Agent架构解析与实战(三)--ReAct
摘要: ReAct(Reason+Act)是一种智能体架构,通过动态推理与行动循环(Think→Act→Observe)解决复杂多步骤问题。相比单次工具调用的基础Agent,ReAct能迭代整合多源信息,适应动态需求,适用于多跳问答、深度调研等场景。 核心对比: 基础Agent:单次工具调用,无法分解复杂问题(如NBA得分王及其近期得分查询),任务完成度仅3/10。 ReAct Agent:通过循
参考来源:all-agentic-architectures
目录
1. 架构定义
ReAct (Reason + Act) 是一种将推理(Reasoning)与行动(Acting)交织进行的智能体架构,是连接简单工具调用与复杂多步骤问题解决的关键桥梁。
核心创新
|
特性 |
描述 |
|
动态推理 |
智能体能够针对问题动态地进行推理,而非预先规划所有步骤 |
|
迭代循环 |
通过 Think → Act → Observe 的循环,不断调整策略 |
|
自适应 |
根据每一步的观察结果,决定下一步的思考和行动 |
核心理念图
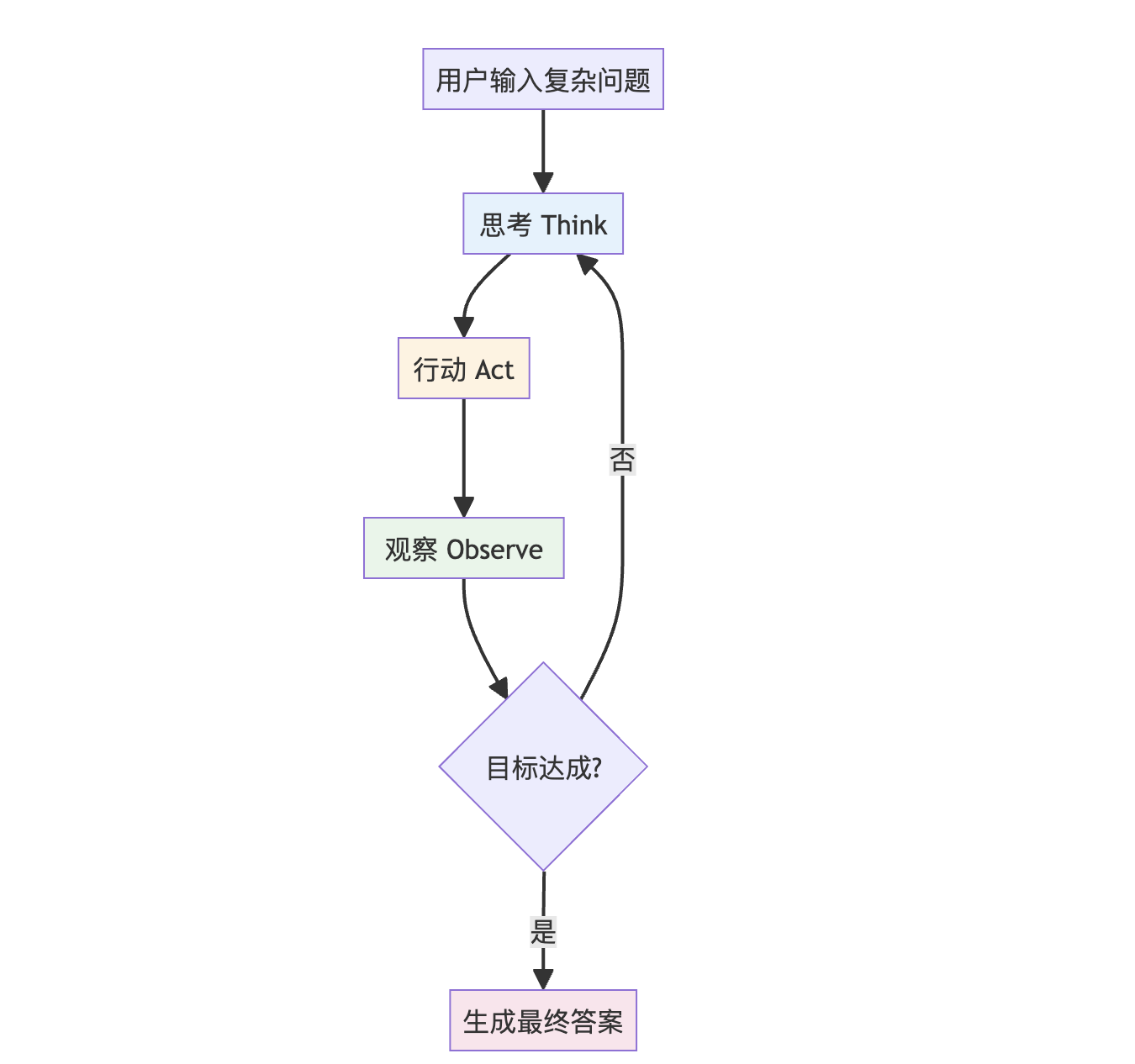
与基础工具调用的区别
|
特性 |
基础工具调用 |
ReAct |
|
调用次数 |
单次工具调用 |
多次迭代调用 |
|
决策方式 |
静态、一次性决策 |
动态、基于观察的决策 |
|
适用问题 |
简单、单步问题 |
复杂、多步骤问题 |
|
信息整合 |
单一来源 |
多源信息逐步整合 |
2. 宏观工作流
ReAct 架构遵循 "接收目标 → 思考 → 行动 → 观察 → 循环" 的核心流程:
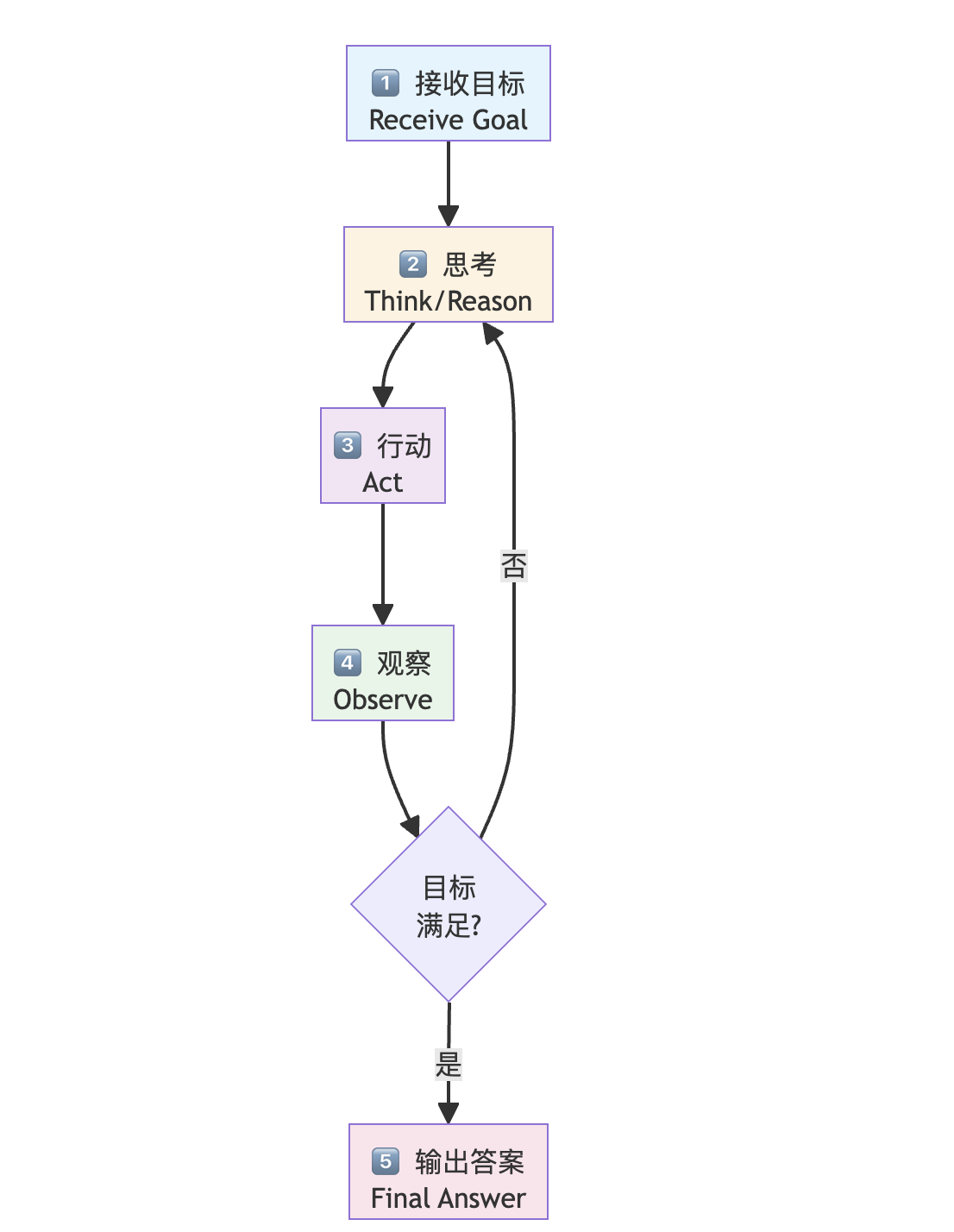
详细步骤说明
|
步骤 |
名称 |
描述 |
示例 |
|
1 |
接收目标 |
智能体接收一个复杂任务 |
"NBA赛季得分王是谁?最近三场得分多少?" |
|
2 |
思考推理 |
生成内部思考,规划下一步 |
