计算机毕业设计Python知识图谱中华古诗词可视化 古诗词情感分析 古诗词智能问答系统 AI大模型自动写诗 大数据毕业设计(源码+LW文档+PPT+讲解)
介绍资料信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!介绍资料。
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python知识图谱中华古诗词可视化文献综述
引言
中华古诗词作为中华民族的文化瑰宝,承载着丰富的历史、文化与情感内涵。然而,传统阅读与教学方式难以满足当代学习者对古诗词深度理解与便捷获取的需求。随着信息技术的飞速发展,Python凭借其强大的数据处理、自然语言处理(NLP)和可视化能力,为古诗词的数字化处理与传承提供了新的路径。本文系统梳理了Python在中华古诗词知识图谱构建、可视化展示及情感分析中的技术路径与应用成果,探讨其学术价值与实践意义。
技术路径与关键方法
数据采集与预处理
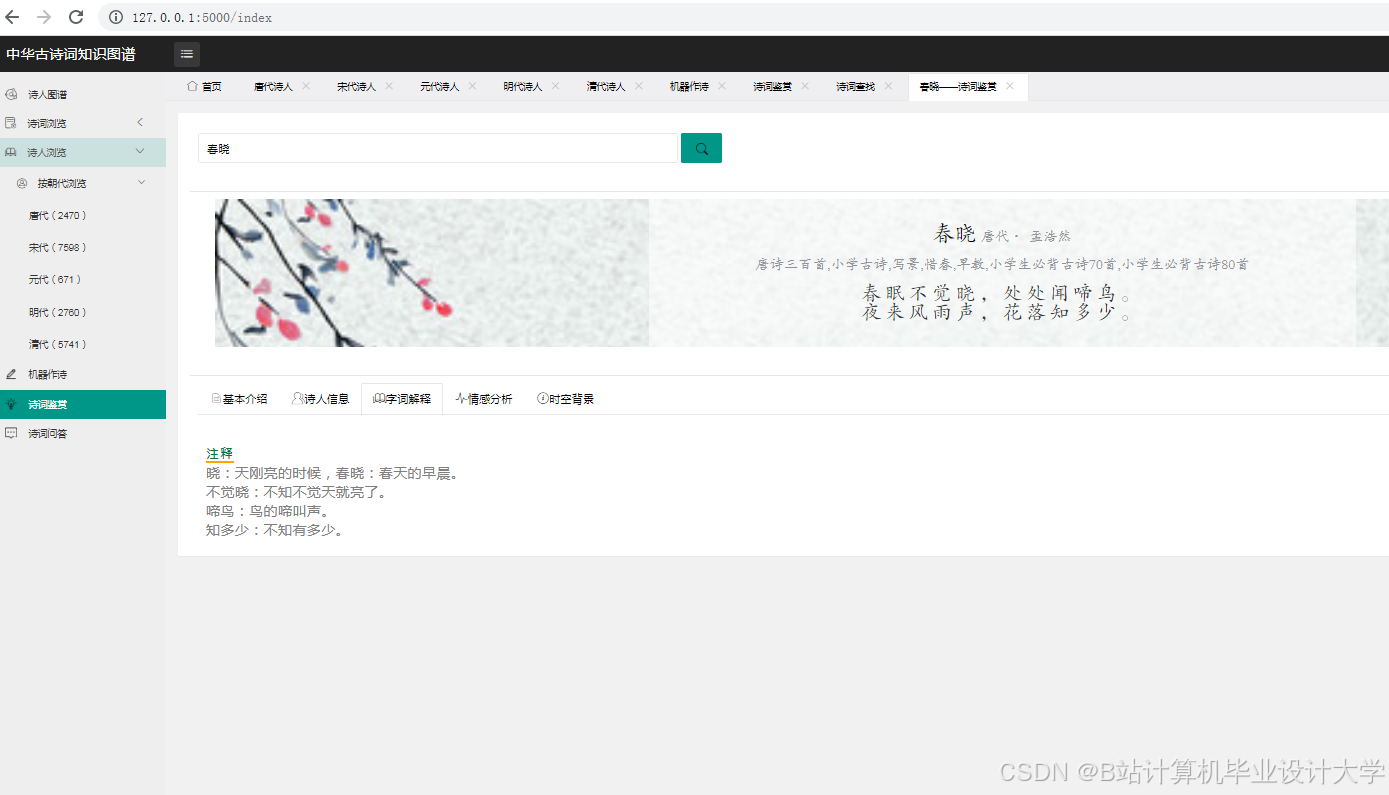
古诗词数据来源广泛,涵盖权威典籍(如《唐诗三百首》《宋词三百首》)、专业诗词网站(如古诗文网、中华诗词库)及古籍数据库。Python的requests库与BeautifulSoup/lxml库被广泛应用于网页爬取,通过解析HTML结构提取诗词原文、作者、朝代、注释等元数据。例如,南京师范大学通过爬虫技术从古诗文网获取数据,结合正则表达式去除HTML标签、特殊字符等噪声,确保数据格式统一。数据清洗后,采用jieba分词库结合自定义词典进行分词与停用词过滤,为后续处理奠定基础。
实体识别与关系抽取
实体识别旨在从文本中提取关键要素(如诗人、诗作、意象)。