收藏必备!AI应用开发中意图识别的重要性与实现(解决模糊问题的多Agent架构)
本文介绍AI应用开发中意图识别的重要性,特别是处理用户模糊或复杂问题时。通过"问题预处理→意图识别→任务拆解→问题改写→答案生成"五阶段流程,结合多Agent协作架构,系统解决用户问题理解难题。文章详细阐述了各核心模块实现方案及基础设施,为构建高效智能的AI问答系统提供完整解决方案。
AI 应用开发,还需要意图识别吗?用户输入模糊不清或复杂问题的场景。通过多个处理模块的协同工作,帮助用户找到准确答案,提升用户体验和问题解决效率。
说明:代码以逻辑为主,并非完整可运行。因个人知识有限,难免会出现错误,欢迎批评指正哈,文章略长,建议先收藏,如果喜欢,请多多转发,谢谢😊
核心处理流程概览
用户输入 → 问题预处理 → 意图识别 → 任务拆解 → 问题改写/扩写 → 答案生成与验证 → 最终输出
↓ ↓ ↓ ↓ ↓ ↓
原始文本 标准化文本 意图+实体 子任务列表 明确问题 验证答案
五个关键阶段:
问题预处理:清洗和标准化用户输入
意图识别:理解用户真实需求和意图
任务拆解:基于意图将复杂问题分解为可执行子任务
问题改写/扩写:针对子任务优化问题表达,补充执行信息
答案生成与验证:生成并验证最终答案
核心价值
智能理解:深度理解用户真实意图,避免误解和偏差
意图驱动:基于明确的意图进行任务分解,确保处理方向正确
任务分解:将复杂问题拆解为可执行的子任务,提高处理效率
精准改写:针对分解后的子任务进行问题优化,补充执行所需信息
协同处理:多模块协作,提供全流程的问题处理能力
核心模块及执行顺序
执行顺序设计原理
问题明确化处理遵循"从粗到细、从简到繁"的原则,采用五阶段流水线处理模式:
- 问题预处理 → 2. 意图识别 → 3. 任务拆解 → 4. 问题改写/扩写 → 5. 答案生成与验证
各阶段详细说明
阶段1:问题预处理
目标:标准化用户输入,为后续处理奠定基础
输入:原始用户问题文本
处理:文本清洗、语言检测、语法纠错、敏感词过滤
输出:标准化的问题文本
关键价值:消除噪音,确保后续模块处理的数据质量
阶段2:意图识别
目标:准确理解用户真实需求和意图
输入:预处理后的问题文本
处理:单/多意图分类、置信度评估、实体抽取
输出:意图类型、置信度、相关实体
关键价值:确定处理方向,避免理解偏差
阶段4:任务拆解
目标:将复杂问题分解为可执行的子任务
输入:明确的问题 + 复杂度评估
处理:依赖分析、优先级排序、执行计划生成
输出:有序的子任务列表
关键价值:化繁为简,提高执行效率
阶段4:问题改写/扩写
目标:基于意图优化问题表达,补充缺失信息
输入:原问题 + 意图信息
处理:语法优化、信息补充、歧义消除
输出:优化后的明确问题
关键价值:提升问题质量,减少后续处理的不确定性
阶段5:答案生成与验证
目标:生成准确、完整的最终答案
输入:子任务列表或单一任务
处理:答案生成、质量验证、结果整合
输出:最终答案
关键价值:确保答案质量和用户满意度

问题拆解与逻辑优先级分析
针对用户“模糊不清或复杂的问题”的处理流程,建议按以下顺序执行模块,并解释其逻辑依据:
1. 意图识别(首要步骤)
为什么先做?
所有后续处理(改写、扩写、拆解)都依赖对用户真实意图的准确理解。若意图误判,后续操作会南辕北辙。
示例:用户问“怎么解决电脑问题?”可能是硬件故障、软件崩溃、系统卡顿等,需先明确意图。
关键动作:
通过上下文、关键词、历史交互推断用户核心需求。
若意图模糊,主动追问(如“您是指软件崩溃还是硬件故障?”)。
2. 任务拆解(次优先)
为什么放在第二?
复杂问题需分解为可执行的子任务,但拆解必须基于已识别的意图。
示例:若意图是“优化电商网站性能”,拆解为:测速→定位瓶颈→前端优化→后端调优→数据库索引优化。
关键动作:
将问题映射到知识库中的结构化任务树(如“性能优化→子任务A/B/C”)。
标记依赖关系(如数据库优化需先完成瓶颈分析)。
3. 问题改写/扩写
为什么最后?
改写或扩写是为了补充细节或适配答案格式,但前提是已明确意图和拆解路径。
示例:
原始问题:“如何学Python?” → 扩写为“零基础自学Python到能写爬虫的3个月计划”。
若未先拆解任务,扩写可能偏离用户实际需求(如用户实际想速成数据分析而非爬虫)。
关键动作:
根据拆解的子任务,补充缺失参数(如时间、技能水平、工具偏好)。
将模糊表述转化为可检索的技术术语(如“电脑卡”→“Windows 11内存占用过高”)。
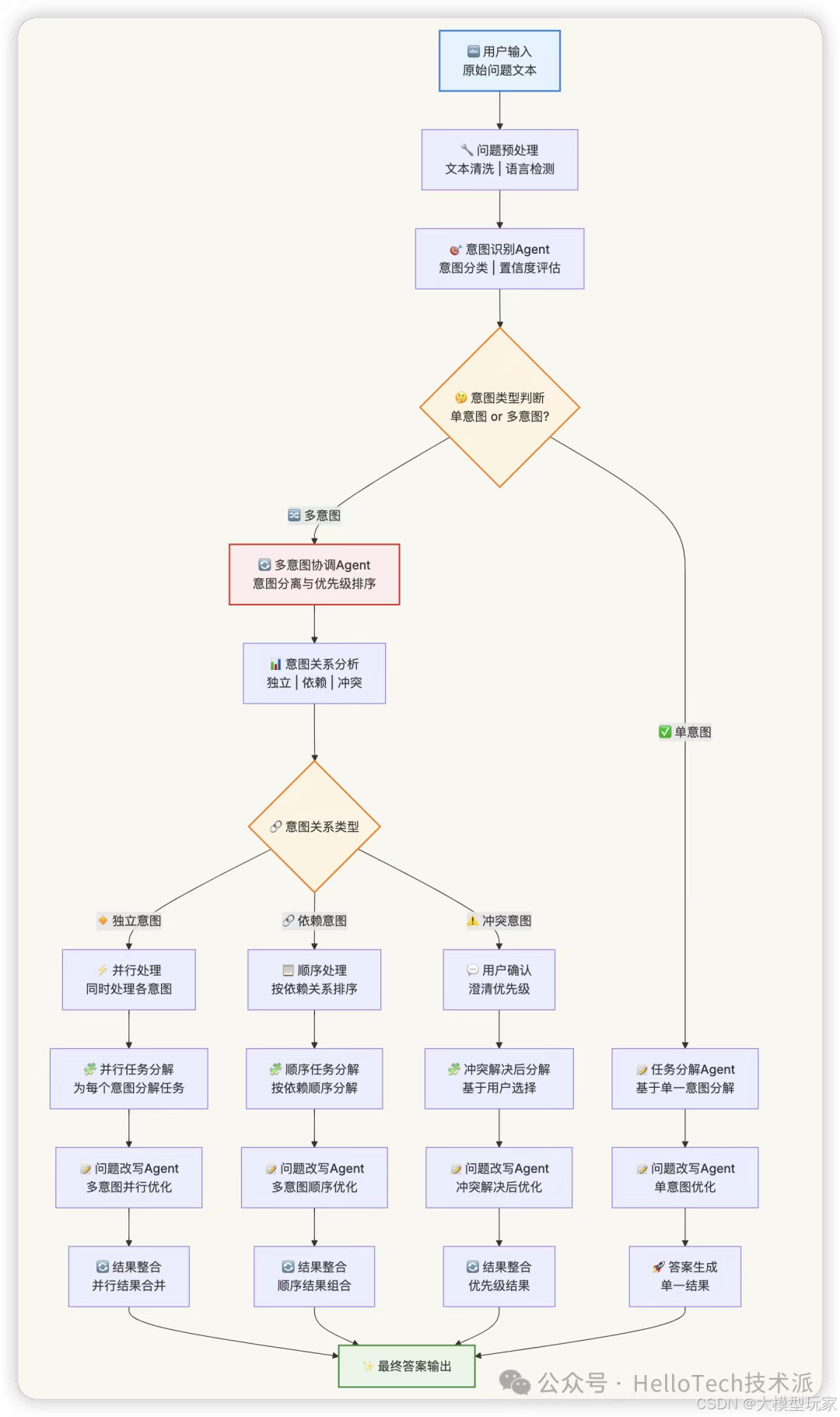
处理流程图

Agent协作架构
多Agent协作设计
- 整体架构图
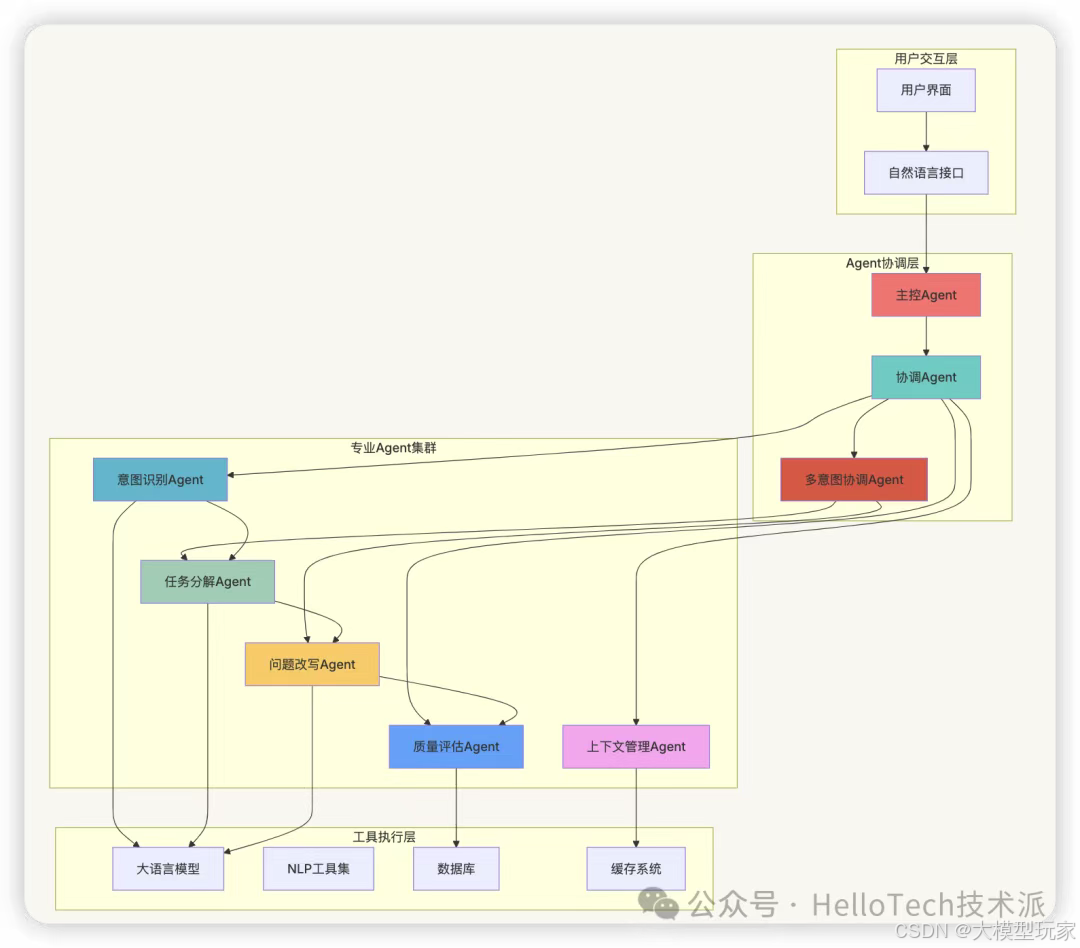
- 多意图处理流程
Agent基础框架
from abc import ABC, abstractmethod
from typing import Dict, List, Any, Optional
import asyncio
import json
import uuid
from datetime import datetime
from enum import Enum
classAgentState(Enum):"""Agent状态枚举"""
IDLE ="idle"
PROCESSING ="processing"
WAITING ="waiting"
ERROR ="error"
COMPLETED ="completed"
classAgentMessage:"""Agent间通信消息"""def__init__(self, sender_id:str, receiver_id:str, message_type: MessageType,
content: Dict[str, Any], correlation_id:str=None):
self.message_id =str(uuid.uuid4())
self.sender_id = sender_id
self.receiver_id = receiver_id
self.message_type = message_type
self.content = content
self.correlation_id = correlation_id orstr(uuid.uuid4())
self.timestamp = datetime.now()
self.processed =False
classAgentMemory:"""Agent记忆管理"""def__init__(self, max_size:int=1000):
self.memory ={}
self.max_size = max_size
self.access_count ={}defupdate(self, key:str, value: Any):"""更新记忆"""iflen(self.memory)>= self.max_size:
self._evict_least_used()
self.memory[key]={'value': value,'timestamp': datetime.now(),'access_count':0}defget(self, key:str)-> Any:"""获取记忆"""if key in self.memory:
self.memory[key]['access_count']+=1return self.memory[key]['value']
returnNone
def_evict_least_used(self):"""淘汰最少使用的记忆"""
ifnot self.memory:return
least_used_key =min(self.memory.keys(),
key=lambda k: self.memory[k]['access_count'])del self.memory[least_used_key]
classBaseAgent(ABC):"""Agent基类"""def__init__(self, agent_id:str, llm_service, message_bus=None):
self.agent_id = agent_id
self.llm_service = llm_service
self.state = AgentState.IDLE
self.memory = AgentMemory()
self.tools ={}
self.message_bus = message_bus
self.message_queue = asyncio.Queue()
self.performance_metrics ={'total_requests':0,'successful_requests':0,'average_response_time':0.0,'error_count':0}
self.created_at = datetime.now()@abstractmethod
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""处理输入数据"""pass@abstractmethoddefget_capabilities(self)-> List[str]:"""获取Agent能力列表"""pass
asyncdef start(self):"""启动Agent"""
self.state = AgentState.IDLE
if self.message_bus:await self.message_bus.subscribe(self.agent_id, self._handle_message)# 启动消息处理循环
asyncio.create_task(self._message_processing_loop())
asyncdef stop(self):"""停止Agent"""
self.state = AgentState.COMPLETED
if self.message_bus:await self.message_bus.unsubscribe(self.agent_id)
asyncdef send_message(self, receiver_id:str, message_type: MessageType,
content: Dict[str, Any], correlation_id:str=None):"""发送消息给其他Agent"""
message = AgentMessage(
sender_id=self.agent_id,
receiver_id=receiver_id,
message_type=message_type,
content=content,
correlation_id=correlation_id
)if self.message_bus:await self.message_bus.send_message(message)
asyncdef _handle_message(self, message: AgentMessage):"""处理接收到的消息"""await self.message_queue.put(message)
asyncdef _message_processing_loop(self):"""消息处理循环"""while self.state != AgentState.COMPLETED:try:
message =await asyncio.wait_for(self.message_queue.get(), timeout=1.0)await self._process_message(message)except asyncio.TimeoutError:continueexcept Exception as e:
self.performance_metrics['error_count']+=1await self._handle_error(e)
asyncdef _process_message(self, message: AgentMessage):"""处理具体消息"""
start_time = datetime.now()try:
self.state = AgentState.PROCESSING
self.performance_metrics['total_requests']+=1if message.message_type == MessageType.REQUEST:
result =await self.process(message.content)# 发送响应await self.send_message(
receiver_id=message.sender_id,
message_type=MessageType.RESPONSE,
content=result,
correlation_id=message.correlation_id
)
self.performance_metrics['successful_requests']+=1except Exception as e:
self.performance_metrics['error_count']+=1# 发送错误响应await self.send_message(
receiver_id=message.sender_id,
message_type=MessageType.ERROR,
content={'error':str(e),'agent_id': self.agent_id},
correlation_id=message.correlation_id
)finally:
self.state = AgentState.IDLE
# 更新性能指标
response_time =(datetime.now()- start_time).total_seconds()
self._update_response_time(response_time)def_update_response_time(self, response_time:float):"""更新响应时间指标"""
current_avg = self.performance_metrics['average_response_time']
total_requests = self.performance_metrics['total_requests']if total_requests ==1:
self.performance_metrics['average_response_time']= response_time
else:
self.performance_metrics['average_response_time']=((current_avg *(total_requests -1)+ response_time)/ total_requests
)
asyncdef _handle_error(self, error: Exception):"""处理错误"""
self.state = AgentState.ERROR
error_info ={'agent_id': self.agent_id,'error_type':type(error).__name__,'error_message':str(error),'timestamp': datetime.now().isoformat()}# 记录错误到内存
self.memory.update(f"error_{datetime.now().timestamp()}", error_info)defget_status(self)-> Dict[str, Any]:"""获取Agent状态"""return{'agent_id': self.agent_id,'state': self.state.value,'capabilities': self.get_capabilities(),'performance_metrics': self.performance_metrics,'uptime':(datetime.now()- self.created_at).total_seconds(),'memory_usage':len(self.memory.memory)}
classMasterCoordinatorAgent(BaseAgent):"""主控协调Agent"""def__init__(self, agent_id:str, llm_service, message_bus=None):super().__init__(agent_id, llm_service, message_bus)
self.agents ={}
self.execution_queue = asyncio.Queue()
self.results_store ={}
self.workflow_templates ={}defget_capabilities(self)-> List[str]:return["workflow_coordination","agent_management","result_integration","error_handling","performance_monitoring"]defregister_agent(self, agent: BaseAgent):"""注册子Agent"""
self.agents[agent.agent_id]= agent
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""协调整个处理流程"""
workflow_id =str(uuid.uuid4())
user_question = input_data.get("user_question","")
context = input_data.get("context",{})try:# 1. 问题预处理
preprocessed =await self._coordinate_preprocessing(user_question, workflow_id)# 2. 意图识别
intent_result =await self._coordinate_intent_recognition(
preprocessed, context, workflow_id
)# 3. 策略选择和执行
strategy_result =await self._coordinate_strategy_execution(
intent_result, preprocessed, workflow_id
)# 4. 结果整合
final_result =await self._integrate_results(strategy_result, workflow_id)return final_result
except Exception as e:
returnawait self._handle_workflow_error(e, workflow_id)
