DeepSeek 新论文 mHC:流形约束超连接——到底是什么?
摘要:DeepSeek提出流形约束超连接(mHC)解决大模型训练稳定性问题。传统残差连接在超大模型中成为带宽瓶颈,而超连接(HC)方案虽提升性能却破坏了恒等映射特性。mHC创新性地将HC连接空间投影到伯克霍夫多面体流形上,通过双随机矩阵确保信号稳定传输,同时结合TileLang等系统优化,仅增加6.7%训练时间就实现了4倍残差路径拓宽。该方案在数学推理等任务上表现优异,为万亿参数模型提供了可行的架
如果你现在走在一家世界级顶尖公司的办公大楼里,发现几千名员工每天上下班、传达指令、交换文件,竟然全都必须挤在同一部电梯里,你会不会觉得这公司的效率迟早要完?
没错,现在的 AI 大模型(LLM)正面临这样一个尴尬的局面。

过去十年,深度学习界有一个公认的“保命神技”——残差连接(Residual Connection)。它的存在就像是给神经网络修了一部直达电梯,让梯度信号能顺畅地在几十层甚至上百层楼之间穿梭。如果没有它,模型层数一深,训练就会像断了线的风筝,彻底崩溃。
但问题来了:随着我们把模型做得越来越大、越来越宽,这原本救命的“单部电梯”,现在成了整个架构最大的带宽瓶颈。

“高速公路”的崩塌与疯狂
为了解决这个问题,科学家们想:既然一部电梯不够用,那多修几部不行吗?
于是诞生了超连接(Hyper-Connections, HC)的概念。它不再只有一条路,而是让信息在多条平行的流中穿梭、交换。理论上,这应该让模型的脑回路变得极其宽阔。
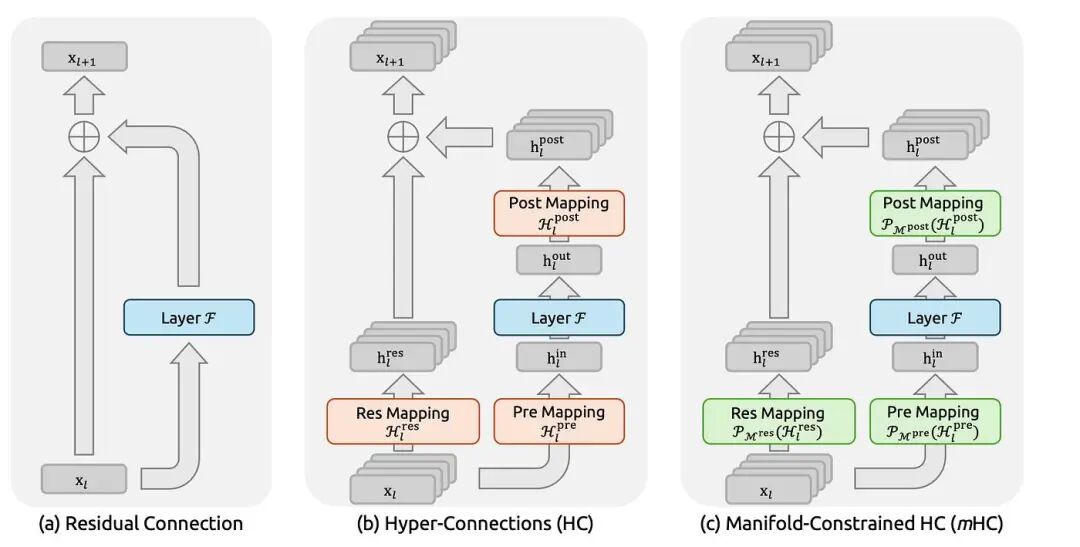
以超连接(Hyper-Connections,HC)为代表的研究通过扩展残差流宽度和多样化连接模式,扩展了过去十年广泛应用的残差连接范式。虽然这种多样化带来了显著的性能提升,但它从根本上损害了残差连接固有的恒等映射特性,导致严重的训练不稳定和可扩展性受限,并增加了显著的内存访问开销。