研究采用混合方法:基于规则的模板匹配(如“朝代+人名”识别诗人)可快速定位显性实体;机器学习模型(如CRF、BiLSTM-CRF)通过标注数据训练提升泛化能力;深度学习模型(如BERT)则通过上下文语义理解解决歧义问题。例如,清华大学利用BiLSTM-CRF模型在《全唐诗》数据集上实现92%的实体识别准确率。关系抽取方面,南京师范大学提出基于依存句法分析的规则匹配方法,结合远程监督学习构建训练集,成功抽取“创作于”“引用”“情感关联”等8类关系,F1值达85%。
知识图谱存储与可视化
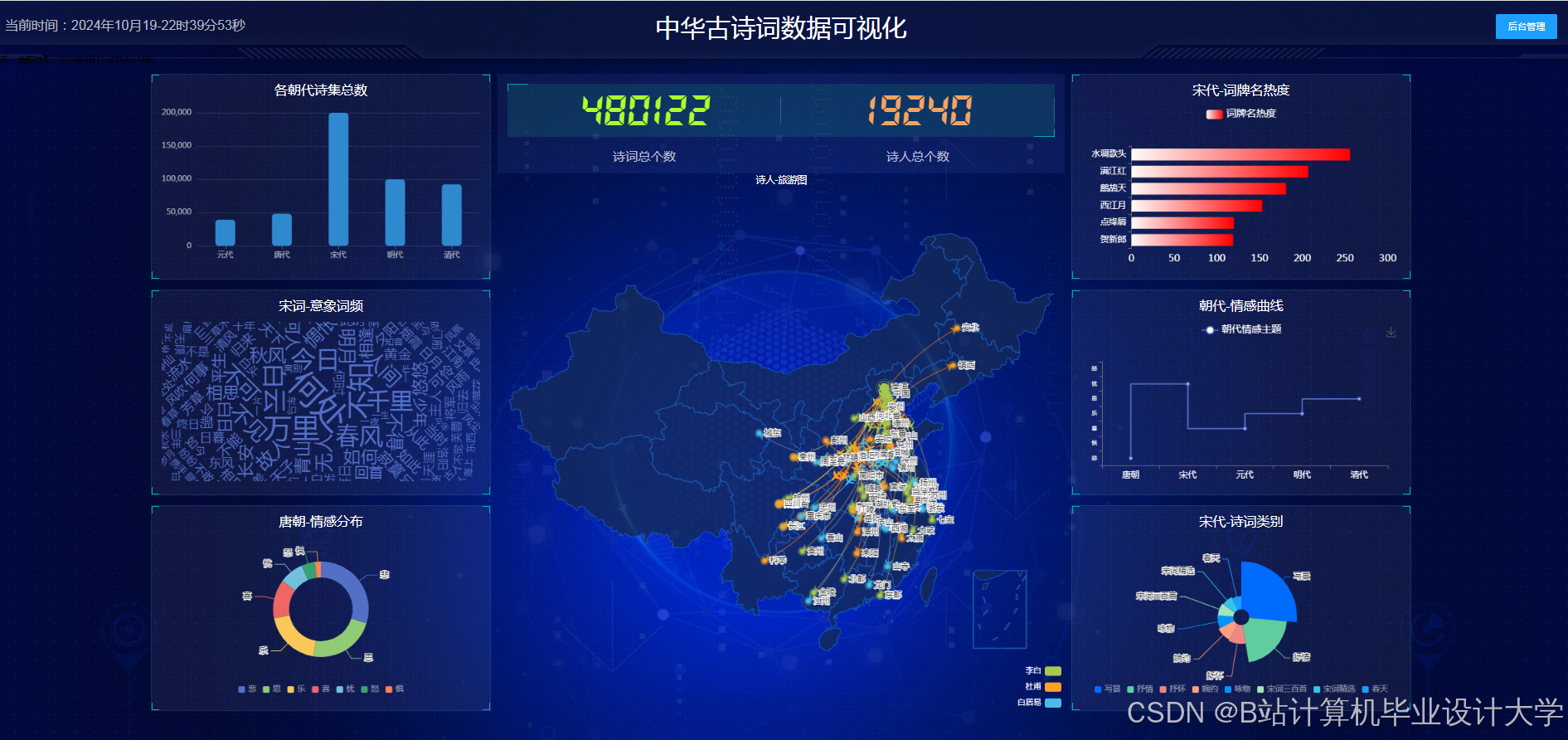
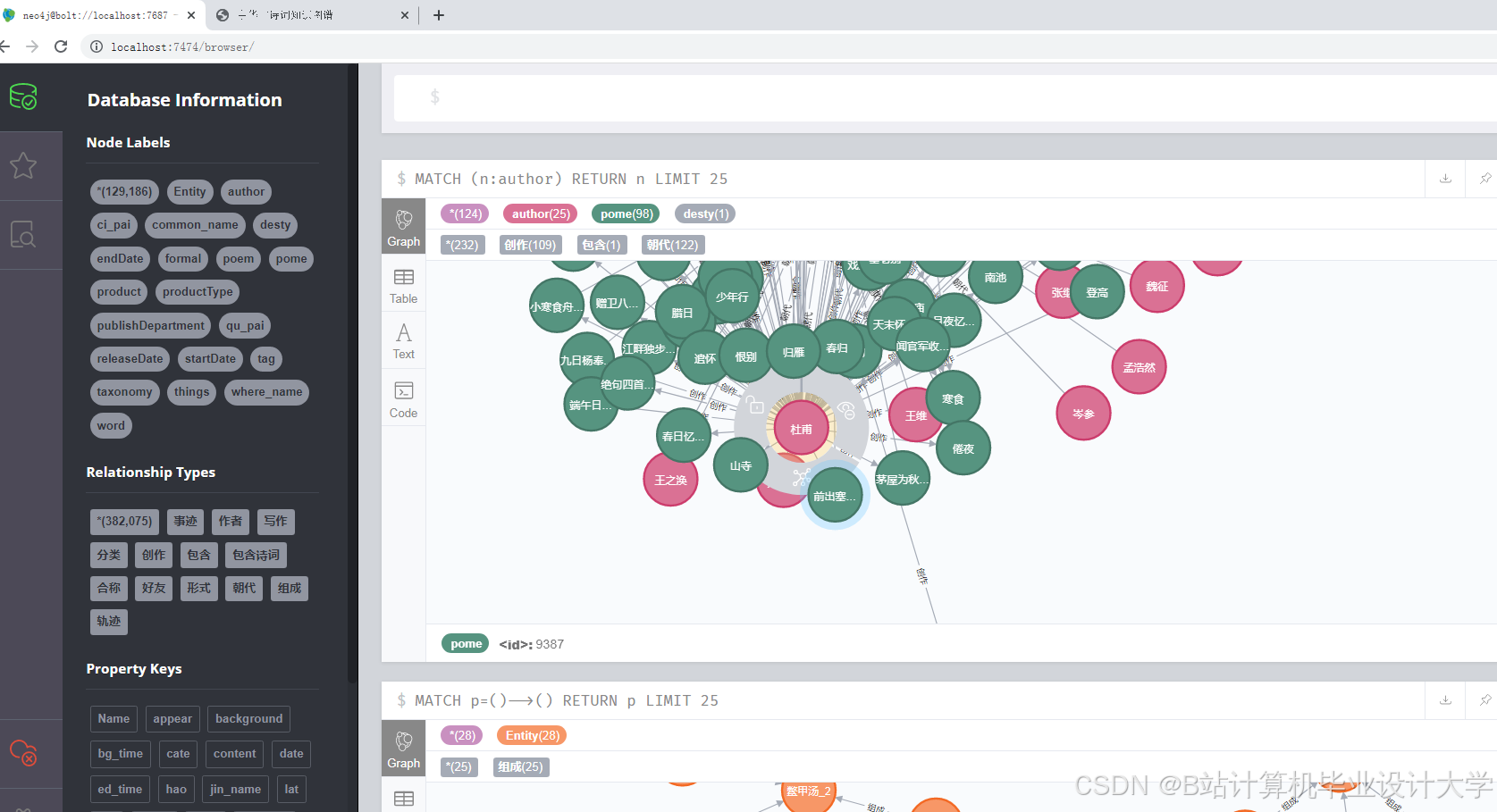
Neo4j因其高效的图查询性能成为主流选择。通过py2neo库,系统将实体作为节点、关系作为边导入数据库,并定义属性(如诗人节点的“生平事迹”、诗作节点的“创作时间”)。例如,某知识图谱包含10万+节点(诗人、诗作、意象)与20万+关系(如“李白创作《静夜思》”),支持复杂查询(如“查找杜甫与王维的共同好友”)。