AI大模型开发实战:(七)基于 Dify + Ollama 搭建私有化知识问答助手
Dify 是一个开源的 LLM 应用开发平台,它解决了 LLM 开发中最常见的问题:知识库的切片与索引、Prompt 的编排、上下文记忆的管理,以及对外提供标准的 API 接口。
你是否也有过这样的经历:当汽车仪表盘上突然跳出一个陌生的黄色故障灯,或者你想调整后视镜的倒车下翻功能,却不得不从副驾手套箱里翻出那本厚达 400 页、封皮都快粘连的《用户使用手册》。你试图在目录中寻找关键词,翻到第 218 页,却发现还有“参见第 56 页”的跳转。在那一刻,你一定希望有一个懂行的老司机坐在旁边,你只需问一句:“这个像茶壶一样的灯亮了是什么意思?”,他就能立马告诉你答案。
在 AI 大模型时代,这个愿望已经可以零成本实现。今天这篇博客,将带大家实战一个非常典型的 RAG(检索增强生成) 场景:利用开源工具 Dify 和本地大模型工具 Ollama,搭建一个能够完全读懂你汽车手册的 AI 智能体。完成后,不仅可以通过 Web 界面与它对话,还能通过 Python API 将其集成到其他应用中。
为什么选择 Dify + Ollama
在开始动手之前,先聊聊为什么选择这套技术栈。市面上有很多构建 AI 应用的方法,比如像之前博客介绍的那样直接用 LangChain 手搓,或者使用云端的 API,但对于不懂编程、不懂技术的用户,Dify + Ollama 是目前性价比最高、上手最快的选择。
Ollama:之前已经介绍过了,它是目前在本地运行大语言模型(LLM)最简单的工具。不需要复杂的环境配置,不需要研究 PyTorch,只需一行命令,就能在 PC 上运行 Llama 3、Qwen 2.5 等开源模型,最重要的是,它是本地化的,隐私绝对安全。
Dify:如果说 Ollama 提供了“大脑”,那么 Dify 就提供了“身体”和“四肢”,使模型具备了一些“能力”。Dify 是一个开源的 LLM 应用开发平台,它解决了 LLM 开发中最常见的问题:知识库的切片与索引、Prompt 的编排、上下文记忆的管理,以及对外提供标准的 API 接口。它是低代码的,几乎不需要写代码就能搭出一个企业级的 AI 应用。
在接下来的教程中,将完成以下操作:
- 环境搭建:在本地部署 Ollama 和 Dify。
