【人工智能引论期末复习】第7章 强化学习1-MDP & Bellman
强化学习基本要素智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、策略(Policy)、奖励(Reward)强化学习的目标:最大化累计奖励马尔可夫性(Markov Property)定义:t+1时刻的状态只与t时刻的状态有关马尔可夫过程、马尔可夫链、马尔可夫决策过程的区别马尔可夫决策过程(MDP)定义:用于建模序贯决策问题,状态具有马尔可夫性策略函数π
一、核心概念与定义(填空、选择高频)
-
强化学习基本要素:
-
智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、策略(Policy)、奖励(Reward)
-
强化学习的目标:最大化累计奖励
-
-
马尔可夫性(Markov Property):
-
定义:t+1时刻的状态只与t时刻的状态有关
-
马尔可夫过程、马尔可夫链、马尔可夫决策过程的区别
-
-
马尔可夫决策过程(MDP):
-
定义:用于建模序贯决策问题,状态具有马尔可夫性
-
MDP五元组:(S,A,P,R,γ)
-
策略函数 π(a∣s) 的含义
-
-
贝尔曼方程(Bellman Equation):
-
又称动态规划方程
-
描述了状态价值函数 V(s) 和动作价值函数 Q(s,a) 的递推关系
-
时间相关性:价值函数与时间相关
-

三、典型模型与问题(问答、建模题)
-
多臂赌博机问题:
-
建模为简化MDP问题
-
目标:在有限次数内最大化累计奖励
-
涉及探索与利用的权衡
-
-
马尔可夫奖励过程(MRP):
-
MDP去除动作后的简化版本
-
用于理解奖励与状态转移的关系
-
-
轨迹(Trajectory)与片段(Episode):
-
例如围棋对局是一个片段
-
四、与“2025回忆卷”相关的考点提示
-
填空/选择可能涉及:
-
贝尔曼方程又称动态规划方程
-
价值函数与时间相关
-
MDP是序贯决策模型
-
马尔可夫性:无记忆性
-
-
计算题可能涉及:
-
给定MDP模型,计算 V(s) 或 Q(s,a)
-
多臂赌博机建模与策略选择
-
贝尔曼方程推导或验证
-
-
问答/论述可能涉及:
-
解释MDP在强化学习中的重要性
-
贝尔曼方程如何帮助求解最优策略
-
结合AlphaGo等案例说明MDP与RL的关系
-
五、建议复习策略
-
理解为主:重点理解马尔可夫性、MDP结构、贝尔曼方程的意义
-
公式推导:掌握贝尔曼方程的推导过程,能写出标准形式
-
联系实际:思考MDP在游戏、机器人控制等场景中的应用
-
结合题库:多练习类似“2025回忆卷”中的Q学习、价值函数计算题型
🧠 第7章 MDP & Bellman 模拟练习题
一、填空题(共10题,每空1分)
-
马尔可夫决策过程的五元组是:______。
-
在MDP中,智能体的目标是最大化______。
-
贝尔曼方程又称______方程,描述了价值函数的______关系。
-
马尔可夫性是指:t+1时刻的状态只与______时刻的状态有关。
-
在MDP中,策略函数 π(a∣s)表示在状态 s 下选择动作 a 的______。
-
如果折扣因子 γ=0,智能体只关心______奖励。
-
多臂赌博机问题是MDP的简化版,它没有______。
-
价值函数 V(s) 表示从状态 ss 出发,遵循策略 π 所能获得的______。
-
动作价值函数 Q(s,a) 表示在状态 s 下执行动作 a 后,再遵循策略 π 所能获得的______。
-
在贝尔曼最优方程中,我们寻找的是______策略。
二、选择题(共5题,每题2分)
-
以下哪个不是MDP的组成部分?
