评估优化器(Evaluator-Optimizer)详解
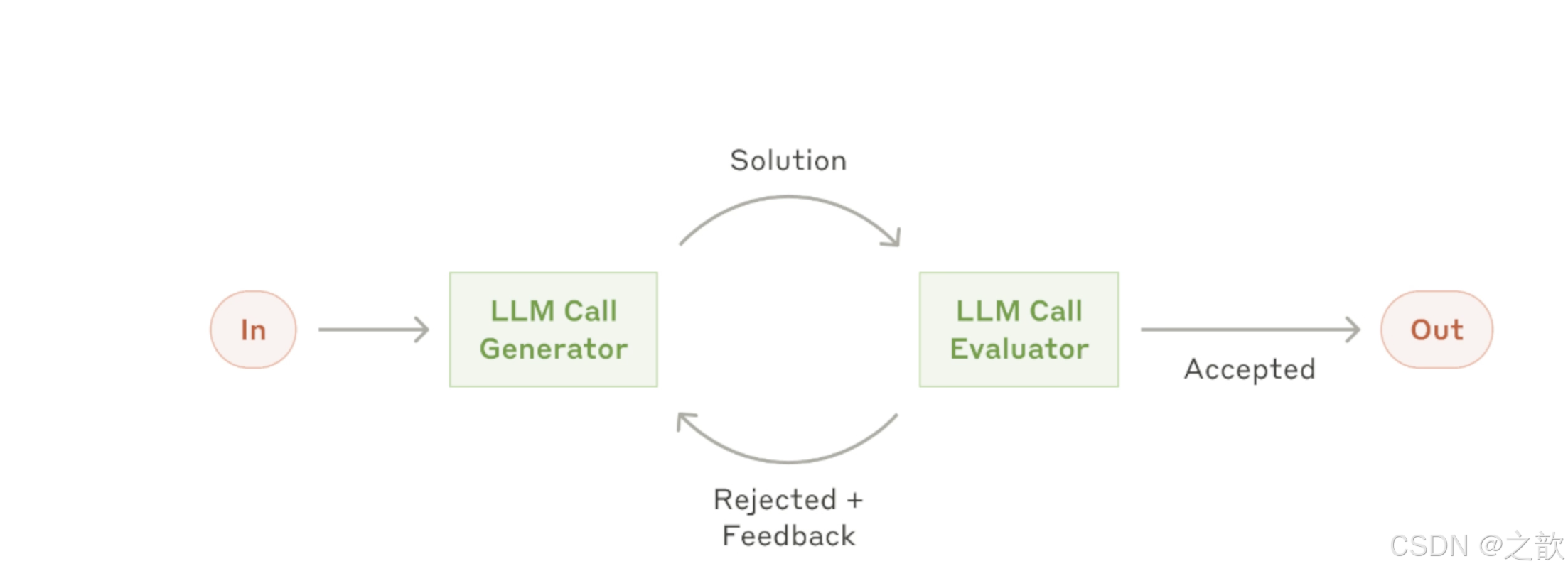
评估优化器模式摘要 评估优化器(Evaluator-Optimizer)是一种基于AI的自动化质量保证机制,采用"生成-评估-优化"循环流程。该系统包含两个独立角色:生成器负责内容创作,评估器进行严格质量审查。通过多轮迭代,系统自动优化输出内容直至达到标准。 核心特点包括: 双角色设计避免自我评估偏见 递归循环实现持续改进 上下文传递历史反馈信息 结构化输出确保流程规范 工作流
评估优化器模式(evaluator-optimizer)
📋 目录
概述
评估优化器(Evaluator-Optimizer) 是一种基于 AI 的迭代式质量保证机制,通过"生成 → 评估 → 优化"的循环流程,确保输出内容达到预期质量标准。
核心思想
生成器(Generator) → 评估器(Evaluator) → 优化器(Optimizer)
↓ ↓ ↓
生成内容 评估质量 根据反馈改进
↑ ↓
└─────────────── 循环迭代 ───────────────────┘
关键特点
- 自动化质量保证:无需人工干预,自动评估和改进
- 迭代优化:通过多轮迭代逐步提升质量
- 反馈驱动:基于评估反馈进行针对性改进
- 标准严格:评估器采用严格标准,确保输出质量
核心原理
1. 生成-评估-优化循环(GEO Loop)
评估优化器实现了经典的 GEO(Generate-Evaluate-Optimize)循环:
┌─────────────────────────────────────────────────────────┐
│ GEO 循环流程 │
└─────────────────────────────────────────────────────────┘
第 N 轮迭代:
┌──────────┐ ┌──────────┐ ┌──────────┐
│ 生成器 │ ───> │ 评估器 │ ───> │ 优化器 │
│ Generator│ │Evaluator │ │Optimizer │
└──────────┘ └──────────┘ └──────────┘
│ │ │
│ │ │
▼ ▼ ▼
生成内容 评估结果 优化策略
│ │ │
│ │ │
└──────────────────┴──────────────────┘
│
▼
是否通过评估?