- 模型接入:让 Dify 连接上本地运行的 Qwen2.5 模型。
- 知识库构建:上传《用户手册》PDF,通过 RAG 技术让 AI “学会”手册的内容。
- 智能体编排:调试 Prompt,让它根据用户手册回答问题。
- API 调用:编写 Python 脚本调用搭建好的智能体,实现问答。
Ollama 本地部署
Ollama 的安装极度简化,几乎是“开箱即用”。直接访问 Ollama 官网 https://ollama.com/download 下载安装包即可。Linux 使用官方的一键安装脚本 curl -fsSL https://ollama.com/install.sh | sh。安装完成后,在命令行输入 ollama -v,看到版本号即表示安装成功。
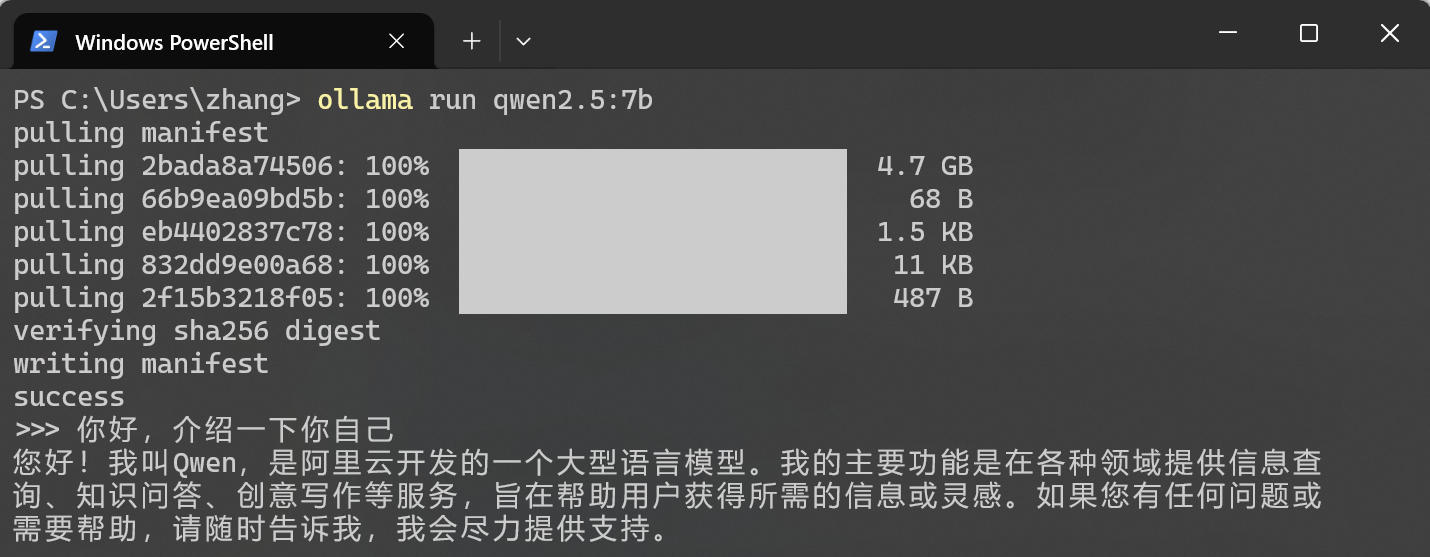
访问 https://ollama.com/search 可以查看 Ollama 支持的模型,这里选择 Qwen2.5-7B 版本(70 亿参数,平衡了速度和智能)。在命令行中执行 ollama run qwen2.5:7b,等待模型下载完成(大约 5GB),即可在本地运行该模型。下载完成后,会直接进入对话框。你可以试着问它:“你好,介绍一下你自己。” 如果它能流畅回复,说明模型已经激活。按 Ctrl + D 退出对话模式,模型会在后台继续运行。
Dify 本地容器化部署
为了保证环境的纯净和易于管理,官方推荐使用 Docker Compose 进行部署。首先,确保你的机器上安装了 Docker 和 Docker Compose(https://www.docker.com)。下面需要将 Dify 的代码仓库下载到本地。在命令行中执行以下命令 git clone --depth 1 https://github.com/langgenius/dify.git,如果你本地没有安装 Git,也可以直接去 GitHub 页面下载 ZIP 压缩包并解压。
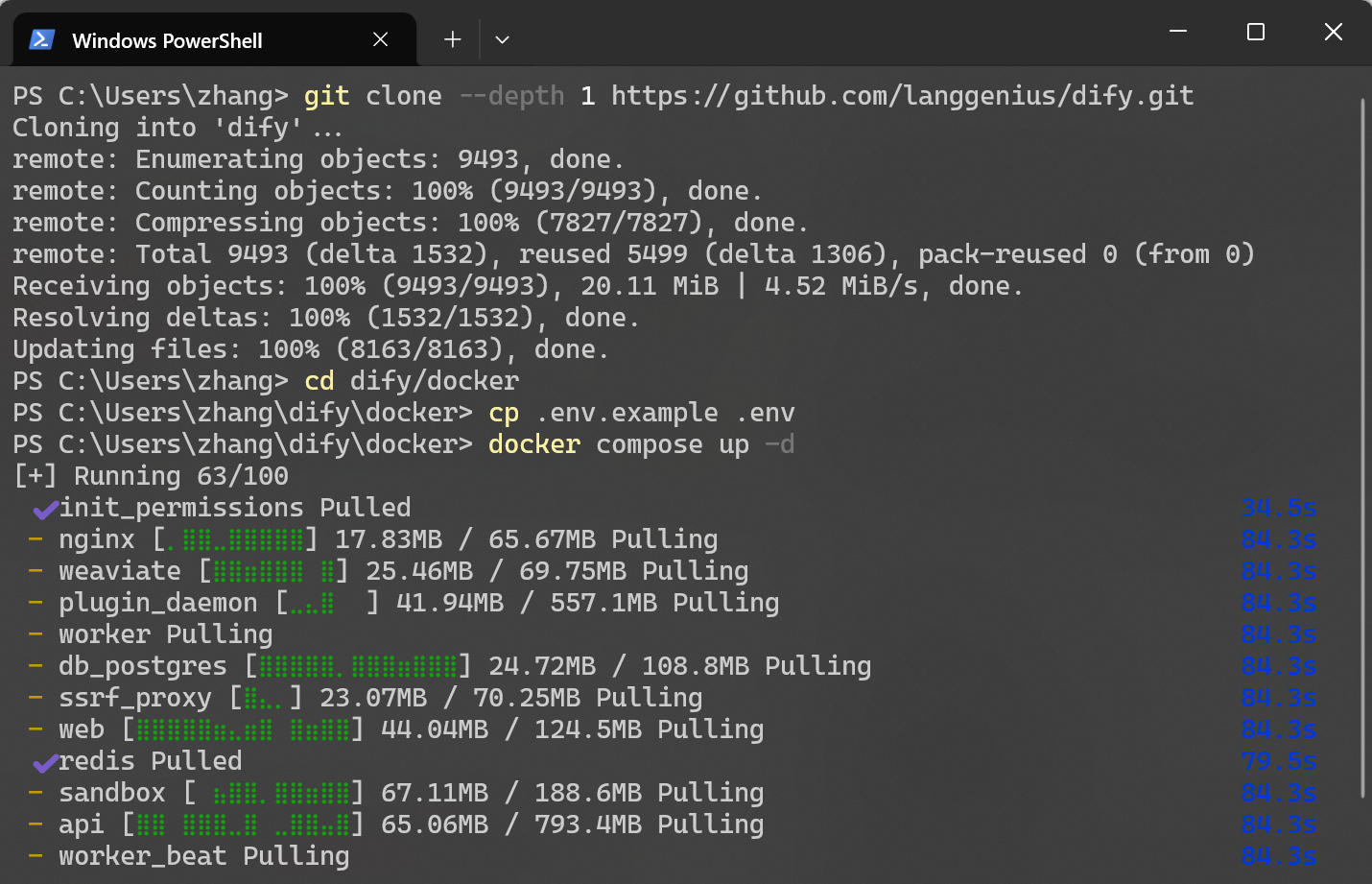
Dify 是一个完整的应用架构,包含前端、后端、数据库(PostgreSQL)、缓存(Redis)和向量数据库(Weaviate/Qdrant)等多个组件。手动安装这些组件非常繁琐,但通过 Docker Compose,可以一键拉起所有服务。进入目录并执行以下命令,初次运行需要拉取多个 Docker 镜像。
