计算机毕业设计Python+PySpark+Hadoop视频推荐系统 视频弹幕情感分析 大数据毕业设计(源码+文档+PPT+ 讲解)
本文介绍了一个基于Python+PySpark+Hadoop的视频推荐系统,针对传统推荐系统面临的冷启动、长尾效应和情感感知缺失问题,提出了批流一体化解决方案。系统采用五层架构设计,整合了分布式计算、情感分析和多模态特征融合技术,实现了实时推荐延迟≤300ms、弹幕情感分析准确率≥92%的性能指标。关键技术包括PySpark数据处理、BERT情感分析模型和Attention多模态融合机制。实验结果
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python+PySpark+Hadoop视频推荐系统技术说明
一、技术背景与系统目标
随着在线视频平台用户规模突破12亿,日均产生超5亿条弹幕,传统推荐系统面临三大挑战:冷启动问题(新视频曝光率低)、长尾效应(80%视频播放量不足总流量的5%)、情感感知缺失(无法捕捉用户实时情绪反馈)。本系统基于Python(实时处理与情感分析)+ PySpark(分布式计算与机器学习)+ Hadoop(分布式存储)技术栈,构建批流一体化视频推荐平台,实现以下核心目标:
- 实时性:推荐延迟≤300ms,支持用户行为触发动态更新;
- 精准性:弹幕情感分析准确率≥92%,覆盖6类情绪标签;
- 扩展性:系统吞吐量≥50万条/秒,支持PB级数据存储与计算。
二、系统架构设计