│
┌───────────┴───────────┐
│ │
PASS FAIL
│ │
▼ ▼
返回结果 进入下一轮迭代
2. 双角色设计
评估优化器使用两个独立的 AI 角色:
角色 1:生成器(Generator)
- 职责:根据任务生成内容
- 特点:创造性、生成性
- Prompt:
GENERATOR_PROMPT
角色 2:评估器(Evaluator)
- 职责:严格评估生成内容的质量
- 特点:批判性、严格性
- Prompt:
EVALUATOR_PROMPT
设计优势:
- 避免"自我评估"的偏见
- 评估器可以更严格、更客观
- 生成器和评估器可以独立优化
代码结构分析
1. 核心类:SimpleEvaluatorOptimizer
public class SimpleEvaluatorOptimizer {
private final ChatClient chatClient; // AI 客户端
// 生成器提示词
private static final String GENERATOR_PROMPT = "...";
// 评估器提示词
private static final String EVALUATOR_PROMPT = "...";
int iteration = 0; // 迭代次数
String context = ""; // 上下文信息(包含历史尝试和反馈)
}
2. 核心方法
方法 1:loop() - 主循环方法
public RefinedResponse loop(String task) {
// 1. 生成内容
Generation generation = generate(task, context);
// 2. 评估内容
EvaluationResponse evaluation = evaluate(generation.response(), task);
// 3. 判断是否通过
if (evaluation.evaluation() == EvaluationResponse.Evaluation.PASS) {
return new RefinedResponse(generation.response());
} else {
// 4. 准备下一轮上下文
context = String.format(
"之前的尝试:\n%s\n\n评估反馈:\n%s\n\n请根据反馈改进代码。",
generation.response(),
evaluation.feedback()
);
iteration++;
// 5. 递归调用,进入下一轮
return loop(task);
}
}
关键点:
- 使用递归实现循环
- 通过
context传递历史信息和反馈 - 只有评估通过才返回结果
方法 2:generate() - 生成方法
private Generation generate(String task, String context) {
return chatClient.prompt()
.user(u -> u.text("{prompt}\n{context}\n任务: {task}")
.param("prompt", GENERATOR_PROMPT)
.param("context", context) // 包含历史尝试和反馈
.param("task", task))
.call()
.entity(Generation.class);
}
关键点:
- 使用结构化输出(
Generationrecord) context参数传递历史信息,实现迭代改进- 生成器会根据反馈调整生成策略
方法 3:evaluate() - 评估方法
private EvaluationResponse evaluate(String content, String task) {
return chatClient.prompt()
.user(u -> u.text("{prompt}\n\n任务: {task}\n\n代码:\n{content}")
.param("prompt", EVALUATOR_PROMPT)
.param("task", task)
.param("content", content))
.call()
.entity(EvaluationResponse.class);
}
关键点:
- 评估器独立于生成器
- 使用结构化输出(
EvaluationResponserecord) - 评估标准在
EVALUATOR_PROMPT中定义
3. 数据模型
Generation(生成结果)
public static record Generation(String thoughts, String response) {}
thoughts:生成器的思考过程和改进思路response:实际生成的内容(代码)
EvaluationResponse(评估结果)
public static record EvaluationResponse(Evaluation evaluation, String feedback) {
public enum Evaluation {
PASS, // 通过
NEEDS_IMPROVEMENT, // 需要改进
FAIL // 失败
}
}
evaluation:评估结果(通过/需要改进/失败)feedback:详细的改进建议
RefinedResponse(最终结果)
public static record RefinedResponse(String solution) {}
solution:经过多轮优化后的最终解决方案
工作流程详解
完整执行流程