# 进入 docker 目录
cd dify/docker
# 复制环境变量配置文件
cp .env.example .env
# 启动容器
docker compose up -d
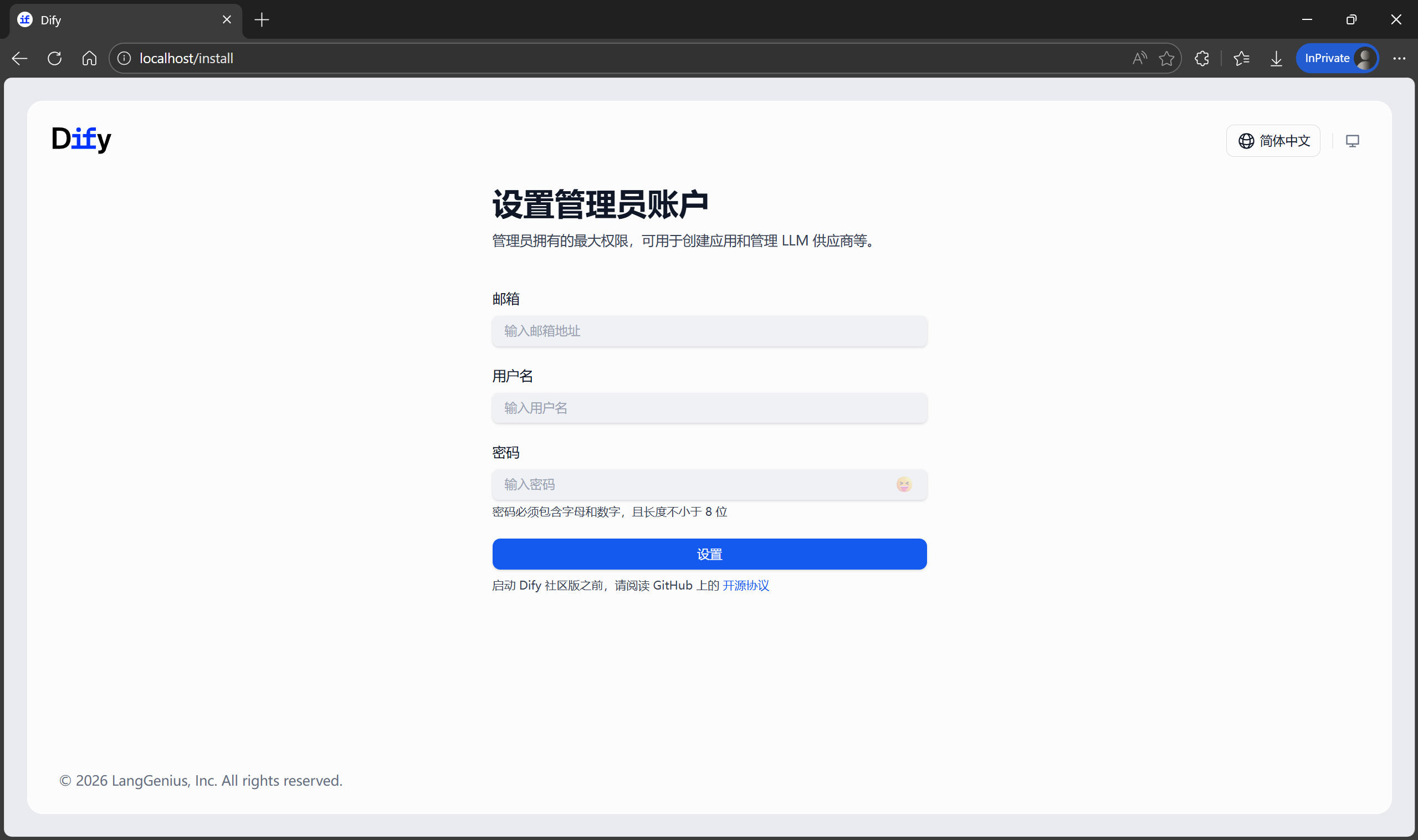
等待所有容器启动完毕后,打开浏览器,访问 http://localhost/install,你将看到 Dify 的初始化引导界面。在这里设置你的管理员账号和密码。设置完成后,即可登录进入 Dify。
模型接入与知识库 RAG 构建
环境搭建完毕后,目前的 Dify 还是一个“空壳”。下面需要做两件事:
- 把 Ollama 的模型接入 Dify,让它拥有对话和理解能力;
- 把《用户手册》喂给它,构建向量知识库。
准备 Embedding 模型
在构建知识库时,除了对话模型,还需要一个专门的 Text Embedding(文本向量化)模型。之前的博客已经介绍了 Embedding 的概念,简单来说,它的作用是把手册里的文字变成计算机能理解的“数字向量”。打开命令行,拉取轻量级向量模型 ollama pull nomic-embed-text。
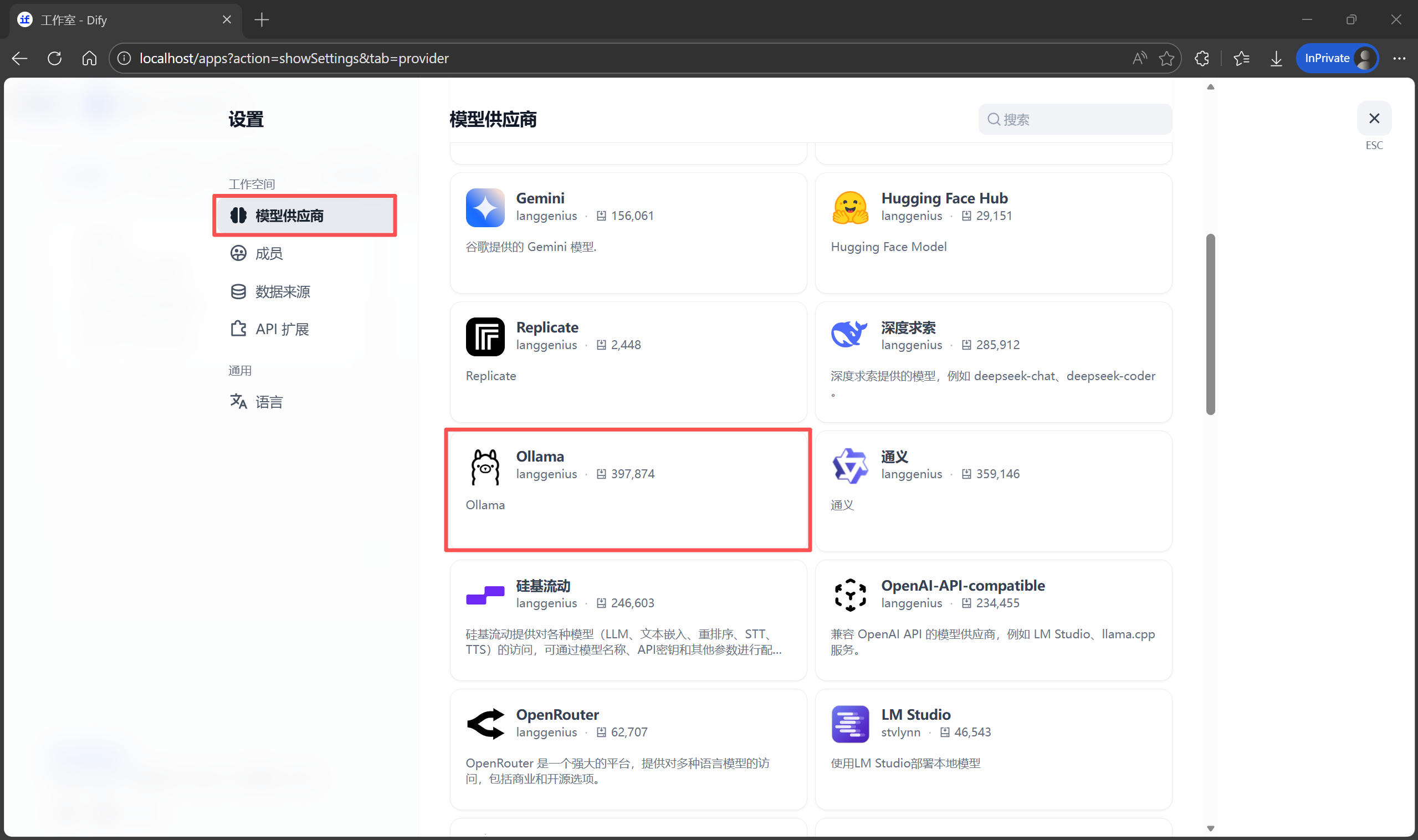
在 Dify 中添加 Ollama 模型供应商
回到 Dify 的网页界面:
- 点击右上角的
头像 -> 设置 -> 模型供应商。 - 找到 Ollama 卡片,点击“安装”。
- 安装完成后,点击 Ollama 卡片中的“添加模型”。
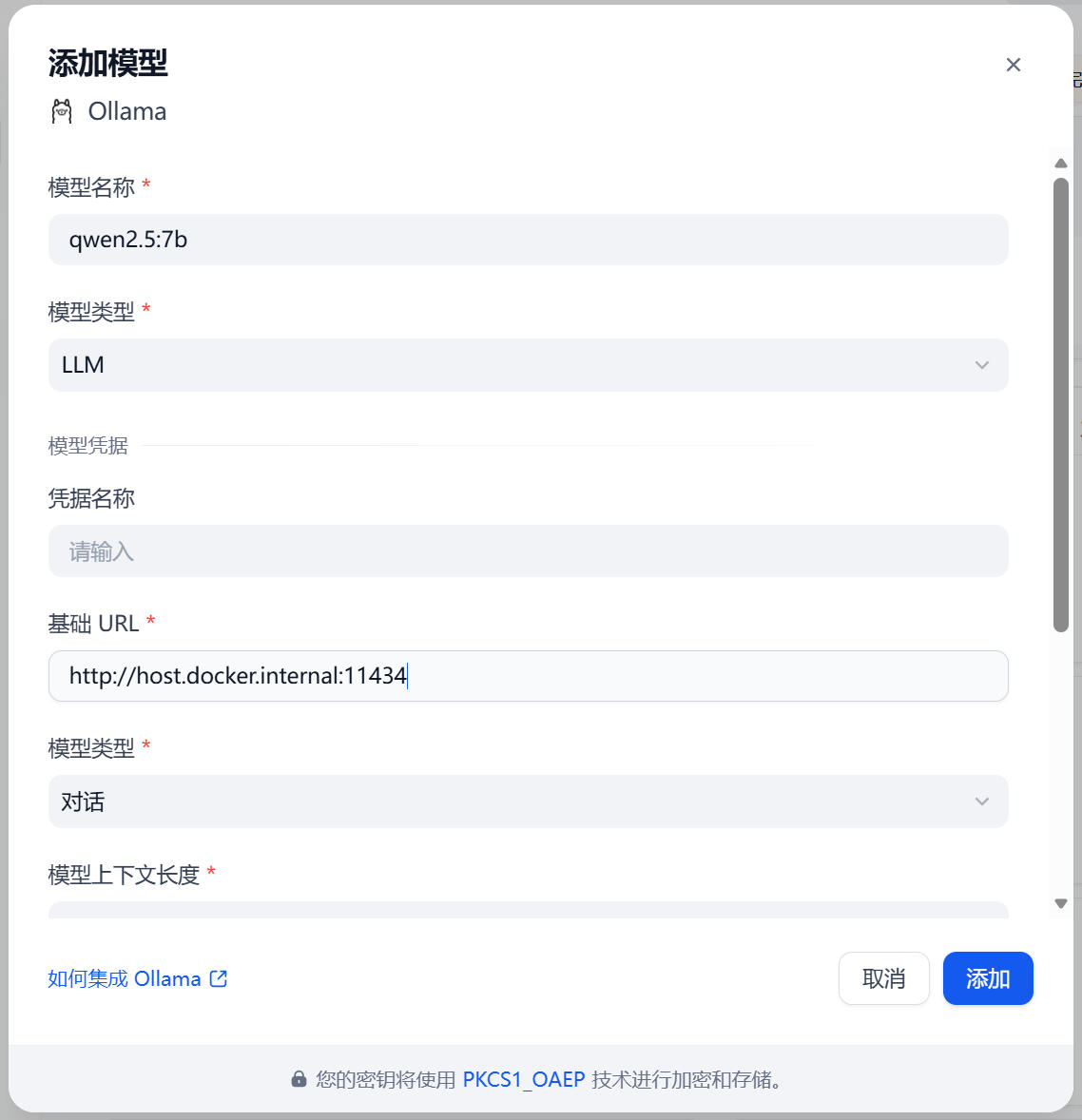
这里需要添加两次:
第一次:添加 LLM(对话模型)
- 模型名称:qwen2.5:7b(必须与你在命令行 ollama list 查看到的名称完全一致)
- 模型类型:LLM
- 基础 URL:http://host.docker.internal:11434(Docker 容器访问宿主机的地址)
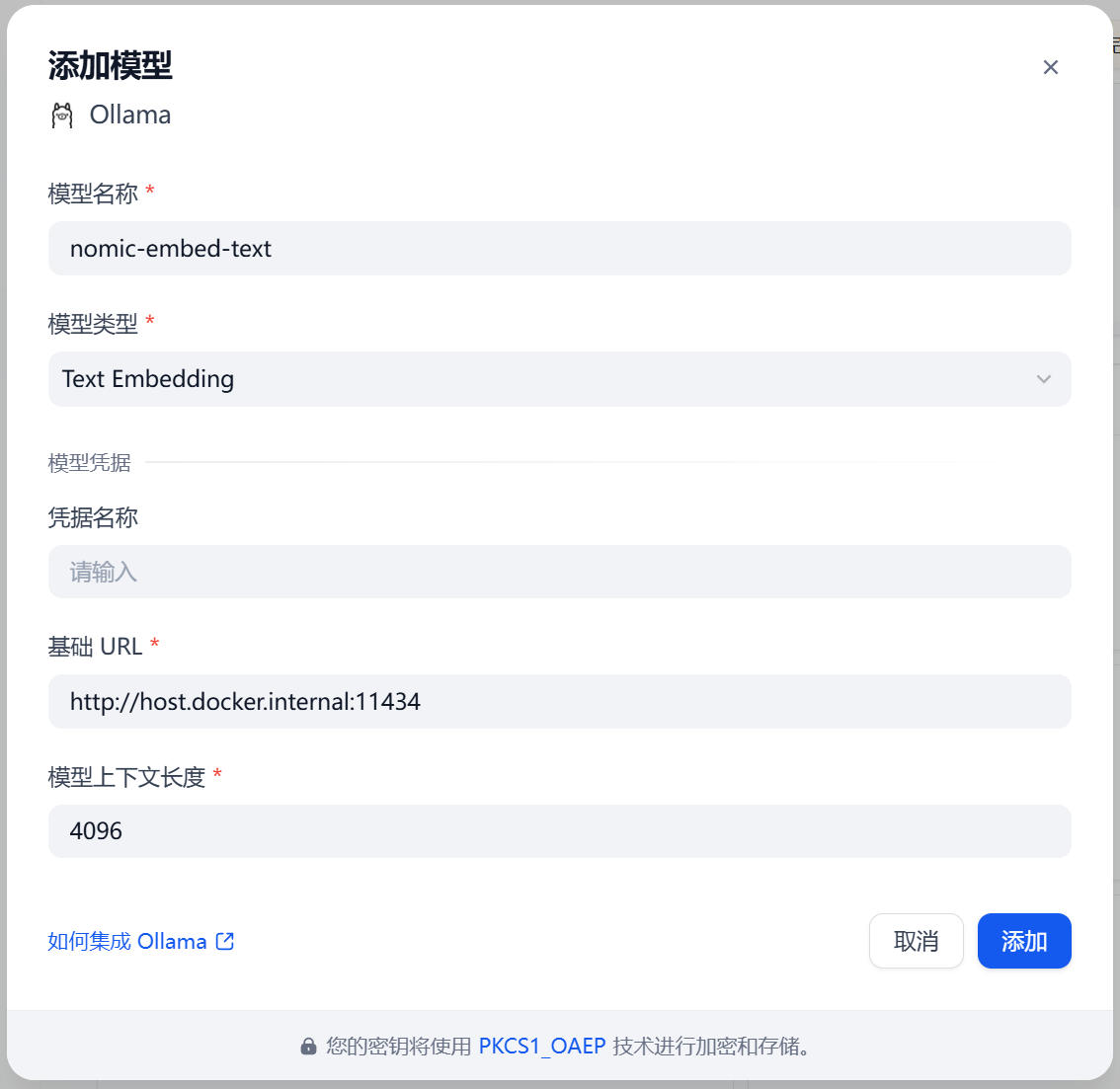
第二次:添加 Text Embedding(向量模型)
- 模型名称:nomic-embed-text
- 模型类型:Text Embedding
