metadata元数据过滤使用方式与业务场景分析
📋 目录
方法代码分析
完整代码流程
@Test
public void testKeywordMetadataEnricher(
@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel chatModel,
@Value("classpath:rag/terms-of-service.txt") Resource resource) {
// 1. 读取文档
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", resource.getFilename());
List<Document> documents = textReader.read();
// 2. 文档分割
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
documents = splitter.apply(documents);
// 3. 关键词元数据增强(核心步骤)
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
documents = enricher.apply(documents);
// 4. 存储到向量库
vectorStore.add(documents);
// 5. 基于元数据过滤检索
documents = vectorStore.similaritySearch(
SearchRequest.builder()
.query("退票") // 相似度检索查询
.topK(5) // 返回前 5 个结果
// .filterExpression("excerpt_keywords in ('退票')") // 元数据过滤
.build());
// 6. 输出结果
documents.forEach(doc -> {
System.out.println("Metadata: " + doc.getMetadata());
System.out.println("excerpt_keywords: " + doc.getMetadata().get("excerpt_keywords"));
});
}
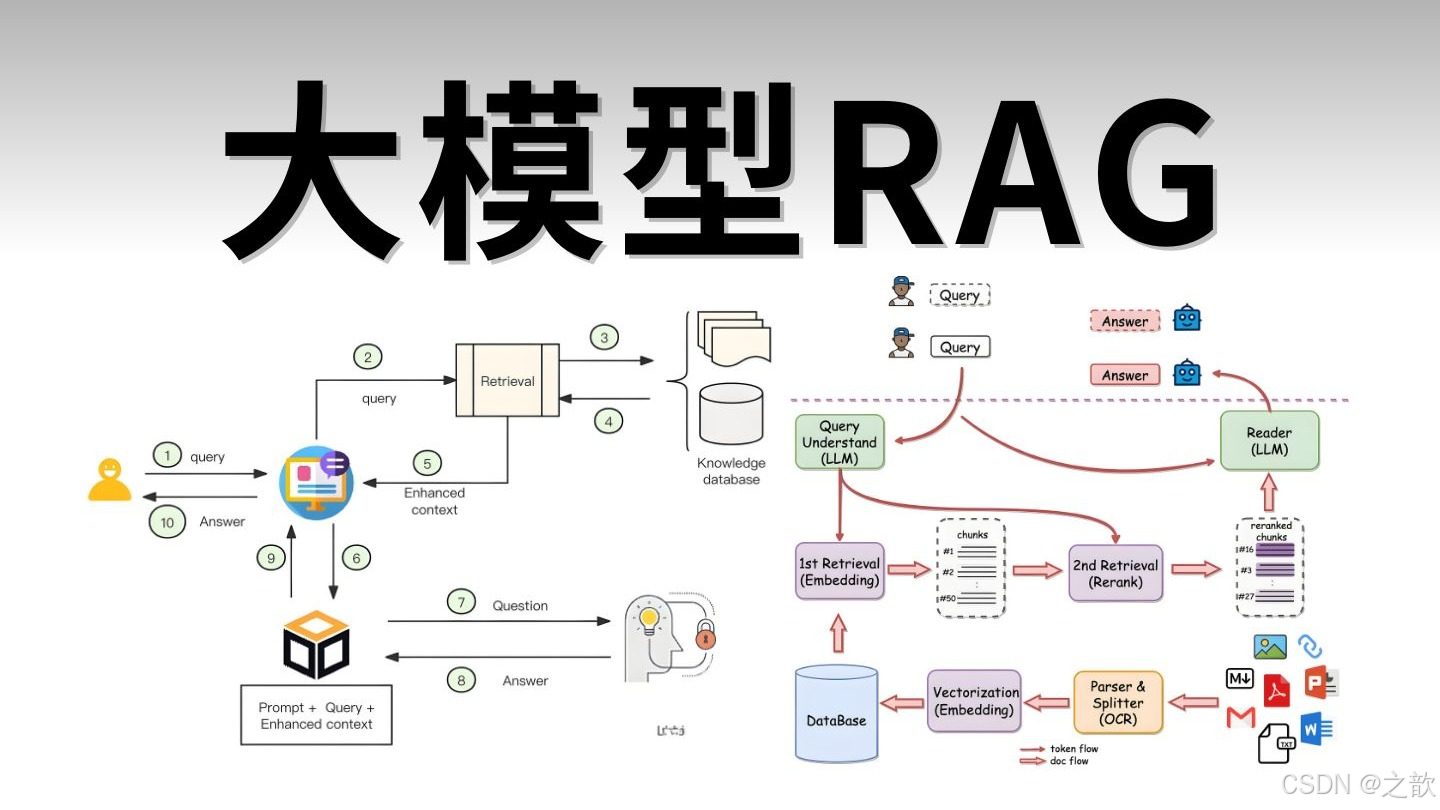
执行流程图示
文档读取
↓
文档分割(ChineseTokenTextSplitter)
↓
关键词提取(KeywordMetadataEnricher)
├─ 调用 LLM 提取关键词
└─ 将关键词存储到 metadata["excerpt_keywords"]
↓
向量化存储(VectorStore.add)
├─ 文本向量化
└─ 元数据与向量一起存储
↓
相似度检索 + 元数据过滤
├─ 向量相似度计算
└─ 元数据过滤(可选)
↓
返回匹配的文档
元数据增强原理
KeywordMetadataEnricher 工作原理
核心功能:使用大语言模型(LLM)为每个文档分块提取关键词,并将关键词存储到文档的元数据中。
1. 初始化
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(
chatModel, // ChatModel 实例(用于调用 LLM)
5 // 提取的关键词数量
);
2. 关键词提取流程
1. 遍历每个 Document 分块
2. 构建 Prompt,调用 LLM:
- 输入:文档文本内容
- 指令:提取 N 个关键词
- 输出:关键词列表(如 ["退票", "费用", "取消", "政策", "退款"])
3. 将关键词存储到 Document.metadata["excerpt_keywords"]
4. 返回增强后的 Document 列表
3. 元数据结构
增强前:
Document {
text: "退票需要支付 75 美元的费用,最晚在航班起飞前 48 小时取消..."