┌─────────────────────────────────────────────────────────────┐
│ 评估优化器执行流程 │
└─────────────────────────────────────────────────────────────┘
开始
│
▼
┌─────────────────┐
│ 初始化 │
│ iteration = 0 │
│ context = "" │
└────────┬────────┘
│
▼
┌─────────────────────────────────────┐
│ 第 1 轮迭代 │
├─────────────────────────────────────┤
│ 1. generate(task, "") │
│ └─> 生成初始代码 │
│ │
│ 2. evaluate(code, task) │
│ └─> 评估代码质量 │
│ │
│ 3. 评估结果? │
│ ├─ PASS → 返回结果 ✅ │
│ └─ FAIL → 继续迭代 │
└────────┬────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 准备下一轮上下文 │
│ context = 之前的代码 + 评估反馈 │
│ iteration++ │
└────────┬────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 第 2 轮迭代 │
├─────────────────────────────────────┤
│ 1. generate(task, context) │
│ └─> 根据反馈改进代码 │
│ │
│ 2. evaluate(improvedCode, task) │
│ └─> 再次评估 │
│ │
│ 3. 评估结果? │
│ ├─ PASS → 返回结果 ✅ │
│ └─ FAIL → 继续迭代 │
└────────┬────────────────────────────┘
│
▼
... 继续迭代直到通过 ...
实际执行示例
任务
面试被问:怎么高效的将10000行list<User>数据,转化成map<id,user>,不是用stream.
第 1 轮迭代
生成器输出:
// 生成器思考
thoughts: "使用 HashMap 预分配容量,避免扩容"
// 生成代码
response: """
public Map<Long, User> convert(List<User> users) {
Map<Long, User> map = new HashMap<>();
for (User user : users) {
map.put(user.getId(), user);
}
return map;
}
"""
评估器输出:
{
"evaluation": "NEEDS_IMPROVEMENT",
"feedback": "代码虽然正确,但可以进一步优化:1. HashMap 应该预分配容量避免扩容;2. 可以考虑使用更高效的 Map 实现"
}
第 2 轮迭代
生成器输出(基于反馈改进):
// 生成器思考
thoughts: "根据反馈,预分配 HashMap 容量为 10000,避免扩容带来的性能损失"
// 改进后的代码
response: """
public Map<Long, User> convert(List<User> users) {
Map<Long, User> map = new HashMap<>(users.size());
for (User user : users) {
map.put(user.getId(), user);
}
return map;
}
"""
评估器输出:
{
"evaluation": "PASS",
"feedback": "代码质量优秀,预分配容量避免了扩容,性能优化到位"
}
结果:通过评估,返回最终代码 ✅
使用方式
1. 基本使用
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public CommandLineRunner commandLineRunner(DashScopeChatModel dashScopeChatModel) {
// 1. 创建 ChatClient
var chatClient = ChatClient.create(dashScopeChatModel);
// 2. 创建评估优化器
var optimizer = new SimpleEvaluatorOptimizer(chatClient);
// 3. 执行任务
return args -> {
RefinedResponse response = optimizer.loop("""
任务:生成一个高效的排序算法
""");
System.out.println("最终结果:" + response.solution());
};
}
}
2. 自定义提示词
如果需要自定义生成器或评估器的提示词,可以修改 SimpleEvaluatorOptimizer 类:
// 自定义生成器提示词
private static final String GENERATOR_PROMPT = """
你是一个专业的代码生成助手。
请根据任务要求生成高质量的代码。
...
""";
// 自定义评估器提示词
private static final String EVALUATOR_PROMPT = """
你是一个严格的代码审查专家。
请从以下维度评估代码:
1. 性能
2. 可读性
3. 安全性
...
