【译】Uber 如何通过集成缓存实现每秒超 1.5 亿次读取请求(ByteByteAI.com)
Uber构建了高性能缓存系统CacheFront,在保证强一致性的前提下每秒处理超1.5亿次读取。系统采用三层架构:查询引擎、存储引擎和缓存层,使用Redis作为缓存,实现99.9%的命中率。针对写操作导致的数据不一致问题,Uber创新性地结合同步失效、异步CDC和TTL三重机制,并改造存储引擎支持条件更新的精确追踪。通过Cache Inspector工具验证,系统在保持极高命中率的同时,几乎消除
免责声明:
本文翻译自ByteByteAI.com
当你打开 Uber 应用请求一次行程、查看行程历史,或者浏览司机信息时,你期望得到的是即时响应。
而在这种流畅体验的背后,运行着一套高度复杂的缓存系统。
Uber 的 CacheFront 在保持强一致性保证的前提下,每秒可以处理 超过 1.5 亿次数据库读取请求。
在本文中,我们将拆解 Uber 是如何构建这套系统的、他们遇到了哪些挑战,以及为此设计了哪些创新性的解决方案。
为什么缓存如此重要
每当用户与 Uber 平台交互时,系统都需要获取各种数据,例如用户资料、行程详情、司机位置以及定价信息。
如果每一个请求都直接访问数据库:
- 会引入明显的延迟
- 会给数据库服务器带来巨大的压力
当你面对的是 数百万用户、每天数十亿次请求 时,传统数据库根本无法承受这样的负载。
缓存 通过将高频访问的数据存储在更快的存储系统中来解决这个问题。
应用在读取数据时:
- 首先查询缓存
- 如果缓存中存在数据(缓存命中,cache hit),立即返回
- 如果不存在(缓存未命中,cache miss),则查询数据库,并将结果写入缓存,供后续请求使用
如下图所示:
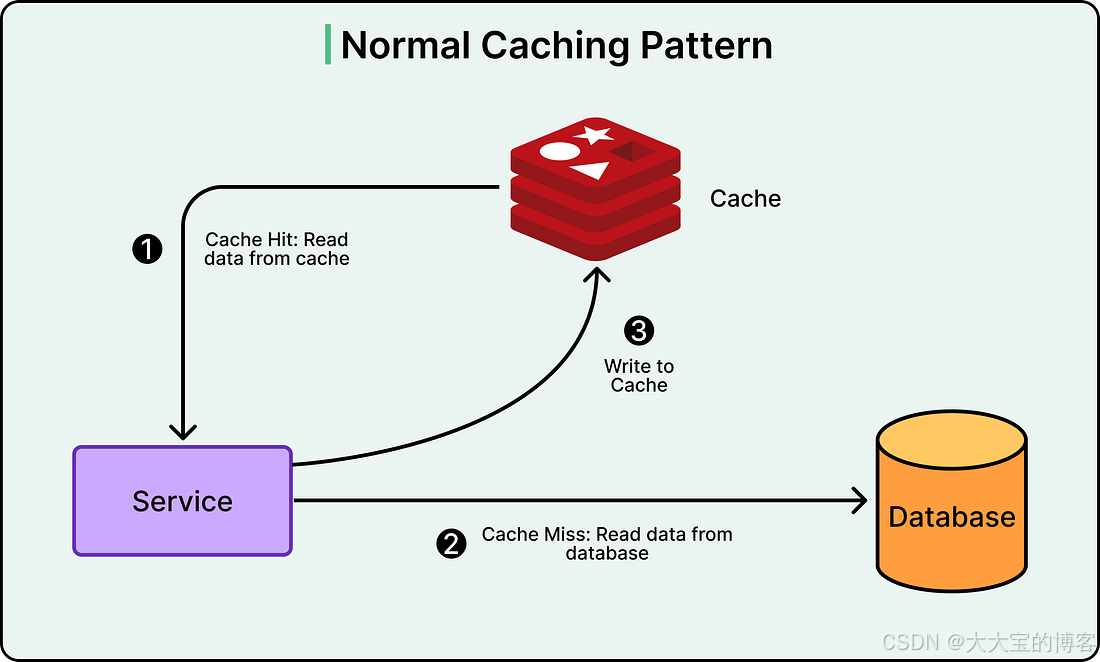
Uber 使用 Redis 作为缓存层。