asyncdef _coordinate_preprocessing(self, question:str, workflow_id:str)->str:"""协调问题预处理"""
if"question_preprocessor"notin self.agents:# 如果没有专门的预处理Agent,使用内置处理return question.strip()
response =await self._send_request_and_wait("question_preprocessor",{"question": question,"workflow_id": workflow_id})return response.get("processed_question", question)
asyncdef _coordinate_intent_recognition(self, question:str, context: Dict,
workflow_id:str)-> Dict:"""协调意图识别"""
if"intent_recognition"notin self.agents:raise ValueError("Intent recognition agent not found")
response =await self._send_request_and_wait("intent_recognition",{"question": question,"context": context,"workflow_id": workflow_id
})return response
asyncdef _coordinate_strategy_execution(self, intent_result: Dict,
question:str, workflow_id:str)-> Dict:"""协调策略执行"""
strategy_type = intent_result.get("recommended_strategy")if strategy_type =="MULTI_TURN":
returnawait self._execute_multi_turn_strategy(intent_result, question, workflow_id)elif strategy_type =="REWRITE_EXPAND":
returnawait self._execute_rewrite_strategy(intent_result, question, workflow_id)elif strategy_type =="SUBTASK_DECOMPOSE":
returnawait self._execute_decompose_strategy(intent_result, question, workflow_id)else:
returnawait self._execute_hybrid_strategy(intent_result, question, workflow_id)
asyncdef _send_request_and_wait(self, agent_id:str, content: Dict,
timeout:float=30.0)-> Dict:"""发送请求并等待响应"""
correlation_id =str(uuid.uuid4())# 发送请求await self.send_message(
receiver_id=agent_id,
message_type=MessageType.REQUEST,
content=content,
correlation_id=correlation_id
)# 等待响应
start_time = datetime.now()while(datetime.now()- start_time).total_seconds()< timeout:try:
message =await asyncio.wait_for(self.message_queue.get(), timeout=1.0)if(message.correlation_id == correlation_id and
message.sender_id == agent_id):if message.message_type == MessageType.RESPONSE:return message.content
elif message.message_type == MessageType.ERROR:raise Exception(f"Agent {agent_id} error: {message.content}")# 如果不是期望的消息,放回队列await self.message_queue.put(message)except asyncio.TimeoutError:continueraise TimeoutError(f"Timeout waiting for response from agent {agent_id}")
asyncdef _execute_multi_turn_strategy(self, intent_result: Dict,
question:str, workflow_id:str)-> Dict:"""执行多轮对话策略"""
clarification_agent ="clarification_agent"
response =await self._send_request_and_wait(
clarification_agent,{"question": question,"intent_result": intent_result,"workflow_id": workflow_id
})return response
asyncdef _execute_rewrite_strategy(self, intent_result: Dict,
question:str, workflow_id:str)-> Dict:"""执行问题改写策略"""
rewrite_agent ="question_rewriter"
response =await self._send_request_and_wait(
rewrite_agent,{"question": question,"intent_result": intent_result,"workflow_id": workflow_id
})return response
asyncdef _execute_decompose_strategy(self, intent_result: Dict,
question:str, workflow_id:str)-> Dict:"""执行任务分解策略"""
decompose_agent ="task_decomposer"
response =await self._send_request_and_wait(
decompose_agent,{"question": question,"intent_result": intent_result,"workflow_id": workflow_id
})return response
asyncdef _execute_hybrid_strategy(self, intent_result: Dict,
question:str, workflow_id:str)-> Dict:"""执行混合策略"""# 根据问题复杂度选择多个Agent协作
complexity = intent_result.get("complexity_score",0.5)if complexity >0.8:# 高复杂度:先分解再改写
decompose_result =await self._execute_decompose_strategy(
intent_result, question, workflow_id
)
returnawait self._execute_rewrite_strategy(
decompose_result, question, workflow_id
)else:# 中等复杂度:直接改写
returnawait self._execute_rewrite_strategy(
intent_result, question, workflow_id
)
asyncdef _integrate_results(self, strategy_result: Dict, workflow_id:str)-> Dict:"""整合处理结果"""
integration_prompt =f"""
请整合以下处理结果,生成最终的用户回复:
处理结果:{json.dumps(strategy_result, ensure_ascii=False, indent=2)}
要求:
1. 提供清晰、准确的答案
2. 如果是多轮对话,生成合适的澄清问题
3. 确保回复符合用户意图
4. 保持专业和友好的语调
请以JSON格式返回:
{{
"final_answer": "最终答案",
"confidence_score": 0.95,
"clarification_needed": false,
"clarification_questions": [],
"metadata": {{
"workflow_id": "{workflow_id}",
"processing_time": "处理时间",
"strategy_used": "使用的策略"
}}
}}
"""
result =await self.llm_service.generate(
prompt=integration_prompt,
max_tokens=500,
temperature=0.3)try:return json.loads(result)except json.JSONDecodeError:return{"final_answer": result,"confidence_score":0.7,"clarification_needed":False,"clarification_questions":[],"metadata":{"workflow_id": workflow_id,"strategy_used":"integration"}}
asyncdef _handle_workflow_error(self, error: Exception, workflow_id:str)-> Dict:"""处理工作流错误"""
error_info ={"error":True,"error_type":type(error).__name__,"error_message":str(error),"workflow_id": workflow_id,"timestamp": datetime.now().isoformat()}# 记录错误
self.memory.update(f"workflow_error_{workflow_id}", error_info)return{"final_answer":"抱歉,处理您的问题时遇到了技术问题,请稍后重试或联系技术支持。","confidence_score":0.0,"clarification_needed":False,"error":True,"error_details": error_info
}
Agent 实现
1. 问题预处理Agent
classQuestionPreprocessorAgent(BaseAgent):"""问题预处理Agent"""def__init__(self, agent_id:str, llm_service, message_bus=None):super().__init__(agent_id, llm_service, message_bus)
self.preprocessing_tools ={'text_cleaner': TextCleaner(),'language_detector': LanguageDetector(),'grammar_checker': GrammarChecker()}defget_capabilities(self)-> List[str]:return["text_cleaning","language_detection","grammar_correction","noise_removal","format_standardization"]
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""预处理用户问题"""
question = input_data.get("question","")
workflow_id = input_data.get("workflow_id","")# 1. 文本清洗
cleaned_text =await self._clean_text(question)# 2. 语言检测
language =await self._detect_language(cleaned_text)# 3. 语法纠错
corrected_text =await self._correct_grammar(cleaned_text, language)# 4. 格式标准化
standardized_text =await self._standardize_format(corrected_text)# 5. 质量评估
quality_score =await self._assess_quality(question, standardized_text)
result ={"processed_question": standardized_text,"original_question": question,"language": language,"quality_improvement": quality_score,"preprocessing_metadata":{"workflow_id": workflow_id,"processing_steps":["text_cleaning","language_detection","grammar_correction","format_standardization"],"timestamp": datetime.now().isoformat()}}# 更新记忆
self.memory.update(f"preprocessing_{workflow_id}", result)return result
asyncdef _clean_text(self, text:str)->str:"""文本清洗"""# 移除多余空格、特殊字符等import re
# 移除多余空格
text = re.sub(r'\s+',' ', text)# 移除特殊字符(保留基本标点)
text = re.sub(r'[^\w\s\u4e00-\u9fff.,!?;:()\[\]{}"\'-]','', text)return text.strip()
asyncdef _detect_language(self, text:str)->str:"""语言检测"""# 简单的语言检测逻辑
chinese_chars =len(re.findall(r'[\u4e00-\u9fff]', text))
total_chars =len(text)if chinese_chars /max(total_chars,1)>0.3:return"zh"else:return"en"
asyncdef _correct_grammar(self, text:str, language:str)->str:"""语法纠错"""
grammar_prompt =f"""
请对以下{language}文本进行语法纠错,保持原意不变:
原文:{text}
要求:
1. 纠正语法错误
2. 保持原意不变
3. 使用标准表达
4. 只返回纠错后的文本
"""
corrected =await self.llm_service.generate(
prompt=grammar_prompt,
max_tokens=200,
temperature=0.1)return corrected.strip()
asyncdef _standardize_format(self, text:str)->str:"""格式标准化"""# 标准化标点符号
text = text.replace('?','?').replace('!','!')
text = text.replace(',',',').replace('。','.')# 确保问句以问号结尾
ifnot text.endswith(('?','?','.','。','!','!')):ifany(word in text.lower()for word in['what','how','why','when','where','who','什么','怎么','为什么','什么时候','哪里','谁']):
text +='?'else:
text +='.'return text
asyncdef _assess_quality(self, original:str, processed:str)->float:"""评估处理质量"""# 简单的质量评估
improvements =0
total_checks =4# 检查长度合理性
if5 <=len(processed)<=500:
improvements +=1# 检查是否有改进iflen(processed)>=len(original)*0.8:
improvements +=1# 检查标点符号if processed.endswith(('.','?','!','。','?','!')):
improvements +=1# 检查空格规范
ifnot re.search(r'\s{2,}', processed):
improvements +=1return improvements / total_checks
2. 意图识别Agent
classIntentRecognitionAgent(BaseAgent):"""意图识别Agent"""def__init__(self, agent_id:str, llm_service, message_bus=None):super().__init__(agent_id, llm_service, message_bus)
self.intent_categories ={"INFORMATION_SEEKING":"信息查询","PROBLEM_SOLVING":"问题解决","TASK_EXECUTION":"任务执行","CREATIVE_GENERATION":"创意生成","ANALYSIS_COMPARISON":"分析比较","EXPLANATION_TEACHING":"解释教学"}defget_capabilities(self)-> List[str]:return["intent_classification","entity_extraction","confidence_assessment","context_analysis","strategy_recommendation"]
