从零开始学Linux进程控制:fork、wait、exec 详解
代码语言:javascriptAI代码解释。
2:创建子进程会经过以下步骤.
- 分配新的内存块和内核数据结构给子进程.
- 将父进程部分数据结构内容拷贝给子进程(子进程要继承于父进程).
- 添加子进程到系统的进程列表中
- 代码:子进程与父进程共享代码
- 数据:则通过写时拷贝的方式
如果理解进程具有独立性
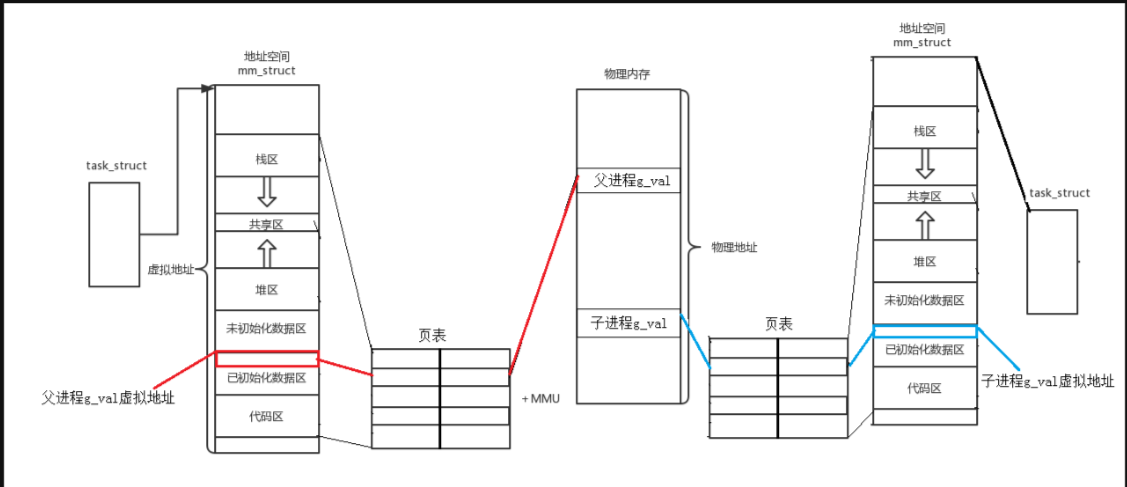
- 根本原因在于:进程 = 内核的相关管理数据结构(task_struct + mm_struct(地址空间) + 页表) + 代码 + 数据.子进程有自己的task_struct + mm_struct(地址空间) + 页表.
- 代码虽然与父进程共享,但是与父进程之间互不影响.
- 而数据是通过写时拷贝的方式进行复用.
- 因此无论从内核的相关管理数据结构还是从代码以及数据,它都是独立的.
1.1:fork函数初识
- 在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程.
进程调用fork,当控制转移到内核中的fork代码后,内核会做:
- 分配新的内存块和内核数据结构给子进程.
- 将父进程部分数据结构内容拷贝至子进程.
- 添加子进程到系统进程列表中.
- fork返回,开始调度器调度.