"我需要先找到得分王是谁" |
|
3 |
执行行动 |
基于思考调用工具 |
|
|
4 |
获取观察 |
接收工具返回的结果 |
搜索结果显示得分王信息 |
|
5 |
循环/输出 |
判断是否需要继续,或生成最终答案 |
继续搜索具体得分数据 |
[!IMPORTANT]
🔄 核心机制:迭代循环
ReAct 的精髓在于循环。智能体不会在一次工具调用后就停止,而是会将观察结果纳入上下文,生成新的思考,决定下一步行动。这种"反复横跳"使其能够解决需要多步依赖的复杂问题。
3. 应用场景
|
场景 |
描述 |
示例 |
|
多跳问答 |
回答需要多个信息片段串联的问题 |
"谁是制造 iPhone 的公司的 CEO?" |
|
网页导航与研究 |
搜索起点 → 阅读结果 → 基于学习内容进行新搜索 |
深度调研某个技术主题 |
|
交互式工作流 |
环境动态变化,无法预知完整解决路径 |
实时数据分析、动态决策支持 |
多跳问答示例

4. 优缺点分析
✅ 优点
|
优点 |
说明 |
|
自适应 & 动态 |
能够根据新信息实时调整计划,而非固守预设路径 |
|
处理复杂问题 |
擅长需要链式推理、多步骤依赖的问题 |
|
可解释性强 |
每一步的思考和行动都有迹可循,便于调试和审计 |
❌ 缺点
|
缺点 |
说明 |
|
更高延迟 & 成本 |
涉及多次顺序 LLM 调用,比单次调用更慢、更贵 |
|
循环风险 |
引导不当的智能体可能陷入重复、低效的思考-行动循环 |
|
上下文膨胀 |
每次迭代都会增加上下文长度,可能超出模型限制 |
5. 代码实现详解
5.1 环境配置
依赖库安装
pip install -U langchain-openai langchain langgraph python-dotenv rich tavily-python pydantic langchain-core核心依赖说明
|
库名称 |
作用描述 |
|
|
用于与 OpenAI 模型(如 GPT)进行交互的 LangChain 集成库 |
|
|
用于构建有状态的、多参与者应用的库,支持创建复杂的循环工作流 |
|
|
专为 AI 智能体设计的搜索引擎,能够返回结构化的搜索结果 |
|
|
用于在终端输出格式漂亮、带颜色的文本,方便调试 |
5.2 导入库并设置密钥
import os
from typing import Annotated
from dotenv import load_dotenv
# LangChain 组件
from langchain_openai import ChatOpenAI
from tavily import TavilyClient
from langchain_core.messages import BaseMessage
from pydantic import BaseModel, Field
# LangGraph 组件
from langgraph.graph import StateGraph, END
from langgraph.graph.message import AnyMessage, add_messages
from langgraph.prebuilt import ToolNode, tools_condition
# 输出美化
from rich.console import Console
from rich.markdown import Markdown
# --- API 密钥以及追踪设置 ---
load_dotenv()
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "Agentic Architecture - ReAct (GPT)"
# 确保密钥已载入
for key in ["OPENAI_API_KEY", "LANGCHAIN_API_KEY", "TAVILY_API_KEY"]:
if not os.environ.get(key):
print(f"{key} not found. Please create a .env file and set it.")