A. 状态
B. 动作
C. 奖励
D. 数据集 -
贝尔曼方程适用于:
A. 监督学习
B. 无监督学习
C. 强化学习
D. 所有机器学习任务 -
马尔可夫性假设是为了:
A. 增加计算复杂度
B. 简化问题建模
C. 引入更多历史信息
D. 减少奖励 -
如果 γ=0.9γ=0.9,则未来第10步的奖励对当前价值的贡献约为初始奖励的:
A. 90%
B. 35%
C. 10%
D. 几乎为0 -
在多臂赌博机问题中,智能体需要平衡:
A. 记忆与遗忘
B. 探索与利用
C. 状态与动作
D. 奖励与惩罚
三、计算与推导题(共3题)

2. 多臂赌博机建模(6分)
简述如何将“选择餐厅”问题建模为一个多臂赌博机问题,并说明:
-
状态是什么?
-
动作是什么?
-
奖励是什么?
-
目标是什么?
3. 简答题(8分)
为什么说“贝尔曼方程是强化学习求解的核心工具”?请结合MDP和动态规划的思想简要说明。
✅ 参考答案
一、填空题
-
状态集 SS、动作集 AA、转移概率 PP、奖励函数 RR、折扣因子 γγ
-
累计奖励(或回报)
-
动态规划、递推
-
t
-
概率
-
即时
-
状态转移(或状态)
-
期望累计奖励
-
期望累计奖励
-
最优
二、选择题
-
D
-
C
-
B
-
B(计算公式:0.910≈0.350.910≈0.35)
-
B
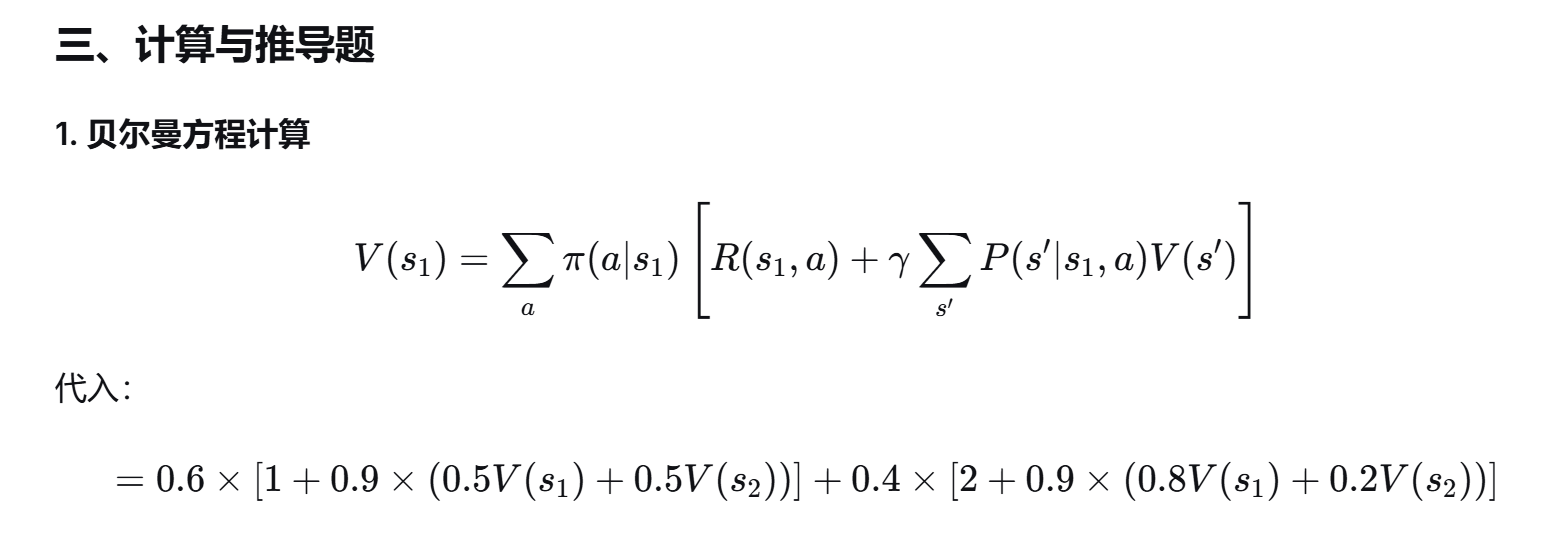
2. 多臂赌博机建模
-
状态:无状态(或仅“已尝试次数”)
-
动作:选择某一家餐厅
-
奖励:用餐满意度(如评分1~5)
-
目标:在有限次数内最大化总满意度
3. 简答题
贝尔曼方程将复杂的序列决策问题分解为“即时奖励 + 未来价值”的递归形式,符合动态规划的“最优子结构”思想。在MDP中,贝尔曼方程允许我们通过迭代更新价值函数,逐步逼近最优策略,是值迭代、策略迭代等强化学习算法的基础。它建立了状态、动作、奖励与价值之间的数学联系,是求解强化学习问题的核心工具。
🧮 题型一:Q学习单步更新计算
题目1(类似2025卷中Q学习题)
已知一个9宫格环境如下:
s1 s2 s3 s4 s5 s6 s7 s8 s9
-
智能体从 s1 出发。
-
可执行动作:上、下、左、右(不可越界)。
-
奖励规则:
-
进入 s9 奖励 +1,并终止。
-
进入 sd(死亡状态,假设为s5)奖励 -1,并终止。
-
其他状态奖励为 0。
-
-
折扣因子 γ=0.9。
-
学习率 α=0.5。
-
初始Q值:
-
对于所有非终止状态:Q(s,右)=0.2,Q(s,下)=0.3,Q(s,左)=0.1,Q(s,上)=0.1Q(s,右)=0.2,Q(s,下)=0.3,Q(s,左)=0.1,Q(s,上)=0.1