""";
3. 添加迭代限制
为了防止无限循环,可以添加最大迭代次数:
private static final int MAX_ITERATIONS = 10;
public RefinedResponse loop(String task) {
if (iteration >= MAX_ITERATIONS) {
throw new RuntimeException("达到最大迭代次数,仍未通过评估");
}
// ... 原有逻辑
}
4. 添加超时控制
@Bean
public RestClient.Builder restClientBuilder() {
return RestClient.builder()
.requestFactory(ClientHttpRequestFactories.get(
ClientHttpRequestFactorySettings.DEFAULTS
.withReadTimeout(Duration.ofSeconds(600)) // 10分钟超时
.withConnectTimeout(Duration.ofSeconds(600))
));
}
业务场景
场景 1:代码生成与优化
需求:自动生成高质量代码,确保性能、可读性、安全性
应用:
- 代码生成工具
- 代码审查助手
- 性能优化工具
示例:
optimizer.loop("""
生成一个线程安全的单例模式实现
""");
场景 2:内容质量保证
需求:确保生成的内容(文章、报告、方案)达到质量标准
应用:
- 自动文档生成
- 营销文案生成
- 技术方案生成
示例:
optimizer.loop("""
生成一份关于 Spring AI 的技术报告,要求:
1. 结构清晰
2. 内容准确
3. 语言专业
""");
场景 3:面试题解答
需求:生成高质量的面试题解答,确保答案准确、完整、深入
应用:
- 面试准备工具
- 技术学习助手
- 知识问答系统
示例(当前代码的实际应用):
optimizer.loop("""
面试被问:怎么高效的将10000行list<User>数据,
转化成map<id,user>,不是用stream.
""");
场景 4:算法优化
需求:生成并优化算法实现,确保时间复杂度和空间复杂度最优
应用:
- 算法学习工具
- 性能优化助手
- 竞赛准备工具
示例:
optimizer.loop("""
实现一个高效的快速排序算法,要求:
1. 时间复杂度 O(n log n)
2. 空间复杂度 O(log n)
3. 处理重复元素
""");
场景 5:配置优化
需求:生成并优化配置文件,确保配置正确、高效、安全
应用:
- 配置生成工具
- 系统优化助手
- 安全配置检查
示例:
optimizer.loop("""
生成一个 Spring Boot 应用的数据库连接池配置,
要求:
1. 连接池大小合理
2. 超时设置正确
3. 支持连接泄漏检测
""");
场景 6:测试用例生成
需求:生成全面的测试用例,确保覆盖率高、边界情况完整
应用:
- 测试用例生成工具
- 测试覆盖率提升
- 质量保证系统
示例:
optimizer.loop("""
为一个用户登录功能生成测试用例,要求:
1. 覆盖正常流程
2. 覆盖异常情况
3. 覆盖边界条件
4. 覆盖安全场景
""");
优缺点分析
优点
1. 自动化质量保证
- ✅ 无需人工审查,自动评估和改进
- ✅ 减少人工成本
- ✅ 提高一致性
2. 迭代优化
- ✅ 通过多轮迭代逐步提升质量
- ✅ 基于反馈的针对性改进
- ✅ 最终结果质量有保障
3. 灵活可配置
- ✅ 可以自定义生成器和评估器的提示词
- ✅ 可以调整评估标准
- ✅ 适用于多种场景
4. 结构化输出
- ✅ 使用 record 类型,类型安全
- ✅ 输出格式统一
- ✅ 易于集成
缺点
1. 可能无限循环
- ❌ 如果评估标准过于严格,可能永远无法通过
- ❌ 没有最大迭代次数限制
- 解决方案:添加最大迭代次数限制
2. 成本较高
- ❌ 每轮迭代需要调用两次 AI(生成 + 评估)
- ❌ 多轮迭代成本成倍增加
- 解决方案:设置合理的迭代上限
3. 时间消耗
- ❌ 多轮迭代需要较长时间
- ❌ 不适合实时性要求高的场景
- 解决方案:异步处理或设置超时
4. 评估标准依赖 Prompt
- ❌ 评估质量完全依赖评估器 Prompt 的设计
- ❌ 如果 Prompt 设计不当,可能评估不准确
- 解决方案:精心设计评估器 Prompt,可以结合规则评估
5. 上下文累积
- ❌ 随着迭代次数增加,上下文越来越长
- ❌ 可能超出模型上下文限制
- 解决方案:限制上下文长度,只保留最近几轮的反馈
改进建议
1. 添加迭代限制
private static final int MAX_ITERATIONS = 10;
public RefinedResponse loop(String task) {
if (iteration >= MAX_ITERATIONS) {
System.out.println("达到最大迭代次数,返回当前最佳结果");
return new RefinedResponse(currentBestSolution);
}
// ... 原有逻辑
}
2. 添加超时控制
public RefinedResponse loop(String task, Duration timeout) {
long startTime = System.currentTimeMillis();
while (System.currentTimeMillis() - startTime < timeout.toMillis()) {
// ... 迭代逻辑
}
throw new TimeoutException("评估优化超时");
}
3. 优化上下文管理
// 只保留最近 N 轮的反馈
private static final int MAX_CONTEXT_ROUNDS = 3;
private String buildContext(List<Generation> history, List<EvaluationResponse> evaluations) {
int startIndex = Math.max(0, history.size() - MAX_CONTEXT_ROUNDS);
StringBuilder context = new StringBuilder();
for (int i = startIndex; i < history.size(); i++) {
context.append("第").append(i + 1).append("轮尝试:\n")
.append(history.get(i).response()).append("\n\n")
.append("评估反馈:\n")
.append(evaluations.get(i).feedback()).append("\n\n");
}
return context.toString();
}
4. 添加评估分数
public static record EvaluationResponse(
Evaluation evaluation,
String feedback,
double score // 添加分数:0.0 - 1.0
) {
// ...