Redis 是一种内存型数据存储,相比数据库查询的毫秒级延迟,它可以在微秒级返回数据。
(来源:[Coderabbit])
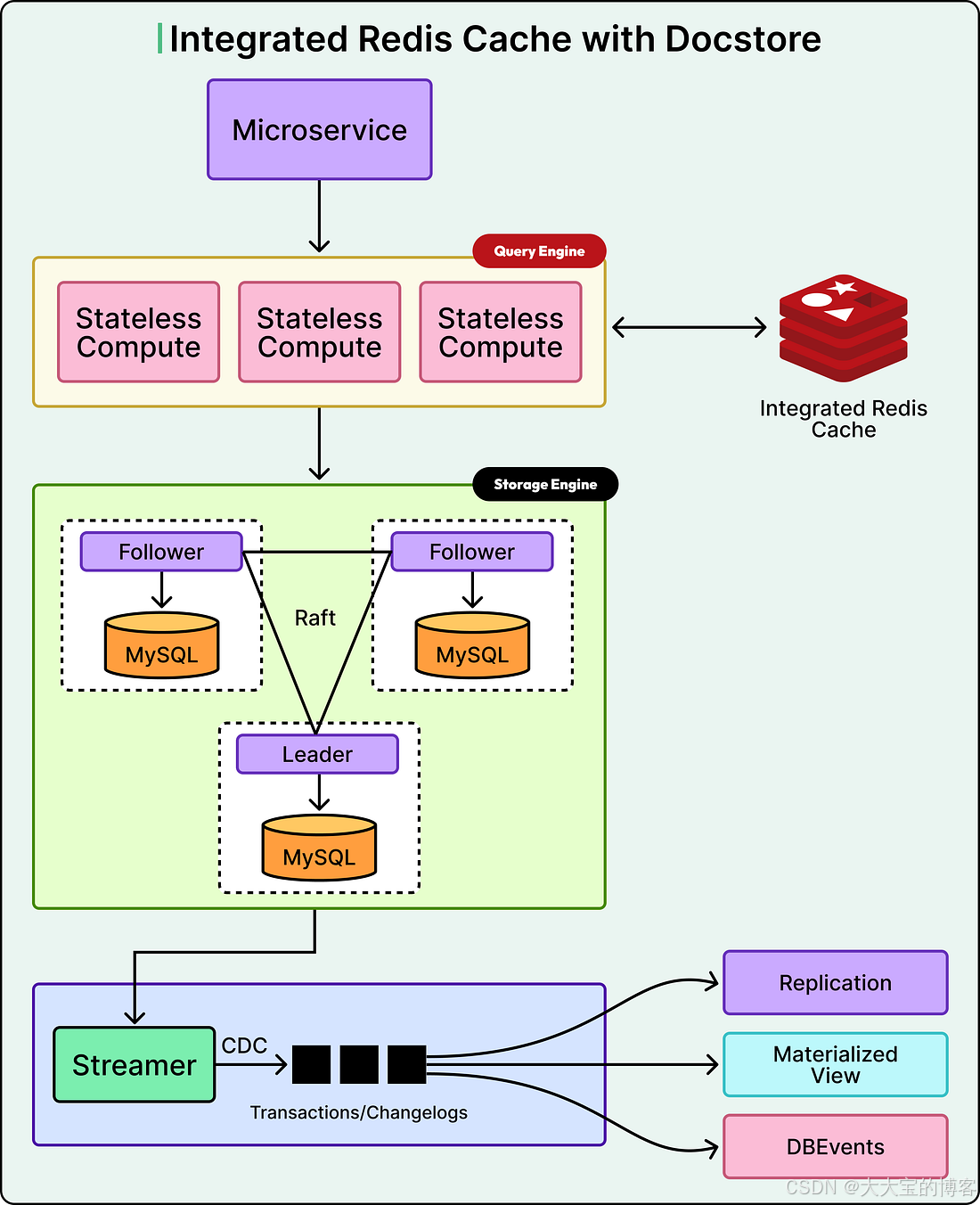
架构:三个协同工作的层次
Uber 的存储系统称为 Docstore,由三个主要组件组成:
-
Query Engine(查询引擎层)
无状态,负责处理来自 Uber 各个服务的所有请求 -
Storage Engine(存储引擎层)
数据的真实存储位置,由多个 MySQL 节点组成 -
CacheFront
缓存逻辑,实现在查询引擎层内部,位于应用请求与数据库之间
读路径(Read Path)
当一个读请求进入系统时:
- CacheFront 首先查询 Redis
- 如果 Redis 中存在数据,立即返回给客户端
在许多使用场景下,Uber 的缓存命中率超过 99.9%,这意味着只有极少量请求需要访问数据库。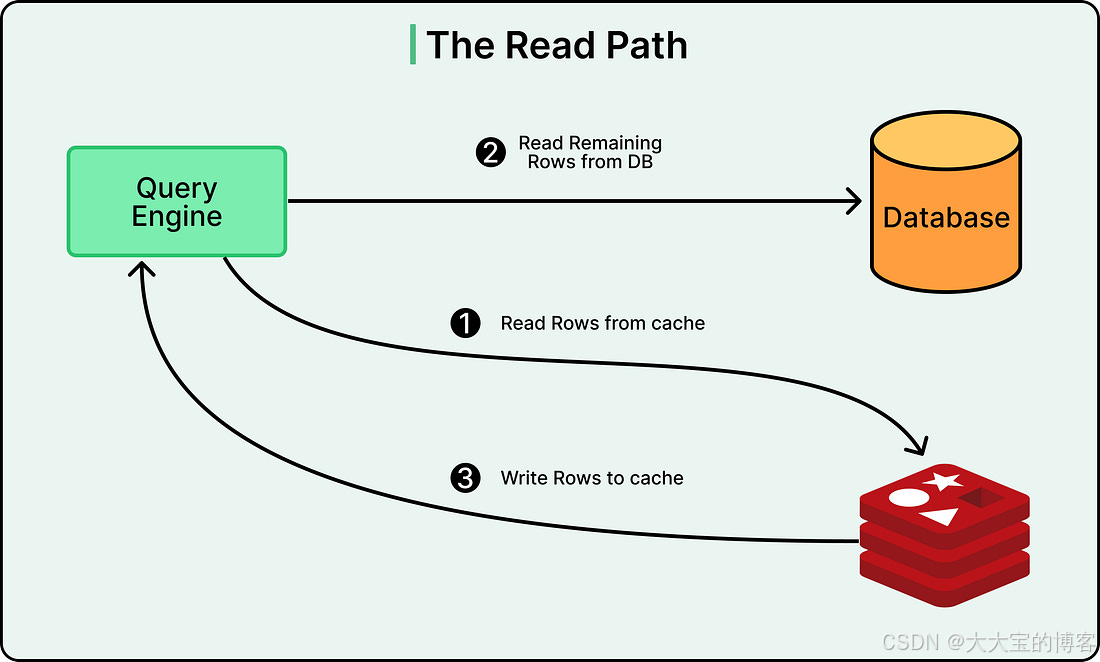
如果 Redis 中不存在对应数据:
- CacheFront 从 MySQL 中读取数据
- 将结果写入 Redis
- 将数据返回给客户端
系统还支持部分缓存未命中的情况。
例如,一个请求需要读取 10 行数据,其中 7 行已存在于缓存中,那么系统只会从数据库中查询缺失的 3 行。
写路径(Write Path)
写操作 会给任何缓存系统带来显著复杂性。
当数据库中的数据发生变化时,缓存中的副本就会变成过期数据(stale data)。
如果系统返回了过期数据,将会破坏业务逻辑并导致糟糕的用户体验。
例如:
你在 Uber 应用中更新了目的地,但系统仍然显示旧目的地,因为它从缓存中读到了过期数据。
缓存刷新(invalidate)面临的核心挑战在于:
如何确定在一次写操作发生后,哪些缓存条目需要被失效。