-
终止状态(s9, sd)所有动作Q值 = 0。
-
智能体执行以下两步:
-
从 s1 选择动作“右” → 进入 s2(奖励0)
-
从 s2 选择动作“下” → 进入 s5(sd,奖励-1,终止)
问题:
a) 哪一步的Q值会被更新?更新后的Q值是多少?
b) 写出Q学习更新公式并代入计算。
题目2(多步更新与策略影响)
环境同上,但:
-
s5 不再是终止状态,只是一个普通状态(奖励0)。
-
智能体从 s1 开始,执行策略:总是选择当前Q值最大的动作(若有多个则选第一个)。
-
初始Q值同上。
执行三步:
-
s1 → 右 → s2
-
s2 → 下 → s5
-
s5 → 右 → s6
假设s6是普通状态(奖励0)。
问题:
a) 分别计算三步后更新的Q值。
b) 三步后智能体会如何调整策略?
📊 题型二:贝尔曼方程与值迭代
题目3(值迭代计算)
已知一个简单MDP:
-
状态:{A, B},B为终止状态(奖励0)。
-
动作:{去B, 停留}
-
转移:
-
在A选择“去B”:100%到B,奖励 +5
-
在A选择“停留”:100%留在A,奖励 +1
-
-
折扣因子 γ=0.9。
-
初始值:V(A)=0,V(B)=0V
问题:
a) 执行一次值迭代(贝尔曼最优方程)更新 V(A)。
b) 最优策略是什么?
📈 历年类似考题分析与预测
常见考点总结(基于“2025回忆卷”及类似试卷):
| 考点 | 出现频率 | 题型 | 备注 |
|---|---|---|---|
| Q学习单步更新 | 高 | 计算题 | 常给一个网格环境,要求计算更新后的Q值 |
| 贝尔曼方程形式 | 中 | 填空/简答 | 要求写出状态价值函数或动作价值函数的贝尔曼方程 |
| 折扣因子计算 | 中 | 选择/计算 | 计算未来奖励的现值 |
| 探索与利用 | 高 | 填空/选择 | UCB、ε-greedy等策略 |
| 多臂赌博机 | 中 | 简答/建模 | 要求将实际问题建模为MAB |
| 值迭代 vs 策略迭代 | 低 | 选择/简答 | 理解区别与适用场景 |
预测可能的新题型(结合近年RL发展):
-
DQN相关:简述DQN如何结合Q学习和深度学习。
-
策略梯度简述:要求写出策略梯度定理的基本形式。
-
Actor-Critic框架:说明Actor和Critic各自的作用。
-
蒙特卡洛树搜索(MCTS)与AlphaGo:简述MCTS在AlphaGo中的应用。
✅ 参考答案(部分)



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)