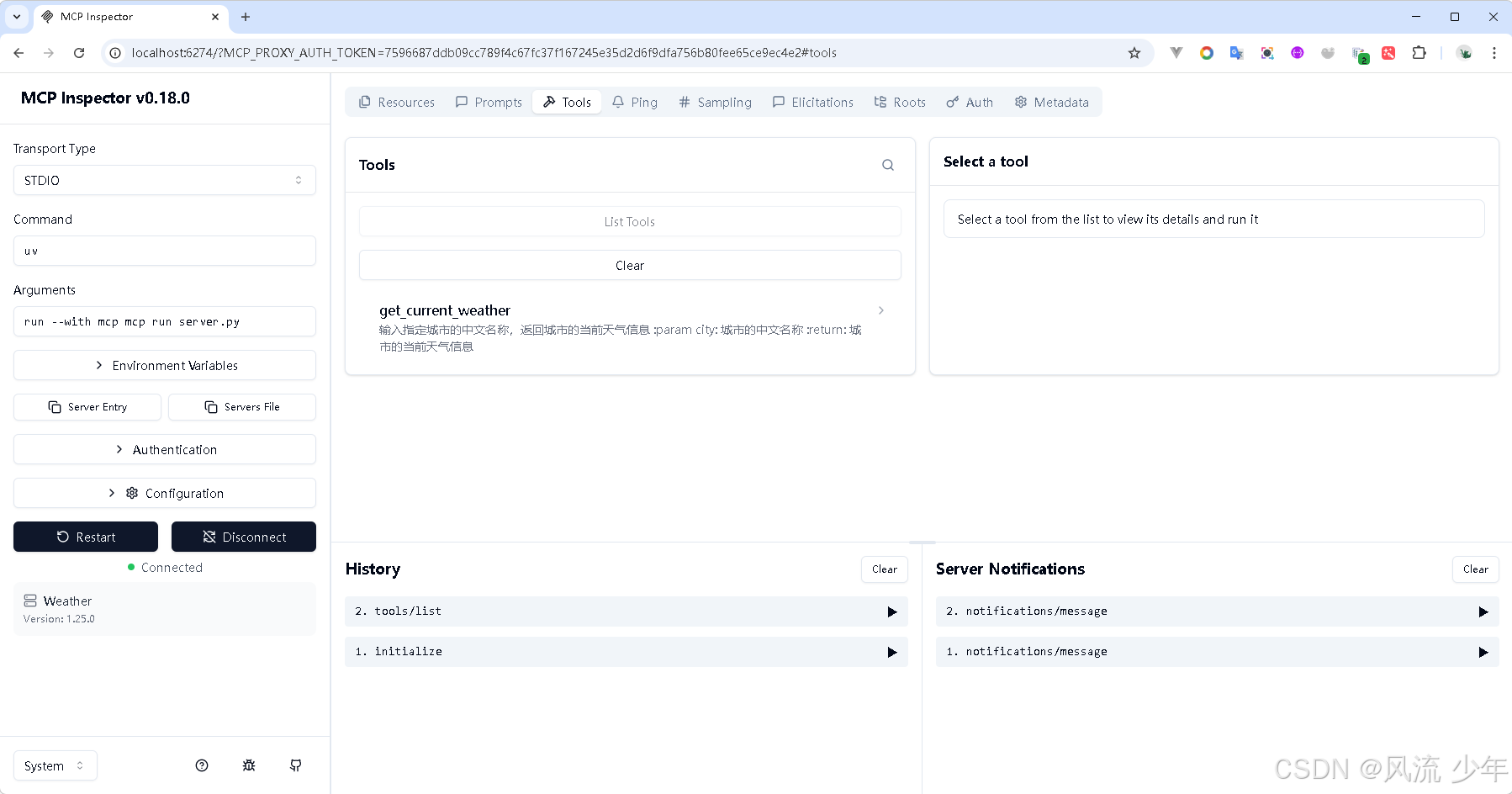
点击工具名称,就可以在右边开始调试server.py中的tool了。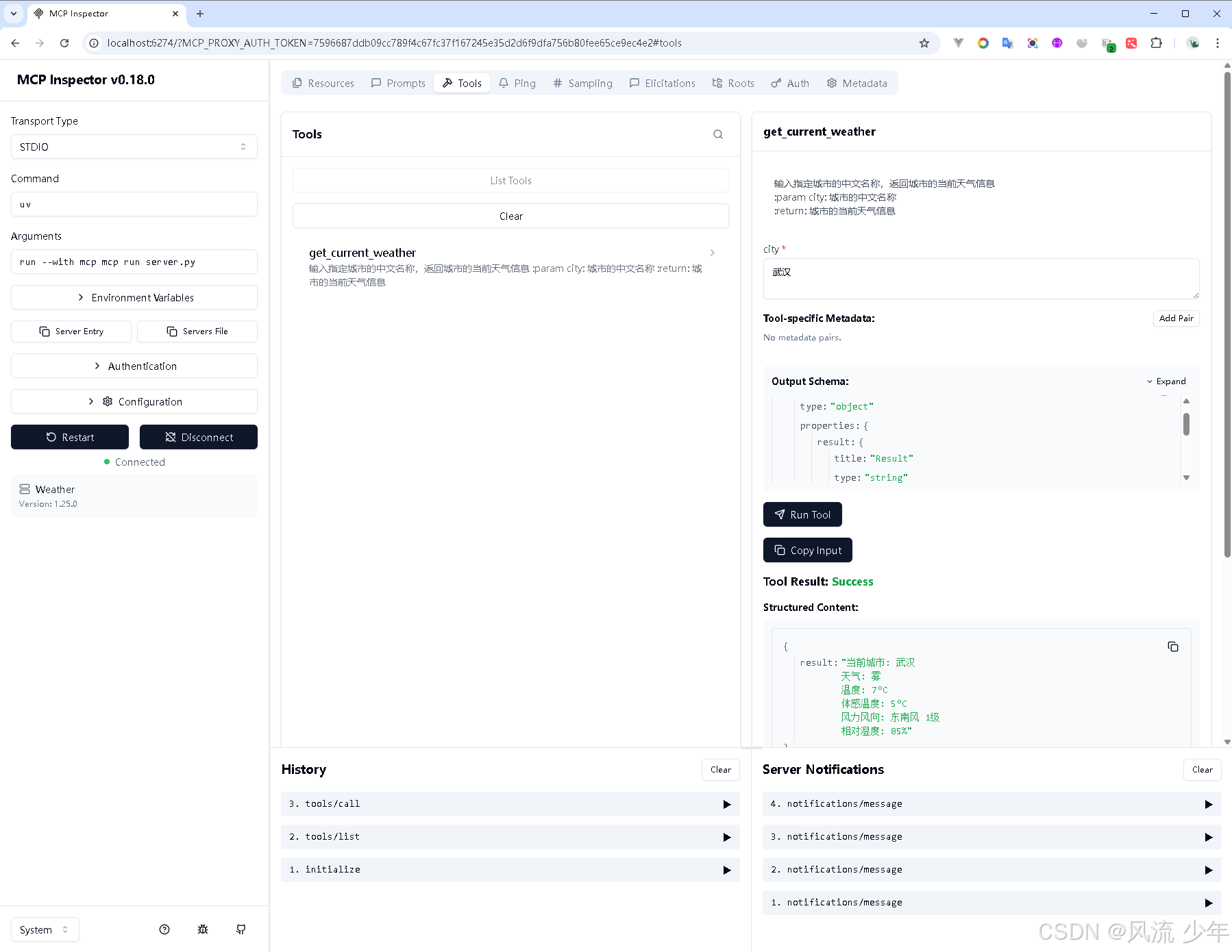
3.2 MCP Client
3.2.1 下载Ollama
从官网下载 Ollama 推理框架 https://ollama.com/download
安装完成后下载模型 ollama run qwen3:8b (5G大小),最好下载qwq模型,而qwen3:8在后面使用时会超时。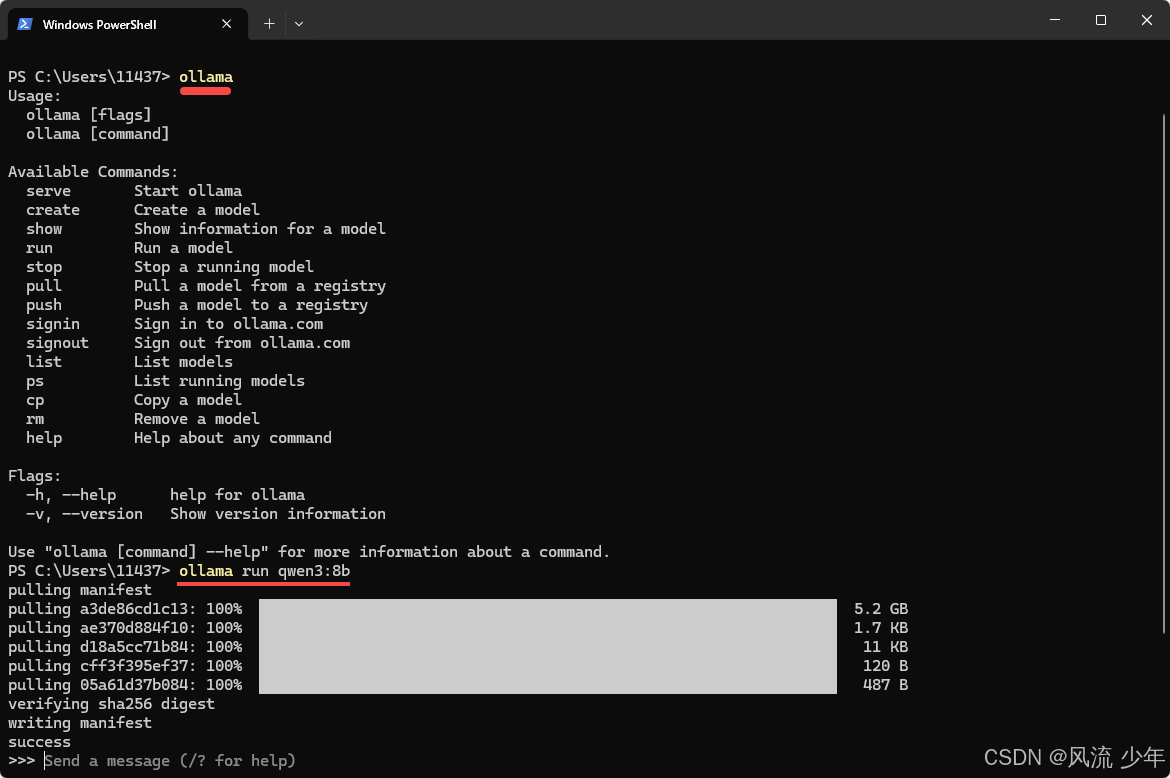
ollama run qwq(建议,19G大小)
下载完成后就可以选择qwq。
3.3.2 client.py
注意:安装必要的依赖,os.getenv(“OLLAMA_MODEL”, “qwen3:8b”) 中的模型名字和上面的模型名字保持一致。
import asyncio
import os
import sys
import json
from typing import Optional
from contextlib import AsyncExitStack
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
class MCPClient:
def __init__(self):
"""初始化MCP客户端"""
load_dotenv()
self.exit_stack = AsyncExitStack()
# Ollama 的 OpenAI 兼容端点
base_url = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434/v1")
# 修改为 OpenAI 兼容的基础 URL
if "/api/generate" in base_url:
base_url = base_url.replace("/api/generate", "")
self.model = os.getenv("OLLAMA_MODEL", "qwen3:8b")
# 初始化 OpenAI 客户端
self.client = OpenAI(
base_url=base_url,
api_key="ollama" # Ollama 不需要真正的 API 密钥,但 OpenAI 客户端需要一个非空值
)
self.session: Optional[ClientSession] = None
async def connect_to_server(self, server_script_path: str):
"""连接到 MCP 服务器并列出可用工具"""
is_python = server_script_path.endswith(".py")
is_js = server_script_path.endswith(".js")
if not (is_python or is_js):
raise ValueError("服务器脚本必须是 Python 或 JavaScript 文件")
# 使用 stdio_client 连接到 MCP 服务器
command = "python" if is_python else "node"
print(f"使用命令: {command} {server_script_path}")
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
# 启动 MCP 服务器并建立通讯
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# 列出 MCP 服务器上的工具
response = await self.session.list_tools()
tools = response.tools
print("\n可用工具:")
for tool in tools:
print(f" {tool.name}: {tool.description}")
async def process_query(self, query: str) -> str:
"""使用 OpenAI 客户端调用 Ollama API 处理用户查询"""
messages = [{"role": "user", "content": query}]
response = await self.session.list_tools()
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
}
} for tool in response.tools]
try:
# 使用 OpenAI 客户端请求
response = await asyncio.to_thread(
lambda: self.client.chat.completions.create(
model=self.model,
messages=messages,
tools = available_tools
)
)
# 从响应中提取文本
content = response.choices[0]
if content.finish_reason == "tool_calls":
# 如果是需要实用工具,就解析工具
tool_call = content.message.tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 执行工具
result = await self.session.call_tool(tool_name, tool_args)
print(f"\n\n工具 {tool_name} 参数 {tool_args} 返回结果: {result}\n\n")
# 将模型返回的工具数据和执行结果都存入message中
messages.append(content.message.model_dump())
messages.append({
"role": "tool",
"content": result.content[0].text,
"tool_call_id": tool_call.id
})
# 将上述结果再返回给大模型用于生成最终结果
response = self.client.chat.completions.create(
model=self.model,
messages=messages
)
return response.choices[0].message.content
except Exception as e:
import traceback
# 收集详细错误信息
error_details = {
"异常类型": type(e).__name__,
"异常消息": str(e),
"请求URL": self.client.base_url,
"请求模型": self.model,
"请求内容": query[:100] + "..." if len(query) > 100 else query
}
print(f"Ollama API 调用失败:详细信息如下:")
for key, value in error_details.items():
print(f" {key}: {value}")
print("\n调用堆栈:")
traceback.print_exc()
return "抱歉,发生未知错误,我暂时无法回答这个问题。"
async def chat_loop(self):
"""交互式聊天循环"""
print("\n欢迎使用MCP客户端!输入 'quit' 退出")
while True:
try:
query = input("\n你: ").strip()
if query.lower() == 'quit':
print("再见!")
break
response = await self.process_query(query)
print(f"\nOllama: {response}")
except Exception as e:
print(f"\n发生错误:{e}")
async def cleanup(self):
"""清理资源"""
await self.exit_stack.aclose()
async def main():
if (len(sys.argv) < 2) :
print("请提供MCP服务器的脚本路径")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_server(sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
同时启动客户端和服务端。
uv run python client.py server.py
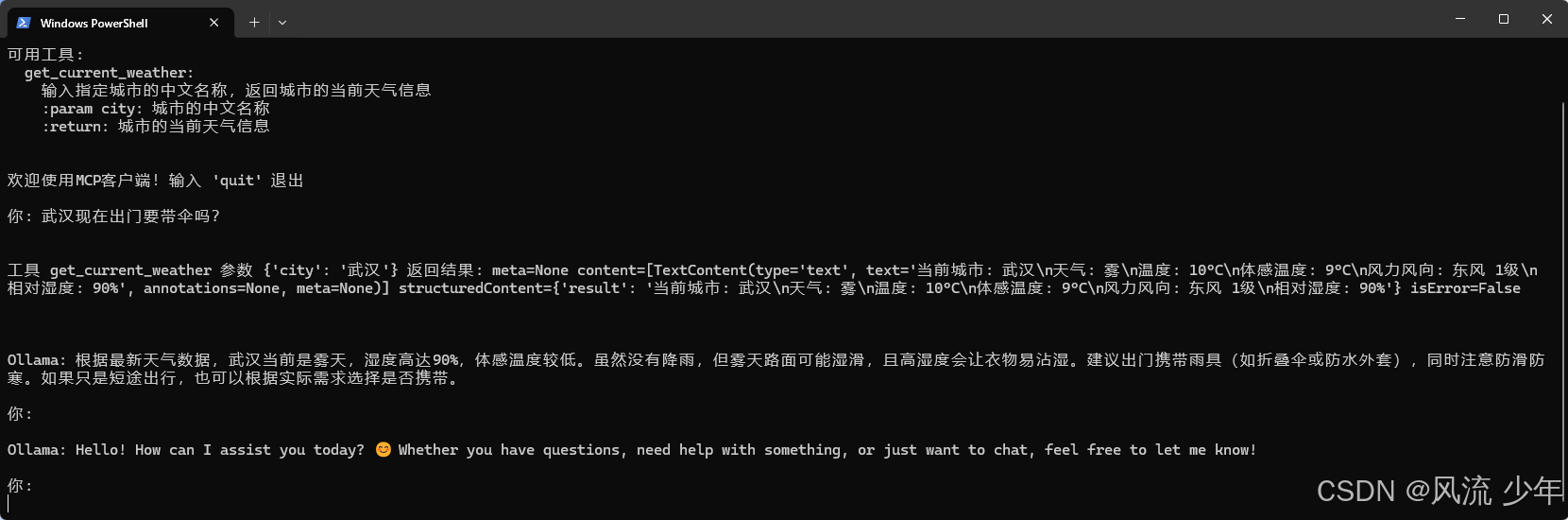
可以看到大模型成功提取出了工具需要的关键字,调用了工具,并依据工具的返回结果进行了最终推理(注意:回答 可能很慢,看机器配置,等几分钟,只要不报错就静静等待)。
四:自定义MCP服务(MongoDB数据库)
4.0 环境准备
MongoDB社区版下载安装 https://www.mongodb.com/try/download/community
MongoDB GUI工具下载安装 https://www.mongodb.com/try/download/terraform-provider
启动MongoDB数据库。
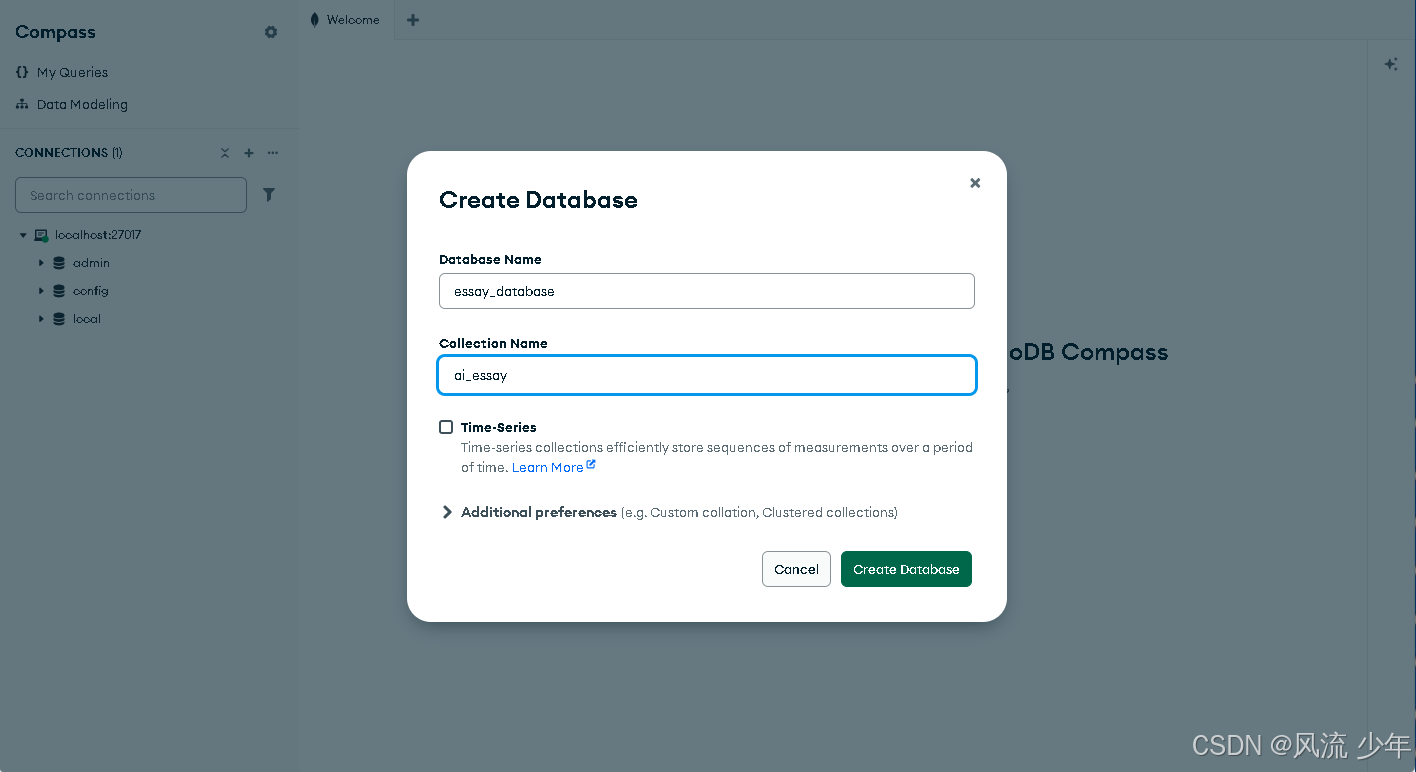
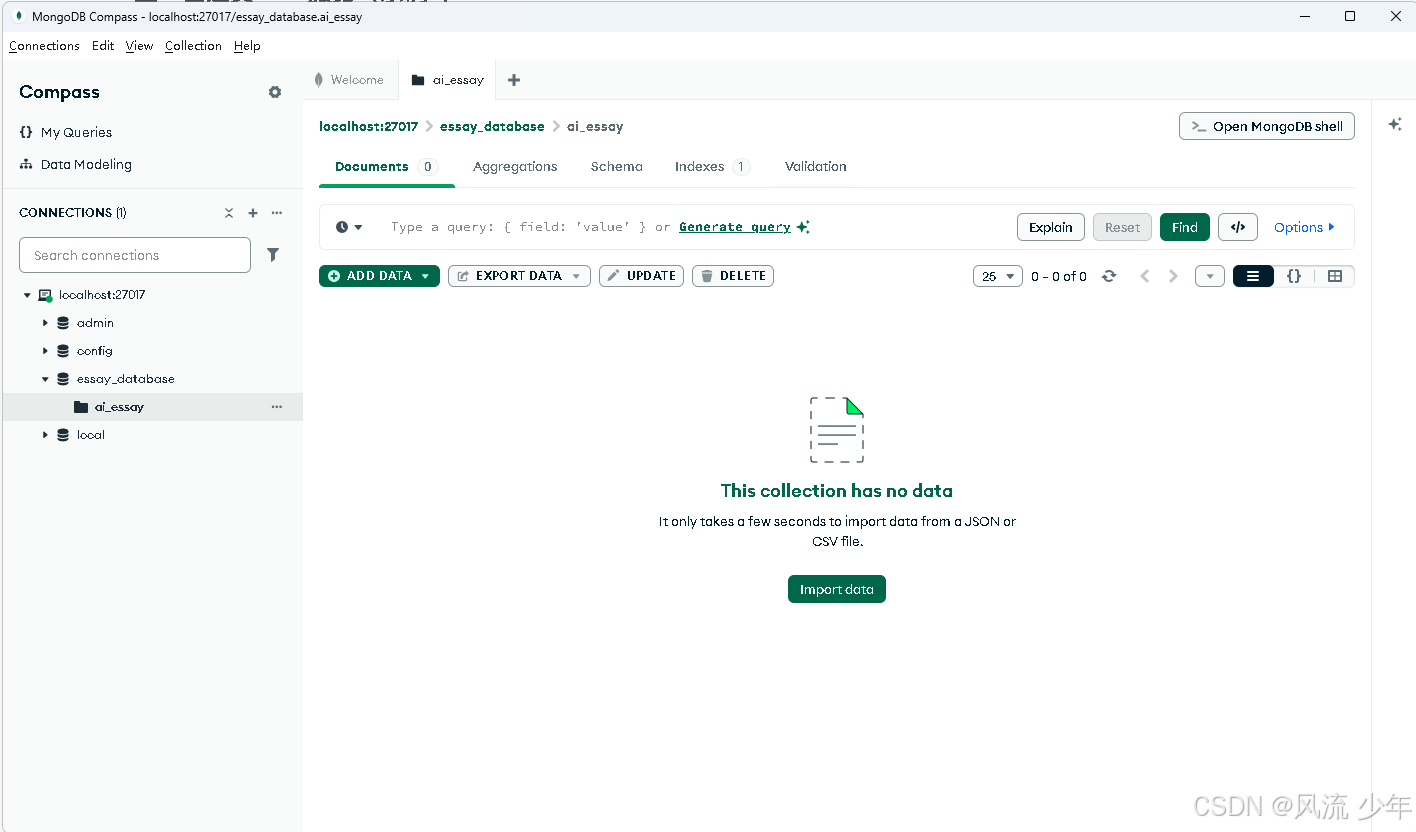
4.1 数据准备
essay_database_insert_essay.py:输入 arxiv.org 论文的链接,获取论文内容,解析整理并存入本地的 MongoDB 数据库。
import re
import os
import requests
import io
import json
import pymongo
import datetime
from urllib.parse import urlparse
from pymongo import MongoClient
from PyPDF2 import PdfReader
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# MongoDB连接设置
MONGO_URI = os.getenv("MONGO_URI", "mongodb://localhost:27017/")
DB_NAME = os.getenv("DB_NAME", "essay_database")
COLLECTION_NAME = os.getenv("COLLECTION_NAME", "ai_essay")
# Ollama设置
OLLAMA_BASE_URL = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434/api")
OLLAMA_MODEL = os.getenv("OLLAMA_MODEL", "qwen3:8b")
def connect_to_mongodb():
"""连接到MongoDB数据库"""
try:
client = MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
return collection
except Exception as e:
print(f"MongoDB连接错误: {e}")
return None
def extract_arxiv_id(url):
"""从URL中提取arXiv ID"""
# 移除URL中的http://或https://前缀,如果存在
url = url.strip()
if url.startswith(('http://', 'https://')):
parsed = urlparse(url)
url = parsed.netloc + parsed.path
# 从URL中提取arXiv ID
match = re.search(r'arxiv\.org/pdf/(\d+\.\d+)(v\d+)?', url)
if match:
arxiv_id = match.group(1)
version = match.group(2) if match.group(2) else ""
return arxiv_id + version
return None
def download_pdf(arxiv_id):
"""下载arXiv PDF文件"""
url = f"https://arxiv.org/pdf/{arxiv_id}.pdf"
try:
response = requests.get(url)
response.raise_for_status()
return io.BytesIO(response.content)
except Exception as e:
print(f"PDF下载错误: {e}")
return None
def extract_pdf_text(pdf_stream):
"""从PDF中提取文本内容"""
try:
reader = PdfReader(pdf_stream)
text = ""
for page in reader.pages:
text += page.extract_text()
return text
except Exception as e:
print(f"PDF解析错误: {e}")
return ""
def extract_pdf_metadata(pdf_stream, arxiv_id):
"""从PDF中提取元数据"""
try:
reader = PdfReader(pdf_stream)
metadata = reader.metadata
# 获取标题和作者
title = metadata.get('/Title', f"Untitled-{arxiv_id}")
authors_raw = metadata.get('/Author', "Unknown")
# 处理作者列表
authors = []
if authors_raw != "Unknown":
# 尝试分割作者(根据实际情况可能需要调整)
author_candidates = re.split(r',\s*|;\s*|\sand\s', authors_raw)
for author in author_candidates:
author = author.strip()
if author:
authors.append(author)
# 获取发布日期
publish_date = metadata.get('/CreationDate', "")
if publish_date:
# 尝试解析PDF元数据中的日期格式
match = re.search(r'D:(\d{4})(\d{2})(\d{2})', publish_date)
if match:
publish_date = f"{match.group(1)}-{match.group(2)}-{match.group(3)}"
else:
publish_date = datetime.datetime.now().strftime("%Y-%m-%d")
else:
publish_date = datetime.datetime.now().strftime("%Y-%m-%d")
return {
"title": title,
"authors": authors,
"publish_date": publish_date
}
except Exception as e:
print(f"元数据提取错误: {e}")
return {
"title": f"Untitled-{arxiv_id}",
"authors": [],
"publish_date": datetime.datetime.now().strftime("%Y-%m-%d")
}
def extract_info_with_ollama(text, query_type):
"""使用Ollama提取文章的类别、关键词、标题或作者"""
prompt = ""
if query_type == "categories":
prompt = f"""
以下是一篇学术论文的摘要,请从中提取出该论文所属的学术类别(最多10个),返回一个JSON格式的类别列表,格式为:["类别1", "类别2", ...]。
尽量使用标准的学术领域分类,如"NLP", "Computer Vision", "Machine Learning"等。
论文摘要:
{text[:10000]}
"""
elif query_type == "keywords":
prompt = f"""
以下是一篇学术论文的摘要,请从中提取出该论文的关键词(最多15个),返回一个JSON格式的关键词列表,格式为:["关键词1", "关键词2", ...]。
论文摘要:
{text[:10000]}
"""
elif query_type == "title":
prompt = f"""
你是一个精确的标题提取工具。请从以下学术论文的开头部分提取出论文的标题。
重要说明:
1. 只返回标题文本本身,不要包含任何解释、思考过程或额外内容
2. 不要使用引号或其他标点符号包裹标题
3. 不要使用"标题是:"或类似的前缀
4. 不要使用<think>或任何标记
5. 不要使用多行,只返回一行标题文本
论文内容开头:
{text[:1000]}
"""
elif query_type == "authors":
prompt = f"""
你是一个精确的作者信息提取工具。请从以下学术论文的开头部分提取出所有作者名字。
重要说明:
1. 直接返回JSON格式的作者列表,格式必须如下:["作者1", "作者2", ...]