metadata: {
"filename": "terms-of-service.txt"
}
}
增强后:
Document {
text: "退票需要支付 75 美元的费用,最晚在航班起飞前 48 小时取消..."
metadata: {
"filename": "terms-of-service.txt",
"excerpt_keywords": ["退票", "费用", "取消", "政策", "退款"] // 新增
}
}
4. 自定义关键词提取模板
// 自定义模板:限制关键词范围
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
给我按照我提供的内容{context_str},生成%s个关键字;
允许的关键字有这些:
['退票','预定']
只允许在这个关键字范围进行选择。
""";
使用场景:
- 需要从预定义的关键词列表中选择
- 确保关键词符合业务规范
- 提高关键词提取的准确性
元数据过滤使用方式
1. FilterExpression 基础语法
Spring AI 提供了两种方式构建过滤表达式:
方式 1:字符串形式(String)
SearchRequest.builder()
.filterExpression("excerpt_keywords in ('退票')") // 字符串形式
.build()
方式 2:FilterExpressionBuilder(推荐)
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票") // 类型安全,推荐使用
.build();
SearchRequest.builder()
.filterExpression(filterExpression)
.build()
2. 支持的过滤操作符
| 操作符 | 说明 | 示例 |
|---|---|---|
eq |
等于 | .eq("category", "退票") |
ne |
不等于 | .ne("category", "预定") |
gt |
大于 | .gt("score", 0.6) |
gte |
大于等于 | .gte("score", 0.6) |
lt |
小于 | .lt("score", 1.0) |
lte |
小于等于 | .lte("score", 1.0) |
in |
在列表中 | .in("excerpt_keywords", "退票", "费用") |
nin |
不在列表中 | .nin("category", "预定", "改签") |
and |
逻辑与 | .eq("category", "退票").and().eq("filename", "terms.txt") |
or |
逻辑或 | .eq("category", "退票").or().eq("category", "取消") |
not |
逻辑非 | .not().eq("category", "预定") |
3. 常用过滤模式
模式 1:单关键词过滤
// 只检索包含"退票"关键词的文档
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build();
SearchRequest searchRequest = SearchRequest.builder()
.query("退票费用")
.topK(5)
.filterExpression(filterExpression)
.build();
模式 2:多关键词过滤(OR)
// 检索包含"退票"或"费用"关键词的文档
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票", "费用")
.build();
模式 3:组合条件过滤(AND)
// 检索同时满足多个条件的文档
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票") // 包含"退票"关键词
.and()
.eq("filename", "terms-of-service.txt") // 并且文件名是 "terms-of-service.txt"
.and()
.gte("score", 0.6) // 并且相似度 >= 0.6
.build();
模式 4:复杂逻辑组合
// (category == "退票" OR category == "取消") AND filename == "terms.txt"
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.eq("category", "退票")
.or()
.eq("category", "取消")
.and()
.eq("filename", "terms.txt")
.build();
4. 在 RAG Advisor 中使用
// 在 QuestionAnswerAdvisor 中使用元数据过滤
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.topK(5)
.similarityThreshold(0.6)
.filterExpression(
FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build()
)
.build()
)
.build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(advisor)
.build();
String answer = chatClient.prompt()
.user("退票需要多少费用?")
.call()
.content();
5. 注意事项
⚠️ 数组类型字段的过滤
excerpt_keywords 是数组类型(List<String>),使用 in 操作符时需要注意:
// ✅ 正确:使用 FilterExpressionBuilder.in()
FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票") // 检查数组是否包含"退票"
.build()
// ❌ 错误:字符串形式的数组语法可能不兼容
.filterExpression("excerpt_keywords in [\"退票\"]") // 可能解析失败
⚠️ 检查元数据格式
在使用过滤表达式前,建议先检查文档的元数据格式:
// 检查元数据格式
documents.forEach(doc -> {
System.out.println("Metadata: " + doc.getMetadata());
System.out.println("excerpt_keywords: " + doc.getMetadata().get("excerpt_keywords"));
System.out.println("excerpt_keywords type: " +
doc.getMetadata().get("excerpt_keywords").getClass());
});
元数据过滤的用途与价值
1. 提高检索精度
问题:仅使用向量相似度检索时,可能返回语义相似但主题不相关的文档。
解决方案:结合元数据过滤,确保检索结果既语义相关,又符合业务主题。
示例:
用户查询:"退票需要多少费用?"
仅向量检索可能返回:
- ✅ "退票费用是 75 美元"(相关)
- ❌ "预定费用是 100 美元"(语义相似但不相关)
向量检索 + 元数据过滤:
- ✅ "退票费用是 75 美元"(excerpt_keywords 包含"退票")
- ❌ "预定费用是 100 美元"(被过滤掉)
2. 减少噪音文档
问题:大规模知识库中,相似度检索可能返回大量不相关文档。
解决方案:使用元数据过滤,在检索前就排除不相关的文档类别。
效果对比:
| 方式 | 检索文档数 | 相关文档数 | 精度 |
|---|---|---|---|
| 仅向量检索 | 100 | 20 | 20% |
| 向量检索 + 元数据过滤 | 15 | 12 | 80% |
3. 支持复杂业务查询
场景:需要同时满足多个业务条件的查询。
示例:
// 查询:2024年发布的、关于"退票"的、评分 >= 4.0 的文档
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.and()
.eq("year", "2024")
.and()
.gte("rating", 4.0)
.build();
4. 提高检索性能
原理:元数据过滤通常在向量检索之前或之后进行,可以减少需要处理的文档数量。
性能提升:
- 减少向量计算:如果向量库支持,可以在向量检索前过滤
- 减少数据传输:只返回符合过滤条件的文档
- 减少后续处理:减少需要排序、重排的文档数量
5. 支持多维度检索
维度:可以基于多个元数据维度进行过滤:
- 主题维度:
excerpt_keywords - 文档类型:
document_type(如 “政策”、“FAQ”、“手册”) - 来源维度:
filename、source - 时间维度:
created_date、updated_date - 质量维度:
score、rating - 业务维度:
category、department、product
业务场景分析
场景 1:企业知识库问答系统
需求:企业内部知识库包含多个部门的文档,需要根据用户部门返回相关文档。
实现:
// 存储时添加部门元数据
Document doc = Document.builder()
.text("财务部门的报销政策...")