从理论上讲,HC看起来很理想:
-
更高的信息带宽
-
FLOP 增幅极小
-
更好的跨层特征混合
但实际上,HC 并不稳定。

核心故障模式
标准残差连接依赖于恒等映射。超连接则用可学习的混合矩阵取代了恒等映射。
随着深度增加:
-
小的放大误差累积
-
信号规范要么爆炸式增长,要么彻底消失。
-
训练变得数值不变
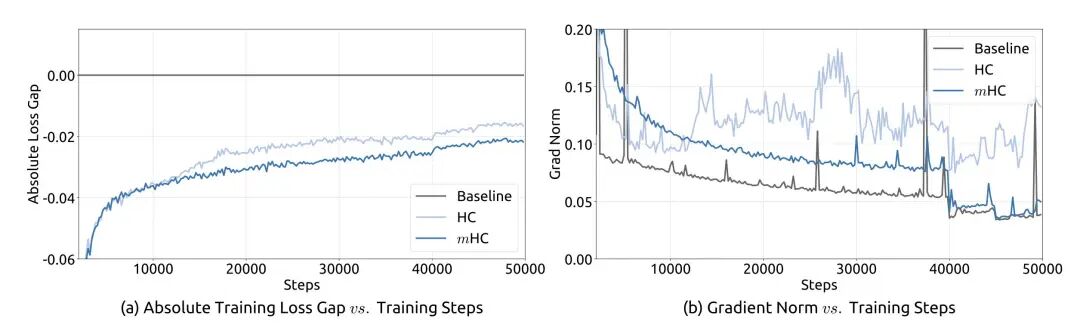
在实际训练中,这些额外的路径就像是失去了红绿灯的十字路口。DeepSeek 的研究员发现,在一个 270 亿参数(27B)的大模型里,如果没有约束,这些信号会像滚雪球一样疯狂叠加,最后信号增益竟然暴涨了 3000 多倍!
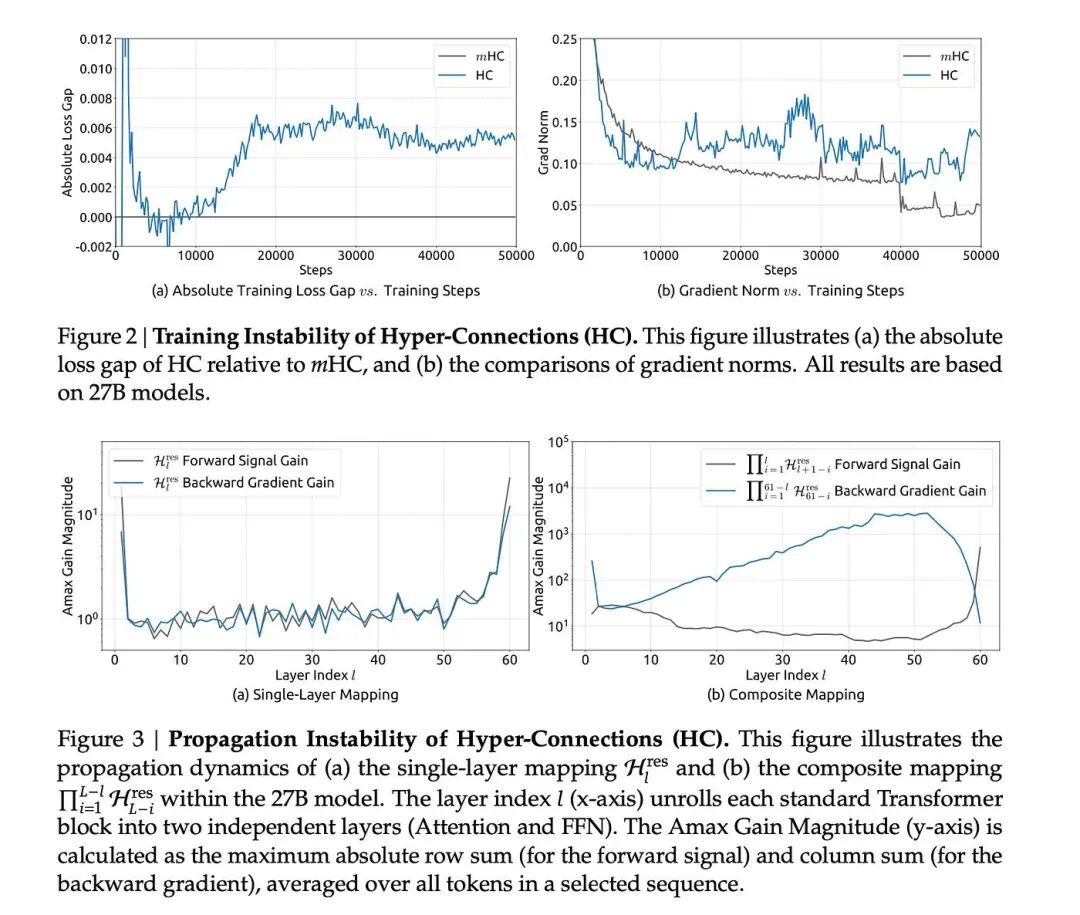
结果就是:模型“脑充血”了,训练直接炸裂。
DeepSeek 的“紧箍咒”:mHC 登场
通俗点说,既然之前的路乱套了,我们就给这些流量加上一套“能量守恒定律”。
为了应对这些挑战,DeepSeek提出了流形约束超连接(Manifold-Constrained Hyper-Connections,mHC)。mHC是一个通用框架,它将HC的残差连接空间投影到特定的流形上,从而恢复恒等映射特性,同时结合严格的基础设施优化来确保效率。
想象一下,mHC 就像是一个极其公平的“资源置换中心”。在每一个交叉路口,它强制执行两项铁律:
- 进出平衡
:从任何一条路流进来的信息量,经过交换后,流出去的总量必须保持一致。
- 雨露均沾
:每条路径既要有贡献,也要有收获,不能让某一条路独霸所有资源,也不能让某条路彻底干涸。