2. 不要包含任何解释、思考过程或额外内容
3. 不要使用<think>或任何标记
4. 仅返回包含作者名字的JSON数组,不要有其他文本
论文内容开头:
{text[:1000]}
"""
try:
response = requests.post(
f"{OLLAMA_BASE_URL}/generate",
json={
"model": OLLAMA_MODEL,
"prompt": prompt,
"stream": False
}
)
response.raise_for_status()
response_data = response.json()
content = response_data.get("response", "")
# 移除可能的思维链标记
content = re.sub(r'<think>.*?</think>', '', content, flags=re.DOTALL)
content = content.strip()
# 对于标题查询,直接返回文本内容
if query_type == "title":
# 清理标题(去除多余空格、换行和引号)
title = re.sub(r'\s+', ' ', content).strip()
# 移除可能的前缀
title = re.sub(r'^(标题是[::]\s*|论文标题[::]\s*|题目[::]\s*|Title[::]*\s*)', '', title, flags=re.IGNORECASE)
# 移除可能的引号
title = re.sub(r'^["\'「『]+|["\'」』]+$', '', title)
# 限制标题长度
if len(title) > 300:
title = title[:300] + "..."
return title
# 对于作者、类别和关键词,尝试提取JSON数组
json_match = re.search(r'\[.*?\]', content, re.DOTALL)
if json_match:
try:
return json.loads(json_match.group(0))
except json.JSONDecodeError:
# 如果JSON解析失败,尝试以其他方式提取
if query_type == "authors":
# 尝试提取逗号分隔的作者
authors = [a.strip() for a in content.split(',') if a.strip()]
# 清理可能的引号
authors = [re.sub(r'^["\'「『]+|["\'」』]+$', '', a) for a in authors]
if authors:
return authors
# 如果是作者查询但无法提取JSON,尝试匹配常见的作者模式
if query_type == "authors":
# 尝试从文本中提取可能的作者名
author_lines = [line.strip() for line in content.split('\n') if line.strip()]
# 清理可能的引号和其他标记
author_lines = [re.sub(r'^["\'「『]+|["\'」』]+$', '', line) for line in author_lines]
if author_lines:
return author_lines[:5] # 限制返回最多5个作者
# 如果无法提取,返回空列表或默认值
return [] if query_type in ["categories", "keywords", "authors"] else ""
except Exception as e:
print(f"Ollama API调用错误 ({query_type}): {e}")
return [] if query_type in ["categories", "keywords", "authors"] else ""
def insert_essay_to_mongodb(collection, essay_data):
"""将论文数据插入MongoDB"""
try:
result = collection.insert_one(essay_data)
return result.inserted_id
except Exception as e:
print(f"数据库插入错误: {e}")
return None
def main():
# 连接MongoDB
collection = connect_to_mongodb()
if collection is None:
print("无法连接到MongoDB,程序退出")
return
# 获取用户输入的arXiv URL
url = input("请输入arXiv论文URL (例如: https://arxiv.org/pdf/2501.09898v4): ")
# 提取arXiv ID
arxiv_id = extract_arxiv_id(url)
if not arxiv_id:
print("无效的arXiv URL")
return
print(f"正在下载arXiv ID为 {arxiv_id} 的论文...")
# 下载PDF
pdf_stream = download_pdf(arxiv_id)
if not pdf_stream:
print("PDF下载失败")
return
# 提取文本和元数据
pdf_stream_copy = io.BytesIO(pdf_stream.getvalue()) # 创建一个副本用于提取文本
pdf_text = extract_pdf_text(pdf_stream)
metadata = extract_pdf_metadata(pdf_stream_copy, arxiv_id)
print("PDF解析完成,正在使用Ollama提取信息...")
# 检查标题是否有效,如果无效则使用大模型提取
title = metadata["title"]
if title == f"Untitled-{arxiv_id}" or not title or title.strip() == "":
print("元数据中未找到有效标题,尝试使用大模型提取...")
title = extract_info_with_ollama(pdf_text[:5000], "title")
if title:
metadata["title"] = title
# 检查作者是否有效,如果无效则使用大模型提取
authors = metadata["authors"]
if not authors:
print("元数据中未找到作者信息,尝试使用大模型提取...")
authors = extract_info_with_ollama(pdf_text[:5000], "authors")
if authors:
metadata["authors"] = authors
# 使用Ollama提取类别和关键词
categories = extract_info_with_ollama(pdf_text[:5000], "categories")
keywords = extract_info_with_ollama(pdf_text[:5000], "keywords")
# 准备要插入的数据
essay_data = {
"arxiv_id": arxiv_id,
"title": metadata["title"],
"authors": metadata["authors"],
"categories": categories,
"keywords": keywords,
"content": pdf_text,
"publish_date": metadata["publish_date"],
"insert_date": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
# 插入数据库
inserted_id = insert_essay_to_mongodb(collection, essay_data)
if inserted_id:
print(f"论文已成功添加到数据库,ID: {inserted_id}")
print(f"标题: {metadata['title']}")
print(f"作者: {', '.join(metadata['authors'])}")
print(f"类别: {', '.join(categories)}")
print(f"关键词: {', '.join(keywords)}")
print(f"发布日期: {metadata['publish_date']}")
else:
print("论文添加失败")
if __name__ == "__main__":
main()
运行essay_database_insert_essay.py
# https://arxiv.org/pdf/2504.05299v1
# https://arxiv.org/pdf/2501.09898v4
uv run essay_database_insert_essay.py
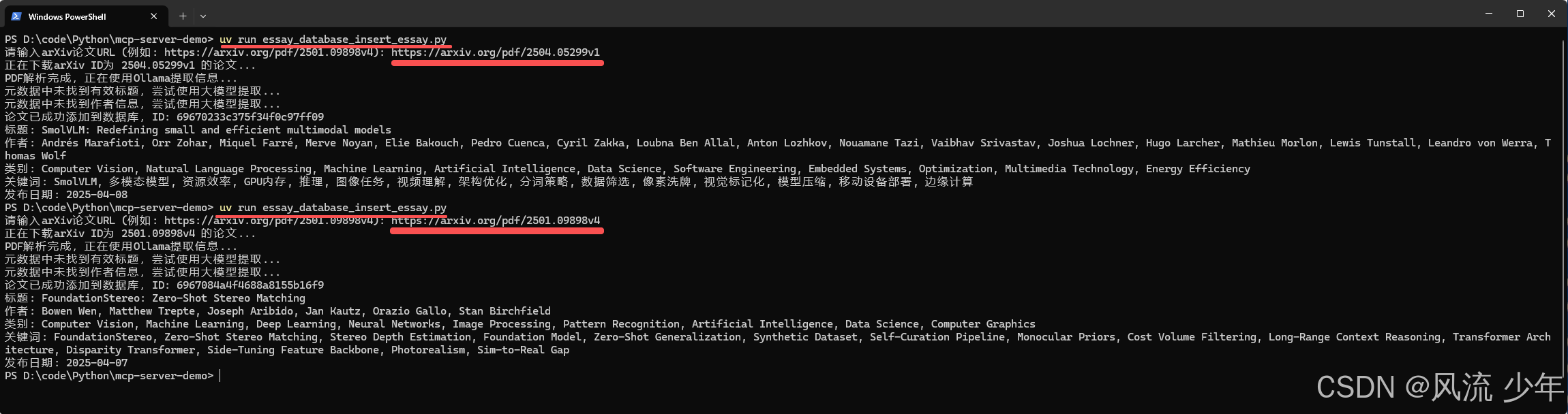
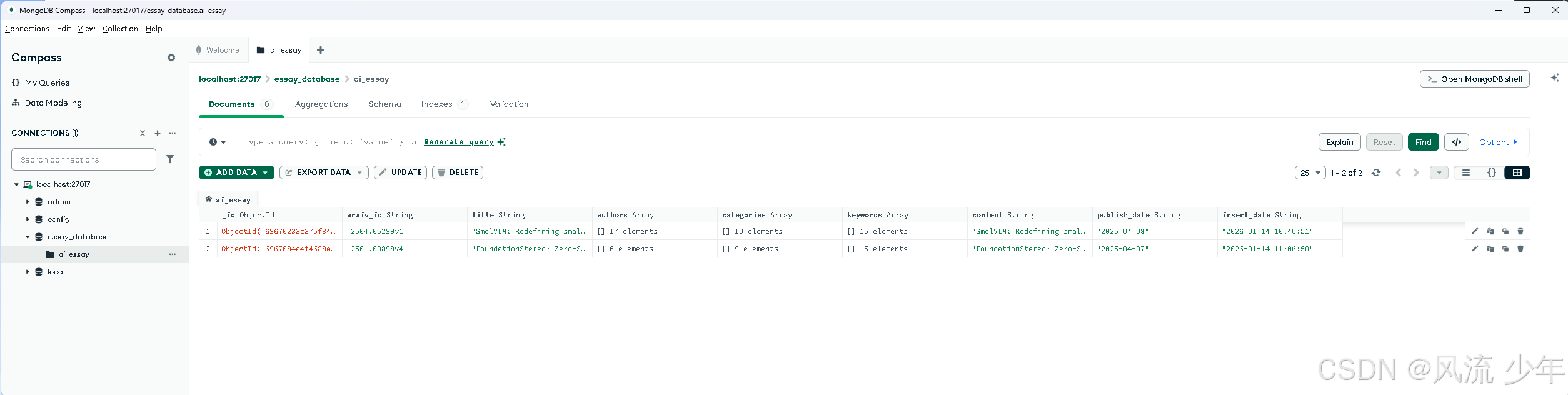
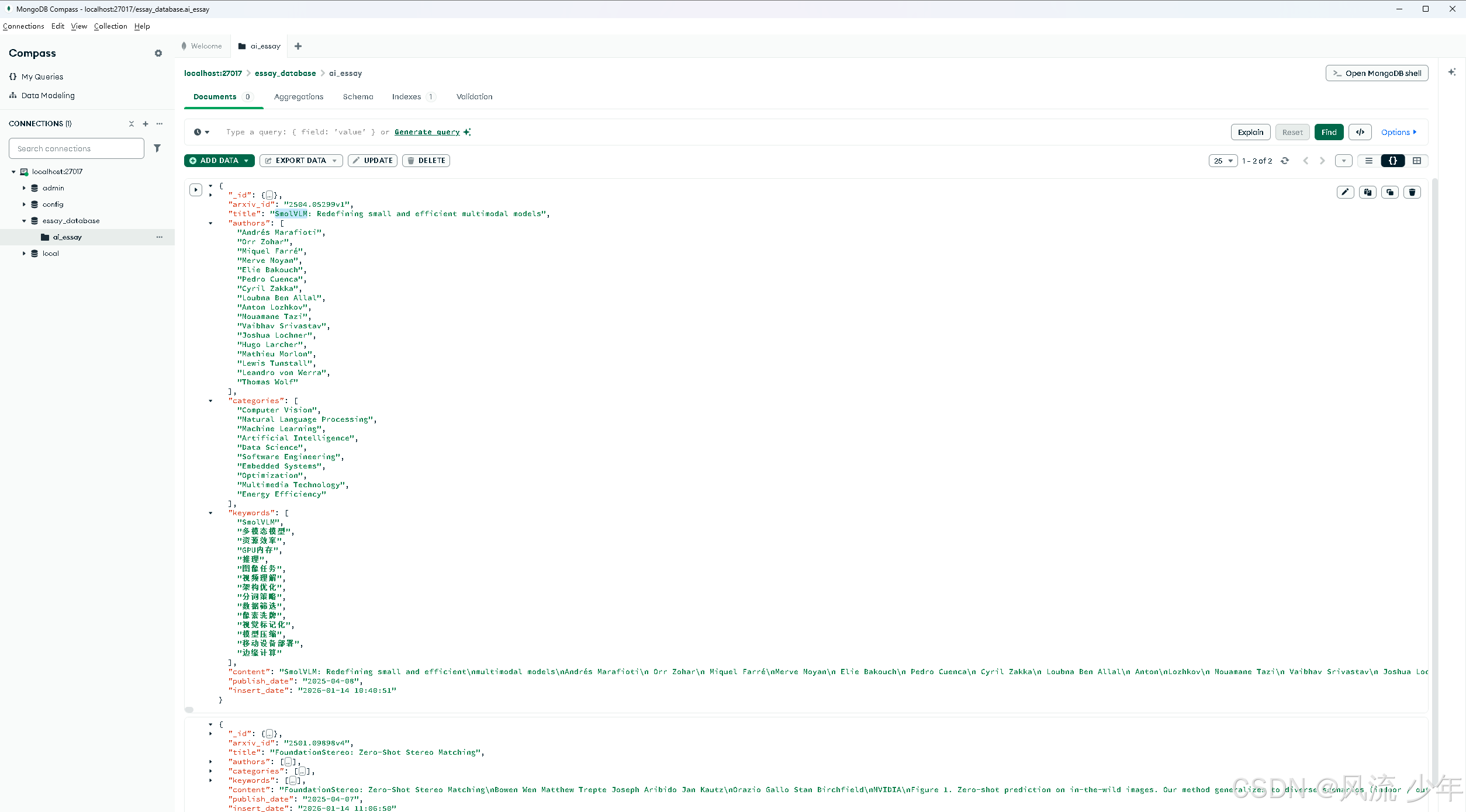
essay_database.ai_essay.json
[{
"_id": {
"$oid": "69670233c375f34f0c97ff09"
},
"arxiv_id": "2504.05299v1",
"title": "SmolVLM: Redefining small and efficient multimodal models",
"authors": [
"Andrés Marafioti",
"Orr Zohar",
"Miquel Farré",
"Merve Noyan",
"Elie Bakouch",
"Pedro Cuenca",
"Cyril Zakka",
"Loubna Ben Allal",
"Anton Lozhkov",
"Nouamane Tazi",
"Vaibhav Srivastav",
"Joshua Lochner",
"Hugo Larcher",
"Mathieu Morlon",
"Lewis Tunstall",
"Leandro von Werra",
"Thomas Wolf"
],
"categories": [
"Computer Vision",
"Natural Language Processing",
"Machine Learning",
"Artificial Intelligence",
"Data Science",
"Software Engineering",
"Embedded Systems",
"Optimization",
"Multimedia Technology",
"Energy Efficiency"
],
"keywords": [
"SmolVLM",
"多模态模型",
"资源效率",
"GPU内存",
"推理",
"图像任务",
"视频理解",
"架构优化",
"分词策略",
"数据筛选",
"像素洗牌",
"视觉标记化",
"模型压缩",
"移动设备部署",
"边缘计算"
],
"content": "SmolVLM: Redefining small and efficient\nmultimodal models\nAndrés Marafioti\n Orr Zohar\n Miquel Farré\nMerve Noyan\n Elie Bakouch\n Pedro Cuenca\n Cyril Zakka\n Loubna Ben Allal\n Anton\nLozhkov\n Nouamane Tazi\n Vaibhav Srivastav\n Joshua Lochner\n Hugo Larcher\n Mathieu\nMorlon\n Lewis Tunstall\n Leandro von Werra\n Thomas Wolf\nHugging Face,\n Stanford University\n Equal Contribution\nFigure 1 ∣Smol yet Mighty: comparison of SmolVLM with other state-of-the-art small VLM models. Image results\nare sourced from the OpenCompass OpenVLM leaderboard (Duan et al., 2024).\nAbstract\nLarge Vision-Language Models (VLMs) deliver exceptional performance but require significant com-\nputational resources, limiting their deployment on mobile and edge devices. Smaller VLMs typically\nmirror design choices of larger models, such as extensive image tokenization, leading to inefficient\nGPU memory usage and constrained practicality for on-device applications.\nWe introduce SmolVLM , a series of compact multimodal models specifically engineered for resource-\nefficient inference. We systematically explore architectural configurations, tokenization strategies, and\ndata curation optimized for low computational overhead. Through this, we identify key design choices\nthat yield substantial performance gains on image and video tasks with minimal memory footprints.\nOur smallest model, SmolVLM-256M, uses less than 1GB GPU memory during inference and out-\nperforms the 300-times larger Idefics-80B model, despite an 18-month development gap. Our largest\nmodel, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM\nmodels extend beyond static images, demonstrating robust video comprehension capabilities.\nOur results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization,\nand carefully curated training data significantly enhance multimodal performance, facilitating practical,\nenergy-efficient deployments at significantly smaller scales.\nCode gitub/huggingface\n Blog blog/smolvlm2\nWeights community/smol-research\n VLM Browser spaces/smolvlm-webgpu\nDemo spaces/smolvlm2\n HuggingSnap apple/huggingsnap\n1arXiv:2504.05299v1 [cs.AI] 7 Apr 2025Image\nSplittingVision\nEncoder\nPixel\nShuffleLinear\nLayer\nSmolLM2(1, 1)\n(1,2)\n(1, 3)\n(2, 1)\n(2,2)\n(2, 3)\nWhat\nis\nthis\n?TokenizerHugging\nFaceThe\nemoji\n!\nImage\nInput\nWhat is this?Figure 2 ∣SmolVLM Architecture . Images are split into subimages, frames are sampled from videos, and then\nencoded into visual features. These features are first rearranged via a pixel-shuffle operation, then mapped into the\nLLM input space as visual tokens using an MLP projection. Visual tokens are then concatenated/interleaved with text\nembeddings (orange/red). This combined sequence is passed to the LLM for text output.\n1 Introduction\nVision-Language Models (VLMs) have rapidly advanced in capability and adoption (Achiam et al., 2023; Bai\net al., 2023; Beyer et al., 2024; Chen et al., 2024c; McKinzie et al., 2024), driving breakthroughs in cross-modal\nreasoning (Liu et al., 2024a, 2023) and document understanding (Appalaraju et al., 2021; Faysse et al., 2024a;\nLivathinos et al., 2025; Nassar et al., 2025a). However, these improvements typically entail large parameter\ncounts and high computational demands.\nSince early large-scale VLMs like Flamingo (Alayrac et al., 2022a) and Idefics (Laurençon et al., 2023)\ndemonstrated capabilities with 80B parameters, new models have slowly appeared at smaller sizes. However,\nthesemodelsoftenretainhighmemorydemandsduetoarchitecturaldecisionsmadefortheirlargercounterparts.\nFor instance, Qwen2-VL (Wang et al., 2024a) and InternVL 2.5 (Chen et al., 2024b) offer smaller variants\n(1B-2B), but retain significant computational overhead. Conversely, models from Meta (Dubey et al., 2024)\nand Google (Gemma 3) reserve vision capabilities for large-scale models. Even PaliGemma (Beyer et al.,\n2024), initially efficiency-focused, scaled up significantly in its second release (Steiner et al., 2024). In\ncontrast, Moondream (Korrapati, 2024) keeps focusing on improving performance while maintaining efficiency,\nand H 2OVL-Mississippi (Galib et al., 2024) explicitly targets on-device deployment. Efficient processing is\nparticularly critical for video understanding tasks, exemplified by Apollo (Zohar et al., 2024b), where memory\nmanagement is essential. Furthermore, reasoning LLMs generate more tokens during inference, compounding\ncomputational costs (DeepSeek-AI, 2025; OpenAI et al., 2024). Therefore, efficiency per token becomes vital\nto ensure models remain practical for real-world use. Our contributions are:\n•Compact yet Powerful Models : We introduce SmolVLM, a family of powerful small-scale multimodal models,\ndemonstrating that careful architectural design can substantially reduce resource requirements without\nsacrificing capability.\n•EfficientGPUMemoryUsage : Oursmallestmodelrunsinferenceusinglessthan1GBGPURAM,significantly\nlowering the barrier to on-device deployment.\n•Systematic Architectural Exploration : We comprehensively investigate the impact of architectural choices,\nincluding encoder-LM parameter balance, tokenization methods, positional encoding, and training data\ncomposition, identifying critical factors that maximize performance in compact VLMs.\n•Robust Video Understanding on Edge Devices : We demonstrate that SmolVLM models generalize effectively\nto video tasks, achieving competitive scores on challenging benchmarks like Video-MME, highlighting their\nsuitability for diverse multimodal scenarios and real-time, on-device applications.\n•Fully Open-source Resources : To promote reproducibility and facilitate further research, we release all\nmodel weights, datasets, code, and a mobile application showcasing inference on a smartphone.\n20 500 1000 1500 2000\nTotal Parameters (M)0.300.350.400.450.500.55Mean CIDEr and VQA accuracy\nEncoder Params\n93M\n428M\n2 8 16\nContext Length (k)0.300.350.400.450.500.55\n256M 500M\nModel Size0.300.350.400.450.500.55\nPixel Shuffle\n2\n4\n1 2 4 8\nFrame Averaging Factor0.450.460.470.480.490.500.51\nFigure 3 ∣Performance analysis of SmolVLM configurations. (Left)Impact of vision encoder and language model\nsizes. Smaller language models ( 135M) benefit less from larger vision encoders (SigLIP-SO- 400M,428M) compared\nto SigLIP-B/ 16(93M), while larger language models gain more from powerful encoders. (Middle-left) Performance\nsignificantly improves with increased context lengths ( 2k to 16k tokens). (Middle-right) Optimal pixel shuffle factor\n(PS=2 vs. PS=4) varies by model size. (Right)Frame averaging reduces video performance, with a rapid decline as\nmore frames are averaged. Metrics average CIDEr (captioning) and accuracy (visual question answering).\n2 Smoller Model Architecture\nWe systematically explore design choices for small multimodal models based on the architecture in Figure 2,\nwhere encoded images are pooled and projected into a SmolLM2 backbone. We first analyze optimal compute\nallocation, showing smaller vision encoders complement compact LMs (§2.1). Extending context length\nenables higher image resolutions at minimal overhead (§2.2), and pixel shuffling reduces visual tokens further.\nFinally, we efficiently handle high-resolution images and videos via document-specific image splitting and\ntargeted token compression (§2.3). Together, these approaches yield a unified, performant, and cost-effective\nrecipe for tiny LMMs.\n2.1 How to assign compute between vision and language towers?\nVLMs utilize vision encoders (see Figure 2) to generate ‘vision tokens’ that are then fed into an LM. We\ninvestigate optimal capacity allocation between vision encoders and language models (LMs) in compact VLMs.\nSpecifically, we pair three SmolLM2 variants ( 135M,360M, and 1.7B parameters) with two SigLIP encoders:\na compact 93M SigLIP-B/ 16and a larger 428M SigLIP-SO 400M. Typically, larger VLMs disproportionately\nallocate parameters to the LM; however, as the LM is scaled down, this is no longer the case.\nFigure 3 (left) confirms that performance declines significantly when using a large encoder with the smallest\nLM ( 135M), highlighting an inefficient encoder-LM balance. At an intermediate LM scale ( 360M), the larger\nencoder improves performance by 11.6%, yet this comes with a substantial 66% increase in parameters, making\nthe compact encoder preferable. Only at the largest LM scale ( 1.7B), the larger encoder represents just a 10%\nparameter increase.\nFinding 1. Compact multimodal models benefit from a balanced encoder-LM parameter allocation,\nmaking smaller vision encoders preferable for efficiency.\n2.2 How can we efficiently pass the images to the Language Model?\nFollowing Laurençon et al. (2024), we adopt a self-attention architecture in which visual tokens from the vision\nencoder are concatenated with textual tokens and jointly processed by a language model (e.g., FROMAGe (Koh\net al., 2023), BLIP- 2(Li et al., 2023a)). This design requires significantly more context than the 2k-token\nlimit used in SmolLM 2, as a single 512×512image encoded with SigLIP-B/ 16requires 1024tokens. To\naddress this, we extended the context capacity by increasing the RoPE base from 10k to 273k, following Liu\net al. (2024c), and fine-tuned the model on a mix of long-context data (Dolma books (Soldaini et al., 2024),\nThe Stack (Kocetkov et al., 2022)) and short-context sources (FineWeb-Edu (Penedo et al., 2024), DCLM (Li\net al., 2024a), and math from SmolLM2).\n3Figure 4 ∣Pixel shuffle. Rearranges encoded images, trading spatial resolution for increased channel depth. This\nreduces visual token count while preserving information density.\nWhile fine-tuning was stable at 16k tokens for the 1.7B LM, smaller models (135M, 360M) struggled beyond\n8k. Experiments with our 2.2B SmolVLM confirmed consistent performance gains up to 16k tokens (Figure 3,\nmiddle). Accordingly, we adopt a 16k-token context for SmolVLM and an 8k-token limit for smaller variants.\nFinding 2. Compact VLMs significantly benefit from extended context lengths.\nExtending the context window alone is not sufficient. Recent VLMs (e.g., MM1 (McKinzie et al., 2024),\nMiniCPM-V (Yao et al., 2024), InternVL (Chen et al., 2024c)) combine the self-attention architecture with\ntoken compression techniques (Zohar et al., 2024b; Laurençon et al., 2024) to fit longer sequences efficiently\nand reduce computational overhead.\nOne particularly effective compression method is pixel shuffle (space-to-depth), initially proposed for super-\nresolution tasks (Shi et al., 2016) and recently adopted by Idefics3. Pixel shuffle rearranges spatial features\ninto additional channels, reducing spatial resolution but increasing representational density (Figure 4). This\nreduces the total number of visual tokens by a factor of r2, where ris the shuffle ratio. However, higher ratios\ncollapse larger spatial regions into single tokens, impairing tasks requiring precise localization, such as OCR.\nModels like InternVL and Idefics 3user=2to balance compression and spatial fidelity. In contrast, our\nexperiments (Figure 3, right) show that smaller VLMs benefit from more aggressive compression ( r=4) as\nthe reduced token count eases attention overhead and improves long-context modeling.\nFinding 3. Small VLMs benefit from more aggressive visual token compression.\n2.3 How can we efficiently encode images and videos?\nBalancing token allocation between images and videos is crucial for efficient multimodal modeling: images\nbenefit from higher resolution and more tokens to retain fidelity, whereas videos typically require fewer tokens\nper frame to handle longer sequences efficiently.\nTo achieve this, we successfully adopted an image-splitting strategy inspired by UReader (Ye et al., 2023)\nand SPHINX (Lin et al., 2023b), where high-resolution images are divided into multiple sub-images along\nwith a downsized version of the original. This approach proved effective in maintaining image quality without\nexcessive computational overhead. For videos, however, we found that strategies such as frame averaging,\ninspired by Liu et al. (2024f), negatively impacted performance. As shown in Figure 3 (right), combining\nmultiple frames significantly degraded OpenCompass-Video results, particularly at higher averaging factors\n(2,4,8). Consequently, frame averaging was excluded from SmolVLM’s final design, and video frames were\ninstead rescaled to the resolution of the image encoder.\nFinding 4. For small models, image splitting enhances performance for vision tasks, whereas video\nframe averaging does not.\n4Figure 5 ∣Tokenization Strategy Comparisons. (Left)Training loss curves illustrating the “OCR loss plague” when\nusing string-based tokens in smaller models. (Center) Aggregated evaluation metrics showing consistently higher scores\nwith learned tokens (orange). (Right)Scatter plot of OpenCompass-Image vs. OpenCompass-Video: learned tokens\ndominate the higher-scoring region, especially in image-intensive tasks.\n3 Smol Instruction Tuning\nSmol instruction tuning requires careful vision (§3.1) and text tokenization (§3.2), alongside unified methods\nfor multimodal modeling under tight compute constraints. Learned positional tokens and structured prompts\nstabilize training and improve OCR, but data composition remains crucial: reusing LLM instruction datasets\nnegatively impacts small VLMs (§3.3), excessive Chain-of-Thought data overwhelms limited capacity (§3.4),\nand moderate video sequence lengths balance efficiency and performance (§3.5). Collectively, these insights\nhighlight targeted strategies essential for effectively scaling multimodal instruction tuning to SmolVLMs.\n3.1 Learned Tokens vs. String\nA primary design consideration in SmolVLM involves encoding split sub-image positions effectively. Initially,\nwe attempted to use simple string tokens (e.g., <row_1_col_2> ), which caused early training plateaus—termed\nthe “OCR loss plague”—characterized by sudden loss drops without corresponding improvements in OCR\nperformance (Figure 5, left and middle).\nTo address instability during training, we introduced positional tokens, significantly improving training\nconvergence and reducing stalls. Although larger models were relatively robust to using raw string positions,\nsmaller models benefited substantially from positional tokens, achieving notably higher OCR accuracy and\nimproved generalization across tasks. Figure 5 (center) shows that learned positional tokens consistently\noutperform naive string positions on multiple image and text benchmarks. Additionally, Figure 5 (right)\nillustrates that models leveraging learned tokens consistently score higher in both OpenCompass-Image\nand OpenCompass-Video evaluations, underscoring the effectiveness of structured positional tokenization in\ncompact multimodal models.\nFinding 5. Learned positional tokens outperform raw text tokens for compact VLMs.\n3.2 Structured Text Prompts and Media Segmentation\nWe evaluated how system prompts and explicit media intro/outro prefixes incrementally improve SmolVLM’s\nperformance on image (left) and video (right) benchmarks, as shown in Figure 6. Each violin plot represents\nthree checkpoints for a given configuration.\nSystem Prompts. We prepend concise instructions to clarify task objectives and reduce ambiguity during\nzero-shot inference. For example, conversational datasets utilize prompts like “You are a useful conversational\nassistant,” whereas vision-focused tasks employ “You are a visual agent and should provide concise answers.”\nThe second violin plot in each subplot (Fig. 6) illustrates clear performance improvements from incorporating\nthese system prompts, particularly evident in image-centric tasks.\nMedia Intro/Outro Tokens. To clearly demarcate visual content, we introduce textual markers around image\n5Image0.300.350.400.450.500.55OpenCompass Average Score\nVideo0.400.450.500.55\nNo System Prompt With System Prompt With Intro/Outro With User Prompt MaskedFigure 6 ∣Cumulative Effect of Training Strategies on SmolVLM Performance. The visualization shows the\nprogression of performance improvements as different tokenization and prompt engineering strategies are applied\nsequentially to the SmolVLM base model. (Left)Image benchmark results show consistent improvements with each\nadded strategy. (Right)Video benchmark results reveal similar patterns with more pronounced gains.\nand video segments (e.g., “ Here is an image... ” and “Here are Nframes sampled from a video... ”). The outro\ntokens then transition back to textual instructions (e.g., “ Given this image/video... ”). The third violin indicates\nthat this strategy substantially boosts performance on video tasks—where confusion between multiple frames\nis more likely—and still yields measurable improvements on image tasks.