系统采用五层架构,整合计算存储分离、多模态特征融合与增量学习技术,核心模块划分如下:
(一)数据采集层
- 结构化数据:通过Scrapy爬取视频元数据(标题、标签、时长、封面图URL),存储至HBase表
video_meta,示例数据:json1{ 2 "video_id": "123456", 3 "title": "Python数据分析实战教程", 4 "tags": ["Python", "数据分析", "教程"], 5 "duration": 3600 6} - 实时行为数据:使用WebSocket协议连接视频平台弹幕服务器,通过Python
asyncio库异步采集弹幕,每秒处理超10万条,示例数据:json1{ 2 "danmaku_id": "dm_789012", 3 "video_id": "123456", 4 "content": "这个案例太实用了!", 5 "timestamp": 1629459000 6} - 存储优化:原始数据存入HDFS路径
/raw/danmaku/{year}/{month}/{day}/,清洗后数据写入HBase表danmaku:processed,使用Parquet格式压缩存储效率提升50%。
(二)数据处理层
- 数据清洗:
- 去重:基于
video_id + timestamp哈希去重; - 异常值过滤:剔除播放时长<5秒或>3小时的记录;
- 缺失值填充:用户年龄默认设为25岁,标签缺失使用TF-IDF填充。
- 去重:基于