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""识别用户意图"""
question = input_data.get("question","")
context = input_data.get("context",{})
workflow_id = input_data.get("workflow_id","")# 1. 意图分类
intent_result =await self._classify_intent(question, context)# 2. 实体抽取
entities =await self._extract_entities(question)# 3. 复杂度评估
complexity =await self._assess_complexity(question, intent_result)# 4. 策略推荐
strategy =await self._recommend_strategy(intent_result, complexity, entities)
result ={"intent_type": intent_result["intent_type"],"confidence_score": intent_result["confidence"],"entities": entities,"complexity_score": complexity,"recommended_strategy": strategy,"intent_metadata":{"workflow_id": workflow_id,"analysis_timestamp": datetime.now().isoformat(),"context_used":bool(context)}}# 更新记忆
self.memory.update(f"intent_{workflow_id}", result)return result
asyncdef _classify_intent(self, question:str, context: Dict)-> Dict:"""意图分类"""
intent_prompt =f"""
请分析以下用户问题的意图类型:
问题:{question}
上下文:{json.dumps(context, ensure_ascii=False)if context else'无'}
可选意图类型:
- INFORMATION_SEEKING: 信息查询(寻找特定信息、事实、数据)
- PROBLEM_SOLVING: 问题解决(解决具体问题、故障排除)
- TASK_EXECUTION: 任务执行(执行特定操作、完成任务)
- CREATIVE_GENERATION: 创意生成(创作内容、生成想法)
- ANALYSIS_COMPARISON: 分析比较(对比分析、评估)
- EXPLANATION_TEACHING: 解释教学(学习理解、概念解释)
请以JSON格式返回:
{{
"intent_type": "主要意图类型",
"secondary_intents": ["次要意图类型列表"],
"confidence": 0.95,
"reasoning": "分析理由"
}}
"""
result =await self.llm_service.generate(
prompt=intent_prompt,
max_tokens=300,
temperature=0.2)try:return json.loads(result)except json.JSONDecodeError:return{"intent_type":"INFORMATION_SEEKING","secondary_intents":[],"confidence":0.5,"reasoning":"解析失败,使用默认意图"}
asyncdef _extract_entities(self, question:str)-> List[Dict]:"""实体抽取"""
entity_prompt =f"""
请从以下问题中抽取关键实体:
问题:{question}
请识别以下类型的实体:
- PERSON: 人名
- ORGANIZATION: 组织机构
- LOCATION: 地点
- TIME: 时间
- PRODUCT: 产品
- CONCEPT: 概念术语
- NUMBER: 数字
请以JSON格式返回:
[
{{
"text": "实体文本",
"type": "实体类型",
"confidence": 0.95
}}
]
"""
result =await self.llm_service.generate(
prompt=entity_prompt,
max_tokens=200,
temperature=0.1)try:return json.loads(result)except json.JSONDecodeError:return[]
asyncdef _assess_complexity(self, question:str, intent_result: Dict)->float:"""评估问题复杂度"""
complexity_factors ={"length":min(len(question)/100,1.0),"intent_confidence":1.0- intent_result.get("confidence",0.5),"secondary_intents":len(intent_result.get("secondary_intents",[]))*0.2,"question_marks": question.count('?')*0.1}# 计算加权复杂度
weights ={"length":0.3,"intent_confidence":0.4,"secondary_intents":0.2,"question_marks":0.1}
complexity =sum(complexity_factors[k]* weights[k]for k in weights)returnmin(complexity,1.0)
asyncdef _recommend_strategy(self, intent_result: Dict, complexity:float, entities: List)->str:"""推荐处理策略"""
intent_type = intent_result.get("intent_type","INFORMATION_SEEKING")
confidence = intent_result.get("confidence",0.5)# 策略决策逻辑if confidence <0.6or complexity >0.8:return"MULTI_TURN"# 多轮对话澄清elif intent_type in["CREATIVE_GENERATION","ANALYSIS_COMPARISON"]and complexity >0.5:return"SUBTASK_DECOMPOSE"# 任务分解eliflen(entities)< 2or complexity >0.6:return"REWRITE_EXPAND"# 问题改写扩展else:return"DIRECT_ANSWER"# 直接回答
3. 问题改写Agent
classQuestionRewriterAgent(BaseAgent):"""问题改写Agent"""def__init__(self, agent_id:str, llm_service, message_bus=None):super().__init__(agent_id, llm_service, message_bus)
self.rewrite_strategies ={"EXPAND":"扩展详细化","CLARIFY":"澄清模糊点","RESTRUCTURE":"重新组织","SIMPLIFY":"简化表达"}defget_capabilities(self)-> List[str]:return["question_expansion","ambiguity_clarification","structure_optimization","context_enrichment"]
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""改写用户问题"""
question = input_data.get("question","")
intent_result = input_data.get("intent_result",{})
workflow_id = input_data.get("workflow_id","")# 1. 选择改写策略
strategy =await self._select_rewrite_strategy(question, intent_result)# 2. 执行问题改写
rewritten_question =await self._rewrite_question(question, strategy, intent_result)# 3. 生成相关问题
related_questions =await self._generate_related_questions(rewritten_question)# 4. 质量评估
quality_score =await self._evaluate_rewrite_quality(question, rewritten_question)
result ={"rewritten_question": rewritten_question,"original_question": question,"rewrite_strategy": strategy,"related_questions": related_questions,"quality_score": quality_score,"rewrite_metadata":{"workflow_id": workflow_id,"timestamp": datetime.now().isoformat(),"intent_type": intent_result.get("intent_type","unknown")}}# 更新记忆
self.memory.update(f"rewrite_{workflow_id}", result)return result
asyncdef _select_rewrite_strategy(self, question:str, intent_result: Dict)->str:"""选择改写策略"""
intent_type = intent_result.get("intent_type","INFORMATION_SEEKING")
confidence = intent_result.get("confidence",0.5)
complexity = intent_result.get("complexity_score",0.5)if confidence <0.6:return"CLARIFY"elif complexity >0.7:return"SIMPLIFY"eliflen(question)<20:return"EXPAND"else:return"RESTRUCTURE"
asyncdef _rewrite_question(self, question:str, strategy:str, intent_result: Dict)->str:"""执行问题改写"""
strategy_prompts ={"EXPAND":f"""
请将以下简短问题扩展为更详细、更具体的问题:
原问题:{question}
意图类型:{intent_result.get('intent_type','unknown')}
要求:
1. 保持原意不变
2. 增加必要的背景信息
3. 明确具体需求
4. 使问题更容易理解和回答
""","CLARIFY":f"""
请澄清以下模糊问题中的不明确之处:
原问题:{question}
意图类型:{intent_result.get('intent_type','unknown')}
要求:
5. 识别模糊或歧义的部分
6. 提供更明确的表达
7. 保持问题的核心意图
8. 使问题更加精确
""","RESTRUCTURE":f"""
请重新组织以下问题的结构,使其更清晰:
原问题:{question}
意图类型:{intent_result.get('intent_type','unknown')}
要求:
9. 优化问题结构
10. 突出关键信息
11. 使逻辑更清晰
12. 便于理解和回答
""","SIMPLIFY":f"""
请简化以下复杂问题,使其更容易理解:
原问题:{question}
意图类型:{intent_result.get('intent_type','unknown')}
要求:
13. 保留核心要点
14. 简化表达方式
15. 去除冗余信息
16. 使问题更直接明了
"""}
prompt = strategy_prompts.get(strategy, strategy_prompts["RESTRUCTURE"])
rewritten =await self.llm_service.generate(
prompt=prompt,
max_tokens=300,
temperature=0.3)return rewritten.strip()
asyncdef _generate_related_questions(self, question:str)-> List[str]:"""生成相关问题"""
related_prompt =f"""
基于以下问题,生成3个相关的问题:
主问题:{question}
要求:
1. 相关但不重复
2. 能够补充主问题的信息
3. 有助于全面理解主题
4. 每个问题一行
格式:
5. 问题1
6. 问题2
7. 问题3
"""
result =await self.llm_service.generate(
prompt=related_prompt,
max_tokens=200,
temperature=0.5)# 解析相关问题
lines = result.strip().split('\n')
related_questions =[]for line in lines:if line.strip()andany(line.startswith(str(i))for i inrange(1,10)):
question = line.split('.',1)[-1].strip()if question:
related_questions.append(question)return related_questions[:3]
asyncdef _evaluate_rewrite_quality(self, original:str, rewritten:str)->float:"""评估改写质量"""
evaluation_prompt =f"""
请评估以下问题改写的质量(0-1分):
原问题:{original}
改写后:{rewritten}
评估维度:
8. 意图保持度(是否保持原意)
9. 清晰度提升(是否更清晰)
10. 完整性(信息是否完整)
11. 可回答性(是否更容易回答)
请只返回一个0-1之间的数字,表示总体质量分数。
"""
result =await self.llm_service.generate(
prompt=evaluation_prompt,
max_tokens=50,
temperature=0.1)try:
score =float(result.strip())returnmax(0.0,min(1.0, score))except ValueError:
return0.7# 默认分数
4. 任务分解Agent
classTaskDecomposerAgent(BaseAgent):"""任务分解Agent"""def__init__(self, agent_id:str, llm_service, message_bus=None):super().__init__(agent_id, llm_service, message_bus)
self.decomposition_patterns ={"SEQUENTIAL":"顺序分解","PARALLEL":"并行分解","HIERARCHICAL":"层次分解","CONDITIONAL":"条件分解"}defget_capabilities(self)-> List[str]:return["task_decomposition","dependency_analysis","priority_assignment","execution_planning"]
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""分解复杂任务"""
question = input_data.get("question","")
intent_result = input_data.get("intent_result",{})
workflow_id = input_data.get("workflow_id","")# 1. 分析任务复杂度
complexity_analysis =await self._analyze_task_complexity(question, intent_result)# 2. 选择分解模式
decomposition_pattern =await self._select_decomposition_pattern(complexity_analysis)# 3. 执行任务分解
subtasks =await self._decompose_task(question, decomposition_pattern, intent_result)# 4. 分析依赖关系
dependencies =await self._analyze_dependencies(subtasks)# 5. 分配优先级
prioritized_tasks =await self._assign_priorities(subtasks, dependencies)
