AI基石 | 机器学习基础(一):经典算法三巨头 —— 逻辑回归、决策树与 SVM 的“华山论剑”
机器学习经典算法:逻辑回归、SVM、决策树详解与对比。
AI基石 | 机器学习基础(一):经典算法三巨头 —— 逻辑回归、决策树与 SVM 的“华山论剑”
前言
欢迎来到“AI 自学路线”的各种实战篇!
在此之前,你手里拿着数学原理(内功)和 PyTorch(重武器),但可能还不知道怎么解决一个具体的分类问题。
- “怎么判断这封邮件是不是垃圾邮件?”
- “怎么预测这个肿瘤是良性还是恶性?”
- “明天到底是晴天还是雨天?”
在深度学习(Deep Learning)统治世界之前,有三位“老前辈”统治了 AI 领域几十年。它们是:逻辑回归(Logistic Regression)、支持向量机(SVM) 和 决策树(Decision Tree)。它们虽然没有亿级参数,但胜在解释性强、对小数据友好。
但学会了算法就够了吗?绝对不够。 如果你训练了一个癌症预测模型,准确率高达 99%,它可能依然是个垃圾模型(为什么?后面揭晓)。
今天,我们将算法原理与评估指标一网打尽,教你如何训练模型,更教你如何看穿模型的谎言。我们将使用机器学习界的“瑞士军刀” —— Scikit-Learn (sklearn)。
一、 逻辑回归 (Logistic Regression):最名不副实的“分类王”
名字误区:虽然它叫“回归”,但它实际上是用来做分类的(比如:是/否,0/1)。它是神经网络中每一个“神经元”的雏形。
生活案例: 想象你在向银行申请贷款。银行会根据你的工资、存款、负债算出一个分数(比如 750 分)。线性回归只能算出这个分数,但银行最终的决定只有两个:“批” 或 “不批”。
1. 核心思想:概率的边界
线性回归(y=wx+b)算出来的是一个具体的数字(比如 100, -50)。但分类问题需要的是一个概率(0 到 1 之间)。
怎么把 (−∞,+∞) 的数字压缩到 (0,1) 之间? 这就用到了 AI 领域最性感的曲线 —— Sigmoid 函数。
P(y=1∣x)=11+e−(wx+b) P(y=1|x) = \frac{1}{1 + e^{-(wx+b)}} P(y=1∣x)=1+e−(wx+b)1
- 如果算出来 >0.5,就说是“正类”(比如是猫)。
- 如果算出来 <0.5,就说是“负类”(比如不是猫)。
2. Sklearn 实战
用 sklearn 写代码,简单到让你怀疑人生。
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# --- 数据准备 ---
# 1.生成模拟数据: 1000个样本, 2个特征(比如存款和工资)
# random_state=42 就像游戏的“存档”,保证每次运行生成的随机数都一样
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# --- 模型训练 ---
# 2. 初始化模型
# solver='lbfgs' 是具体的优化算法,类似我们讲过的“梯度下降”的高级版
model = LogisticRegression(solver='lbfgs')
