DeepSeek革命性条件记忆架构详解:让大模型更高效调用知识的新维度!
DeepSeek与北京大学共同提出条件记忆(Conditional Memory)及Engram记忆检索架构,通过可学习的知识嵌入和检索机制,显著提升大模型在知识调用、推理、代码等任务表现。实验证明,Engram能增加模型有效深度,加速预测收敛,且对推理效率影响微小,为大模型优化提供了新思路。
DeepSeek 于 12 日晚发布新论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》(基于可扩展查找的条件记忆:大型语言模型稀疏性的新维度)。
https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
该论文为北京大学与 DeepSeek 共同完成,合著作者署名中出现梁文锋。
论文提出条件记忆(conditional memory),通过引入可扩展的查找记忆结构,在等参数、等算力条件下显著提升模型在知识调用、推理、代码、数学等任务上的表现。同时,DeepSeek 开源相关记忆模块 Engram。
那么这次 DeepSeek 提出「条件记忆」及 Engram 记忆检索架构有哪些亮点?
一、动机
当前的 LLM 需要依靠计算来模拟知识检索,这导致模型需要在早期层中消耗大量计算资源来重建静态知识,从而浪费了宝贵的模型深度和计算能力。
针对这个问题,论文提出了一种实时知识检索的方法,来减轻模型依靠计算来模拟知识检索产生的负担。
二、实现
a.整体方法介绍
论文在原有 transformer 架构上增加了一个 Engram 模块,其核心是可学习的知识嵌入,以及相应的知识检索和上下文融合机制。
给定当前序列,在预测下一个 token 前,使用当前序列的最后几个 gram 作为查询,这几个 gram 经过多个哈希头进行哈希计算之后,检索出对应的知识嵌入向量。这些被检索到的知识嵌入向量被动态地融合进上下文当中。
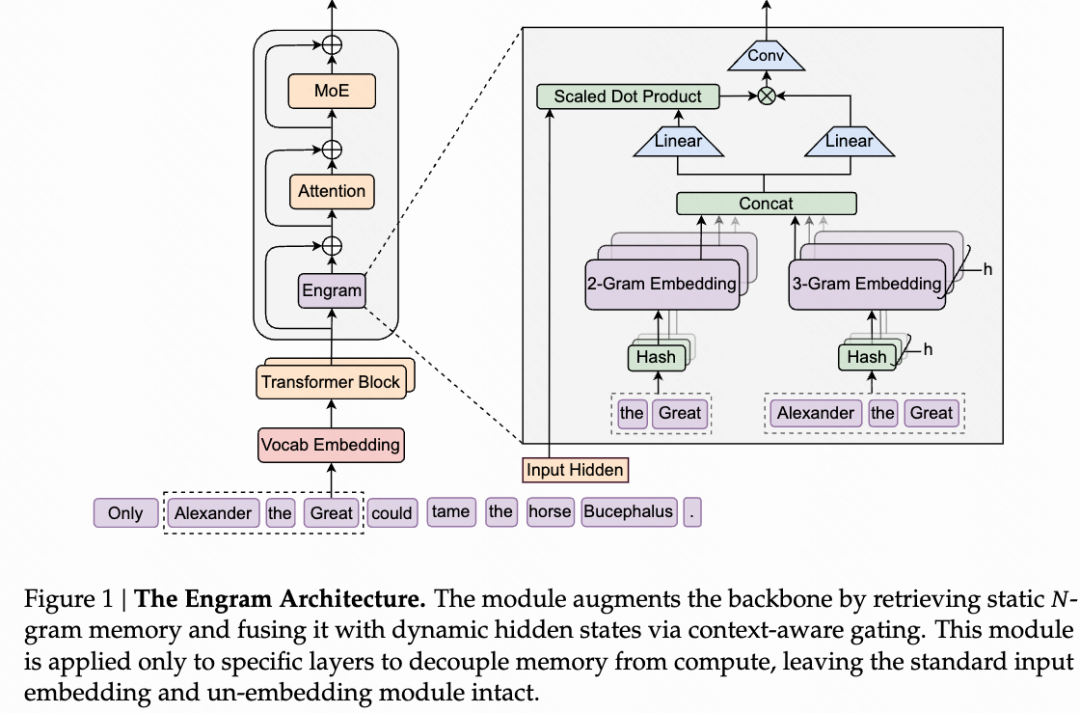