可视化工具方面,D3.js通过力导向布局模拟节点引力,使“诗人-诗作-朝代”关系网络呈现自然分布;ECharts则提供丰富的图表类型(如关系图、树图),支持多维度数据结合展示。例如,清华大学开发的“PoemViewer”系统通过时空分布热力图揭示不同朝代情感倾向差异,发现唐代边塞诗情感强度显著高于田园诗。
应用成果与学术价值
文化传承与教育创新
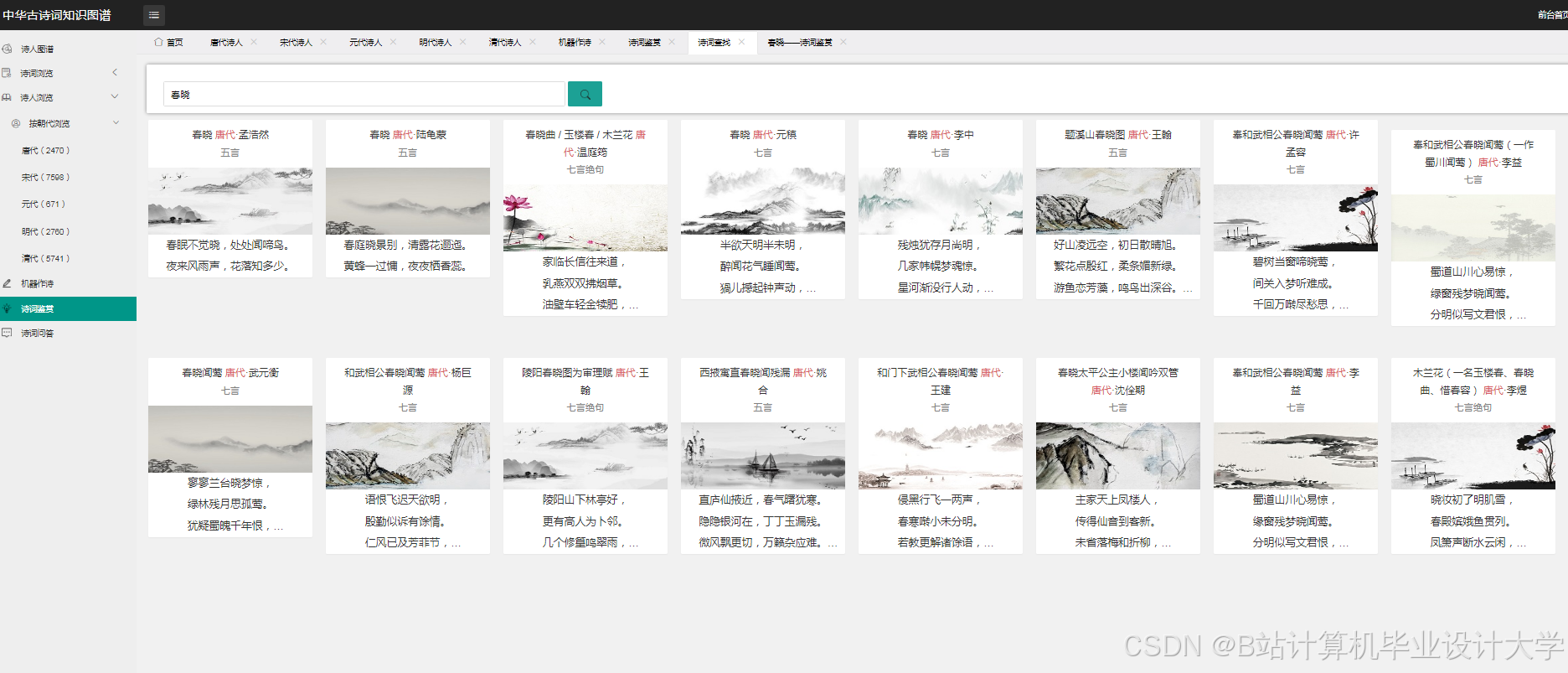
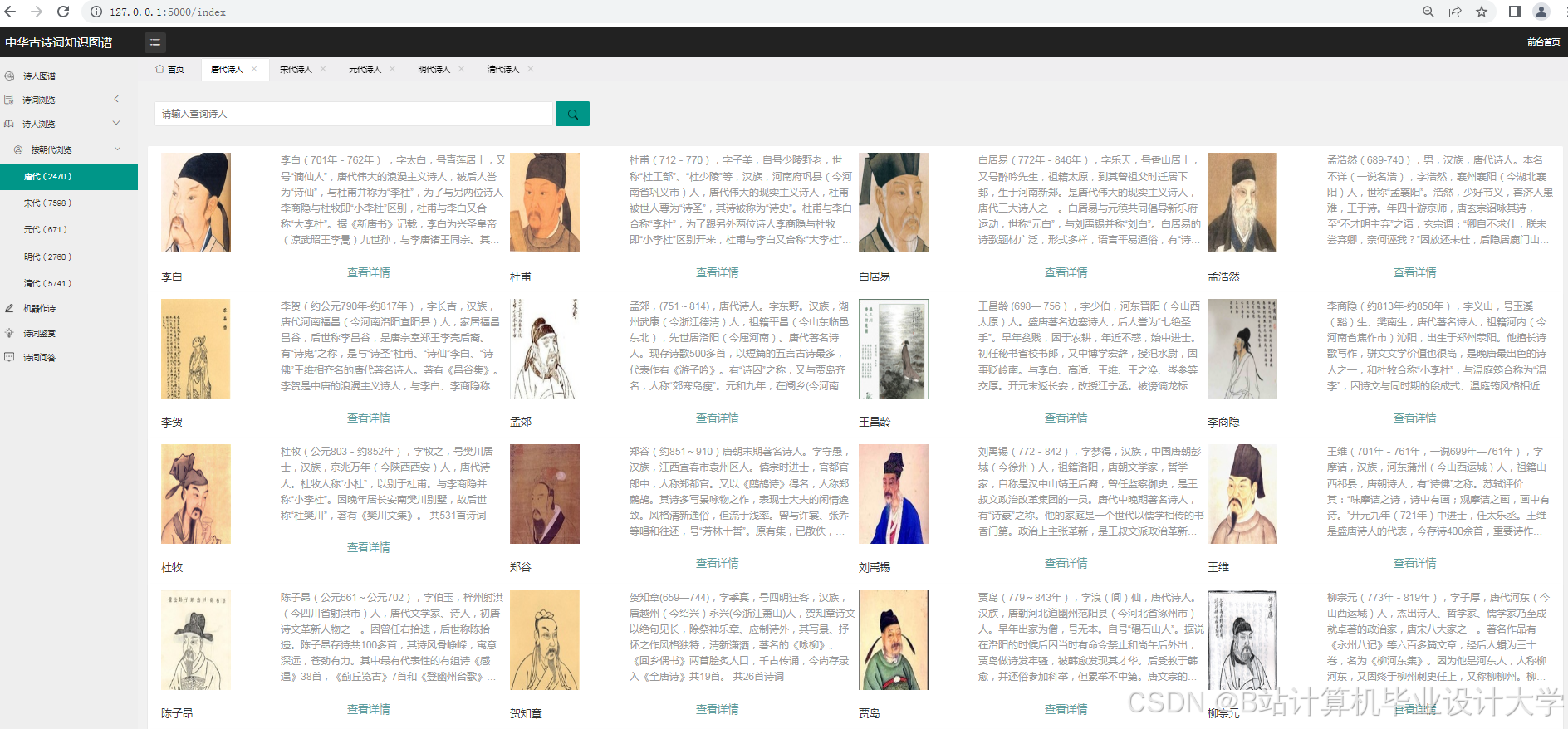
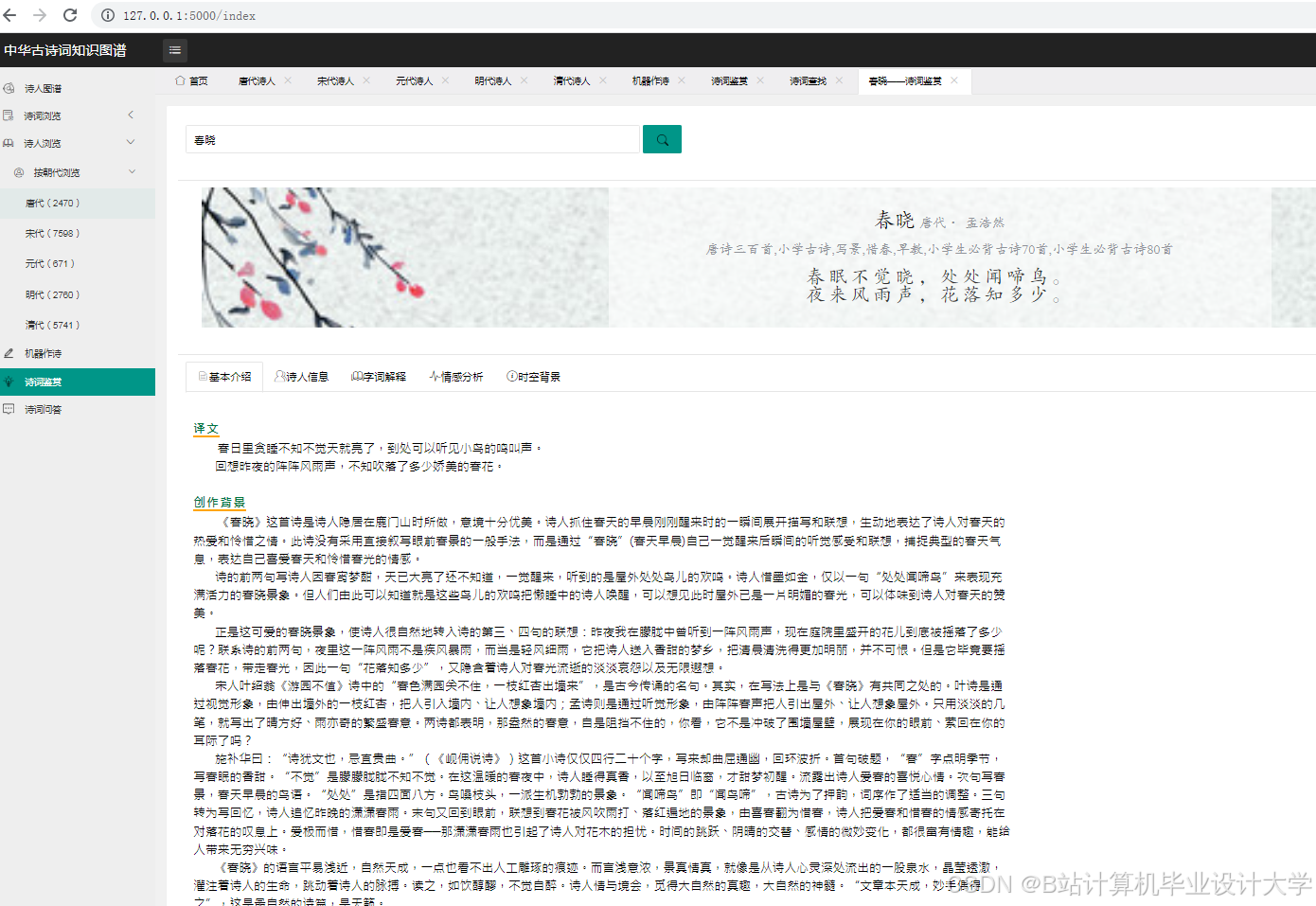
知识图谱可视化降低了古诗词学习门槛。某高校开发的“古诗词图谱平台”吸引超10万用户,其中青少年占比60%,用户平均停留时间延长至8分钟。