- 基础 URL:同上
如果保存时提示“Error”,请检查 Ollama 能否通过 URL http://localhost:11434 访问,或者 Docker 网络配置和防火墙设置。
构建知识库
- 点击顶部导航栏的
知识库 -> 创建知识库。
- 上传文档:选择“导入已有文本”,将
用户手册.pdf拖进去,点击“下一步”。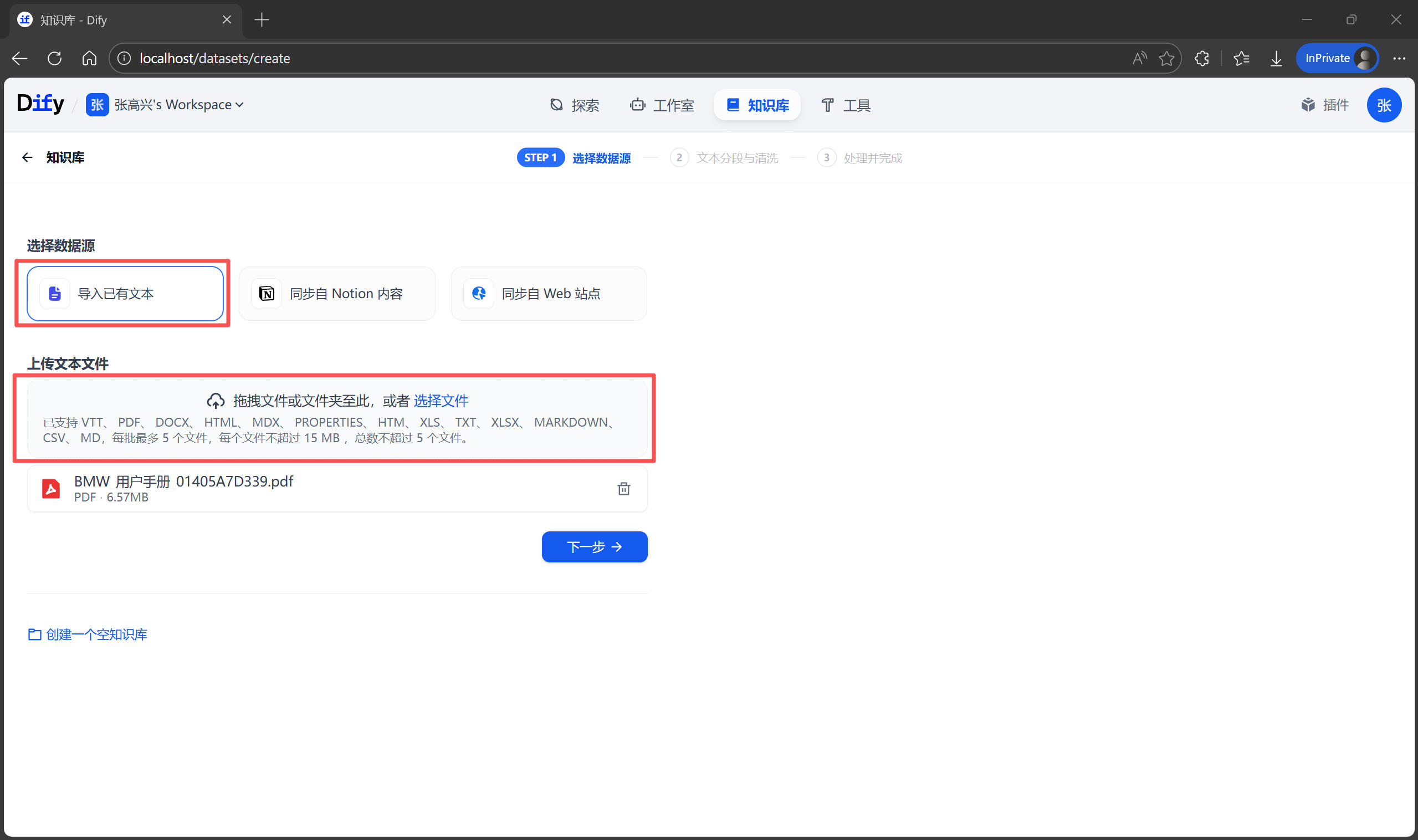
- 分段(Chunk)设置:这里需要配置如何将 PDF 拆解成小段落,方便后续检索。
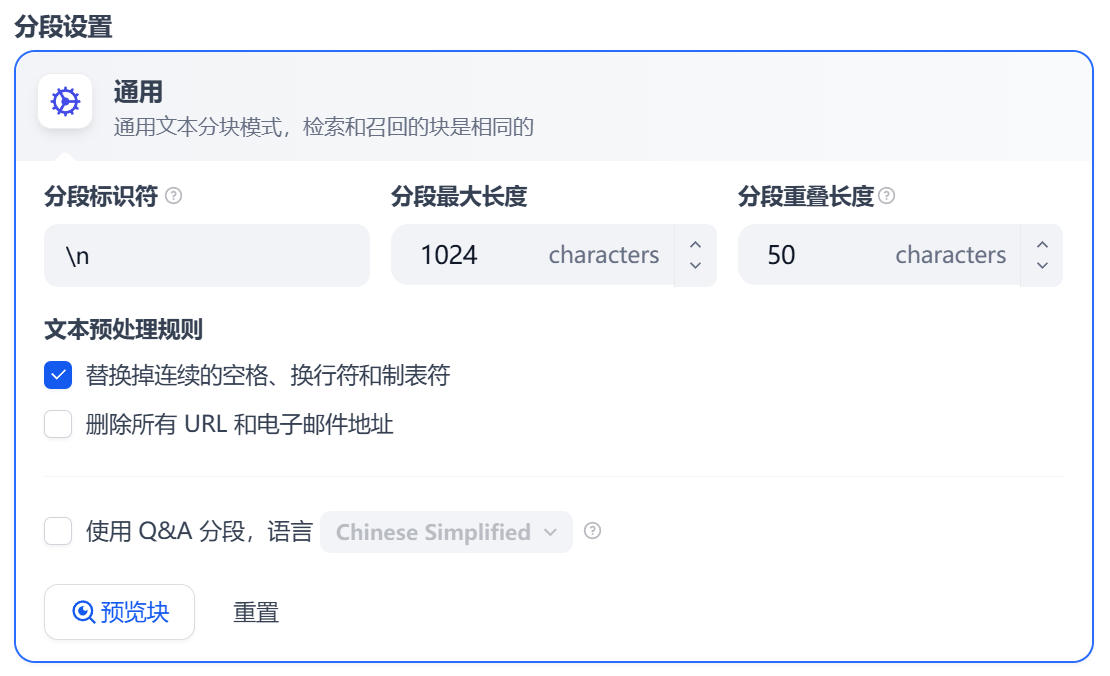
- 分段标识符:文档段落之间是怎样分隔的。
\n表示换行符,例如此处上传的文档段落之间就是通过换行符分隔的,有些时候可能会使用双换行符\n\n,即两个段落之间有一个空行。
- 最大分段长度:决定了 AI “一口吃多少东西”。如果设置得太小,知识库会被切得过碎,影响检索效果;如果设置得太大,AI 可能无法有效利用上下文。
- 分段重叠长度*:相邻段落之间重叠的字符数,有助于保持上下文连续性。
- 使用 Q&A 分段:如果你的文档是“问答”类型的,开启此选项可以让 Dify 识别问答对,提升检索效果。
- 分段标识符:文档段落之间是怎样分隔的。
- 索引方式:选择 “高质量”,这会调用刚才配置的
nomic-embed-text模型进行向量化处理。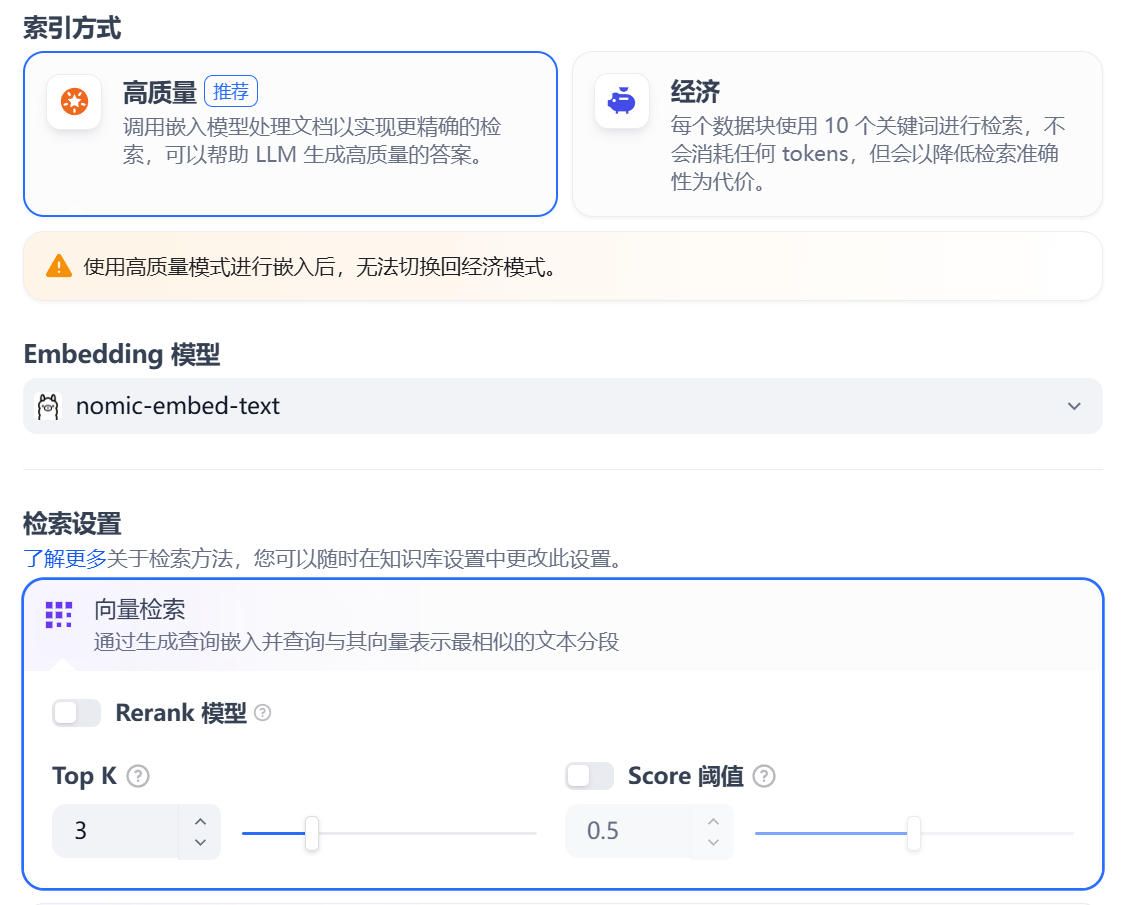
- 点击 “保存并处理”。
此时,Dify 会将几百页的 PDF 拆解成小段,转换成向量,并存入内置的向量数据库中。根据文档大小,这可能需要较长的时间。
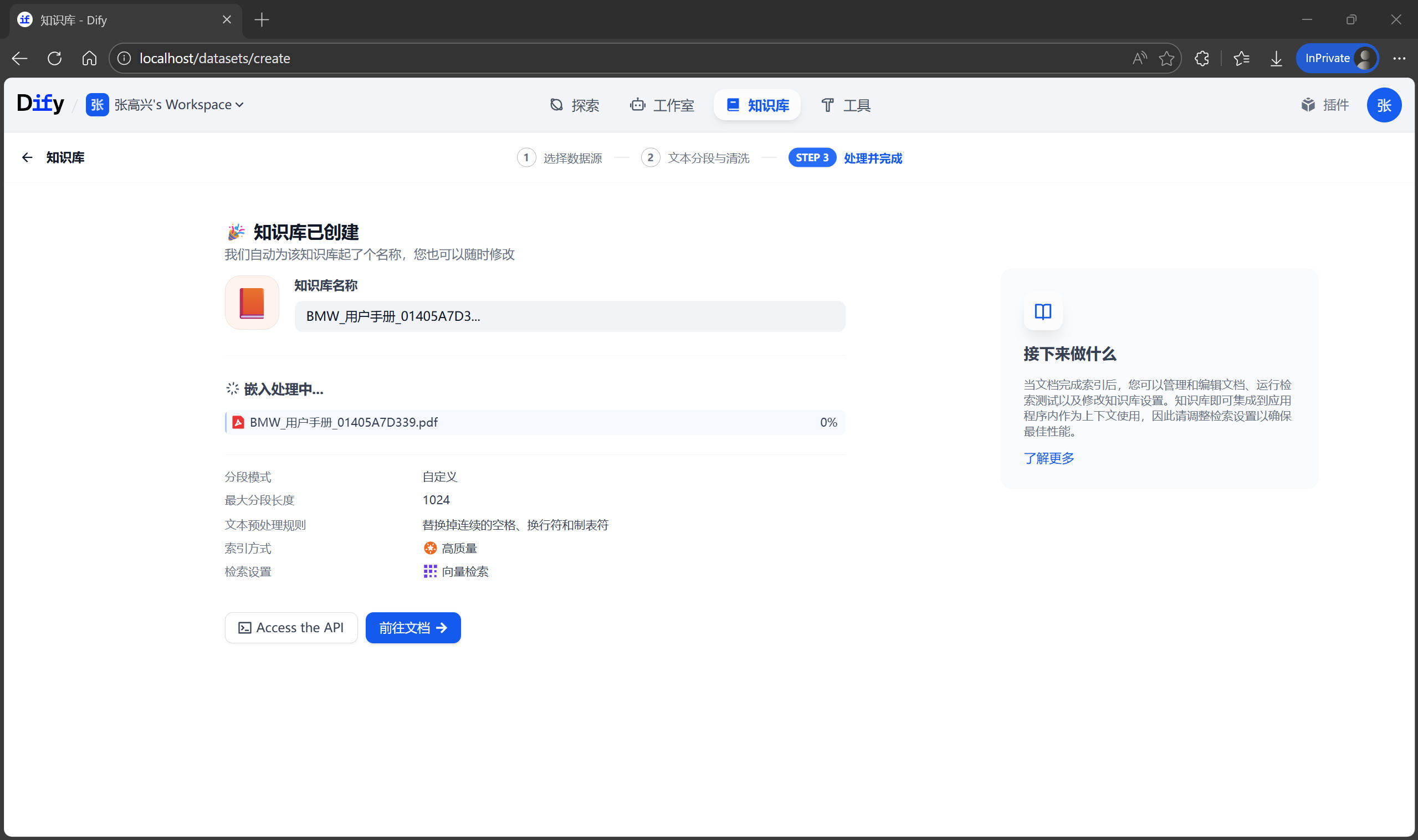
检索测试
不要急着去创建聊天助手,先确认知识库“懂了”没有。在知识库详情页的左侧,找到 召回测试 按钮。这里可以模拟检索过程。例如输入测试文本:“如何打开远光灯?”,点击 测试,系统会展示它从手册中找到的最相关的几个段落。如果结果不准,说明分段可能切得太碎了,或者 PDF 解析乱码。这时需要回到 设置 中调整分段规则重新索引。
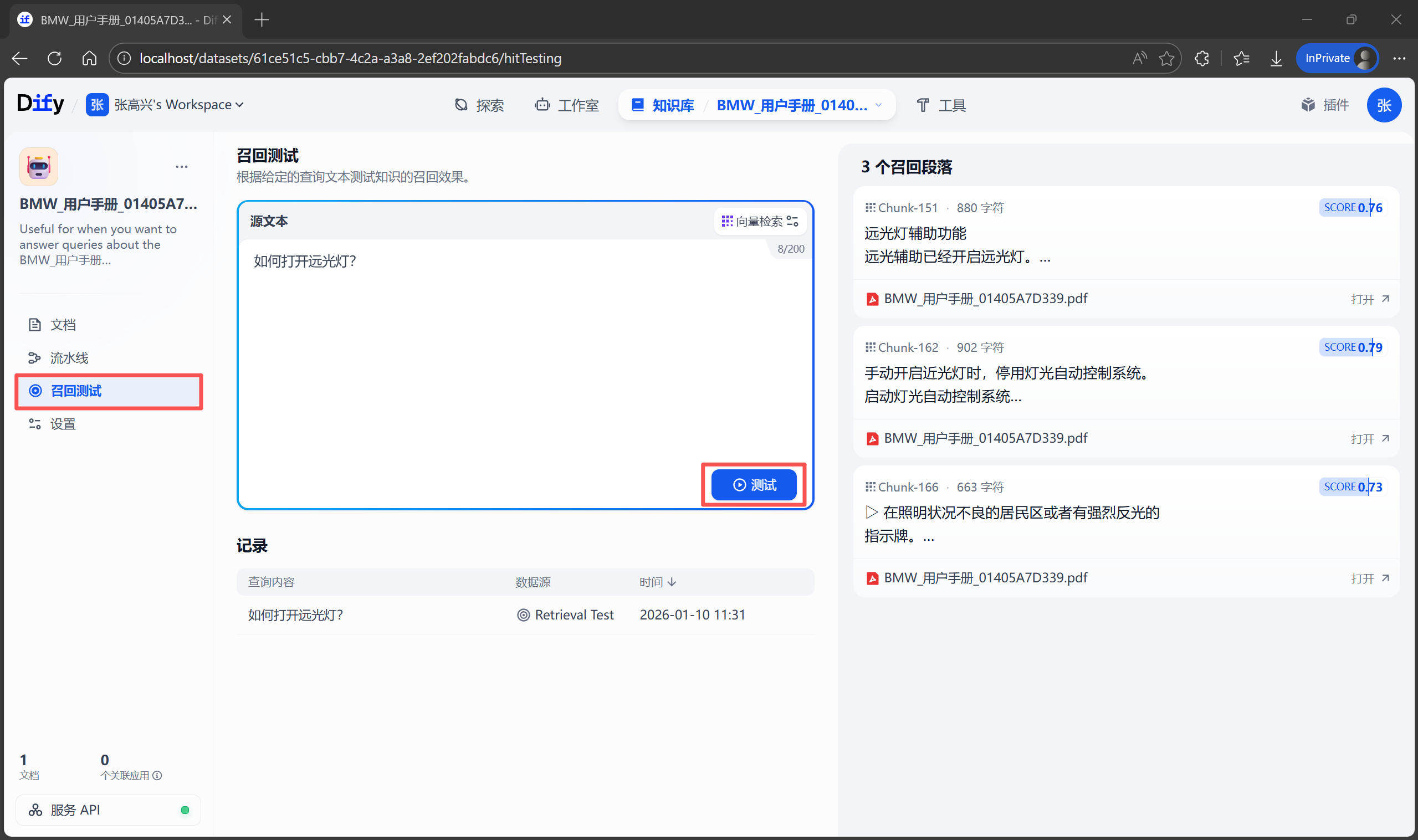
构建智能体应用