b.具体实现细节
-
给定上下文,例如“2019 年美国纽约市”
-
提取最后的 2-gram(当然,也可以是 3-gram),也就是"美国 纽约市”。将 N-gram 中的 token 映射到规范化的 ID。
-
使用 k 个 hash 函数,将"美国 纽约市”隐射为 k 个整数序号。
-
依据这 k 个整数序号,从 k 个知识嵌入向量表中检索得到 k 个知识嵌入向量。
-
将检索得到 k 个知识嵌入向量拼接为一个长向量。
-
使用门控方法调节知识向量的强度。

- 对知识向量进行卷积。

- 将知识向量加入上下文。

三、实验
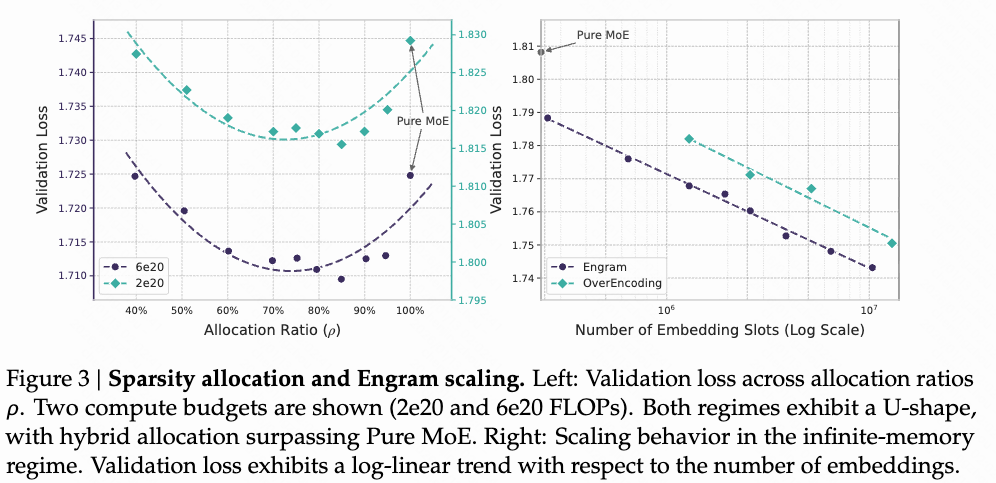
a.知识嵌入与模型主参数之间参数量的平衡
左图:当总参数量一定时,知识嵌入-主模型参数分配比例与验证损失的关系。
右图:模型主参数不变,扩增知识嵌入参数量,可以显著降低验证损失。(无痛scaling)
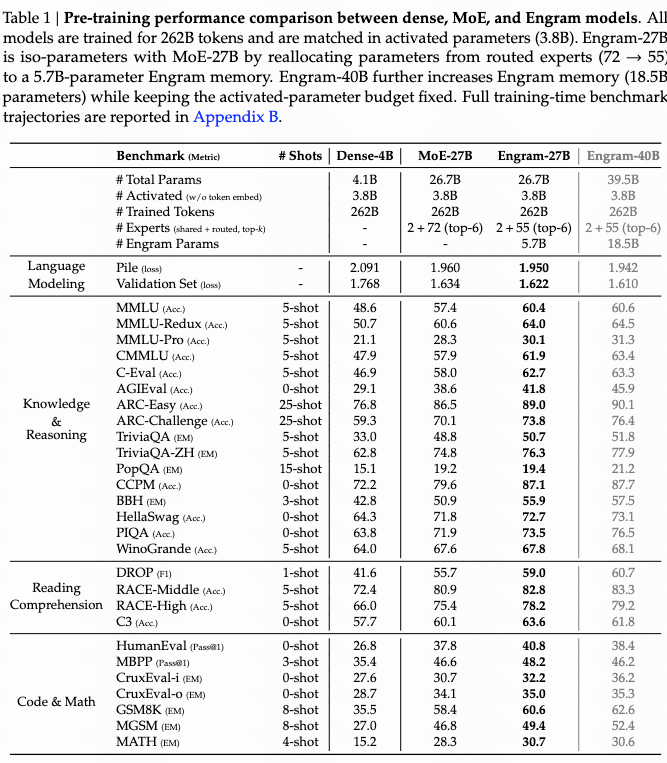
b.benchmark 测试结果
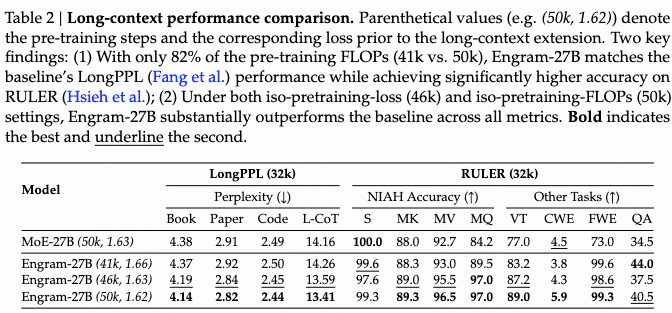
四、分析性实验
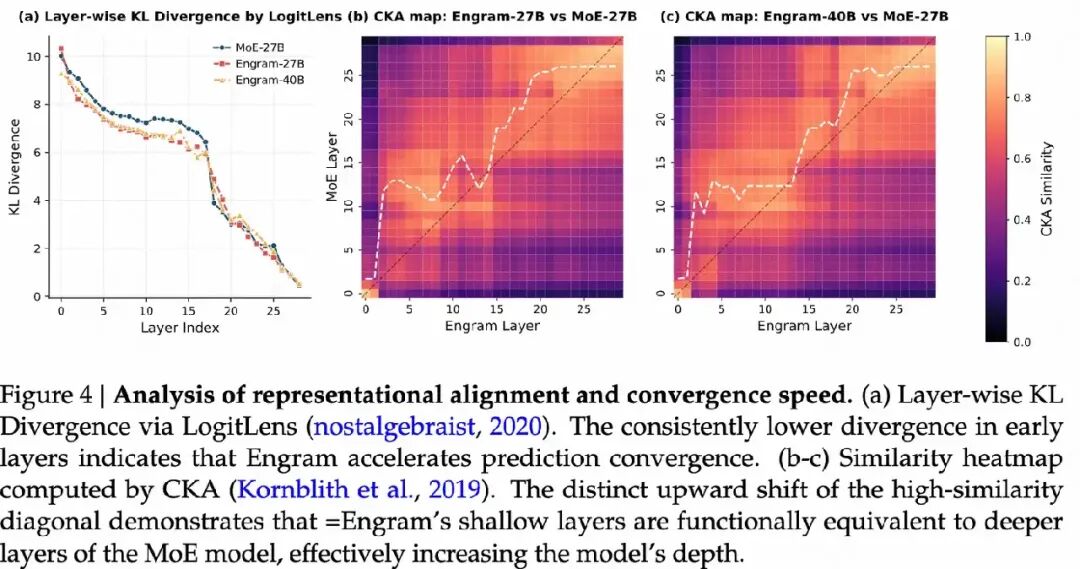
- Engram 是否增加了模型的有效深度?
加速预测收敛:
- 分析方法:使用 LogitLens 工具,通过计算每一层隐藏状态与最终输出分布之间的 Kullback-Leibler 散度(KL 散度),来衡量每一层的预测置信度。
- 结果:Engram 模型在早期层的 KL 散度显著低于 MoE 基线模型,表明 Engram 模型能够更快地完成特征组合,更早地达到高置信度的预测结果。