Uber 支持两种写操作类型,它们需要不同的处理方式。
点写(Point Writes)
点写操作比较简单。
这是指在 SQL 中明确指定具体行的 INSERT、UPDATE 或 DELETE 操作。
例如:根据 user_id 更新某个用户的资料。
由于行的主键在查询中是已知的,因此可以准确地定位并失效对应的缓存条目。
条件更新(Conditional Updates)
条件更新要复杂得多。
这是指带有 WHERE 条件的 UPDATE 或 DELETE 语句。
例如:
将所有行程时间超过 60 分钟的订单标记为已完成。
在查询执行之前,你并不知道哪些行会匹配这个条件,因此:
- 无法提前确定哪些缓存条目会受到影响
- 也就无法在写入时同步失效缓存
正是这种不确定性,使得 Uber 在最初无法在写路径中同步执行缓存失效。
最初的解决方案
Uber 最初采用了一个名为 Flux 的系统,它基于 变更数据捕获(Change Data Capture,CDC)。
Flux 会监听 MySQL 的 binlog(二进制日志),该日志记录了数据库中的所有变更。
写事务提交后:
-
MySQL 将变更写入 binlog

-
Flux 通过持续读取 binlog,识别哪些行发生了变化
-
对 Redis 中对应的缓存条目进行失效或更新
如下图所示:
(图略)
这种方式在功能上是可行的,但存在一个致命限制:
Flux 是异步的。
这意味着数据库写入与缓存更新之间存在延迟。
虽然通常是亚秒级,但在系统重启、部署或拓扑变化时,这个延迟可能会明显变长。
异步失效会带来一致性问题。
如果用户刚刚写入数据,随后立即读取,可能会因为缓存尚未失效而读到旧数据。
这违反了**“读你所写(read-your-own-writes)一致性”**,而这是大多数应用的基本预期。
系统还依赖 TTL(Time-To-Live,存活时间) 机制。