\nMasking User Prompts Drawing on techniques from Allal et al. (2025), we explore user-prompt masking\nduring supervised fine-tuning as a way to reduce overfitting. The right violin plot in Figure 6 shows that\nmasking user queries (orange) yields improved performance in both image and video tasks, compared to the\nunmasked baseline (blue). This effect is significantly pronounced in multimodal QA, where questions are often\nrepetitive and can be trivially memorized by the model. Masking thus forces SmolVLM to rely on task-related\ncontent rather than superficial repetition, promoting better generalization.\nFinding 6. System prompts and media intro/outro tokens significantly improve compact VLM perfor-\nmance, particularly for video tasks. During SFT, only train on completions.\n3.3 Impact of Text Data Reuse from LLM-SFT\nA seemingly intuitive practice is to reuse text data from the final supervised fine-tuning stages of large language\nmodels, anticipating in-distribution prompts and higher-quality linguistic inputs. However, Figure 7 (left)\nshows that incorporating LLM-SFT text data ( SmolTalk ) can degrade performance in smaller multimodal\narchitectures by as much as 3.7% in video tasks and 6.5% in image tasks. We attribute this negative transfer to\nreduced data diversity, which outweighs any benefits of reusing text. In keeping with Zohar et al. (2024b), we\ntherefore maintain a strict 14% text proportion in our training mix. These findings highlight the importance\nof a carefully balanced data pipeline, rather than direct adoption of large-scale SFT text for small-scale\nmultimodal models.\nFinding 7. Adding text from SFT blend proved worse than new text SFT data.\n3.4 Optimizing Chain-of-Thought Integration for Compact Models\nChain-of-Thought (CoT) prompting, which exposes models to explicit reasoning steps during training, generally\nenhances reasoning capabilities in large models. However, its effect on smaller multimodal architectures\nremains unclear. To investigate this, we varied the proportion of CoT data integrated into the Mammoth\ndataset (Yue et al., 2024b), covering text, image, and video tasks. Figure 7 (middle) shows that incorporating\na minimal fraction (0.02–0.05%) of CoT examples slightly improved performance, but higher proportions\n6Video Image0.350.400.450.500.55OpenCompass Average-3.7%\n-6.5%Without SmolTalk\nWith SmolTalk\n0.0 0.2 0.4 0.6\nCoT Data0.450.50\nVideo\nImage\n1.5 min 2.5 min 3.5 min\nAverage Video Duration0.350.400.450.500.55\nVideo\nImageFigure7 ∣ImpactofTrainingStrategiesonSmol-ScaleMultimodalModels. (Left)Reusing text data from LLM-SFT\n(SmolTalk ) reduces both image and video scores in smaller models. (Middle) A minimal fraction ( 0.02%–0.05%) of\nChain-of-Thought (CoT) data yields optimal results, while heavier CoT usage degrades performance. (Right)Increasing\naverage video duration beyond 3.5min leads to diminished returns for both image and video tasks.\nmarkedly degraded results, especially in image tasks. These observations suggest that excessive reasoning-\noriented textual data can overwhelm the limited capacity of smaller VLMs, thereby compromising their visual\nrepresentation capabilities. Consequently, compact models benefit most from very sparse inclusion of CoT\ndata rather than the extensive use typically beneficial in larger-scale architectures.\nFinding 8. Excessive CoT data harms compact model performance.\n3.5 Impact of Video Sequence Length on Model Performance\nIncreasing video duration during training offers richer temporal context but comes at a greater computational\ncost. To identify an optimal duration, we trained SmolVLM on average video lengths ranging from 1.5 to 3.5\nminutes. Figure 7 (right) demonstrates clear performance improvements for both video and image benchmarks\nas video durations approached approximately 3.5 minutes, likely due to more effective cross-modal feature\nlearning. Extending video duration beyond 3.5 minutes yielded minimal further gains, indicating diminishing\nreturns relative to the added computational expense. Thus, moderately extending video sequences enhances\nperformance significantly in smaller models, whereas overly long sequences do not proportionally justify their\ncomputational cost.\nFinding 9. Moderately increasing video duration during training improves both video and image task\nperformance in compact VLMs.\n4 Experimental Results\nWe construct three variants of SmolVLM, tailored to different computational environments:\n•SmolVLM- 256M: Our smallest model, combining the 93M SigLIP-B/ 16and the SmolLM 2-135M (Allal et al.,\n2025). Operating on <1GB GRAM makes it ideal for resource-constrained edge applications.\n•SmolVLM- 500M: A mid-range model with the same 93M SigLIP-B/ 16paired with the larger SmolLM 2-360M.\nBalancing memory efficiency and performance, it is suitable for moderate-resource edge devices.\n•SmolVLM- 2.2B: The largest variant, with a 400M SigLIP-SO 400M and a 1.7B-parameter SmolLM 2backbone.\nThis model maximizes performance while remaining deployable on higher-end edge systems.\n7Vision Training DataImage86%\nText\n14%\nOCR& Documents\n48%\nCaptioning\n14%\nChartUnderstanding\n12%\nReasoning\n& Logic\n9%\n Table\nUnderstanding\n9%\nVisual\nQ&A\n8%\nReasoning\n& Logic\n79%\nGeneneral \nKnowledge \n21%\nVideo Fine-Tuning DataImage\n35%\nVideo\n33%\nText\n20%Multi-Image\n12%\nCaptioning\n37%\nReasoning\n& Logic\n26%\nDocument\nUnderstanding\n23%\nVisual\nQ&A\n14%\nVisual\nDescription& Captioning76%\nTemporal\nUnderst.\n18%\n Narrative6%\nInformation\nSeeking\n60%\nGeneralKnowledge\n25%\nReasoning \n& Logic\n15%\nVisual\nQ&A\n100%Figure 8 ∣Data Details. Training dataset details for Vision (Left)and video (Right), broken down by modality and\nsub-categories.\n4.1 Training Data\nModel training proceeds in two stages: (1) a vision stage, and (2) a video stage. The vision training\nstage uses a new mixture of the datasets used in Laurençon et al. (2024), to which we added MathWriting\n(Gervais et al., 2024). The mixture was balanced to emphasize visual and structured data interpretation\nwhile maintaining the focus on reasoning and problem-solving capabilities. The visual components comprise\ndocument understanding, captioning, and visual question answering (including 2% dedicated to multi-image\nreasoning), chart understanding, table understanding, and visual reasoning tasks. To preserve the model’s\nperformance in text-based tasks, we retained a modest amount of general knowledge Q&A and text-based\nreasoning & logic problems, which incorporate mathematics and coding challenges.\nThe video fine-tuning stage maintains 14% of text data and 33% of video to achieve optimal performance,\nfollowing the learnings of Zohar et al. (2024b). For video, we sample visual description and captioning\nfrom LLaVA-video- 178k (Zhang et al., 2024), Video-STAR (Zohar et al., 2024a), Vript (Yang et al., 2024),\nand ShareGPT4Video (Chen et al., 2023), temporal understanding from Vista- 400k (Ren et al., 2024), and\nnarrative comprehension from MovieChat (Song et al., 2024) and FineVideo (Farré et al., 2024). Multi-image\ndata was sampled from M 4-Instruct (Liu et al., 2024a) and Mammoth (Guo et al., 2024). The text samples\nwere sourced from (Xu et al., 2024).\nFor a more granular description, Figure 8 provides a detailed overview of the training data distribution used\nin both our vision and video fine-tuning stages.\n4.2 Evaluation details\nWe evaluated SmolVLM using VLMEvalKit (Duan et al., 2024) to ensure reproducibility. The full results\nare available online1. Currently, the OpenVLM Leaderboard covers 239different VLMs and 31different\nmulti-modal benchmarks. Further, we plot the performance against the RAM required to run the evaluations.\nWe argue that model size is usually used as a proxy for the computational cost required to run a model. This\nis misleading for VLMs because the architecture strongly influences how expensive it is to run the model; in\nour opinion, RAM usage is a better proxy. For SmolVLM, this resizes the longest edge of images to 1920in\nthe256M and 500M models and 1536in the 2.2B.\n4.3 Strong Performance at a Tiny Scale\nWe evaluate SmolVLM’s performance relative to model size, comparing three variants ( 256M,500M, and\n2.2B) against efficient state-of-the-art open-source models. Table 1 summarizes results across nine demanding\nvision-language benchmarks and five video benchmarks. We highlight in the table MolmoE 7B with 1B\n1OpenVLM Leaderboard\n8Capability Benchmark SmolVLM 256M SmolVLM 500M SmolVLM 2.2B Efficient OS\nSingle-ImageOCRBench (Liu et al., 2024e)\nCharacter Recognition52.6% 61.0% 72.9% 54.7%\nMolmoE-A1B-7B\nAI2D (Kembhavi et al., 2016)\nScience Diagrams46.4% 59.2% 70.0% 71.0%\nMolmoE-A1B-7B\nChartQA (Masry et al., 2022)\nChart Understanding55.6% 62.8% 68.7% 48.0%\nMolmoE-A1B-7B\nTextVQA (Singh et al., 2019)\nText Understanding50.2% 60.2% 73.0% 61.5%\nMolmoE-A1B-7B\nDocVQA (Mathew et al., 2021)\nDocument Understanding58.3% 70.5% 80.0% 77.7%\nMolmoE-A1B-7B\nScienceQA (Lu et al., 2022)\nHigh-school Science73.8% 80.0% 89.6% 87.5%\nMolmoE-A1B-7B\nMulti-taskMMMU (Yue et al., 2024a)\nCollege-level Multidiscipline29.0% 33.7% 42.0% 33.9%\nMolmoE-A1B-7B\nMathVista (Lu et al., 2024b)\nGeneral Math Understanding35.9% 40.1% 51.5% 37.6%\nMolmoE-A1B-7B\nMMStar (Chen et al., 2024a)\nMultidisciplinary Reasoning34.6% 38.3% 46.0% 43.1%\nMolmoE-A1B-7B\nVideoVideo-MME (Fu et al., 2024)\nGeneral Video Understanding33.7% 42.2% 52.1% 45.0%\nInternVL2-2B\nMLVU (Zhou et al., 2024)\nMovieQA + MSRVTT-Cap40.6% 47.3% 55.2% 48.2%\nInternVL2-2B\nMVBench (Li et al., 2024b)\nMultiview Reasoning32.7% 39.7% 46.3% 60.2%\nInternVL2-2B\nWorldSense (Hong et al., 2025)\nTemporal + Physics29.7% 30.6% 36.2% 32.4%\nQwen2VL-7B\nTempCompass (Liu et al., 2024d)\nTemporal Understanding43.1% 49.0% 53.7% 53.4%\nInternVL2-2B\nAverage Across Benchmarks 44.0% 51.0% 59.8% –\nRAM UsageBatch size = 1 0.8 GB 1.2 GB 4.9 GB 27.7 GB\nMolmoE-A1B-7B\nbatch size = 64 15.0 GB 16.0 GB 49.9 GB –\nTable 1 ∣Benchmark comparison of SmolVLM variants across vision-language tasks. Performance of SmolVLM\nmodels at three scales (256M, 500M, and 2.2B parameters) compared to efficient open-source models on single-image,\nmulti-task, and video benchmarks. SmolVLM models demonstrate strong accuracy while maintaining significantly\nlower RAM usage, highlighting their computational efficiency for resource-constrained multimodal scenarios.\nactivated parameters (Deitke et al., 2024)(MolmoE-A 1B-7B) for vision tasks and InternVL 2-2B Chen et al.\n(2024c) for video tasks. A broader array of competing models are shown in Fig. 1.\nEfficiency and Memory Footprint. SmolVLM demonstrates remarkable computational efficiency compared to\nsignificantly larger models. Single-image inference requires only 0.8GB of VRAM for the 256M variant, 1.2GB\nfor the 500M, and 4.9GB for the 2.2B—dramatically lower than the 27.7GB required by MolmoE-A 1B-7B. Even\ncompared to models of similar parameter scales, SmolVLM is notably more efficient: Qwen 2VL-2B requires\n13.7GB VRAM and InternVL2- 2B requires 10.5GB VRAM, highlighting that parameter count alone does\nnot dictate compute requirements. At batch size 64, memory usage for SmolVLM remains practical: 15.0GB\n(256M),16.0GB ( 500M), and 49.9GB ( 2.2B). These results highlight SmolVLM’s substantial advantages for\ndeployment in GPU-constrained environments.\nOverall Gains from Scaling. Increasing SmolVLM’s parameter count consistently yields substantial per-\nformance improvements across all evaluated benchmarks. The largest model ( 2.2B) achieves the highest\noverall score at 59.8%, followed by the intermediate 500M variant ( 51.0%) and the smallest 256M variant\n(44.0%). Notably, even the smallest SmolVLM- 256M significantly surpasses the much larger Idefics 80B model\n(see Fig. 1) on nearly all benchmarks, emphasizing effective vision capabilities at modest scales. The few\nexceptions—particularly MMMU ( 29.0%vs.42.3%) and AI2D ( 46.4%vs.56.3%)—highlight benchmarks\nwhere strong linguistic reasoning from a large language backbone remains crucial. Intriguingly, visually\noriented tasks such as OCRBench also benefit markedly from scaling language model capacity, with a nearly\n10-point improvement when moving from 256M (52.6%) to 500M (61.0%). These results underscore that\n9Figure 9 ∣SmolVLM on edge device. (Left)Examples of the HuggingSnap app, where SmolVLM can run locally, on\nthe device, on consumer phones. For example, interactions can be done using a mobile interface to detect objects and\nanswer questions. (Right)Throughput in tokens per second on NVIDIA A 100GPUs(top)and different consumer\npersonal computers (bottom) across different batch sizes and model variants.\nlarger language models provide enhanced context management and improved multimodal reasoning, benefiting\nboth language-intensive and vision-centric tasks.\nComparison with Other Compact VLMs. Figure 1 situates SmolVLM- 2.2B among recent small-scale VLMs by\ncomparing OpenCompass benchmark performance against GPU memory consumption per image. SmolVLM-\n2.2B achieves notably strong performance on MathVista ( 51.5) and ScienceQA ( 90.0), while maintaining\nexceptionally low GPU usage of just 4.9GB VRAM. In contrast, models requiring significantly more compute,\nsuch as Qwen 2VL-2B and InternVL 2-2B, aren’t clearly better performers. Specifically, Qwen 2VL-2B slightly\nsurpasses SmolVLM- 2.2B on AI 2D (74.7vs.70.0) and ChartQA ( 73.5vs.68.8), yet falls short on MathVista\n(48.0vs.51.5) and ScienceQA ( 78.7vs.90.0). Similarly, InternVL2- 2B achieves higher scores on ScienceQA\n(94.1vs.90.0) and MMStar ( 49.8vs.46.0), but at more than double the VRAM cost.\nFurther comparisons highlight distinct trade-offs among size, memory footprint, and task-specific performance.\nMiniCPM-V2 ( 2.8B parameters) underperforms SmolVLM- 2.2B on most benchmarks. Other models such as\nMoondream2 and PaliGemma (both around 2˘3B parameters) exhibit significant variance across tasks: Moon-\ndream2, for instance, scores well on ChartQA ( 72.2) with just 3.9GB VRAM but substantially underperforms\non MMMU ( 29.3). Conversely, PaliGemma excels at ScienceQA ( 94.3) yet struggles on ChartQA ( 33.7). This\nvariability underscores how specialized training impacts per-task.\nVideoBenchmarks. Table 1 provides comprehensive results across five diverse video benchmarks: Video-MME,\nMLVU, MVBench, TempCompass, and WorldSense. SmolVLM- 2.2B notably excels at Video-MME ( 52.1) and\nWorldSense ( 36.2), outperforming significantly larger models such as Qwen 2VL-7B ( 32.4on WorldSense),\nshowcasing strong capabilities in complex multimodal video comprehension tasks. The SmolVLM- 500M variant\nalso demonstrates robust performance, achieving competitive scores on TempCompass ( 49.0) and WorldSense\n(30.6), highlighting sophisticated temporal reasoning and real-world visual understanding at a scale ideal for\nedge-device deployment. Despite their compact parameter counts, SmolVLM variants consistently balance\nefficient resource use with impressive accuracy, reinforcing their suitability for resource-constrained scenarios.\n104.4 On-Device Performance\nTo comprehensively assess the deployment practicality of SmolVLM, we benchmarked its throughput across\nvarying batch sizes on two representative hardware platforms: NVIDIA A 100and NVIDIA L 4GPUs (see\nFigure 9). Our evaluations highlight SmolVLM’s suitability for on-device and edge deployment scenarios.\nOn the A 100GPU, the smallest SmolVLM-256M variant achieves impressive throughput, scaling from 0.8\nexamples per second at batch size 1to16.3examples per second at batch size 64. The 500M variant similarly\nscales from 0.7to9.9examples per second, while the largest 2.2B variant demonstrates more modest scaling\n(0.6to1.7examples per second), indicative of its higher computational demands.\nEvaluations on the L 4GPU further emphasize SmolVLM’s edge compatibility. Here, the 256M variant reaches\npeak throughput at 2.7examples per second with batch size 8, subsequently diminishing due to memory\nconstraints. The 500M and 2.2B variants peak at lower batch sizes ( 1.4and 0.25examples per second,\nrespectively), underscoring their efficiency even under more restrictive hardware conditions.\nFinally, we accompany the release with several optimized ONNX (Open Neural Network Exchange) exports,\nfacilitating cross-platform compatibility and broadening deployment opportunities across consumer-grade\nhardware targets. Notably, we demonstrate the ability to efficiently run these models locally within a browser\nenvironment via WebGPU, with the 256M variant achieving up to 80decode tokens per second on a 14-inch\nMacBook Pro (M 4Max).\n4.5 Downstream Applications\nBeyond our own evaluations, SmolVLM has seen adoption in various downstream applications developed by\nthe broader research community, emphasizing its efficiency in real-world, resource-constrained scenarios.\nColSmolVLM: On-Device Multimodal Inference. ColSmolVLM utilizes the smaller SmolVLM variants ( 256M\nand500M parameters) designed explicitly for on-device deployment, as detailed in recent work by Hugging\nFace (Faysse et al., 2024b). These compact models enable efficient multimodal inference directly on mobile\ndevices, consumer laptops, and even within browser-based environments, significantly lowering computational\ndemands and operational costs.\nSmol Docling: Ultra-Compact Document Processing. Smol Docling is an ultra-compact 256M-parameter\nvariant of SmolVLM, optimized explicitly for end-to-end multimodal document conversion tasks (Nassar\net al., 2025b). By employing specialized representations known as DocTags, Smol Docling efficiently captures\ncontent, context, and spatial relationships across diverse document types, including business documents,\nacademic papers, and patents. Its compact architecture maintains competitive performance with considerably\nlarger VLMs, highlighting its suitability for deployment in scenarios with computational constraints.\nBioVQA: Biomedical Visual Question Answering. BioVQA leverages SmolVLM’s compact and efficient\narchitecture to address visual question answering tasks within the biomedical domain (Lozano et al., 2025).\nSmall-scale SmolVLM models have demonstrated promising capabilities in interpreting medical images,\nassisting healthcare professionals by providing accurate answers to clinical questions based on visual data.\nThis capability is particularly valuable in healthcare settings where quick, reliable image interpretation is\ncritical, yet computational resources may be limited.\n5 Related Work\n5.1 First-Generation Vision-Language Models\nEarly multimodal models achieved significant progress primarily by scaling parameters, but their high\ncomputational demands limited practical deployment. For instance, Flamingo (Alayrac et al., 2022b), an\n80B-parameter Vision-Language Model (VLM), integrated a frozen 70B-parameter LM (Hoffmann et al., 2022)\nwith a vision encoder employing gated cross-attention and a Perceiver Resampler (Jaegle et al., 2021) for\n11efficient token compression. Despite state-of-the-art few-shot capabilities without task-specific fine-tuning,\nFlamingo’s large scale posed significant deployment challenges.\nHugging Face’s Idefics (Laurençon et al., 2023) adopted Flamingo’s architecture, offering models at both\n9B and 80B parameters, further exemplifying the approach of large-scale multimodal training. In contrast,\nBLIP-2 (Li et al., 2023a) proposed a more parameter-efficient, modular design by freezing both the vision\nencoder and language model, introducing instead a lightweight Query Transformer (Q-Former) that translates\nvisual features into language-compatible tokens. This approach significantly reduced trainable parameters,\nsurpassing Flamingo’s performance on VQA tasks (Antol et al., 2015; Goyal et al., 2017) with roughly 54\ntimes fewer trainable parameters, thus paving the way toward more efficient multimodal architectures.\nSimilarly, LLaVA (Large Language-and-Vision Assistant) (Liu et al., 2023) connected a pretrained CLIP (Rad-\nford et al., 2021) ViT image encoder to a LLaMA/Vicuna language backbone (Touvron et al., 2023; Zheng\net al., 2024), fine-tuning the combined model on instruction-following datasets. Resulting in a 13B-parameter\nmultimodal chatbot with GPT-4V-like capabilities (Achiam et al., 2023), LLaVA achieved notable visual\nconversational performance. However, despite being smaller and faster than Flamingo, it still demands\nsubstantial GPU memory for real-time interaction and inherits the limitations of the underlying language\nmodel’s context window (typically 2048 tokens).\nRecent research has actively explored various design choices, training strategies, and data configurations\nto enhance Vision-Language Models (VLMs). For instance, Idefics2 (Laurençon et al., 2024) introduced\narchitectural and training-data improvements compared to its predecessor, advancing open-source VLM\ncapabilities. Concurrently, Cambrian1 (Tong et al., 2024) examined fundamental design principles and scaling\nbehaviors, aiming for more efficient architectures. Projects like Eagle (Shi et al., 2024) and its successor\nEagle2 (Li et al., 2025b) have optimized specific architectural components, targeting improved performance\nand efficiency. Additionally, recent efforts such as Apollo (Zohar et al., 2024b) extend multimodal architectures\nfrom static images to video understanding, further enriching the diversity of approaches.