result ={"subtasks": prioritized_tasks,"decomposition_pattern": decomposition_pattern,"dependencies": dependencies,"complexity_analysis": complexity_analysis,"execution_plan":await self._create_execution_plan(prioritized_tasks, dependencies),"decomposition_metadata":{"workflow_id": workflow_id,"timestamp": datetime.now().isoformat(),"original_question": question
}}# 更新记忆
self.memory.update(f"decomposition_{workflow_id}", result)return result
asyncdef _analyze_task_complexity(self, question:str, intent_result: Dict)-> Dict:"""分析任务复杂度"""
analysis_prompt =f"""
请分析以下任务的复杂度:
任务:{question}
意图类型:{intent_result.get('intent_type','unknown')}
请从以下维度分析:
1. 步骤数量(需要多少个步骤)
2. 知识领域(涉及多少个领域)
3. 依赖关系(步骤间的依赖复杂度)
4. 时间跨度(完成所需时间)
5. 资源需求(需要的资源类型)
请以JSON格式返回:
{{
"step_count": 5,
"domain_count": 2,
"dependency_complexity": "medium",
"time_span": "short",
"resource_types": ["information", "computation"],
"overall_complexity": 0.7
}}
"""
result =await self.llm_service.generate(
prompt=analysis_prompt,
max_tokens=300,
temperature=0.2)try:return json.loads(result)except json.JSONDecodeError:return{"step_count":3,"domain_count":1,"dependency_complexity":"low","time_span":"short","resource_types":["information"],"overall_complexity":0.5}
asyncdef _select_decomposition_pattern(self, complexity_analysis: Dict)->str:"""选择分解模式"""
complexity = complexity_analysis.get("overall_complexity",0.5)
step_count = complexity_analysis.get("step_count",3)
dependency = complexity_analysis.get("dependency_complexity","low")if dependency =="high"or step_count >7:return"HIERARCHICAL"elif dependency =="low"and step_count <=5:return"PARALLEL"elif complexity >0.8:return"CONDITIONAL"else:return"SEQUENTIAL"
asyncdef _decompose_task(self, question:str, pattern:str, intent_result: Dict)-> List[Dict]:"""执行任务分解"""
decomposition_prompt =f"""
请使用{pattern}模式分解以下任务:
任务:{question}
意图类型:{intent_result.get('intent_type','unknown')}
分解模式:{pattern}
要求:
6. 将复杂任务分解为可执行的子任务
7. 每个子任务应该明确、具体
8. 子任务之间逻辑清晰
9. 考虑实际执行的可行性
请以JSON格式返回:
[
{{
"id": "task_1",
"title": "子任务标题",
"description": "详细描述",
"type": "information_gathering",
"estimated_time": "5分钟",
"required_resources": ["搜索引擎", "数据库"]
}}
]
"""
result =await self.llm_service.generate(
prompt=decomposition_prompt,
max_tokens=500,
temperature=0.3)try:return json.loads(result)except json.JSONDecodeError:# 返回默认分解结果return[{"id":"task_1","title":"信息收集","description":"收集相关信息和资料","type":"information_gathering","estimated_time":"5分钟","required_resources":["搜索"]},{"id":"task_2","title":"分析处理","description":"分析收集的信息","type":"analysis","estimated_time":"3分钟","required_resources":["分析工具"]},{"id":"task_3","title":"结果整合","description":"整合分析结果","type":"integration","estimated_time":"2分钟","required_resources":["整合工具"]}]
asyncdef _analyze_dependencies(self, subtasks: List[Dict])-> Dict:"""分析依赖关系"""iflen(subtasks)<=1:return{}
dependency_prompt =f"""
请分析以下子任务之间的依赖关系:
子任务列表:
{json.dumps(subtasks, ensure_ascii=False, indent=2)}
请识别:
10. 哪些任务必须按顺序执行
11. 哪些任务可以并行执行
12. 哪些任务依赖其他任务的输出
请以JSON格式返回:
{{
"sequential_pairs": [["task_1", "task_2"]],
"parallel_groups": [["task_3", "task_4"]],
"dependencies": {{
"task_2": ["task_1"],
"task_3": ["task_1", "task_2"]
}}
}}
"""
result =await self.llm_service.generate(
prompt=dependency_prompt,
max_tokens=300,
temperature=0.2)try:return json.loads(result)except json.JSONDecodeError:# 返回默认依赖关系(顺序执行)
task_ids =[task["id"]for task in subtasks]
dependencies ={}for i inrange(1,len(task_ids)):
dependencies[task_ids[i]]=[task_ids[i-1]]return{"sequential_pairs":[[task_ids[i], task_ids[i+1]]for i inrange(len(task_ids)-1)],"parallel_groups":[],"dependencies": dependencies
}
asyncdef _assign_priorities(self, subtasks: List[Dict], dependencies: Dict)-> List[Dict]:"""分配优先级"""# 基于依赖关系计算优先级
task_priorities ={}
dependency_map = dependencies.get("dependencies",{})for task in subtasks:
task_id = task["id"]# 计算依赖深度作为优先级
priority = self._calculate_priority(task_id, dependency_map,set())
task_priorities[task_id]= priority
# 为每个任务添加优先级for task in subtasks:
task["priority"]= task_priorities.get(task["id"],1)# 按优先级排序returnsorted(subtasks, key=lambda x: x["priority"])def_calculate_priority(self, task_id:str, dependency_map: Dict, visited:set)->int:"""递归计算任务优先级"""if task_id in visited:
return1# 避免循环依赖
visited.add(task_id)
dependencies = dependency_map.get(task_id,[])
ifnot dependencies:
return1
max_dep_priority =max(
self._calculate_priority(dep, dependency_map, visited.copy())for dep in dependencies
)return max_dep_priority +1
asyncdef _create_execution_plan(self, prioritized_tasks: List[Dict], dependencies: Dict)-> Dict:"""创建执行计划"""return{"total_tasks":len(prioritized_tasks),"estimated_total_time":sum(int(task.get("estimated_time","5分钟").replace("分钟",""))for task in prioritized_tasks
),"execution_order":[task["id"]for task in prioritized_tasks],"parallel_opportunities": dependencies.get("parallel_groups",[]),"critical_path": self._find_critical_path(prioritized_tasks, dependencies)}def_find_critical_path(self, tasks: List[Dict], dependencies: Dict)-> List[str]:"""找到关键路径"""# 简化的关键路径算法
dependency_map = dependencies.get("dependencies",{})# 找到没有依赖的起始任务
start_tasks =[task["id"]for task in tasks if task["id"] notin dependency_map]
ifnot start_tasks:return[tasks[0]["id"]]if tasks else[]# 找到最长路径
longest_path =[]for start_task in start_tasks:
path = self._find_longest_path(start_task, dependency_map, tasks)iflen(path)>len(longest_path):
longest_path = path
return longest_path
def_find_longest_path(self, task_id:str, dependency_map: Dict, tasks: List[Dict])-> List[str]:"""找到从指定任务开始的最长路径"""# 找到依赖当前任务的任务
dependent_tasks =[tid for tid, deps in dependency_map.items()if task_id in deps]
ifnot dependent_tasks:return[task_id]
longest_sub_path =[]for dep_task in dependent_tasks:
sub_path = self._find_longest_path(dep_task, dependency_map, tasks)iflen(sub_path)>len(longest_sub_path):
longest_sub_path = sub_path
return[task_id]+ longest_sub_path
5. 多意图协调Agent
classMultiIntentCoordinatorAgent(BaseAgent):"""多意图协调Agent"""def__init__(self, agent_id:str, llm_service, message_bus=None):super().__init__(agent_id, llm_service, message_bus)
self.intent_relationship_types ={"INDEPENDENT":"独立意图","DEPENDENT":"依赖意图","CONFLICTING":"冲突意图","COMPLEMENTARY":"互补意图","HIERARCHICAL":"层次意图"}
self.processing_strategies ={"PARALLEL":"并行处理","SEQUENTIAL":"顺序处理","PRIORITY_BASED":"优先级处理","USER_GUIDED":"用户引导处理"}defget_capabilities(self)-> List[str]:return["multi_intent_detection","intent_separation","relationship_analysis","priority_assignment","conflict_resolution","parallel_coordination","result_integration"]
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""处理多意图协调"""
question = input_data.get("question","")
intent_result = input_data.get("intent_result",{})
workflow_id = input_data.get("workflow_id","")# 1. 检测是否为多意图
is_multi_intent =await self._detect_multi_intent(question, intent_result)
ifnot is_multi_intent:# 单意图,直接返回原始结果return{"is_multi_intent":False,"intent_result": intent_result,"processing_strategy":"SINGLE_INTENT","workflow_id": workflow_id
}# 2. 分离多个意图
separated_intents =await self._separate_intents(question, intent_result)# 3. 分析意图关系
intent_relationships =await self._analyze_intent_relationships(separated_intents)# 4. 确定处理策略
processing_strategy =await self._determine_processing_strategy(intent_relationships)# 5. 分配优先级
prioritized_intents =await self._assign_intent_priorities(separated_intents, intent_relationships)# 6. 处理冲突(如果存在)
conflict_resolution =await self._resolve_conflicts(prioritized_intents, intent_relationships)
result ={"is_multi_intent":True,"separated_intents": prioritized_intents,"intent_relationships": intent_relationships,"processing_strategy": processing_strategy,"conflict_resolution": conflict_resolution,"coordination_plan":await self._create_coordination_plan(prioritized_intents, processing_strategy),"multi_intent_metadata":{"workflow_id": workflow_id,"timestamp": datetime.now().isoformat(),"original_question": question,"intent_count":len(separated_intents)}}# 更新记忆
self.memory.update(f"multi_intent_{workflow_id}", result)return result
asyncdef _detect_multi_intent(self, question:str, intent_result: Dict)->bool:"""检测是否为多意图"""# 检查是否有次要意图
secondary_intents = intent_result.get("secondary_intents",[])if secondary_intents:
returnTrue
# 使用LLM进行多意图检测
detection_prompt =f"""
请分析以下问题是否包含多个意图:
问题:{question}
主要意图:{intent_result.get('intent_type','unknown')}
判断标准:
1. 是否包含多个动作或请求
2. 是否涉及多个不同的主题
3. 是否有连接词("和"、"还有"、"另外"等)
4. 是否有条件分支("如果...那么...")