每个缓存条目都有一个 TTL,决定它在缓存中保留多久。
Uber 的默认推荐值是 5 分钟,但可以根据业务需求调整。
TTL 作为兜底机制,确保即使缓存失效失败,过期数据最终也会被清除。
然而,仅靠 TTL 并不能满足很多使用场景。
服务负责人希望获得更高的缓存命中率,于是倾向于设置更长的 TTL。
但 TTL 越长:
- 命中率越高
- 提供过期数据的时间窗口也越大
一致性问题的来源
随着 CacheFront 的规模不断扩大,Uber 发现了三种主要的不一致来源:
-
Flux 失效延迟
导致写后立即读可能返回旧数据 -
缓存失效失败
当 Redis 节点短暂不可用时,缓存条目可能一直保留到 TTL 到期 -
从延迟的 MySQL 从库回填缓存
如果从库尚未同步最新写入,就可能将旧数据重新写入缓存
超越 TTL 的陈旧问题
还有一个更加隐蔽的一致性问题,与“缓存数据到底能有多旧”有关。
很多工程师认为:
如果 TTL 设置为 5 分钟,那么最多只会返回 5 分钟的旧数据。
这个认知是错误的。
考虑以下场景:
- 某一行数据在 一年前 被写入数据库,之后从未被访问
- 在今天时间点 T,一个读请求到来
- 缓存中没有该数据,于是从数据库中读取并写入缓存
- 此时,缓存中的数据本身已经是一年前的内容
随后不久:
- 一个写请求更新了数据库中的这行数据
- Flux 尝试失效缓存,但由于 Redis 的临时问题失败了
此时:
- 缓存仍然保存着一年前的数据
- 数据库中是最新数据
在接下来的一小时内(假设 TTL 为 1 小时),
所有读请求都会返回这一年前的数据。
也就是说:
数据的陈旧程度并不受 TTL 的上限约束。
TTL 只控制缓存条目存在多久,
并不限制缓存中数据本身有多旧。
这个问题在 TTL 设置较长时尤为严重。
如果 TTL 设置为 24 小时,一旦失效失败,就可能在整整一天内持续返回极度过期的数据。