\n5.2 Efficiency-Focused Vision-Language Models\nLargermodels, suchasInternVL(Chenetal.,2024c,b)andQwen-VL(Baietal.,2023,2025;Wangetal.,2024a),\nintroduced architectural innovations for improved computational efficiency. InternVL aligns a 6B-parameter\nvision transformer (ViT) with an 8B-parameter language \"middleware,\" forming a 14B-parameter model\nthat achieves state-of-the-art results across multiple vision and multimodal tasks. This balanced architecture\nnarrows the modality gap, enabling robust multimodal perception and generation capabilities. Similarly,\nQwen-VL integrates a Qwen language model with specialized visual modules, leveraging captioned bounding-\nbox data to enhance visual grounding and text recognition capabilities. Despite its strong multilingual and\nmultimodal performance, Qwen-VL generates exceptionally long token sequences for high-resolution inputs,\nincreasing memory requirements.\nOn the smaller end, models like PaliGemma, Moondream2, and MiniCPM-V demonstrate impressive mul-\ntimodal capabilities within constrained parameter budgets. PaliGemma (Team et al., 2024), with just 3B\nparameters (400M vision encoder from SigLIP-So (Zhai et al., 2023) and 2B Gemma language model),\neffectively covers a wide range of multimodal tasks. However, its condensed visual interface can limit detailed\nvisual analysis. Moondream2, at merely 1.8B parameters, pairs SigLIP visual features with Microsoft’s\nPhi-1.5 language model (Li et al., 2023b), showcasing competitive performance on tasks such as image\ndescription, OCR, counting, and classification, ideal for edge and mobile applications. MiniCPM-V (Hu et al.,\n2024), specifically designed for on-device scenarios, integrates a 400M vision encoder and a 7.5B language\nmodel via a perceiver-style adapter. This compact model notably achieves GPT-4V-level performance on\nselected benchmarks. Deepseek VL and Deepseek VL2 (Lu et al., 2024a; Wu et al., 2024), spanning 2–7B\nand 4–27B parameters respectively, further illustrate the growing focus on efficient yet powerful multimodal\nmodels suitable for resource-constrained environments. Collectively, these models demonstrate the increasing\nfeasibility of deploying effective, real-time multimodal AI in practical scenarios.\n125.3 Multimodal Tokenization and Compression Strategies\nEfficient tokenization significantly reduces computational and memory demands in Vision-Language Models\n(VLMs). Early methods, encoding every pixel or patch individually, resulted in lengthy sequences—196\ntokens for a 224 ×224 image at 16 ×16 resolution. Recent strategies compress visual data while preserving\nessential details. Learned modules like Perceiver Resamplers (Jaegle et al., 2021) used by Flamingo and\nIdefics2 (Alayrac et al., 2022b; Laurençon et al., 2024), and BLIP-2’s Q-Former (Li et al., 2023a), compress\ninputs into a small set of latent tokens. While effective in shortening sequences, these methods may limit\nperformance on fine-grained tasks like OCR (Singh et al., 2019; Biten et al., 2019). Spatial compression via\npatch pooling and pixel shuffle is increasingly popular. InternVL v1.5 and Idefics3 (Chen et al., 2024c,b;\nLaurençon et al., 2023) use 2 ×2 pixel-shuffle, reducing token counts fourfold while maintaining OCR capability.\nModels like Qwen-VL-2 (Wang et al., 2024a) adopt multi-scale representations and selective token dropping\nvia convolutional and Transformer modules. Adaptive methods, such as image tiling in UReader and DocOwl,\ndynamically adjust token counts based on task complexity, sacrificing some global context.\n5.4 Video-Capable Vision-Language Models\nExtending vision-language models (VLMs) from images to videos significantly increases complexity due to\ntemporal dimensions, expanding token counts and computational demands. Early models, such as Video-\nLLaVA (Lin et al., 2023a), unified image and video training, aligning video frame features with static\nimages and substantially outperforming predecessors like Video-ChatGPT (Maaz et al., 2023) on benchmarks\nincluding MSRVTT (Xu et al., 2016), MSVD (Chen and Dolan, 2011), TGIF (Li et al., 2016), and ActivityNet\n(Caba Heilbron et al., 2015). Meanwhile, Video-STaR (Zohar et al., 2024a) introduced the first self-training\napproach that leverages existing labeled video datasets for instruction tuning of Large Multimodal Models.\nRecent models enhance efficiency and effectiveness in handling long-form video content. Temporal Preference\nOptimization (TPO) (Li et al., 2025a) employs self-training with localized and comprehensive temporal\ngrounding, improving benchmarks like LongVideoBench, MLVU, and Video-MME. Oryx MLLM (Liu et al.,\n2024g) dynamically compresses visual tokens via its OryxViT encoder, balancing efficiency and precision\nacross tasks. VideoAgent (Wang et al., 2024b) models long-form video understanding as a decision-making\nprocess, utilizing a large language model (LLM) as an agent to identify and compile crucial information for\nquestion answering iteratively. VideoLLaMA3 (Zhang et al., 2025) adapts its vision encoder for variable\nresolutions and uses multi-task fine-tuning to enhance video comprehension. Video-XL (Shu et al., 2024)\nintroduces Visual Summarization Tokens (VST) and curriculum learning for efficient handling of hour-scale\nvideos. Similarly, Kangaroo (Liu et al., 2024b) utilizes curriculum training to scale input resolution and frame\ncount progressively, achieving top performance on diverse benchmarks.\nApollo (Zohar et al., 2024b) recently made an in-depth exploration of Video-LMMs and showed the architecture\nand training schedule that most affect performance. In so doing, it showed the remarkable efficiency gains that\ncan be made during training and inference. Apollo achieved state-of-the-art results with modest parameter\nsizes on benchmarks such as LongVideoBench, MLVU, and Video-MME (Zhou et al., 2024; Fu et al., 2024).\n6 Conclusion\nWe introduced SmolVLM , a family of memory-efficient Vision-Language Models ranging from 256M to 2.2B\nparameters. Remarkably, even our smallest variant requires less than 1GB of GPU memory yet surpasses state-\nof-the-art 80B-parameter models from just 18 months ago (Laurençon et al., 2023). Our findings emphasize a\ncritical insight: scaling down large VLM architectures optimized under resource-rich conditions results in\ndisproportionately high memory demands during inference with little advantage over specialized architectures.\nBy contrast, SmolVLM’s design philosophy explicitly prioritizes compact architectural innovations, aggressive\nbut careful tokenization methods, and efficient training strategies, enabling powerful multimodal capabilities\nat a fraction of the computational cost.\nAll model weights, training datasets, and training code are publicly released to encourage reproducibility,\ntransparency, and continued innovation. We hope SmolVLM will inspire the next generation of lightweight,\nefficient VLMs, unlocking new possibilities for real-time multimodal inference with minimal power consumption.\n13References\nJosh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida,\nJanko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 ,\n2023.\nJean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur\nMensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han,\nZhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L Menick, Sebastian Borgeaud, Andy Brock, Aida\nNematzadeh, Sahand Sharifzadeh, Mikoł aj Bińkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and\nKarén Simonyan. Flamingo: a visual language model for few-shot learning. In S. Koyejo, S. Mohamed, A. Agarwal,\nD. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems , volume 35, pages\n23716–23736. Curran Associates, Inc., 2022a. https://proceedings.neurips.cc/paper_files/paper/2022/file/\n960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf .\nJean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch,\nKatherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in\nneural information processing systems , 35:23716–23736, 2022b.\nLoubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés\nMarafioti, Hynek Kydlíček, Agustín Piqueres Lajarín, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan-Son\nNguyen, Clémentine Fourrier, Ben Burtenshaw, Hugo Larcher, Haojun Zhao, Cyril Zakka, Mathieu Morlon, Colin\nRaffel, Leandro von Werra, and Thomas Wolf. Smollm2: When smol goes big – data-centric training of a small\nlanguage model, 2025. https://arxiv.org/abs/2502.02737 .\nStanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi\nParikh. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision ,\npages 2425–2433, 2015.\nSrikar Appalaraju, Bhavan Jasani, Bhargava Urala Kota, Yusheng Xie, and R Manmatha. Docformer: End-to-end\ntransformer for document understanding. In Proceedings of the IEEE/CVF international conference on computer\nvision, pages 993–1003, 2021.\nJinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren\nZhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv\npreprint arXiv:2308.12966 , 2023.\nShuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun\nTang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu,\nYiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang\nLin. Qwen2.5-vl technical report, 2025. https://arxiv.org/abs/2502.13923 .\nLucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann,\nIbrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.\narXiv preprint arXiv:2407.07726 , 2024.\nAli Furkan Biten, Rubèn Tito, Andrés Mafla, Lluis Gomez, Marçal Rusiñol, C.V. Jawahar, Ernest Valveny, and\nDimosthenis Karatzas. Scene text visual question answering. In 2019 IEEE/CVF International Conference on\nComputer Vision (ICCV) , pages 4290–4300, 2019. doi: 10.1109/ICCV.2019.00439.\nFabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video\nbenchmark for human activity understanding. In Proceedings of the ieee conference on computer vision and pattern\nrecognition , pages 961–970, 2015.\nDavid Chen and William B Dolan. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th\nannual meeting of the association for computational linguistics: human language technologies , pages 190–200, 2011.\nLin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v:\nImproving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793 , 2023.\nLin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua\nLin, et al. Are we on the right way for evaluating large vision-language models? arXiv preprint arXiv:2403.20330 ,\n2024a.\n14Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian,\nZhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and\ntest-time scaling. arXiv preprint arXiv:2412.05271 , 2024b.\nZhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo,\nZheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source\nsuites.arXiv preprint arXiv:2404.16821 , 2024c.\nDeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. https:\n//arxiv.org/abs/2501.12948 .\nMatt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi,\nNiklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo,\nYenSung Chen, Ajay Patel, Mark Yatskar, Chris Callison-Burch, Andrew Head, Rose Hendrix, Favyen Bastani,\nEli VanderBilt, Nathan Lambert, Yvonne Chou, Arnavi Chheda, Jenna Sparks, Sam Skjonsberg, Michael Schmitz,\nAaron Sarnat, Byron Bischoff, Pete Walsh, Chris Newell, Piper Wolters, Tanmay Gupta, Kuo-Hao Zeng, Jon\nBorchardt, Dirk Groeneveld, Crystal Nam, Sophie Lebrecht, Caitlin Wittlif, Carissa Schoenick, Oscar Michel,\nRanjay Krishna, Luca Weihs, Noah A. Smith, Hannaneh Hajishirzi, Ross Girshick, Ali Farhadi, and Aniruddha\nKembhavi. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models, 2024.\nhttps://arxiv.org/abs/2409.17146 .\nHaodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan\nZhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. arXiv\npreprint arXiv:2407.11691 , 2024.\nAbhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil\nMathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 ,\n2024.\nMiquel Farré, Andi Marafioti, Lewis Tunstall, Leandro Von Werra, and Thomas Wolf. Finevideo. https://huggingface.\nco/datasets/HuggingFaceFV/finevideo , 2024.\nManuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali:\nEfficient document retrieval with vision language models. arXiv preprint arXiv:2407.01449 , 2024a.\nManuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali:\nEfficient document retrieval with vision language models, 2024b. https://arxiv.org/abs/2407.01449 .\nChaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang\nShen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms\nin video analysis. arXiv preprint arXiv:2405.21075 , 2024.\nShaikat Galib, Shanshan Wang, Guanshuo Xu, Pascal Pfeiffer, Ryan Chesler, Mark Landry, and Sri Satish Ambati.\nH2ovl-mississippi vision language models technical report, 2024. https://arxiv.org/abs/2410.13611 .\nPhilippe Gervais, Asya Fadeeva, and Andrii Maksai. Mathwriting: A dataset for handwritten mathematical expression\nrecognition, 2024. https://arxiv.org/abs/2404.10690 .\nYash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating\nthe role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer\nvision and pattern recognition , pages 6904–6913, 2017.\nJarvis Guo, Tuney Zheng, Yuelin Bai, Bo Li, Yubo Wang, King Zhu, Yizhi Li, Graham Neubig, Wenhu Chen, and Xiang\nYue. Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale. arXiv preprint arXiv:2412.05237 ,\n2024.\nJordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego\nde Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language\nmodels.arXiv preprint arXiv:2203.15556 , 2022.\nJack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world\nomnimodal understanding for multimodal llms, 2025. https://arxiv.org/abs/2502.04326 .\nShengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin\nZhao, Xinrong Zhang, Zheng Leng Thai, Kaihuo Zhang, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai,\nZhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Minicpm: Unveiling\nthe potential of small language models with scalable training strategies, 2024. https://arxiv.org/abs/2404.06395 .\n15Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General\nperception with iterative attention. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International\nConference on Machine Learning , volume 139 of Proceedings of Machine Learning Research , pages 4651–4664. PMLR,\n18–24 Jul 2021. https://proceedings.mlr.press/v139/jaegle21a.html .\nAniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram\nis worth a dozen images. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors, Computer Vision –\nECCV 2016 , pages 235–251, Cham, 2016. Springer International Publishing. ISBN 978-3-319-46493-0.\nDenis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite,\nMargaret Mitchell, Sean Hughes, Thomas Wolf, et al. The stack: 3 tb of permissively licensed source code. arXiv\npreprint arXiv:2211.15533 , 2022.\nJing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. Grounding language models to images for multimodal inputs\nand outputs, 2023.\nVik Korrapati. Moondream. Online, 2024. https://moondream.ai/ . Accessed: 2025-03-27.\nHugo Laurençon, Lucile Saulnier, Leo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang,\nSiddharth Karamcheti, Alexander M Rush, Douwe Kiela, Matthieu Cord, and Victor Sanh. OBELICS: An open\nweb-scale filtered dataset of interleaved image-text documents. In Thirty-seventh Conference on Neural Information\nProcessing Systems Datasets and Benchmarks Track , 2023. https://openreview.net/forum?id=SKN2hflBIZ .\nHugo Laurençon, Léo Tronchon, Matthieu Cord, and Victor Sanh. What matters when building vision-language\nmodels? arXiv preprint arXiv:2405.02246 , 2024.\nHugo Laurençon, Andrés Marafioti, Victor Sanh, and Léo Tronchon. Building and better understanding vision-language\nmodels: insights and future directions, 2024. https://arxiv.org/abs/2408.12637 .\nJeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick\nKeh, Kushal Arora, et al. Datacomp-LM: In search of the next generation of training sets for language models.\narXiv preprint arXiv:2406.11794 , 2024a.\nJunnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: bootstrapping language-image pre-training with\nfrozen image encoders and large language models. In Proceedings of the 40th International Conference on Machine\nLearning , ICML’23. JMLR.org, 2023a.\nKunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin\nWang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 22195–22206, June 2024b.\nRui Li, Xiaohan Wang, Yuhui Zhang, Zeyu Wang, and Serena Yeung-Levy. Temporal preference optimization for\nlong-form video understanding. arXiv preprint arXiv:2501.13919 , 2025a.\nYuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all\nyou need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463 , 2023b.\nYuncheng Li, Yale Song, Liangliang Cao, Joel Tetreault, Larry Goldberg, Alejandro Jaimes, and Jiebo Luo. Tgif: A\nnew dataset and benchmark on animated gif description. In Proceedings of the IEEE Conference on Computer\nVision and Pattern Recognition , pages 4641–4650, 2016.\nZhiqi Li, Guo Chen, Shilong Liu, Shihao Wang, Vibashan VS, Yishen Ji, Shiyi Lan, Hao Zhang, Yilin Zhao, Subhashree\nRadhakrishnan, et al. Eagle 2: Building post-training data strategies from scratch for frontier vision-language\nmodels.arXiv preprint arXiv:2501.14818 , 2025b.\nBin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual\nrepresentation by alignment before projection. arXiv preprint arXiv:2311.10122 , 2023a.\nZiyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen,\net al. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models.\narXiv preprint arXiv:2311.07575 , 2023b.\nHaotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Thirty-seventh Conference\non Neural Information Processing Systems , 2023. https://openreview.net/forum?id=w0H2xGHlkw .\nHaotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved rea-\nsoning, ocr, and world knowledge, January 2024a. https://llava-vl.github.io/blog/2024-01-30-llava-next/ .\n16Jiajun Liu, Yibing Wang, Hanghang Ma, Xiaoping Wu, Xiaoqi Ma, Xiaoming Wei, Jianbin Jiao, Enhua Wu, and Jie Hu.\nKangaroo: A powerful video-language model supporting long-context video input. arXiv preprint arXiv:2408.15542 ,\n2024b.\nXiaoran Liu, Hang Yan, Shuo Zhang, Chenxin An, Xipeng Qiu, and Dahua Lin. Scaling laws of rope-based extrapolation,\n2024c. https://arxiv.org/abs/2310.05209 .\nYuanxinLiu, ShichengLi, YiLiu, YuxiangWang, ShuhuaiRen, LeiLi, SishuoChen, XuSun, andLuHou. Tempcompass:\nDo video llms really understand videos?, 2024d. https://arxiv.org/abs/2403.00476 .\nYuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen\nJin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information\nSciences, 67(12):220102, 2024e.\nZhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian\nGu, Dacheng Li, et al. Nvila: Efficient frontier visual language models. arXiv preprint arXiv:2412.04468 , 2024f.\nZuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Oryx mllm: On-demand spatial-\ntemporal understanding at arbitrary resolution. arXiv preprint arXiv:2409.12961 , 2024g.\nNikolaos Livathinos, Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Panos Vagenas, Cesar Berrospi\nRamis, Matteo Omenetti, Kasper Dinkla, Yusik Kim, et al. Docling: An efficient open-source toolkit for ai-driven\ndocument conversion. In AAAI 25: Workshop on Open-Source AI for Mainstream Use , 2025.\nAlejandro Lozano, Min Woo Sun, James Burgess, Jeffrey J. Nirschl, Christopher Polzak, Yuhui Zhang, Liangyu Chen,\nJeffrey Gu, Ivan Lopez, Josiah Aklilu, Anita Rau, Austin Wolfgang Katzer, Collin Chiu, Orr Zohar, Xiaohan\nWang, Alfred Seunghoon Song, Chiang Chia-Chun, Robert Tibshirani, and Serena Yeung-Levy. A large-scale\nvision-language dataset derived from open scientific literature to advance biomedical generalist ai. arXiv preprint\narXiv:2503.22727 , 2025. https://arxiv.org/abs/2503.22727 .\nHaoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li,\nYaofeng Sun, et al. Deepseek-vl: towards real-world vision-language understanding. arXiv preprint arXiv:2403.05525 ,\n2024a.\nPan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark,\nand Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In\nS. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information\nProcessing Systems , volume 35, pages 2507–2521. Curran Associates, Inc., 2022. https://proceedings.neurips.\ncc/paper_files/paper/2022/file/11332b6b6cf4485b84afadb1352d3a9a-Paper-Conference.pdf .\nPan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang,\nMichel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual\ncontexts. In International Conference on Learning Representations (ICLR) , 2024b.\nMuhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed\nvideo understanding via large vision and language models. arXiv preprint arXiv:2306.05424 , 2023.\nAhmed Masry, Do Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question\nanswering about charts with visual and logical reasoning. In Findings of the Association for Computational\nLinguistics: ACL 2022 , pages 2263–2279, Dublin, Ireland, May 2022. Association for Computational Linguistics.\ndoi: 10.18653/v1/2022.findings-acl.177. https://aclanthology.org/2022.findings-acl.177 .\nMinesh Mathew, Dimosthenis Karatzas, and C. V. Jawahar. Docvqa: A dataset for vqa on document images.\nIn2021 IEEE Winter Conference on Applications of Computer Vision (WACV) , pages 2199–2208, 2021. doi:\n10.1109/WACV48630.2021.00225.\nBrandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier Biard, Sam Dodge, Philipp Dufter, Bowen Zhang, Dhruti\nShah, Xianzhi Du, Futang Peng, Haotian Zhang, Floris Weers, Anton Belyi, Karanjeet Singh, Doug Kang, Ankur\nJain, Hongyu He, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du,\nTao Lei, Sam Wiseman, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, and Yinfei Yang.