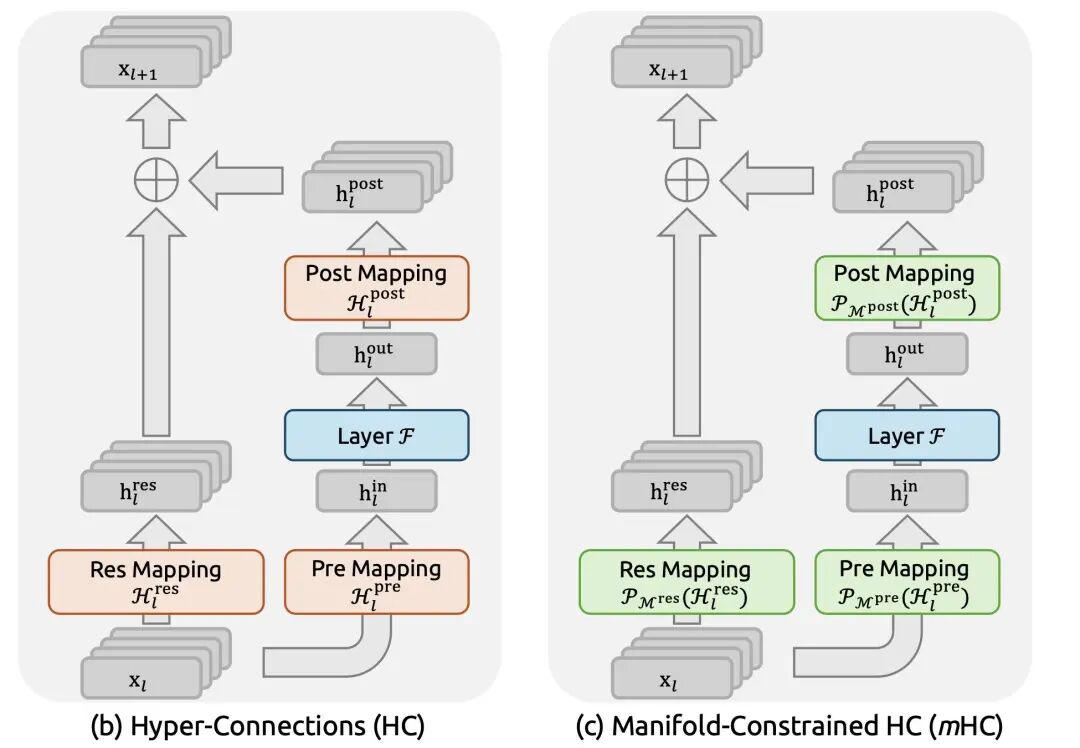
在数学上,这被称为“双随机矩阵”和“伯克霍夫多面体”。听起来很高深,但道理很简单:它既保留了多条路径的宽带宽,又让每一条路都像原来那部“稳定电梯”一样听话。mHC 不是随意混合矩阵,而是强制它们存在于一个被称为伯克霍夫多面体的数学流形上。
mHC 的创新之处在于它没有放弃多流连接,而是利用数学工具为这些连接加上了“紧箍咒”。
- 双随机矩阵(Doubly Stochastic Matrices)
:mHC 强制混合矩阵每一行和每一列的和都等于 1,且元素非负。
- 伯克霍夫多面体(Birkhoff Polytope)
:这些矩阵构成的几何空间被称为伯克霍夫多面体。从几何上看,它是所有置换矩阵(Permutation Matrices)的凸包。
- 稳定性保障
:双随机矩阵具有一个优异的特性——其谱范数(Spectral Norm)不大于 1。这意味着无论经过多少层,信号既不会爆炸也不会坍缩,完美恢复了残差连接的稳定性。
DeepSeek 使用 Sinkhorn-Knopp 算法(一种通过不断交替进行行归一化和列归一化来逼近双随机矩阵的迭代方法)在每次前向传播中强制执行这一约束。
为什么流形约束可以解决稳定性问题
1. 规范保存保障
双随机矩阵能够保持信号幅度不变。无论模型深度如何,残差流既不会爆炸也不会坍缩。这既恢复了身份残差的关键优势,又允许更丰富的混合。
2. 受控信息交换
mHC 仍然允许数据流之间进行交互,但它强制这种交互保持平衡。每个流都有贡献,每个流都有收获,没有哪个流占主导地位。这使得残差路径成为稳定的特征融合层,而不是数值风险。
3. 与深度无关的稳定性
与标准HC不同,其稳定性不会随深度增加而降低。这对于下一代LLM扩展至关重要。
使mHC速度足够快,以进行真正的训练