.metadata(Map.of(
"department", "财务部",
"excerpt_keywords", List.of("报销", "政策", "财务")
))
.build();
// 检索时过滤部门
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.eq("department", userDepartment) // 只检索用户部门的文档
.in("excerpt_keywords", queryKeywords) // 并且包含查询关键词
.build();
业务价值:
- ✅ 确保用户只看到自己部门的文档
- ✅ 提高答案的相关性和准确性
- ✅ 保护敏感信息(跨部门文档不泄露)
场景 2:电商客服系统
需求:根据商品类别、订单状态等条件,检索相关的客服文档。
实现:
// 用户查询:"我的订单什么时候能退款?"
// 需要检索:退款相关的、订单状态的文档
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退款", "订单") // 包含退款或订单关键词
.eq("document_type", "客服FAQ") // 并且是客服FAQ类型
.build();
业务价值:
- ✅ 快速定位相关客服文档
- ✅ 提高客服响应速度
- ✅ 减少人工客服工作量
场景 3:法律文档检索系统
需求:根据法律领域、发布时间、效力状态等条件检索法律条文。
实现:
// 查询:2024年发布的、关于"合同"的、有效的法律条文
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "合同", "协议")
.and()
.eq("law_field", "合同法")
.and()
.eq("year", "2024")
.and()
.eq("status", "有效")
.build();
业务价值:
- ✅ 确保检索到最新、有效的法律条文
- ✅ 避免引用已失效的法律条文
- ✅ 提高法律咨询的准确性
场景 4:产品文档助手
需求:根据产品版本、功能模块、文档类型检索产品文档。
实现:
// 查询:v2.0版本的、关于"支付"功能的、用户手册
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.eq("product_version", "v2.0")
.and()
.in("excerpt_keywords", "支付", "付款")
.and()
.eq("document_type", "用户手册")
.build();
业务价值:
- ✅ 确保用户看到正确版本的产品文档
- ✅ 避免版本混淆导致的错误操作
- ✅ 提高用户自助解决问题的能力
场景 5:医疗知识问答系统
需求:根据疾病类型、症状、治疗方案等条件检索医疗文献。
实现:
// 查询:关于"高血压"的、包含"药物治疗"的、2020年后的文献
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "高血压", "药物治疗")
.and()
.gte("published_year", 2020)
.and()
.eq("literature_type", "临床研究")
.build();
业务价值:
- ✅ 确保检索到最新、相关的医疗文献
- ✅ 提高医疗咨询的准确性
- ✅ 支持循证医学实践
场景 6:多语言知识库
需求:支持多语言文档检索,根据用户语言偏好返回对应语言的文档。
实现:
// 存储时添加语言元数据
Document doc = Document.builder()
.text("Refund policy: You can cancel your booking...")
.metadata(Map.of(
"language", "en",
"excerpt_keywords", List.of("refund", "cancel", "policy")
))
.build();
// 检索时过滤语言
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.eq("language", userLanguage) // 只检索用户语言版本的文档
.in("excerpt_keywords", queryKeywords)
.build();
业务价值:
- ✅ 提供本地化的用户体验
- ✅ 避免语言混淆导致的误解
- ✅ 支持国际化业务场景
场景 7:权限控制的知识库
需求:根据用户权限级别,只返回用户有权限访问的文档。
实现:
// 存储时添加权限级别
Document doc = Document.builder()
.text("高级管理政策...")
.metadata(Map.of(
"access_level", "高级",
"excerpt_keywords", List.of("管理", "政策")
))
.build();
// 检索时过滤权限
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.lte("access_level", userAccessLevel) // 只检索用户权限范围内的文档
.in("excerpt_keywords", queryKeywords)
.build();
业务价值:
- ✅ 实现细粒度的权限控制
- ✅ 保护敏感信息不被未授权访问
- ✅ 符合企业安全合规要求
场景 8:时效性文档管理
需求:只检索在有效期内的文档,排除已过期或未生效的文档。
实现:
// 存储时添加有效期元数据
Document doc = Document.builder()
.text("促销活动政策...")