\nMm1: Methods, analysis & insights from multimodal llm pre-training, 2024. https://arxiv.org/abs/2403.09611 .\nAhmed Nassar, Andres Marafioti, Matteo Omenetti, Maksym Lysak, Nikolaos Livathinos, Christoph Auer, Lucas\nMorin, Rafael Teixeira de Lima, Yusik Kim, A. Said Gurbuz, Michele Dolfi, Miquel Farré, and Peter W. J. Staar.\nSmoldocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion, 2025a.\nhttps://arxiv.org/abs/2503.11576 .\n17Ahmed Nassar, Andres Marafioti, Matteo Omenetti, Maksym Lysak, Nikolaos Livathinos, Christoph Auer, Lucas\nMorin, Rafael Teixeira de Lima, Yusik Kim, A Said Gurbuz, et al. Smoldocling: An ultra-compact vision-language\nmodel for end-to-end multi-modal document conversion. arXiv preprint arXiv:2503.11576 , 2025b.\nOpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar,\nAleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz,\nAlexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone,\nAndrew Duberstein, Andrew Kondrich, Andrey Mishchenko, Andy Applebaum, Angela Jiang, Ashvin Nair, Barret\nZoph, Behrooz Ghorbani, Ben Rossen, Benjamin Sokolowsky, Boaz Barak, Bob McGrew, Borys Minaiev, Botao\nHao, Bowen Baker, Brandon Houghton, Brandon McKinzie, Brydon Eastman, Camillo Lugaresi, Cary Bassin, Cary\nHudson, Chak Ming Li, Charles de Bourcy, Chelsea Voss, Chen Shen, Chong Zhang, Chris Koch, Chris Orsinger,\nChristopher Hesse, Claudia Fischer, Clive Chan, Dan Roberts, Daniel Kappler, Daniel Levy, Daniel Selsam, David\nDohan, David Farhi, David Mely, David Robinson, Dimitris Tsipras, Doug Li, Dragos Oprica, Eben Freeman,\nEddie Zhang, Edmund Wong, Elizabeth Proehl, Enoch Cheung, Eric Mitchell, Eric Wallace, Erik Ritter, Evan\nMays, Fan Wang, Felipe Petroski Such, Filippo Raso, Florencia Leoni, Foivos Tsimpourlas, Francis Song, Fred von\nLohmann, Freddie Sulit, Geoff Salmon, Giambattista Parascandolo, Gildas Chabot, Grace Zhao, Greg Brockman,\nGuillaume Leclerc, Hadi Salman, Haiming Bao, Hao Sheng, Hart Andrin, Hessam Bagherinezhad, Hongyu Ren,\nHunter Lightman, Hyung Won Chung, Ian Kivlichan, Ian O’Connell, Ian Osband, Ignasi Clavera Gilaberte, Ilge\nAkkaya, Ilya Kostrikov, Ilya Sutskever, Irina Kofman, Jakub Pachocki, James Lennon, Jason Wei, Jean Harb, Jerry\nTwore, Jiacheng Feng, Jiahui Yu, Jiayi Weng, Jie Tang, Jieqi Yu, Joaquin Quiñonero Candela, Joe Palermo, Joel\nParish, Johannes Heidecke, John Hallman, John Rizzo, Jonathan Gordon, Jonathan Uesato, Jonathan Ward, Joost\nHuizinga, Julie Wang, Kai Chen, Kai Xiao, Karan Singhal, Karina Nguyen, Karl Cobbe, Katy Shi, Kayla Wood,\nKendra Rimbach, Keren Gu-Lemberg, Kevin Liu, Kevin Lu, Kevin Stone, Kevin Yu, Lama Ahmad, Lauren Yang,\nLeo Liu, Leon Maksin, Leyton Ho, Liam Fedus, Lilian Weng, Linden Li, Lindsay McCallum, Lindsey Held, Lorenz\nKuhn, Lukas Kondraciuk, Lukasz Kaiser, Luke Metz, Madelaine Boyd, Maja Trebacz, Manas Joglekar, Mark Chen,\nMarko Tintor, Mason Meyer, Matt Jones, Matt Kaufer, Max Schwarzer, Meghan Shah, Mehmet Yatbaz, Melody Y.\nGuan, Mengyuan Xu, Mengyuan Yan, Mia Glaese, Mianna Chen, Michael Lampe, Michael Malek, Michele Wang,\nMichelle Fradin, Mike McClay, Mikhail Pavlov, Miles Wang, Mingxuan Wang, Mira Murati, Mo Bavarian, Mostafa\nRohaninejad, Nat McAleese, Neil Chowdhury, Neil Chowdhury, Nick Ryder, Nikolas Tezak, Noam Brown, Ofir\nNachum, Oleg Boiko, Oleg Murk, Olivia Watkins, Patrick Chao, Paul Ashbourne, Pavel Izmailov, Peter Zhokhov,\nRachel Dias, Rahul Arora, Randall Lin, Rapha Gontijo Lopes, Raz Gaon, Reah Miyara, Reimar Leike, Renny\nHwang, Rhythm Garg, Robin Brown, Roshan James, Rui Shu, Ryan Cheu, Ryan Greene, Saachi Jain, Sam Altman,\nSam Toizer, Sam Toyer, Samuel Miserendino, Sandhini Agarwal, Santiago Hernandez, Sasha Baker, Scott McKinney,\nScottie Yan, Shengjia Zhao, Shengli Hu, Shibani Santurkar, Shraman Ray Chaudhuri, Shuyuan Zhang, Siyuan Fu,\nSpencer Papay, Steph Lin, Suchir Balaji, Suvansh Sanjeev, Szymon Sidor, Tal Broda, Aidan Clark, Tao Wang, Taylor\nGordon, Ted Sanders, Tejal Patwardhan, Thibault Sottiaux, Thomas Degry, Thomas Dimson, Tianhao Zheng, Timur\nGaripov, Tom Stasi, Trapit Bansal, Trevor Creech, Troy Peterson, Tyna Eloundou, Valerie Qi, Vineet Kosaraju,\nVinnie Monaco, Vitchyr Pong, Vlad Fomenko, Weiyi Zheng, Wenda Zhou, Wes McCabe, Wojciech Zaremba, Yann\nDubois, Yinghai Lu, Yining Chen, Young Cha, Yu Bai, Yuchen He, Yuchen Zhang, Yunyun Wang, Zheng Shao, and\nZhuohan Li. Openai o1 system card, 2024. https://arxiv.org/abs/2412.16720 .\nGuilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Hamza Alobeidli, Alessandro Cappelli,\nBaptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The RefinedWeb dataset for Falcon LLM: Outperforming\ncurated corpora with web data only. In Advances in Neural Information Processing Systems , 2024.\nAlec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda\nAskell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models\nfrom natural language supervision. In International Conference on Machine Learning , 2021.\nWeiming Ren, Huan Yang, Jie Min, Cong Wei, and Wenhu Chen. Vista: Enhancing long-duration and high-resolution\nvideo understanding by video spatiotemporal augmentation, 2024. https://arxiv.org/abs/2412.00927 .\nMin Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, De-An Huang, Hongxu Yin, Karan Sapra,\nYaser Yacoob, Humphrey Shi, et al. Eagle: Exploring the design space for multimodal llms with mixture of encoders.\narXiv preprint arXiv:2408.15998 , 2024.\nWenzhe Shi, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and\nZehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural\nnetwork, 2016. https://arxiv.org/abs/1609.05158 .\nYan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao.\nVideo-xl: Extra-long vision language model for hour-scale video understanding. arXiv preprint arXiv:2409.14485 ,\n2024.\n18Amanpreet Singh, Vivek Natarjan, Meet Shah, Yu Jiang, Xinlei Chen, Devi Parikh, and Marcus Rohrbach. Towards\nvqa models that can read. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ,\npages 8317–8326, 2019.\nLuca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi\nChandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu,\nNathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E.\nPeters, Abhilasha Ravichander, Kyle Richardson, Zejiang Shen, Emma Strubell, Nishant Subramani, Oyvind Tafjord,\nPete Walsh, Luke Zettlemoyer, Noah A. Smith, Hannaneh Hajishirzi, Iz Beltagy, Dirk Groeneveld, Jesse Dodge, and\nKyle Lo. Dolma: an open corpus of three trillion tokens for language model pretraining research, 2024.\nEnxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo,\nTian Ye, Yanting Zhang, Yan Lu, Jenq-Neng Hwang, and Gaoang Wang. Moviechat: From dense token to sparse\nmemory for long video understanding, 2024. https://arxiv.org/abs/2307.16449 .\nAndreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey\nGritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, Siyang Qin, Reeve Ingle, Emanuele Bugliarello,\nSahar Kazemzadeh, Thomas Mesnard, Ibrahim Alabdulmohsin, Lucas Beyer, and Xiaohua Zhai. Paligemma 2: A\nfamily of versatile vlms for transfer, 2024. https://arxiv.org/abs/2412.03555 .\nGemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard\nHussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models\nat a practical size, 2024. URL https://arxiv. org/abs/2408.00118 , 1(3), 2024.\nPeter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng\nYang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric exploration of\nmultimodal llms. Advances in Neural Information Processing Systems , 37:87310–87356, 2024.\nHugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste\nRozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and\nGuillaume Lample. Llama: Open and efficient foundation language models, 2023.\nPeng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin\nGe, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint\narXiv:2409.12191 , 2024a.\nXiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understanding with\nlarge language model as agent. In European Conference on Computer Vision , pages 58–76. Springer, 2024b.\nZhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue\nWu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Jiawei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan,\nAixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, and Chong\nRuan. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding, 2024.\nhttps://arxiv.org/abs/2412.10302 .\nJun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language.\nInProceedings of the IEEE conference on computer vision and pattern recognition , pages 5288–5296, 2016.\nZhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie:\nAlignment data synthesis from scratch by prompting aligned llms with nothing. arXiv preprint arXiv:2406.08464 ,\n2024.\nDongjie Yang, Suyuan Huang, Chengqiang Lu, Xiaodong Han, Haoxin Zhang, Yan Gao, Yao Hu, and Hai Zhao. Vript:\nA video is worth thousands of words, 2024. https://arxiv.org/abs/2406.06040 .\nYuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui\nHe, Qianyu Chen, Huarong Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai,\nXu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Minicpm-v: A gpt-4v level mllm on your phone,\n2024. https://arxiv.org/abs/2408.01800 .\nJiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Guohai Xu, Chenliang Li, Junfeng Tian, Qi Qian, Ji Zhang,\net al. Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model.\narXiv preprint arXiv:2310.05126 , 2023.\nXiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming\nRen, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang,\n19Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal\nunderstanding and reasoning benchmark for expert agi. In Proceedings of CVPR , 2024a.\nXiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building\nmath generalist models through hybrid instruction tuning, 2023. URL https://arxiv. org/abs/2309.05653 , 2024b.\nXiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training.\nInProceedings of the IEEE/CVF International Conference on Computer Vision , pages 11975–11986, 2023.\nBoqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang,\nHang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.\narXiv preprint arXiv:2501.13106 , 2025.\nYuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with\nsynthetic data, 2024. https://arxiv.org/abs/2410.02713 .\nLianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan\nLi, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural\nInformation Processing Systems , 36, 2024.\nJunjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng\nLiu. Mlvu: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264 ,\n2024.\nOrr Zohar, Xiaohan Wang, Yonatan Bitton, Idan Szpektor, and Serena Yeung-Levy. Video-star: Self-training enables\nvideo instruction tuning with any supervision, 2024a. https://arxiv.org/abs/2407.06189 .\nOrr Zohar, Xiaohan Wang, Yann Dubois, Nikhil Mehta, Tong Xiao, Philippe Hansen-Estruch, Licheng Yu, Xiaofang\nWang, Felix Juefei-Xu, Ning Zhang, et al. Apollo: An exploration of video understanding in large multimodal\nmodels.arXiv preprint arXiv:2412.10360 , 2024b.\n20",
"publish_date": "2025-04-08",
"insert_date": "2026-01-14 10:40:51"
},
{
"_id": {
"$oid": "6967084a4f4688a8155b16f9"
},
"arxiv_id": "2501.09898v4",
"title": "FoundationStereo: Zero-Shot Stereo Matching",
"authors": [
"Bowen Wen",
"Matthew Trepte",
"Joseph Aribido",
"Jan Kautz",
"Orazio Gallo",
"Stan Birchfield"
],
"categories": [
"Computer Vision",
"Machine Learning",
"Deep Learning",
"Neural Networks",
"Image Processing",
"Pattern Recognition",
"Artificial Intelligence",
"Data Science",
"Computer Graphics"
],
"keywords": [
"FoundationStereo",
"Zero-Shot Stereo Matching",
"Stereo Depth Estimation",
"Foundation Model",
"Zero-Shot Generalization",
"Synthetic Dataset",
"Self-Curation Pipeline",
"Monocular Priors",
"Cost Volume Filtering",
"Long-Range Context Reasoning",
"Transformer Architecture",
"Disparity Transformer",
"Side-Tuning Feature Backbone",
"Photorealism",
"Sim-to-Real Gap"
],
"content": "FoundationStereo: Zero-Shot Stereo Matching\nBowen Wen Matthew Trepte Joseph Aribido Jan Kautz\nOrazio Gallo Stan Birchfield\nNVIDIA\nFigure 1. Zero-shot prediction on in-the-wild images. Our method generalizes to diverse scenarios (indoor / outdoor), objects of challenging properties\n(textureless / reflective / translucent / thin-structured), complex illuminations (shadow / strong exposure), various viewing perspectives and sensing ranges.\nAbstract\nTremendous progress has been made in deep stereo match-\ning to excel on benchmark datasets through per-domain\nfine-tuning. However, achieving strong zero-shot general-\nization — a hallmark of foundation models in other com-\nputer vision tasks — remains challenging for stereo match-\ning. We introduce FoundationStereo, a foundation model\nfor stereo depth estimation designed to achieve strong zero-\nshot generalization. To this end, we first construct a large-\nscale (1M stereo pairs) synthetic training dataset featuring\nlarge diversity and high photorealism, followed by an auto-\nmatic self-curation pipeline to remove ambiguous samples.\nWe then design a number of network architecture compo-\nnents to enhance scalability, including a side-tuning fea-\nture backbone that adapts rich monocular priors from vi-\nsion foundation models to mitigate the sim-to-real gap, and\nlong-range context reasoning for effective cost volume fil-\ntering. Together, these components lead to strong robust-\nness and accuracy across domains, establishing a new stan-\ndard in zero-shot stereo depth estimation. Project page:\nhttps://nvlabs.github.io/FoundationStereo/\n1. Introduction\nSince the advent of the first stereo matching algorithm\nnearly half a century ago [42], we have come a long way.Recent stereo algorithms can achieve amazing results, al-\nmost saturating the most challenging benchmarks—thanks\nto the proliferation of training datasets and advances in deep\nneural network architectures. Yet, fine-tuning on the dataset\nof the target domain is stillthe method of choice to get com-\npetitive results. Given the zero-shot generalization ability\nshown on other problems within computer vision via the\nscaling law [32, 46, 78, 79], what prevents stereo matching\nalgorithms from achieving a similar level of generalization?\nLeading stereo networks [11, 41, 53, 54, 73, 80] con-\nstruct cost volumes from the unary features and lever-\nage 3D CNNs for cost filtering. Refinement-based meth-\nods [14, 21, 27, 34, 36, 60, 67, 86] iteratively refine the\ndisparity map based on recurrent modules such as Gated\nRecurrent Units (GRU). Despite their success on public\nbenchmarks under per-domain fine-tuning setup, however,\nthey struggle to gather non-local information to effectively\nscale to larger datasets. Other methods [35, 68] explore\ntransformer architectures for unary feature extraction, while\nlacking the specialized structure afforded by cost volumes\nand iterative refinement to achieve high accuracy.\nSuch limitations have, to date, hindered the development\nof a stereo network that generalizes well to other domains.\nWhile it is true that cross-domain generalization has been\nexplored by some prior works [10, 17, 37, 49, 82, 84], sucharXiv:2501.09898v4 [cs.CV] 4 Apr 2025approaches have not achieved results that are competitive\nwith those obtained by fine-tuning on the target domain, ei-\nther due to insufficient structure in the network architecture,\nimpoverished training data, or both. These networks are\ngenerally experimented on Scene Flow [43], a rather small\ndataset with only 40K annotated training image pairs. As a\nresult, none of these methods can be used as an off-the-shelf\nsolution, as opposed to the strong generalizability of vision\nfoundation models that have emerged in other tasks.\nTo address these limitations, we propose Foundation-\nStereo, a large foundation model for stereo depth estimation\nthat achieves strong zero-shot generalization without per-\ndomain fine-tuning. We train the network on a large-scale\n(1M image pairs) high-fidelity synthetic training dataset\nwith high diversity and photorealism. An automatic self-\ncuration pipeline is developed to eliminate the ambiguous\nsamples that are inevitably introduced during the domain\nrandomized data generation process, improving both the\ndataset quality and model robustness over iterate updates.\nTo mitigate the sim-to-real gap, we propose a side-tuning\nfeature backbone that adapts internet-scale rich priors from\nDepthAnythingV2 [79] that is trained on real monocular\nimages to the stereo setup. To effectively leverage these\nrich monocular priors embedded into the 4D cost volume,\nwe then propose an Attentive Hybrid Cost V olume (AHCF)\nmodule, consisting of 3D Axial-Planar Convolution (APC)\nfiltering that decouples standard 3D convolution into two\nseparate spatial- and disparity-oriented 3D convolutions,\nenhancing the receptive fields for volume feature aggrega-\ntion; and a Disparity Transformer (DT) that performs self-\nattention over the entire disparity space within the cost vol-\nume, providing long range context for global reasoning. To-\ngether, these innovations significantly enhance the represen-\ntation, leading to better disparity initialization, as well as\nmore powerful features for the subsequent iterative refine-\nment process.\nOur contributions can be summarized as follows:\n•We present FoundationStereo, a zero-shot generalizable\nstereo matching model that achieves comparable or even\nmore favorable results to prior works fine-tuned on a\ntarget domain; it also significantly outperforms existing\nmethods when applied to in-the-wild data.\n•We create a large-scale (1M) high-fidelity synthetic\ndataset for stereo learning with high diversity and pho-\ntorealism; and a self-curation pipeline to ensure that bad\nsamples are pruned.\n•To harness internet-scale knowledge containing rich se-\nmantic and geometric priors, we propose a Side-Tuning\nAdapter (STA) that adapts the ViT-based monocular\ndepth estimation model [79] to the stereo setup.\n•We develop Attentive Hybrid Cost Filtering (AHCF),\nwhich includes an hourglass module with 3D Axial-\nPlanar Convolution (APC), and a Disparity Transformer(DT) module that performs full self-attention over the\ndisparity dimension.\n2. Related Work\nDeep Stereo Matching. Recent advances in stereo match-\ning have been driven by deep learning, significantly enhanc-\ning accuracy and generalization. Cost volume aggregation\nmethods construct cost volumes from unary features and\nperform 3D CNN for volume filtering [11, 41, 53, 54, 73,\n80], though the high memory consumption prevents direct\napplication to high resolution images. Iterative refinement\nmethods, inspired by RAFT [57], bypasses the costly 4D\nvolume construction and filtering by recurrently refining the\ndisparity [14, 21, 27, 34, 36, 60, 67, 86]. While they gener-\nalize well to various disparity range, the recurrent updates\nare often time-consuming, and lack long-range context rea-\nsoning. Recent works [71, 72] thus combine the strengths\nof cost filtering and iterative refinement. With the tremen-\ndous progress made by vision transformers, another line of\nresearch [23, 35, 68] introduces transformer architecture to\nstereo matching, particularly in the unary feature extrac-\ntion stage. Despite their success on per-domain fine-tuning\nsetup, zero-shot generalization still remains challenging. To\ntackle this problem, [10, 17, 37, 49, 82, 84] explore learning\ndomain-invariant features for cross-domain generalization,\nwith a focus on training on Scene Flow [43] dataset. Con-\ncurrent work [3] achieves remarkable zero-shot generaliza-\ntion with monocular prior enhanced correlation volumes.\nHowever, the strong generalizability of vision foundation\nmodels emerged in other tasks that is supported by scaling\nlaw has yet to be fully realized in stereo matching for prac-\ntical applications.\nStereo Matching Training Data. Training data is essen-\ntial for deep learning models. KITTI 12 [20] and KITTI\n15 [45] provide hundreds of training pairs on driving sce-\nnarios. DrivingStereo [76] further scales up to 180K stereo\npairs. Nevertheless, the sparse ground-truth disparity ob-\ntained by LiDAR sensors hinders learning accurate and\ndense stereo matching. Middlebury [51] and ETH3D [52]\ndevelop a low number of training data covering both in-\ndoor and outdoor scenarios beyond driving. Booster [48]\npresents a real-world dataset focusing on transparent ob-\njects. InStereo2K [2] presents a larger training dataset con-\nsisting of 2K stereo pairs with denser ground-truth dispar-\nity obtained with structured light system. However, chal-\nlenges of scarce data size, imperfect ground-truth disparity\nand lack of collection scalability in real-world have driven\nthe widespread adoption of synthetic data for training. This\nincludes Scene Flow [43], Sintel [6], CREStereo [34],\nIRS [64], TartanAir [66], FallingThings [61], Virtual KITTI\n2 [7], CARLA HR-VS [75], Dynamic Replica [28]. In\nTab. 1, we compare our proposed FoundationStereo dataset\n(FSD) with commonly used synthetic training datasets forProperties Sintel [6] Sceneflow [43] CREStereo [34] IRS [64] TartanAir [66] FallingThings [61] UnrealStereo4K [59] Spring [44] FSD (Ours)ScenariosFlying Objects ✗ ✓ ✓ ✗ ✗ ✗ ✗ ✗ ✓\nIndoor ✗ ✗ ✗ ✓ ✓ ✓ ✓ ✗ ✓\nOutdoor ✗ ✓ ✗ ✗ ✓ ✓ ✓ ✗ ✓\nDriving ✗ ✓ ✗ ✗ ✗ ✗ ✗ ✗ ✓\nMovie ✓ ✓ ✗ ✗ ✗ ✗ ✗ ✓ ✗\nSimulator Blender Blender Blender Unreal Engine Unreal Engine Unreal Engine Unreal Engine Blender NVIDIA Omniverse\nRendering Realism High Low High High High High High High High\nScenes 10 9 0 4 18 3 8 47 12\nLayout Realism Medium Low Low High High Medium High High High\nStereo Pairs 1K†40K†200K 103K†306K†62K 7.7K 6K†1000K\nResolution 1024×436 960 ×540 1920 ×1080 960 ×540 640 ×480 960 ×540 3840 ×2160 1920 ×1080 1280 ×720\nReflections ✗ ✗ ✓ ✓ ✓ ✓ ✓ ✗ ✓\nCamera Params Constant Constant Constant Constant Constant Constant ConstantConstant baseline,\nvarying intrinsicsVarying baseline\nand intrinsics\nTable 1. Synthetic datasets for training stereo algorithms (excluding test images with inaccessible ground truth).