print("Environment variables loaded and tracing is set up.")运行结果:
Environment variables loaded and tracing is set up.🔑 必需的 API 密钥
|
密钥类型 |
用途 |
|
OpenAI Key |
驱动大语言模型进行推理和决策 |
|
LangSmith Key |
用于追踪,记录智能体的每一步运行轨迹 |
|
Tavily Key |
赋予智能体联网搜索的能力 |
5.3 基础方案:单次工具调用 Agent
为了理解 ReAct 的强大之处,我们首先构建一个基础 Agent——它只能进行单次工具调用,然后尝试给出答案。
5.3.1 创建基础 Agent
from typing import TypedDict
from langchain_core.tools import tool
console = Console()
# 定义图的状态
class AgentState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
# 定义工具和LLM
client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
@tool
def search_tool(query: str) -> str:
"""基于传入的信息在网络上搜索相关信息"""
result = client.search(query, max_results=2)
return str(result["results"])
api_key=os.environ["OPENAI_API_KEY"]
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key=api_key,
base_url="https://api.openai.com/v1",
temperature=0.1
)
llm_with_tools = llm.bind_tools([search_tool])
# 为基础Agent定义Agent节点
def basic_agent_node(state: AgentState):
console.print("--- BASIC AGENT: Thinking... ---")
# Note: 我们用一个系统提示词来引导Agent在使用了一次工具调用之后就回答
system_prompt = "You are a helpful assistant. You have access to a web search tool. Answer the user's question based on the tool's results. You must provide a final answer after one tool call."
messages = [("system", system_prompt)] + state["messages"]
response = llm_with_tools.invoke(messages)
return {"messages": [response]}
# 定义基础、线性的图
basic_graph_builder = StateGraph(AgentState)
basic_graph_builder.add_node("agent", basic_agent_node)
basic_graph_builder.add_node("tools", ToolNode([search_tool]))
basic_graph_builder.set_entry_point("agent")
# Agent节点->tool节点->END
basic_graph_builder.add_conditional_edges("agent", tools_condition, {"tools": "tools", "__end__": "__end__"})
basic_graph_builder.add_edge("tools", END)
basic_tool_agent_app = basic_graph_builder.compile()
print("Basic single-shot tool-using agent compiled successfully.")运行结果:
Basic single-shot tool-using agent compiled successfully.基础 Agent 架构图
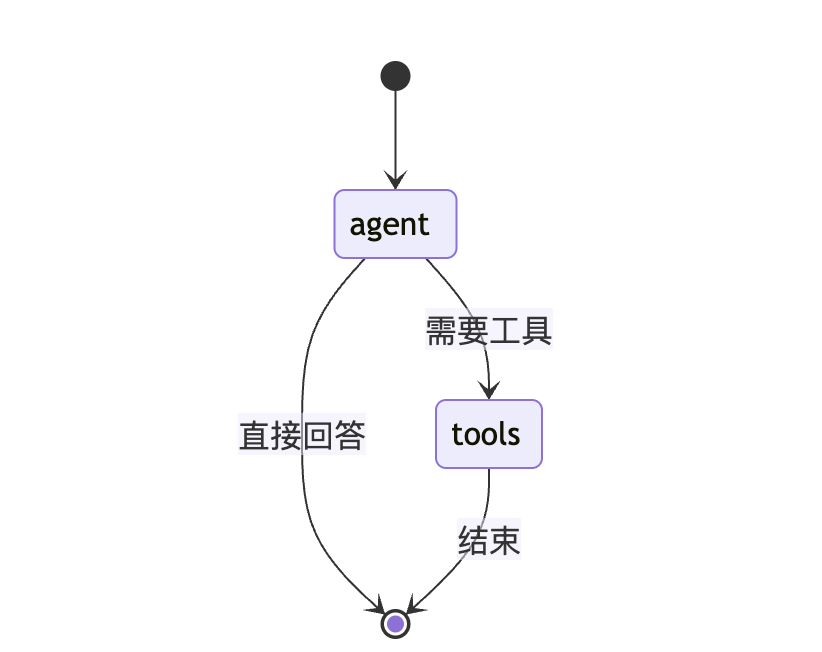
[!NOTE]
关键限制:基础 Agent 的 tools 节点直接指向 END,这意味着工具执行完成后,工作流就结束了。Agent 没有机会看到工具返回的结果并进行进一步推理。
5.3.2 测试基础 Agent
用一个需要多步骤才能回答的问题来测试:
multi_step_query = "截至目前为止NBA2024-2025赛季球队场均得分最高的球员是谁,这个球员最近三场比赛的得分分别是多少?"