.metadata(Map.of(
"valid_from", "2024-01-01",
"valid_to", "2024-12-31",
"excerpt_keywords", List.of("促销", "活动")
))
.build();
// 检索时过滤有效期
LocalDate currentDate = LocalDate.now();
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.lte("valid_from", currentDate.toString()) // 已生效
.and()
.gte("valid_to", currentDate.toString()) // 未过期
.in("excerpt_keywords", queryKeywords)
.build();
业务价值:
- ✅ 确保用户看到的是当前有效的文档
- ✅ 避免引用过期信息导致的错误
- ✅ 自动管理文档生命周期
最佳实践
1. 元数据设计原则
✅ 推荐做法
原则 1:选择有意义的元数据字段
// ✅ 好的元数据设计
metadata.put("department", "财务部"); // 业务相关
metadata.put("document_type", "政策"); // 分类清晰
metadata.put("excerpt_keywords", keywords); // 支持过滤
// ❌ 不好的元数据设计
metadata.put("field1", "value1"); // 无意义的字段名
metadata.put("temp", "data"); // 临时字段
原则 2:使用标准化的值
// ✅ 使用枚举或常量
metadata.put("status", DocumentStatus.ACTIVE.name());
metadata.put("category", DocumentCategory.REFUND.name());
// ❌ 避免自由文本
metadata.put("status", "active"); // 可能不一致
metadata.put("status", "Active"); // 大小写不一致
原则 3:避免过度设计
// ✅ 只添加必要的元数据
metadata.put("excerpt_keywords", keywords);
metadata.put("filename", filename);
// ❌ 不要添加过多元数据
metadata.put("keyword1", "value1");
metadata.put("keyword2", "value2");
metadata.put("keyword3", "value3");
// ... 应该使用数组或列表
2. 关键词提取优化
关键词数量选择
// 根据文档长度选择关键词数量
int keywordCount;
if (documentLength < 500) {
keywordCount = 3; // 短文档:3个关键词
} else if (documentLength < 2000) {
keywordCount = 5; // 中等文档:5个关键词
} else {
keywordCount = 7; // 长文档:7个关键词
}
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(
chatModel,
keywordCount
);
自定义关键词模板
// 针对特定业务场景定制模板
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
请从以下内容中提取 %s 个关键词:
{context_str}
要求:
1. 关键词必须来自预定义列表:['退票', '预定', '改签', '费用', '政策']
2. 选择最能代表文档主题的关键词
3. 如果文档不包含预定义关键词,返回空列表
""";
3. 过滤表达式构建
✅ 推荐:使用 FilterExpressionBuilder
// ✅ 类型安全,易于维护
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.and()
.eq("status", "active")
.build();
❌ 避免:直接使用字符串
// ❌ 容易出错,难以维护
.filterExpression("excerpt_keywords in ('退票') AND status == 'active'")
复杂表达式的组织
// 将复杂表达式拆分为多个部分
FilterExpressionBuilder keywordFilter = FilterExpressionBuilder.builder()
.in("excerpt_keywords", keywords)
.build();
FilterExpressionBuilder statusFilter = FilterExpressionBuilder.builder()
.eq("status", "active")
.build();
// 组合使用
FilterExpressionBuilder combinedFilter = FilterExpressionBuilder.builder()
.in("excerpt_keywords", keywords)
.and()
.eq("status", "active")
.build();
4. 性能优化建议
过滤顺序优化
// ✅ 先过滤,再检索(如果向量库支持)
SearchRequest.builder()
.query(query)
.filterExpression(filterExpression) // 先过滤
.topK(5) // 再取前5个
.build();
// ❌ 先检索,再过滤(性能较差)
// 检索所有结果,然后在代码中过滤
索引元数据字段
如果使用支持索引的向量库(如 Pinecone、Weaviate),建议为常用过滤字段创建索引:
// 为常用过滤字段创建索引
// 例如:excerpt_keywords, category, status 等
缓存过滤结果
// 对于频繁使用的过滤条件,可以缓存结果
String cacheKey = "filter:" + filterExpression.toString();
List<Document> cachedResults = cache.get(cacheKey);
if (cachedResults == null) {
cachedResults = vectorStore.similaritySearch(searchRequest);
cache.put(cacheKey, cachedResults);
}
5. 错误处理
处理过滤表达式错误
try {
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build();
SearchRequest searchRequest = SearchRequest.builder()
.query(query)
.filterExpression(filterExpression)
.build();
List<Document> documents = vectorStore.similaritySearch(searchRequest);
} catch (FilterExpressionParseException e) {
// 过滤表达式解析失败,降级为不使用过滤
log.warn("Filter expression parse failed, falling back to no filter", e);
SearchRequest fallbackRequest = SearchRequest.builder()
.query(query)
.topK(5)
.build();
documents = vectorStore.similaritySearch(fallbackRequest);
}
处理元数据缺失
// 检查元数据是否存在
documents.forEach(doc -> {
if (!doc.getMetadata().containsKey("excerpt_keywords")) {
log.warn("Document missing excerpt_keywords metadata: {}", doc.getId());
// 可以选择跳过或使用默认值
}
});
6. 测试建议
单元测试
@Test
public void testMetadataFiltering() {
// 1. 准备测试数据
Document doc1 = Document.builder()
.text("退票政策...")
.metadata(Map.of("excerpt_keywords", List.of("退票", "政策")))
.build();
Document doc2 = Document.builder()
.text("预定政策...")
.metadata(Map.of("excerpt_keywords", List.of("预定", "政策")))
.build();
vectorStore.add(List.of(doc1, doc2));
// 2. 测试过滤
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build();
SearchRequest searchRequest = SearchRequest.builder()
.query("退票")
.filterExpression(filterExpression)
.topK(5)
.build();
List<Document> results = vectorStore.similaritySearch(searchRequest);
// 3. 验证结果
assertEquals(1, results.size());
assertTrue(results.get(0).getMetadata().get("excerpt_keywords")
.toString().contains("退票"));
}
集成测试
@Test
public void testEndToEndMetadataFiltering() {
// 1. 读取文档
List<Document> documents = readDocuments();
// 2. 关键词增强
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
documents = enricher.apply(documents);
// 3. 存储
vectorStore.add(documents);
// 4. 检索并过滤
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build();
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("退票费用")
.filterExpression(filterExpression)
.topK(5)
.build()
);
// 5. 验证所有结果都包含"退票"关键词
results.forEach(doc -> {
List<String> keywords = (List<String>) doc.getMetadata().get("excerpt_keywords");
assertTrue(keywords.contains("退票"),
"Document should contain '退票' keyword");
});
}
常见问题
Q1: 为什么使用元数据过滤后,检索结果变少了?