†Indicates reduced diversity, caused by\nincluding many similar frames from video sequences.\nstereo matching. Our dataset encompasses a wide range of\nscenarios, features the largest data volume to date, includes\ndiverse 3D assets, captures stereo images under diversely\nrandomized camera parameters, and achieves high fidelity\nin both rendering and spatial layouts.\nVision Foundation Models. Vision foundation models\nhave significantly advanced across various vision tasks in\n2D, 3D and multi-modal alignment. CLIP [47] leverages\nlarge-scale image-text pair training to align visual and tex-\ntual modalities, enabling zero-shot classification and facil-\nitating cross-modal applications. DINO series [8, 38, 46]\nemploy self-supervised learning for dense representation\nlearning, effectively capturing detailed features critical for\nsegmentation and recognition tasks. SAM series [32, 50,\n77] demonstrate high versatility in segmentation driven\nby various prompts such as points, bounding boxes, lan-\nguage. Similar advancements also appear in 3D vision\ntasks. DUSt3R [65] and MASt3R [33] present generaliz-\nable frameworks for dense 3D reconstruction from uncali-\nbrated and unposed cameras. FoundationPose [69] develops\na unified framework of 6D object pose estimation and track-\ning for novel objects. More closely related to this work, a\nnumber of efforts [4, 29, 78, 79] demonstrated strong gener-\nalization in monocular depth estimation task and multi-view\nstereo [26]. Together, these approaches exemplify under the\nscaling law, how foundation models in vision are evolving\nto support robust applications across diverse scenarios with-\nout tedious per-domain fine-tuning.\n3. Approach\nThe overall network architecture is shown in Fig. 2. The\nrest of this section describes the various components.\n3.1. Monocular Foundation Model Adaptation\nTo mitigate the sim-to-real gap when the stereo network is\nprimarily trained on synthetic dataset, we leverage the re-\ncent advancements on monocular depth estimation trained\non internet-scale real data [5, 79]. We use a CNN network\nto adapt the ViT-based monocular depth estimation network\nto the stereo setup, thus synergizing the strengths of both\nCNN and ViT architectures.We explored multiple design choices for combining\nCNN and ViT approaches, as outlined in Fig. 3 (left). In\nparticular, (a) directly uses the feature pyramids from the\nDPT head in a frozen DepthAnythingV2 [79] without using\nCNN features. (b) resembles ViT-Adapter [12] by exchang-\ning features between CNN and ViT. (c) applies a 4×4con-\nvolution with stride 4 to downscale the feature before the\nDepthAnythingV2 final output head. The feature is then\nconcatenated with the same level CNN feature to obtain a\nhybrid feature at 1/4 scale. The side CNN network is thus\nlearned to adapt the ViT features [83] to stereo matching\ntask. Surprisingly, while being simple, we found (c) signifi-\ncantly surpasses the alternative choices on the stereo match-\ning task, as shown in the experiments (Sec. 4.5). As a result,\nwe adopt (c) as the main design of STA module.\nFormally, given a pair of left and right images Il, Ir∈\nRH×W×3, we employ EdgeNeXt-S [40] as the CNN\nmodule within STA to extract multi-level pyramid fea-\ntures, where the 1/4 level feature is equipped with\nDepthAnythingV2 feature: f(i)\nl, f(i)\nr∈RCi×H\ni×W\ni,i∈\n{4,8,16,32}. EdgeNeXt-S [40] is chosen for its memory\nefficiency and because larger CNN backbones did not yield\nadditional benefits in our investigation. When forwarding to\nDepthAnythingV2, we first resize the image to be divisible\nby 14, to be consistent with its pretrained patch size. The\nSTA weights are shared when applied to Il, Ir.\nSimilarly, we employ STA to extract context feature,\nwith the difference that the CNN module is designed with\na sequence of residual blocks [25] and down-sampling lay-\ners. It generates context features of multiple scales: f(i)\nc∈\nRCi×H\ni×W\ni,i∈ {4,8,16}, as in [36]. fcparticipates in\ninitializing the hidden state of the ConvGRU block and in-\nputting to the ConvGRU block at each iteration, effectively\nguiding the iterative process with progressively refined con-\ntextual information.\nFig. 3 visualizes the power of rich monocular prior that\nhelps to reliably predict on ambiguous regions which is\nchallenging to deal with by naive correspondence search\nalong the epipolar line. Instead of using the raw monocular\ndepth from DepthAnythingV2 which has scale ambiguity,\nwe use its latent feature as geometric priors extracted fromFigure 2. Overview of our proposed FoundationStereo. The Side-Tuning Adapter (STA) adapts the rich monocular priors from a frozen DepthAny-\nthingV2 [79], while combined with fine-grained high-frequency features from multi-level CNN for unary feature extraction. Attentive Hybrid Cost Filtering\n(AHCF) combines the strengths of the Axial-Planar Convolution (APC) filtering and a Disparity Transformer (DT) module to effectively aggregate the\nfeatures along spatial and disparity dimensions over the 4D hybrid cost volume. An initial disparity is then predicted from the filtered cost volume, and\nsubsequently refined through GRU blocks. At each refinement step, the latest disparity is used to look up features from both filtered hybrid cost volume and\ncorrelation volume to guide the next refinement. The iteratively refined disparity becomes the final output.\nDepth\nAnything \nV2\nCNN\nDepth\nAnything \nV2\nCNN\nCNN\nCNN\n(a) (b) (c)1/16\n1/8\n1/4\n1/32\n1/16\n1/8\n1/41/32\n1/16\n1/8\n1/4\nDown\nDepth\nAnything \nV2\nCNN\nCNN\nCNN\nCNN\nFigure 3. Left: Design choices for STA module. Right: Effects of the proposed STA and AHCF modules. “W/o STA” only uses CNN to extract features.\n“W/o AHCF” uses conventional 3D CNN-based hourglass network for cost volume filtering. Results are obtained via zero-shot inference without fine-\ntuning on target dataset. STA leverages rich monocular prior to reliably predict the lamp region with inconsistent lighting and dark guitar sound hole. AHCF\neffectively aggregates the spatial and long-range disparity context to accurately predict over thin repetitive structures.\nboth stereo images and compared through cost filtering as\ndescribed next.\n3.2. Attentive Hybrid Cost Filtering\nHybrid Cost Volume Construction. Given unary features\nat 1/4 scale f4\nl, f4\nrextracted from previous step, we con-\nstruct the cost volume VC∈RC×D\n4×H\n4×W\n4with a com-\nbination of group-wise correlation and concatenation [24]:\nVgwc(g, d, h, w ) =D\nbf(4)\nl,g(h, w),bf(4)\nr,g(h, w−d)E\n,\nVcat(d, h, w ) =h\nConv(f(4)\nl)(h, w),Conv(f(4)\nr)(h, w−d)i\n,\nVC(d, h, w ) = [Vgwc(d, h, w ),Vcat(d, h, w )] (1)\nwherebfdenotes L2normalized feature for better training\nstability; ⟨·,·⟩represents dot product; g∈ {1,2, ..., G}is\nthe group index among the total G= 8 feature groups that\nwe evenly divide the total features into; d∈ {1,2, ...,D\n4}is\nthe disparity index. [·,·]denotes concatenation along chan-\nnel dimension. The group-wise correlation Vgwcharnesses\nthe strengths of conventional correlation-based matchingcosts, offering a diverse set of similarity measurement fea-\ntures from each group. Vcatpreserves unary features includ-\ning the rich monocular priors by concatenating left and right\nfeatures at shifted disparity. To reduce memory consump-\ntion, we linearly downsize the unary feature dimension to\n14 using a convolution of kernel size 1 (weights are shared\nbetween f4\nlandf4\nr) before concatenation. Next, we de-\nscribe two sub-modules for effective cost volume filtering.\nAxial-Planar Convolution (APC) Filtering. An hourglass\nnetwork consisting of 3D convolutions, with three down-\nsampling blocks and three up-sampling blocks with residual\nconnections, is leveraged for cost volume filtering [1, 71].\nWhile 3D convolutions of kernel size 3×3×3are com-\nmonly used for relatively small disparity sizes [9, 24, 71],\nwe observe it struggles with larger disparities when applied\nto high resolution images, especially since the disparity di-\nmension is expected to model the probability distribution\nfor the initial disparity prediction. However, it is impracti-\ncal to naively increase the kernel size, due to the intensive\nmemory consumption. In fact, even when setting kernel size\nto5×5×5we observe unmanageable memory usage on an80 GB GPU. This drastically limits the model’s representa-\ntion power when scaling up with large amount of training\ndata. We thus develop “Axial-Planar Convolution” which\ndecouples a single 3×3×3convolution into two sepa-\nrate convolutions: one over spatial dimensions (kernel size\nKs×Ks×1) and the other over disparity ( 1×1×Kd),\neach followed by BatchNorm and ReLU. APC can be re-\ngarded as a 3D version of Separable Convolution [16] with\nthe difference that we only separate the spatial and dispar-\nity dimensions without subdividing the channel into groups\nwhich sacrifices representation power. The disparity dimen-\nsion is specially treated due to its uniquely encoded feature\ncomparison within the cost volume. We use APC wher-\never possible in the hourglass network except for the down-\nsampling and up-sampling layers.\nDisparity Transformer (DT). While prior works [35, 68]\nintroduced transformer architecture to unary feature extrac-\ntion step to scale up stereo training, the cost filtering pro-\ncess is often overlooked, which remains an essential step\nin achieving accurate stereo matching by encapsulating cor-\nrespondence information. Therefore, we introduce DT to\nfurther enhance the long-range context reasoning within the\n4D cost volume. Given VCobtained in Eq. (1), we first\napply a 3D convolution of kernel size 4×4×4with stride\n4 to downsize the cost volume. We then reshape the vol-\nume into a batch of token sequences, each with length of\ndisparity. We apply position encoding before feeding it to a\nseries (4 in our case) of transformer encoder blocks, where\nFlashAttention [18] is leveraged to perform multi-head self-\nattention [63]. The process can be written as:\nQ0=PE(R(Conv 4×4×4(VC)))∈R(H\n16×W\n16)×C×D\n16\nMultiHead (Q,K,V) = [ head 1, . . . , head h]WO\nwhere head i=FlashAttention (Qi,Ki,Vi)\nQ1=Norm (MultiHead (Q0,Q0,Q0) +Q0)\nQ2=Norm (FFN(Q1) +Q1)\nwhereR(·)denotes reshape operation; PE (·)represents po-\nsition encoding; [·,·]denotes concatenation along the chan-\nnel dimension; WOis linear weights. The number of heads\nish= 4 in our case. Finally, the DT output is up-sampled\nto the same size as VCusing trilinear interpolation and\nsummed with hourglass output, as shown in Fig. 2.\nInitial Disparity Prediction. We apply soft-argmin [30] to\nthe filtered volume V′\nCto produce an initial disparity:\nd0=D\n4−1X\nd=0d·Softmax (V′\nC)(d) (2)\nwhere d0is at 1/4 scale of the original image resolution.\n3.3. Iterative Refinement\nGiven d0, we perform iterative GRU updates to progres-\nsively refine disparity, which helps to avoid local optimum\nand accelerate convergence [71]. In general, the k-th updatecan be formulated as:\nVcorr(w′, h, w ) =D\nf(4)\nl(h, w), f(4)\nr(h, w′)E\n(3)\nFV(h, w) = [V′\nC(dk, h, w ),Vcorr(w−dk, h, w )] (4)\nxk= [Conv v(FV),Conv d(dk), dk, c] (5)\nzk=σ(Conv z([hk−1, xk])) (6)\nrk=σ(Conv r([hk−1, xk])) (7)\nˆhk=tanh(Conv h([rk⊙hk−1, xk])) (8)\nhk= (1−zk)⊙hk−1+zk⊙ˆhk (9)\ndk+1=dk+Conv ∆(hk) (10)\nwhere⊙denotes element-wise product; σdenotes sigmoid;\nVcorr∈RW\n4×H\n4×W\n4is the pair-wise correlation volume;\nFVrepresents the looked up volume features using lat-\nest disparity; c=ReLU (fc)encodes the context feature\nfrom left image, including STA adapted features (Sec. 3.1)\nwhich effectively guide the refinement process leveraging\nrich monocular priors.\nWe use three levels of GRU blocks to perform coarse-\nto-fine hidden state update in each iteration, where the ini-\ntial hidden states are produced from context features h(i)\n0=\ntanh(f(i)\nc), i∈ {4,8,16}. At each level, attention-based se-\nlection mechanism [67] is leveraged to capture information\nat different frequencies. Finally, dkis up-sampled to the full\nresolution using convex sampling [57].\n3.4. Loss Function\nThe model is trained with the following objective:\nL=\f\fd0−d\f\f\nsmooth+KX\nk=1γK−k\r\rdk−d\r\r\n1(11)\nwhere drepresents ground-truth disparity; |·|smoothdenotes\nsmooth L1loss;kis the iteration number; γis set to 0.9, and\nwe apply exponentially increasing weights [36] to supervise\nthe iteratively refined disparity.\n3.5. Synthetic Training Dataset\nWe created a large scale synthetic training dataset with\nNVIDIA Omniverse. This FoundationStereo Dataset (FSD)\naccounts for crucial stereo matching challenges such as re-\nflections, low-texture surfaces, and severe occlusions. We\nperform domain randomization [58] to augment dataset\ndiversity, including random stereo baseline, focal length,\ncamera perspectives, lighting conditions and object config-\nurations. Meanwhile, high-quality 3D assets with abundant\ntextures and path-tracing rendering are leveraged to enhance\nrealism in rendering and layouts. Fig. 4 displays some sam-\nples from our dataset including both structured indoor and\noutdoor scenarios, as well as more diversely randomized\nflying objects with various geometries and textures under\ncomplex yet realistic lighting. See the appendix for details.\nIterative Self-Curation. While synthetic data generationFoundation\nStereo\nAmbiguous Stereo Pairs\nFSD\nTraining\nCuration\nFigure 4. Left: Samples from our FoundationStereo dataset (FSD), which consists of synthetic stereo images with structured indoor / outdoor scenes (top),\nas well as more randomized scenes with challenging flying objects and higher geometry and texture diversity (bottom). Right: The iterative self-curation\nprocess removes ambiguous samples inevitably produced from the domain randomized synthetic data generation process. Example ambiguities include\nsevere texture repetition, ubiquitous reflections with limited surrounding context, and pure color under improper lighting.\nin theory can produce unlimited amount of data and achieve\nlarge diversity through randomization, ambiguities can be\ninevitably introduced especially for less structured scenes\nwith flying objects, which confuses the learning process.\nTo eliminate those samples, we design an automatic itera-\ntive self-curation strategy. Fig. 4 demonstrates this process\nand detected ambiguous samples. We start with training an\ninitial version of FoundationStereo on FSD, after which it is\nevaluated on FSD. Samples where BP-2 (Sec. 4.2) is larger\nthan 60% are regarded as ambiguous samples and replaced\nby regenerating new ones. The training and curation pro-\ncesses are alternated to iteratively (twice in our case) update\nboth FSD and FoundationStereo.\n4. Experiments\n4.1. Implementation Details\nWe implement FoundationStereo in PyTorch. The foun-\ndation model is trained on a mixed dataset consisting of\nour proposed FSD, together with Scene Flow [43], Sin-\ntel [6], CREStereo [34], FallingThings [61], InStereo2K [2]\nand Virtual KITTI 2 [7]. We train FoundationStereo using\nAdamW optimizer [39] for 200K steps with a total batch\nsize of 128 evenly distributed over 32 NVIDIA A100 GPUs.\nThe learning rate starts at 1e-4 and decays by 0.1 at 0.8 of\nthe entire training process. Images are randomly cropped\nto 320×736 before feeding to the network. Data augmen-\ntations similar to [36] are performed. During training, 22\niterations are used in GRU updates. In the following, unless\notherwise mentioned, we use the same foundation model for\nzero-shot inference with 32 refinement iterations and 416\nfor maximum disparity.\n4.2. Benchmark Datasets and Metric\nDatasets. We consider five commonly used public datasets\nfor evaluation: Scene Flow [43] is a synthetic dataset\nincluding three subsets: FlyingThings3D, Driving, and\nMonkaa. Middlebury [51] consists of indoor stereo image\npairs with high-quality ground-truth disparity captured via\nstructured light. Unless otherwise mentioned, evaluations\nare performed on half resolution and non-occluded regions.\nETH3D [52] provides grayscale stereo image pairs cover-MethodsMiddlebury ETH3D KITTI-12 KITTI-15\nBP-2 BP-1 D1 D1\nCREStereo++ [27] 14.8 4.4 4.7 5.2\nDSMNet [82] 13.8 6.2 6.2 6.5\nMask-CFNet [49] 13.7 5.7 4.8 5.8\nHVT-RAFT [10] 10.4 3.0 3.7 5.2\nRAFT-Stereo [36] 12.6 3.3 4.7 5.5\nSelective-IGEV [67] 9.2 5.7 4.5 5.6\nIGEV [36] 8.8 4.0 5.2 5.7\nFormer-RAFT-DAM [84] 8.1 3.3 3.9 5.1\nIGEV++ [72] 7.8 4.1 5.1 5.9\nNMRF [22] 7.5 3.8 4.2 5.1\nOurs (Scene Flow) 5.5 1.8 3.2 4.9\nSelective-IGEV* [67] 7.5 3.4 3.2 4.5\nOurs 1.1 0.5 2.3 2.8\nTable 2. Zero-shot generalization results on four public datasets. The most\ncommonly used metrics for each dataset were adopted. In the first block,\nall methods were trained only on Scene Flow. In the second block, meth-\nods are allowed to train on any existing datasets excluding the four target\ndomains. The weights and parameters are fixed for evaluation.\ning both indoor and outdoor scenarios. KITTI 2012 [20]\nand KITTI 2015 [45] datasets feature real-world driving\nscenes, where sparse ground-truth disparity maps are pro-\nvided, which are derived from LIDAR sensors.\nMetrics. “EPE” computes average per-pixel disparity er-\nror. “BP-X” computes the percentage of pixels where the\ndisparity error is larger than X pixels. “D1” computes the\npercentage of pixels whose disparity error is larger than 3\npixels and 5% of the ground-truth disparity.\n4.3. Zero-Shot Generalization Comparison\nBenchmark Evaluation. Tab. 2 exhibits quantitative com-\nparison of zero-shot generalization results on four public\nreal-world datasets. Even when trained solely on Scene\nFlow, our method outperforms the comparison methods\nconsistently across all datasets, thanks to the efficacy of\nadapting rich monocular priors from vision foundation\nmodels. We further evaluate in a more realistic setup, al-\nlowing methods to train on any available dataset while ex-\ncluding the target domain, to achieve optimal zero-shot in-\nference results as required in practical applications.\nIn-the-Wild Generalization. We compare our foundation\nmodel against recent approaches that released their check-\npoints trained on a mixture of datasets, to resemble the prac-\ntical zero-shot application on in-the-wild images. Com-3912 Context-Oriented Feature Fusion and \nEnhancement for Robust Stereo MatchingContributed paper\nFigure 5. Qualitative comparison of zero-shot inference on in-the-wild images. For each comparison method we select the best performing checkpoint from\ntheir public release, which has been trained on a mixture of public datasets. These images exhibit challenging reflection, translucency, repetitive textures,\ncomplex illuminations and thin-structures, revealing the importance of our network architecture and large-scale training.\nMethod LEAStereo [15] GANet [81] ACVNet [70] IGEV-Stereo [71] NMRF [22] MoCha-Stereo [14] Selective-IGEV [67] Ours\nEPE 0.78 0.84 0.48 0.47 0.45 0.41 0.44 0.34\nTable 3. Comparison of methods trained / tested on the Scene Flow train / test sets, respectively.\nMethod Zero-Shot BP-0.5 BP-1.0 EPE\nGMStereo [74] ✗ 5.94 1.83 0.19\nHITNet [56] ✗ 7.83 2.79 0.20\nEAI-Stereo [85] ✗ 5.21 2.31 0.21\nRAFT-Stereo [36] ✗ 7.04 2.44 0.18\nCREStereo [34] ✗ 3.58 0.98 0.13\nIGEV-Stereo [71] ✗ 3.52 1.12 0.14\nCroCo-Stereo [68] ✗ 3.27 0.99 0.14\nMoCha-Stereo [14] ✗ 3.20 1.41 0.13\nSelective-IGEV [67] ✗ 3.06 1.23 0.12\nOurs (finetuned) ✗ 1.26 0.26 0.09\nOurs ✓ 2.31 1.52 0.13\nTable 4. Results on ETH3D leaderboard (test set). All methods except for\nthe last row have used ETH3D training set for fine-tuning. Our fine-tuned\nversion ranks 1st on leaderboard at the time of submission. Last row is\nobtained via zero-shot inference from our foundation model.\nparison methods include CroCo v2 [68], CREStereo [34],\nIGEV [71] and Selective-IGEV [67]. For each method, we\nselect the best performing checkpoint from their public re-\nlease. In this evaluation, the four real-world benchmark\ndatasets [20, 45, 51, 52] have been used for training compar-\nison methods, whereas they are not used in our fixed foun-\ndation model. Fig. 5 displays qualitative comparison on var-\nious scenarios, including a robot scene from DROID [31]\ndataset and custom captures covering indoor and outdoor.\n4.4. In-Domain Comparison\nTab. 3 presents quantitative comparison on Scene Flow,\nwhere all methods are following the same officially divided\ntrain and test split. Our FoundationStereo model outper-\nforms the comparison methods by a large margin, reduc-ing the previous best EPE from 0.41 to 0.33. Although in-\ndomain training is not the focus of this work, the results\nreflect the effectiveness of our model design.\nTab. 4 exhibits quantitative comparison on ETH3D\nleaderboard (test set). For our approach, we perform eval-\nuations in two settings. First, we fine-tune our foundation\nmodel on a mixture of the default training dataset (Sec. 4.1)\nand ETH3D training set for another 50K steps, using the\nsame learning rate schedule and data augmentation. Our\nmodel significantly surpasses the previous best approach by\nreducing more than half of the error rates and ranks 1st\non leaderboard at the time of submission. This indicates\ngreat potential of transferring capability from our founda-\ntion model if in-domain fine-tuning is desired. Second, we\nalso evaluated our foundation model without using any data\nfrom ETH3D. Remarkably, our foundation model’s zero-\nshot inference achieves comparable or even better results\nthan leading approaches that perform in-domain training.