- 结论:Engram 通过显式的知识检索能力,减少了模型早期阶段的计算步骤,从而加速了预测收敛。
表示对齐与有效深度:
- 分析方法:使用 Centered Kernel Alignment(CKA)分析 Engram 模型与 MoE 模型各层之间的表示结构相似性。
- 结果:Engram 模型的早期层(如第 5 层)的表示与 MoE 模型的深层(如第 12 层)表示高度相似,呈现出明显的“向上偏移”。
- 结论:Engram 通过显式的知识检索,跳过了早期的静态特征组合任务,使得模型在更浅的层次上就能达到与 MoE 模型深层相似的表示,从而有效地增加了模型的有效深度。
- 结构消融与层敏感性
内存注入的最佳位置:
- 实验设计:在 3B MoE 模型中插入 Engram 模块,固定参数预算(1.6B),改变 Engram 的插入位置(从第 1 层到第 12 层)。
- 结果:Engram 在第 2 层插入时表现最佳(验证损失最低)。将 Engram 分成两个模块分别插入第 2 层和第 6 层时,性能进一步提升。
- 结论:早期注入 Engram 可以更有效地卸载静态模式的重建任务,但过早注入会导致上下文信息不足,影响门控机制的精度。因此,最佳位置需要在早期干预和上下文信息之间进行权衡。
关键组件的重要性:
- 实验设计:在参考配置基础上,逐个移除 Engram 的关键组件(如多分支融合、上下文感知门控、分词器压缩等)。
- 结果:移除这些组件会导致显著的性能下降,表明这些组件对 Engram 的有效性至关重要。
- 结论:多分支融合、上下文感知门控和分词器压缩是 Engram 模型的关键设计,它们共同提升了模型的性能。
敏感性分析:
- 实验设计:在推理过程中完全抑制 Engram 模块的输出,观察模型在不同任务上的表现。
- 结果:在事实知识任务中,性能大幅下降(如 TriviaQA 只保留 29% 的性能),而在阅读理解任务中,性能几乎不受影响(如 C3 保留了 93% 的性能)。
- 结论:Engram 主要负责存储和检索事实知识,而阅读理解任务更多依赖于模型的注意力机制和上下文理解能力。
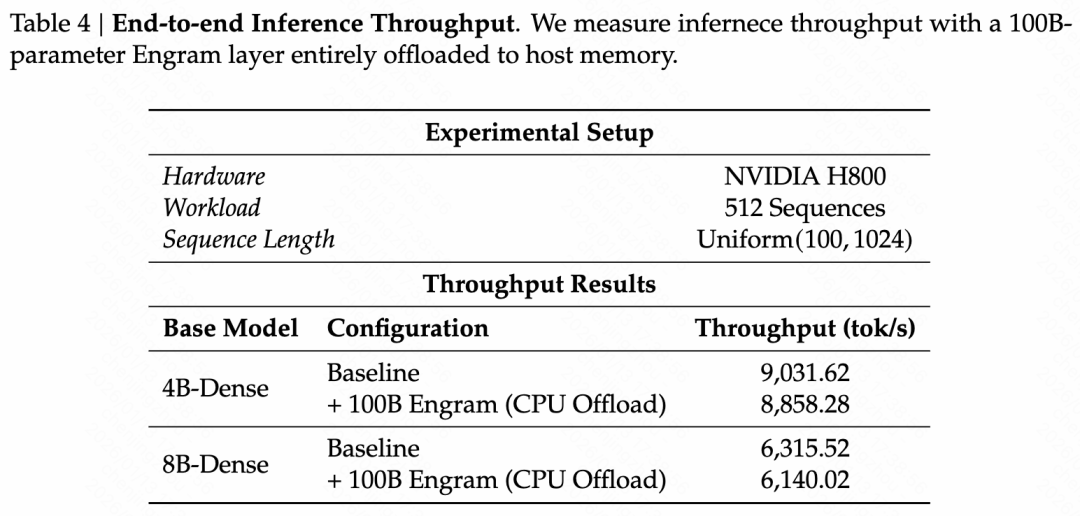
系统效率:
- 实验设计:将一个 100B 参数的 Engram 层完全卸载到主机内存,在推理过程中异步预取嵌入向量,观察对吞吐量的影响。
- 结果:在 4B 和 8B 模型中,吞吐量下降分别仅为 2% 和 2.8%,表明 Engram 的内存访问对推理效率的影响微乎其微。
- 结论:Engram 的确定性寻址机制允许在推理过程中高效地预取和传输嵌入向量,即使将大量参数存储在主机内存中,也不会显著影响推理速度。
案例研究:门控可视化
- 分析方法:可视化 Engram 模型在不同样本上的门控标量(α),观察其对静态模式的激活情况。
- 结果:Engram 在识别多词实体(如“Alexander the Great”)和固定短语(如“By the way”)时表现出强烈的激活,表明其成功地识别并检索了这些静态模式。
- 结论:Engram 的上下文感知门控机制能够动态地调节检索到的静态知识与动态特征的融合,有效减轻了 Transformer 主干网络的负担。

最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 40
40 0
0- 0



 已为社区贡献520条内容
已为社区贡献520条内容

所有评论(0)