原因分析:
- 过滤条件太严格:过滤表达式可能排除了太多文档
- 元数据不完整:部分文档可能缺少必要的元数据字段
- 关键词提取不准确:
KeywordMetadataEnricher提取的关键词可能不包含查询关键词
解决方案:
// 方案 1:放宽过滤条件
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票", "取消", "退款") // 增加关键词范围
.build();
// 方案 2:使用 OR 逻辑
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.or()
.in("excerpt_keywords", "取消") // 包含任一关键词即可
.build();
// 方案 3:降级处理(无过滤时返回结果)
if (results.isEmpty()) {
// 降级为不使用过滤
results = vectorStore.similaritySearch(
SearchRequest.builder().query(query).topK(5).build()
);
}
Q2: 如何调试过滤表达式?
调试步骤:
// 步骤 1:检查元数据格式
documents.forEach(doc -> {
System.out.println("Document ID: " + doc.getId());
System.out.println("Metadata: " + doc.getMetadata());
System.out.println("excerpt_keywords: " +
doc.getMetadata().get("excerpt_keywords"));
System.out.println("excerpt_keywords type: " +
doc.getMetadata().get("excerpt_keywords").getClass());
});
// 步骤 2:测试简单过滤表达式
FilterExpressionBuilder simpleFilter = FilterExpressionBuilder.builder()
.eq("filename", "terms-of-service.txt") // 先测试简单条件
.build();
// 步骤 3:逐步增加复杂度
FilterExpressionBuilder complexFilter = FilterExpressionBuilder.builder()
.eq("filename", "terms-of-service.txt")
.and()
.in("excerpt_keywords", "退票") // 再添加复杂条件
.build();
Q3: excerpt_keywords 是数组类型,如何正确过滤?
问题:excerpt_keywords 存储的是 List<String>,使用 in 操作符时需要注意语法。
解决方案:
// ✅ 正确:使用 FilterExpressionBuilder.in()
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票") // 检查数组是否包含"退票"
.build();
// ✅ 正确:检查多个值
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票", "费用") // 检查数组是否包含任一值
.build();
// ❌ 错误:字符串形式的数组语法
.filterExpression("excerpt_keywords in [\"退票\"]") // 可能解析失败
Q4: 如何提高关键词提取的准确性?
优化方法:
// 方法 1:使用更强大的模型
// 选择能力更强的 ChatModel(如 GPT-4、Claude)
// 方法 2:自定义模板,提供更多上下文
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
请从以下文档内容中提取 %s 个关键词:
{context_str}
文档类型:服务条款
业务领域:航空票务
要求:
1. 关键词必须准确反映文档主题
2. 优先选择业务相关的关键词
3. 避免选择过于通用的词汇
""";
// 方法 3:后处理验证
List<String> extractedKeywords = (List<String>) doc.getMetadata()
.get("excerpt_keywords");
List<String> validKeywords = extractedKeywords.stream()
.filter(keyword -> isValidKeyword(keyword, documentText))
.collect(Collectors.toList());
doc.getMetadata().put("excerpt_keywords", validKeywords);
Q5: 元数据过滤会影响性能吗?
性能影响分析:
| 因素 | 影响 | 说明 |
|---|---|---|
| 向量库类型 | 高 | 支持索引的向量库(如 Pinecone)性能更好 |
| 过滤条件复杂度 | 中 | 简单条件(eq, in)比复杂条件(and, or)快 |
| 文档数量 | 高 | 文档越多,过滤开销越大 |
| 元数据索引 | 高 | 为常用过滤字段创建索引可显著提升性能 |
优化建议:
// 1. 使用支持索引的向量库
// 2. 为常用过滤字段创建索引
// 3. 简化过滤表达式
// 4. 考虑缓存过滤结果
Q6: 如何处理元数据不一致的问题?
问题场景:
- 部分文档有
excerpt_keywords,部分没有 - 关键词格式不一致(字符串 vs 数组)
- 字段名拼写错误
解决方案:
// 方案 1:数据清洗
documents.forEach(doc -> {
Map<String, Object> metadata = doc.getMetadata();
// 标准化字段名
if (metadata.containsKey("keywords")) {
metadata.put("excerpt_keywords", metadata.remove("keywords"));
}
// 确保 excerpt_keywords 是 List 类型
Object keywords = metadata.get("excerpt_keywords");
if (keywords instanceof String) {
metadata.put("excerpt_keywords", List.of((String) keywords));
} else if (keywords == null) {
metadata.put("excerpt_keywords", List.of()); // 空列表
}
});
// 方案 2:使用默认值
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.or()
.eq("excerpt_keywords", null) // 允许元数据缺失的文档
.build();
Q7: 什么时候应该使用元数据过滤?
适用场景:
- ✅ 需要精确匹配特定类别或主题的文档
- ✅ 需要基于业务规则过滤文档(如权限、有效期)
- ✅ 大规模知识库中需要减少噪音文档
- ✅ 需要支持复杂的多条件查询
不适用场景:
- ❌ 简单的语义检索(仅使用向量相似度即可)
- ❌ 文档数量很少(过滤开销可能大于收益)
- ❌ 元数据不完整或不准确(过滤可能失效)
Q8: 如何平衡相似度检索和元数据过滤?