代码语言:javascript
AI代码解释
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
int main()
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if((pid = fork()) == -1)
{
perror("fork() fail");
exit(-1);
}
printf("After:pid is %d, fork return %d\n", getpid(), pid);
return 0;
}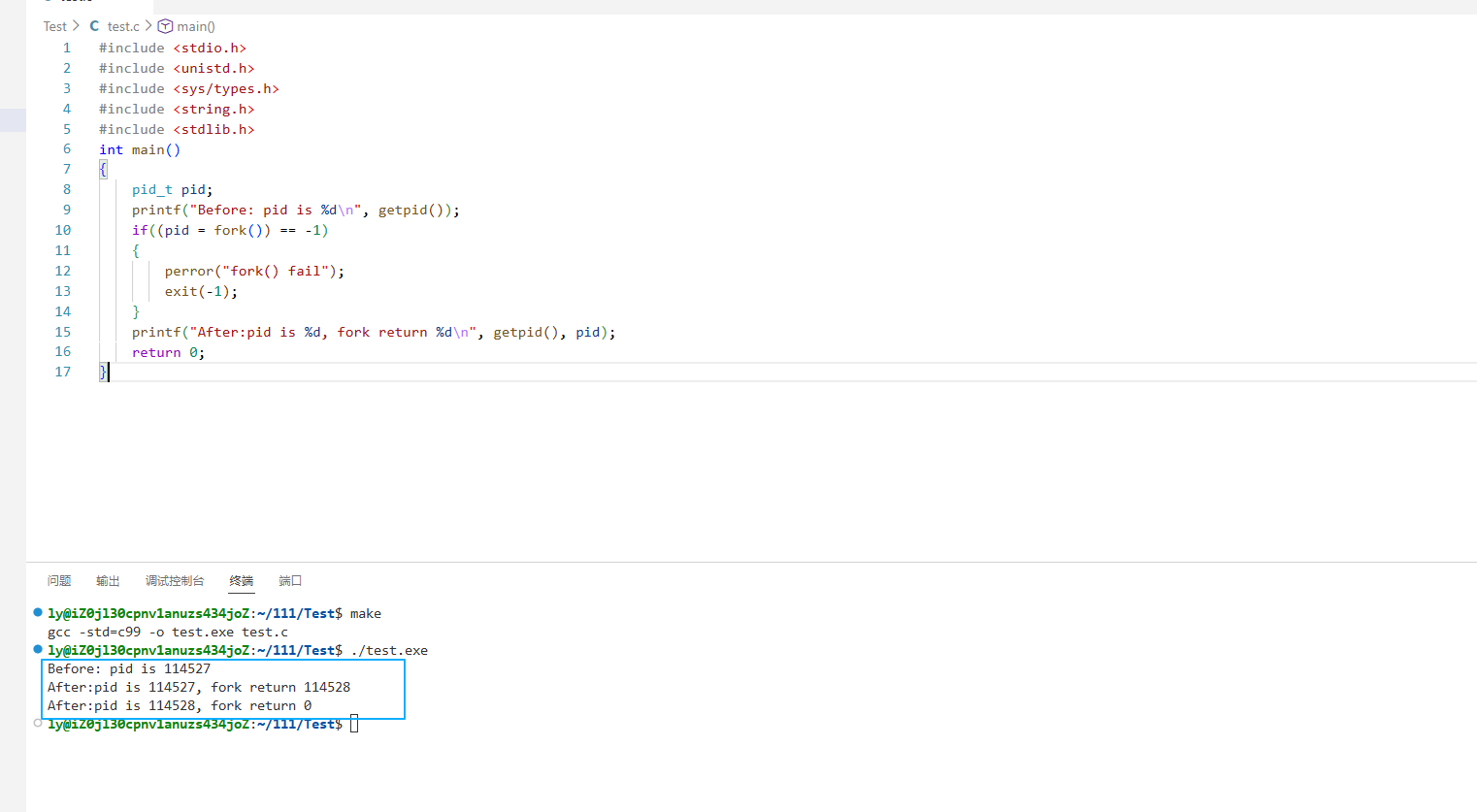
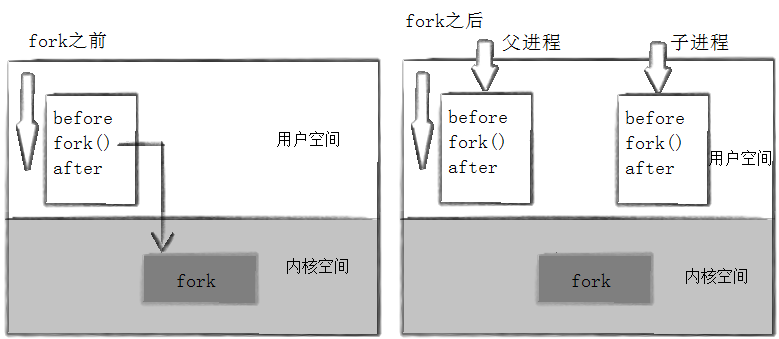
这里看到了三行输出,一行 before ,两行 after 。进程114527 先打印 before 消息,然后它有打印 after 。另一个 after消息有114528 打印的。注意到进程114528 没有打印 before,为什么呢?如下图所示.