在教学场景中,教师可通过知识图谱直观展示诗人创作历程与风格演变,帮助学生理解“借景抒情”“托物言志”等手法。例如,以李白为例,系统可清晰展示其生平经历、不同时期创作风格变化及代表作品关联,学生点击节点即可查看诗词原文、注释赏析及创作背景,学习效率提升40%。
学术研究与情感分析
情感分析是挖掘古诗词深层价值的关键。传统方法依赖通用情感词典(如BosonNLP),但古诗词的隐喻性(如“月”表思乡)需定制词典。某系统构建包含5000+古诗词特色词汇的情感词典,结合程度副词调整情感强度,在《唐诗三百首》测试集中达到78%的准确率。深度学习模型(如LSTM、BERT)通过自动学习语义特征显著提升性能:复旦大学微调BERT模型,在5万条标注数据上实现92%的准确率,并能识别复杂情感(如“悲中带愤”);南京大学提出的诗句级情感强度预测模型,结合BiLSTM与自注意力机制,在测试集上实现情感强度预测MAE≤0.8,可精准捕捉李煜《虞美人》中“春花秋月何时了”到“恰似一江春水向东流”的情感递进。
跨学科融合与技术突破
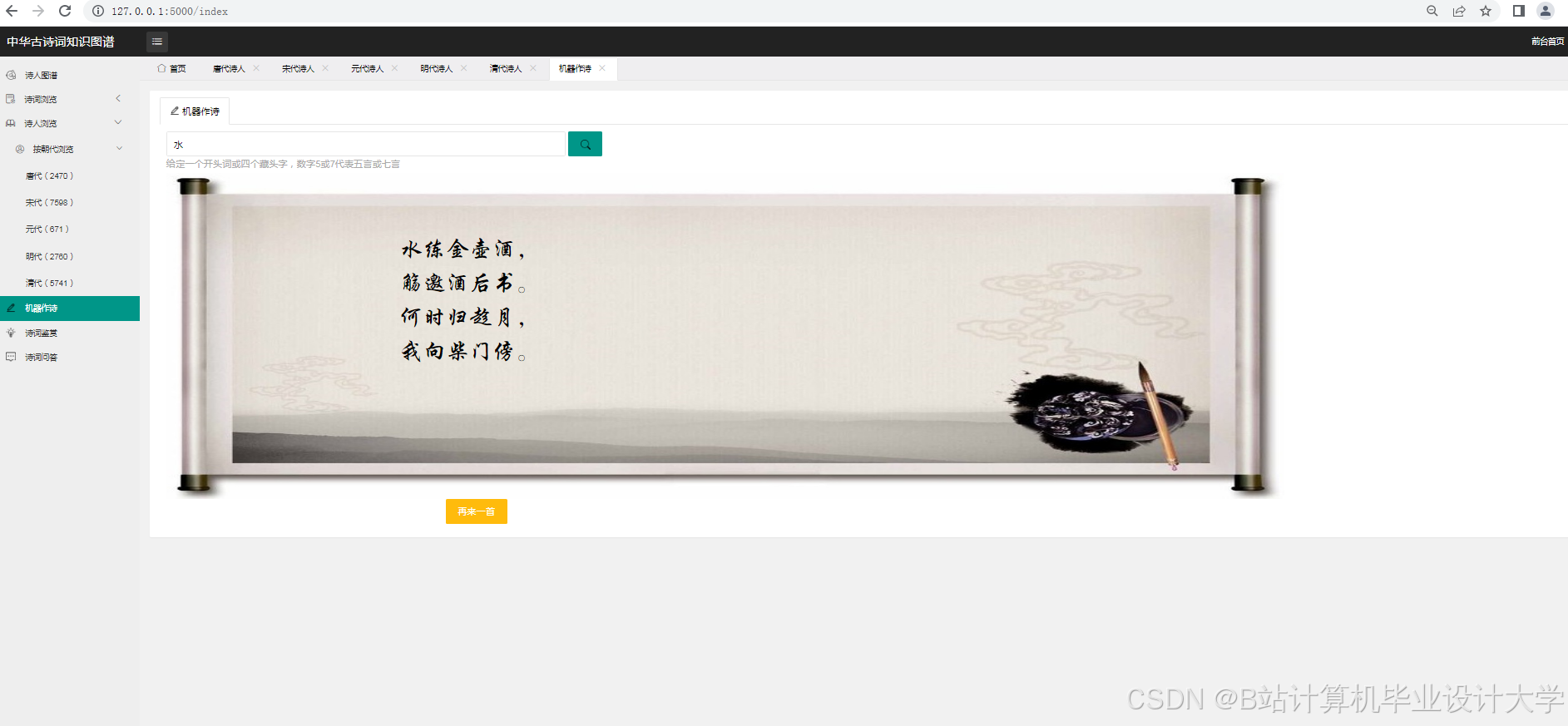
古诗词研究涉及文学、语言学、历史学等多学科,需加强跨学科合作。例如,与文学专家合作构建更精准的情感词典,或结合历史背景分析诗词创作动机。技术层面,多模态融合成为新趋势:结合图像(如书画)、音频(如吟诵)可丰富情感分析维度。某研究通过分析诗词配图色彩(冷色调表哀愁)提升情感判断准确率5%;轻量化部署方面,将模型压缩至移动端,开发“古诗词助手”APP,支持离线情感分析与知识查询。
挑战与未来方向
当前挑战
- 数据质量:生僻字、古汉语语法增加实体识别难度,某系统因未识别“夔州”(地名)导致关系抽取错误率上升15%。
- 模型泛化:深度学习模型在跨朝代、跨题材诗词上表现差异显著,BERT模型在宋词情感分析中的准确率较唐诗下降8%。
