ChatGPT 叫我不要直接用 AI 生成测试用例
在尝试使用 AI 生成测试用例的过程中,我发现同一个需求、相同输入下,多次生成的结果在覆盖点和侧重点上存在明显差异。为此,我以一个常见的登录页面为例,在不改变 prompt 的前提下连续生成三次测试用例和风险提示,并对结果进行对比。实验发现,AI 更擅长从不同视角提醒可能的测试点,但单次生成结果难以支撑对测试覆盖性的确定判断。本文记录了这次小实践的过程与阶段性思考,供同样在探索 AI 辅助测试的同
一、为什么我开始怀疑「AI 生成用例」这件事
最近一段时间,我在尝试用 AI 辅助生成测试用例。
而且市面上也有很多教材教AI 生成测试用例的。
一开始的直觉是:省事、省时间,看起来也挺全。
但实际用了一段时间后,我发现一个问题:
同一个需求、同一个输入,每次生成的用例都不太一样。
不是差一点,是:
-
覆盖点顺序不一样
-
风险关注点不一样
-
有些场景这次有、下次没了
这让我有点不踏实,那到底用哪一版本生成的用例啊。
于是我干脆做一个小的对比实验,看看这种不一致到底有多大。
二、我做了什么小实践
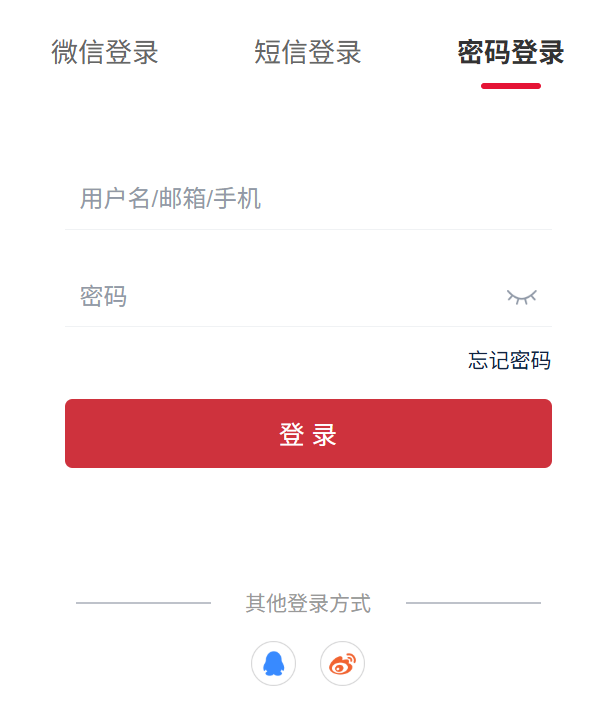
我没有搞复杂场景,就选了一个我自己非常熟悉的功能:登录页面。
实验方式很简单:
-
使用 同一个 AI 工具(我这次用的是元宝)
-
使用 完全相同的 prompt
-
每次都 新开一个窗口
-
连续生成 3 次
输入内容只有两样:
-
登录页面截图
-
一句话提示:
请基于该登录页面,生成测试用例,包含正常、异常和边界场景。
没有加任何“高级提示词”,就是大家平时最常用的那种。
三、三次生成结果,大概发生了什么
1️⃣ 测试用例本身
三次生成的结果有几个明显特征:
-
核心流程都会覆盖到
比如:正常登录、账号密码错误、为空等,这些几乎每次都有。 -
用例结构不一致
-
有的偏「功能 + 异常」
-
有的单独拉出了「安全」「UI」「兼容性」
-
有的混在一起写
-
-
细节覆盖不稳定
-
有一次有「密码可见性 / 复制粘贴」
-
有一次有「防暴力破解」
-
有一次完全没提
-
我截一下这三次的结果,截取部分:
第一次生成用例:

第二次用例生成:

第三次用例生成:

👉 结论不是“AI 不行”,而是:
它每次都会“换一个角度帮你想”。
2️⃣ 风险提示对比(差异更明显)
我又加了一轮问题:
基于这个登录页,你觉得最容易被忽略的 5 类风险是什么?
同样,问了三次。下面是部分截图。
第一次生成用例截图:

第二次生成用例截图:

第三次生成用例截图:

结果更明显了:
-
有一次偏 安全工程视角
-
有一次偏 用户行为 / 社会工程
-
有一次偏 产品设计 & 使用习惯
每一版说的都“有道理”,但:
-
关注点不一致
-
很难选哪一版才是“对的”
四、这次实验让我改变的一个认知
在公司里用 AI 生成用例时,我其实早就隐约感觉到这个问题:
每次生成的内容都差不多,但又不完全一样。
以前我会觉得:
“反正流程都覆盖了,问题不大。”
但这次对比后,我的态度变了。
五、我现在更倾向于怎么用 AI
经过这次实验,我目前更倾向于:
把 AI 当成「风险提醒工具」,反向生成用例,而不是「测试设计的最终答案」。
更具体一点说:
-
✅ 用它来:
-
提醒我有没有漏掉某些边界
-
从安全、异常、用户行为等角度“换脑子想一遍”
-
-
❌ 不再指望:
-
一次生成就能直接作为测试用例集
-
把“确定性工作”完全交给一次生成结果
-
至少在测试设计这种需要确定性的事情上,
我暂时还不太敢只依赖 AI 的“一次回答”。
六、这篇不是结论,只是一个记录
这不是说:
-
AI 不能用
-
生成用例没价值
而是我在真实使用后,发现:
AI 更擅长帮你“想漏了什么”,
但不擅长帮你“一次性想对”。
后面我还会继续试:
-
加约束 prompt
-
固定风险分类
-
或者用反向方式让 AI 做补漏
但至少在现在这个阶段,这次实验对我挺有价值的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)