请以JSON格式返回:
{{
"is_multi_intent": true/false,
"intent_count": 数字,
"reasoning": "判断理由",
"confidence": 0.95
}}
"""
result =await self.llm_service.generate(
prompt=detection_prompt,
max_tokens=200,
temperature=0.2)try:
detection_result = json.loads(result)return detection_result.get("is_multi_intent",False)except json.JSONDecodeError:returnlen(secondary_intents)>0
asyncdef _separate_intents(self, question:str, intent_result: Dict)-> List[Dict]:"""分离多个意图"""
separation_prompt =f"""
请将以下包含多个意图的问题分离为独立的子意图:
原问题:{question}
主要意图:{intent_result.get('intent_type','unknown')}
要求:
5. 每个子意图应该是完整的、可独立处理的
6. 保持原问题的完整语义
7. 标识每个意图的类型和优先级
8. 提取相关实体信息
请以JSON格式返回:
{{
"intents": [
{{
"id": "intent_1",
"type": "INFORMATION_SEEKING",
"description": "具体意图描述",
"question": "独立的问题表述",
"entities": ["实体1", "实体2"],
"priority": "high/medium/low",
"confidence": 0.9
}}
]
}}
"""
result =await self.llm_service.generate(
prompt=separation_prompt,
max_tokens=500,
temperature=0.3)try:
separation_result = json.loads(result)return separation_result.get("intents",[])except json.JSONDecodeError:# 回退策略:基于主要意图创建单一意图return[{"id":"intent_1","type": intent_result.get("intent_type","INFORMATION_SEEKING"),"description":"主要意图","question": question,"entities": intent_result.get("entities",{}),"priority":"high","confidence": intent_result.get("confidence",0.8)}]
asyncdef _analyze_intent_relationships(self, intents: List[Dict])-> Dict:"""分析意图关系"""iflen(intents)<=1:return{"relationship_type":"SINGLE","relationships":[]}
analysis_prompt =f"""
请分析以下多个意图之间的关系:
意图列表:
{json.dumps(intents, ensure_ascii=False, indent=2)}
关系类型:
- INDEPENDENT: 独立意图,可以并行处理
- DEPENDENT: 依赖关系,需要按顺序处理
- CONFLICTING: 冲突关系,需要用户选择
- COMPLEMENTARY: 互补关系,结合处理效果更好
- HIERARCHICAL: 层次关系,主次分明
请以JSON格式返回:
{{
"overall_relationship": "主要关系类型",
"pairwise_relationships": [
{{
"intent1_id": "intent_1",
"intent2_id": "intent_2",
"relationship": "DEPENDENT",
"description": "关系描述"
}}
],
"processing_order": ["intent_1", "intent_2"],
"parallel_groups": [["intent_1"], ["intent_2"]]
}}
"""
result =await self.llm_service.generate(
prompt=analysis_prompt,
max_tokens=400,
temperature=0.2)try:return json.loads(result)except json.JSONDecodeError:# 回退策略:假设所有意图独立return{"overall_relationship":"INDEPENDENT","pairwise_relationships":[],"processing_order":[intent["id"]for intent in intents],"parallel_groups":[[intent["id"]]for intent in intents]}
asyncdef _determine_processing_strategy(self, relationships: Dict)->str:"""确定处理策略"""
overall_relationship = relationships.get("overall_relationship","INDEPENDENT")
strategy_mapping ={"INDEPENDENT":"PARALLEL","DEPENDENT":"SEQUENTIAL","CONFLICTING":"USER_GUIDED","COMPLEMENTARY":"PARALLEL","HIERARCHICAL":"PRIORITY_BASED"}return strategy_mapping.get(overall_relationship,"SEQUENTIAL")
asyncdef _assign_intent_priorities(self, intents: List[Dict], relationships: Dict)-> List[Dict]:"""分配意图优先级"""# 基于关系分析调整优先级
processing_order = relationships.get("processing_order",[])for i, intent inenumerate(intents):if intent["id"]in processing_order:# 基于处理顺序分配优先级
order_index = processing_order.index(intent["id"])
intent["computed_priority"]=len(processing_order)- order_index
else:# 基于原始优先级
priority_map ={"high":3,"medium":2,"low":1}
intent["computed_priority"]= priority_map.get(intent.get("priority","medium"),2)# 按计算优先级排序returnsorted(intents, key=lambda x: x.get("computed_priority",2), reverse=True)
asyncdef _resolve_conflicts(self, intents: List[Dict], relationships: Dict)-> Dict:"""解决意图冲突"""
overall_relationship = relationships.get("overall_relationship","INDEPENDENT")if overall_relationship !="CONFLICTING":return{"has_conflicts":False,"resolution":None}# 生成冲突解决方案
conflict_prompt =f"""
检测到以下意图存在冲突,请提供解决方案:
冲突意图:
{json.dumps(intents, ensure_ascii=False, indent=2)}
请提供以下解决方案:
1. 用户确认问题(帮助用户选择)
2. 推荐的处理顺序
3. 可能的合并方案
请以JSON格式返回:
{{
"clarification_questions": ["您是想要...还是...?"],
"recommended_order": ["intent_1", "intent_2"],
"merge_suggestions": ["可以将...合并为..."],
"default_choice": "intent_1"
}}
"""
result =await self.llm_service.generate(
prompt=conflict_prompt,
max_tokens=300,
temperature=0.3)try:
resolution = json.loads(result)return{"has_conflicts":True,"resolution": resolution}except json.JSONDecodeError:return{"has_conflicts":True,"resolution":{"clarification_questions":["请明确您的主要需求是什么?"],"recommended_order":[intent["id"]for intent in intents],"merge_suggestions":[],"default_choice": intents[0]["id"]if intents elseNone
}}
asyncdef _create_coordination_plan(self, intents: List[Dict], strategy:str)-> Dict:"""创建协调计划"""return{"strategy": strategy,"total_intents":len(intents),"execution_plan":{"PARALLEL":{"parallel_groups":[[intent["id"]]for intent in intents],"estimated_time":"同时处理,预计时间取决于最复杂的意图"},"SEQUENTIAL":{"processing_order":[intent["id"]for intent in intents],"estimated_time":"顺序处理,预计时间为各意图处理时间之和"},"PRIORITY_BASED":{"priority_order":sorted(intents, key=lambda x: x.get("computed_priority",2), reverse=True),"estimated_time":"按优先级处理,高优先级优先完成"},"USER_GUIDED":{"requires_user_input":True,"estimated_time":"需要用户确认后才能确定处理时间"}}.get(strategy,{}),"coordination_metadata":{"created_at": datetime.now().isoformat(),"strategy_reason":f"基于意图关系选择{strategy}策略"}}
6. 澄清对话Agent
classClarificationAgent(BaseAgent):"""澄清对话Agent"""def__init__(self, agent_id:str, llm_service, message_bus=None):super().__init__(agent_id, llm_service, message_bus)
self.clarification_types ={"AMBIGUITY":"歧义澄清","MISSING_INFO":"信息补充","CONTEXT":"上下文确认","PREFERENCE":"偏好确认"}defget_capabilities(self)-> List[str]:return["ambiguity_detection","question_generation","response_analysis","context_building"]
asyncdef process(self, input_data: Dict[str, Any])-> Dict[str, Any]:"""处理澄清对话"""
question = input_data.get("question","")
intent_result = input_data.get("intent_result",{})
workflow_id = input_data.get("workflow_id","")
conversation_history = input_data.get("conversation_history",[])# 1. 检测需要澄清的点
clarification_points =await self._detect_clarification_needs(question, intent_result)# 2. 生成澄清问题
clarification_questions =await self._generate_clarification_questions(
clarification_points, question, conversation_history
)# 3. 选择最佳问题
best_question =await self._select_best_question(clarification_questions, intent_result)# 4. 生成对话策略
conversation_strategy =await self._create_conversation_strategy(
best_question, clarification_points
)
result ={"clarification_needed":len(clarification_points)>0,"clarification_points": clarification_points,"clarification_question": best_question,"alternative_questions": clarification_questions,"conversation_strategy": conversation_strategy,"clarification_metadata":{"workflow_id": workflow_id,"timestamp": datetime.now().isoformat(),"turn_count":len(conversation_history)}}# 更新记忆
self.memory.update(f"clarification_{workflow_id}", result)return result
asyncdef _detect_clarification_needs(self, question:str, intent_result: Dict)-> List[Dict]:"""检测需要澄清的点"""
detection_prompt =f"""
请分析以下问题中需要澄清的点:
问题:{question}
意图类型:{intent_result.get('intent_type','unknown')}
置信度:{intent_result.get('confidence_score',0.5)}
请识别以下类型的澄清需求:
1. AMBIGUITY - 歧义或模糊表达
2. MISSING_INFO - 缺失关键信息
3. CONTEXT - 需要上下文确认
4. PREFERENCE - 需要偏好确认
请以JSON格式返回:
[
{{
"type": "AMBIGUITY",
"description": "具体的歧义点",
"importance": "high",
"suggested_clarification": "建议的澄清方式"
}}
]
"""
result =await self.llm_service.generate(
prompt=detection_prompt,
max_tokens=400,
temperature=0.2)try:return json.loads(result)except json.JSONDecodeError:return[]
asyncdef _generate_clarification_questions(self, clarification_points: List[Dict],
original_question:str,
conversation_history: List)-> List[Dict]:"""生成澄清问题"""
ifnot clarification_points:return[]
questions =[]for point in clarification_points:
question_prompt =f"""
基于以下澄清需求,生成一个合适的澄清问题:
原问题:{original_question}
澄清类型:{point.get('type','AMBIGUITY')}
澄清描述:{point.get('description','')}
对话历史:{len(conversation_history)}轮
要求:
1. 问题简洁明了
2. 易于用户理解和回答
3. 能够有效澄清歧义
4. 保持友好的语调
请以JSON格式返回:
{{
"question": "澄清问题",
"type": "{point.get('type','AMBIGUITY')}",
"expected_answer_type": "期望的回答类型",
"priority": "high"
}}
"""
result =await self.llm_service.generate(
prompt=question_prompt,
max_tokens=200,
temperature=0.3)try:
question_data = json.loads(result)
questions.append(question_data)except json.JSONDecodeError:# 生成默认问题
questions.append({"question":f"关于'{point.get('description','这个问题')}',您能提供更多详细信息吗?","type": point.get('type','AMBIGUITY'),"expected_answer_type":"text","priority": point.get('importance','medium')})return questions
asyncdef _select_best_question(self, questions: List[Dict], intent_result: Dict)-> Dict:"""选择最佳澄清问题"""
ifnot questions:return{"question":"您能提供更多详细信息来帮助我更好地理解您的需求吗?","type":"GENERAL","expected_answer_type":"text","priority":"medium"}# 按优先级排序
priority_order ={"high":3,"medium":2,"low":1}
sorted_questions =sorted(
questions,
key=lambda x: priority_order.get(x.get('priority','medium'),2),
reverse=True)return sorted_questions[0]
asyncdef _create_conversation_strategy(self, best_question: Dict,