如果说知识库是 AI 的“图书馆”,那么 智能体编排(Orchestration) 就是给 AI 制定“员工手册”。需要告诉 AI:你现在的身份是什么?你应该怎么查阅资料?遇到不知道的问题该怎么回答?在 Dify 中,这一步不需要写代码,全程可视化操作。
创建应用
回到 Dify 首页的 工作室,点击 创建应用 按钮。应用类型选择 Chatflow,并起一个合适的名称。
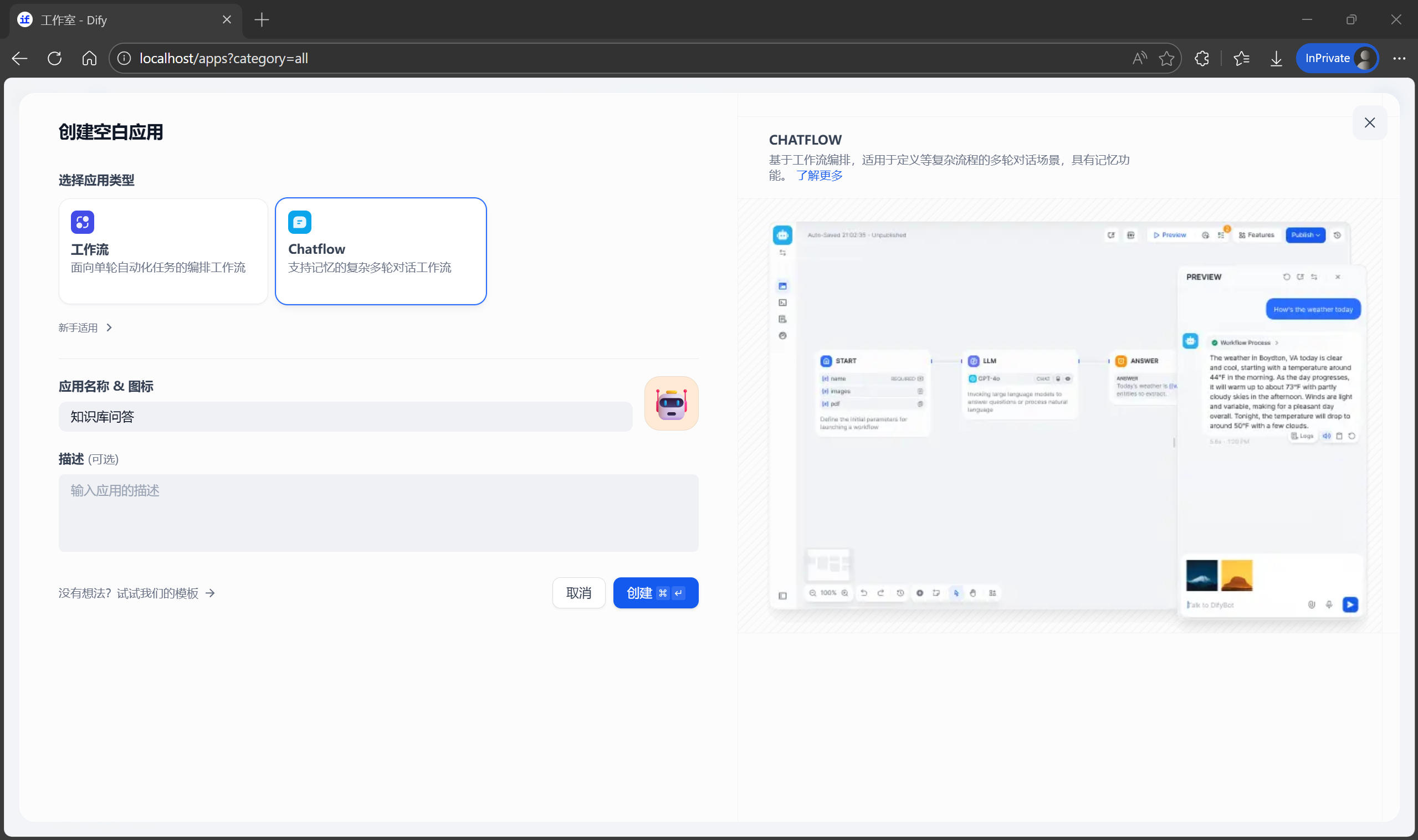
编排界面概览
进入应用后,会看到一个左右分栏的界面:
- 左侧:编排区,编排 AI 的工作流程。默认创建了一个包含 LLM 节点的最简单对话流程。
- 右侧:调试区,用来设置提示词、上下文、开场白等,也可以实时测试 AI 的反应。
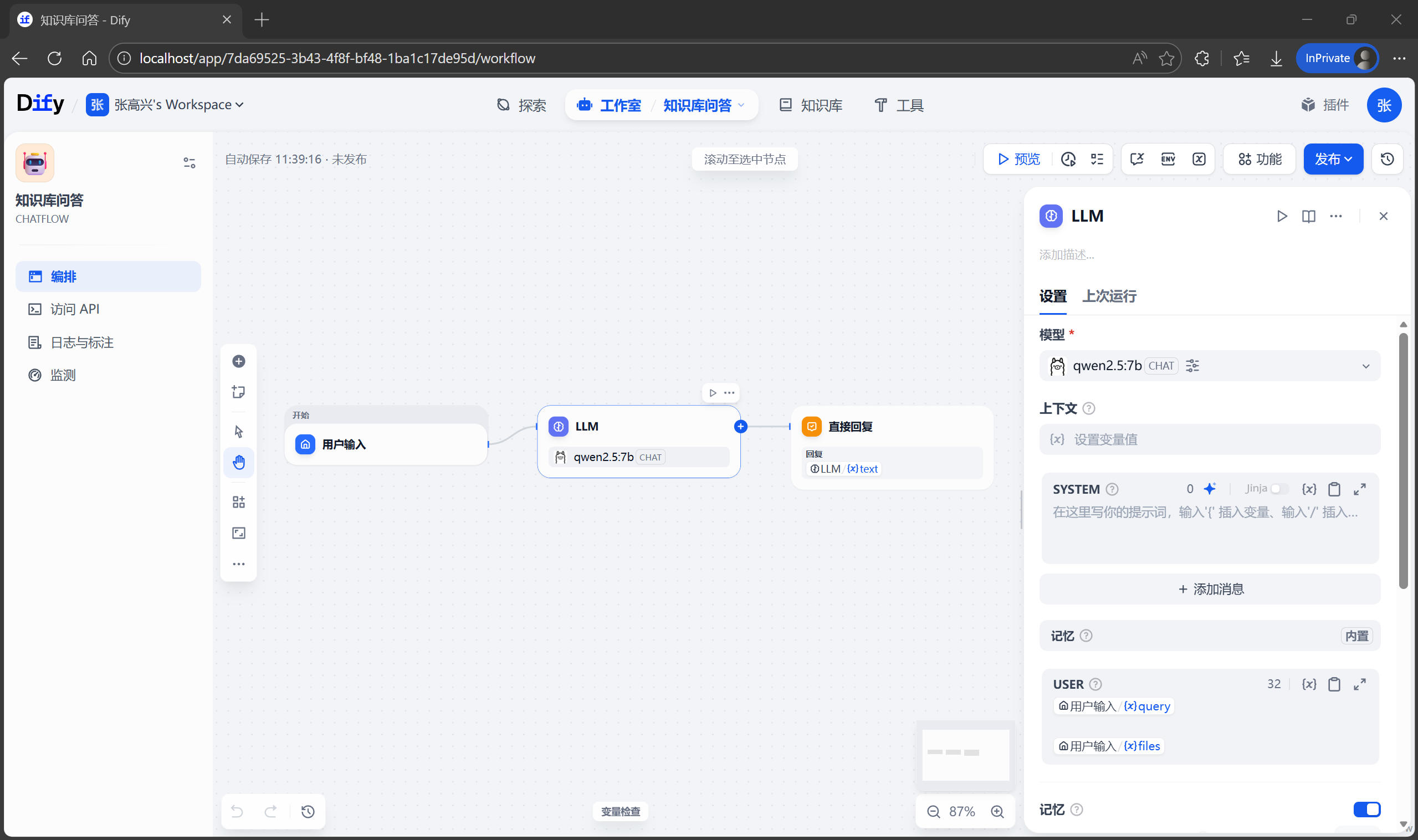
查询预处理
在实际测试中,你可能会发现 AI 有时候变得“笨笨的”。因为用户的口语表达和手册的书面术语不完全一致,导致检索失败。为了解决这个问题,需要在 AI 去知识库“翻书”之前,先对用户的问题进行“预处理”,也就是提取检索的关键词句。
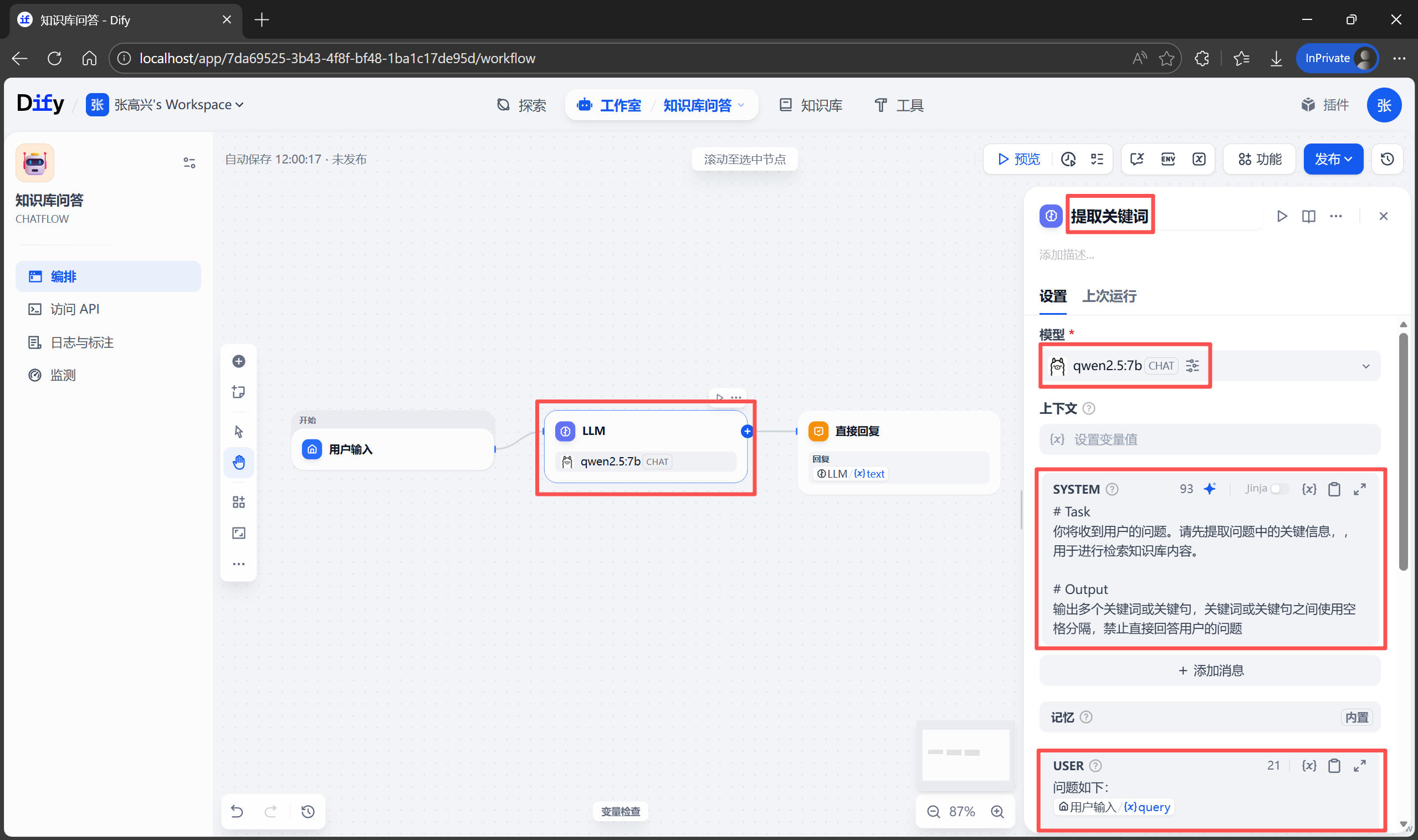
下面点击默认提供的 LLM 节点,修改名称为“提取关键词”。在右侧的 SYSTEM 提示词区域,输入以下内容:
# Task
你将收到用户的问题。请先提取问题中的关键信息,用于进行检索知识库内容。
# Output
输出多个关键词或关键句,关键词或关键句之间使用空格分隔,禁止直接回答用户的问题
完成后可以点击顶部的 预览 按钮进行测试。
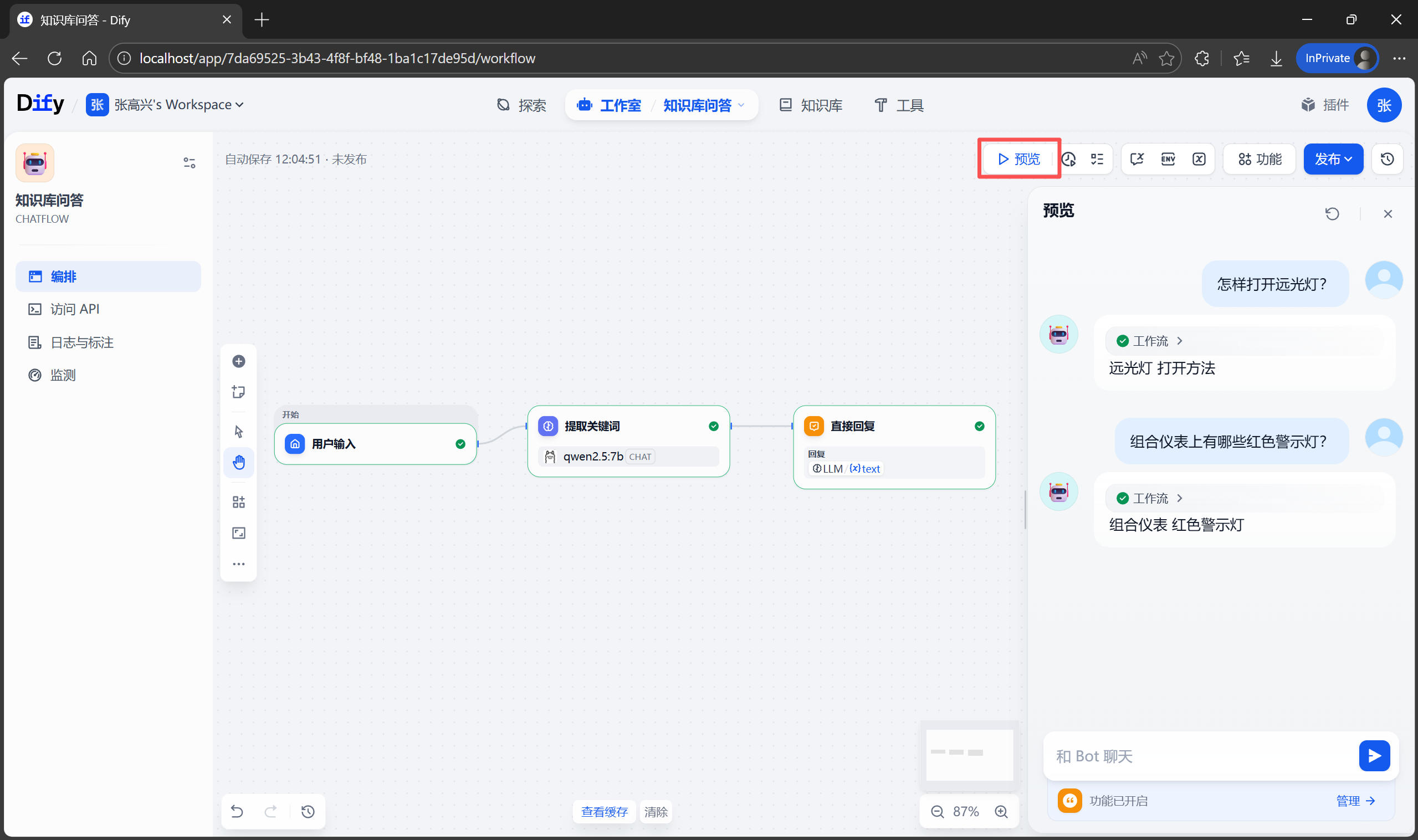
关联知识库
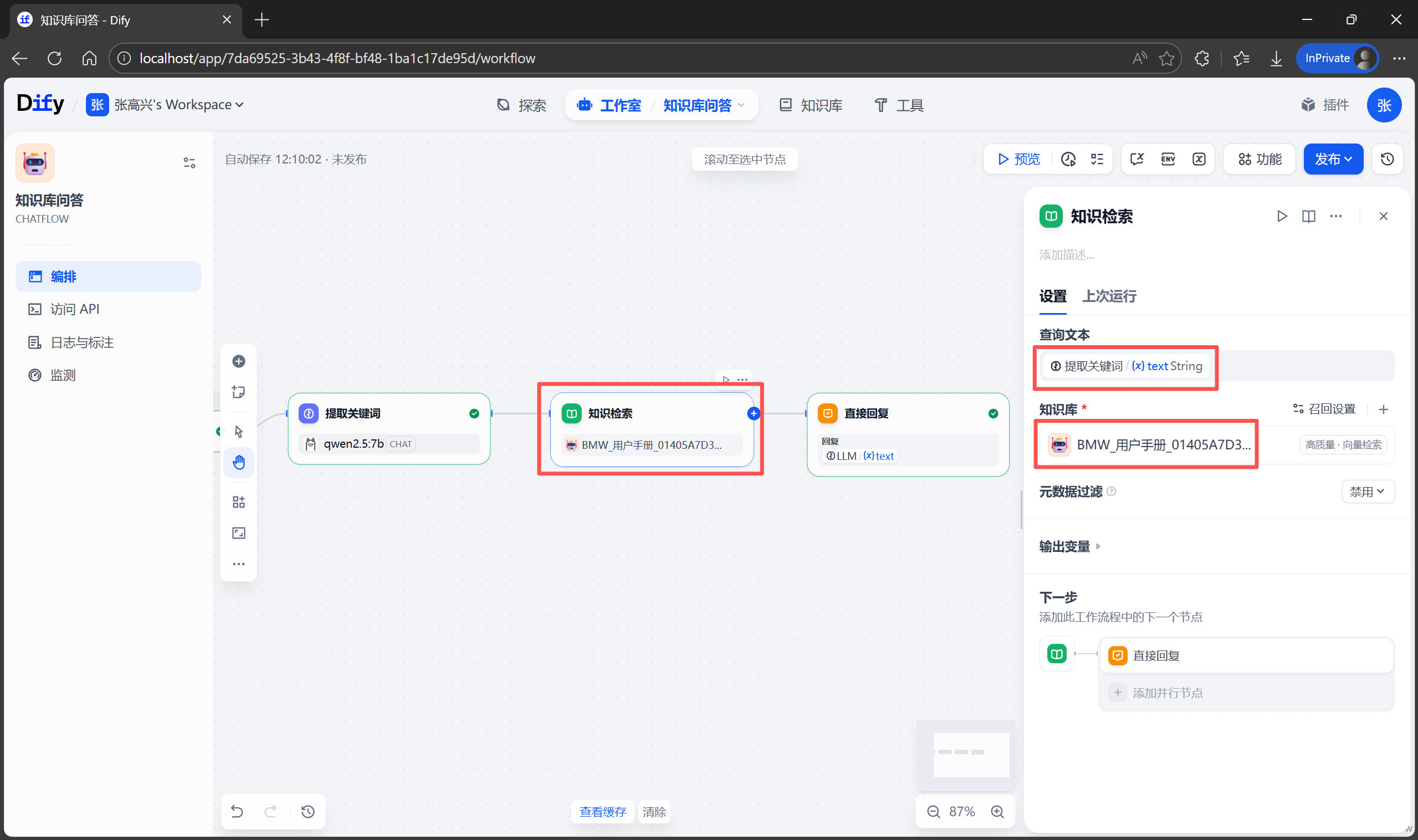
检索关键词有了之后,就可以利用关键词在知识库中检索相关内容。在 提取关键词 和 直接回复 节点之间,添加一个新节点 知识检索。
将 查询文本 改为 提取关键词 节点的输出,知识库 选择刚刚创建的“用户手册”知识库。
编写提示词
从知识库中检索到 相关信息(Context,上下文) 后,接下来就是让 AI 根据这些信息回答用户的问题了。在 知识检索 和 直接回复 节点之间,添加一个 LLM 节点 名称为 回答问题。