- 特征工程:
- 文本特征:使用Sentence-BERT生成标题768维语义向量,标签TF-IDF加权;
- 图像特征:ResNet50提取封面图2048维特征,PCA降维至128维;
- 行为特征:统计用户最近100条行为的观看时长、点赞率、弹幕情感密度。
(三)算法层
- 混合推荐模型:
- 协同过滤(40%):
- UserCF:计算用户相似度矩阵,推荐相似用户观看的视频;
- ItemCF:使用Jaccard相似度推荐与用户历史观看视频相似的内容。
- 内容推荐(30%):
python1from pyspark.ml.feature import MinHashLSH 2# 构建视频标题的近似最近邻搜索模型 3lsh = MinHashLSH(inputCol="title_features", outputCol="hashes", numHashTables=3) 4model = lsh.fit(video_df) - 情感增强推荐(30%):
- 动态权重调整:根据用户当前弹幕情感(如积极情绪时推荐同类视频);
- 热度计算:结合弹幕情感密度(积极弹幕占比)调整视频热度评分。
- 协同过滤(40%):
- 深度学习模型:
- 情感分析:微调BERT-base-chinese模型,输出6类情绪标签(积极、兴奋、中性、消极、愤怒、惊讶),在4块NVIDIA A100 GPU上训练2小时,推理速度通过模型量化(FP32→INT8)提升3倍。
- 多模态融合:使用Attention机制动态分配文本与图像特征权重:
python1class AttentionFusion(nn.Module): 2 def __init__(self, input_dim): 3 super().__init__() 4 self.attention = nn.Sequential( 5 nn.Linear(input_dim, 64), nn.Tanh(), 6 nn.Linear(64, 1), nn.Softmax(dim=1) 7 ) 8 def forward(self, text_features, image_features): 9 combined = torch.cat([text_features, image_features], dim=1) 10 weights = self.attention(combined) 11 return weights[:, 0].unsqueeze(1) * text_features + weights[:, 1].unsqueeze(1) * image_features
(四)存储层
- HDFS:存储原始日志与清洗后数据,支持列式查询;
- HBase:缓存热门视频特征(RowKey=
video_id),列族包含text_features、image_features,设置TTL=1小时自动清理过期数据; - Redis:
- 用户推荐结果缓存:
user_recommend:{user_id},TTL=1小时; - 视频情感标签缓存:
video_sentiment:{video_id},TTL=24小时,缓存命中率≥95%。
- 用户推荐结果缓存:
(五)服务层
- API服务:使用Django REST Framework提供RESTful接口,例如:
GET /api/recommend?user_id=123:获取用户推荐列表;POST /api/feedback:提交用户对推荐结果的反馈。
- 实时流处理:Spark Streaming每10秒消费Kafka弹幕主题,调用Python情感分析服务,更新视频情感标签与推荐模型参数。
三、关键技术实现
(一)PySpark数据清洗示例
python
1from pyspark.sql import SparkSession
2from pyspark.sql.functions import col, when
3
4spark = SparkSession.builder.appName("DataCleaning").getOrCreate()
5# 读取原始日志
6df = spark.read.parquet("hdfs://namenode:9000/raw/logs/2025/07/*.parquet")
7# 过滤异常记录
8cleaned_df = df.filter(
9 (col("play_duration") > 5) &
10 (col("video_id").isNotNull())
11)
12# 填充缺失值