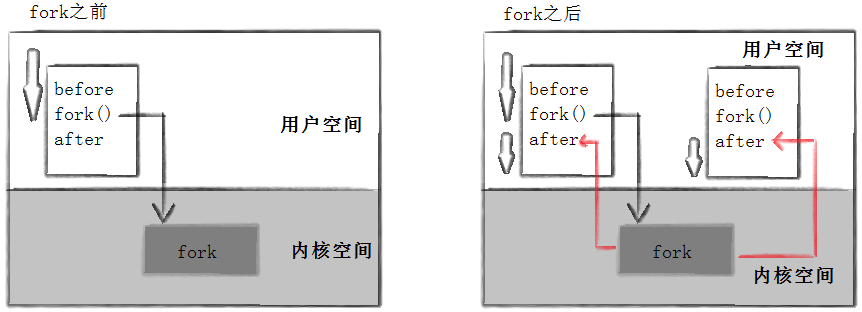
- fork之前父进程独立执行,而fork之后父子两个执行流分别执行.
PS:fork之后,父进程和子进程谁先执行完全由调度器决定.
1.2:fork函数返回值
fork函数为什么要给子进程返回0,给父进程返回子进程的PID?
一个父进程可以创建多个子进程,而一个子进程只能有一个父进程.因此,对于子进程来说,父进程是不需要被标识的;而对于父进程来说,子进程是需要被标识的,因为父进程创建子进程的目的是让其完成任务的,父进程只有知道了子进程的pid才能更加有针对性地去给子进程指定任务.
为什么fork函数有两个返回值
父进程调用fork函数后,为了创建子进程,fork函数内部将会进行一系列操作,包括创建子进程的进程控制块、创建子进程的地址空间、创建子进程对应的页表等等.子进程创建完毕后,操作系统还需要将子进程的进程控制块添加到系统进程列表中,此时子进程便创建完毕了
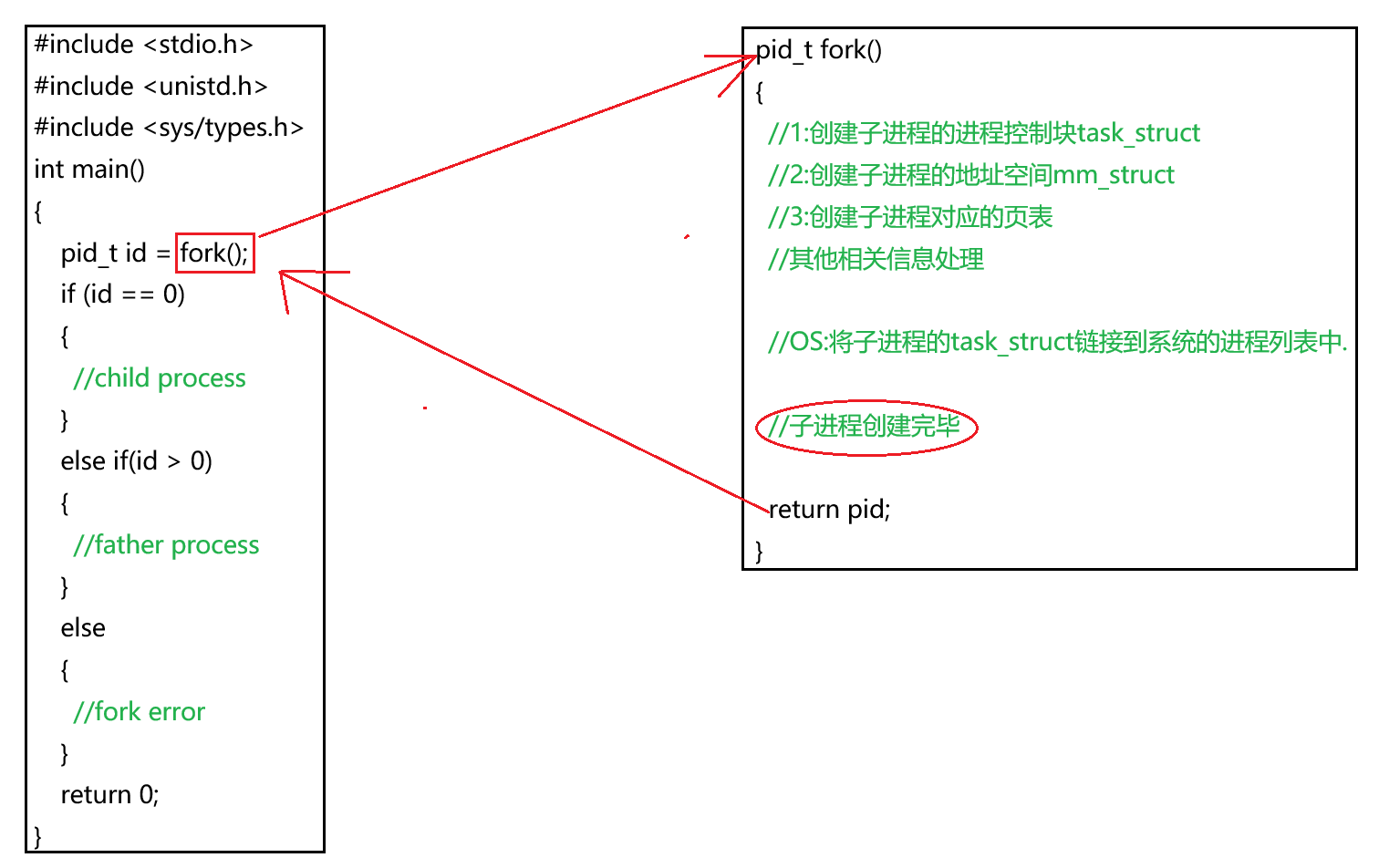
那么也就是说,在fork函数内部执行return语句以前,子进程就已经创建完毕了,那么之后的return语句不仅需要父进程执行,子进程也同样需要执行,这就是fork函数有两个返回值的原因.