策略:
// 策略 1:先过滤,再检索(推荐)
// 适用于:过滤条件能显著减少候选文档数量
SearchRequest.builder()
.query(query)
.filterExpression(filterExpression) // 先过滤
.topK(5) // 再取前5个
.build();
// 策略 2:先检索,再过滤
// 适用于:过滤条件复杂,或向量库不支持过滤
List<Document> candidates = vectorStore.similaritySearch(
SearchRequest.builder().query(query).topK(20).build()
);
List<Document> filtered = candidates.stream()
.filter(doc -> matchesFilter(doc, filterExpression))
.limit(5)
.collect(Collectors.toList());
// 策略 3:混合策略
// 使用较低的相似度阈值 + 元数据过滤
SearchRequest.builder()
.query(query)
.similarityThreshold(0.3) // 较低的阈值,召回更多
.filterExpression(filterExpression) // 用过滤提高精度
.topK(5)
.build();
总结
核心要点
-
元数据增强是基础:使用
KeywordMetadataEnricher为文档添加关键词元数据,是元数据过滤的前提。 -
过滤表达式要规范:优先使用
FilterExpressionBuilder构建过滤表达式,避免字符串形式的语法错误。 -
业务场景决定设计:根据实际业务需求设计元数据字段和过滤策略,不要过度设计。
-
性能与精度平衡:在检索精度和性能之间找到平衡点,必要时使用降级策略。
-
错误处理要完善:处理过滤表达式解析错误、元数据缺失等异常情况,确保系统稳定性。
最佳实践总结
| 实践 | 说明 |
|---|---|
✅ 使用 FilterExpressionBuilder |
类型安全,易于维护 |
| ✅ 设计有意义的元数据字段 | 业务相关,分类清晰 |
| ✅ 为常用过滤字段创建索引 | 提升查询性能 |
| ✅ 实现降级策略 | 过滤失败时仍能返回结果 |
| ✅ 完善的错误处理 | 提高系统健壮性 |
| ✅ 充分的测试覆盖 | 确保功能正确性 |
适用场景总结
元数据过滤特别适合以下场景:
- 企业知识库(部门、权限过滤)
- 电商客服(商品类别、订单状态)
- 法律文档(领域、时效性)
- 产品文档(版本、功能模块)
- 医疗知识(疾病类型、文献类型)
- 多语言知识库(语言过滤)
- 权限控制(访问级别)
- 时效性文档(有效期管理)
参考资料
- Spring AI 官方文档 - Vector Store
- Spring AI 官方文档 - Metadata Filtering
- FilterExpressionBuilder API
- KeywordMetadataEnricher API求**:支持多语言文档检索,根据用户语言偏好返回对应语言的文档。
实现:
// 存储时添加语言元数据
Document doc = Document.builder()
.text("Refund policy: You can cancel your booking...")
.metadata(Map.of(
"language", "en",
"excerpt_keywords", List.of("refund", "cancel", "policy")
))
.build();
// 检索时过滤语言
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.eq("language", userLanguage) // 只检索用户语言版本的文档
.in("excerpt_keywords", queryKeywords)
.build();
业务价值:
- ✅ 提供本地化的用户体验
- ✅ 避免语言混淆导致的误解
- ✅ 支持国际化业务场景
场景 7:权限控制的知识库
需求:根据用户权限级别,只返回用户有权限访问的文档。
实现:
// 存储时添加权限级别
Document doc = Document.builder()
.text("高级管理政策...")
.metadata(Map.of(
"access_level", "高级",
"excerpt_keywords", List.of("管理", "政策")
))
.build();
// 检索时过滤权限
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.lte("access_level", userAccessLevel) // 只检索用户权限范围内的文档
.in("excerpt_keywords", queryKeywords)
.build();
业务价值:
- ✅ 实现细粒度的权限控制
- ✅ 保护敏感信息不被未授权访问
- ✅ 符合企业安全合规要求
场景 8:时效性文档管理
需求:只检索在有效期内的文档,排除已过期或未生效的文档。
实现:
// 存储时添加有效期元数据
Document doc = Document.builder()
.text("促销活动政策...")
.metadata(Map.of(
"valid_from", "2024-01-01",
"valid_to", "2024-12-31",
"excerpt_keywords", List.of("促销", "活动")
))
.build();
// 检索时过滤有效期
LocalDate currentDate = LocalDate.now();
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.lte("valid_from", currentDate.toString()) // 已生效
.and()
.gte("valid_to", currentDate.toString()) // 未过期
.in("excerpt_keywords", queryKeywords)
.build();
业务价值:
- ✅ 确保用户看到的是当前有效的文档
- ✅ 避免引用过期信息导致的错误
- ✅ 自动管理文档生命周期
最佳实践
1. 元数据设计原则
✅ 推荐做法
原则 1:选择有意义的元数据字段
// ✅ 好的元数据设计
metadata.put("department", "财务部"); // 业务相关
metadata.put("document_type", "政策"); // 分类清晰
metadata.put("excerpt_keywords", keywords); // 支持过滤
// ❌ 不好的元数据设计
metadata.put("field1", "value1"); // 无意义的字段名
metadata.put("temp", "data"); // 临时字段
原则 2:使用标准化的值
// ✅ 使用枚举或常量
metadata.put("status", DocumentStatus.ACTIVE.name());
metadata.put("category", DocumentCategory.REFUND.name());
// ❌ 避免自由文本
metadata.put("status", "active"); // 可能不一致
metadata.put("status", "Active"); // 大小写不一致
原则 3:避免过度设计
// ✅ 只添加必要的元数据
metadata.put("excerpt_keywords", keywords);
metadata.put("filename", filename);
// ❌ 不要添加过多元数据
metadata.put("keyword1", "value1");
metadata.put("keyword2", "value2");
metadata.put("keyword3", "value3");
// ... 应该使用数组或列表
2. 关键词提取优化
关键词数量选择
// 根据文档长度选择关键词数量
int keywordCount;
if (documentLength < 500) {
keywordCount = 3; // 短文档:3个关键词
} else if (documentLength < 2000) {
keywordCount = 5; // 中等文档:5个关键词
} else {
keywordCount = 7; // 长文档:7个关键词
}
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(
chatModel,
keywordCount
);
自定义关键词模板
// 针对特定业务场景定制模板
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
请从以下内容中提取 %s 个关键词:
{context_str}
要求:
1. 关键词必须来自预定义列表:['退票', '预定', '改签', '费用', '政策']
2. 选择最能代表文档主题的关键词
3. 如果文档不包含预定义关键词,返回空列表
""";
3. 过滤表达式构建
✅ 推荐:使用 FilterExpressionBuilder
// ✅ 类型安全,易于维护
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.and()
.eq("status", "active")
.build();
❌ 避免:直接使用字符串
// ❌ 容易出错,难以维护
.filterExpression("excerpt_keywords in ('退票') AND status == 'active'")
复杂表达式的组织
// 将复杂表达式拆分为多个部分