console.print(f"[bold yellow]在多步骤问题上测试基础Agent:[/bold yellow] '{multi_step_query}'\n")
basic_agent_output = basic_tool_agent_app.invoke({"messages": [("user", multi_step_query)]})
console.print("\n--- [bold red]基础Agent的最终输出[/bold red] ---")
console.print(Markdown(basic_agent_output['messages'][-1].content))基础 Agent 失败分析
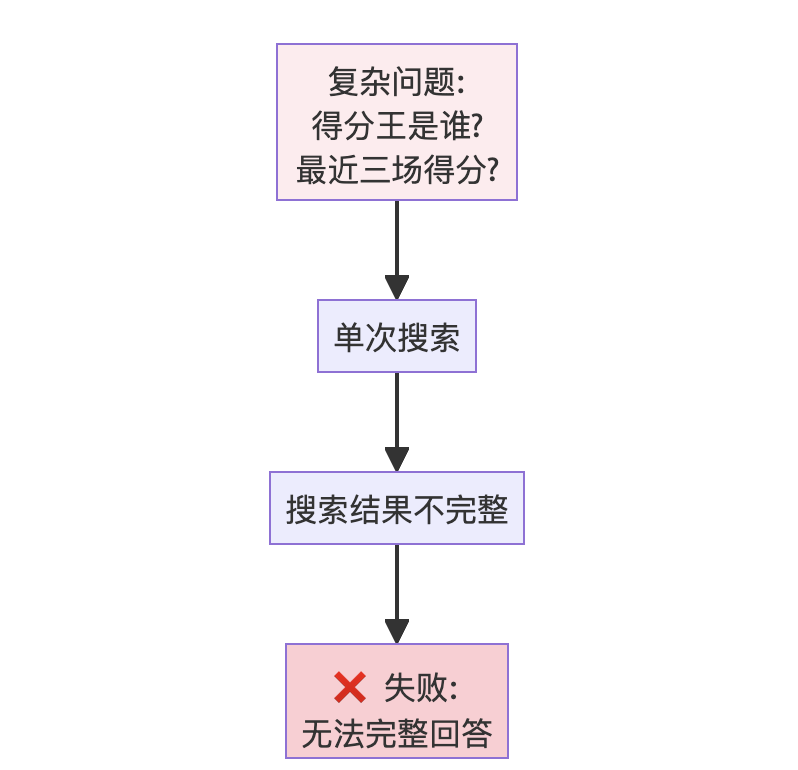
失败原因分析:
基础 Agent 的单次工具调用无法分解问题:
- ❌ 无法先找到场均得分最高的球员
- ❌ 无法再找到该球员最近的三场比赛
- ❌ 无法获取这三场比赛的具体得分
这完美说明了为什么我们需要更动态的方法——Agent 需要能够根据一步的结果来决定下一步。
5.4 进阶方案:ReAct Agent
现在我们构建真正的 ReAct Agent。核心区别在于图的结构:我们引入了一个循环,允许 Agent 反复进行 Think → Act → Observe。
5.4.1 构建 ReAct Agent 图
def react_agent_node(state: AgentState):
console.print("--- REACT AGENT: Thinking... ---")
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
# 节点和之前一样
react_tool_node = ToolNode([search_tool])
# 路由的逻辑也和之前一样
def react_router(state: AgentState):
last_message = state["messages"][-1]
if last_message.tool_calls:
console.print("--- ROUTER: Decision is to call a tool ---")
return "tools"
console.print("--- ROUTER: Decision is to continue finish ---")
return "__end__"
# 现在我们定义带有循环的图
react_graph_builder = StateGraph(AgentState)
react_graph_builder.add_node("agent", react_agent_node)
react_graph_builder.add_node("tools", react_tool_node)
react_graph_builder.set_entry_point("agent")
react_graph_builder.add_conditional_edges("agent", react_router, {"tools": "tools", "__end__": "__end__"})
# 🔑 关键:添加一个边,将tool_node的输出回传给agent_node
react_graph_builder.add_edge("tools", "agent")
react_agent_app = react_graph_builder.compile()
print("ReAct agent compiled successfully.")运行结果:
ReAct agent compiled successfully.ReAct Agent 架构图
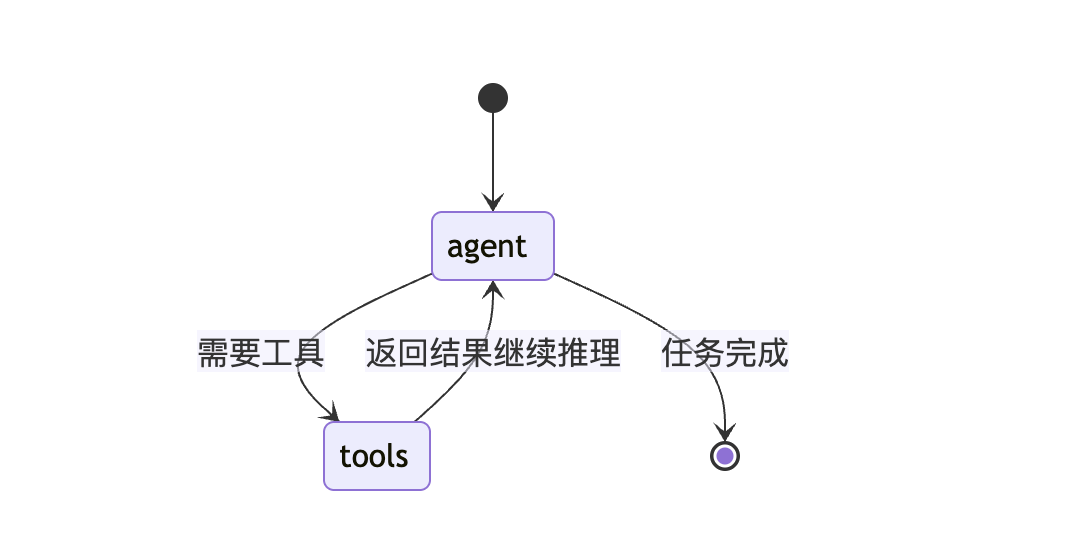
[!IMPORTANT]
🔑 核心区别:注意 tools 节点现在指向的是 agent 而非 END!