1.3:写时拷贝
当子进程刚刚被创建时,子进程和父进程的数据和代码是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间。只有当父进程或子进程需要修改数据时,才将父进程的数据在内存当中拷贝一份,然后再进行修改。
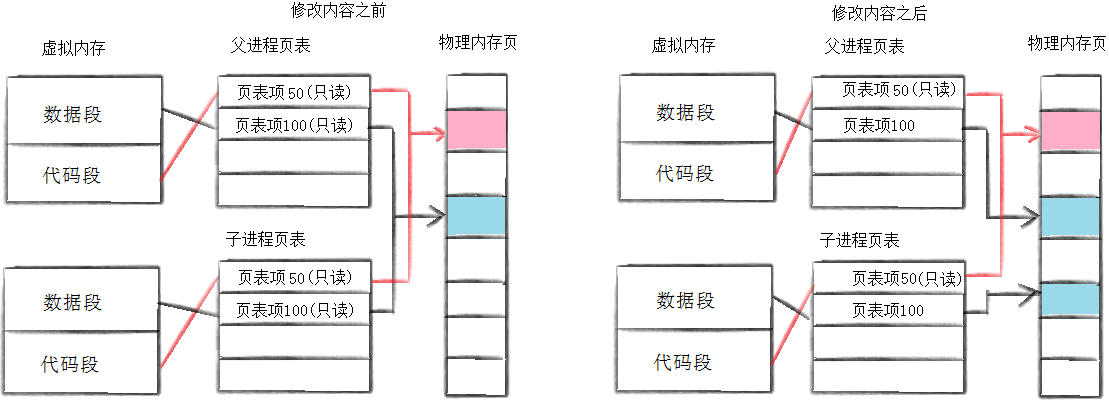
这种在需要进行数据修改时再进行拷贝的技术,称为写时拷贝.