}
// 在评估器中要求返回分数
private static final String EVALUATOR_PROMPT = """
...
必须以JSON格式回复:
{
"evaluation": "PASS或NEEDS_IMPROVEMENT或FAIL",
"feedback": "详细的分维度反馈",
"score": 0.0-1.0的分数
}
""";
5. 支持并行评估
// 使用多个评估器并行评估,取平均结果
private EvaluationResponse evaluateParallel(String content, String task) {
List<EvaluationResponse> evaluations = List.of(
evaluateWithEvaluator1(content, task),
evaluateWithEvaluator2(content, task),
evaluateWithEvaluator3(content, task)
);
// 综合多个评估结果
return aggregateEvaluations(evaluations);
}
6. 添加缓存机制
// 缓存已评估的内容,避免重复评估
private final Map<String, EvaluationResponse> evaluationCache = new ConcurrentHashMap<>();
private EvaluationResponse evaluate(String content, String task) {
String cacheKey = content + "|" + task;
return evaluationCache.computeIfAbsent(cacheKey, key -> {
return chatClient.prompt()
.user(u -> u.text("{prompt}\n\n任务: {task}\n\n代码:\n{content}")
.param("prompt", EVALUATOR_PROMPT)
.param("task", task)
.param("content", content))
.call()
.entity(EvaluationResponse.class);
});
}
7. 支持自定义评估标准
public SimpleEvaluatorOptimizer(
ChatClient chatClient,
String generatorPrompt,
String evaluatorPrompt // 允许自定义评估标准
) {
this.chatClient = chatClient;
this.generatorPrompt = generatorPrompt;
this.evaluatorPrompt = evaluatorPrompt;
}
8. 添加进度回调
public interface ProgressCallback {
void onIteration(int iteration, Generation generation, EvaluationResponse evaluation);
void onComplete(RefinedResponse result);
void onError(Exception error);
}
public RefinedResponse loop(String task, ProgressCallback callback) {
try {
// ... 迭代逻辑
callback.onIteration(iteration, generation, evaluation);
// ...