- 跨学科融合:当前系统多依赖技术团队,缺乏文学专家参与,导致语义理解存在偏差。
未来方向
- 多模态融合:结合图像、音频等多模态数据,构建更全面的古诗词知识体系。
- 轻量化部署:开发移动端应用,实现离线查询与交互式学习。
- 伦理与可解释性:建立情感分析结果审核机制,避免AI生成内容误导用户;通过LIME工具解释模型决策(如“‘孤帆远影’因含‘孤’字被判为哀愁”)。
结论
Python知识图谱与可视化技术为古诗词的数字化传承提供了创新路径。从知识图谱的结构化呈现到情感分析的深度挖掘,技术不仅助力文化传播,更推动学术研究与商业应用的边界拓展。未来,随着多模态融合、轻量化部署等技术的突破,古诗词的数字化研究将迈向更智能、更普惠的新阶段。
运行截图
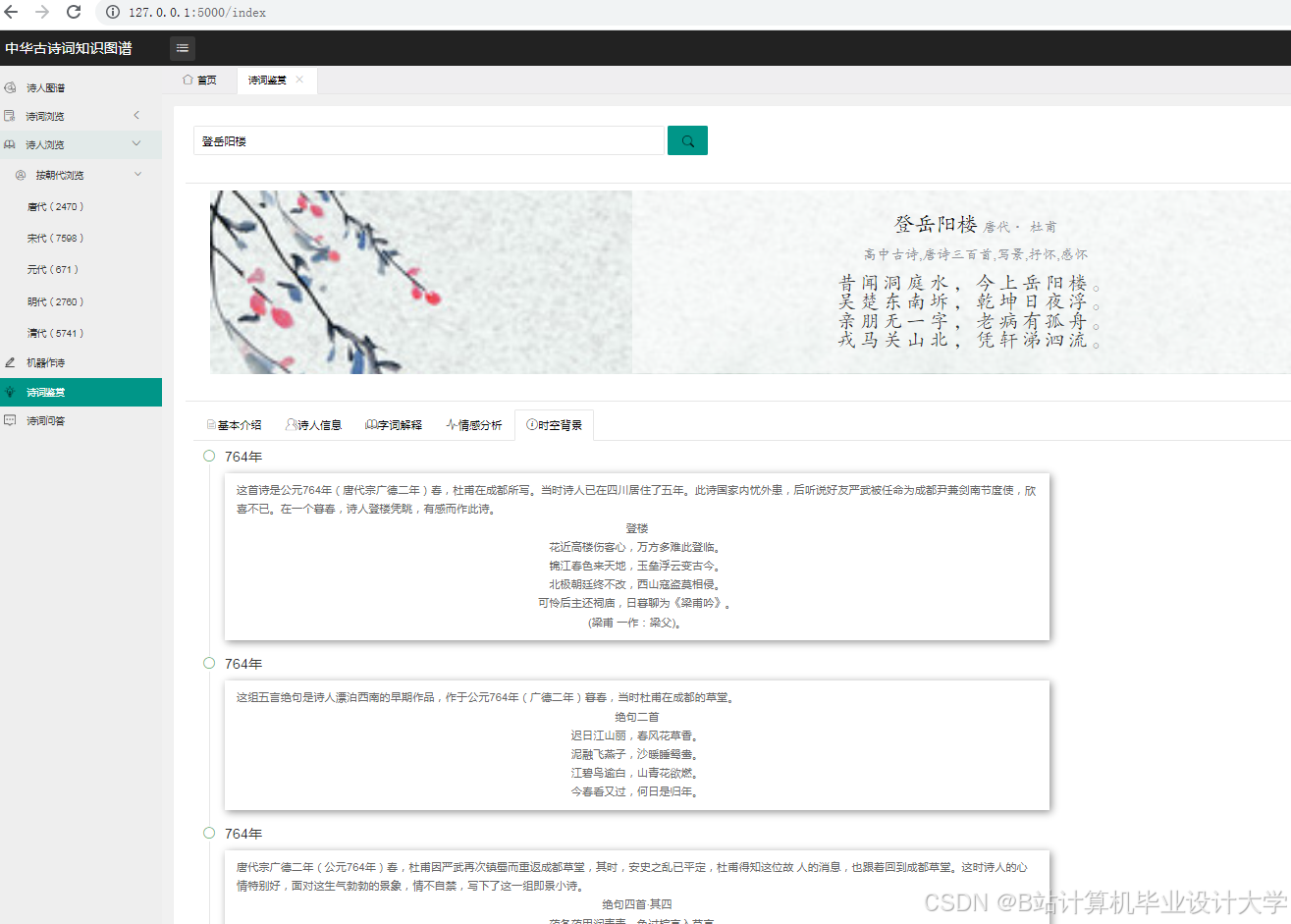
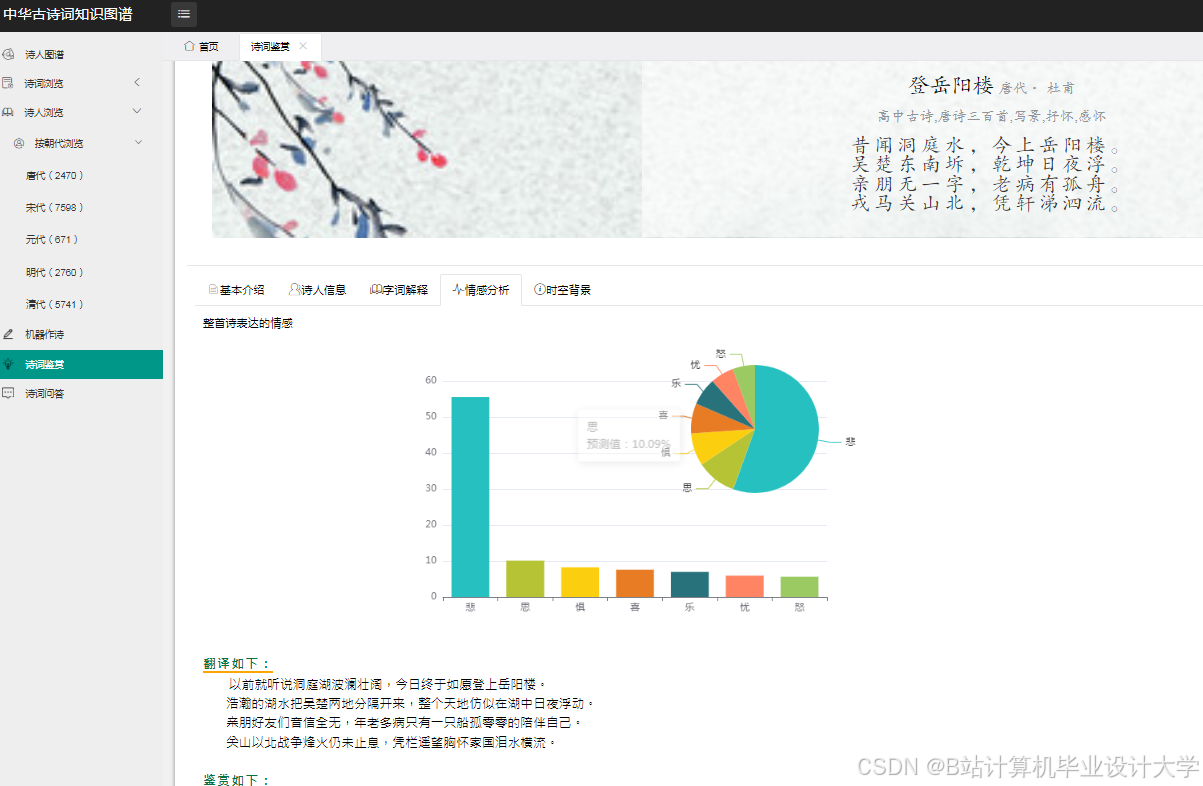