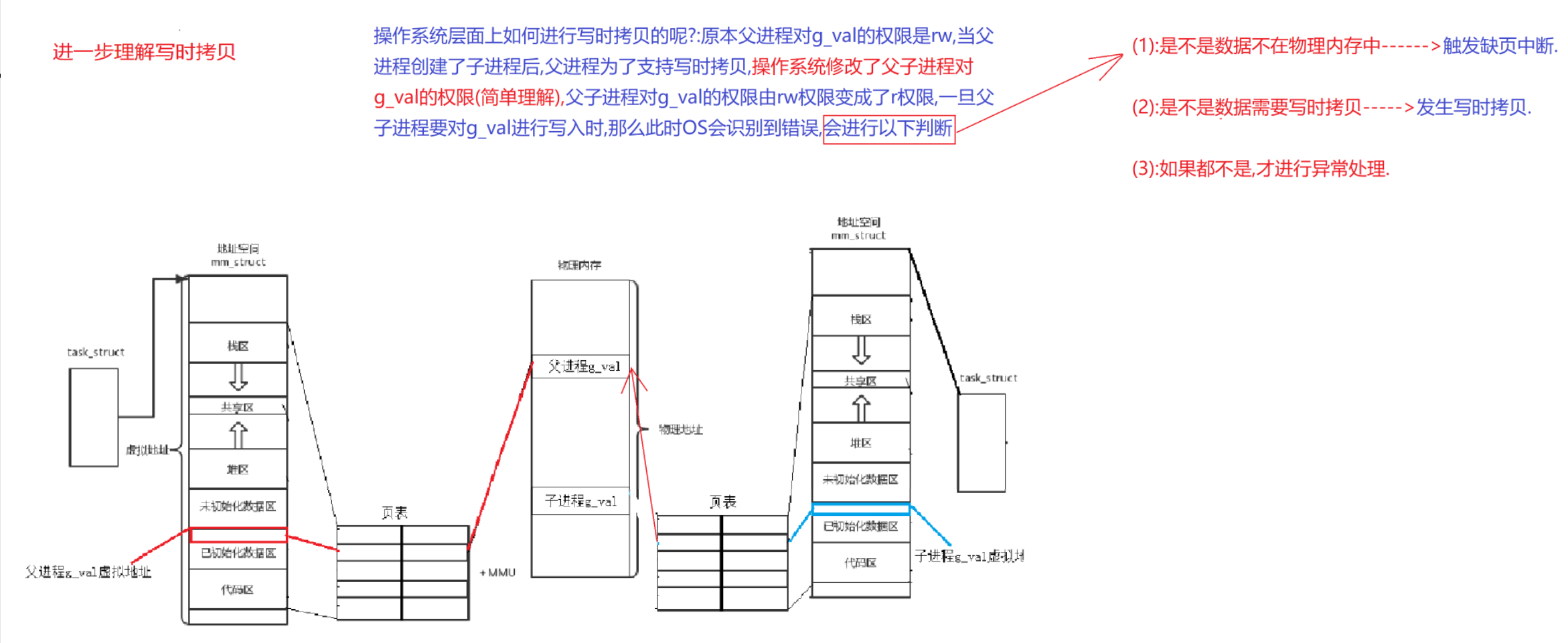
1:为什么数据要进行写时拷贝?
进程具有独立性.多个进程在运行时,需要独享各种资源,多进程运行期间互不干扰,不能让子进程的改变影响到父进程.
2:为什么不在创建子进程的时候进行写时拷贝.
子进程不一定会使用父进程的所有数据,并且在子进程不对数据进行写入的情况下,没有必要对数据进行拷贝,那么应该按需分配,在需要修改数据的时候再分配(延时分配),这样可以高效的使用内存空间,避免空间的浪费.
3:代码会不会进行写时拷贝?
90%的情况下是不会的,但这并不代表代码不能进行写时拷贝,例如在进行进程替换的时候,则需要进行代码的写时拷贝.
1.3:fork函数常规用法
- 一个进程希望复制自己,使子进程同时执行不同的代码段。例如父进程等待客户端请求,生成子进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
1.4:fork函数调用失败原因
fork函数创建子进程也可能会失败,有以下两种情况:
- 系统中有太多的进程,内存空间不足,子进程创建失败。
- 实际用户的进程数超过了限制,子进程创建失败
2:进程终止
进程 = 内核相关的数据结构(task_struct + mm_struct + 页表) + 代码 + 数据. 创建进程时,会先创建进程的内核的相关管理数据结构.
那么终止是在做什么呢
- 释放曾经的代码和数据所占据的空间.
- 释放内核数据结构.
那么进程终止存在以下三种情况
- 代码跑完,结果正确.
- 代码跑完,结果不正确.
- 代码执行的时候,出现了异常,提前退出了.
- 第一种情况和第二种情况可以通过进程的退出码来决定.
- 第三种情况,得通过OS发给进程的信号来确定.
2.1:退出码
- 我们都知道main函数是代码的入口,但实际上main函数只是用户级别代码的入口,main函数也是被其他函数调用的,例如在VS2013当中main函数就是被一个名为__tmainCRTStartup的函数所调用,而__tmainCRTStartup函数又是通过加载器被操作系统所调用的,也就是说main函数是间接性被操作系统所调用的.
- 既然main函数是间接性被操作系统所调用的,那么当main函数调用结束后就应该给操作系统返回相应的退出信息,而这个所谓的退出信息就是以退出码的形式作为main函数的返回值返回,一般以0表示代码成功执行完毕,以非0表示代码执行过程中出现错误,这就是为什么我们都在main函数的最后返回0的原因.