\nIn addition, our finetuned model also ranks 1st on the\nMiddlebury leaderboard. See appendix for details.\n4.5. Ablation Study\nWe investigate different design choices for our model\nand dataset. Unless otherwise mentioned, we train on\na randomly subsampled version (100K) of FSD to make\nthe experiment scale more affordable. Given Middlebury\ndataset’s high quality ground-truth, results are evaluated on\nits training set to reflect zero-shot generalization. Since the\nfocus of this work is to build a stereo matching foundationRow Variations BP-2\n1 DINOv2-L [46] 2.46\n2 DepthAnythingV2-S [79] 2.22\n3 DepthAnythingV2-B [79] 2.11\n4 DepthAnythingV2-L [79] 1.97\n5 STA (a) 6.48\n6 STA (b) 2.22\n7 STA (c) 1.97\n8 Unfreeze ViT 3.94\n9 Freeze ViT 1.97\nTable 5. Ablation study of STA module. Variations (a-c) correspond to\nFig. 3. The choices adopted in our full model are highlighted in green.\nRow Variations BP-2 Row Variations BP-2\n1 RoPE 2.19 10 (3,3,1), (1,1,5) 2.10\n2 Cosine 1.97 11 (3,3,1), (1,1,9) 2.06\n3 1/32 2.06 12 (3,3,1), (1,1,13) 2.01\n4 1/16 1.97 13 (3,3,1), (1,1,17) 1.97\n5 Full 2.25 14 (3,3,1), (1,1,21) 1.98\n6 Disparity 1.97 15 (7,7,1), (1,1,17) 1.99\n7 Pre-hourglass 2.06\n8 Post-hourglass 2.20\n9 Parallel 1.97\nTable 6. Ablation study of AHCF module. Left corresponds to DT, while\nright corresponds to APC. The choices adopted in our full model are high-\nlighted in green.\nmodel with strong generalization, we do not deliberately\nlimit model size while pursuing better performance.\nSTA Design Choices. As shown in Tab. 5, we first compare\ndifferent vision foundation models for adapting rich monoc-\nular priors, including different model sizes of DepthAny-\nthingV2 [79] and DINOv2-Large [46]. While DINOv2\npreviously exhibited promising results in correspondence\nmatching [19], it is not as effective as DepthAnythingV2\nin the stereo matching task, possibly due to its less task-\nrelevance and its limited resolution to reason high-precision\npixel-level correspondence. We then study different design\nchoices from Fig. 3. Surprisingly, while being simple, we\nfound (c) significantly surpasses the alternatives. We hy-\npothesize the latest feature before the final output head pre-\nserves high-resolution and fine-grained semantic and geo-\nmetric priors that are suitable for subsequent cost volume\nconstruction and filtering process. We also experimented\nwhether to freeze the adapted ViT model. As expected, un-\nfreezing ViT corrupts the pretrained monocular priors, lead-\ning to degraded performance.\nAHCF Design Choices. As shown in Tab. 6, for DT mod-\nule we study different position embedding (row 1-2); dif-\nferent feature scale to perform transformer (row 3-4); trans-\nformer over the full cost-volume or only along the disparity\ndimension (row 5-6); different placements of DT module\nrelative to the hourglass network (row 7-9). Specifically,\nRoPE [55] encodes relative distances between tokens in-\nstead of absolute positions, making it more adaptive to vary-Row STAAHCF\nBP2Row FSD BP2\nAPC DT 1 ✗ 2.34\n1 2.48 2 ✓ 1.15\n2✓ 2.21\n3✓ ✓ 2.16\n4✓ ✓ 2.05\n5✓✓✓ 1.97\nTable 7. Left: Ablation study of proposed network modules. Right: Ab-\nlation study of whether to use FSD dataset when training the foundation\nmodel described in Sec. 4.1. The choices adopted in our full model are\nhighlighted in green.\ning sequence lengths. However, it does not outperform co-\nsine position embedding, probably due to the constant dis-\nparity size in 4D cost volume. While in theory, full volume\nattention provides larger receptive field, it is less effective\nthan merely applying over the disparity dimension of the\ncost volume. We hypothesize the extremely large space of\n4D cost volume makes it less tractable, whereas attention\nover disparity provides sufficient context for a better initial\ndisparity prediction and subsequent volume feature lookup\nduring GRU updates. Next, we compare different kernel\nsizes in APC (row 10-15), where the last dimension in each\nparenthesis corresponds to disparity dimension. We observe\nincreasing benefits when enlarging disparity kernel size un-\ntil it saturates at around 17.\nEffects of Proposed Modules. The quantitative effects are\nshown in Tab. 7 (left). STA leverages rich monocular pri-\nors which greatly enhances generalization to real images\nfor ambiguous regions. DT and APC effectively aggregate\ncost volume features along spatial and disparity dimensions,\nleading to improved context for disparity initialization and\nsubsequent volume feature look up during GRU updates.\nFig. 3 further visualizes the resulting effects.\nEffects of FoundationStereo Dataset. We study whether\nto include FSD dataset with the existing public datasets for\ntraining our foundation model described in Sec. 4.1. Results\nare shown in Tab. 7 (right).\n5. Conclusion\nWe introduced FoundationStereo, a foundation model for\nstereo depth estimation that achieves strong zero-shot gen-\neralization across various domains without fine-tuning. We\nenvision such a foundation model can facilitate broader\nadoption of stereo estimation models in practical applica-\ntions. Despite its remarkable generalization, it has several\nlimitations. First, our model is not yet optimized for ef-\nficiency, which takes 0.7s on image size of 375 ×1242 on\nNVIDIA A100 GPU. Future work could explore adapting\ndistillation and pruning techniques applied to other vision\nfoundation models [13, 87]. Second, our dataset FSD in-\ncludes a limited collection of transparent objects. Robust-\nness could be further enhanced by augmenting with a larger\ndiversity of fully transparent objects during training.References\n[1] Antyanta Bangunharcana, Jae Won Cho, Seokju Lee, In So\nKweon, Kyung-Soo Kim, and Soohyun Kim. Correlate-and-\nexcite: Real-time stereo matching via guided cost volume\nexcitation. In 2021 IEEE/RSJ International Conference on\nIntelligent Robots and Systems (IROS) , pages 3542–3548.\nIEEE, 2021. 4\n[2] Wei Bao, Wei Wang, Yuhua Xu, Yulan Guo, Siyu Hong, and\nXiaohu Zhang. InStereo2k: a large real dataset for stereo\nmatching in indoor scenes. Science China Information Sci-\nences , 63:1–11, 2020. 2, 6\n[3] Luca Bartolomei, Fabio Tosi, Matteo Poggi, and Stefano\nMattoccia. Stereo anywhere: Robust zero-shot deep stereo\nmatching even where either stereo or mono fail. arXiv\npreprint arXiv:2412.04472 , 2024. 2\n[4] Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter\nWonka, and Matthias Müller. ZoeDepth: Zero-shot trans-\nfer by combining relative and metric depth. arXiv preprint\narXiv:2302.12288 , 2023. 3\n[5] Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain,\nMarcel Santos, Yichao Zhou, Stephan R Richter, and\nVladlen Koltun. Depth Pro: Sharp monocular metric depth in\nless than a second. arXiv preprint arXiv:2410.02073 , 2024.\n3\n[6] Daniel J Butler, Jonas Wulff, Garrett B Stanley, and\nMichael J Black. A naturalistic open source movie for optical\nflow evaluation. In Proceedings of the European Conference\non Computer Vision (ECCV) , pages 611–625, 2012. 2, 3, 6\n[7] Yohann Cabon, Naila Murray, and Martin Humenberger. Vir-\ntual KITTI 2. arXiv preprint arXiv:2001.10773 , 2020. 2, 6\n[8] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou,\nJulien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg-\ning properties in self-supervised vision transformers. In Pro-\nceedings of the IEEE International Conference on Computer\nVision (ICCV) , pages 9650–9660, 2021. 3\n[9] Jia-Ren Chang and Yong-Sheng Chen. Pyramid stereo\nmatching network. In Proceedings of the IEEE/CVF Confer-\nence on Computer Vision and Pattern Recognition (CVPR) ,\npages 5410–5418, 2018. 4\n[10] Tianyu Chang, Xun Yang, Tianzhu Zhang, and Meng Wang.\nDomain generalized stereo matching via hierarchical visual\ntransformation. In Proceedings of the IEEE/CVF Conference\non Computer Vision and Pattern Recognition (CVPR) , pages\n9559–9568, 2023. 1, 2, 6\n[11] Liyan Chen, Weihan Wang, and Philippos Mordohai. Learn-\ning the distribution of errors in stereo matching for joint\ndisparity and uncertainty estimation. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 17235–17244, 2023. 1, 2\n[12] Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong\nLu, Jifeng Dai, and Yu Qiao. Vision transformer adapter for\ndense predictions. ICLR , 2023. 3\n[13] Zigeng Chen, Gongfan Fang, Xinyin Ma, and Xinchao\nWang. 0.1% data makes segment anything slim. NeurIPS ,\n2023. 8\n[14] Ziyang Chen, Wei Long, He Yao, Yongjun Zhang, Bingshu\nWang, Yongbin Qin, and Jia Wu. Mocha-stereo: Motif chan-nel attention network for stereo matching. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 27768–27777, 2024. 1, 2, 7\n[15] Xuelian Cheng, Yiran Zhong, Mehrtash Harandi, Yuchao\nDai, Xiaojun Chang, Hongdong Li, Tom Drummond, and\nZongyuan Ge. Hierarchical neural architecture search for\ndeep stereo matching. Proceedings of Neural Information\nProcessing Systems (NeurIPS) , 33:22158–22169, 2020. 7\n[16] François Chollet. Xception: Deep learning with depthwise\nseparable convolutions. In Proceedings of the IEEE/CVF\nConference on Computer Vision and Pattern Recognition\n(CVPR) , pages 1251–1258, 2017. 5\n[17] WeiQin Chuah, Ruwan Tennakoon, Reza Hoseinnezhad,\nAlireza Bab-Hadiashar, and David Suter. ITSA: An\ninformation-theoretic approach to automatic shortcut avoid-\nance and domain generalization in stereo matching net-\nworks. In Proceedings of the IEEE/CVF Conference on\nComputer Vision and Pattern Recognition (CVPR) , pages\n13022–13032, 2022. 1, 2\n[18] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christo-\npher Ré. FlashAttention: Fast and memory-efficient exact\nattention with io-awareness. Proceedings of Neural Informa-\ntion Processing Systems (NeurIPS) , 35:16344–16359, 2022.\n5\n[19] Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Ab-\nhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun,\nLeonidas Guibas, Justin Johnson, and Varun Jampani. Prob-\ning the 3D awareness of visual foundation models. In Pro-\nceedings of the IEEE/CVF Conference on Computer Vision\nand Pattern Recognition (CVPR) , pages 21795–21806, 2024.\n8\n[20] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we\nready for autonomous driving? the KITTI vision benchmark\nsuite. In Proceedings of the IEEE/CVF Conference on Com-\nputer Vision and Pattern Recognition (CVPR) , pages 3354–\n3361, 2012. 2, 6, 7\n[21] Rui Gong, Weide Liu, Zaiwang Gu, Xulei Yang, and\nJun Cheng. Learning intra-view and cross-view geomet-\nric knowledge for stereo matching. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 20752–20762, 2024. 1, 2\n[22] Tongfan Guan, Chen Wang, and Yun-Hui Liu. Neural\nmarkov random field for stereo matching. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern\nRecognition , pages 5459–5469, 2024. 6, 7, 1\n[23] Weiyu Guo, Zhaoshuo Li, Yongkui Yang, Zheng Wang, Rus-\nsell H Taylor, Mathias Unberath, Alan Yuille, and Yingwei\nLi. Context-enhanced stereo transformer. In Proceedings\nof the European Conference on Computer Vision (ECCV) ,\npages 263–279, 2022. 2\n[24] Xiaoyang Guo, Kai Yang, Wukui Yang, Xiaogang Wang,\nand Hongsheng Li. Group-wise correlation stereo network.\nInProceedings of the IEEE/CVF Conference on Computer\nVision and Pattern Recognition (CVPR) , pages 3273–3282,\n2019. 4\n[25] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.\nDeep residual learning for image recognition. In Proceed-ings of the IEEE/CVF Conference on Computer Vision and\nPattern Recognition (CVPR) , pages 770–778, 2016. 3\n[26] Sergio Izquierdo, Mohamed Sayed, Michael Firman,\nGuillermo Garcia-Hernando, Daniyar Turmukhambetov,\nJavier Civera, Oisin Mac Aodha, Gabriel J. Brostow, and\nJamie Watson. MVSAnywhere: Zero shot multi-view stereo.\nInCVPR , 2025. 3\n[27] Junpeng Jing, Jiankun Li, Pengfei Xiong, Jiangyu Liu,\nShuaicheng Liu, Yichen Guo, Xin Deng, Mai Xu, Lai Jiang,\nand Leonid Sigal. Uncertainty guided adaptive warping for\nrobust and efficient stereo matching. In Proceedings of the\nIEEE International Conference on Computer Vision (ICCV) ,\npages 3318–3327, 2023. 1, 2, 6\n[28] Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia\nNeverova, Andrea Vedaldi, and Christian Rupprecht. Dy-\nnamicStereo: Consistent dynamic depth from stereo videos.\nInProceedings of the IEEE/CVF Conference on Com-\nputer Vision and Pattern Recognition (CVPR) , pages 13229–\n13239, 2023. 2\n[29] Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Met-\nzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurpos-\ning diffusion-based image generators for monocular depth\nestimation. In Proceedings of the IEEE/CVF Conference\non Computer Vision and Pattern Recognition (CVPR) , pages\n9492–9502, 2024. 3\n[30] Alex Kendall, Hayk Martirosyan, Saumitro Dasgupta, Peter\nHenry, Ryan Kennedy, Abraham Bachrach, and Adam Bry.\nEnd-to-end learning of geometry and context for deep stereo\nregression. In Proceedings of the IEEE International Con-\nference on Computer Vision (ICCV) , pages 66–75, 2017. 5\n[31] Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash-\nwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti,\nSoroush Nasiriany, Mohan Kumar Srirama, Lawrence Yun-\nliang Chen, Kirsty Ellis, et al. DROID: A large-scale\nin-the-wild robot manipulation dataset. arXiv preprint\narXiv:2403.12945 , 2024. 7\n[32] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao,\nChloe Rolland, Laura Gustafson, Tete Xiao, Spencer White-\nhead, Alexander C Berg, Wan-Yen Lo, et al. Segment any-\nthing. In Proceedings of the IEEE International Conference\non Computer Vision (ICCV) , pages 4015–4026, 2023. 1, 3\n[33] Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Ground-\ning image matching in 3D with MASt3R. arXiv preprint\narXiv:2406.09756 , 2024. 3\n[34] Jiankun Li, Peisen Wang, Pengfei Xiong, Tao Cai, Ziwei\nYan, Lei Yang, Jiangyu Liu, Haoqiang Fan, and Shuaicheng\nLiu. Practical stereo matching via cascaded recurrent net-\nwork with adaptive correlation. In Proceedings of the\nIEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 16263–16272, 2022. 1, 2, 3, 6,\n7\n[35] Zhaoshuo Li, Xingtong Liu, Nathan Drenkow, Andy Ding,\nFrancis X Creighton, Russell H Taylor, and Mathias Un-\nberath. Revisiting stereo depth estimation from a sequence-\nto-sequence perspective with transformers. In Proceedings\nof the IEEE International Conference on Computer Vision\n(ICCV) , pages 6197–6206, 2021. 1, 2, 5[36] Lahav Lipson, Zachary Teed, and Jia Deng. RAFT-Stereo:\nMultilevel recurrent field transforms for stereo matching. In\nInternational Conference on 3D Vision (3DV) , pages 218–\n227, 2021. 1, 2, 3, 5, 6, 7\n[37] Biyang Liu, Huimin Yu, and Guodong Qi. GraftNet: To-\nwards domain generalized stereo matching with a broad-\nspectrum and task-oriented feature. In Proceedings of the\nIEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 13012–13021, 2022. 1, 2\n[38] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao\nZhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang,\nHang Su, et al. Grounding DINO: Marrying DINO with\ngrounded pre-training for open-set object detection. In Pro-\nceedings of the European Conference on Computer Vision\n(ECCV) , 2024. 3\n[39] I Loshchilov. Decoupled weight decay regularization. ICLR ,\n2019. 6\n[40] Muhammad Maaz, Abdelrahman Shaker, Hisham\nCholakkal, Salman Khan, Syed Waqas Zamir, Rao Muham-\nmad Anwer, and Fahad Shahbaz Khan. EdgeNeXt:\nEfficiently amalgamated cnn-transformer architecture for\nmobile vision applications. In Proceedings of the European\nConference on Computer Vision (ECCV) , pages 3–20, 2022.\n3\n[41] Yamin Mao, Zhihua Liu, Weiming Li, Yuchao Dai, Qiang\nWang, Yun-Tae Kim, and Hong-Seok Lee. UASNet: Un-\ncertainty adaptive sampling network for deep stereo match-\ning. In Proceedings of the IEEE International Conference on\nComputer Vision (ICCV) , pages 6311–6319, 2021. 1, 2\n[42] D. Marr and T. Poggio. Cooperative computation of stereo\ndisparity. Science , 194:283–287, 1976. 1\n[43] Nikolaus Mayer, Eddy Ilg, Philip Hausser, Philipp Fischer,\nDaniel Cremers, Alexey Dosovitskiy, and Thomas Brox. A\nlarge dataset to train convolutional networks for disparity,\noptical flow, and scene flow estimation. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 4040–4048, 2016. 2, 3, 6\n[44] Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Yaroslava Nali-\nvayko, and Andrés Bruhn. Spring: A high-resolution high-\ndetail dataset and benchmark for scene flow, optical flow and\nstereo. In Proc. IEEE/CVF Conference on Computer Vision\nand Pattern Recognition (CVPR) , 2023. 3\n[45] Moritz Menze and Andreas Geiger. Object scene flow for au-\ntonomous vehicles. In Proceedings of the IEEE/CVF Confer-\nence on Computer Vision and Pattern Recognition (CVPR) ,\npages 3061–3070, 2015. 2, 6, 7\n[46] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy\nV o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez,\nDaniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al.\nDINOv2: Learning robust visual features without supervi-\nsion. TMLR , 2024. 1, 3, 8\n[47] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya\nRamesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry,\nAmanda Askell, Pamela Mishkin, Jack Clark, et al. Learn-\ning transferable visual models from natural language super-\nvision. In International Conference on Machine Learning\n(ICML) , pages 8748–8763, 2021. 3[48] Pierluigi Zama Ramirez, Alex Costanzino, Fabio Tosi, Mat-\nteo Poggi, Samuele Salti, Stefano Mattoccia, and Luigi\nDi Stefano. Booster: A benchmark for depth from images\nof specular and transparent surfaces. IEEE Transactions on\nPattern Analysis and Machine Intelligence (PAMI) , 2023. 2,\n1\n[49] Zhibo Rao, Bangshu Xiong, Mingyi He, Yuchao Dai, Renjie\nHe, Zhelun Shen, and Xing Li. Masked representation learn-\ning for domain generalized stereo matching. In Proceedings\nof the IEEE/CVF Conference on Computer Vision and Pat-\ntern Recognition (CVPR) , pages 5435–5444, 2023. 1, 2, 6\n[50] Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang\nHu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman\nRädle, Chloe Rolland, Laura Gustafson, et al. SAM 2:\nSegment anything in images and videos. arXiv preprint\narXiv:2408.00714 , 2024. 3\n[51] Daniel Scharstein, Heiko Hirschmüller, York Kitajima,\nGreg Krathwohl, Nera Neši ´c, Xi Wang, and Porter West-\nling. High-resolution stereo datasets with subpixel-accurate\nground truth. In Pattern Recognition: 36th German Confer-\nence, GCPR 2014, Münster, Germany, September 2-5, 2014,\nProceedings 36 , pages 31–42. Springer, 2014. 2, 6, 7, 1\n[52] Thomas Schops, Johannes L Schonberger, Silvano Galliani,\nTorsten Sattler, Konrad Schindler, Marc Pollefeys, and An-\ndreas Geiger. A multi-view stereo benchmark with high-\nresolution images and multi-camera videos. In Proceedings\nof the IEEE/CVF Conference on Computer Vision and Pat-\ntern Recognition (CVPR) , pages 3260–3269, 2017. 2, 6, 7\n[53] Zhelun Shen, Yuchao Dai, and Zhibo Rao. CFNet: Cascade\nand fused cost volume for robust stereo matching. In Pro-\nceedings of the IEEE/CVF Conference on Computer Vision\nand Pattern Recognition (CVPR) , pages 13906–13915, 2021.\n1, 2\n[54] Zhelun Shen, Yuchao Dai, Xibin Song, Zhibo Rao, Dingfu\nZhou, and Liangjun Zhang. PCW-Net: Pyramid combina-\ntion and warping cost volume for stereo matching. In Pro-\nceedings of the European Conference on Computer Vision\n(ECCV) , pages 280–297, 2022. 1, 2\n[55] Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen\nBo, and Yunfeng Liu. RoFormer: Enhanced transformer with\nrotary position embedding. Neurocomputing , 568:127063,\n2024. 8\n[56] Vladimir Tankovich, Christian Hane, Yinda Zhang, Adarsh\nKowdle, Sean Fanello, and Sofien Bouaziz. HITNet: Hier-\narchical iterative tile refinement network for real-time stereo\nmatching. In Proceedings of the IEEE/CVF Conference on\nComputer Vision and Pattern Recognition (CVPR) , pages\n14362–14372, 2021. 7\n[57] Zachary Teed and Jia Deng. RAFT: Recurrent all-pairs field\ntransforms for optical flow. In Proceedings of the European\nConference on Computer Vision (ECCV) , pages 402–419,\n2020. 2, 5\n[58] Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Woj-\nciech Zaremba, and Pieter Abbeel. Domain randomization\nfor transferring deep neural networks from simulation to the\nreal world. In IEEE/RSJ International Conference on Intel-\nligent Robots and Systems (IROS) , pages 23–30, 2017. 5[59] Fabio Tosi, Yiyi Liao, Carolin Schmitt, and Andreas Geiger.\nSmd-nets: Stereo mixture density networks. In Proceedings\nof the IEEE/CVF conference on computer vision and pattern\nrecognition , pages 8942–8952, 2021. 3\n[60] Fabio Tosi, Filippo Aleotti, Pierluigi Zama Ramirez, Matteo\nPoggi, Samuele Salti, Stefano Mattoccia, and Luigi Di Ste-\nfano. Neural disparity refinement. IEEE Transactions on\nPattern Analysis and Machine Intelligence (PAMI) , 2024. 1,\n2\n[61] Jonathan Tremblay, Thang To, and Stan Birchfield. Falling\nthings: A synthetic dataset for 3d object detection and pose\nestimation. In Proceedings of the IEEE Conference on\nComputer Vision and Pattern Recognition Workshops , pages\n2038–2041, 2018. 2, 3, 6\n[62] Jonathan Tremblay, Thang To, Balakumar Sundaralingam,\nYu Xiang, Dieter Fox, and Stan Birchfield. Deep object pose\nestimation for semantic robotic grasping of household ob-\njects. In Conference on Robot Learning (CoRL) , pages 306–\n316, 2018. 