clarification_points: List[Dict])-> Dict:"""创建对话策略"""return{"approach":"progressive_clarification","max_turns":min(len(clarification_points)+1,3),"fallback_strategy":"provide_general_answer","follow_up_questions":[
point.get('suggested_clarification','')for point in clarification_points[1:3]# 最多2个后续问题],"conversation_flow":{"current_step":1,"total_steps":len(clarification_points),"next_action":"wait_for_user_response"}}
3. 核心基础设施
1. 消息总线
from typing import Dict, List, Callable, Any
import asyncio
from dataclasses import dataclass
from enum import Enum
import json
import logging
from datetime import datetime
classMessageType(Enum):"""消息类型枚举"""
AGENT_REQUEST ="agent_request"
AGENT_RESPONSE ="agent_response"
WORKFLOW_EVENT ="workflow_event"
SYSTEM_EVENT ="system_event"
ERROR_EVENT ="error_event"@dataclassclassMessage:"""消息数据结构"""id:strtype: MessageType
source:str
target:str
payload: Dict[str, Any]
timestamp:str
correlation_id:str=None
priority:int=1
retry_count:int=0
max_retries:int=3classMessageBus:"""消息总线 - 负责Agent间通信"""def__init__(self):
self.subscribers: Dict[str, List[Callable]]={}
self.message_queue = asyncio.Queue()
self.running =False
self.logger = logging.getLogger(__name__)
self.message_history: List[Message]=[]
self.max_history =1000
asyncdef start(self):"""启动消息总线"""
self.running =Trueawait self._process_messages()
asyncdef stop(self):"""停止消息总线"""
self.running =Falsedefsubscribe(self, topic:str, handler: Callable):"""订阅消息主题"""if topic notin self.subscribers:
self.subscribers[topic]=[]
self.subscribers[topic].append(handler)
self.logger.info(f"Handler subscribed to topic: {topic}")defunsubscribe(self, topic:str, handler: Callable):"""取消订阅"""if topic in self.subscribers and handler in self.subscribers[topic]:
self.subscribers[topic].remove(handler)
self.logger.info(f"Handler unsubscribed from topic: {topic}")
asyncdef publish(self, message: Message):"""发布消息"""await self.message_queue.put(message)
self._add_to_history(message)
self.logger.debug(f"Message published: {message.id}")
asyncdef send_to_agent(self, target_agent:str, message_type: MessageType,
payload: Dict[str, Any], source_agent:str="system",
correlation_id:str=None)->str:"""发送消息给指定Agent"""
message = Message(id=self._generate_message_id(),type=message_type,
source=source_agent,
target=target_agent,
payload=payload,
timestamp=datetime.now().isoformat(),
correlation_id=correlation_id
)await self.publish(message)return message.id
asyncdef broadcast(self, message_type: MessageType, payload: Dict[str, Any],
source_agent:str="system"):"""广播消息"""
message = Message(id=self._generate_message_id(),type=message_type,
source=source_agent,
target="*",
payload=payload,
timestamp=datetime.now().isoformat())await self.publish(message)
asyncdef _process_messages(self):"""处理消息队列"""while self.running:try:
message =await asyncio.wait_for(self.message_queue.get(), timeout=1.0)await self._deliver_message(message)except asyncio.TimeoutError:continueexcept Exception as e:
self.logger.error(f"Error processing message: {e}")
asyncdef _deliver_message(self, message: Message):"""投递消息给订阅者"""
topic =f"{message.type.value}:{message.target}"
broadcast_topic =f"{message.type.value}:*"# 投递给特定目标if topic in self.subscribers:await self._notify_subscribers(self.subscribers[topic], message)# 投递给广播订阅者if broadcast_topic in self.subscribers:await self._notify_subscribers(self.subscribers[broadcast_topic], message)
asyncdef _notify_subscribers(self, handlers: List[Callable], message: Message):"""通知订阅者"""
tasks =[]for handler in handlers:try:if asyncio.iscoroutinefunction(handler):
tasks.append(handler(message))else:
handler(message)except Exception as e:
self.logger.error(f"Error in message handler: {e}")if tasks:await asyncio.gather(*tasks, return_exceptions=True)def_generate_message_id(self)->str:"""生成消息ID"""import uuid
returnstr(uuid.uuid4())def_add_to_history(self, message: Message):"""添加到历史记录"""
self.message_history.append(message)iflen(self.message_history)> self.max_history:
self.message_history.pop(0)defget_message_history(self, correlation_id:str=None)-> List[Message]:"""获取消息历史"""if correlation_id:return[msg for msg in self.message_history if msg.correlation_id == correlation_id]return self.message_history.copy()
2. Agent管理器
classAgentManager:"""Agent管理器 - 负责Agent的生命周期管理"""def__init__(self, message_bus: MessageBus, llm_service):
self.message_bus = message_bus
self.llm_service = llm_service
self.agents: Dict[str, BaseAgent]={}
self.agent_configs: Dict[str, Dict]={}
self.logger = logging.getLogger(__name__)
self.health_check_interval =30# 秒
self.running =False
asyncdef start(self):"""启动Agent管理器"""
self.running =True# 启动健康检查
asyncio.create_task(self._health_check_loop())
self.logger.info("Agent Manager started")
asyncdef stop(self):"""停止Agent管理器"""
self.running =False# 停止所有Agentfor agent in self.agents.values():await self._stop_agent(agent)
self.logger.info("Agent Manager stopped")
asyncdef register_agent(self, agent_class, agent_id:str, config: Dict =None)-> BaseAgent:"""注册Agent"""if agent_id in self.agents:raise ValueError(f"Agent {agent_id} already exists")# 创建Agent实例
agent = agent_class(agent_id, self.llm_service, self.message_bus)# 应用配置if config:await self._apply_agent_config(agent, config)# 启动Agentawait self._start_agent(agent)# 注册到管理器
self.agents[agent_id]= agent
self.agent_configs[agent_id]= config or{}
self.logger.info(f"Agent {agent_id} registered and started")return agent
asyncdef unregister_agent(self, agent_id:str):"""注销Agent"""if agent_id notin self.agents:raise ValueError(f"Agent {agent_id} not found")
agent = self.agents[agent_id]await self._stop_agent(agent)del self.agents[agent_id]del self.agent_configs[agent_id]
self.logger.info(f"Agent {agent_id} unregistered")defget_agent(self, agent_id:str)-> BaseAgent:"""获取Agent实例"""return self.agents.get(agent_id)deflist_agents(self)-> List[Dict]:"""列出所有Agent"""return[{"id": agent_id,"type":type(agent).__name__,"status":"running"if agent.is_running else"stopped","capabilities": agent.get_capabilities(),"config": self.agent_configs.get(agent_id,{})}for agent_id, agent in self.agents.items()]
asyncdef send_to_agent(self, agent_id:str, input_data: Dict[str, Any])-> Dict[str, Any]:"""向Agent发送处理请求"""
agent = self.get_agent(agent_id)
ifnot agent:raise ValueError(f"Agent {agent_id} not found")
ifnot agent.is_running:raise RuntimeError(f"Agent {agent_id} is not running")try:
result =await agent.process(input_data)return result
except Exception as e:
self.logger.error(f"Error processing request in agent {agent_id}: {e}")raise
asyncdef broadcast_to_agents(self, input_data: Dict[str, Any],
agent_filter: Callable[[BaseAgent],bool]=None)-> Dict[str, Any]:"""向多个Agent广播请求"""
results ={}
tasks =[]for agent_id, agent in self.agents.items():if agent_filter andnot agent_filter(agent):continueif agent.is_running:
tasks.append(self._process_with_agent(agent_id, agent, input_data))if tasks:
task_results =await asyncio.gather(*tasks, return_exceptions=True)for i,(agent_id, _)inenumerate([(aid, a)for aid, a in self.agents.items()
ifnot agent_filter or agent_filter(a)]):
results[agent_id]= task_results[i]return results
asyncdef _process_with_agent(self, agent_id:str, agent: BaseAgent,
input_data: Dict[str, Any])-> Any:"""使用Agent处理数据"""try:
returnawait agent.process(input_data)except Exception as e:
self.logger.error(f"Error in agent {agent_id}: {e}")return{"error":str(e)}
asyncdef _start_agent(self, agent: BaseAgent):"""启动Agent"""try:await agent.start()except Exception as e:
self.logger.error(f"Failed to start agent {agent.agent_id}: {e}")raise
asyncdef _stop_agent(self, agent: BaseAgent):"""停止Agent"""try:await agent.stop()except Exception as e:
self.logger.error(f"Failed to stop agent {agent.agent_id}: {e}")
asyncdef _apply_agent_config(self, agent: BaseAgent, config: Dict):"""应用Agent配置"""# 这里可以根据配置调整Agent的行为# 例如设置温度、最大token数等pass
asyncdef _health_check_loop(self):"""健康检查循环"""while self.running:try:await self._perform_health_check()await asyncio.sleep(self.health_check_interval)except Exception as e:
self.logger.error(f"Health check error: {e}")
asyncdef _perform_health_check(self):"""执行健康检查"""for agent_id, agent in self.agents.items():try:# 检查Agent是否响应
health_data ={"type":"health_check","timestamp": datetime.now().isoformat()}# 这里可以实现更复杂的健康检查逻辑
ifnot agent.is_running:
self.logger.warning(f"Agent {agent_id} is not running")except Exception as e:
self.logger.error(f"Health check failed for agent {agent_id}: {e}")
3. 工作流引擎
from enum import Enum
from dataclasses import dataclass, field
from typing import Dict, List, Any, Optional, Callable
import asyncio
import json
from datetime import datetime
classWorkflowStatus(Enum):"""工作流状态"""
PENDING ="pending"
RUNNING ="running"
COMPLETED ="completed"
FAILED ="failed"
CANCELLED ="cancelled"classStepStatus(Enum):"""步骤状态"""
PENDING ="pending"
RUNNING ="running"
COMPLETED ="completed"
FAILED ="failed"