代码1
代码语言:javascript
AI代码解释
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("I am process and My pid =%d,ppid == %d\n",getpid(),getppid());
sleep(1);
return 99;
}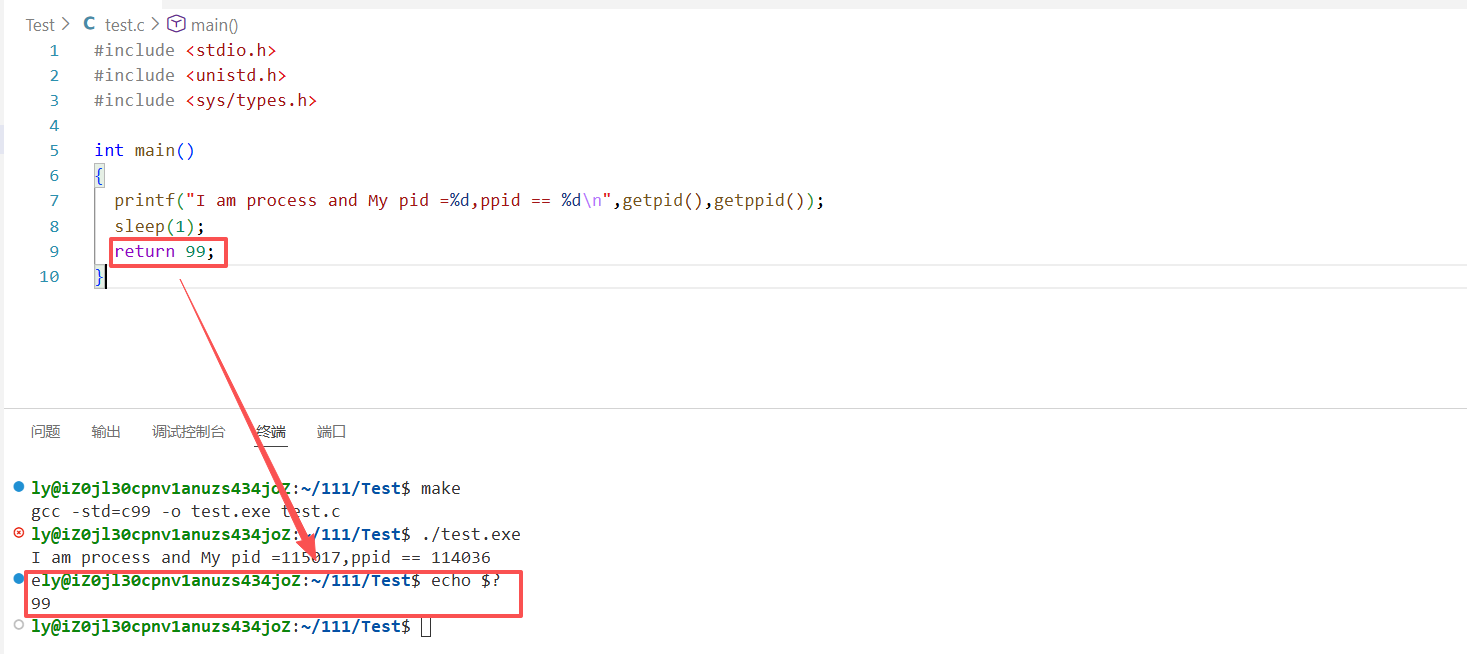
当我们的代码运行起来就变成了进程,当进程结束后main函数的返回值实际上就是该进程的进程退出码,我们可以使用echo $?命令查看最近一次进程退出的退出码信息.
- 退出码存在的意义就是在于:告诉关心方,我将任务完成得怎么样了.
- 退出码为0则表示成功,为非0表示失败.(博主使用99是为了方便uu们查看).