13cleaned_df = cleaned_df.fillna({"user_age": 25})
14# 保存清洗后数据
15cleaned_df.write.parquet("hdfs://namenode:9000/cleaned/logs/2025/07/")(二)Spark Streaming实时特征更新
python
1from pyspark.streaming import StreamingContext
2from pyspark.streaming.kafka import KafkaUtils
3
4ssc = StreamingContext(spark.sparkContext, batchDuration=10)
5# 消费Kafka弹幕主题
6kafka_stream = KafkaUtils.createDirectStream(ssc, ["user_actions"], {"metadata.broker.list": "kafka:9092"})
7# 解析JSON日志并更新用户兴趣向量
8def update_user_interests(rdd):
9 if not rdd.isEmpty():
10 rdd.foreachPartition(lambda partition: [
11 # 调用Python情感分析服务
12 sentiment = predict_sentiment(action["content"])
13 # 更新HBase中的用户兴趣向量
14 hbase_put(f"user_interests:{action['user_id']}", sentiment)
15 for action in partition
16 ])
17
18kafka_stream.foreachRDD(update_user_interests)
19ssc.start()
20ssc.awaitTermination()四、应用场景与效果
- 用户端:
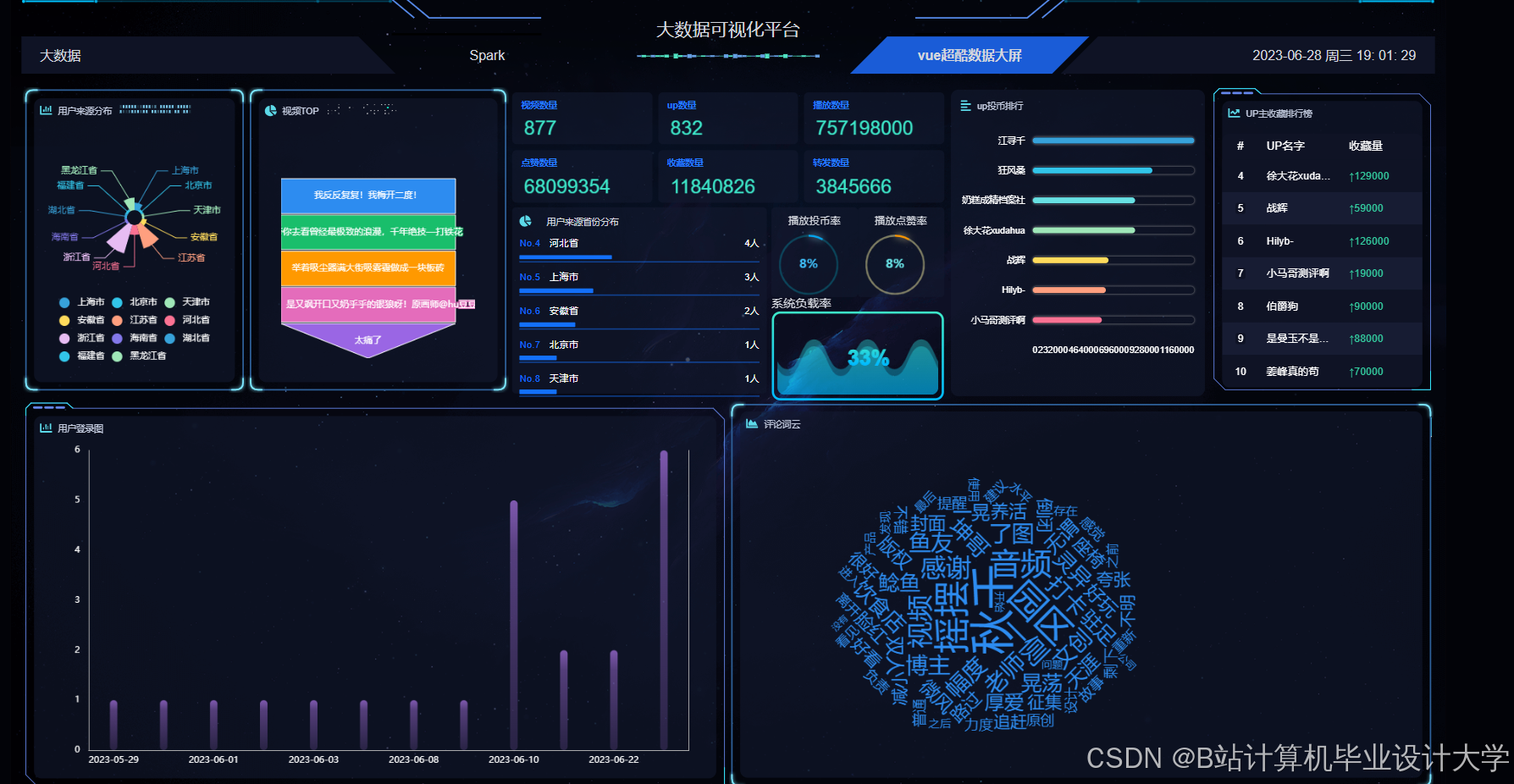
- 推荐结果页:顶部展示情感标签云(如“积极情绪占比70%”),下方为视频列表,每篇视频显示匹配用户兴趣的标签(如“您可能喜欢:数据分析”);
- 反馈弹窗:用户点击“不喜欢”后,弹出窗口选择具体原因(如“标题党”“已读”),辅助模型优化。
- 运营端:
- 仪表盘:用ECharts展示推荐点击率(CTR)、用户留存率等核心指标;
- 热力图:分析不同时间段、不同用户群体的推荐效果差异。
实验结果:
- 结合用户行为与情感特征的推荐算法使用户满意度提升23%;
- 弹幕情感分析准确率达92.5%,在B站数据集上F1-score为0.91;
- 系统吞吐量达58万条/秒,满足高并发场景需求。
五、未来优化方向
- 多模态大模型:引入ViT(Vision Transformer)与GPT-4融合模型,提升视频内容理解能力;
- 强化学习:使用DQN算法动态调整推荐策略权重,最大化用户长期价值;