突破:让条件更新可追踪
同步缓存失效的根本障碍在于:
无法在条件更新中知道哪些行发生了变化。
Uber 为此对存储引擎做了两项关键改造:
改造一:软删除
所有 DELETE 操作都改为软删除,
即设置一个 tombstone(墓碑)标志位,而不是真正删除行。
改造二:严格单调递增的时间戳
系统引入了微秒级、严格单调递增的时间戳,
确保每个事务都有唯一可识别的提交时间。
有了这两个保证,系统现在可以准确确定哪些行被修改。
当行被更新时,其时间戳字段会被设置为该事务的时间戳。
在提交事务之前,系统会执行一个轻量级查询,
选出时间戳落在该事务时间窗口内的所有行主键。
这个查询非常快,因为:
- 数据已经在 MySQL 存储引擎的缓存中
- 时间戳字段是有索引的
重构后的写路径
当写请求进入查询引擎时:
- 系统注册一个回调
- 当存储引擎返回时,该回调会被执行
返回信息包括:
- 写操作是否成功
- 受影响的行主键集合
- 事务的提交时间戳
回调函数使用这些信息,对 Redis 中对应的缓存条目进行失效。
缓存失效可以选择:
-
同步执行:
在请求上下文中完成,增加写延迟,但提供最强一致性 -
异步执行:
放入队列中处理,避免增加延迟,但一致性略弱
如下图所示:
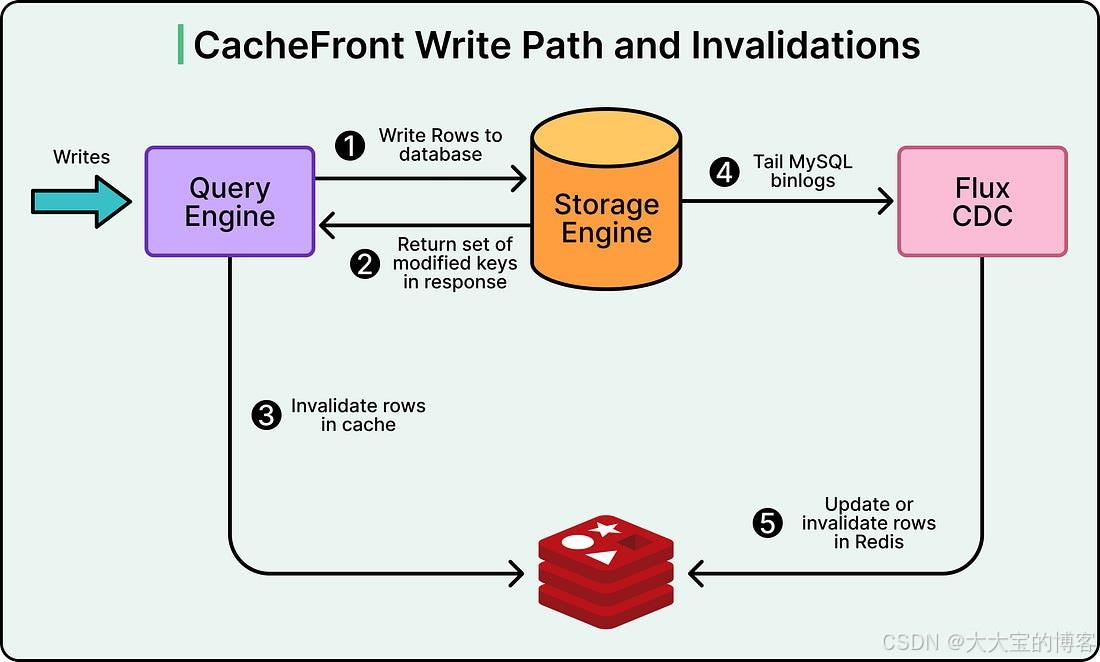
需要强调的是:
即使缓存失效失败,写请求也不会失败。
缓存问题不会影响写入成功,从而保证系统的可用性。
三重防御策略
目前,Uber 同时运行三套缓存一致性机制:
- TTL 到期自动清除(默认 5 分钟)
- Flux 异步 CDC 失效
- 写路径同步失效机制
三种机制并行运行,
相比依赖单一方案,效果要好得多。
Cache Inspector
为了验证改进效果并量化一致性水平,Uber 构建了 Cache Inspector。