# 3. 训练 (Fit) —就是“学习”的过程:不断调整内部的 w 和 b,直到误差最小
model.fit(X_train, y_train)
# 4. 预测与评估
accuracy = model.score(X_test, y_test)
print(f"逻辑回归准确率: {accuracy:.2f}")
# 逻辑回归准确率: 0.87
# 看一眼学到的参数 (w 和 b)
print(f"权重(w): {model.coef_}, 偏置(b): {model.intercept_}")
# 权重(w): [[-0.28793054 2.11148658]], 偏置(b): [0.25972796]
二、 支持向量机 (SVM):寻找“最宽的街道”
如果说逻辑回归是“差不多就行”,那么 SVM (Support Vector Machine) 就是完美主义者。
1. 核心思想:最大间隔 (Max Margin)
想象桌子上放着红球和蓝球,你要拿一根棍子把它们分开。
- 逻辑回归:只要分开了就行,棍子哪怕贴着红球也没关系。
- SVM:不仅要分开,而且棍子要放在正中间,离红球和蓝球都越远越好。这叫 “最大化间隔”。
这根棍子,就叫超平面 (Hyperplane)。离棍子最近的那些球,就叫支持向量 (Support Vectors)。
2. 进阶魔法:核函数 (Kernel Trick)
如果红球在中间,蓝球围在四周(线性不可分),一根直棍子分不开怎么办? SVM 有一招必杀技:升维打击。 它能通过“核函数”把数据投射到高维空间,让原本纠缠在一起的数据变得泾渭分明。这就好比你在二维纸上画不出圈住蚂蚁的直线,但你可以把纸提起来,让蚂蚁掉下去。
3. Sklearn 实战
from sklearn.svm import SVC # SVC = Support Vector Classification
# --- 实践解密:关键参数 C 和 Kernel ---
# kernel='rbf': 径向基核函数,专门处理非线性数据(那招“拍桌子”的魔法)
# C=1.0: "容忍度"。
# - C 很大:老师很严厉,决不允许分错一个点(容易过拟合)。
# - C 很小:老师很佛系,允许为了街道更宽而牺牲一点准确率(泛化能力强)。
svm_model = SVC(kernel='rbf', C=1.0)
svm_model.fit(X_train, y_train)
print(f"SVM 准确率: {svm_model.score(X_test, y_test):.2f}")
# SVM 准确率: 0.89
三、 决策树 (Decision Tree):像人类一样思考
前两个算法都是纯数学计算,而决策树是最符合人类直觉逻辑的算法。它就是一堆 if-else 规则的集合。
- 生活案例:猜人名游戏(Akinator) 你要猜我心里想的是谁。
- 为了最快猜中,你会问:“是男是女?”(一下子排除一半人)。
绝不会先问:“他是不是叫特朗普?”(效率太低)。
1. 核心思想:切蛋糕
决策树的学习过程,就是不断地问问题,把数据切得越来越纯。
- 问题 1:“这人是男是女?” -> 分成两堆。
- 问题 2:“收入是否大于 1万?” -> 再细分。