FilterExpressionBuilder keywordFilter = FilterExpressionBuilder.builder()
.in("excerpt_keywords", keywords)
.build();
FilterExpressionBuilder statusFilter = FilterExpressionBuilder.builder()
.eq("status", "active")
.build();
// 组合使用
FilterExpressionBuilder combinedFilter = FilterExpressionBuilder.builder()
.in("excerpt_keywords", keywords)
.and()
.eq("status", "active")
.build();
4. 性能优化建议
过滤顺序优化
// ✅ 先过滤,再检索(如果向量库支持)
SearchRequest.builder()
.query(query)
.filterExpression(filterExpression) // 先过滤
.topK(5) // 再取前5个
.build();
// ❌ 先检索,再过滤(性能较差)
// 检索所有结果,然后在代码中过滤
索引元数据字段
如果使用支持索引的向量库(如 Pinecone、Weaviate),建议为常用过滤字段创建索引:
// 为常用过滤字段创建索引
// 例如:excerpt_keywords, category, status 等
缓存过滤结果
// 对于频繁使用的过滤条件,可以缓存结果
String cacheKey = "filter:" + filterExpression.toString();
List<Document> cachedResults = cache.get(cacheKey);
if (cachedResults == null) {
cachedResults = vectorStore.similaritySearch(searchRequest);
cache.put(cacheKey, cachedResults);
}
5. 错误处理
处理过滤表达式错误
try {
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build();
SearchRequest searchRequest = SearchRequest.builder()
.query(query)
.filterExpression(filterExpression)
.build();
List<Document> documents = vectorStore.similaritySearch(searchRequest);
} catch (FilterExpressionParseException e) {
// 过滤表达式解析失败,降级为不使用过滤
log.warn("Filter expression parse failed, falling back to no filter", e);
SearchRequest fallbackRequest = SearchRequest.builder()
.query(query)
.topK(5)
.build();
documents = vectorStore.similaritySearch(fallbackRequest);
}
处理元数据缺失
// 检查元数据是否存在
documents.forEach(doc -> {
if (!doc.getMetadata().containsKey("excerpt_keywords")) {
log.warn("Document missing excerpt_keywords metadata: {}", doc.getId());
// 可以选择跳过或使用默认值
}
});
6. 测试建议
单元测试
@Test
public void testMetadataFiltering() {
// 1. 准备测试数据
Document doc1 = Document.builder()
.text("退票政策...")
.metadata(Map.of("excerpt_keywords", List.of("退票", "政策")))
.build();
Document doc2 = Document.builder()
.text("预定政策...")
.metadata(Map.of("excerpt_keywords", List.of("预定", "政策")))
.build();
vectorStore.add(List.of(doc1, doc2));
// 2. 测试过滤
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build();
SearchRequest searchRequest = SearchRequest.builder()
.query("退票")
.filterExpression(filterExpression)
.topK(5)
.build();
List<Document> results = vectorStore.similaritySearch(searchRequest);
// 3. 验证结果
assertEquals(1, results.size());
assertTrue(results.get(0).getMetadata().get("excerpt_keywords")
.toString().contains("退票"));
}
集成测试
@Test
public void testEndToEndMetadataFiltering() {
// 1. 读取文档
List<Document> documents = readDocuments();
// 2. 关键词增强
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
documents = enricher.apply(documents);
// 3. 存储
vectorStore.add(documents);
// 4. 检索并过滤
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.build();
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("退票费用")
.filterExpression(filterExpression)
.topK(5)
.build()
);
// 5. 验证所有结果都包含"退票"关键词
results.forEach(doc -> {
List<String> keywords = (List<String>) doc.getMetadata().get("excerpt_keywords");
assertTrue(keywords.contains("退票"),
"Document should contain '退票' keyword");
});
}
常见问题
Q1: 为什么使用元数据过滤后,检索结果变少了?
原因分析:
- 过滤条件太严格:过滤表达式可能排除了太多文档
- 元数据不完整:部分文档可能缺少必要的元数据字段
- 关键词提取不准确:
KeywordMetadataEnricher提取的关键词可能不包含查询关键词
解决方案:
// 方案 1:放宽过滤条件
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票", "取消", "退款") // 增加关键词范围
.build();
// 方案 2:使用 OR 逻辑
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.or()
.in("excerpt_keywords", "取消") // 包含任一关键词即可
.build();
// 方案 3:降级处理(无过滤时返回结果)
if (results.isEmpty()) {
// 降级为不使用过滤
results = vectorStore.similaritySearch(
SearchRequest.builder().query(query).topK(5).build()
);
}
Q2: 如何调试过滤表达式?
调试步骤:
// 步骤 1:检查元数据格式
documents.forEach(doc -> {
System.out.println("Document ID: " + doc.getId());
System.out.println("Metadata: " + doc.getMetadata());
System.out.println("excerpt_keywords: " +
doc.getMetadata().get("excerpt_keywords"));
System.out.println("excerpt_keywords type: " +
doc.getMetadata().get("excerpt_keywords").getClass());
});
// 步骤 2:测试简单过滤表达式
FilterExpressionBuilder simpleFilter = FilterExpressionBuilder.builder()
.eq("filename", "terms-of-service.txt") // 先测试简单条件
.build();
// 步骤 3:逐步增加复杂度
FilterExpressionBuilder complexFilter = FilterExpressionBuilder.builder()
.eq("filename", "terms-of-service.txt")
.and()
.in("excerpt_keywords", "退票") // 再添加复杂条件
.build();
Q3: excerpt_keywords 是数组类型,如何正确过滤?