SKIPPED ="skipped"@dataclassclassWorkflowStep:"""工作流步骤"""id:str
agent_id:str
input_mapping: Dict[str,str]= field(default_factory=dict)
output_mapping: Dict[str,str]= field(default_factory=dict)
condition: Optional[str]=None
retry_count:int=0
max_retries:int=3
timeout:int=300# 秒
status: StepStatus = StepStatus.PENDING
result: Optional[Dict[str, Any]]=None
error: Optional[str]=None
start_time: Optional[str]=None
end_time: Optional[str]=None@dataclassclassWorkflow:"""工作流定义"""id:str
name:str
description:str
steps: List[WorkflowStep]
dependencies: Dict[str, List[str]]= field(default_factory=dict)
global_context: Dict[str, Any]= field(default_factory=dict)
status: WorkflowStatus = WorkflowStatus.PENDING
start_time: Optional[str]=None
end_time: Optional[str]=None
result: Optional[Dict[str, Any]]=None
error: Optional[str]=NoneclassWorkflowEngine:"""工作流引擎"""def__init__(self, agent_manager: AgentManager, message_bus: MessageBus):
self.agent_manager = agent_manager
self.message_bus = message_bus
self.workflows: Dict[str, Workflow]={}
self.running_workflows: Dict[str, asyncio.Task]={}
self.logger = logging.getLogger(__name__)
asyncdef create_workflow(self, workflow_definition: Dict[str, Any])->str:"""创建工作流"""
workflow = self._parse_workflow_definition(workflow_definition)
self.workflows[workflow.id]= workflow
self.logger.info(f"Workflow {workflow.id} created")return workflow.id
asyncdef execute_workflow(self, workflow_id:str, initial_context: Dict[str, Any]=None)->str:"""执行工作流"""if workflow_id notin self.workflows:raise ValueError(f"Workflow {workflow_id} not found")
workflow = self.workflows[workflow_id]if workflow_id in self.running_workflows:raise RuntimeError(f"Workflow {workflow_id} is already running")# 设置初始上下文if initial_context:
workflow.global_context.update(initial_context)# 启动工作流执行任务
task = asyncio.create_task(self._execute_workflow_task(workflow))
self.running_workflows[workflow_id]= task
self.logger.info(f"Workflow {workflow_id} execution started")return workflow_id
asyncdef cancel_workflow(self, workflow_id:str):"""取消工作流"""if workflow_id in self.running_workflows:
task = self.running_workflows[workflow_id]
task.cancel()del self.running_workflows[workflow_id]
workflow = self.workflows[workflow_id]
workflow.status = WorkflowStatus.CANCELLED
workflow.end_time = datetime.now().isoformat()
self.logger.info(f"Workflow {workflow_id} cancelled")defget_workflow_status(self, workflow_id:str)-> Dict[str, Any]:"""获取工作流状态"""if workflow_id notin self.workflows:raise ValueError(f"Workflow {workflow_id} not found")
workflow = self.workflows[workflow_id]return{"id": workflow.id,"name": workflow.name,"status": workflow.status.value,"start_time": workflow.start_time,"end_time": workflow.end_time,"steps":[{"id": step.id,"agent_id": step.agent_id,"status": step.status.value,"start_time": step.start_time,"end_time": step.end_time,"error": step.error
}for step in workflow.steps
],"result": workflow.result,"error": workflow.error
}
asyncdef _execute_workflow_task(self, workflow: Workflow):"""执行工作流任务"""try:
workflow.status = WorkflowStatus.RUNNING
workflow.start_time = datetime.now().isoformat()# 执行步骤await self._execute_steps(workflow)# 完成工作流
workflow.status = WorkflowStatus.COMPLETED
workflow.end_time = datetime.now().isoformat()# 收集结果
workflow.result = self._collect_workflow_result(workflow)except Exception as e:
workflow.status = WorkflowStatus.FAILED
workflow.end_time = datetime.now().isoformat()
workflow.error =str(e)
self.logger.error(f"Workflow {workflow.id} failed: {e}")finally:# 清理运行中的工作流if workflow.idin self.running_workflows:del self.running_workflows[workflow.id]
asyncdef _execute_steps(self, workflow: Workflow):"""执行工作流步骤"""# 构建执行计划
execution_plan = self._build_execution_plan(workflow)for step_group in execution_plan:# 并行执行同一组的步骤
tasks =[]for step in step_group:if self._should_execute_step(step, workflow):
tasks.append(self._execute_step(step, workflow))else:
step.status = StepStatus.SKIPPED
if tasks:await asyncio.gather(*tasks)def_build_execution_plan(self, workflow: Workflow)-> List[List[WorkflowStep]]:"""构建执行计划"""# 简化的拓扑排序实现
steps_by_id ={step.id: step for step in workflow.steps}
dependencies = workflow.dependencies
# 计算每个步骤的依赖深度
depths ={}for step in workflow.steps:
depths[step.id]= self._calculate_depth(step.id, dependencies,set())# 按深度分组
groups ={}for step_id, depth in depths.items():if depth notin groups:
groups[depth]=[]
groups[depth].append(steps_by_id[step_id])# 返回按深度排序的步骤组return[groups[depth]for depth insorted(groups.keys())]def_calculate_depth(self, step_id:str, dependencies: Dict[str, List[str]], visited:set)->int:"""计算步骤的依赖深度"""if step_id in visited:
return0# 避免循环依赖
visited.add(step_id)
deps = dependencies.get(step_id,[])
ifnot deps:
return0
max_depth =max(self._calculate_depth(dep, dependencies, visited.copy())for dep in deps)return max_depth +1def_should_execute_step(self, step: WorkflowStep, workflow: Workflow)->bool:"""判断是否应该执行步骤"""# 检查依赖是否完成
dependencies = workflow.dependencies.get(step.id,[])for dep_id in dependencies:
dep_step =next((s for s in workflow.steps if s.id== dep_id),None)
ifnot dep_step or dep_step.status != StepStatus.COMPLETED:
returnFalse
# 检查条件if step.condition:return self._evaluate_condition(step.condition, workflow.global_context)
returnTrue
def_evaluate_condition(self, condition:str, context: Dict[str, Any])->bool:"""评估条件表达式"""# 简化的条件评估实现# 在实际应用中,可以使用更复杂的表达式引擎try:# 这里只是一个示例,实际应该使用安全的表达式评估器returneval(condition,{"__builtins__":{}}, context)except Exception:
returnTrue# 默认执行
asyncdef _execute_step(self, step: WorkflowStep, workflow: Workflow):"""执行单个步骤"""try:
step.status = StepStatus.RUNNING
step.start_time = datetime.now().isoformat()# 准备输入数据
input_data = self._prepare_step_input(step, workflow)# 执行步骤
result =await asyncio.wait_for(
self.agent_manager.send_to_agent(step.agent_id, input_data),
timeout=step.timeout
)# 处理输出
step.result = result
self._process_step_output(step, workflow, result)
step.status = StepStatus.COMPLETED
step.end_time = datetime.now().isoformat()except asyncio.TimeoutError:
step.status = StepStatus.FAILED
step.error =f"Step timeout after {step.timeout} seconds"
step.end_time = datetime.now().isoformat()except Exception as e:
step.status = StepStatus.FAILED
step.error =str(e)
step.end_time = datetime.now().isoformat()# 重试逻辑if step.retry_count < step.max_retries:
step.retry_count +=1
step.status = StepStatus.PENDING
await asyncio.sleep(2** step.retry_count)# 指数退避await self._execute_step(step, workflow)def_prepare_step_input(self, step: WorkflowStep, workflow: Workflow)-> Dict[str, Any]:"""准备步骤输入数据"""
input_data ={"workflow_id": workflow.id}# 应用输入映射for target_key, source_key in step.input_mapping.items():if source_key in workflow.global_context:
input_data[target_key]= workflow.global_context[source_key]return input_data
def_process_step_output(self, step: WorkflowStep, workflow: Workflow, result: Dict[str, Any]):"""处理步骤输出"""# 应用输出映射for source_key, target_key in step.output_mapping.items():if source_key in result:
workflow.global_context[target_key]= result[source_key]def_collect_workflow_result(self, workflow: Workflow)-> Dict[str, Any]:"""收集工作流结果"""return{"global_context": workflow.global_context,"step_results":{
step.id: step.result for step in workflow.steps
if step.status == StepStatus.COMPLETED
}}def_parse_workflow_definition(self, definition: Dict[str, Any])-> Workflow:"""解析工作流定义"""
steps =[]for step_def in definition.get("steps",[]):
step = WorkflowStep(id=step_def["id"],
agent_id=step_def["agent_id"],
input_mapping=step_def.get("input_mapping",{}),
output_mapping=step_def.get("output_mapping",{}),
condition=step_def.get("condition"),
max_retries=step_def.get("max_retries",3),
timeout=step_def.get("timeout",300))
steps.append(step)return Workflow(id=definition["id"],
name=definition["name"],
description=definition.get("description",""),
steps=steps,
dependencies=definition.get("dependencies",{}),
global_context=definition.get("global_context",{}))
4. 系统集成层
classSystemIntegrator:"""系统集成器 - 整合所有组件"""def__init__(self, config: Dict[str, Any]):
self.config = config
self.logger = logging.getLogger(__name__)# 初始化核心组件
self.message_bus = MessageBus()
self.llm_service = self._create_llm_service()
self.agent_manager = AgentManager(self.message_bus, self.llm_service)
self.workflow_engine = WorkflowEngine(self.agent_manager, self.message_bus)
self.monitor = SystemMonitor()# 组件状态
self.running =False
asyncdef start(self):"""启动整个系统"""try:
self.logger.info("Starting Question Clarification System...")# 启动消息总线await self.message_bus.start()# 启动Agent管理器await self.agent_manager.start()# 注册默认Agentawait self._register_default_agents()# 启动监控await self.monitor.start()
self.running =True
self.logger.info("Question Clarification System started successfully")except Exception as e:
self.logger.error(f"Failed to start system: {e}")await self.stop()raise
asyncdef stop(self):"""停止整个系统"""
self.logger.info("Stopping Question Clarification System...")