callback.onComplete(result);
return result;
} catch (Exception e) {
callback.onError(e);
throw e;
}
}
总结
核心价值
评估优化器通过 “生成 → 评估 → 优化” 的迭代循环,实现了:
- 自动化质量保证:无需人工干预,自动提升输出质量
- 迭代改进:通过多轮迭代逐步优化
- 反馈驱动:基于评估反馈进行针对性改进
- 严格标准:确保最终结果达到高质量标准
适用场景
- ✅ 代码生成与优化
- ✅ 内容质量保证
- ✅ 面试题解答
- ✅ 算法优化
- ✅ 配置优化
- ✅ 测试用例生成
关键要点
- 双角色设计:生成器和评估器分离,避免偏见
- 迭代优化:通过多轮迭代逐步提升质量
- 上下文传递:通过 context 传递历史信息和反馈
- 结构化输出:使用 record 类型,类型安全
注意事项
- ⚠️ 需要设置最大迭代次数,防止无限循环
- ⚠️ 注意成本控制,每轮迭代需要调用两次 AI
- ⚠️ 评估标准的设计至关重要,影响最终质量
- ⚠️ 上下文管理需要注意长度限制
未来改进方向
- 支持多评估器并行评估
- 添加评估分数机制
- 优化上下文管理策略
- 支持自定义评估标准
- 添加缓存机制减少重复评估
- 支持异步处理和进度回调
参考代码位置:
SimpleEvaluatorOptimizer.java:核心实现Application.java:使用示例
相关模式:
- 生成-评估-优化循环(GEO Loop)
- 迭代式改进(Iterative Refinement)
- 反馈驱动优化(Feedback-Driven Optimization)
根据任务–>生成信息—>通过评估器不断完善—>最终输出结果
示例:
application.properties
spring.ai.dashscope.api-key=sk-xxx
spring.ai.dashscope.embedding.options.model= text-embedding-v4
package com.xs.agent.evaluator_optimizer;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.evaluation.EvaluationResponse;
import java.util.ArrayList;
import java.util.List;
public class SimpleEvaluatorOptimizer {
private final ChatClient chatClient;
// 中文生成器提示词
private static final String GENERATOR_PROMPT = """
你是一个Java代码生成助手。请根据任务要求生成高质量的Java代码。
重要提醒:
- 第一次生成时,创建一个基础但完整的实现
- 如果收到反馈,请仔细分析每一条建议并逐一改进
- 每次迭代都要在前一版本基础上显著提升代码质量
- 不要一次性实现所有功能,而是逐步完善
必须以JSON格式回复:
{"thoughts":"详细说明本轮的改进思路","response":"改进后的Java代码"}
""";
// 中文评估器提示词
private static final String EVALUATOR_PROMPT = """
你是一个非常严格的面试官。请从以下维度严格评估代码:
1. 代码是否高效:从底层分析每一个类型以满足最佳性能!
2. 满足不重复扩容影响的性能
评估标准:
- 只有当代码满足要求达到优秀水平时才返回PASS
- 如果任何一个维度有改进空间,必须返回NEEDS_IMPROVEMENT
- 提供具体、详细的改进建议
必须以JSON格式回复:
{"evaluation":"PASS或NEEDS_IMPROVEMENT或FAIL","feedback":"详细的分维度反馈"}
记住:宁可严格也不要放松标准!
""";
public SimpleEvaluatorOptimizer(ChatClient chatClient) {
this.chatClient = chatClient;
}
int iteration = 0;
String context = "";
public RefinedResponse loop(String task) {
System.out.println("=== 第" + (iteration + 1) + "轮迭代 ===");
// 生成代码
Generation generation = generate(task,context);
// 评估代码
EvaluationResponse evaluation = evaluate(generation.response(), task);
System.out.println("生成结果: " + generation.response());
System.out.println("评估结果: " + evaluation.evaluation());
System.out.println("反馈: " + evaluation.feedback());
if (evaluation.evaluation() == EvaluationResponse.Evaluation.PASS) {
System.out.println("代码通过评估!");
return new RefinedResponse(generation.response());
}
else{
// 准备下一轮的上下文
context = String.format("之前的尝试:\n%s\n\n评估反馈:\n%s\n\n请根据反馈改进代码。",
generation.response(), evaluation.feedback());
iteration++;
return loop(task);
}
}
private Generation generate(String task, String context) {
return chatClient.prompt()
.user(u -> u.text("{prompt}\n{context}\n任务: {task}")
.param("prompt", GENERATOR_PROMPT)
.param("context", context)
.param("task", task))
.call()
.entity(Generation.class);
}
private EvaluationResponse evaluate(String content, String task) {
return chatClient.prompt()
.user(u -> u.text("{prompt}\n\n任务: {task}\n\n代码:\n{content}")
.param("prompt", EVALUATOR_PROMPT)
.param("task", task)
.param("content", content))
.call()
.entity(EvaluationResponse.class);
}
// 使用原始的记录类
public static record Generation(String thoughts, String response) {}
public static record EvaluationResponse(Evaluation evaluation, String feedback) {
public enum Evaluation { PASS, NEEDS_IMPROVEMENT, FAIL }
}
public static record RefinedResponse(String solution) {}
}
启动类
/*
* Copyright 2024 - 2024 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.xs.agent.evaluator_optimizer;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.xs.agent.config.RestClientConfig;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.web.client.RestClientBuilderConfigurer;
import org.springframework.boot.web.client.ClientHttpRequestFactories;
import org.springframework.boot.web.client.ClientHttpRequestFactorySettings;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Import;
import org.springframework.context.annotation.Scope;
import org.springframework.web.client.RestClient;
import java.time.Duration;
// ------------------------------------------------------------
// EVALUATOR-OPTIMIZER
// ------------------------------------------------------------
@SpringBootApplication
@Import(RestClientConfig.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public CommandLineRunner commandLineRunner(DashScopeChatModel dashScopeChatModel) {
var chatClient = ChatClient.create(dashScopeChatModel);
return args -> {
new SimpleEvaluatorOptimizer(chatClient).loop("""
<user input>
面试被问: 怎么高效的将10000行list<User>数据,转化成map<id,user>,不是用stream.