代码2
代码语言:javascript
AI代码解释
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <string.h>
int main()
{
for (int errorcode = 0; errorcode <= 255; errorcode++)
{
printf("errorcode == %d:%s\n",errorcode,strerror(errorcode));
}
return 0;
}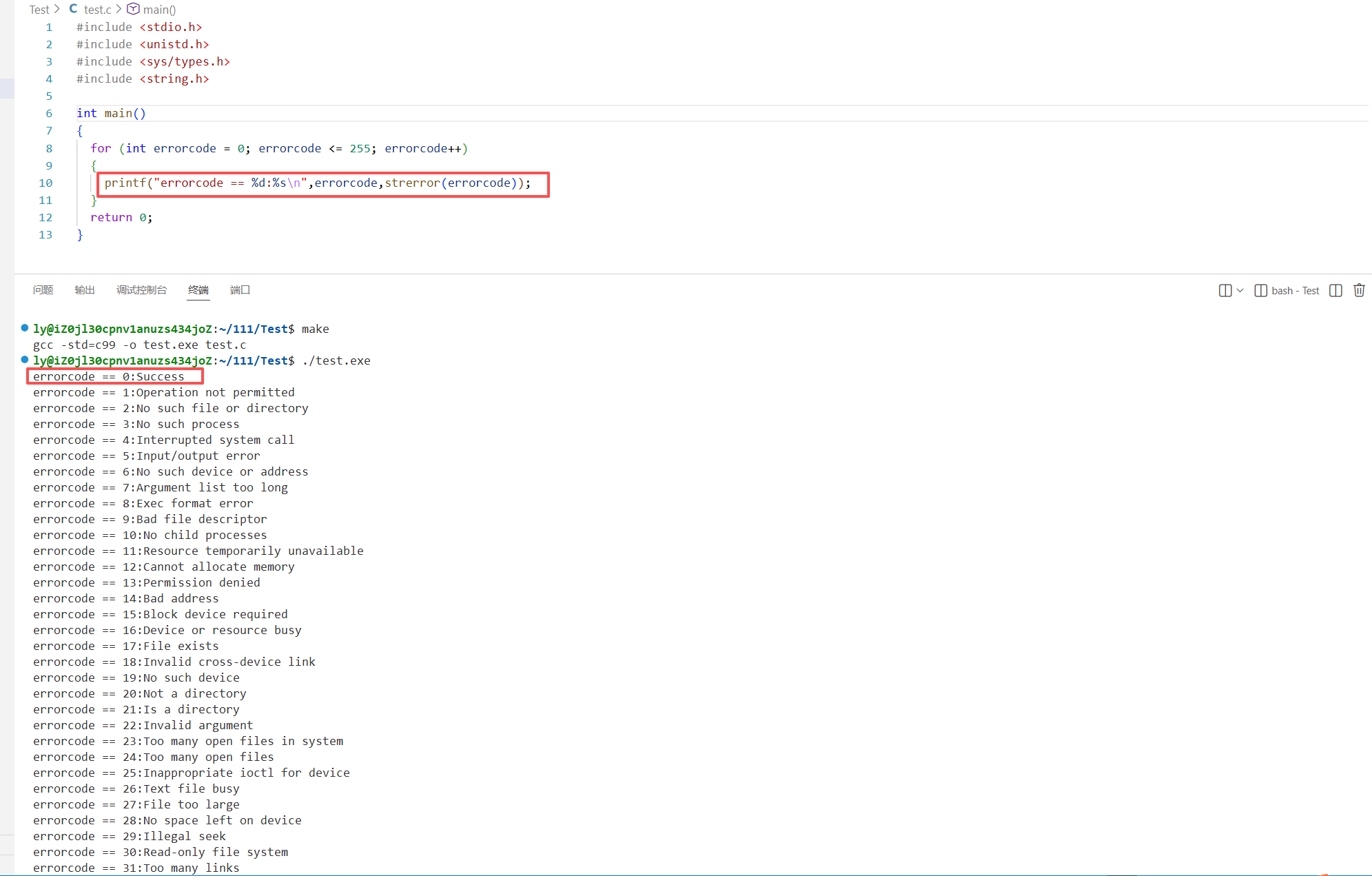
- 1,2,3,4,5,6.....不同的非0值,一方面表示失败,另一方面表示失败的原因.
父进程bash为什么要得到子进程的退出码呢?
- 要知道子进程的退出情况(成功,失败,以及失败的原因是什么)------>核心宗旨是为用户负责.
2.2:异常
异常这里后面会有专门的部分讲解,这里首先uu们简单理解下就好
- 可以想象一个场景,编程运行的时候,突然崩溃了,这个时候的根本原因是:发生了异常,操作系统系统发现进程做了不该做的事情,从而杀死了进程.
- 那么为什么会出现异常,原因在于:进程出现了异常,本质是因为进程收到了OS发给进程的信号.
- 一旦出现了异常,退出码就没有任何意义了.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)