问题:excerpt_keywords 存储的是 List<String>,使用 in 操作符时需要注意语法。
解决方案:
// ✅ 正确:使用 FilterExpressionBuilder.in()
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票") // 检查数组是否包含"退票"
.build();
// ✅ 正确:检查多个值
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票", "费用") // 检查数组是否包含任一值
.build();
// ❌ 错误:字符串形式的数组语法
.filterExpression("excerpt_keywords in [\"退票\"]") // 可能解析失败
Q4: 如何提高关键词提取的准确性?
优化方法:
// 方法 1:使用更强大的模型
// 选择能力更强的 ChatModel(如 GPT-4、Claude)
// 方法 2:自定义模板,提供更多上下文
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
请从以下文档内容中提取 %s 个关键词:
{context_str}
文档类型:服务条款
业务领域:航空票务
要求:
1. 关键词必须准确反映文档主题
2. 优先选择业务相关的关键词
3. 避免选择过于通用的词汇
""";
// 方法 3:后处理验证
List<String> extractedKeywords = (List<String>) doc.getMetadata()
.get("excerpt_keywords");
List<String> validKeywords = extractedKeywords.stream()
.filter(keyword -> isValidKeyword(keyword, documentText))
.collect(Collectors.toList());
doc.getMetadata().put("excerpt_keywords", validKeywords);
Q5: 元数据过滤会影响性能吗?
性能影响分析:
| 因素 | 影响 | 说明 |
|---|---|---|
| 向量库类型 | 高 | 支持索引的向量库(如 Pinecone)性能更好 |
| 过滤条件复杂度 | 中 | 简单条件(eq, in)比复杂条件(and, or)快 |
| 文档数量 | 高 | 文档越多,过滤开销越大 |
| 元数据索引 | 高 | 为常用过滤字段创建索引可显著提升性能 |
优化建议:
// 1. 使用支持索引的向量库
// 2. 为常用过滤字段创建索引
// 3. 简化过滤表达式
// 4. 考虑缓存过滤结果
Q6: 如何处理元数据不一致的问题?
问题场景:
- 部分文档有
excerpt_keywords,部分没有 - 关键词格式不一致(字符串 vs 数组)
- 字段名拼写错误
解决方案:
// 方案 1:数据清洗
documents.forEach(doc -> {
Map<String, Object> metadata = doc.getMetadata();
// 标准化字段名
if (metadata.containsKey("keywords")) {
metadata.put("excerpt_keywords", metadata.remove("keywords"));
}
// 确保 excerpt_keywords 是 List 类型
Object keywords = metadata.get("excerpt_keywords");
if (keywords instanceof String) {
metadata.put("excerpt_keywords", List.of((String) keywords));
} else if (keywords == null) {
metadata.put("excerpt_keywords", List.of()); // 空列表
}
});
// 方案 2:使用默认值
FilterExpressionBuilder filterExpression = FilterExpressionBuilder.builder()
.in("excerpt_keywords", "退票")
.or()
.eq("excerpt_keywords", null) // 允许元数据缺失的文档
.build();
Q7: 什么时候应该使用元数据过滤?
适用场景:
- ✅ 需要精确匹配特定类别或主题的文档
- ✅ 需要基于业务规则过滤文档(如权限、有效期)
- ✅ 大规模知识库中需要减少噪音文档
- ✅ 需要支持复杂的多条件查询
不适用场景:
- ❌ 简单的语义检索(仅使用向量相似度即可)
- ❌ 文档数量很少(过滤开销可能大于收益)
- ❌ 元数据不完整或不准确(过滤可能失效)
Q8: 如何平衡相似度检索和元数据过滤?
策略:
// 策略 1:先过滤,再检索(推荐)
// 适用于:过滤条件能显著减少候选文档数量
SearchRequest.builder()
.query(query)
.filterExpression(filterExpression) // 先过滤
.topK(5) // 再取前5个
.build();
// 策略 2:先检索,再过滤
// 适用于:过滤条件复杂,或向量库不支持过滤
List<Document> candidates = vectorStore.similaritySearch(
SearchRequest.builder().query(query).topK(20).build()
);
List<Document> filtered = candidates.stream()
.filter(doc -> matchesFilter(doc, filterExpression))
.limit(5)
.collect(Collectors.toList());
// 策略 3:混合策略
// 使用较低的相似度阈值 + 元数据过滤
SearchRequest.builder()
.query(query)
.similarityThreshold(0.3) // 较低的阈值,召回更多
.filterExpression(filterExpression) // 用过滤提高精度
.topK(5)
.build();
总结
核心要点
-
元数据增强是基础:使用
KeywordMetadataEnricher为文档添加关键词元数据,是元数据过滤的前提。 -
过滤表达式要规范:优先使用
FilterExpressionBuilder构建过滤表达式,避免字符串形式的语法错误。 -
业务场景决定设计:根据实际业务需求设计元数据字段和过滤策略,不要过度设计。
-
性能与精度平衡:在检索精度和性能之间找到平衡点,必要时使用降级策略。
-
错误处理要完善:处理过滤表达式解析错误、元数据缺失等异常情况,确保系统稳定性。
最佳实践总结
| 实践 | 说明 |
|---|---|
✅ 使用 FilterExpressionBuilder |
类型安全,易于维护 |
| ✅ 设计有意义的元数据字段 | 业务相关,分类清晰 |
| ✅ 为常用过滤字段创建索引 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)