</user input>
""");
};
}
}
测试结果
2026-01-15T09:25:02.625+08:00 INFO 17610 --- [ main] c.x.a.evaluator_optimizer.Application : Started Application in 1.198 seconds (process running for 1.463)
=== 第1轮迭代 ===
生成结果: import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class User {
private Long id;
private String name;
public User(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "User{id=" + id + ", name='" + name + "'}";
}
}
public class ListToMapConverter {
public static Map<Long, User> convertListToMap(List<User> userList) {
// 预设容量,减少扩容开销
Map<Long, User> userMap = new HashMap<>((int) (userList.size() / 0.75f) + 1);
for (User user : userList) {
userMap.put(user.getId(), user);
}
return userMap;
}
public static void main(String[] args) {
List<User> users = new ArrayList<>();
for (int i = 1; i <= 10000; i++) {
users.add(new User((long) i, "User" + i));
}
Map<Long, User> userMap = convertListToMap(users);
System.out.println("Converted map size: " + userMap.size());
}
}
评估结果: NEEDS_IMPROVEMENT
反馈: 1. 代码效率:虽然使用了增强for循环进行遍历,这是合理的,但未考虑并发或并行处理场景下的性能优化。对于10000行数据,单线程处理是可接受的,但仍有潜在优化空间(如批量处理、缓存友好性),不过当前实现已接近最优,此项尚可接受。
2. 扩容影响:预设HashMap容量的计算方式为 (int)(size / 0.75f) + 1,这确实是防止初始扩容的标准做法,因为HashMap默认负载因子为0.75。然而,该计算未充分考虑哈希冲突和底层桶数组的实际分配策略。更精确的做法是使用 `HashMap<>(calculateCapacity(userList.size()))` 并参考JDK的tableSizeFor逻辑,确保初始容量为2的幂次,从而完全避免早期扩容。当前计算可能导致实际容量仍触发resize——例如当size=10000时,10000/0.75≈13334,+1后为13335,而HashMap会将其调整到下一个2的幂(16384),但此过程依赖内部resize,未能在构造时直接传入正确大小。应改为调用静态方法明确计算目标容量,以彻底消除任何扩容可能。
改进建议:
- 引入一个私有方法 `static int getInitialCapacity(int expectedSize)`,返回大于等于 expectedSize / 0.75 的最小2的幂。
- 使用该值作为HashMap构造函数参数,确保从一开始就无需resize。
- 示例实现:
private static int getInitialCapacity(int expectedSize) {
int cap = (int) Math.ceil(expectedSize / 0.75f);
int n = 1;
while (n < cap) n <<= 1;
return n;
}
综上,尽管代码整体结构良好且性能较好,但由于未能完全消除HashMap扩容的可能性,在极端重视性能的场景下仍存在微小风险,因此不满足‘优秀’标准。
=== 第2轮迭代 ===
生成结果: import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class User {
private Long id;
private String name;
public User(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
@Override
public String toString() {
return \"User{id=\" + id + \", name='\" + name + \"'}\";
}
}
public class ListToMapConverter {
private static int getInitialCapacity(int expectedSize) {
int cap = (int) Math.ceil(expectedSize / 0.75f);
int n = 1;
while (n < cap) n <<= 1;
return n;
}
public static Map<Long, User> convertListToMap(List<User> userList) {
Map<Long, User> userMap = new HashMap<>(getInitialCapacity(userList.size()));
for (User user : userList) {
userMap.put(user.getId(), user);
}
return userMap;
}
public static void main(String[] args) {
List<User> users = new ArrayList<>();
for (int i = 1; i <= 10000; i++) {
users.add(new User((long) i, \"User\" + i));
}
Map<Long, User> userMap = convertListToMap(users);
System.out.println(\"Converted map size: \" + userMap.size());
}
}
评估结果: NEEDS_IMPROVEMENT
反馈: 1. 代码是否高效:从底层分析每一个类型以满足最佳性能!