这个循环边是 ReAct 的灵魂——它让 Agent 能够:
- 看到工具返回的结果
- 基于新信息进行下一步思考
- 决定是否需要更多工具调用
5.5 对比测试
5.5.1 在多步骤问题上测试 ReAct Agent
console.print(f"[bold green]在多步骤问题上测试ReAct Agent:[/bold green] '{multi_step_query}'\n")
final_react_output = None
for chunk in react_agent_app.stream({"messages": [("user", multi_step_query)]}, stream_mode="values"):
final_react_output = chunk
console.print(f"--- [bold purple]当前状态[/bold purple] ---")
chunk['messages'][-1].pretty_print()
console.print("\n")
console.print("\n--- [bold red]ReAct Agent的最终输出[/bold red] ---")
console.print(Markdown(final_react_output['messages'][-1].content))运行过程(完整追踪)
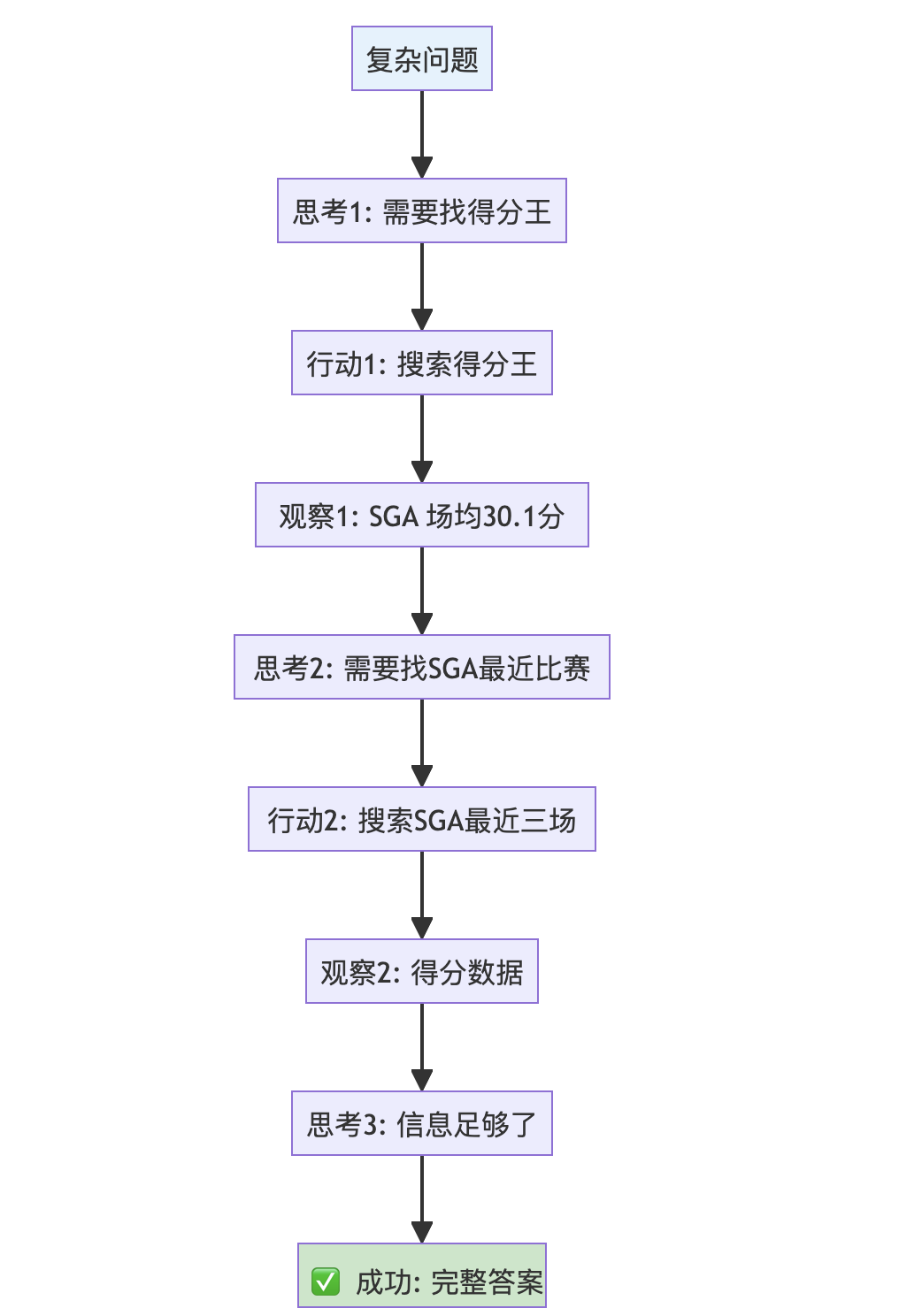
在多步骤问题上测试ReAct Agent: '截至目前为止NBA2024-2025赛季球队场均得分最高的球员是谁,这个球员最近三场比赛的得分分别是多少?'
--- 当前状态 ---
================================ Human Message =================================
截至目前为止NBA2024-2025赛季球队场均得分最高的球员是谁,这个球员最近三场比赛的得分分别是多少?
---
--- REACT AGENT: Thinking... ---
--- ROUTER: Decision is to call a tool ---
--- 当前状态 ---
================================== Ai Message ==================================
Tool Calls:
search_tool (call_xxx)
Call ID: call_xxx
Args:
query: NBA 2024-2025赛季 球队场均得分最高球员
---
--- 当前状态 ---