该工具使用与 Flux 相同的 CDC 管道,但人为引入 1 分钟延迟。
它不会进行缓存失效,而是:
- 将 binlog 中的变更与 Redis 中的数据进行对比
- 统计发现的过期条目数量
- 记录数据陈旧的持续时间
结果非常积极。
对于 TTL 设置为 24 小时的表:
- Cache Inspector 在连续一周的观测中几乎没有发现过期数据
- 缓存命中率仍然超过 99.9%
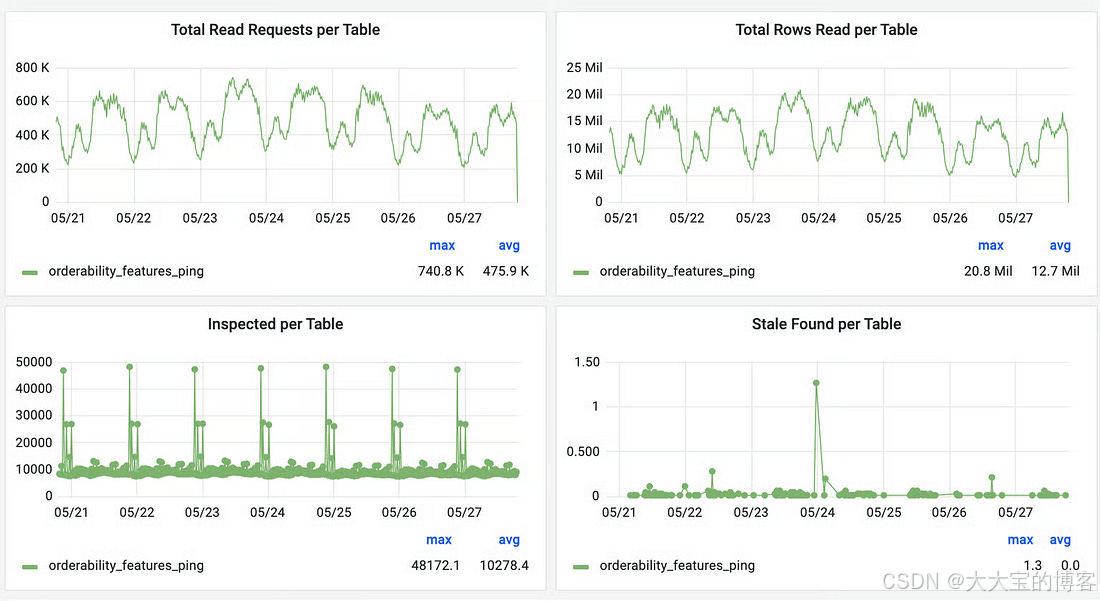
这让 Uber 能够有信心地为合适的场景提高 TTL,
在不牺牲一致性的前提下显著提升性能。
其他优化
除了核心的失效机制改进外,Uber 还实现了大量工程优化,包括:
- 基于负载的自适应超时
- 对不存在数据的负缓存(negative caching)
- 使用流水线(pipeline)批量读取
- 针对不健康节点的熔断器
- 连接速率限制
- 数据压缩以降低内存和带宽开销
总结
如今,CacheFront 在高峰期每秒可以处理 超过 1.5 亿行读取请求。
在许多场景下,缓存命中率超过 99.9%。
系统规模相比最初增长了近 4 倍,
同时一致性保障反而更强。
通过 写路径同步失效 + 异步 CDC + TTL 兜底 的组合方案,
Uber 在超大规模下实现了高性能与强一致性的平衡。
参考资料
- How Uber Serves over 150 Million Reads per Second from Integrated Cache with Stronger Consistency Guarantees
- How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated Cache

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)