拓宽残差流会增加内存流量。如果没有系统级优化,这将无法使用。DeepSeek 直接解决了这个问题。使用 TileLang 进行内核融合多个操作被融合到单个GPU内核中。这最大限度地减少了内存I/O,避免了内存瓶颈。
选择性重计算:前向传播过程中会丢弃一些激活值。为了节省内存,反向传播过程中会重新计算这些激活值。
双管重叠:通信和计算是重叠进行的。数据传输发生在GPU仍在进行计算的同时。
不只是理论,更是“基建狂魔”的胜利
你可能会问:“路修宽了 4 倍,那训练速度岂不是要慢死?”
这就是 DeepSeek 厉害的地方。他们不仅是数学家,更是顶级的“包工头”。为了不让这些复杂的交通规则拖慢速度,他们开发了一套叫 TileLang 的黑科技。
这就好比是在修路的同时,发明了一种全自动铺路机。他们把各种复杂的计算步骤融合在了一起,减少了数据的搬运次数。结果令人震惊:残差路径拓宽了 4 倍,但整体训练时间只增加了微乎其微的 6.7%!
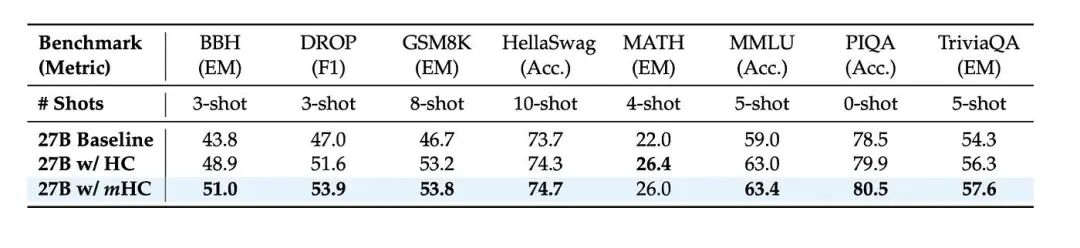
这不仅仅是小修小补
结果证明,这套方案在 GSM8K(数学推理)和 MMLU(综合知识)等各大考试中,表现全面超越了传统的大模型架构。
这意味着什么?这意味着我们终于找到了在大规模扩展模型时,如何让信息流得更稳、更宽的方法。
目前的 LLM 架构就像是已经触碰到了某种天花板,而 DeepSeek 的 mHC 就像是直接在天花板上开了一个洞。这不仅仅是技术上的优化,更是对未来万亿级参数模型如何构建的一张进化蓝图。
当信息不再拥挤在窄窄的独木桥上,大模型的潜力究竟还能被推向何方?这篇论文留下的悬念,或许就是下一代 AI 革命的开端。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)