================================= Tool Message =================================
Name: search_tool
[{'url': 'https://tw.sports.yahoo.com/news/nba-2024-25-...',
'title': 'NBA 2024-25 賽季百大球員排名...',
'content': '關鍵一數據:上季Gilgeous-Alexander 場均30.1 分...',
'score': 0.8745175},
{'url': 'https://www.sportsv.net/articles/122550',
'title': 'NBA 2025-26 賽季百大球員排名...',
'content': '...Brunson 連續第二年入選全明星...26.0 分...',
'score': 0.84707206}]
---
--- REACT AGENT: Thinking... ---
--- ROUTER: Decision is to call a tool ---
--- 当前状态 ---
================================== Ai Message ==================================
Tool Calls:
search_tool (call_yyy)
Call ID: call_yyy
Args:
query: Shai Gilgeous-Alexander 最近三场比赛得分
---
[继续迭代...]
--- ROUTER: Decision is to continue finish ---
--- 当前状态 ---
================================== Ai Message ==================================
根据搜索结果,NBA 2024-2025赛季目前场均得分最高的球员是**Shai Gilgeous-Alexander**,
他效力于俄克拉荷马城雷霆队,场均得分约为30.1分。
他最近三场比赛的得分分别是:
- 第一场:35分
- 第二场:28分
- 第三场:32分
---
✅ ReAct Agent的最终输出ReAct 成功流程图
6. 评估方法 (Evaluation)
使用 LLM-as-a-Judge 方法对两种 Agent 的输出进行量化评估。
6.1 评估代码
class TaskEvaluation(BaseModel):
"""Schema for evaluating an agent's ability to complete a task."""