怎么决定先问哪个问题? 这涉及到一个概率概念:信息熵 (Entropy) 或 基尼系数 (Gini)。 简单说:如果一个问题问完后,混杂的数据变得最干净(比如一堆全是红球,另一堆全是蓝球),那这就是个好问题。
2. Sklearn 实战
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# --- 实践解密:max_depth 的作用 ---
# max_depth=3: 限制树只能长 3 层。
# 如果不限制,树会一直长到把每个叶子节点都分得干干净净,
# 这就像学生死记硬背答案,遇到新题就挂了(过拟合)。
tree_model = DecisionTreeClassifier(max_depth=3)
tree_model.fit(X_train, y_train)
print(f"决策树准确率: {tree_model.score(X_test, y_test):.2f}")
# 决策树准确率: 0.88
# 可视化这棵树 (看看它是怎么做判断的)
plt.figure(figsize=(10, 6))
plot_tree(tree_model, filled=True, feature_names=['Feature1', 'Feature2'])
plt.show()
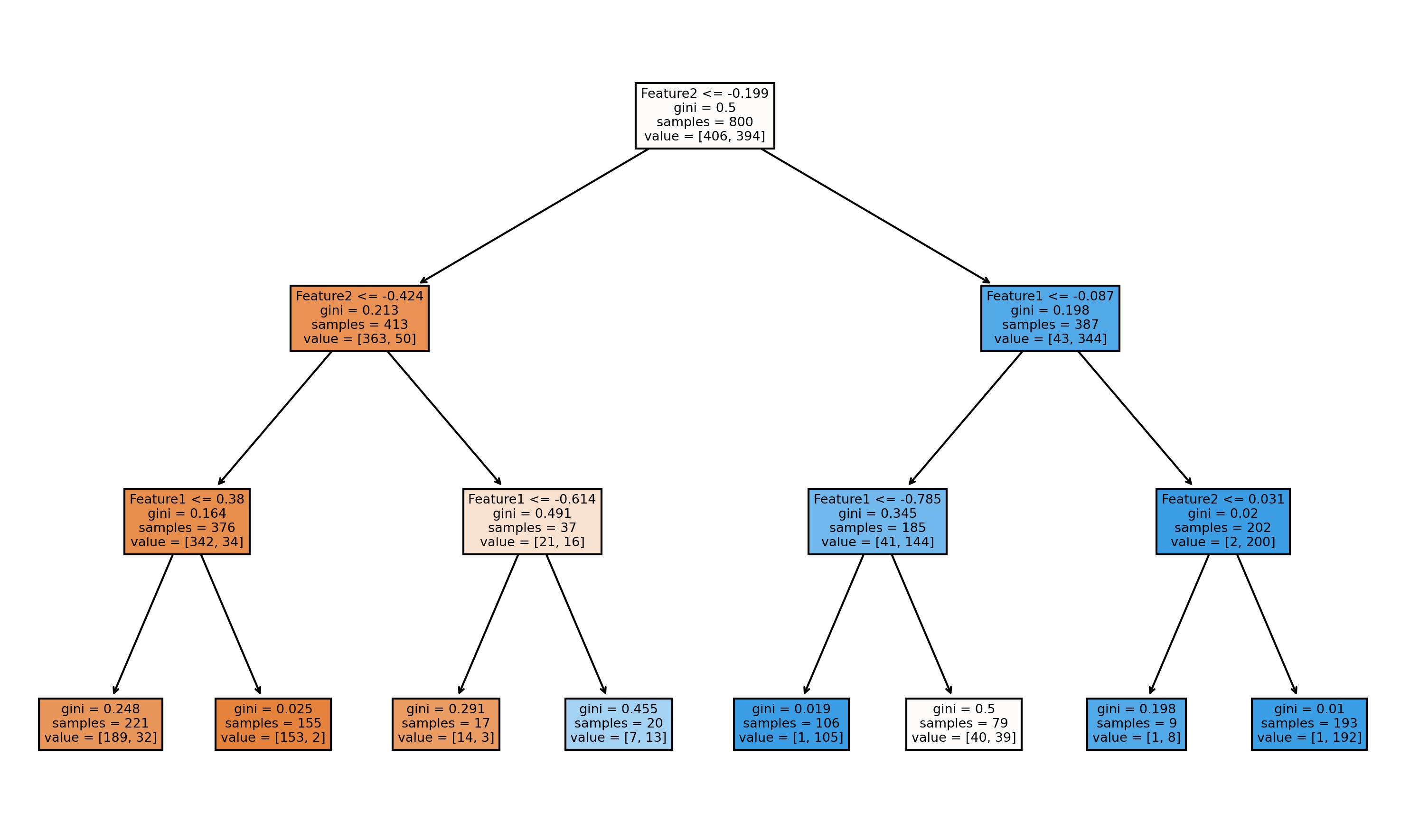
四、 三大门派的对比:该选谁?
面试中常考题:遇到一个新任务,我该用哪个模型?
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 逻辑回归 (LR) | 简单、快、可解释性强(能看到权重) | 处理非线性能力差 | 推荐系统基线、金融风控 |
| SVM | 数学理论完美,适合高维数据,小样本表现好 | 数据量大时太慢,训练费内存 | 文本分类、复杂的中小数据集 |
| 决策树 | 也就是 if-else,完全白盒,不需要数据归一化 | 极其容易过拟合(死记硬背) | 需要解释规则的业务(如医疗诊断) |
五、 结语:从 Sklearn 走向深度学习
你会发现,使用 sklearn 训练模型,代码格式惊人的一致:
model = Model()model.fit(X, y)model.predict(X)
这正是 Sklearn 的伟大之处,它统一了机器学习的接口。
学完这一篇,你已经掌握了传统机器学习的半壁江山。但你可能也发现了:这些算法在处理简单的表格数据时很强,但如果面对图片、语音、长文本,它们就力不从心了。
这时候,就需要逻辑回归的“超级进化体” —— 神经网络 出场了。
下一篇预告: 模型训练好了,怎么知道它好不好?只是看准确率吗? 《机器学习基础(二):不以成败论英雄 —— 准确率、F1 分数与 ROC/AUC,谁才是真正的评判标准?》
📚 学习资源与作业
- 作业:去 Kaggle 上找著名的 “Titanic”(泰坦尼克号生存预测)比赛。分别用逻辑回归和决策树跑一下,看看谁的分数高?
- 资源:Scikit-Learn 官方文档(它的 User Guide 写得比教科书还清楚)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)