self.running =False# 停止监控ifhasattr(self,'monitor'):await self.monitor.stop()# 停止Agent管理器ifhasattr(self,'agent_manager'):await self.agent_manager.stop()# 停止消息总线ifhasattr(self,'message_bus'):await self.message_bus.stop()
self.logger.info("Question Clarification System stopped")
asyncdef process_question(self, question:str, context: Dict[str, Any]=None)-> Dict[str, Any]:"""处理问题明确化请求"""
ifnot self.running:raise RuntimeError("System is not running")try:# 创建工作流
workflow_def = self._create_question_clarification_workflow(question, context)
workflow_id =await self.workflow_engine.create_workflow(workflow_def)# 执行工作流await self.workflow_engine.execute_workflow(workflow_id,{"original_question": question})# 等待完成并返回结果
returnawait self._wait_for_workflow_completion(workflow_id)except Exception as e:
self.logger.error(f"Error processing question: {e}")raisedef_create_llm_service(self):"""创建LLM服务"""# 这里根据配置创建相应的LLM服务
llm_config = self.config.get("llm",{})
provider = llm_config.get("provider","openai")if provider =="openai":return OpenAILLMService(llm_config)elif provider =="anthropic":return AnthropicLLMService(llm_config)else:raise ValueError(f"Unsupported LLM provider: {provider}")
asyncdef _register_default_agents(self):"""注册默认Agent"""
agents_config = self.config.get("agents",{})# 注册问题分析Agentawait self.agent_manager.register_agent(
QuestionAnalysisAgent,"question_analyzer",
agents_config.get("question_analyzer",{}))# 注册意图识别Agentawait self.agent_manager.register_agent(
IntentRecognitionAgent,"intent_recognizer",
agents_config.get("intent_recognizer",{}))# 注册问题生成Agentawait self.agent_manager.register_agent(
QuestionGenerationAgent,"question_generator",
agents_config.get("question_generator",{}))# 注册答案验证Agentawait self.agent_manager.register_agent(
AnswerValidationAgent,"answer_validator",
agents_config.get("answer_validator",{}))def_create_question_clarification_workflow(self, question:str, context: Dict[str, Any])-> Dict[str, Any]:"""创建问题明确化工作流"""import uuid
workflow_id =str(uuid.uuid4())return{"id": workflow_id,"name":"Question Clarification Workflow","description":"Workflow for clarifying user questions","steps":[{"id":"analyze_question","agent_id":"question_analyzer","input_mapping":{"question":"original_question"},"output_mapping":{"analysis_result":"question_analysis"}},{"id":"recognize_intent","agent_id":"intent_recognizer","input_mapping":{"question":"original_question","analysis":"question_analysis"},"output_mapping":{"intent":"user_intent","confidence":"intent_confidence"}},{"id":"generate_clarification","agent_id":"question_generator","input_mapping":{"question":"original_question","analysis":"question_analysis","intent":"user_intent"},"output_mapping":{"clarification_questions":"generated_questions"},"condition":"intent_confidence < 0.8"},{"id":"validate_result","agent_id":"answer_validator","input_mapping":{"original_question":"original_question","analysis":"question_analysis","intent":"user_intent","clarification_questions":"generated_questions"},"output_mapping":{"validation_result":"final_result"}}],"dependencies":{"recognize_intent":["analyze_question"],"generate_clarification":["recognize_intent"],"validate_result":["analyze_question","recognize_intent"]},"global_context": context or{}}
asyncdef _wait_for_workflow_completion(self, workflow_id:str, timeout:int=300)-> Dict[str, Any]:"""等待工作流完成"""
start_time = asyncio.get_event_loop().time()
whileTrue:
status = self.workflow_engine.get_workflow_status(workflow_id)if status["status"]in["completed","failed","cancelled"]:return status
if asyncio.get_event_loop().time()- start_time > timeout:await self.workflow_engine.cancel_workflow(workflow_id)raise TimeoutError(f"Workflow {workflow_id} timed out")await asyncio.sleep(1)
5. 监控和告警
classSystemMonitor:"""系统监控器"""def__init__(self):
self.metrics: Dict[str, Any]={}
self.alerts: List[Dict[str, Any]]=[]
self.running =False
self.logger = logging.getLogger(__name__)
self.monitor_interval =10# 秒
asyncdef start(self):"""启动监控"""
self.running =True
asyncio.create_task(self._monitor_loop())
self.logger.info("System Monitor started")
asyncdef stop(self):"""停止监控"""
self.running =False
self.logger.info("System Monitor stopped")defrecord_metric(self, name:str, value: Any, tags: Dict[str,str]=None):"""记录指标"""
timestamp = datetime.now().isoformat()if name notin self.metrics:
self.metrics[name]=[]
self.metrics[name].append({"value": value,"timestamp": timestamp,"tags": tags or{}})# 保持最近1000条记录iflen(self.metrics[name])>1000:
self.metrics[name]= self.metrics[name][-1000:]defget_metrics(self, name:str=None)-> Dict[str, Any]:"""获取指标"""if name:return self.metrics.get(name,[])return self.metrics
defcreate_alert(self, level:str, message:str, details: Dict[str, Any]=None):"""创建告警"""
alert ={"id":str(uuid.uuid4()),"level": level,"message": message,"details": details or{},"timestamp": datetime.now().isoformat(),"resolved":False}
self.alerts.append(alert)
self.logger.warning(f"Alert created: {level} - {message}")# 保持最近100条告警iflen(self.alerts)>100:
self.alerts = self.alerts[-100:]defget_alerts(self, level:str=None, resolved:bool=None)-> List[Dict[str, Any]]:"""获取告警"""
alerts = self.alerts
if level:
alerts =[a for a in alerts if a["level"]== level]if resolved isnotNone:
alerts =[a for a in alerts if a["resolved"]== resolved]return alerts
defresolve_alert(self, alert_id:str):"""解决告警"""for alert in self.alerts:if alert["id"]== alert_id:
alert["resolved"]=True
alert["resolved_at"]= datetime.now().isoformat()break
asyncdef _monitor_loop(self):"""监控循环"""while self.running:try:await self._collect_system_metrics()await self._check_alerts()await asyncio.sleep(self.monitor_interval)except Exception as e:
self.logger.error(f"Monitor loop error: {e}")
asyncdef _collect_system_metrics(self):"""收集系统指标"""import psutil
# CPU使用率
cpu_percent = psutil.cpu_percent()
self.record_metric("system.cpu_percent", cpu_percent)# 内存使用率
memory = psutil.virtual_memory()
self.record_metric("system.memory_percent", memory.percent)# 磁盘使用率
disk = psutil.disk_usage('/')
self.record_metric("system.disk_percent",(disk.used / disk.total)*100)
asyncdef _check_alerts(self):"""检查告警条件"""# 检查CPU使用率
cpu_metrics = self.get_metrics("system.cpu_percent")if cpu_metrics andlen(cpu_metrics)>=3:
recent_cpu =[m["value"]for m in cpu_metrics[-3:]]ifall(cpu > 90for cpu in recent_cpu):
self.create_alert("high","High CPU usage detected",{"cpu_percent": recent_cpu})# 检查内存使用率
memory_metrics = self.get_metrics("system.memory_percent")if memory_metrics:
latest_memory = memory_metrics[-1]["value"]if latest_memory >85:
self.create_alert("high","High memory usage detected",{"memory_percent": latest_memory})
6. 配置管理
classConfigManager:"""配置管理器"""def__init__(self, config_file:str=None):
self.config_file = config_file
self.config: Dict[str, Any]={}
self.watchers: List[Callable]=[]
self.logger = logging.getLogger(__name__)# 默认配置
self.default_config ={"llm":{"provider":"openai","model":"gpt-4","temperature":0.7,"max_tokens":2000},"agents":{"question_analyzer":{"temperature":0.3,"max_tokens":1000},"intent_recognizer":{"temperature":0.2,"max_tokens":500},"question_generator":{"temperature":0.8,"max_tokens":1500},"answer_validator":{"temperature":0.1,"max_tokens":800}},"system":{"max_concurrent_workflows":10,"workflow_timeout":300,"health_check_interval":30,"monitor_interval":10}}defload_config(self)-> Dict[str, Any]:"""加载配置"""
self.config = self.default_config.copy()if self.config_file and os.path.exists(self.config_file):try:withopen(self.config_file,'r', encoding='utf-8')as f:
file_config = json.load(f)
self.config = self._merge_config(self.config, file_config)
self.logger.info(f"Configuration loaded from {self.config_file}")except Exception as e:
self.logger.error(f"Failed to load config file {self.config_file}: {e}")# 从环境变量加载配置
self._load_from_env()return self.config
defsave_config(self, config: Dict[str, Any]=None):"""保存配置"""
ifnot self.config_file:raise ValueError("No config file specified")
config_to_save = config or self.config
try:withopen(self.config_file,'w', encoding='utf-8')as f:
json.dump(config_to_save, f, indent=2, ensure_ascii=False)
self.logger.info(f"Configuration saved to {self.config_file}")except Exception as e:
self.logger.error(f"Failed to save config file {self.config_file}: {e}")raisedefget(self, key:str, default: Any =None)-> Any:"""获取配置值"""
keys = key.split('.')
value = self.config
for k in keys:ifisinstance(value,dict)and k in value:
value = value[k]else:return default
return value
defset(self, key:str, value: Any):"""设置配置值"""
keys = key.split('.')
config = self.config
for k in keys[:-1]:if k notin config:
config[k]={}
config = config[k]
config[keys[-1]]= value
# 通知观察者
self._notify_watchers(key, value)defwatch(self, callback: Callable[[str, Any],None]):"""监听配置变化"""
self.watchers.append(callback)def_merge_config(self, base: Dict[str, Any], override: Dict[str, Any])-> Dict[str, Any]:"""合并配置"""
result = base.copy()for key, value in override.items():if key in result andisinstance(result[key],dict)andisinstance(value,dict):
result[key]= self._merge_config(result[key], value)else:
result[key]= value
return result
def_load_from_env(self):"""从环境变量加载配置"""
env_mappings ={"OPENAI_API_KEY":"llm.api_key","LLM_PROVIDER":"llm.provider","LLM_MODEL":"llm.model","LLM_TEMPERATURE":"llm.temperature","MAX_CONCURRENT_WORKFLOWS":"system.max_concurrent_workflows","WORKFLOW_TIMEOUT":"system.workflow_timeout"}for env_key, config_key in env_mappings.items():
env_value = os.getenv(env_key)if env_value:# 尝试转换类型try:if config_key.endswith(('timeout','interval','max_tokens','max_concurrent_workflows')):
env_value =int(env_value)elif config_key.endswith('temperature'):
env_value =float(env_value)except ValueError:pass
self.set(config_key, env_value)def_notify_watchers(self, key:str, value: Any):"""通知配置观察者"""for watcher in self.watchers:try:
watcher(key, value)except Exception as e:
self.logger.error(f"Error in config watcher: {e}")
总结
–
通过"问题预处理 → 意图识别 → 任务分解 → 问题改写 → 答案生成与验证"的流程,系统性地解决用户问题模糊不清的挑战。核心特点包括:
技术风险
模型准确性风险
风险描述:意图识别错误导致后续处理偏差
影响程度:高
缓解措施:
多模型融合提高准确性
建立人工审核机制
持续模型训练和优化
核心价值
智能理解 :深度理解用户真实意图,避免误解和偏差
意图驱动 :基于明确的意图进行任务分解,确保处理方向正确
任务分解 :将复杂问题拆解为可执行的子任务,提高处理效率
精准改写 :针对分解后的子任务进行问题优化,补充执行所需信息
协同处理 :多模块协作,提供全流程的问题处理能力
核心处理流程
问题预处理 → 标准化用户输入,消除噪音
意图识别 → 理解用户真实需求和意图
任务拆解 → 基于意图将复杂问题分解为可执行子任务
问题改写/扩写 → 针对子任务优化问题表达,补充执行信息
答案生成与验证 → 生成并验证最终答案
系统化处理模糊问题,为用户提供更智能、更准确的服务体验,可以广泛应用于客服系统、知识问答、智能助手等场景。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献545条内容
已为社区贡献545条内容

所有评论(0)