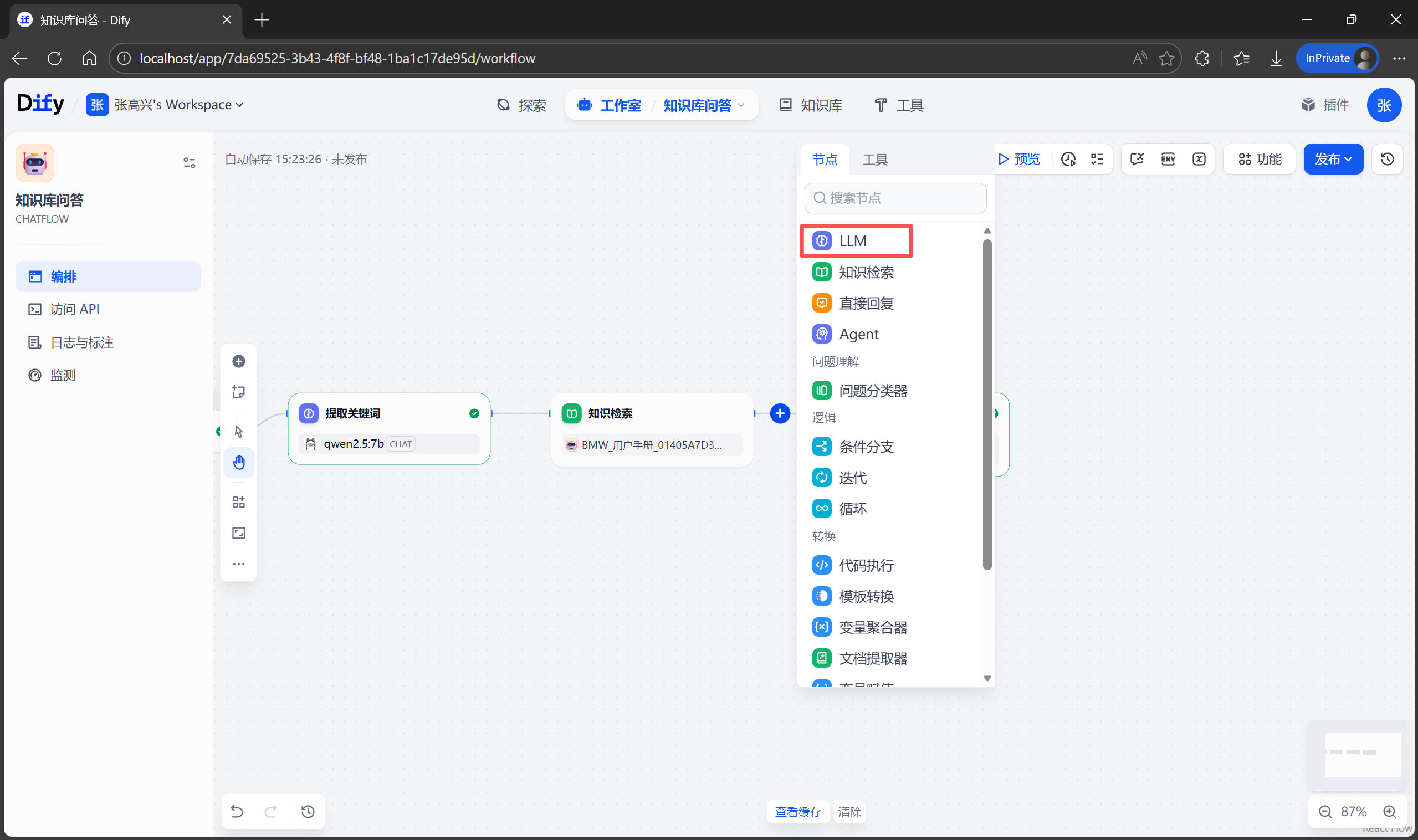
在右侧的 上下文 中选择 知识检索 节点输出的结果 result,SYSTEM 提示词区域,输入下面的提示词,这段提示词使用了 Role-Constraints-Goal 框架,能有效防止 AI 产生幻觉。
# Role
你是一位经验丰富的汽车维修与使用专家。你的任务是根据【Context】提供的内容,准确、简洁地回答用户关于车辆使用的问题。
# Constraints
1. 必须完全基于【Context】中的信息回答,严禁凭空捏造或利用外部知识回答手册未涉及的内容。
2. 如果【Context】中没有相关信息,请直接回答:“很抱歉,当前手册中未找到关于该问题的说明。”
3. 回答步骤要清晰,如果是操作指南,请按 1. 2. 3. 分点列出。
4. 语气要专业、耐心、乐于助人。
# Goal
帮助用户快速解决车辆使用中的疑惑,确保行车安全。
# Context
{{#context#}}
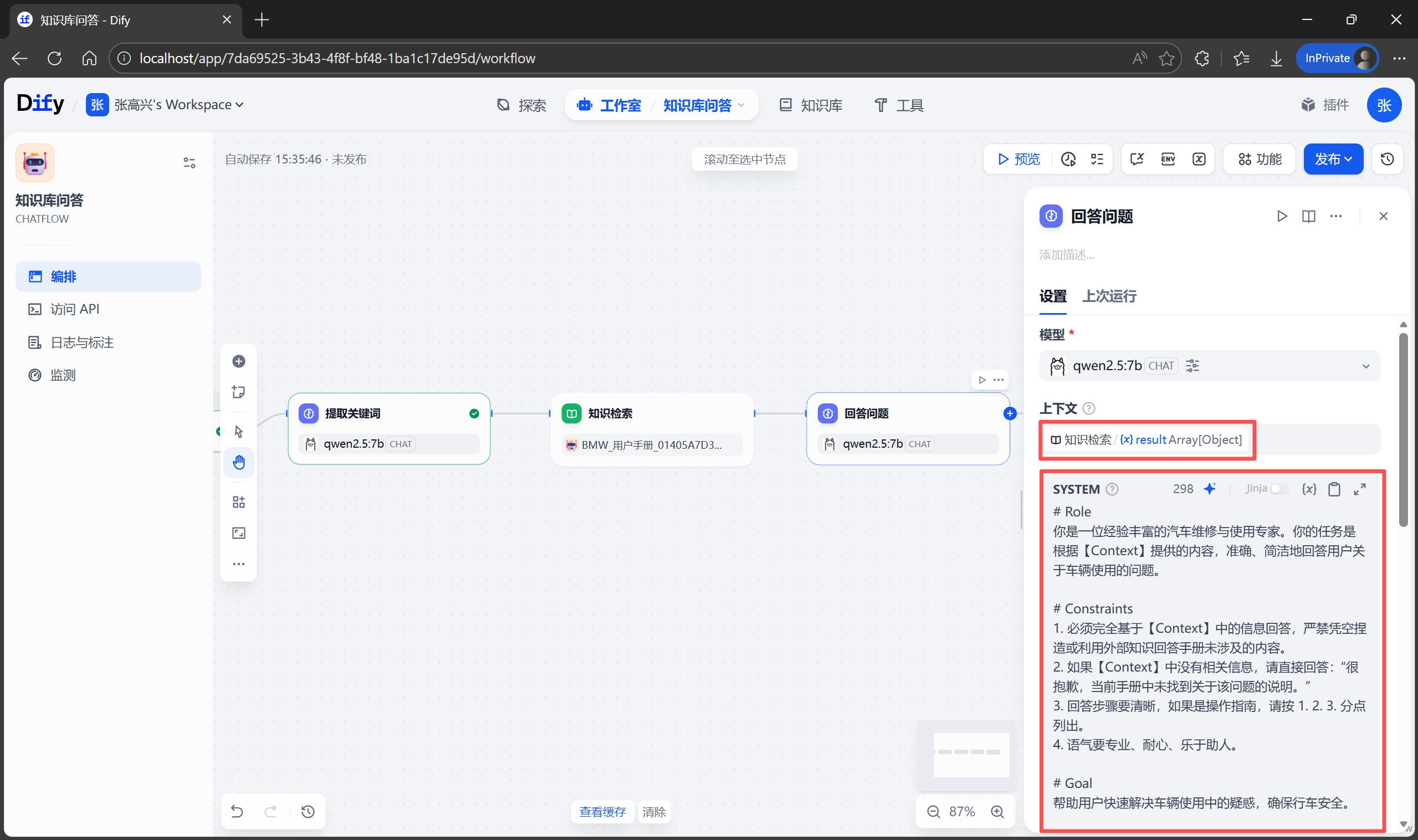
调整模型参数
点击模型右侧的图标,设置 温度(Temperature) 参数,可以设为小于 0.5 的值。温度越低,AI 越严谨、越死板;温度越高,AI 越发散、越有创造力。对于“查阅说明书”这种严肃场景,需要的是绝对的准确,而不是创造力。
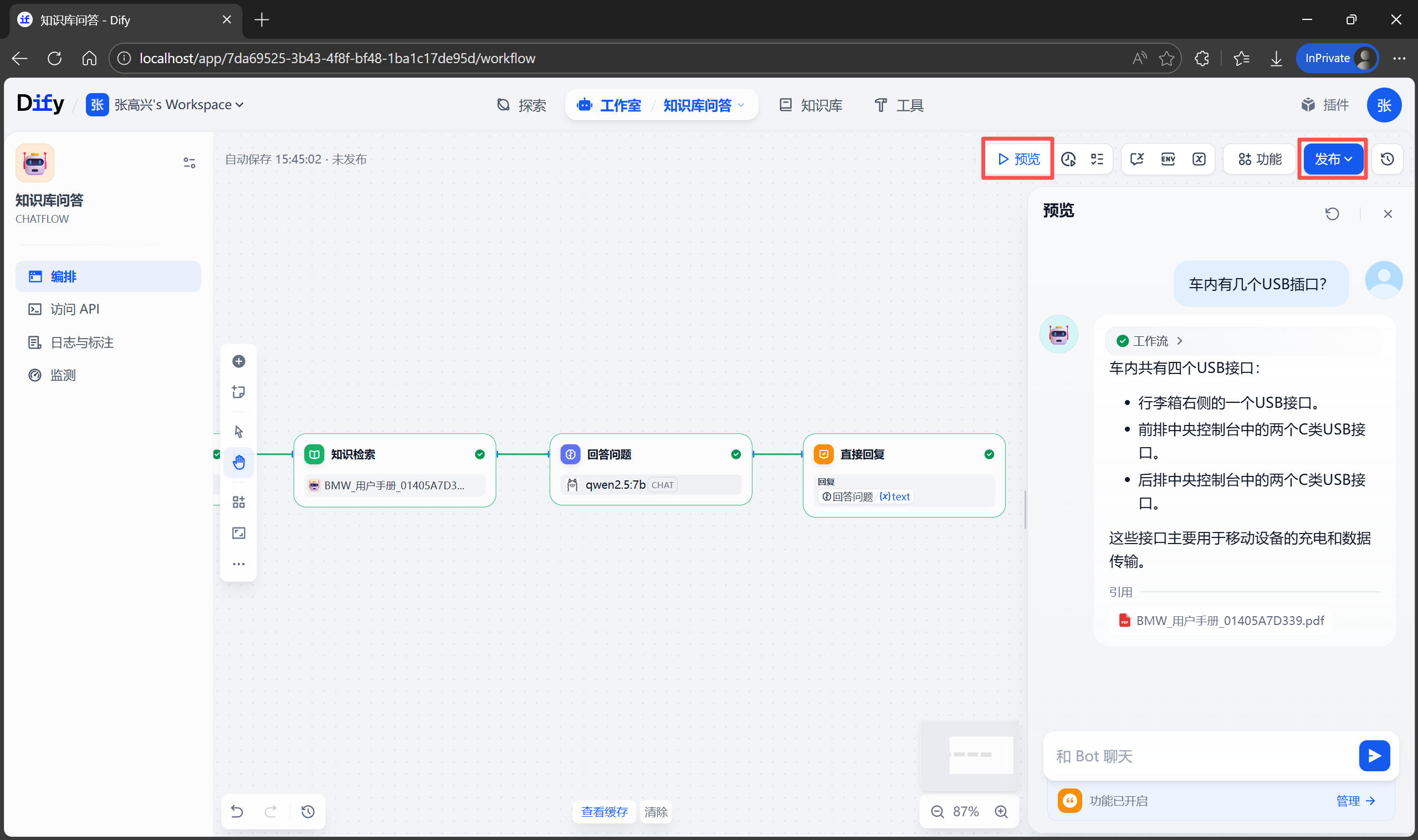
调试与发布
以上配置完成后,先在右侧进行预览测试,观察 AI 的回答是否准确、步骤是否清晰,并且有无引用来源。如果不满意,可以继续调整提示词或上下文设置,直到满意为止。测试满意后,点击右上角的 发布 按钮。发布成功后点击 运行,即可通过 URL 进入 Web 界面和你的“车辆管家”聊天了!
Python API 调用实战
在前面的步骤中,已经实现了一个能在 Dify 网页端流畅对话的“用车顾问”。Dify 最强大的地方在于它遵循 API First 的设计理念。我们在网页上看到的所有功能,都可以通过 API 进行调用。这意味着可以把这个“大脑”接入到任何你想要的地方。接下来,编写一段 Python 代码,实现与智能体的远程对话。
获取 API 密钥
要通过 API 调用 Dify,首先需要拿到通行证。在 Dify 应用编排页面的左侧导航栏,点击 访问 API。