- 虽然使用了预估容量并通过负载因子0.75计算初始容量,但HashMap的构造函数接受的初始容量是直接作为底层数组大小的提示,而你的getInitialCapacity方法进行了不必要的二次幂对齐。JDK的HashMap内部已经处理了容量对齐(即自动扩展到2的幂),因此手动进行n <<= 1是冗余操作,并可能因过度对齐导致内存浪费(例如当size=10000时,实际需要约13334,向上取2的幂为16384,远超必要)。这影响空间效率和缓存局部性。
- 建议直接使用Math.ceil(expectedSize / 0.75f)的结果作为构造参数即可,无需手动对齐2的幂。
2. 满足不重复扩容影响的性能
- 尽管通过预计算容量避免了动态扩容,但由于上述错误地将容量调整至2的幂且算法实现冗余,增加了不必要的内存占用。虽然确实避免了rehashing,但代价是潜在多占用~20-25%的桶空间(如10000元素本需约13334桶,却被扩大到16384)。
- 此外,未考虑并发或不可变性等高性能场景下的优化(如构建后不可变Map),但对于单次转换任务尚可接受。
综上所述:尽管逻辑正确并避免了扩容,但在底层类型使用与容量控制上存在冗余设计,未达最优性能标准。建议移除手动2的幂对齐逻辑,直接传入基于负载因子计算后的容量值。
=== 第3轮迭代 ===
生成结果: import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class User {
private Long id;
private String name;
public User(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
@Override
public String toString() {
return \"User{id=\" + id + \", name='\" + name + \"'}\";
}
}
public class ListToMapConverter {
private static int getInitialCapacity(int expectedSize) {
return (int) Math.ceil(expectedSize / 0.75f);
}
public static Map<Long, User> convertListToMap(List<User> userList) {
Map<Long, User> userMap = new HashMap<>(getInitialCapacity(userList.size()));
for (User user : userList) {
userMap.put(user.getId(), user);
}
return userMap;
}
public static void main(String[] args) {
List<User> users = new ArrayList<>();
for (int i = 1; i <= 10000; i++) {
users.add(new User((long) i, \"User\" + i));
}
Map<Long, User> userMap = convertListToMap(users);
System.out.println(\"Converted map size: \" + userMap.size());
}
}
评估结果: NEEDS_IMPROVEMENT
反馈: 1. 代码是否高效:
- 虽然使用了HashMap并预先计算初始容量,但getInitialCapacity方法中使用了浮点运算Math.ceil和除以0.75f,这在性能敏感场景下是不必要的开销。应使用整数运算替代:(expectedSize * 4 + 2) / 3 或更优的位运算近似来避免浮点操作。
- HashMap的加载因子硬编码为0.75f,虽然合理,但未考虑实际场景是否可调整。对于已知大小的10000条数据,应直接使用最接近的2的幂且能容纳10000/0.75 ≈ 13333的容量(即16384),可进一步减少哈希冲突和扩容概率。
2. 满足不重复扩容影响的性能:
- 尽管预设了初始容量,但getInitialCapacity计算方式不够精确且依赖浮点运算,可能导致最终容量仍触发一次扩容。例如,当userList.size()=10000时,计算值为13334,HashMap会将其调整为大于等于13334的最小2的幂(16384),这是正确的,但过程低效。
- 更优做法是使用Integer.highestOneBit或位移操作手动计算目标容量,确保无浮点运算、无函数调用开销,并保证一次性分配到位,彻底避免任何扩容可能。
改进建议:
- 替换getInitialCapacity实现为纯整数位运算版本,例如:
private static int getInitialCapacity(int expectedSize) {
int cap = 1;
while (cap < expectedSize) cap <<= 1;
return cap;
}
- 或者直接使用 (int) ((float) expectedSize / 0.75f + 1.0f) 并通过位运算向上取最近2的幂,避免浮点除法。
- 进一步可考虑使用LinkedHashMap若需保持插入顺序,但当前需求未提,故HashMap足够。
综上,虽逻辑正确,但在底层性能优化和扩容控制上仍有改进空间,未达优秀水平。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)