3\n[63] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko-\nreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia\nPolosukhin. Attention is all you need. Advances in Neural\nInformation Processing Systems (NeurIPS) , 30, 2017. 5\n[64] Qiang Wang, Shizhen Zheng, Qingsong Yan, Fei Deng,\nKaiyong Zhao, and Xiaowen Chu. IRS: A large naturalistic\nindoor robotics stereo dataset to train deep models for dis-\nparity and surface normal estimation. In IEEE International\nConference on Multimedia and Expo (ICME) , 2021. 2, 3\n[65] Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris\nChidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D\nvision made easy. In Proceedings of the IEEE/CVF Confer-\nence on Computer Vision and Pattern Recognition (CVPR) ,\npages 20697–20709, 2024. 3\n[66] Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu,\nYuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Se-\nbastian Scherer. TartanAir: A dataset to push the limits of\nvisual slam. In IEEE/RSJ International Conference on Intel-\nligent Robots and Systems (IROS) , pages 4909–4916, 2020.\n2, 3\n[67] Xianqi Wang, Gangwei Xu, Hao Jia, and Xin Yang.\nSelective-Stereo: Adaptive frequency information selection\nfor stereo matching. In Proceedings of the IEEE/CVF\nConference on Computer Vision and Pattern Recognition\n(CVPR) , pages 19701–19710, 2024. 1, 2, 5, 6, 7\n[68] Philippe Weinzaepfel, Thomas Lucas, Vincent Leroy,\nYohann Cabon, Vaibhav Arora, Romain Brégier, Gabriela\nCsurka, Leonid Antsfeld, Boris Chidlovskii, and Jérôme Re-\nvaud. CroCo v2: Improved cross-view completion pre-\ntraining for stereo matching and optical flow. In Proceedings\nof the IEEE International Conference on Computer Vision\n(ICCV) , pages 17969–17980, 2023. 1, 2, 5, 7\n[69] Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield.\nFoundationPose: Unified 6D pose estimation and tracking\nof novel objects. In Proceedings of the IEEE/CVF Confer-\nence on Computer Vision and Pattern Recognition (CVPR) ,\npages 17868–17879, 2024. 3\n[70] Gangwei Xu, Junda Cheng, Peng Guo, and Xin Yang. Atten-\ntion concatenation volume for accurate and efficient stereomatching. In Proceedings of the IEEE/CVF Conference on\nComputer Vision and Pattern Recognition (CVPR) , pages\n12981–12990, 2022. 7\n[71] Gangwei Xu, Xianqi Wang, Xiaohuan Ding, and Xin Yang.\nIterative geometry encoding volume for stereo matching. In\nProceedings of the IEEE/CVF Conference on Computer Vi-\nsion and Pattern Recognition , pages 21919–21928, 2023. 2,\n4, 5, 7\n[72] Gangwei Xu, Xianqi Wang, Zhaoxing Zhang, Junda Cheng,\nChunyuan Liao, and Xin Yang. IGEV++: Iterative multi-\nrange geometry encoding volumes for stereo matching.\narXiv preprint arXiv:2409.00638 , 2024. 2, 6\n[73] Haofei Xu and Juyong Zhang. AANet: Adaptive aggrega-\ntion network for efficient stereo matching. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 1959–1968, 2020. 1, 2\n[74] Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi,\nFisher Yu, Dacheng Tao, and Andreas Geiger. Unifying flow,\nstereo and depth estimation. IEEE Transactions on Pattern\nAnalysis and Machine Intelligence (PAMI) , 2023. 7\n[75] Gengshan Yang, Joshua Manela, Michael Happold, and\nDeva Ramanan. Hierarchical deep stereo matching on high-\nresolution images. In Proceedings of the IEEE/CVF Confer-\nence on Computer Vision and Pattern Recognition (CVPR) ,\npages 5515–5524, 2019. 2\n[76] Guorun Yang, Xiao Song, Chaoqin Huang, Zhidong Deng,\nJianping Shi, and Bolei Zhou. DrivingStereo: A large-scale\ndataset for stereo matching in autonomous driving scenar-\nios. In Proceedings of the IEEE/CVF Conference on Com-\nputer Vision and Pattern Recognition (CVPR) , pages 899–\n908, 2019. 2\n[77] Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing\nWang, and Feng Zheng. Track anything: Segment anything\nmeets videos. arXiv preprint arXiv:2304.11968 , 2023. 3\n[78] Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi\nFeng, and Hengshuang Zhao. Depth anything: Unleashing\nthe power of large-scale unlabeled data. In Proceedings of\nthe IEEE/CVF Conference on Computer Vision and Pattern\nRecognition (CVPR) , pages 10371–10381, 2024. 1, 3\n[79] Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao-\ngang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any-\nthing v2. In Proceedings of Neural Information Processing\nSystems (NeurIPS) , 2024. 1, 2, 3, 4, 8\n[80] Menglong Yang, Fangrui Wu, and Wei Li. WaveletStereo:\nLearning wavelet coefficients of disparity map in stereo\nmatching. In Proceedings of the IEEE/CVF Conference on\nComputer Vision and Pattern Recognition (CVPR) , pages\n12885–12894, 2020. 1, 2\n[81] Feihu Zhang, Victor Prisacariu, Ruigang Yang, and\nPhilip HS Torr. GA-Net: Guided aggregation net for end-\nto-end stereo matching. In Proceedings of the IEEE/CVF\nConference on Computer Vision and Pattern Recognition\n(CVPR) , pages 185–194, 2019. 7\n[82] Feihu Zhang, Xiaojuan Qi, Ruigang Yang, Victor Prisacariu,\nBenjamin Wah, and Philip Torr. Domain-invariant stereo\nmatching networks. In Proceedings of the European Con-\nference on Computer Vision (ECCV) , pages 420–439, 2020.\n1, 2, 6[83] Jeffrey O Zhang, Alexander Sax, Amir Zamir, Leonidas\nGuibas, and Jitendra Malik. Side-tuning: a baseline for net-\nwork adaptation via additive side networks. In Proceedings\nof the European Conference on Computer Vision (ECCV) ,\npages 698–714, 2020. 3\n[84] Yongjian Zhang, Longguang Wang, Kunhong Li, Yun Wang,\nand Yulan Guo. Learning representations from foundation\nmodels for domain generalized stereo matching. In European\nConference on Computer Vision , pages 146–162. Springer,\n2024. 1, 2, 6\n[85] Haoliang Zhao, Huizhou Zhou, Yongjun Zhang, Yong Zhao,\nYitong Yang, and Ting Ouyang. EAI-Stereo: Error aware\niterative network for stereo matching. In Proceedings of the\nAsian Conference on Computer Vision (ACCV) , pages 315–\n332, 2022. 7\n[86] Haoliang Zhao, Huizhou Zhou, Yongjun Zhang, Jie Chen,\nYitong Yang, and Yong Zhao. High-frequency stereo match-\ning network. In Proceedings of the IEEE/CVF Conference\non Computer Vision and Pattern Recognition (CVPR) , pages\n1327–1336, 2023. 1, 2\n[87] Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu,\nMin Li, Ming Tang, and Jinqiao Wang. Fast segment any-\nthing. arXiv preprint arXiv:2306.12156 , 2023. 8FoundationStereo: Zero-Shot Stereo Matching\nSupplementary Material\n6. ETH3D Leaderboard\nAt the time of submission, our fine-tuned model ranks\n1st on the ETH3D leaderboard, significantly outperforming\nboth published and unpublished works. The screenshot is\nshown in Fig. 6.\n7. Middlebury Leaderboard\nAt the time of submission, our fine-tuned model ranks 1st\non the Middlebury leaderboard, significantly outperforming\nboth published and unpublished works. The screenshot is\nshown in Fig. 8.\n8. More Ablation Study on Synthetic Data\nEffects of Self-Curation. We study the effectiveness of\nself-curation pipeline introduced in Sec. 3.5. When dis-\nabling the self-curation while keeping the same data size,\nthe synthetic dataset involves ambiguous samples that con-\nfuse the learning process, leading to slight performance\ndrop when evaluated on Middlebury [51] dataset.\nVariation BP2\nW/ self-curation 1.15\nW/o self-curation 1.27\nTable 8. Effectiveness of self-curation pipeline when generating synthetic\ndata.\nEffects of FSD for Other Methods. Table 2 (main paper)\nindicates benefits by introducing FSD for FoundationStereo\nmodel. To answer the question of whether FSD can benefit\nother methods beyond FoundationStereo, we now train rep-\nresentative works IGEV and Selective-IGEV on FSD and\ncompare with their counterparts trained on Scene Flow. As\nshown in the table below, for both methods, our proposed\nFSD effectively boosts the performance compared to the\ncommonly used Scene Flow dataset.\nMethods Train dataMiddlebury ETH3D KITTI-12 KITTI-15\nBP-2 BP-1 D1 D1\nIGEV Scene Flow 8.8 4.0 5.2 5.7\nIGEV FSD 7.8 3.5 3.2 4.7\nSelective-IGEV Scene Flow 9.2 5.7 4.5 5.6\nSelective-IGEV FSD 7.9 3.5 3.0 4.4\nTable 9. Effects of FSD for other methods.\n9. Results on Translucent Objects\nWe evaluate on Booster [48] (half resolution), which is a\nchallenging dataset consisting of specular and transparentobjects. We compare with the most competitive methods\nfrom Fig. 5 (main paper) in the zero-shot setting. The quan-\ntitative and qualitative results are shown below.\nMethodsHalf\nBP1 BP-2 BP-3 EPE\nSelective-IGEV 23.8 15.0 12.0 6.6\nIGEV 30.8 22.3 19.0 22.7\nOurs 19.0 9.6 6.7 2.2\nIGEV\nSelective-IGEV\n Ours\n10. More Results on Middlebury Dataset\nWe compare with competitive methods that released their\npublic weights in zero-shot on Middlebury, shown in below\ntable. Since NMRF [22] did not report their evaluated Mid-\ndlebury resolution, we rerun their released weights on all\nresolutions. At full resolution, maximum disparity 320 is\nused for FoundationStereo. Across all resolutions, ours sig-\nnificantly outperforms baselines. We also report the peak\nmemory usage and running time averaged across the dataset\non the same hardware, particularly single GPU 3090. On\nhalf and quarter resolutions, our peak memory occurs at\nSTA module. On full resolution, it occurs at DT module.\nDespite the speed limitation which is not the focus when de-\nveloping this work, ours can successfully run on a desktop\nGPU. Pruning or distillation remains an interesting future\nwork to improve speed and memory footprint.\nMethodsFull Half Quarter\nBP-2peak\nmem (G)time (s) BP-2peak\nmem (G)time (s) BP-2peak\nmem (G)time (s)\nSelective-\nIGEV[61]12.9 6.9 2.52 9.2 1.7 0.72 7.0 0.5 0.25\nIGEV[33] 13.1 6.3 2.06 8.8 1.6 0.53 6.4 0.5 0.18\nIGEV++[66] 12.7 13.1 2.12 7.8 3.4 0.50 6.3 0.9 0.15\nNMRF[20] 35.3 8.1 0.95 10.9 1.8 0.20 5.0 0.5 0.05\nOurs 4.8 18.5 8.14 1.1 10.5 2.97 1.3 2.3 0.55\nTable 10. Results on varying resolutions in Middlebury.\n11. More Details of Synthetic Data Generation\nTooling and Assets. The dataset generation is built on\nNVIDIA Omniverse. We use RTX path-tracing with 32\nto 128 samples per pixel for high-fidelity photorealistic\nrendering. The data generation is performed across 48\nNVIDIA A40 GPUs for 10 days. There are more than 5K\nobject assets collected from varying sources including artist\ndesigns and 3D scanning with high-frequency geometry de-\ntails. Object assets are divided into the groups of: furniture,\nopen containers, vehicles, robots, floor tape, free-standing\nwalls, stairs, plants, forklifts, dynamically animated digi-\ntal humans, other obstacles and distractors. Each group isFigure 6. ETH3D leaderboard screenshot. Our fine-tuned foundation model (red box) ranks 1st at the time of submission.\nFigure 7. Examples scene models involving factory, hospital, wood attic, office, grocery store and warehouse. In the third column, we demonstrate an\nexample of metallic material randomization being applied to augment scene diversity. The last column shows comparison of a warehouse between the real\n(bottom) and our simulated digital twin (top) in high fidelity.\ndefined with a separate randomization range for sampling\nlocations, scales and appearances. In addition, we curated\n12 large scene models (Fig. 7), 16 skybox images, more\nthan 150 materials, and 400 textures for tiled wrapping on\nobject geometries for appearance augmentation. These tex-\ntures are obtained from real-world photos and procedurally\ngenerated random patterns.\nCamera Configuration. For each data sample, we first ran-\ndomly sample the stereo baseline camera focal length to di-\nversify the coverage of field-of-views and disparity distri-butions. Next, objects are spawned into the scene in two\ndifferent methods to randomize the scene configuration: 1)\ncamera is spawned in a random pose, and objects are added\nrelative to the camera at random locations; 2) objects are\nspawned near a random location, and the camera is spawned\nnearby and oriented to the center of mass of the object clut-\nter.\nLayout Configuration. We generate layouts in two kinds\nof styles: chaotic and realistic. Such combination of the\nmore realistic structured layouts with the more randomizedIGEV\nSelective-IGEV\n Ours\nFigure 8. Middlebury leaderboard screenshot. Our fine-tuned foundation model (red box) ranks 1st at the time of submission.\n3912 Context-Oriented Feature Fusion and \nEnhancement for Robust Stereo MatchingContributed paper\nFigure 9. Disparity distribution in our proposed FSD.\nsetups with flying objects has been shown to benefit sim-to-\nreal generalization [62]. Specifically, chaotic-style scenes\ninvolve large number of flying distractors and simple scene\nlayouts which consists of infinitely far skybox and a back-\nground plane. The lighting and object appearances (texture\nand material) are highly randomized. The realistic-style\ndata uses indoor and outdoor scene models where the cam-\nera is restricted to locate at predefined areas. Object assets\nare dropped and applied with physical properties for colli-\nsion. The simulation is performed randomly between 0.25to 2 seconds to create physically realistic layouts with no\npenetration, involving both settled and falling objects. Ma-\nterials and scales native to object assets are maintained and\nmore natural lighting is applied. Among the realistic-style\ndata, we further divide the scenes into three types which de-\ntermine what categories of objects are selected to compose\nthe scene for more consistent semantics:\n•Navigation - camera poses are often in parallel to the\nground and objects are often spawned further away. Ob-\njects such as free-standing walls, furniture, and digitalhumans are sampled with higher probability.\n•Driving - camera is often in parallel to the ground above\nthe ground and objects are often spawned further away.\nObjects such as vehicles, digital humans, poles, signs and\nspeed bumps are sampled with higher probability.\n•Manipulation - camera is oriented to face front or down-\nward as in ego-centric views and objects are often\nspawned in closer range to resemble interaction scenar-\nios. Objects such as household or grocery items, open\ncontainers, robotic arms are sampled with higher proba-\nbility.\nLighting Configuration. Light types include global illu-\nmination, directed sky rays, lights baked-into 3D scanned\nassets, and light spheres which add dynamic lighting when\nspawned near to surfaces. Light colors, intensities and di-\nrections are randomized. Lighting vibes such as daytime,\ndusk and night are included within the random sampling\nranges.\nDisparity Distribution. Fig. 9 shows the disparity distribu-\ntion of our FSD dataset.\n12. Acknowledgement\nWe would like to thank Gordon Grigor, Jack Zhang, Xu-\ntong Ren, Karsten Patzwaldt, Hammad Mazhar and other\nNVIDIA Isaac team members for their tremendous engi-\nneering support and valuable discussions.",
"publish_date": "2025-04-07",
"insert_date": "2026-01-14 11:06:50"
}]
4.2 mongodb_server.py
构建 MCP Server :使 LLM 可以访问 MongoDB 数据库结构和数据,允许 LLM 获取并选择 Collections,获取论文的关键词和分类,并根据 id 获取论文的完整内容。
import json
from mcp.server.fastmcp import FastMCP
import os
from pymongo import MongoClient
from bson.objectid import ObjectId
MONGO_URI = os.getenv("MONGO_URI", "mongodb://localhost:27017/")
SERVER_PORT = 9002
mcp = FastMCP("MongoDB", port=SERVER_PORT)
@mcp.tool()
def get_db_collections(db_name: str) -> str:
"""
输入数据库名称,返回该数据库中的所有集合名称
:param db_name: 数据库名称
:return: 包含数据库名和集合列表的JSON对象
"""
client = MongoClient(MONGO_URI)
db = client[db_name]
collections = db.list_collection_names()
# 构建返回结果为指定格式
result = {
"db_name": db_name,
"collections": collections
}
# 返回JSON格式字符串
return json.dumps(result, ensure_ascii=False)
@mcp.tool()
def get_essays_metadata_from_collection(db_name: str, collection_name: str) -> list[dict]:
"""
输入数据库名称和集合名称,返回该集合中的所有论文元数据
:param db_name: 数据库名称
:param collection_name: 集合名称
"""
client = MongoClient(MONGO_URI)
db = client[db_name]
collection = db[collection_name]
# 获取所有论文元数据:_id, title, authors, categories, keywrods, publish_date, 并根据publish_date降序排序
essays_metadata = list(collection.find({}, {"_id": 1, "title": 1, "authors": 1, "categories": 1, "keywords": 1, "publish_date": 1}).sort("publish_date", -1))
# Convert ObjectId to string for JSON serialization
for essay in essays_metadata:
essay['_id'] = str(essay['_id'])
return essays_metadata
@mcp.tool()
def get_essay_content_from_id(db_name: str, collection_name: str, essay_id: str) -> str:
"""
输入数据库名称、集合名称和论文ID,返回该论文的完整内容
:param db_name: 数据库名称
:param collection_name: 集合名称
:param essay_id: 论文ID
"""
client = MongoClient(MONGO_URI)
db = client[db_name]
collection = db[collection_name]
essay = collection.find_one({"_id": ObjectId(essay_id)}, {"_id": 0, "content": 1})
return essay["content"]
if __name__ == "__main__":
mcp.run(transport="sse")
运行mongodb_server.py
# 运行 9002 sse
uv run mongodb_server.py

启动之后也可以使用 MCP Inspector 进行验证server中的tool是否正常,这里不再验证。
4.3 mongdb_client.py
注意:这里使用了qwq模型,因为qwen3:8b会超时。os.getenv(“OLLAMA_MODEL”, “qwq”)
import asyncio
import os
import sys
import json
from typing import Optional
from contextlib import AsyncExitStack
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession
from mcp.client.sse import sse_client
class MCPClient:
def __init__(self):
"""初始化MCP客户端"""
load_dotenv()
self.exit_stack = AsyncExitStack()
# Ollama 的 OpenAI 兼容端点
base_url = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434/v1")
# 修改为 OpenAI 兼容的基础 URL
if "/api/generate" in base_url:
base_url = base_url.replace("/api/generate", "")
self.model = os.getenv("OLLAMA_MODEL", "qwq")
# 初始化 OpenAI 客户端
self.client = OpenAI(
base_url=base_url,
api_key="ollama" # Ollama 不需要真正的 API 密钥,但 OpenAI 客户端需要一个非空值
)
self.session: Optional[ClientSession] = None
# MongoDB 服务器配置
self.mongo_server_url = os.getenv("MONGO_SERVER_URL", "http://localhost:9002/sse")
async def connect_to_server(self):
"""连接到MongoDB服务器"""
try:
print(f"正在尝试连接到MongoDB服务器: {self.mongo_server_url}")
# 使用sse_client连接到服务器
self._streams_context = sse_client(url=self.mongo_server_url)
streams = await self._streams_context.__aenter__()
self._session_context = ClientSession(*streams)
self.session: ClientSession = await self._session_context.__aenter__()
print("session创建完成 - 开始初始化")
await self.session.initialize()
print("session初始化完成")
print(f"成功连接到MongoDB服务器: {self.mongo_server_url}")
except Exception as e:
print(f"连接服务器失败: {e}")
import traceback
traceback.print_exc()
raise
async def process_query(self, query: str) -> str:
"""使用 OpenAI 客户端调用 Ollama API 处理用户查询,支持多轮调用MCP工具"""
# 初始化对话历史
messages = [{"role": "user", "content": query}]
# 获取可用工具
print("开始获取可用工具")
response = await self.session.list_tools()
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
}
} for tool in response.tools]
print(f"可用工具: {available_tools}")
# 添加系统消息,指导大模型如何使用工具和决定何时停止
system_message = {
"role": "system",
"content": """你是一个智能助手,能够调用外部工具来回答用户的问题。
本地的MongoDB存储了大量的学术论文,请根据用户的问题,调用工具来获取相关信息。
目前数据库名称为: essay_database
你必须按照以下固定步骤处理用户查询:
1. 获取数据库中所有collections (使用get_db_collections工具)
2. 选择步骤1返回的、相关的collections,并获取这些collections中的所有论文的metadata (使用get_essays_metadata_from_collection工具)
3. 从步骤2中所有的metadata里,选择相关的论文,并获取完整论文内容 (使用get_essay_content_from_id工具)
4. 根据步骤3中获取的论文内容,回答用户问题
注意事项:
- 不要跳过任何步骤,必须按顺序执行上述4个步骤
- 确保在每个步骤中记录和分析获取到的信息
- 执行每一个步骤时,都需要根据上一个步骤的返回结果,来决定下一步的执行
- 在选择collections和论文时,要基于用户问题的相关性进行选择
- 如果步骤1发现没有collections,告知用户数据库可能为空
- 如果步骤2发现没有metadata,尝试其他collections或告知用户没有找到相关论文
- 如果用户提问不明确,可以基于获取到的信息进行合理推断
请确保你的最终回答全面、准确,并明确指出是基于哪些论文内容得出的结论。
"""
}
messages.insert(0, system_message)
# 多轮调用工具,直到大模型决定停止
max_tool_calls = 5 # 设置最大工具调用次数,防止无限循环
for i in range(max_tool_calls):
try:
# 发送请求给大模型
print(f"第 {i+1} 轮与大模型对话")
response = await asyncio.to_thread(
lambda: self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=available_tools
)
)
# 处理模型响应
content = response.choices[0]
# 如果模型决定使用工具
if content.finish_reason == "tool_calls" and content.message.tool_calls:
# 添加模型决定使用工具的消息到对话历史
messages.append(content.message.model_dump())
# 处理所有工具调用
for tool_call in content.message.tool_calls:
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
print(f"调用工具: {tool_name},参数: {tool_args}")
# 执行工具调用
result = await self.session.call_tool(tool_name, tool_args)
print(f"工具返回结果: {result}")
# 将工具执行结果添加到对话历史
messages.append({
"role": "tool",
"content": result.content[0].text,
"tool_call_id": tool_call.id
})
else:
# 模型决定不再使用工具,直接给出最终回答
print("大模型决定不再调用工具,给出最终回答")
return content.message.content
except Exception as e:
import traceback
# 收集详细错误信息
error_details = {
"异常类型": type(e).__name__,
"异常消息": str(e),
"请求URL": self.client.base_url,
"请求模型": self.model,
"请求内容": query[:100] + "..." if len(query) > 100 else query
}
print(f"API调用失败:详细信息如下:")
for key, value in error_details.items():
print(f" {key}: {value}")
print("\n调用堆栈:")
traceback.print_exc()
return "抱歉,发生未知错误,我暂时无法回答这个问题。"
# 如果达到最大工具调用次数仍未得到最终答案,让模型给出最终总结
print("达到最大工具调用次数,请求模型给出最终回答")
final_prompt = {
"role": "user",
"content": "你已经进行了多次工具调用。基于目前收集到的所有信息,请给出最终的完整回答。"
}
messages.append(final_prompt)
try:
final_response = self.client.chat.completions.create(
model=self.model,
messages=messages
)
return final_response.choices[0].message.content
except Exception as e:
print(f"获取最终回答时出错: {e}")
return "抱歉,在整理最终答案时发生错误。基于已收集的信息,我无法给出完整回答。"
async def chat_loop(self):
"""交互式聊天循环"""
print("\n欢迎使用MCP客户端!输入 'quit' 退出")
while True:
try:
query = input("\n你: ").strip()
if query.lower() == 'quit':
print("再见!")
break
response = await self.process_query(query)
print(f"\nOllama: {response}")
except Exception as e:
print(f"\n发生错误:{e}")
async def cleanup(self):
"""清理资源"""
await self.exit_stack.aclose()
async def main():
client = MCPClient()
try:
# 连接MongoDB服务器
await client.connect_to_server()
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
运行mongdb_client.py
# SmolVLM有哪些技术优势
# 根据电脑性能,可能要运行很久
uv run mongdb_client.py
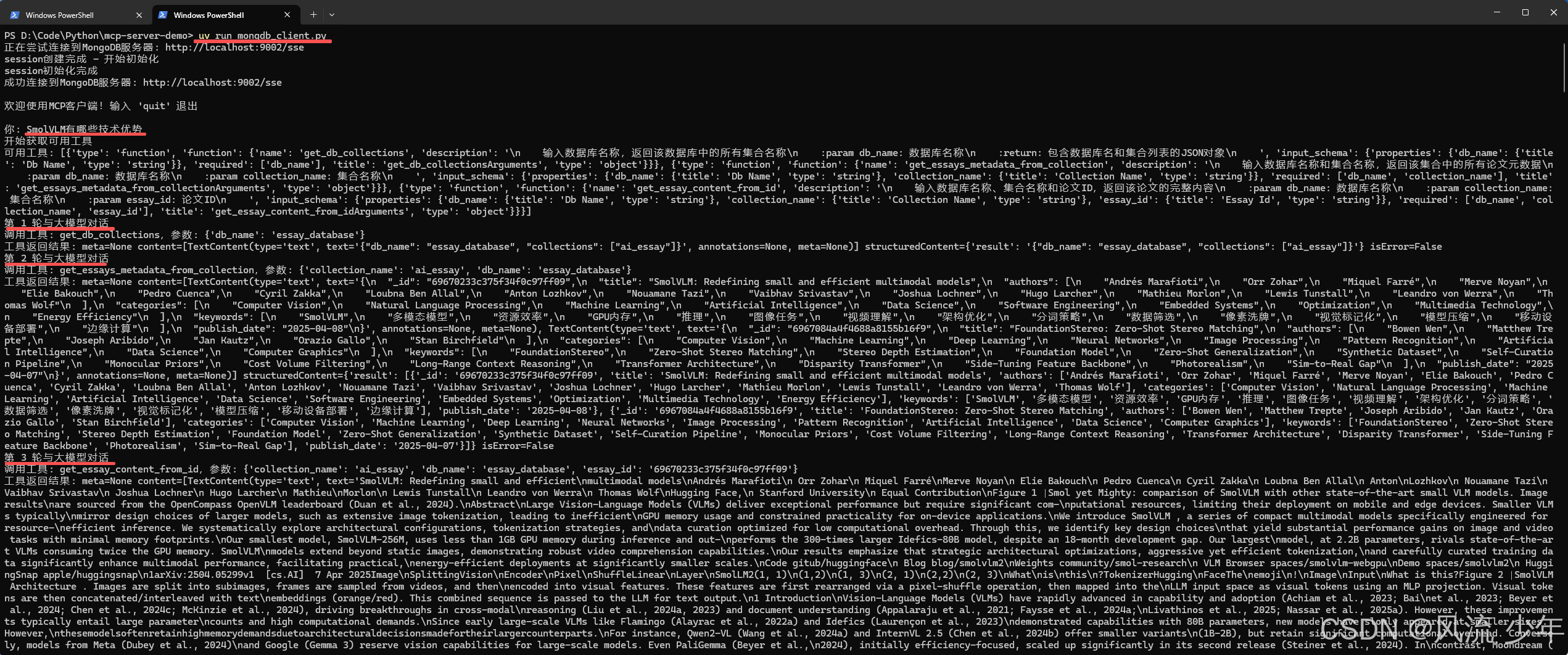
至此:两个案例都成功实现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)