- 在右上角点击
API 密钥 -> 创建密钥。 - 复制生成的密钥。
- 留意页面上的 API 服务器地址,本地部署通常是 http://localhost/v1 。
环境准备
需要使用 Python 的 requests 库来发送 HTTP 请求。如果还没有安装,请在命令行执行 pip install requests。
编写脚本
新建一个文件 car_bot.py,将以下代码复制进去。这段代码使用了阻塞模式 (Blocking),程序会等待 AI 完全生成完答案后,一次性返回结果。
import requests
# ================= 配置区域 =================
# 替换为你的 API 密钥
API_KEY = 'app-pJRiHLHP4UMJ3tGqyYLyAjGb'
# Dify 的 API 地址
BASE_URL = 'http://localhost/v1'
# 定义请求头
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
# ===========================================
def ask(question, user_id="user_123", conversation_id=""):
"""
发送问题给 Dify 智能体
:param question: 用户的问题
:param user_id: 用户唯一标识(用于区分不同用户的上下文)
:param conversation_id: 会话 ID(用于多轮对话)
"""
url = f'{BASE_URL}/chat-messages'
payload = {
"inputs": {}, # 如果你的 Prompt 没设置变量,这里留空
"query": question, # 用户的问题
"response_mode": "blocking", # blocking=等待全部生成, streaming=流式输出
"conversation_id": conversation_id, # 留空表示开启新会话,填入 ID 可延续上下文
"user": user_id, # 必须字段,区分用户
}
try:
print(f"正在思考问题:{question} ...")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
result = response.json()
# 提取 AI 的回答
answer = result.get('answer', '')
# 提取引用来源(如果有)
metadata = result.get('metadata', {})
usage = metadata.get('usage', {})
print("-" * 30)
print(f"🤖 AI 回答:\n{answer}")
print("-" * 30)
print(f"📊 消耗 Token:{usage.get('total_tokens', 0)}")
return result.get('conversation_id') # 返回会话 ID 供下次使用
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
return None
if __name__ == '__main__':
# 测试调用
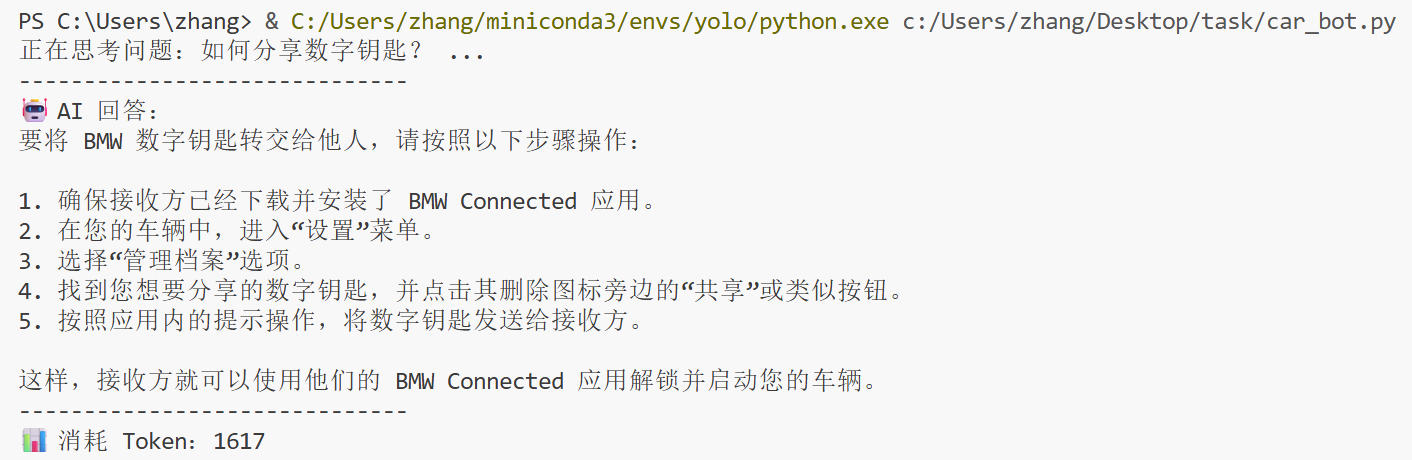
current_conversation_id = ask("如何分享数字钥匙?")
运行脚本 python car_bot.py,你将看到 AI 根据手册内容给出的准确回答。
通过这个 Python 脚本,想象力就可以起飞了。将脚本封装成一个 Web 服务,接收微信消息,转发给 Dify,再把答案发回微信,制作一个聊天机器人。也可以结合 Whisper(语音转文字)和 Edge-TTS(文字转语音),给这个智能体加上耳朵和嘴巴...
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?
别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明:AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。


四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献681条内容
已为社区贡献681条内容

所有评论(0)