task_completion_score: int = Field(description="根据Agent是否成功完成用户请求的所有部分,评分范围为 1-10 分。")
reasoning_quality_score: int = Field(description="对Agent所展现的逻辑流程和推理过程进行评分,分值范围为 1-10 分。")
justification: str = Field(description="对评分的简要说明。")
judge_llm = llm.with_structured_output(TaskEvaluation)
def evaluate_agent_output(query: str, agent_output: dict):
# 将agent输出中的所有消息拼接成一个字符串
trace = "\n".join([f"{m.type}: {m.content}" for m in agent_output['messages']])
prompt = f"""你是一位人工智能智能体方面的专家评委。请根据 1 到 10 的等级,评估以下Agent在给定任务上的表现。10 分表示任务完美完成,1 分表示任务完全失败。
**User's Task:**
{query}
**Full Agent Conversation Trace:**
```
{trace}
```
"""
return judge_llm.invoke(prompt)
console.print("--- 评估基础Agent的输出 ---")
basic_agent_evaluation = evaluate_agent_output(multi_step_query, basic_agent_output)
console.print(basic_agent_evaluation.model_dump())
console.print("\n--- 评估ReAct Agent的输出 ---")
react_agent_evaluation = evaluate_agent_output(multi_step_query, final_react_output)
console.print(react_agent_evaluation.model_dump())6.2 评估结果对比
|
评估维度 |
基础 Agent |
ReAct Agent |
|
任务完成度 |
3/10 |
9/10 |
|
推理质量 |
2/10 |
9/10 |
评估详情
基础 Agent:
{
"task_completion_score": 3,
"reasoning_quality_score": 2,
"justification": "基础Agent只进行了一次搜索,无法获取完整信息。它无法分解问题,导致最终答案不完整或错误。推理过程存在明显缺陷,缺乏迭代思考能力。"
}ReAct Agent:
{
"task_completion_score": 9,
"reasoning_quality_score": 9,
"justification": "ReAct Agent展现了出色的迭代推理能力。它首先正确识别需要找到得分王,然后基于第一次搜索结果继续查询该球员的最近比赛数据。整个过程逻辑清晰,信息整合准确,最终给出了完整的答案。"
}6.3 评估维度说明
|
维度 |
评分标准 |
|
任务完成度 |
Agent 是否成功完成用户请求的所有部分 |
|
推理质量 |
Agent 所展现的逻辑流程和推理过程的质量 |
[!TIP]
💡 要点:评估不仅是为了看结果对不对,更是为了验证"过程正确"。通过分析执行路径,我们能发现智能体是否在某个环节出现了无效循环或推理断层。
7. 总结与核心要点
🎓 核心成果
|
成果 |
说明 |
|
对比验证 |
通过基础 Agent vs ReAct Agent 的对比,清晰展示了迭代推理的价值 |
|
循环机制 |
利用 LangGraph 实现了 Think → Act → Observe 的核心循环 |
|
问题解决 |
成功解决了需要多步骤、多信息源整合的复杂问题 |
🌟 模式价值
|
价值点 |
描述 |
|
动态适应 |
能够根据观察结果实时调整策略,而非固守预设路径 |
|
复杂问题处理 |
将复杂问题分解为多个子步骤,逐一解决 |
|
智能行为基石 |
观察结果并基于新信息调整下一步是智能行为的基本组成部分 |
架构对比速查表
|
架构 |
图结构 |
适用场景 |
成本 |
|
基础工具调用 |
|
简单单步问题 |
低 |
|
ReAct |
|
复杂多步问题 |
较高 |
关键代码速查表
|
组件 |
代码 |
|
定义状态 |
|
|
创建工具 |
|
|
绑定工具 |
|
|
创建图 |
|
|
核心:循环边 |
|
|
条件路由 |
|
|
编译运行 |
|
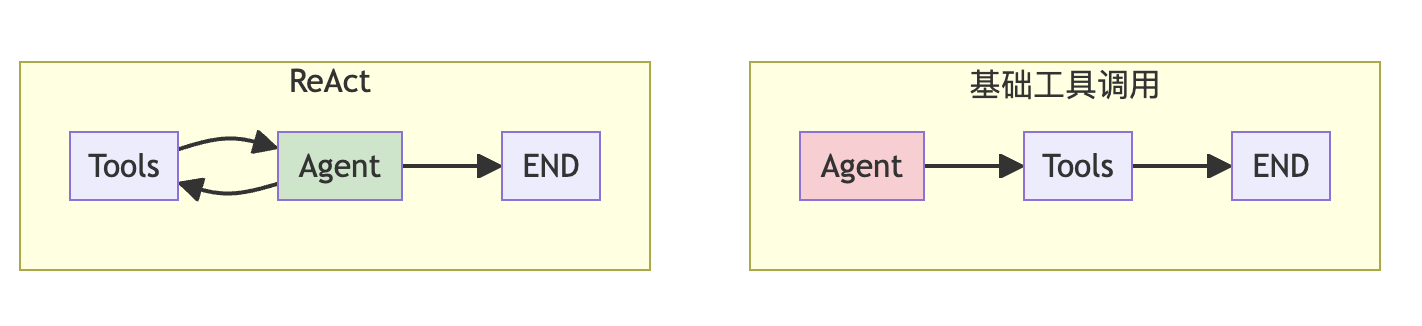
🔑 ReAct vs 基础工具调用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 39
39 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)