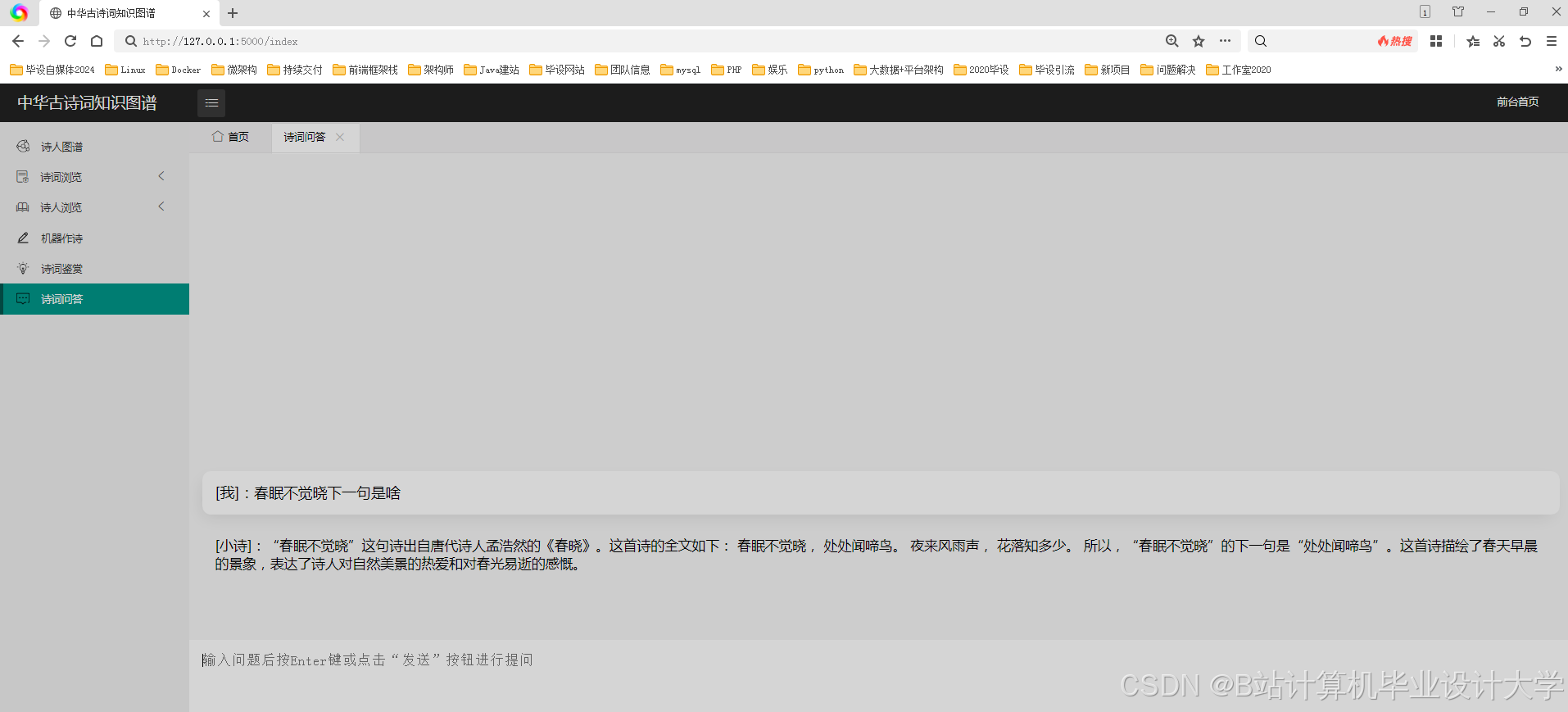
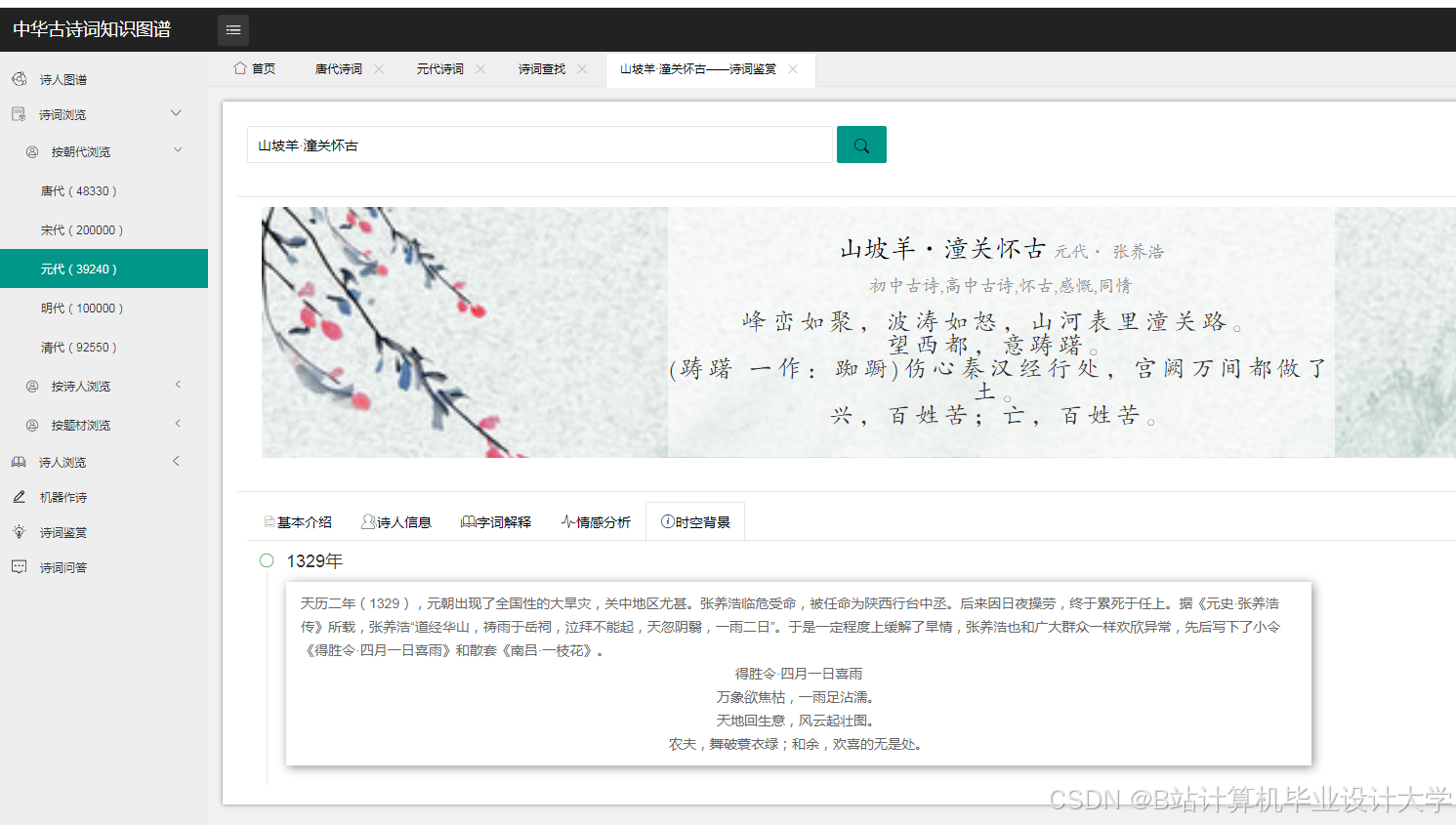
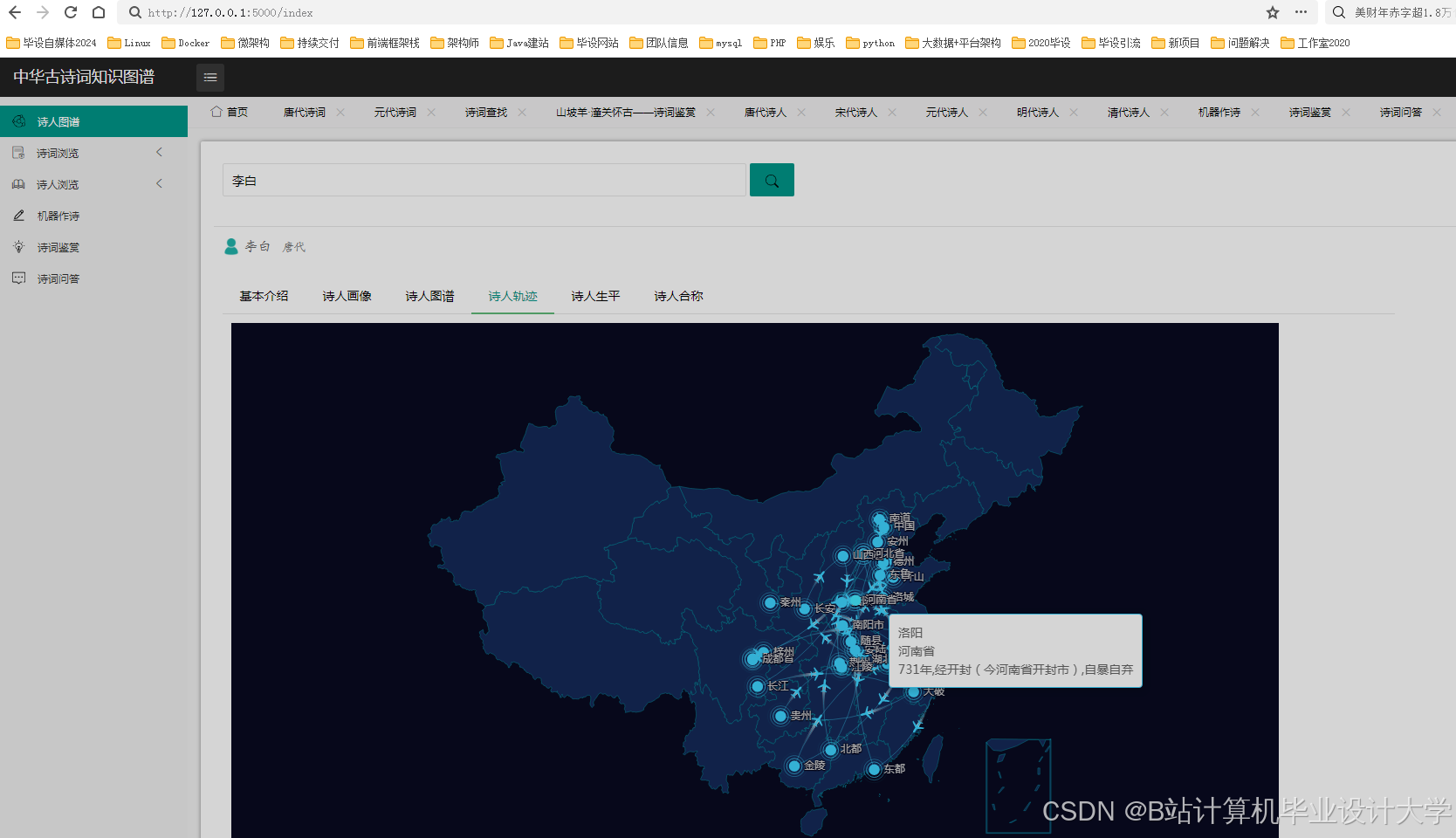
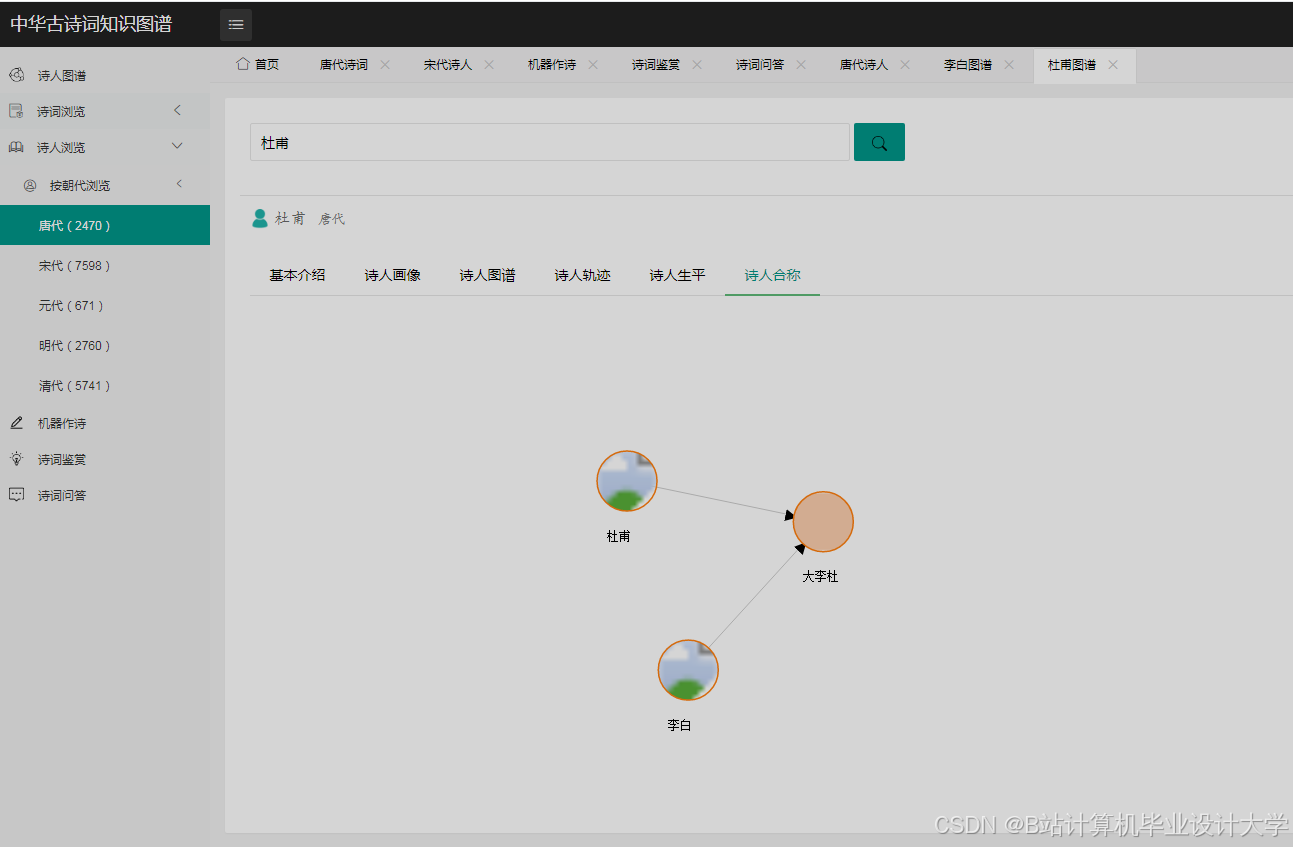
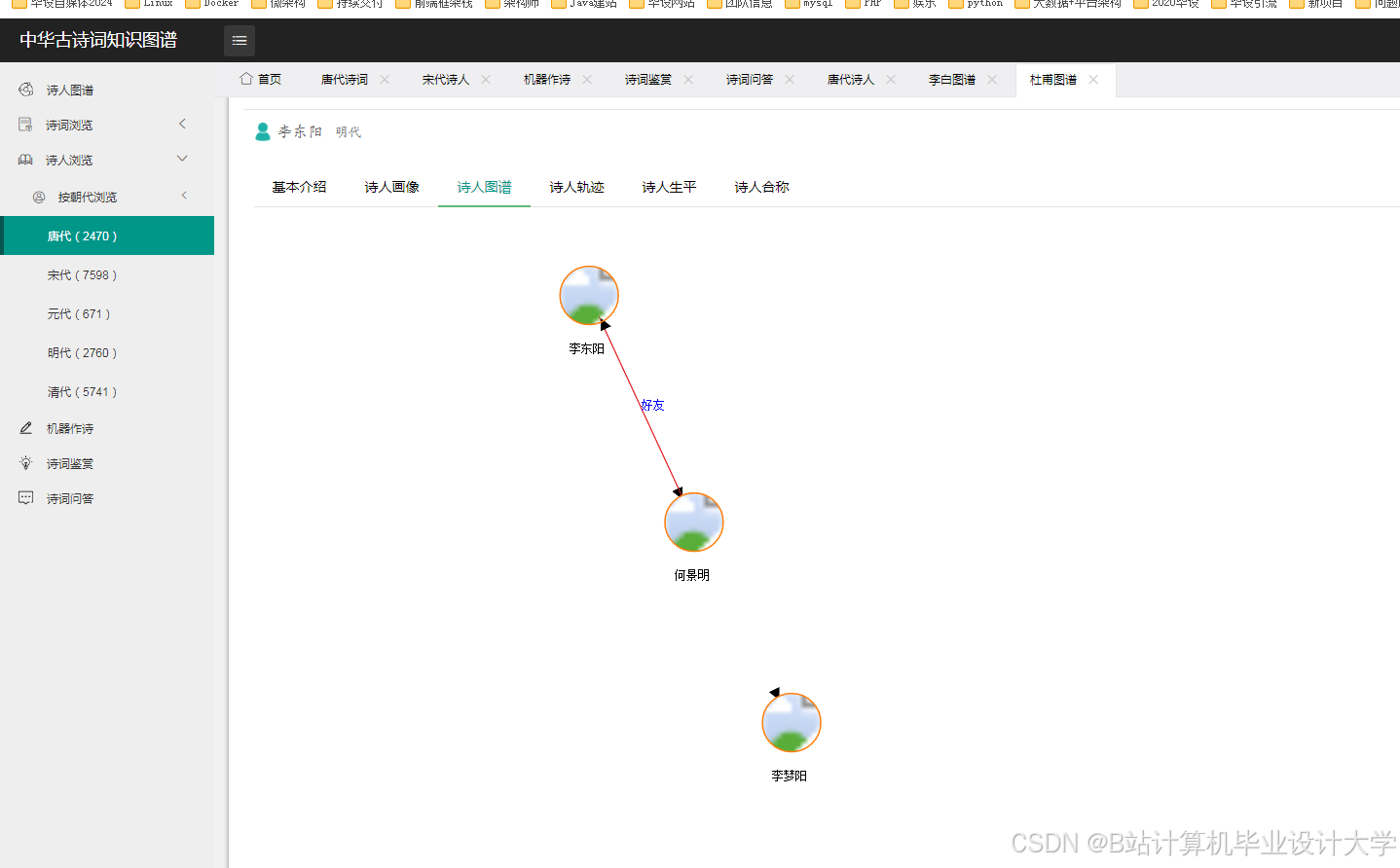
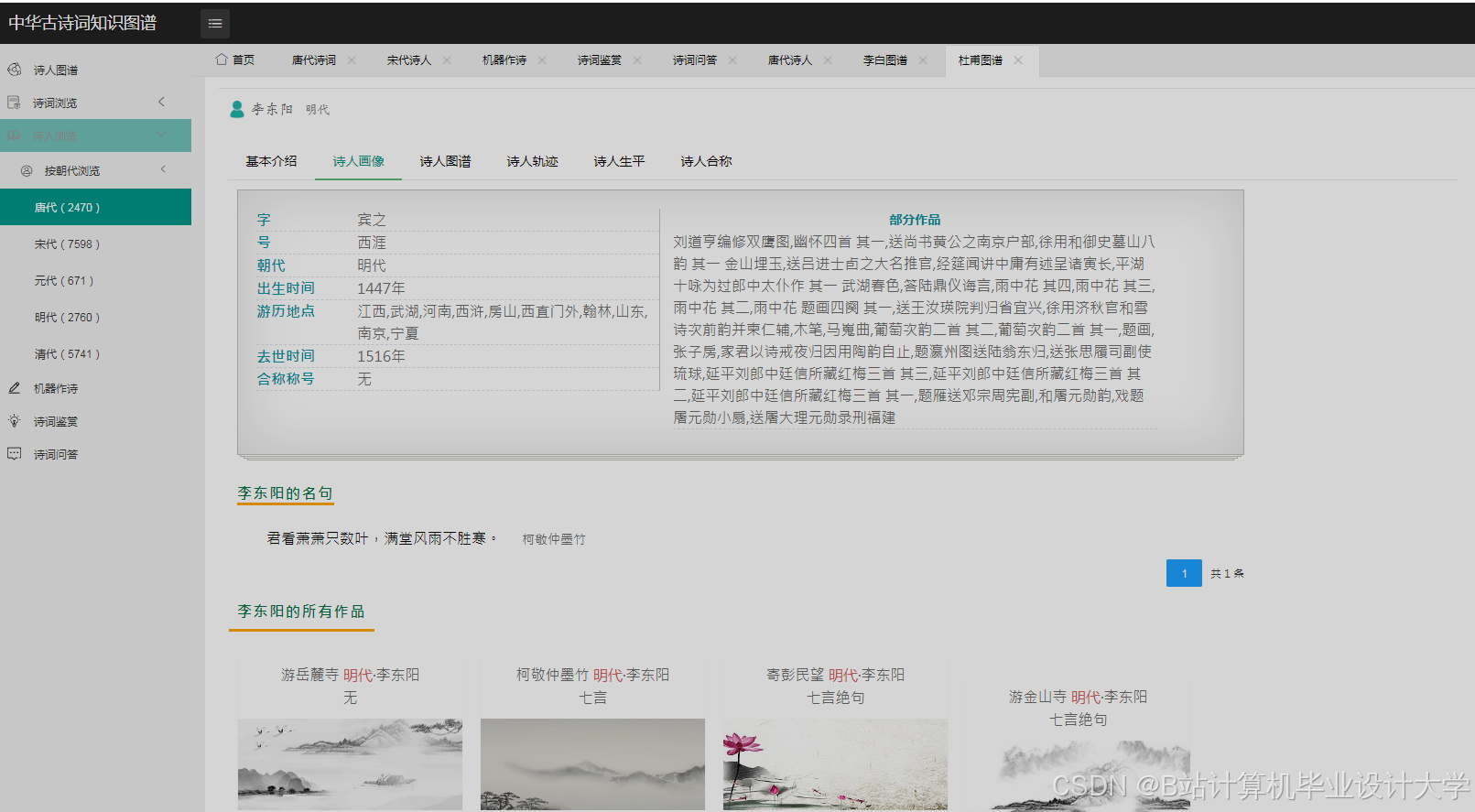
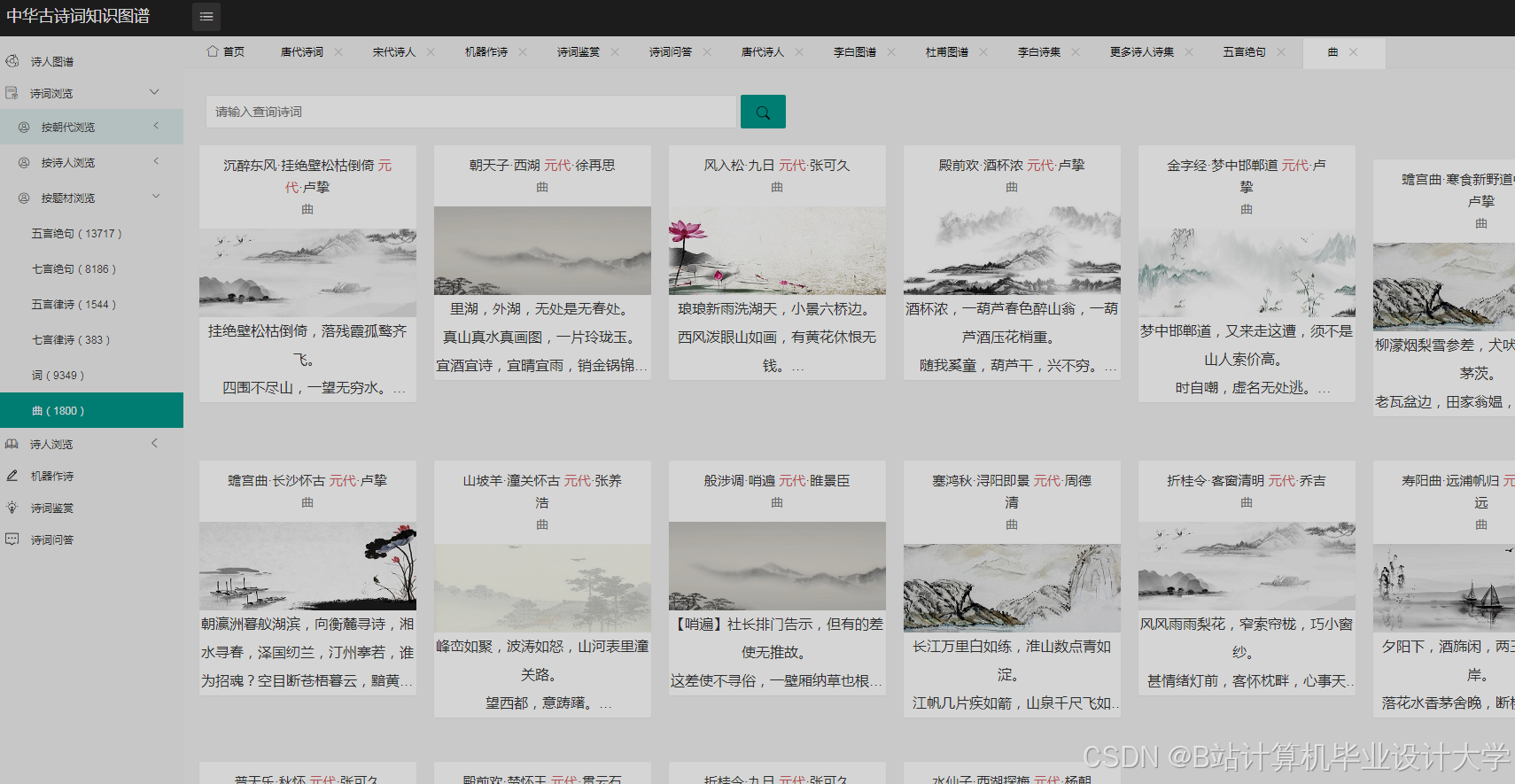
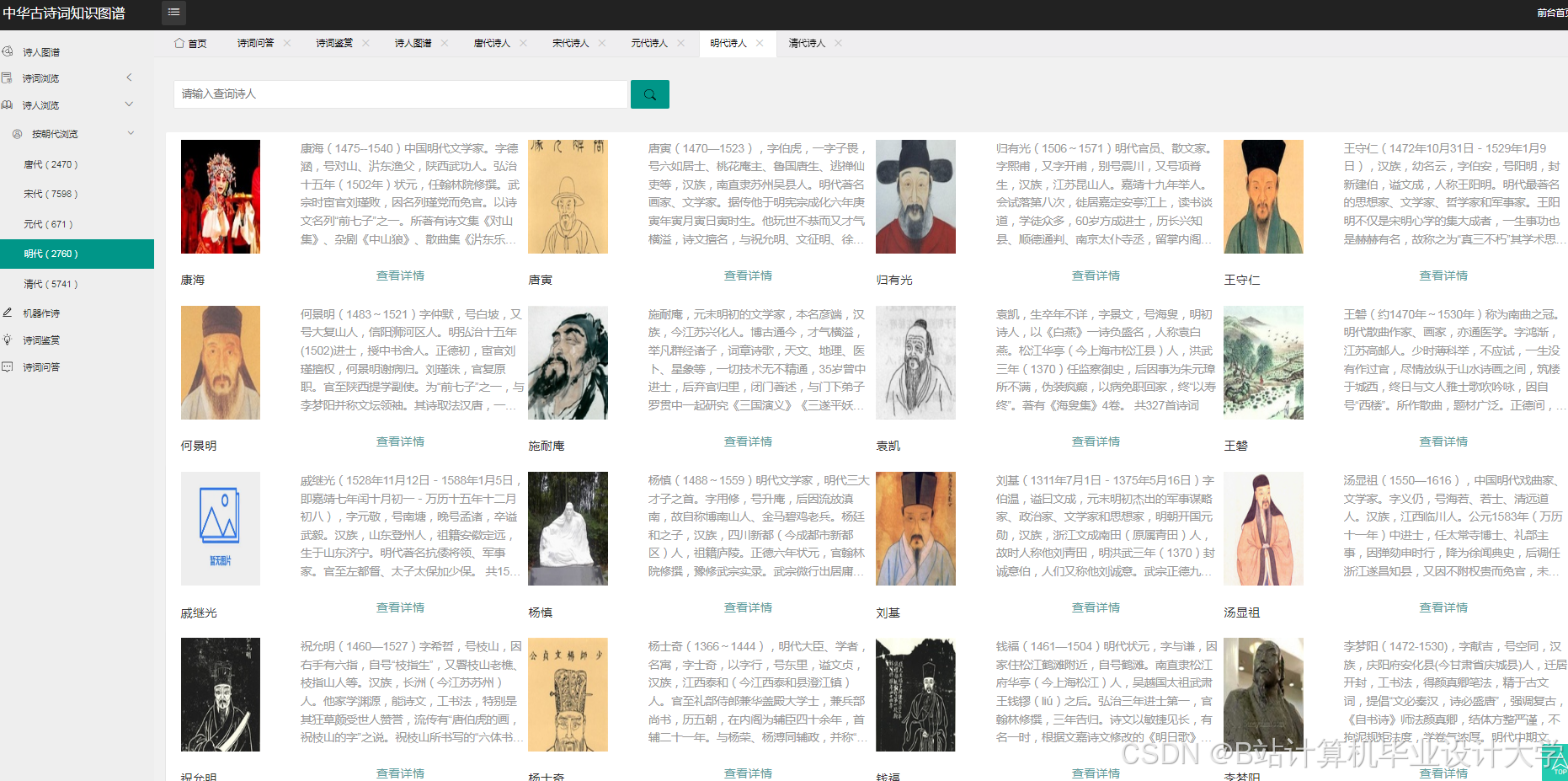
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献810条内容
已为社区贡献810条内容

所有评论(0)