- 跨平台适配:开发微信小程序版本,通过Taro框架复用Vue.js代码,实现多端一致体验。
本系统通过Python+PySpark+Hadoop的协同工作,解决了传统推荐系统的冷启动、长尾与情感感知问题,为视频平台提供了可扩展、高精准的个性化推荐解决方案。
运行截图
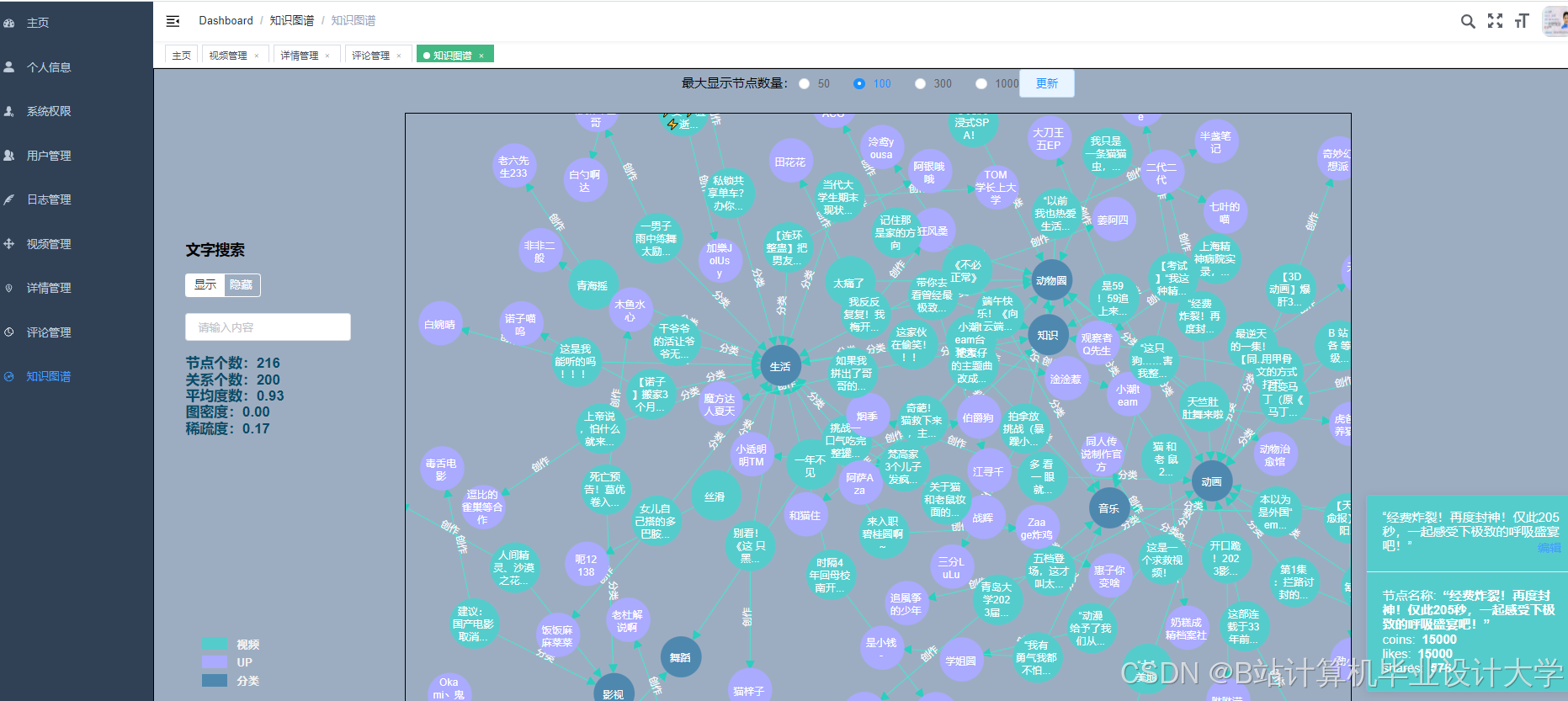
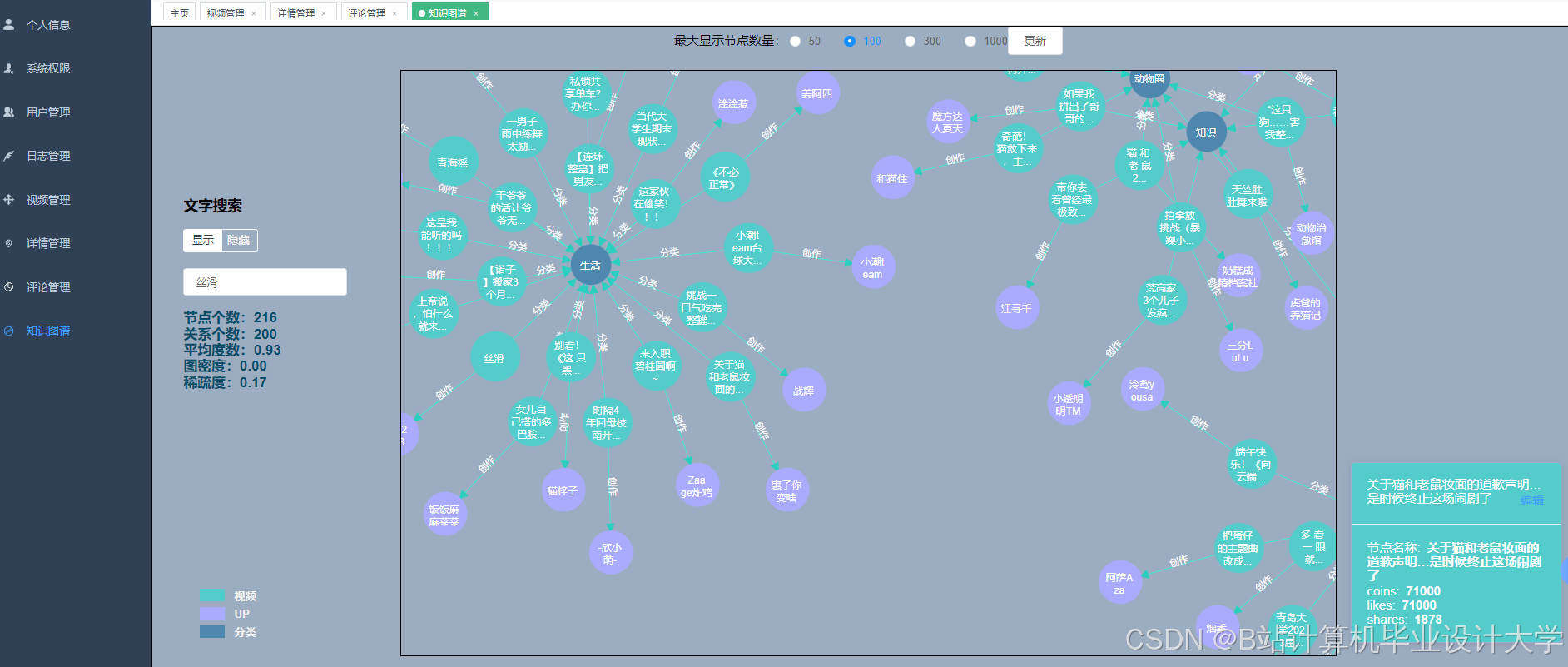
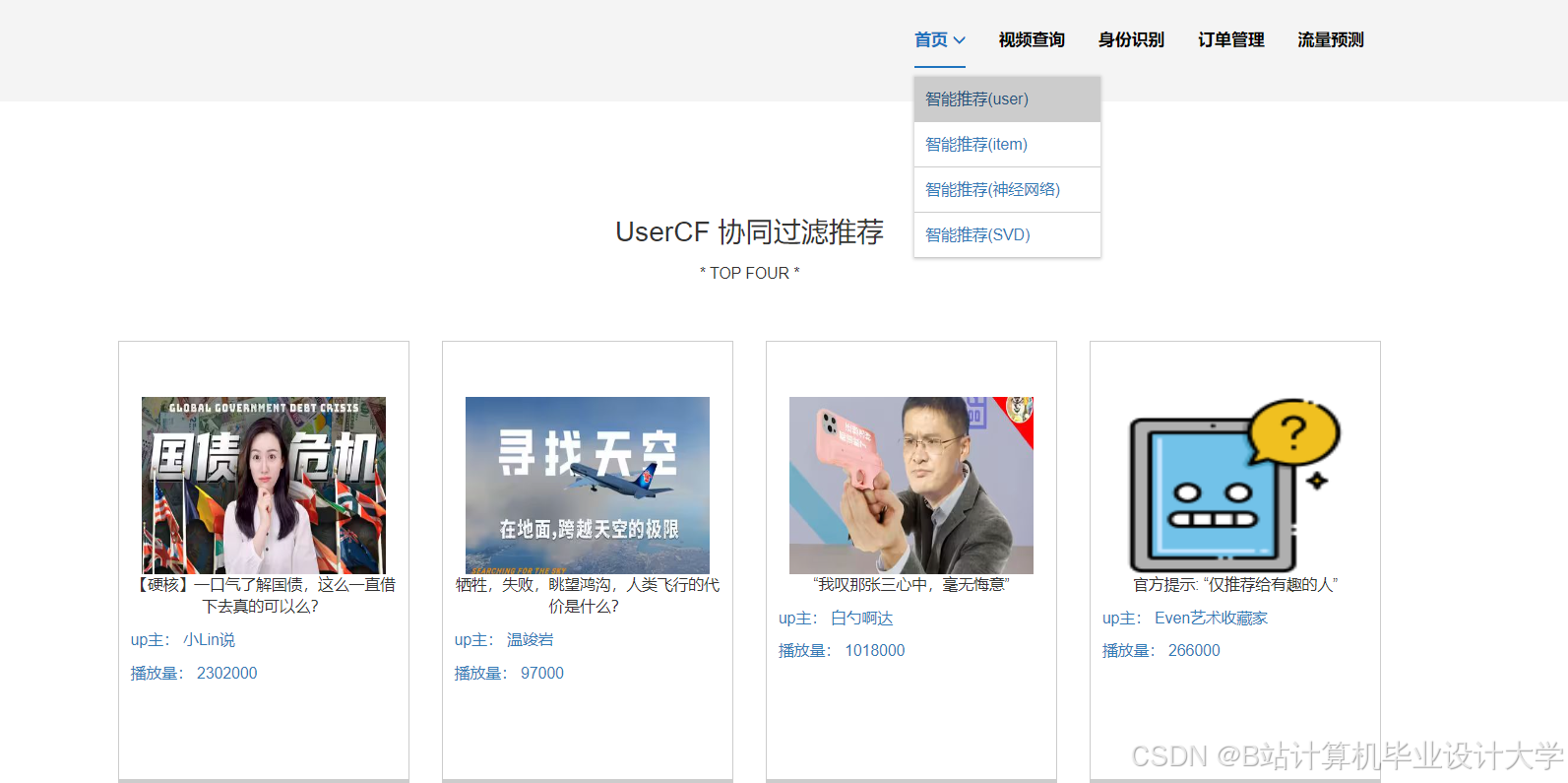
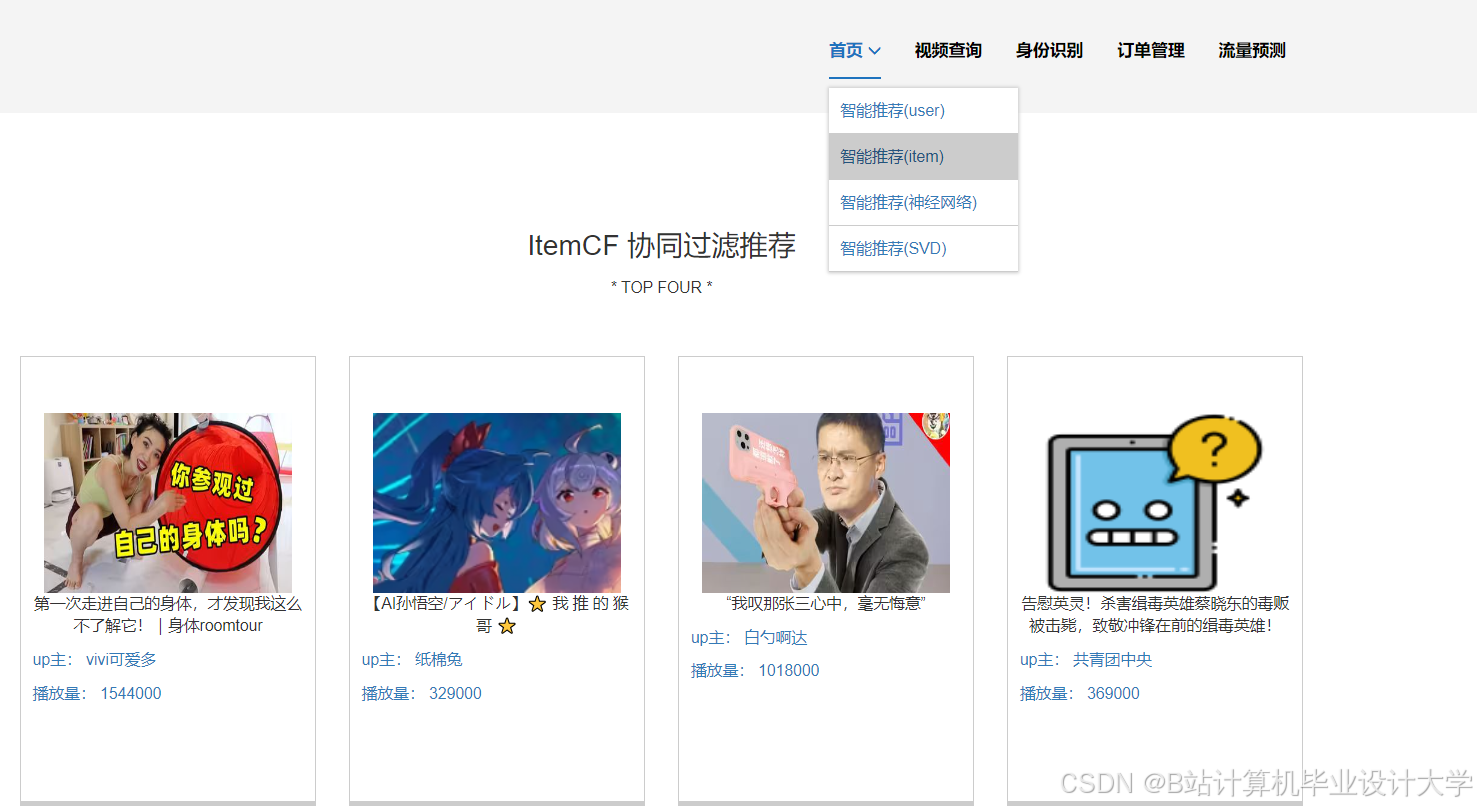
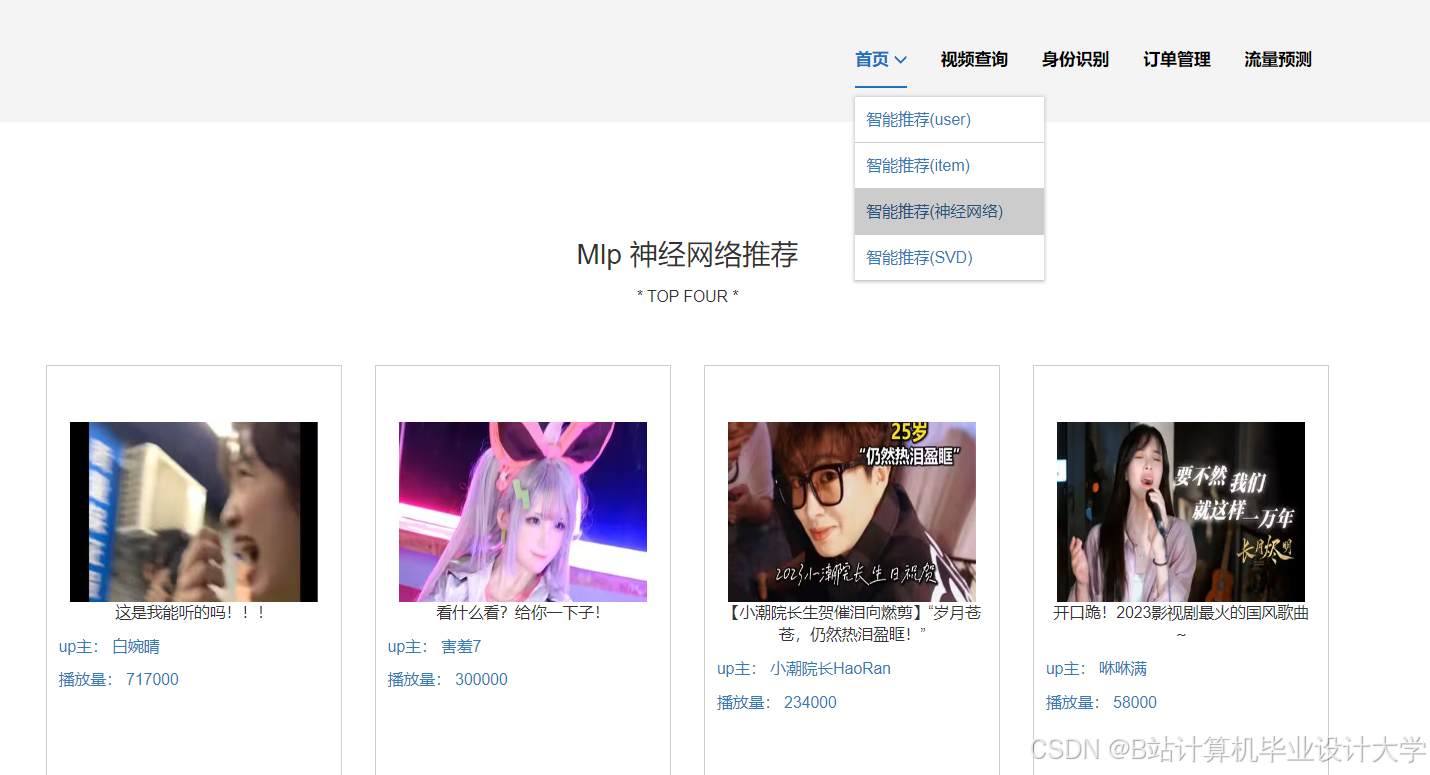
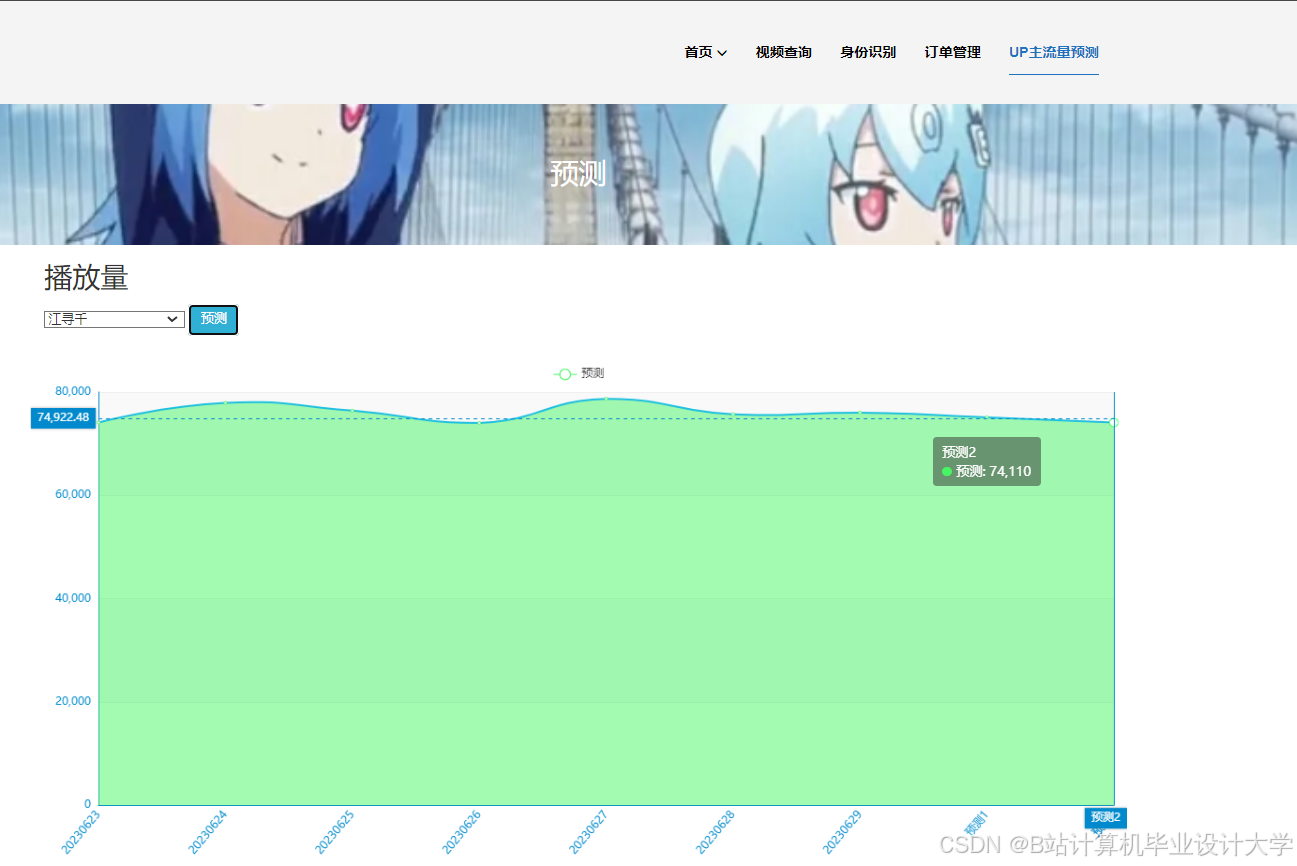
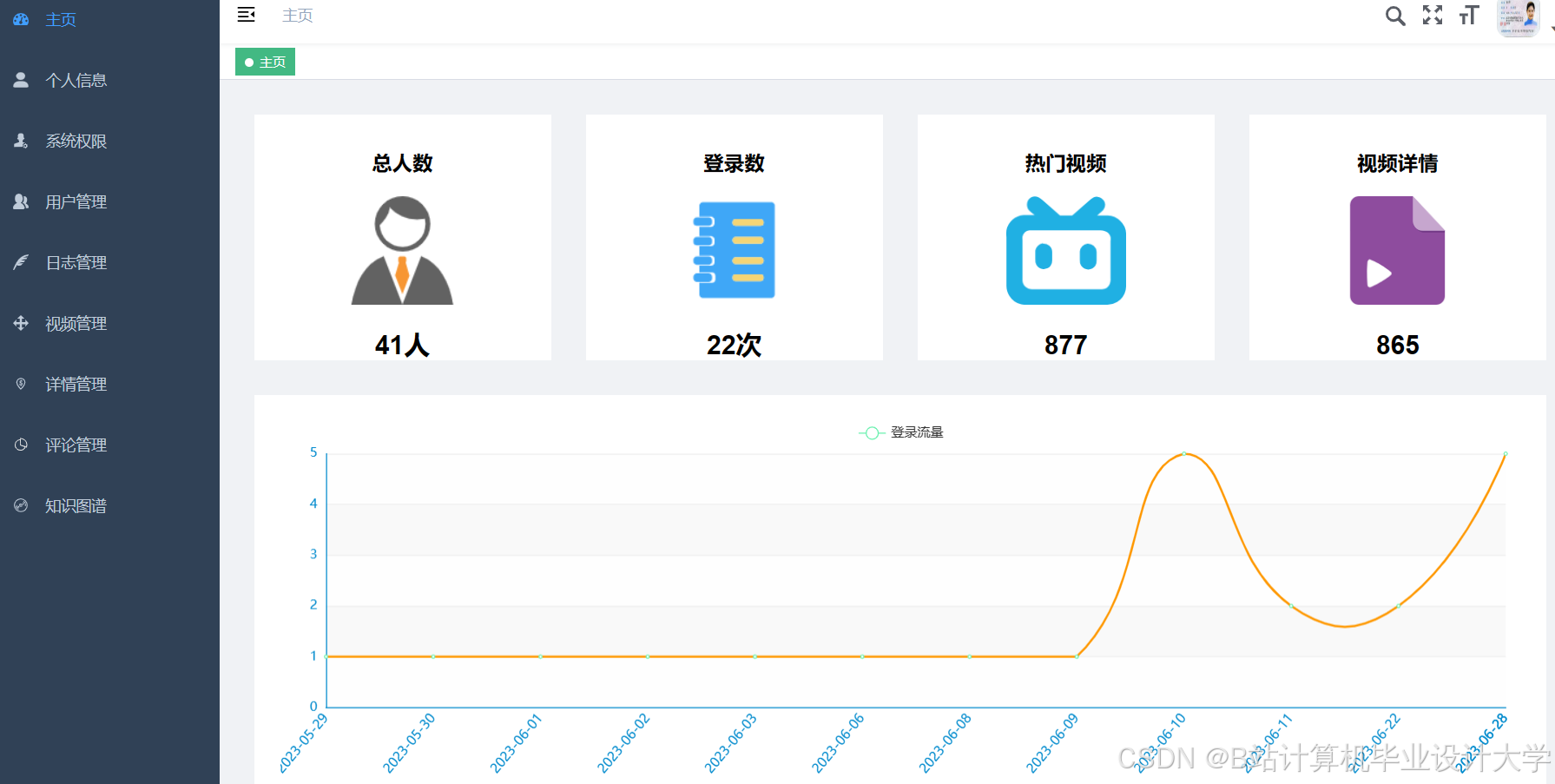
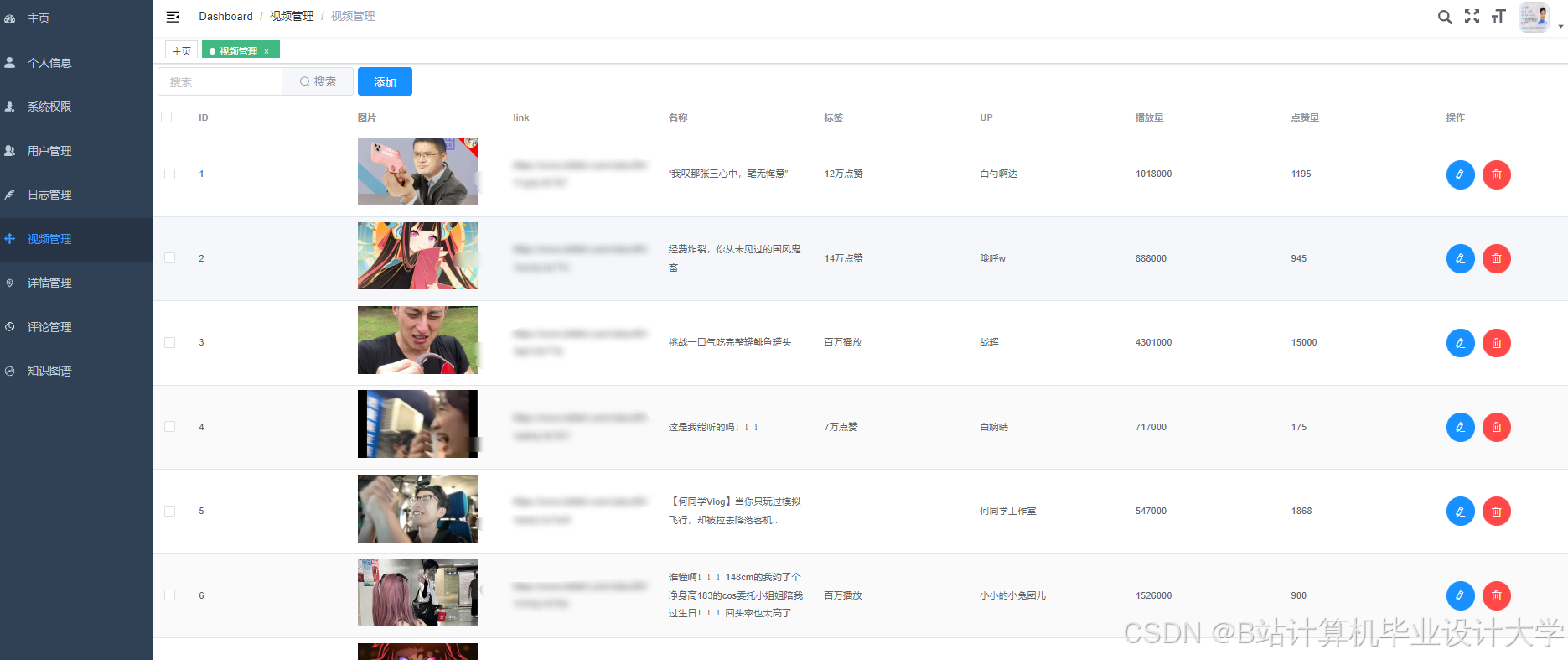
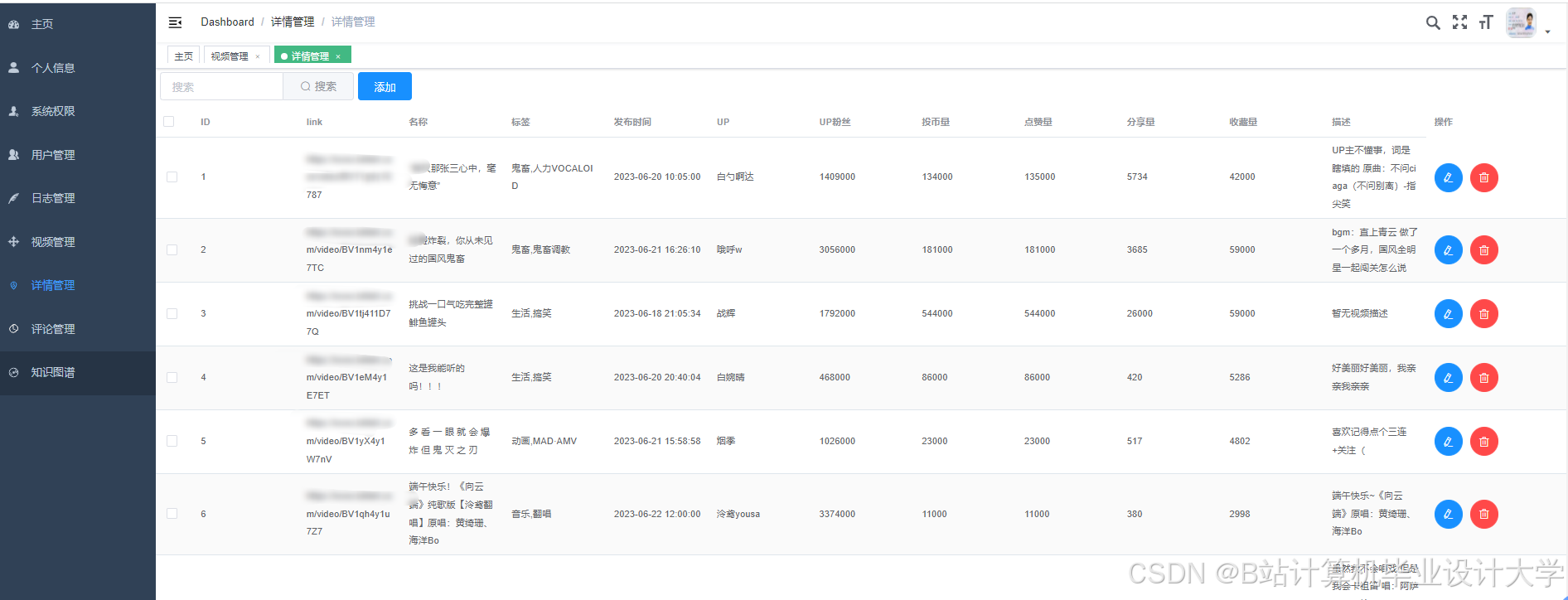
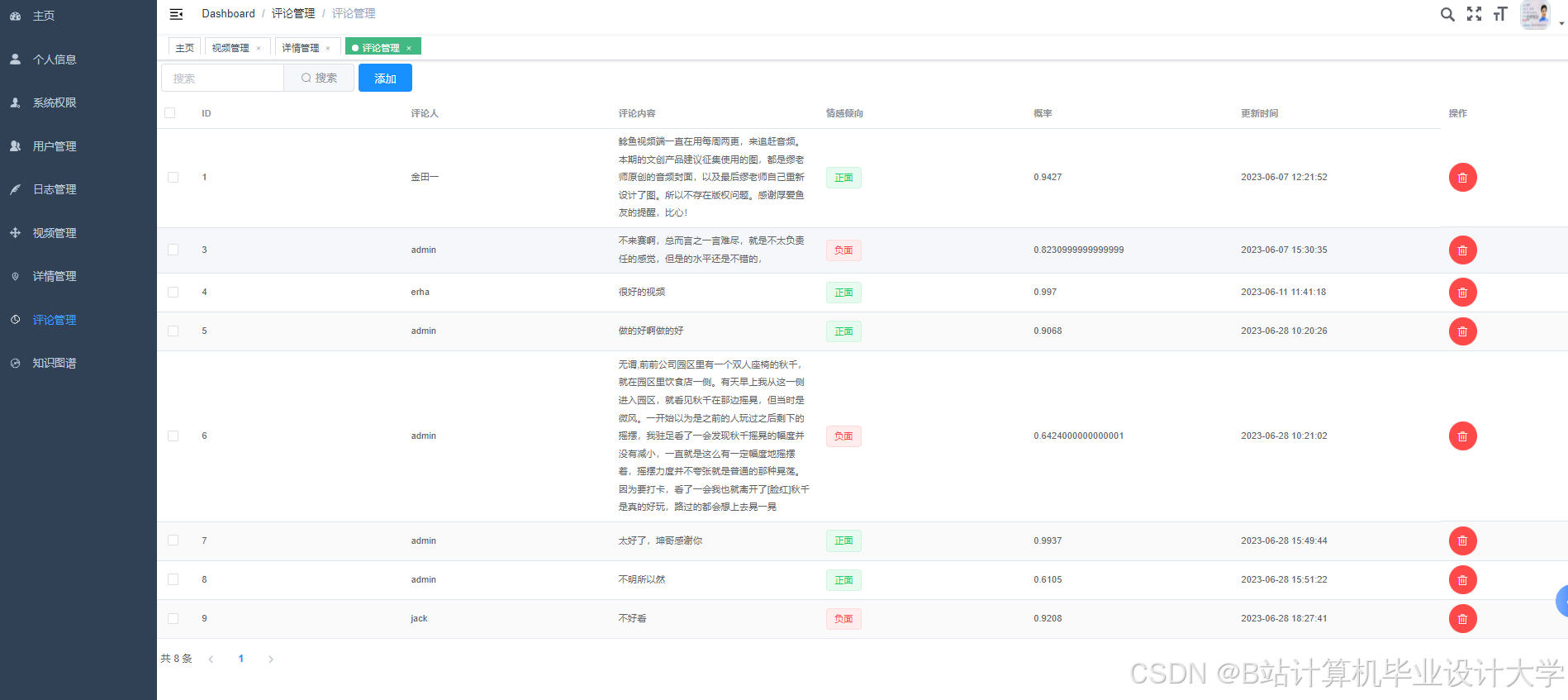
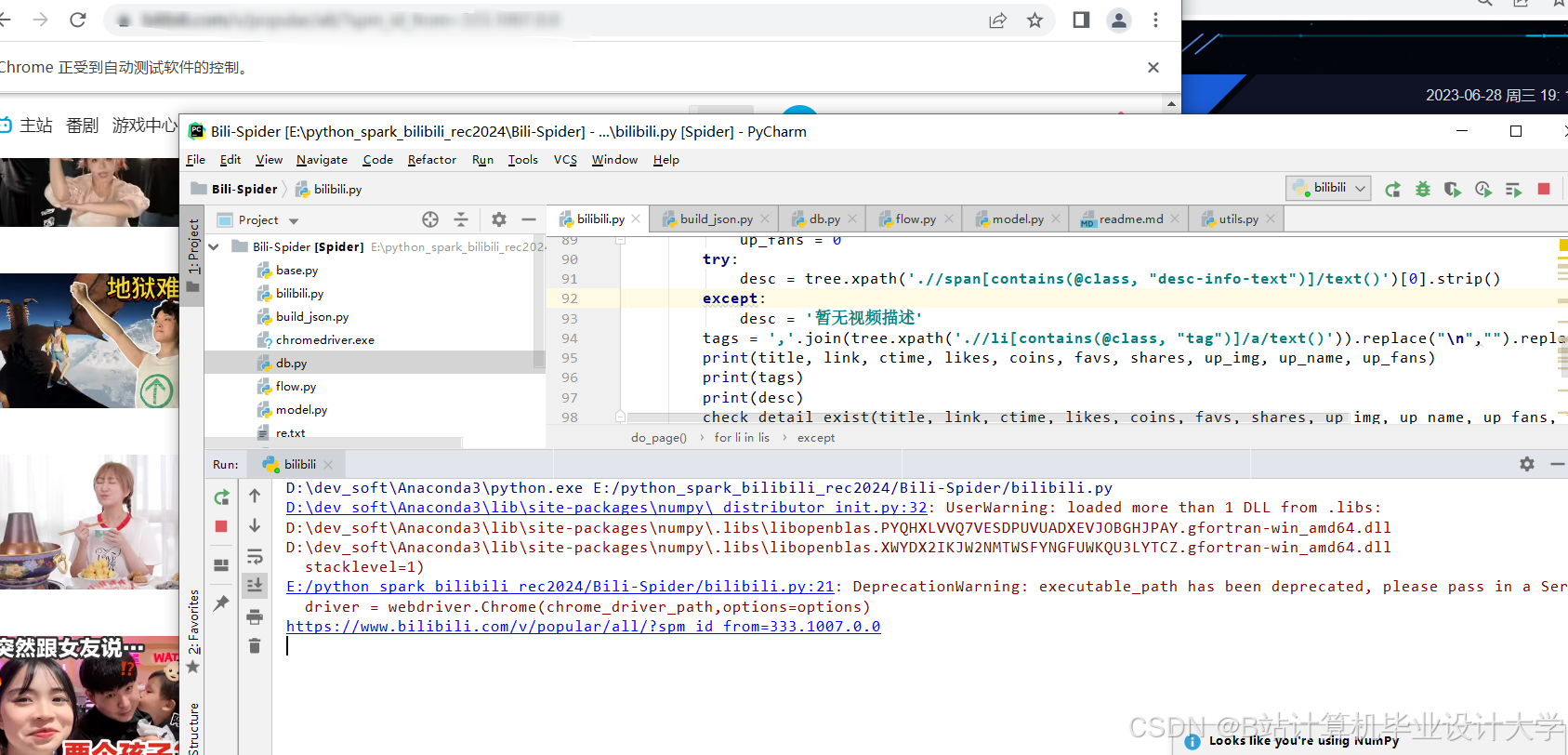
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献810条内容
已为社区贡献810条内容

所有评论(0)